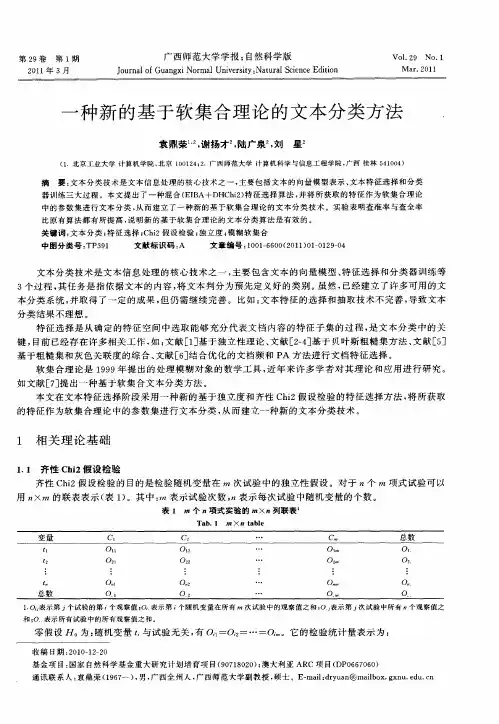
基于模糊软集合理论的文本分类方法
- 格式:ppt
- 大小:290.00 KB
- 文档页数:16

基于模糊聚类算法的文本自动分类技术研究随着信息技术的不断发展,文本数据在我们的日常生活中变得越来越重要。
随之而来的挑战之一是如何对大量的文本数据进行自动分类。
本文将讨论基于模糊聚类算法的文本自动分类技术,探讨其原理、应用和潜在优势。
## 1. 引言文本分类是将文本数据划分为不同的类别或标签的过程。
这一技术在信息检索、情感分析、垃圾邮件过滤和新闻分类等领域具有广泛的应用。
传统的文本分类方法通常依赖于精确的特征提取和监督学习算法。
然而,这些方法对于大规模、高维度的文本数据面临挑战,而模糊聚类算法则提供了一种新的解决方案。
## 2. 模糊聚类算法### 2.1 概述模糊聚类是一种聚类分析技术,它允许一个对象同时属于多个不同的类别,而不是严格划分为某个类别。
这种模糊性在文本分类中具有重要意义,因为一篇文本可能涉及多个主题或类别,而不容易划分到某一个类别中。
### 2.2 模糊c-均值(FCM)模糊c-均值是一种常用的模糊聚类算法,它将每个文本分配到不同类别的隶属度。
这种模糊性的隶属度可以更好地反映文本与不同类别的关系。
FCM的核心思想是最小化目标函数,以确定每个文本与每个类别的隶属度。
### 2.3 模糊聚类的优势与传统的硬聚类方法相比,模糊聚类在文本分类中具有以下优势:- 考虑文本的多主题性。
- 允许文本在不同类别中具有不同的隶属度。
- 对噪声数据有一定的容忍度。
## 3. 文本自动分类的应用文本自动分类技术在多个领域有着广泛的应用,以下是一些典型应用:### 3.1 情感分析情感分析是一种文本分类任务,旨在确定文本中的情感倾向,如正面、负面或中性。
模糊聚类可以更好地处理情感分析中的主题多样性,因为一篇文本可能包含多种情感信息。
### 3.2 新闻分类新闻分类是将新闻文章划分为不同主题或类别的任务。
模糊聚类可以更好地处理新闻文章可能涉及多个主题的情况,而不必强行将其分为一个类别。
### 3.3 信息检索信息检索涉及从大量文档中检索与用户查询相关的文档。


基于模糊分类规则树的文本分类郭玉琴;袁方;刘海博【期刊名称】《东南大学学报(英文版)》【年(卷),期】2008(024)003【摘要】针对传统的基于关联规则的文本分类方法在分类文本时需要遍历分类器中的所有规则,分类效率非常低的问题,提出一种基于模糊分类规则树(FCR-tree)的文本分类方法.分类器中的规则以树的形式存储,由于树型结构避免了重复结点的存储,节省了存储空间.模糊分类关联规则与一般分类规则相比,不仅包含了词条信息,还包含了词条出现频度对应的模糊集,所以FCR-tree的构建过程及树的结构不同于一般规则树CR-tree.为降低构建及遍历FCR-tree的难度,采用了构造多棵k-FCR-tree的方法.在搜索规则树时,如果结点中的词条没在待分类文本中出现,则不需要再搜索该结点引导的子树,大大减少了需要匹配的规则的数量.实验表明该方法是可行的,与遍历分类器的分类方法相比,分类效率有了明显提高.%To deal with the problem that arises when the conventional fuzzy class-association method applies repetitive scans of the classifier to classify new texts, which has low efficiency, a new approach based on the FCR-tree (fuzzy classification rules tree)for text categorization is proposed. The compactness of the FCR-tree saves significant space in storing a large set of rules when there are many repeated words in the rules. In comparison with classification rules, the fuzzy classification rules contain not only words, but also the fuzzy sets corresponding to the frequencies of words appearing in texts. Therefore, the construction of an FCR-tree and its structure are different from a CR-tree. To debase the difficulty of FCR-tree construction and rules retrieval, more k-FCR-trees are built. When classifying a new text, it is not necessary to search the paths of the sub-trees led by those words not appearing in this text, thus reducing the number of traveling rules. Experimental results show that the proposed approach obviously outperforms the conventional method in efficiency.