利用Eviews软件进行最小二乘法回归实例
- 格式:doc
- 大小:479.00 KB
- 文档页数:9

Glossa ry:ls(leastsquare s)最小二乘法R-sequar ed样本决定系数(R2):值为0-1,越接近1表示拟合越好,>0.8认为可以接受,但是R2随因变量的增多而增大,解决这个问题使用来调整Adjust R-seqaur ed()S.E of regres sion回归标准误差Log likeli hood对数似然比:残差越小,L值越大,越大说明模型越正确Durbin-Watson stat:DW统计量,0-4之间Mean depend ent var因变量的均值S.D. depend ent var因变量的标准差Akaike info criter ion赤池信息量(AIC)(越小说明模型越精确)Schwar z ctiter ion:施瓦兹信息量(SC)(越小说明模型越精确)Prob(F-statis tic)相伴概率fitted(拟合值)线性回归的基本假设:1.自变量之间不相关2.随机误差相互独立,且服从期望为0,标准差为σ的正态分布3.样本个数多于参数个数建模方法:ls y c x1 x2 x3 ...x1 x2 x3的选择先做各序列之间的简单相关系数计算,选择同因变量相关系数大而自变量相关系数小的一些变量。
模型的实际业务含义也有指导意义,比如m1同g d p肯定是相关的。
模型的建立是简单的,复杂的是模型的检验、评价和之后的调整、择优。
模型检验:1)方程显著性检验(F检验):模型拟合样本的效果,即选择的所有自变量对因变量的解释力度F大于临界值则说明拒绝0假设。
Eviews给出了拒绝0假设(所有系统为0的假设)犯错误(第一类错误或α错误)的概率(收尾概率或相伴概率)p值,若p小于置信度(如0.05)则可以拒绝0假设,即认为方程显著性明显。
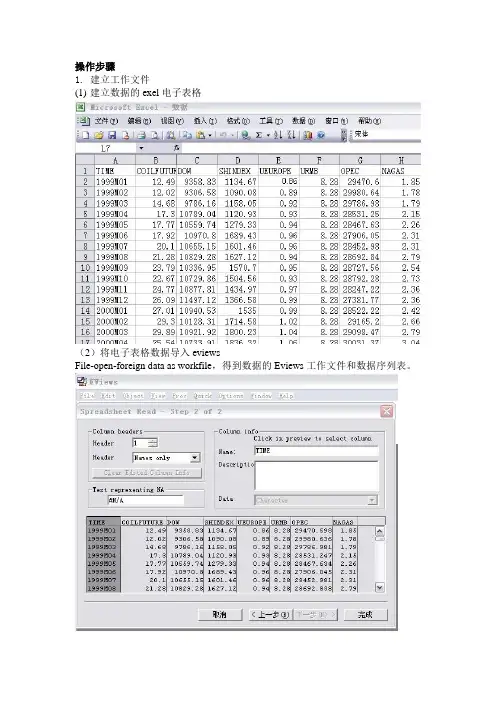
操作步骤1.建立工作文件(1)建立数据的exel电子表格(2)将电子表格数据导入eviewsFile-open-foreign data as workfile,得到数据的Eviews工作文件和数据序列表。
2.计算变量间的相关系数在窗口中输入命令:cor coilfuture dow shindex nagas opec ueurope urmb,点击回车键,得到各序列之间的相关系数。
结果表明Coilfuture数列与其他数列存在较好的相关关系。
3.时间序列的平稳性检验(1)观察coilfuture序列趋势图在eviews中得到时间序列趋势图,在quick菜单中单击graph,在series list对话框中输入序列名称coilfuture,其他选择默认操作。
图形表明序列随时间变化存在上升趋势。
(2)对原序列进行ADF平稳性检验quick-series statistics-unit root test,在弹出的series name对话框中输入需要检验的序列的名称,在test for unit root in 选择框中选择level,得到原数据序列的ADF检验结果,其他保持默认设置。
得到序列的ADF平稳性检验结果,检测值0.97大于所有临界值,则表明序列不平稳。
以此方法,对各时间序列依次进行ADF检验,将检验值与临界值比较,发现所有序列的检验值均大于临界值,表明各原序列都是非平稳的。
(3)时间序列数据的一阶差分的ADF检验quick-series statistics-unit root test,在series name对话框中输入需要检验的序列的名称,在test for unit root in 选择框中选择1nd difference,对其一阶差分进行平稳性检验,其他保持默认设置。
得到序列的ADF平稳性检验结果,检测值-7.8远小于所有临界值,则表明序列一阶差分平稳。
以此方法,对各时间序列的一阶差分依次进行ADF检验,将检验值与临界值比较,发现所有序列的检验值均小于临界值,表明各序列一阶差分都是平稳的。

eviews实验报告总结eviews实验报告总结篇一:Evies实验报告实验报告一、实验数据:1994至201X年天津市城镇居民人均全年可支配收入数据 1994至201X年天津市城镇居民人均全年消费性支出数据 1994至201X年天津市居民消费价格总指数二、实验内容:对搜集的数据进行回归,研究天津市城镇居民人均消费和人均可支配收入的关系。
三、实验步骤:1、百度进入“中华人民共和国国家统计局”中的“统计数据”,找到相关数据并输入Exc el,统计结果如下表1:表11994年--201X年天津市城镇居民消费支出与人均可支配收入数据2、先定义不变价格(1994=1)的人均消费性支出(Yt)和人均可支配收入(Xt)令:Yt=cn sum/priceXt=ine/pri ce 得出Yt与Xt的散点图,如图1.很明显,Yt和X t服从线性相关。
