语音信号处理作业2
- 格式:doc
- 大小:103.00 KB
- 文档页数:7

语音信号处理实验报告实验二一、实验目的本次语音信号处理实验的目的是深入了解语音信号的特性,掌握语音信号处理的基本方法和技术,并通过实际操作和数据分析来验证和巩固所学的理论知识。
具体而言,本次实验旨在:1、熟悉语音信号的采集和预处理过程,包括录音设备的使用、音频格式的转换以及噪声去除等操作。
2、掌握语音信号的时域和频域分析方法,能够使用相关工具和算法计算语音信号的短时能量、短时过零率、频谱等特征参数。
3、研究语音信号的编码和解码技术,了解不同编码算法对语音质量和数据压缩率的影响。
4、通过实验,培养我们的动手能力、问题解决能力和团队协作精神,提高我们对语音信号处理领域的兴趣和探索欲望。
二、实验原理(一)语音信号的采集和预处理语音信号的采集通常使用麦克风等设备将声音转换为电信号,然后通过模数转换器(ADC)将模拟信号转换为数字信号。
在采集过程中,可能会引入噪声和干扰,因此需要进行预处理,如滤波、降噪等操作,以提高信号的质量。
(二)语音信号的时域分析时域分析是对语音信号在时间轴上的特征进行分析。
常用的时域参数包括短时能量、短时过零率等。
短时能量反映了语音信号在短时间内的能量分布情况,短时过零率则表示信号在单位时间内穿过零电平的次数,可用于区分清音和浊音。
(三)语音信号的频域分析频域分析是将语音信号从时域转换到频域进行分析。
通过快速傅里叶变换(FFT)可以得到语音信号的频谱,从而了解信号的频率成分和分布情况。
(四)语音信号的编码和解码语音编码的目的是在保证一定语音质量的前提下,尽可能降低编码比特率,以减少存储空间和传输带宽的需求。
常见的编码算法有脉冲编码调制(PCM)、自适应差分脉冲编码调制(ADPCM)等。
三、实验设备和软件1、计算机一台2、音频采集设备(如麦克风)3、音频处理软件(如 Audacity、Matlab 等)四、实验步骤(一)语音信号的采集使用麦克风和音频采集软件录制一段语音,保存为常见的音频格式(如 WAV)。

语⾳信号处理实验讲义语⾳信号处理实验讲义编写⼈:蔡萍时间:2011-12实验⼀语⾳信号⽣成模型分析⼀、实验⽬的1、了解语⾳信号的⽣成机理,了解由声门产⽣的激励函数、由声道产⽣的调制函数和由嘴唇产⽣的辐射函数。
2、编程实现声门激励波函数波形及频谱,与理论值进⾏⽐较。
3、编程实现已知语⾳信号的语谱图,区分浊⾳信号和清⾳信号在语谱图上的差别。
⼆、实验原理语⾳⽣成系统包含三部分:由声门产⽣的激励函数()G z 、由声道产⽣的调制函数()V z 和由嘴唇产⽣的辐射函数()R z 。
语⾳⽣成系统的传递函数由这三个函数级联⽽成,即()()()()H z G z V z R z =1、激励模型发浊⾳时,由于声门不断开启和关闭,产⽣间隙的脉冲。
经仪器测试它类似于斜三⾓波的脉冲。
也就是说,这时的激励波是⼀个以基⾳周期为周期的斜三⾓脉冲串。
单个斜三⾓波的频谱表现出⼀个低通滤波器的特性。
可以把它表⽰成z 变换的全极点形式121()(1)cTG z ez --=-?这⾥c 是⼀个常数,T 是脉冲持续时间。
周期的三⾓波脉冲还得跟单位脉冲串的z 变换相乘:1121()()()1(1)v cT A U z E z G z z e z ---=?=--这就是整个激励模型,v A 是⼀个幅值因⼦。
2、声道模型当声波通过声道时,受到声腔共振的影响,在某些频率附近形成谐振。
反映在信号频谱图上,在谐振频率处其谱线包络产⽣峰值,把它称为共振峰。
⼀个⼆阶谐振器的传输函数可以写成12()1ii i i A V z B z C z--=-- 实践表明,⽤前3个共振峰代表⼀个元⾳⾜够了。
对于较复杂的辅⾳或⿐⾳共振峰要到5个以上。
多个()i V z 叠加可以得到声道的共振峰模型12111()()11Rrr MMir i N ki i i ik k b zA V z V zB zC z a z -=---======---∑∑∑∑3、辐射模型从声道模型输出的是速度波,⽽语⾳信号是声压波。