【总页数】4页(P339-342)【作者】郭玉琴;袁方;刘海博【作者单位】河北大学数学与计算机学院,保定071002;中国人民银行天津分行,天津300040;河北大学数学与计算机学院,保定071002;河北大学数学与计算机学院,保定071002【正文语种】中文【中图分类】TP393因版权原因,仅展示原文概要,查看原文内容请购买。




一种基于模糊VSM和神经网络的文本分类方法潘俊辉;王辉【摘要】针对文本自动分类时可能存在一个文本属于多类的问题,提出了一种基于模糊向量空间模型和神经网络的文本自动分类方法.该方法采用模糊集理论,把特征项在文档中出现的位置作为反映文档主题的重要程度(隶属度),并在特征提取时充分考虑该位置信息,从而构造出模糊特征向量,使文本分类更接近手工分类方法.建立的网络由输入层、隐含层和输出层组成,其中输入层完成分类样本的输入,隐含层提取输入样本所隐含的模式特征,输出层用于输出分类结果.实验部分以万方数据库中部分文档数据为例验证了该方法的有效性.%A kind of text classification method based on fuzzy vector space model and neural networks is proposed to counter the problems that a text can be belongs to many types during the text classification. Fuzzy theory is adopted in the method to look the occuring position of feature items in text on as the importantdegree(membership)reflecteing text subject, and fully considered the position information while the features are extracted , thus the fuzzy feature vectors are constructed, as a result, the text classification is close to the manual classification method.The established networks are constituted of input layer, hidden layer and output layer, the input layer completes the inputs of classification samples, hidden layer extracts the implicit pattern features of input samples, the output layer is used to output the classification results. Finally the effectiveness of this method is proved by some documents of Wanfang data in experimental section.【期刊名称】《科学技术与工程》【年(卷),期】2011(011)009【总页数】4页(P2121-2124)【关键词】文本分类;模糊向量空间;神经网络;模糊特征向量;特征提取;隶属度【作者】潘俊辉;王辉【作者单位】东北石油大学,大庆,163318;东北石油大学,大庆,163318【正文语种】中文【中图分类】TP391.3数据挖掘(Data Mining),是从存放在数据库、数据仓库或其他信息库中的大量的数据中获取有效的、新颖的、潜在有用的、最终可理解模式的非平凡过程[1]。

一种基于模糊聚类的汉语文本自动分类方法
卢忠良;王家云;荣融;朱劲松;孙即祥
【期刊名称】《计算机应用与软件》
【年(卷),期】2003(020)010
【摘要】如何快速地整理海量信息,对不同的文本进行有效分类,已成为获取有价值信息的瓶颈.本文提出的中文文本分类方法,较好地解决了信息的实时分类问题,在实践中收到了良好的效果.由于汉语文本的特殊性,在分类器训练前对训练文本进行自动分词和降维预处理.许多文本往往可能归到多个类,因此分类算法采用模糊c-原型算法.实验表明,该方法综合效果较好,可以实现文本的快速分类.