图1 Yt和Xt散点图3、应用统计软件EVies完成线性回归解:根据经济理论和对实际情况的分析也都可以知道,城镇居民人均全年耐用消费品支出Yt依赖于人均全年可支配收入Xt的变化,因此设定回归模型为 Yt=β0+β?Xt﹢μt(1)打开E Vies软件,首先建立工作文件, Fil e rkfile ,然后通过bject建立 Y、X系列,并得到相应数据。
(2)在工作文件窗口输入命令:l s y c x,按E nter键,回归结果如表2 :表2 回归结果根据输出结果,得到如下回归方程:Y t=977.908+0.670Xt s=(172.3797) (0.0122) t=(5.673) (54.950) R2=0.995385 Adjust ed R2=0.995055 F-sta tistic=3019.551 残差平方和Sum sq uared resi d =1254108回归标准差S.E.f regressi n=299.2978(3)根据回归方程进行统计检验:拟合优度检验由上表2中的数分别为0.995385和0.995055,计算结果表明,估计的样本回归方程较好地拟合了样本观测值。

美股行情对A股的影响性分析——标普500与沪深300相关性分析摘要:本文主要通过分析标准普尔500指数与沪深300指数的相关性,以标普500指数为解释变量,以沪深300指数为被解释变量,利用Eviews软件,使用其中的最小二乘法对其进行线性回归分析,最终得出方程。
并对其进行显著性检验(F,t)、异方差检验、自相关性检验来验证方程的可靠性。
然后解释方程的经济意义,并利用软件对未来指数变动进行预测。
最后在未来几天比较预测结果与实际两个指数的变化情况,验证实际应用情况。
关键词:标普500、沪深300、Eviews、显著性检验、异方差检验、自相关性检验。
一、研究背景1.全球化大环境在经济全球化不断深入发展的今天,全球资本市场,尤其是中美两个超级大国之间的资本流通,早已彼此嵌入,密不可分。
全世界早有不少学者对中美资本流通做了深入研究。
但美国股市发展早于中国十几年,其内部的资金也远远超过中国股市,美国股市的资本流动势必会对中国股市产生一定影响,这种影响不仅体现在情绪面,更反映在指数变动方向上。
2.对外开放资本市场的QFII政策Qualified Foreign Institutional Investor,作为一种过渡性制度安排,QFII制度是在资本项目尚未完全开放的国家和地区,实现有序、稳妥开放证券市场的特殊通道。
外资对中国股市的影响早已不可忽视,而美国市场的变动也一定程度会影响在中国股市外资的操作行为。
所以研究两个指数的变动是很有意义的。
二、数据1.数据选择沪深两个市场各自均有独立的综合指数和成份指数,这些指数不能用来反映沪深两市的整体情况,而沪深300指数则同时考虑了两市的交易情况,是中国A股市场的“晴雨表”。
标准普尔500指数英文简写为S&P 500 Index,是记录美国500家上市公司的一个股票指数。
与道琼斯指数等其他指数相比,标准普尔500指数包含的公司更多,因此风险更为分散,能够反映更广泛的市场变化。
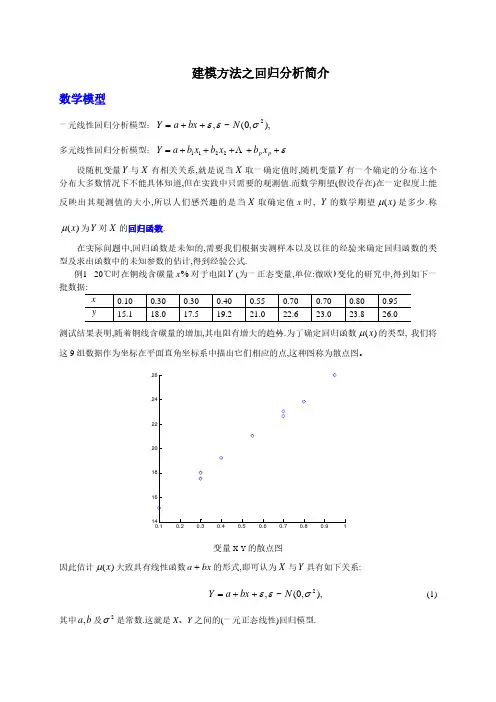
建模方法之回归分析简介数学模型一元线性回归分析模型:),,0(~,2σεεN bx a Y ++= 多元线性回归分析模型:ε+++++=p p x b x b x b a Y Λ2211设随机变量Y 与X 有相关关系,就是说当X 取一确定值时,随机变量Y 有一个确定的分布.这个分布大多数情况下不能具体知道,但在实践中只需要的观测值.而数学期望(假设存在)在一定程度上能反映出其观测值的大小,所以人们感兴趣的是当X 取确定值x 时, Y 的数学期望)(x μ是多少.称)(x μ为Y 对X 的回归函数.在实际问题中,回归函数是未知的,需要我们根据实测样本以及以往的经验来确定回归函数的类型及求出函数中的未知参数的估计,得到经验公式.例1 20℃时在铜线含碳量%x 对于电阻Y (为一正态变量,单位:微欧)变化的研究中,得到如下一测试结果表明,随着铜线含碳量的增加,其电阻有增大的趋势.为了确定回归函数)(x μ的类型, 我们将这9组数据作为坐标在平面直角坐标系中描出它们相应的点,这种图称为散点图。
