Petrel入门培训随机相建模
- 格式:ppt
- 大小:2.36 MB
- 文档页数:32

Input里面加载所有单井数据well、well tops、;Model是所建模型;Templates是做的模板以上窗口可以随意摆放,双击即可回去这是地震上的解释是构造模型的建立,property modeling是属性建模(包括孔隙度模型,渗透率模型,含油饱和度模型等等)是数值模拟加载数据:先新建insert ->new well folder;对井进行编组:右击wells->insert folder,把所有井拖进去;井位数据(well heads)、井轨迹数据(well path)、测井数据(well logs)、分层数据(well tops:well、surface、MD)测井解释成果(.Prn)用production log格式加载井对比(对比剖面图):新建一个new wellsection window(对比窗口),为相建模打基础,建立层拉平,setting->flatten on well top,在此之前先把others里面的分层拖进stratigraphy 里面,按顶(base)来拉平,(建立层拉平:按分层数据拉平)调整纵向比:setting->absolute(1000即可),手动调整比例尺通过这是将一个图道中的两条曲线反向的操作可去掉网格线调整曲线颜色,然后上色,因为所有gamma值都在0~1中间,调整曲线的取值范围,回到well,进到colors,设置最大值为120(或者自动获取)gamma 值大对应泥岩(孔隙度比较小)(孔隙度和gamma成反相关);RT电阻率(电阻率一般按对数的方式显示),SP自然电位,DT声波曲线;设置一口井为模板(单井模板只能保存一个:->),应用到所有井,(地质上分层就是按照测井曲线来分层的),(如果发现分层有问题,通过来调整这就是手动修改的层位)去掉中间井的分层名字:双击well tops->去掉sub labels,只留下两侧井的分层名字用可以圈定含油面积(根据井的油水对比剖面图)setting调整polygon的粗细颜色聚类分析:classsification对应岩相和地震相的解释设定:井、曲线、聚出几类数据流程窗口,选择,双击,要选有数据的井,setting设置为2,选择create(以后有新的数据要加载时选update),先点,apply,wells->里面多处一项(神经网络),此处将他换为相(facies),勾上facies,(泥岩shale;砂岩sand),,重新应用模板,用调整解释出的泥岩砂岩,建完构造模型后才能做离散化。



可能是最简单的Petrel建模流程Petrel是一种用于油气勘探和生产建模的地质学和工程学软件,可以帮助地质学家和工程师进行不同类型输入数据的解释和模拟。
本文将介绍Petrel的最简单建模流程,并逐步讲解其主要步骤。
步骤1:启动Petrel软件并创建一个新的工程首先,您需要启动Petrel软件。
打开软件后,您将看到一个“新建工程”对话框。
在这个对话框中,您可以为新的工程选择一个名称并定义其相应的路径。
然后,单击“创建”按钮以创建新的工程。
步骤2:导入数据一旦新的工程创建完成,您将看到Petrel的主界面。
在主界面的左侧面板中,选择“数据导入管理器(Data Import Manager)”按钮。
然后,在数据导入管理器对话框中,选择“添加”按钮,以导入地质数据。
步骤3:解释地质数据在步骤2中,您可以导入各种类型的地质数据,例如测井数据、地震数据和地质模型数据。
当数据导入完成后,您需要对这些数据进行解释。
例如,您可以使用测井数据对地层进行解释,并使用地震数据进行结构解释。
通过解释地质数据,您可以获得有关地下结构和储层特性的更多信息。
步骤4:创建地质模型在步骤3中,您可以将解释好的地质数据用于创建地质模型。
在Petrel中,您可以通过多种方式创建地质模型,包括地层划分、网格建模和地质建模等。
这些方法允许您将地质数据应用于地质建模,以获得更准确的地质模型。
步骤5:导入生产数据在创建了地质模型之后,您可以导入生产数据,以评估油田或气田的生产潜力。
在Petrel的左侧面板中,选择“数据导入管理器(Data Import Manager)”按钮,并选择“添加”按钮,以导入生产数据。
然后,使用这些生产数据对地质模型进行评估,以确定最佳的开发方案。
步骤6:评估生产方案在步骤5中,您导入了生产数据并将其应用到地质模型中。
您可以使用这些数据来评估不同的生产方案,并找到最佳的开发策略。
例如,您可以尝试不同的注水井和采油井配置,并使用模型进行模拟以评估不同方案的效果。





Petrel地震地质解释和建模使用技巧Petrel 合成记录工作流制作合成地震记录,进行层位标定和确定时深关系是地震解释工作中非常重要的环节。
从Petel2009.1.1,开始Petrel里有两个制作合成记录的模块,一个叫Synthetics,一个叫Seismic-Well tie。