【总页数】3页(P49-50,61)
【作者】卢忠良;王家云;荣融;朱劲松;孙即祥
【作者单位】国防科技大学电子科学与工程学院,长沙,410073;解放军61587部队,上海,200336;解放军61587部队,上海,200336;解放军61587部队,上海,200336;解放军61587部队,上海,200336;国防科技大学电子科学与工程学院,长沙,410073【正文语种】中文
【中图分类】TP3
【相关文献】
1.一种基于粗糙-神经网络的文本自动分类方法 [J], 王效岳;白如江
2.一种基于模糊聚类级进模冲切刃口设计的改进方法 [J], 吴彬;张小萍;王国伟
3.一种基于模糊聚类模型的动量轮健康性排序方法 [J], 季业;崔振;王雪涛;严嵘;刘
一帆
4.一种基于词上下文向量的文本自动分类方法 [J], 郭少友
5.一种基于改进模糊聚类算法的自适应典型日选取方法 [J], 邬浩泽;朱晨烜;张贻山;龙艳花
因版权原因,仅展示原文概要,查看原文内容请购买。


基于模糊VSM和RBF网络的文本分类方法
许少华;李小红;潘俊辉
【期刊名称】《计算机工程与设计》
【年(卷),期】2007(028)001
【摘要】针对文本自动分类问题,提出了一种基于模糊向量空间模型和径向基函数网络的分类方法.网络由输入层、隐层和输出层组成.输入层完成分类样本的输入,隐层提取输入样本所隐含的模式特征,将分类结果在输出层表现出来.该方法在特征提取时充分考虑了特征项在文档中的位置信息,构造出模糊特征向量,使自动分类更接近手工分类方法.以中国期刊网全文数据库部分文档数据为例验证了该方法的有效性.
【总页数】4页(P145-148)
【作者】许少华;李小红;潘俊辉
【作者单位】大庆石油学院,计算机科学与工程学院,黑龙江,大庆,163318;大庆石油学院,计算机科学与工程学院,黑龙江,大庆,163318;大庆石油学院,计算机科学与工程学院,黑龙江,大庆,163318
【正文语种】中文
【中图分类】TP391
【相关文献】
1.基于改进VSM的Web文本分类方法 [J], 胡晓;王理;潘守慧
2.基于聚类的VSM模糊标引模式下文本检索问题研究 [J], 刘海峰;张学仁;王倩
3.基于FVSM和自组织映射网络的Web文本自动分类方法 [J], 许增福;梁静国;田晓宇
4.基于改进模糊语法增量式算法的文本分类方法 [J], 龚静;黄欣阳
5.一种基于模糊VSM和神经网络的文本分类方法 [J], 潘俊辉;王辉
因版权原因,仅展示原文概要,查看原文内容请购买。
基于模糊-粗糙集的文本分类方法
付雪峰;王明文
【期刊名称】《华南理工大学学报(自然科学版)》
【年(卷),期】2004(032)0z1
【摘要】在文本分类过程中,类别之间的重叠以及标志类别属性的不足会导致类别的边界之间出现模糊不确定性和粗糙不确定性,而传统的k-近邻方法无法解决这一问题;同时,在传统的k-近邻方法以及其他一些改进的k-近邻方法中,最优k值的选取需要通过训练得到.文中借助模糊-粗糙集理论来改进传统的k-近邻方法,并使用基于距离的邻域空间,以不经训练地确定适宜每个待分类文本的k值,最后将所提方法和其他一些k-近邻方法进行了实验比较,结果表明模糊-粗糙集方法能够在一定程度上提高分类的精度和召回率.