变量X -Y 的散点图因此估计)(x μ大致具有线性函数bx a +的形式,即可认为X 与Y 具有如下关系:),,0(~,2σεεN bx a Y ++= (1)其中b a ,及2σ是常数.这就是X 、Y 之间的(一元正态线性)回归模型.对n 根铜线进行独立观测,能得到n 个含碳量n x x x ,,,21Λ及对应的n Y Y Y ,,,21Λ,把i Y 看成随即变量,则它们可以表示成⎭⎬⎫=++=.,,,),,0(~,,,2,1,212相互独立n i i i i N n i bx a Y εεεσεεΛΛ (2)记⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=n x x x X 11121M M ,⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=n Y Y Y Y M 21,⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=n εεεεM 21, 则(2)式也可表示为ε+⎪⎪⎭⎫⎝⎛=b a X Y .在一元线性回归中主要解决下列问题: (I ) 对未知参数b a ,及2σ进行估计; (II ) 对线性模型的假设进行检验; (III ) 对Y 进行预测和控制.参数的估计:对未知参数b a ,的估计,一个直观的想法便是希望选取这样的a 与b ,使得他们在n x x x ,,,21Λ各处计算的理论值i bx a +与实测值i y 的偏离达到最小.为此人们常用最小二乘法:求b a ,使∑=−−=ni i ibx a yQ 12)(为最小.在几何上,即是在平面上选取一条直线,使直线在横坐标为n x x x ,,,21Λ处的纵坐标与相应的实测点的纵坐标之差的平方和为最小.利用求极值的方法求b a ,,令⎪⎪⎩⎪⎪⎨⎧=−−−=∂∂=−−−=∂∂∑∑==.0)(2,0)(211ni i i i ni i i x bx a y b Q bx a y a Q整理得⎪⎪⎩⎪⎪⎨⎧=+=+∑∑∑∑∑=====ni i i n i i n i i ni i n i i y x x b x a y x b na 112111解此方程组得到的不是b a ,的真值,而是b a ,的估计值,ˆ,ˆb a它们为 ,)())((ˆ1212121∑∑∑∑====−−−=−−=ni ini i ini ini ii x xy y x xx n xyx n yx b(3),ˆˆx b y a−= (4) 其中.,111∑∑====ni i ni i y y x n x 具体计算得Y 对X 的线性回归方程为.59.1297.13ˆx y+= 等价公式:Y X X X ba TT 1)(ˆˆ−=⎥⎦⎤⎢⎣⎡. (5)方差分析:总平方和:,)(12∑=−=ni iT Y YQ 自由度为1−n回归平方和:∑=−=ni iR Y Y Q 12)ˆ(,)(ˆ122∑=−=ni i x x b 自由度为1=p 残差平方和:,)ˆ(12∑=−=ni iiE Y YQ 自由度为1−−p n 关系式:.E R T Q Q Q += 性质:2)1(σ=−−p n Q E E 。

(Error Correction Model)Srba 和Yeo 于模型。
它常常作为协整回归模型的补充模型出现。
两步法建立误差修正模型
p t B Y -++
绘制中国城镇居民月人均生活费支出(y)和可支配收入序列(x)的折线图: 可以看到两者呈现公共的上升趋势。
对X与Y分别取对数:
然后对xt与yt序列进行平稳性检验:
容易发现: XT与YT序列均不是平稳的, 但是其一阶差分都是平稳的, 因此猜测他们具有协整关系。
对YT和XT序列进行回归后发现:
可以看到对应的两个参数的系数的p值都显著小于0.001。
生成一列序列=残差, 对该序列进行ADF检验后可以发现p值小于0.05, 因
此认为不存在单位根, 序列是平稳的。
因此, 尽管国城镇居民月人均生活费支出(y )和可支配收入序列(x )都是非平稳的, 但是由于它们之间具有协整关系, 因此可以建立动态回归模型准确预测其长期互动关系。
模型拟合的预测值DCPIF 的折线图和与dcpi 的对比图如下:
可以看到, 最后的拟合效果非常好。
从而我们得到最后的拟合方程为:
t t t x y ε++=)ln(*934.0328.0)ln(
即:
因此, 城镇居民收入没增加一个百分点, 其消费支出也增加0.934各百分点。
【结论】(结果)
我国城镇居民月人均生活费支出(y )和可支配收入序列(x )的对数化后的XT 与YT 序列均不是平稳的, 但是其一阶差分都是平稳的, 因此猜测他们具有协。