这里介绍如何使用Synthetics模块制作合成地震记录。
从Petrel 2007开始Synthetics模块有了很大改进。
最重要的变化是其结果可在Global well logs下有相应的synthetic目录,其相应时深关系可在数据表中显示。
对同一口井可产生多个合成记录,如图1-1,1-2所示。
Synthetics模块制作合成记录工作流主要分为两大步骤:按照已有数据产生合成记录通过welltop 进行时深关系调整(bulkshift或sqeeze/stretch)一、 生成合成记录1. 双击synthetic模块,打开合成记录主界面(如下图),选择create new folder,从界面中well 到well seismic 四个界面对合成记录中所需数据进行选择或创建,如图2所示。
Well:选择要做合成记录的井,可多选,但每口井必须有相应的数据(DT和子波)。
Sonic and time:确定原始输入数据及时深关系。
根据实际数据品质,如果有checkshot,可用来做DT曲线校正;所有井上时深关系以工区井目录,以及每口井的Settings界面里Time界面下设置为准,Synthetics界面里的Overwrite global time log项不启用。
Create synthetic seismogram:创建合成记录选择创建合成记录所需数据:Density、Acoustic Impedence、Reflectiotion coefficients和Wavelet。
如果这些数据都不存在,或者希望修改参数重新创建,则点击黄色星状按钮创建新数据。
P e t r e l中的属性建模流程简介属性建模:一、相模型的建立:1、测井曲线离散化双击:Process ——Proerty modelding——Scall up well logs;弹出对话框:在Select里选择需要离散化的相曲线数据 facies(input到wells的沉积相数据),点击all可以对需要离散的井进行选择,剔除没有曲线或者曲线数据不正确的井)。
在相模型建立时:Average选择“most of”、method选择“Simple”。
单击“Apply”或“OK”确定。
完成沉积相数据的离散化,离散化后,沉积相数据赋给井轨迹所通过的网格。
离散化后models里的properties里新增了沉积相属性“facies”,可在3D视图里进行查看。
2、沉积相模型建立;双击:Process ——Proerty modelding——Facies modeling。
弹出对话框:对话框右上角选择离散化后的沉积相数据,依次选择各小层(zone)进行属性控制;点击解锁进行编辑控制。
目前的沉积相建模算法很多;通常,纵向上细分网格后用序贯高斯的算法,纵向上未细分用经典算法(此处的“纵向细分“是指layering里把zone细分为不同个数的网格。
⑴、序贯高斯的算法;“Method for zone /facie”选项单击下拉菜单,选择序贯高斯算法:“Sequential indicator simula”,在左侧选择该小层所以相类型(可从左侧出现的百分比统计中看出)单击箭头,相类型移动到右侧。
下侧空白区域新增两个选项卡“Variogram”,“Fraction”,点击按钮,弹出对话框:点击解锁,点击后如图:点击按钮:点击“OK”确定;自动返回之前属性设置界面。
单击“红圈”按钮,点亮其功能,点亮后按钮会变为淡红底色。
在“Variogram”选项卡将Range:里三个值“1000,1000,10”设置为默认值“0.1、0.1、0.1”(注意:每个相类型都需设置,包括M)。
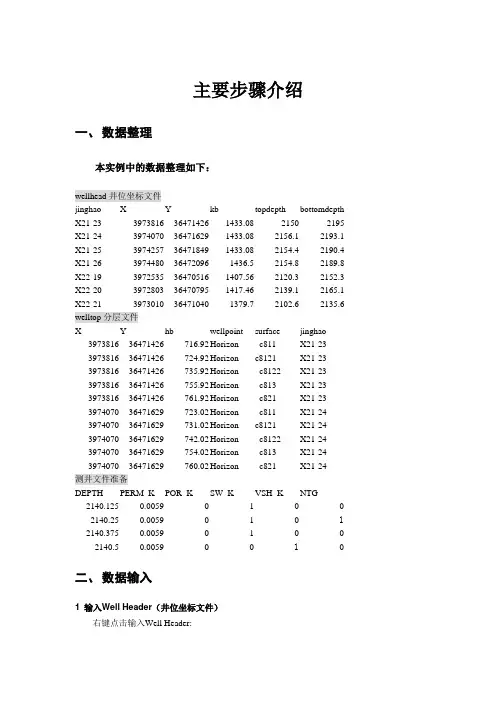
PETREL操作流程1.前期数据准备地震数据体,断层线FAULT LINS OR 断层棍FAULT STICKS,FAULTPOL YGONS,数字化的等值线。
工区内各井的坐标,顶深,海拔,底深(完钻井深),东西偏移,方位角,倾角,砂岩分层数据,砂层等厚图,测井曲线(公制单位),单井相,各层沉积相图,砂岩顶面构造图,单井岩性划分,测井解释成果表,含油面积图。