【总页数】4页(P73-76)
【作者】付雪峰;王明文
【作者单位】江西师范大学,计算机信息工程学院,江西,南昌,330027;江西师范大学,计算机信息工程学院,江西,南昌,330027
【正文语种】中文
【中图分类】TP18
【相关文献】
1.基于粗糙集与改进KNN算法的文本分类方法的研究 [J], 邵莉
2.基于粗糙集的文本分类方法在网络科技资源应用集成环境中的应用 [J], 侯凡;周
明全;耿国华;李杰
3.一种基于粗糙集的Web文本分类方法 [J], 阚言东;倪茂树;刘国庆
4.基于粗糙集和最小二乘支持向量机的文本分类方法 [J], 张庙林;牛犇
5.基于粗糙集和最小二乘支持向量机的文本分类方法 [J], 张庙林;牛犇
因版权原因,仅展示原文概要,查看原文内容请购买。
基于模糊集的文本分类技术研究随着互联网的发展,我们所面临的文本数据呈现出爆炸式的增长趋势,如何对这些海量的文本进行分类成为了一个非常重要和热门的研究方向。
目前,文本分类技术被广泛应用于安全监控、搜索推荐、电商推荐和情感分析等领域。
本文将基于模糊集理论,探讨其在文本分类中的应用以及其效果。
一、概述文本是信息的载体之一,它包含着大量的隐含信息和知识。
因此,文本分类成为信息处理和知识发现中最重要的组成部分之一。
文本分类从数据挖掘、机器学习、自然语言处理、信息检索等领域集成了多种技术手段,如朴素贝叶斯、KNN、SVM等经典算法。
但是,这些算法都只是在样本分类明确、对比明显的情况下,取得了较好的分类性能,而在样本少的情况下,它们往往不能很好的进行分类。
此时,模糊集理论可以为文本分类提供一个很好的解决方案。
二、模糊集理论模糊集理论是一种用来描述语言学和认知科学中的模糊概念的数学理论。
它在处理不精确或不确定问题方面具有广泛应用。
其核心是将“非绝对的事物”表示成若干个隶属程度不同的隶属函数,即“集合函数”,这样就可以将某个事物从全集中抽象出来形成它的“模糊集合”。
三、模糊集在文本分类中的应用在传统的文本分类方法中,每个样本只被划分到一个类别中,即存在绝对的类别划分。
但是,在现实中,有些文本存在比较模糊的归属关系,比如新闻稿件、文学作品等,这些文本常常具有多个主题。
因此,将文本的分类也转化为了一种模糊的划分。
而模糊集理论为这种模糊的文本分类提供了一种解决方案。
模糊集理论将每个样本划分到各个类别中的概率认为是一个隶属函数。
对于每个文本,模糊集理论可以用多个隶属函数表示它的多个语义。
在这个过程中,选取合适的隶属函数非常关键。
通常比较常见的隶属函数模型包括线性隶属函数、指数隶属函数和S型隶属函数。
四、模糊集文本分类的优势相比于传统的文本分类方法,基于模糊集的文本分类具有以下优势:1. 系统灵活性高传统的文本分类方法最大的弊端在于某个文本必须被赋予一个唯一的分类标签,然而这种分类方法在混淆的情况下往往无法精确分类,而基于模糊集的文本分类方法可以给出有关于文本在多个类别下的概率,因此可以使用一个模糊的弱分类系统来实现该任务。
基于模糊集和支持向量机的文本流派分类方法
朱艳辉;阳爱民;杨伟丰
【期刊名称】《计算机工程与应用》
【年(卷),期】2008(44)11
【摘要】针对目前流派分类技术分类性能不够好的问题,将支持向量机和模糊集理论的优点结合起来,提出了一种基于模糊集和支持向量机的文本流派分类方法.并以电影评论作为数据集,比较和分析了该方法在不同文本特征生成方法、不同特征数目下的分类效果,并与SVM方法进行了比较,实验结果表明其微平均查准率要优于SVM方法.理论和实验都证明了提出的方法可以取得较好的分类性能.