[经验分享] 使用eviews做线性回归分析Glossary:ls(least squares)最小二乘法R-sequared样本决定系数(R2):值为0-1,越接近1表示拟合越好,>0.8认为可以接受,但是R2随因变量的增多而增大,解决这个问题使用来调整Adjust R-seqaured()S.E of regression回归标准误差Log likelihood对数似然比:残差越小,L值越大,越大说明模型越正确Durbin-Watson stat:DW统计量,0-4之间Mean dependent var因变量的均值S.D. dependent var因变量的标准差Akaike info criterion赤池信息量(AIC)(越小说明模型越精确)Schwarz ctiterion:施瓦兹信息量(SC)(越小说明模型越精确)Prob(F-statistic)相伴概率fitted(拟合值)线性回归的基本假设:1.自变量之间不相关2.随机误差相互独立,且服从期望为0,标准差为σ的正态分布3.样本个数多于参数个数建模方法:ls y c x1 x2 x3 ...x1 x2 x3的选择先做各序列之间的简单相关系数计算,选择同因变量相关系数大而自变量相关系数小的一些变量。
模型的实际业务含义也有指导意义,比如m1同gdp肯定是相关的。
模型的建立是简单的,复杂的是模型的检验、评价和之后的调整、择优。
模型检验:1)方程显著性检验(F检验):模型拟合样本的效果,即选择的所有自变量对因变量的解释力度F大于临界值则说明拒绝0假设。
Eviews给出了拒绝0假设(所有系统为0的假设)犯错误(第一类错误或α错误)的概率(收尾概率或相伴概率)p 值,若p小于置信度(如0.05)则可以拒绝0假设,即认为方程显著性明显。
2)回归系数显著性检验(t检验):检验每一个自变量的合理性|t|大于临界值表示可拒绝系数为0的假设,即系数合理。

[经验分享] 使用eviews做线性回归分析Glossary:ls(least squares)最小二乘法R-sequared样本决定系数(R2):值为0-1,越接近1表示拟合越好,>0.8认为可以接受,但是R2随因变量的增多而增大,解决这个问题使用来调整Adjust R-seqaured()S.E of regression回归标准误差Log likelihood对数似然比:残差越小,L值越大,越大说明模型越正确Durbin-Watson stat:DW统计量,0-4之间Mean dependent var因变量的均值S.D. dependent var因变量的标准差Akaike info criterion赤池信息量(AIC)(越小说明模型越精确)Schwarz ctiterion:施瓦兹信息量(SC)(越小说明模型越精确)Prob(F-statistic)相伴概率fitted(拟合值)线性回归的基本假设:1.自变量之间不相关2.随机误差相互独立,且服从期望为0,标准差为σ的正态分布3.样本个数多于参数个数建模方法:ls y c x1 x2 x3 ...x1 x2 x3的选择先做各序列之间的简单相关系数计算,选择同因变量相关系数大而自变量相关系数小的一些变量。
模型的实际业务含义也有指导意义,比如m1同gdp肯定是相关的。
模型的建立是简单的,复杂的是模型的检验、评价和之后的调整、择优。
模型检验:1)方程显著性检验(F检验):模型拟合样本的效果,即选择的所有自变量对因变量的解释力度F大于临界值则说明拒绝0假设。
Eviews给出了拒绝0假设(所有系统为0的假设)犯错误(第一类错误或α错误)的概率(收尾概率或相伴概率)p 值,若p小于置信度(如0.05)则可以拒绝0假设,即认为方程显著性明显。
2)回归系数显著性检验(t检验):检验每一个自变量的合理性|t|大于临界值表示可拒绝系数为0的假设,即系数合理。
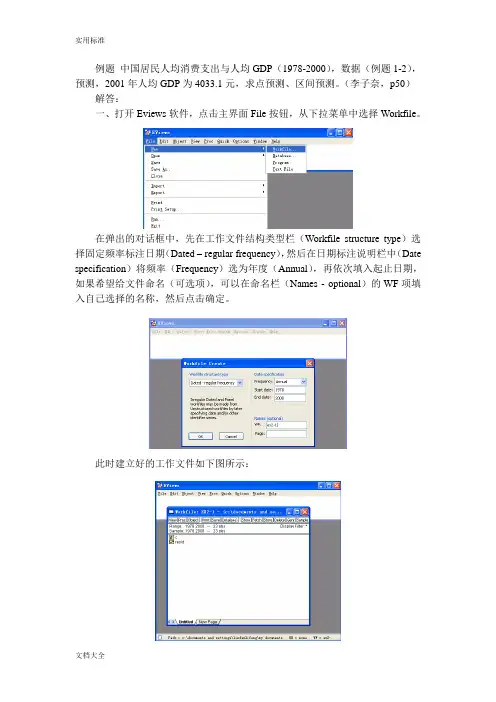
例题中国居民人均消费支出与人均GDP(1978-2000),数据(例题1-2),预测,2001年人均GDP为4033.1元,求点预测、区间预测。
(李子奈,p50)解答:一、打开Eviews软件,点击主界面File按钮,从下拉菜单中选择Workfile。
在弹出的对话框中,先在工作文件结构类型栏(Workfile structure type)选择固定频率标注日期(Dated – regular frequency),然后在日期标注说明栏中(Date specification)将频率(Frequency)选为年度(Annual),再依次填入起止日期,如果希望给文件命名(可选项),可以在命名栏(Names - optional)的WF项填入自己选择的名称,然后点击确定。
此时建立好的工作文件如下图所示:在主界面点击快捷方式(Quick)按钮,从下拉菜单中选空白数据组(Empty Group)选项。
此时空白数据组出现,可以在其中通过键盘输入数据或者将数据粘贴过来。
在Excel文件(例题1-2)中选定要粘贴的数据,然后在主界面中点击编辑(Edit)按钮,从下拉菜单中选择粘贴(Paste),数据将被导入Eviews软件。
将右侧的滚动条拖至最上方,可以在最上方的单元格中给变量命名。
二、估计参数在主界面中点击快捷方式(Quick)按钮,从下拉菜单中选择估计方程(Estimate Equation)在弹出的对话框中设定回归方程的形式。