(在编辑数据的过程中,命名文件时最好数据文件名都和井名一致)2.数据加载①加载井口数据(WELL HEADERS)WELL_NAME X Y KB TOP BOTTOM SYMBOL井名X坐标Y坐标海拔顶深底深(完钻)井的类型②加载井斜数据(WELL PATH)第一种数据格式MD TVD DX DY AZIM INCL斜深垂深东西偏移南北偏移方位角倾角第二种数据格式MD INCL AZIM第三种数据格式TVD DX DY(单井用WELL LOGS,多井加井斜可用PRODUCTION LOGS)③加载分层数据(WELL TOPS)(包括断点数据)MD WELLPOINT 层名WELL NAME-1500 HORIZON Nm31 NP1-1600 FAULT Nm32 NP1以WELL TOPS加载之后删除系统的缺省项,新建4项,对应输入数据的列,名称进行编辑,Sub-sea Z values must be negative!(低于海平面的Z值都为负),该选项在编辑时不要选中④加载测井曲线(WELL LOGS)LAS格式文件MD RESIS AC SP GR曲线采用0.125m的点数据(1m8个点数据),注意有的曲线单位要由英制转换为公制,如:AC 英制单位μs/in要换成工制单位μs/m,再用转换程序转换为LAS格式文件进行输入,以提高数据的加载速度。
如果有孔渗饱数据,按相同格式依次排列即可。
在/INPUT DATA中设置数据的排列顺序,曲线内容较多,系统缺省项只有MD,所以要用SPECIFY TO BE LOADED定义新的曲线,对应加载数据的列数,名称和属性进行编辑。
Petrel属性建模系列(3)—相数据分析及相建模构造模型建好之后,在此基础上进行属性建模的工作,属性建模包括相建模和岩石物理属性建模两个部分。
主要分为四大步完成:属性数据准备、属性数据粗化、相数据分析及相建模、孔渗饱数据分析及孔渗饱建模。
相数据分析及相建模流程如下:一、相数据分析:1、在Models面板,激活三维模型Exercise model。
2、数据分析选上Property Modeling标签,在Data preparation组,点击图标,选择要分析的沉积相为Facies。
点开锁图标,选择要分析的Zones:zoneA。
相数据分析包括有5项内容:相比例Proportion、相厚度Thickness、相概率曲线Probability、变差函数Variograms和去丛聚Declustering。
1)相比例Proportion分析在相比例Proportion标签下,在左边窗口的Estimated facies proportions是井上粗化的每个小层layer的相比例,如果对井上粗化的相比例认为不能完全代表一个小层的真正的相比例,可以通过右边的窗口去手动调整小层的相比例。
调整过程如下:可以选上要调整的相,比如Channel,点击图标得到井上粗化的相曲线,然后点击圆滑图标,对调整的相曲线做一下圆滑。
可以调整每个小层的控制点得到新的相比例曲线,要调整的相曲线都调好以后点击Apply保存相比例调整结果,可以为后面的相建模调用。
2)相厚度Thickness分析在Thickness标签下可以查看在每个Zone里井上粗化的每种相的厚度分布,如下图:3)相概率曲线Probability分析在Probability标签下可以选择和沉积相相关性比较好的第二属性,比如反演的波阻抗属性AI,分析在第二属性的分布范围内,相出现的概率曲线,如果分析得到了很好的正相关或负相关的概率分布曲线,则可以用该概率曲线约束相建模。
第六章相建模(FaciesModeling)6.1 Petrel2010版本中相建模技术的大发展Petrel相建模(Facies Modeling)现有方法主要包括:多点地质统计学相模拟、基于目标的河流相模拟,基于像元的序贯指示模拟、截断高斯模拟,带趋势的截断高斯模拟,指示克里金模拟、神经网络方法,用于详细表征相带分布特征的确定性和随机性相建模技术,而且可以交互使用。
同时用户可以导入自己的算法和人工赋值的方法,建立沉积相模型。
Petrel2010在原有版本基础上对相建模方法做了较大的改进,主要体现在以下四个方面:1)全新的MPS多点统计相模拟算法在Petrel2010版本中,引进了多点地质统计学相模拟方法,该方法的引进改变了过去传统的两点统计地质学方法,而发展为多点地质学,解决了过去两点统计关系上变差函数的不足,特别是对储层非均质性描述上的不足,多点统计地质学能够充分描述复杂几何形状砂体的空间连续性和变异性。
多点统计地质学是建立在多个点的相关关系上,它在解决描述空间变量的连续性和变异性方面得到越来越广泛的应用。
斯坦福大学的Journel教授曾指出多点地质统计学是今后地质统计学发展的方向,它的优势已越来越显著。
2)基于快速傅立叶变换的高斯模拟算法一种新的新的高斯模拟算法在Petrel 2010.1.中被引用,这种算法与GSLIB的序贯随机模拟方式不同。
A 它比SGS运算速度提高了很多B 它不是序贯算法C 它可以并行运算D 它可以进行快速的协同模拟设定如同上面提到的,这种高斯算法不同于序贯模拟的序贯算法,允许并行计算,采用的算法是傅立叶变换算法,这种算法具有快速、并行、在大的范围变程内优选最合理的变程等优点,这种算法的界面与序贯高斯模拟算法有些类似。
3)进一步改进克里金算法在2010.1版本中引用了新的克里金算法,这是完全不同于标准GSLIB 克里金的一种设计,其搜索性能和并行运算都有很大改进。
克里金可以沿网格方向、也可以沿海平面进行插值。