【总页数】4页(P145-147,157)
【作者】朱艳辉;阳爱民;杨伟丰
【作者单位】湖南工业大学,计算机与通信学院,湖南,株洲,412008;国防科学技术大学,计算机学院,长沙,410073;湖南工业大学,计算机与通信学院,湖南,株洲,412008【正文语种】中文
【中图分类】TP301
【相关文献】
1.基于支持向量机的不均衡文本分类方法 [J], 高超;许翰林
2.基于粗糙集和最小二乘支持向量机的文本分类方法 [J], 张庙林;牛犇
3.基于粗糙集和最小二乘支持向量机的文本分类方法 [J], 张庙林;牛犇
4.基于主题模型和支持向量机的文本情感分类方法 [J], 王华
5.基于主题模型和支持向量机的文本情感分类方法 [J], 王华
因版权原因,仅展示原文概要,查看原文内容请购买。
基于模糊粗糙集的Web文本分类
孙海虹;丁华福
【期刊名称】《计算机技术与发展》
【年(卷),期】2010(020)007
【摘要】网络信息的多样性和多变性给信息的管理和过滤带来极大困难,为加快网络信息的分类速度和分类精度,提出了一种基于模糊粗糙集的Wdb文本分类方法.采用机器学习的方法:在训练阶段,首先对Web文本信息预处理,用向量空间模型表示文本,生成初始特征属性空间,并进行权值计算;然后用模糊粗糙集算法来进行信息过滤,用基于模糊租糙集的属性约简算法生成分类规则:最后利用知识库进行文档分类.在测试阶段,对未经预处理的文本直接进行关键属性匹配,经模糊粗糙因子加权后,用空间距离法分类.通过试验比较,该方法具有较好的分类效果.
【总页数】4页(P21-24)
【作者】孙海虹;丁华福
【作者单位】哈尔滨理工大学计算机科学与技术系,黑龙江,哈尔滨,150080;哈尔滨理工大学计算机科学与技术系,黑龙江,哈尔滨,150080
【正文语种】中文
【中图分类】TP301
【相关文献】
1.一种基于人工免疫的Web文本分类方法研究——以Web信息分类为例 [J], 何晓庆;贾钊
2.基于朴素贝叶斯的Web文本分类及其应用 [J], 包小兵
3.基于稳健模糊粗糙集模型的多标记文本分类 [J], 张晶;李德玉;王素格;李华
4.一个基于朴素贝叶斯方法的web文本分类系统:WebCAT [J], 余芳
5.基于Web技术的航天文本分类系统研究与应用 [J], 徐建忠;朱俊;赵瑞;张亮;李娇娇
因版权原因,仅展示原文概要,查看原文内容请购买。
基于模糊综合评判的文本自动分类算法
陈勤;张国煊;王小华
【期刊名称】《计算机应用与软件》
【年(卷),期】2001(018)009
【摘要】文本分类在文献检索、信息过滤、数据组织、信息管理等领域中应用十分广泛.本文给出了一种基于模糊综合评判的文本自动分类算法,该算法以文本分词技术作为基础,以类间词频方差作为评判因素的选择依据,通过预定义类中关键词的词频均值高低构造评判矩阵,以最大隶属度作为评判原则.文中详细描述了算法的理论依据、评判因数的选择、评判矩阵的构造及分类算法.实验结果表明本文提出的分类算法具有相当的应用价值.
【总页数】4页(P56-59)
【作者】陈勤;张国煊;王小华
【作者单位】杭州电子工业学院计算机科学与技术系,;杭州电子工业学院计算机科学与技术系,;杭州电子工业学院计算机科学与技术系,
【正文语种】中文
【中图分类】TP3
【相关文献】
1.LDA模型下文本自动分类算法比较研究——基于网页和图书期刊等数字文本资源的对比 [J], 李湘东;潘练
2.基于KNN的烟草企业档案文本自动分类算法研究 [J], 黄世反;沈勇;康洪炜;王道
红;郑见琳;郎波;王冬;贾丛丛;;;;;;;;
3.基于贝叶斯算法的蒙古语文本自动分类研究 [J], 都兰;金罡;
4.基于语料库文本自动分类算法及应用比较研究 [J], 许和旭;王兰成
5.基于语料库文本自动分类算法及应用比较研究 [J], 许和旭;王兰成
因版权原因,仅展示原文概要,查看原文内容请购买。