在方程表示式栏中(Equation specification ),按照被解释变量(Consp )、常数项(c )、解释变量(Gdpp )的顺序填入变量名,在估计设置(Estimation settings )栏中选择估计方法(Method )为最小二乘法(LS – Least Squares ),样本(Sample )栏中选择全部样本(本例中即为1978-2000),然后点击确定,即可得到回归结果。

案例分析1.问题的提出和模型的设定根据我国1978—1997年的财政收入Y 和国民生产总值X 的数据资料,分析财政收入和国民生产总值的关系建立财政收入和国民生产总值的回归模型。
假定财政收入和国民收入总值之间满足线性约束,则理论模型设定为i i i u X Y ++=21ββ其中i Y 表示财政收入,i X 表示国民生产总值。
表1我国1978—1997年财政收入和国民生产总值2.参数估计进入EViews 软件包,确定时间范围;编辑输入数据;选择估计方程菜单,估计样本回归函数如下表 2obsX Y 19783624.100 1132.260 19794038.200 1146.380 19804517.800 1159.930 19814860.300 1175.790 19825301.800 1212.330 19835957.400 1366.950 19847206.700 1624.860 19858989.100 2004.820 198610201.40 2122.010 198711954.50 2199.350 198814922.30 2357.240 198916917.80 2664.900 199018598.40 2937.100 199121662.50 3149.480 199226651.90 3483.370 199334560.50 4348.950 199446670.00 5218.100 199557494.90 6242.200 199666850.50 7407.990 1997 73452.50 8651.140估计结果为Y=858.3108 + 0.100031X(12.78768) (46.04788)R^2=0.991583 S.E.=208.508 F=2120.408括号内为t统计量值。
3.检验模型的异方差(一)图形法1、EViews软件操作。
第十四章其他回归方法本章讨论加权最小二乘估计,异方差性和自相关一致协方差估计,两阶段最小二乘估计(TSLS),非线性最小二乘估计和广义矩估计(GMM)。
这里的大多数方法在“联立方程系统”一章中也适用。
线性回归模型的基本假设iki k i i t u x x x y +++++=ββββ 22110i = 1 , 2 , … , n在普通最小二乘法中,为保证参数估计量具有良好的性质,通常对模型提出若干基本假设:1.解释变量之间互不相关;2.随机误差项具有0均值和同方差。
即0)(=iu E 2)(σ=iu Var i = 1 , 2 , … , n 即随机误差项的方差是与观测时点t 无关的常数;3.不同时点的随机误差项互不相关(序列不相关),即0),(=-s i i u u Cov 4.随机误差项与解释变量之间互不相关。
即),(=i ji u x Cov 5.随机误差项服从0均值、同方差的正态分布。
即i u ~),0(2σN 当随机误差项满足假定1 ~ 4时,将回归模型称为“标准回归模型”,当随机j = 1 , 2 , … , k , i = 1 , 2 , … , n i = 1 , 2 , … , n s ≠ 0, i = 1 , 2 , … , n古典线性回归模型的一个重要假设是总体回归方程的随机扰动项同方差,即他们具有相同的方差。
如果随机扰动项的方差随观测值不同而异,即的方差为,就是异方差。
用符号表示异方差为。
异方差性在许多应用中都存在,但主要出现在截面数据分析中。
例如我们调查不同规模公司的利润,会发现大公司的利润变化幅度要比小公司的利润变化幅度大,即大公司利润的方差比小公司利润的方差大。
利润方差的大小取决于公司的规模、产业特点、研究开发支出多少等因素。
又如在分析家庭支出模式时,我们会发现高收入家庭通常比低收入家庭对某些商品的支出有更大的方差。
i u 2σ2i σ22)(i i u E σ=i u §14.1 加权最小二乘估计变量可支配收入交通和通讯支出变量可支配收入交通和通讯支出地区IN CUM地区IN CUM甘肃山西宁夏吉林河南陕西青海江西黑龙江内蒙古贵州辽宁安徽湖北海南4009.614098.734112.414206.644219.424220.244240.134251.424268.504353.024565.394617.244770.474826.364852.87159.60137.11231.51172.65193.65191.76197.04176.39185.78206.91227.21201.87237.16214.37265.98新疆河北四川山东广西湖南重庆江苏云南福建天津浙江北京上海广东5000.795084.645127.085380.085412.245434.265466.576017.856042.786485.637110.547836.768471.988773.108839.68212.30270.09212.46255.53252.37255.79337.83255.65266.48346.75258.56388.79369.54384.49640.56表1 中国1998年各地区城镇居民平均每人全年家庭可支配收入及交通和通讯支出单位:元使用加权最小二乘法估计方程,首先到主菜单中选Quick/ Estimate Equation … , 然后选择LS-Least Squares(NLS and ARMA)。
三、模型的建立与调整对样本量为23这类旅游产品是以欣赏纯自然风光为主,其旅游活动节奏缓慢,沿途风景优美,有利于怡神养情、缓解紧张和压力、排除内心的空虚与寂寞以至追求天人合一的精神境界,因此深受银发旅游者喜欢。
设计把嵩山、少林寺、郑州黄河游览区作为郑州市游览观光类旅游产品的主打品牌,其他相似的景点作为附属部分。
郑州市游览观光类银发旅游产品有:环翠峪风景区、康百万庄园、浮戏山雪花洞、黄帝宫、始祖山、三黄山、洞林湖、等。
(二)文化体验类银发旅游产品郑州有着大量的历史遗存和丰富的文化积淀,通过章节的分析研究我们发现,吸引老年游客出游的主要因素是文化和历史。
因此,郑州市银发旅游产品开发的重点产品之一就是文化历史类旅游产品。
结合郑州市现有的银发旅游资源,可将郑州的文化体验类银发旅游产品设计为以下两类:博物馆类旅游产品:河南博物馆、黄河博物馆、郑州城隍庙、河南艺术中心、郑州科技馆等;历史遗址类旅游产品:黄帝故里、汉霸二王城、北宋皇商城遗址、古荥冶铁遗址、杜甫陵园、永昭陵、裴李岗遗址、欧阳修陵园等。
我们在针对老年游客开发博物馆旅游产品时,应该在一般旅游产品之外增加一些适合老年游客的旅游产品,譬如,在对博物馆的馆藏进行解释说明的时候可以利用现代化科技的影像复原当时的场景,让人过目难忘。
对历史遗址类旅游产品我们针对老年人开发时,应注意要将相应的历史背景、古代文化详尽解说,易于老年人吸收接受。
(三)参与性民俗类银发旅游产品郑州市可针对老年游客开发的民俗文化类旅游产品有:郑州农耕文化民俗村、郑州剪纸、郑州香包、豫剧等。
在开发此类银发旅游产品时,要多添加老年游客的参与性产品,比如:在专业人士的精心指导下现场学习、制作简单的郑州香包;用剪刀剪出古朴的图案;学唱豫剧等。
(四)度假疗养类旅游产品度假疗养类银发旅游产品:思念果岭山水、丰乐农庄、美玉桃源原生态旅游区等。
此类银发旅游产品开发应区别于一般的休闲度假旅游,因为它比一般的休闲度假旅游时间长、生活化气息浓、消费相对较低。
小学期作业影响财政收入的主要因素学院:经济学院班级:统计学班**:***学号:**********影响财政收入的主要因素摘要:财政收入是一国政府实现政府职能的基本保障,主要有资源配置、收入再分配和宏观经济调控三大职能。
财政收入的增长情况关系着一个国家经济的发展和社会的进步。
我国财政收入主要受国民经济发展、预算外资金收入、税收收入等因素的影响。
本文针对我国财政收入影响因素建立了计量经济模型,并利用Eviews软件对收集到的数据进行相关回归分析,排除简单多元回归模型存在的严重多重共线性等问题,建立财政收入影响因素更精确的模型,分析了影响财政收入主要因素及其影响程度,预测我国财政收入增长趋势。
二、模型设定研究财政收入的影响因素离不开一些基本的经济变量。
大多数相关的研究文献中都把总税收、国内生产总值这两个指标作为影响财政收入的基本因素,还有一些文献中也提出了其他一些变量, 比如其他收入、经济发展水平等。
影响财政收入的因素众多复杂, 但是通过研究经济理论对财政收入的解释以及对实践的观察, 对财政收入影响的因素主要是税收收入。
下面我们就以税收收入、能源消费总量、和预算外资金收入作为影响财政收入的主要研究因素。
从中国统计局网站上可以查询到1993年至2008年的相关数据,对其进行计算整理可得:4.、模型的建立根据1978—2008年每年的财政收入Y( 亿元) , 能源消费总量X1( 亿元),预算外资金收入X2( 亿元) ,税收收入X3( 亿元) 的统计数据,由E-views软件得到y,x1,x2,x3的线性图,如下:由图可知,y,x1, x3都是逐年增长的,但增长速率有所变动,而x2呈现水平波动,说明变量间不一定是线性关系,可探索将模型设定为以下形式:lnY=β0+β1lnX1+β2X2+β3lnX3+U三,模型估计与调整利用Eviews软件对模型进行最小二乘法全回归,结果如下:第一步,进行模型的检验。
(一),进行多重共线性的检验方程的修正后的R平方值很高,说明变量对因变量的拟合程度很好,但是应该注意到c,lnx1,x2三者的t值很低(在此选择置信度为0.05),未通过检验,因此怀疑其中存在变量之间的多重共线问题。
例题中国居民人均消费支出与人均GDP(1978-2000),数据(例题1-2),预测,2001年人均GDP为4033.1元,求点预测、区间预测。
(李子奈,p50)解答:
一、打开Eviews软件,点击主界面File按钮,从下拉菜单中选择Workfile。
在弹出的对话框中,先在工作文件结构类型栏(Workfile structure type)选择固定频率标注日期(Dated – regular frequency),然后在日期标注说明栏中(Date specification)将频率(Frequency)选为年度(Annual),再依次填入起止日期,如果希望给文件命名(可选项),可以在命名栏(Names - optional)的WF项填入自己选择的名称,然后点击确定。
此时建立好的工作文件如下图所示:
在主界面点击快捷方式(Quick)按钮,从下拉菜单中选空白数据组(Empty Group)选项。
此时空白数据组出现,可以在其中通过键盘输入数据或者将数据粘贴过来。
在Excel文件(例题1-2)中选定要粘贴的数据,然后在主界面中点击编辑(Edit)按钮,从下拉菜单中选择粘贴(Paste),数据将被导入Eviews软件。
将右侧的滚动条拖至最上方,可以在最上方的单元格中给变量命名。
二、估计参数
在主界面中点击快捷方式(Quick)按钮,从下拉菜单中选择估计方程(Estimate Equation)
在弹出的对话框中设定回归方程的形式。
在方程表示式栏中(Equation specification ),按照被解释变量(Consp )、常数项(c )、解释变量(Gdpp )的顺序填入变量名,在估计设置(Estimation settings )栏中选择估计方法(Method )为最小二乘法(LS – Least Squares ),样本(Sample )栏中选择全部样本(本例中即为1978-2000),然后点击确定,即可得到回归结果。
以上得到的回归结果可以表示为:
201.1190.3862(13.51)(53.47)
Consp GDPP =+⨯ 如果你试图关闭回归方程页面(或Eviews 主程序),这时将会弹出一个对话框,询问是否删除未命名的回归方程,如下图所示
此时如果同意删除,可以点击Yes,如果想把回归结果保存下来,可以点击命名(Name),这时就会弹出一个对话框,在其中填入为方程取的名字,点击OK即可。
本例中方程自动命名为方程-1(eq01)。
点击确定之后,方程页面关闭,同时在工作文件页面内可以发现多了一个表示回归方程的对象(图中的eq01)。
如果以后需要用到回归结果时,就不需要象前面那样逐步地去做,而只需要双击eq01图标即可。
如果试图关闭工作文件或Eviews主程序,将会弹出警示框询问是否对该工作文件进行保存,此时如果不计划对工作文件进行保存,直接点击No即可,如果点击取消(Cancel),将回到关闭前的状态。
如果计划保存工作文件以备将来使用,则可以点击Yes。
随后弹出的对话框询问按照怎样的精确度保存数据,此时选择高精确度即可。
即选择Double precision 。
注意!按照当前的设置,Eviews 默认的保存路径是“我的文档”。
将来打开文件时可以从Eviews 主程序中按照文件(File )——打开(Open )——Eviews 工作文件(Eviews Workfile )的方式,也可以直接在“我的文档”中双击要打开的工作文件。
三、相关的检验
1. 拟合优度(可决系数)
从回归结果中可以看出,本例中20.9927R =,说明模型在整体上拟合得非常好。
2. 显著性检验
首先看截距项和斜率项的t 统计量取值情况。
因为本例中使用的观察值个数为23,因此这些t 统计量应该服从自由度为(232)21-=的t 分布,查书后附录中给出的t 分布表,可以发现自由度为21、检验水平为0.1、0.05、0.01时相对应的临界值分别为1.721、2.080、2.831,而本例中的两个t 统计量的取值分别为13.51和53.47,说明在通常使用的检验水平下,本例中所选择的两个解释变量对被解释变量有很好的解释能力,或者说数据强烈支持将这两个解释变量纳入模型之中。
3. 置信区间
以下建立总体参数0β和1β置信度为95%的置信区间。
前面已经介绍过,当置信度为1α-时,置信区间为 2211ˆˆ11ˆˆ(2),(2)t t n s n s ααββββ⎡⎤--⨯+-⨯⎣⎦
而0.025(21) 2.080t =,从回归结果中还可以查到1ˆ0.007222s β=,因此1β的置信度为95%的置信区间为0.3862 2.0800.0072220.38620.0150±⨯=±。
或者表示为
[0.3712,0.4012]
同样的道理,0β的置信度为95%的置信区间为201.118930.9587±。
或者表示为
[170.1602,232.0776]
四、预测
以上是根据中国1978-2000年人均消费与人均GDP (按1990年价格表示)得到的回归结果,现在据此对2001年人均消费的情况进行预测。
1. 点预测
2001年,以1990年不变价格表示的中国人均GDP 约为4033.1元,根据前面得出的样本回归函数,可以计算出
2001201.1190.38624033.11758.7Consp =+⨯=
2001年人均消费的实际值为1782.2元,与预测的结果进行比较,发现相对误差为 1.32%-。
2. 区间预测
首先对2001()E Consp 进行区间预测。
如果选择置信度为1α-,则置信区间为 222222()()11ˆˆˆˆ(2),(2)()()F F F F i i x x x x y t n y t n n x x n x x αασσ⎡⎤----⨯⨯++-⨯⨯+⎢⎥--⎢⎥⎣⎦
∑∑ 这里ˆ1758.7F y
=,2(2) 2.080t n α-=,ˆ33.2645σ=,23n =,4033.1F x =均为已知,下面介绍22()()/i F x x x x --∑的求法。
启动Eviews 程序,在主界面点击文件(File )按钮,在下拉菜单中选择打开(Open ),然后选择Eviews 工作文件(Eviews Workfile ),在上次保存文件的目录下找到Eviews 工作文件ex1-2,在工作文件页面中双击表示人均GDP 的变量gdpp ,即可打开这一数据序列。
此时在数据序列页面中点击查看(View )按钮,然后将光标移动到描述性统计量(Descriptive Statistics )上面,在右侧出现的选项中选择统计量表格(Stats Table ),这样关于数据序列人均GDP 的一些统计量就可以显示出来了。
表格中各项分别是平均值(Mean )、中位数(Median )、最大值(Maximum )、最小值(Minimum )、标准差(Std. Dev )、偏度(Skewness )、峰度(Kurtosis )、JB 正态性检验统计量(Jarque-Bera )、JB 统计量对应的概率值(Probability )、数组求和结果(Sum )、离差平方和(Sum Sq. Dev.)、观察值个数(Observations )。
我们进行区间预测时需要的x 就是表中的平均值,2()i x x -∑即为表中的离差平方和。
将这些结果代入前面的表示式,就可以得到对2001()E Consp 的置信度为95%的区间估计了:1758.736.19±,也就是[1722.51,1794.89]。
另外我们还注意到2001年人均消费的实际数据是1782.2元,落在了这一区间内。
接下来对2001Consp 进行区间预测。
前面已经得出,置信度为1α-的区间预测是 222222()()11ˆˆˆˆ(2)1,(2)1()()F F F F i i x x x x y t n y t n n x x n x x αασσ⎡----⨯+++-⨯++⎢--⎢⎣∑∑ 此时置信区间的上下限与前一种情况相比有少许变化,区间的宽度有所增加,这是因为2001Consp 比2001()E Consp 的方差要大一些。
将各种数据代入上面表示式,得到的结果是:1758.778.08±,或者表示为区间形式[1680.62,1836.78],很显然,对2001Consp 的区间估计不如对2001()E Consp 的区间估计精确。
五、经济学含义的分析
以下对回归结果的经济学含义做一个简单的分析,回归结果是
201.1190.3862Consp GDPP =+⨯
1. 凯恩斯的绝对收入假说认为,当收入增加时,消费支出也会相应地增加,
但是不如收入增加得多,这从回归结果中1
ˆβ大于0且小于1可以得到验证;另外凯恩斯还认为,随着收入的增加,人们会将收入中更多的部分储蓄起来,这一点可以从截距项为正得到验证。
201.1190.6138GDPP Consp s GDPP GDPP
--=
=+ 其中的s 是储蓄率,显然随着收入的增加,s 将不断地变大。
2. 回归结果中解释变量收入前面的系数表示,1978-2000年间,中国的人均收入每增加1元钱,消费支出将会增加0.3862元钱,这就是一种典型的乘数分析。
3. 在经济学中,消费对收入求一阶偏导数,得到的结果被称作是边际消费倾向,本例中的边际消费倾向为0.3862,这一结果明显低于发达国家,例如美国,同时也低于世界平均水平,表明中国的消费需求比较低,启动内需即是针对这一问题而言。