华南理工大学《语音信号处理》作业报告姓名:学号:班级:10级电信5班日期:2013年5 月24日1.实验要求编程实现:作业1、提取一段语音信号的短时能量、过零率、短时平均幅度差。
作业2、提取一段语音的傅里叶变换幅度谱、线性倒谱、梅尔频率倒谱(MFCC)。
作业3、提取一段语音的LPC参数。
作业4、估计一段语音的基音频率。
作业5、估计一段语音的前3个共振峰频率。
作业1:1、实验原理(1)、短时能量语音和噪声的区别可以体现在它们的能量上,语音段的能量比噪声段能量大,语音段的能量是噪声段能量叠加语音声波能量的和。
在信噪比很高时,那么只要计算输入信号的短时能量或短时平均幅度就能够把语音段和噪声背景区分开。
这是仅基于短时能量的端点检测方法。
信号{x(n)}的短时能量定义为:语音信号的短时平均幅度定义为:其中w(n)为窗函数。
(2)、短时平均过零率短时过零表示一帧语音信号波形穿过横轴(零电平)的次数。
过零分析是语音时域分析中最简单的一种。
对于连续语音信号,过零意味着时域波形通过时间轴;而对于离散信号,如果相邻的取样值的改变符号称为过零。
过零率就是样本改变符号次数。
信号{x(n)}的短时平均过零率定义为:式中,sgn为符号函数,即:过零率有两类重要的应用:第一,用于粗略地描述信号的频谱特性;第二,用于判别清音和浊音、有话和无话。
从上面提到的定义出发计算过零率容易受低频干扰,特别是50Hz交流干扰的影响。
解决这个问题的办法,一个是做高通滤波器或带通滤波,减小随机噪声的影响;另一个有效方法是对上述定义做一点修改,设一个门限T,将过零率的含义修改为跨过正负门限。
于是,有定义:2、实验结果及讨论本次实验选取语音文件phrase.WA V,运行程序,结果如下图:3、实验代码[x,fs,nbits]=wavread('E:\yuuyin\phrase.WAV');x = x / max(abs(x));%幅度归一化到[-1,1]%参数设置FrameLen = 256; %帧长inc = 90; %未重叠部分amp1 = 10; %短时能量阈值amp2 = 2;zcr1 = 10; %过零率阈值zcr2 = 5;%计算过零率tmp1 = enframe(x(1:end-1), FrameLen,inc);tmp2 = enframe(x(2:end) , FrameLen,inc);signs = (tmp1.*tmp2)<0;diffs = (tmp1 -tmp2)>0.02;zcr = sum(signs.*diffs,2);%计算短时能量amp = sum((abs(enframe(filter([1 -0.9375], 1, x), FrameLen, inc))).^2, 2);subplot(3,1,1)plot(x)axis([1 length(x) -1 1])xlabel('帧数');ylabel('Speech');subplot(3,1,2)plot(amp);axis([1 length(amp) 0 max(amp)])xlabel('帧数');ylabel('Energy');subplot(3,1,3)plot(zcr);axis([1 length(zcr) 0 max(zcr)])xlabel('帧数');ylabel('ZCR');作业2、3:1、 提取一段语音的傅里叶变换幅度谱[x]=wavread('E:\yuuyin\monologue speech_male.wav'); y=fft(x); %傅里叶变换函数 plot(abs(y)); %振幅频率 title('傅里叶变换幅度谱');2、 提取一段语音的线性倒谱和LPC 参数基本原理:由于频率响应)(jw e H 反映声道的频率响应和被分析信号的谱包络,因此用|)(|log jw e H 做反傅里叶变换求出的LPC 倒谱系数。

《语音信号处理》课程试验练习
本课程专题试验练习的目的是循序渐进,通过组合若干次专题练习,最终实现一个能够识别10个数字的孤立字语音识别系统。
练习1.
使用能量特征、过零率特征设计一个语音检测算法。
要求能在普通的实验室噪声环境下,准确地检测出语音信号的起终点位置。
练习2.
编写计算LPC 预测器系数的Durbin 算法程序,在此基础上计算全极点模型的倒谱。
编写FFT程序,由此计算语音信号的倒谱。
练习3.
编写语音识别的DTW 模板匹配算法程序。
练习4
用DTW算法和语音的倒谱特征实现一个能够识别10个不同数字发音的孤立字语音识别系统。


语音信号处理(第2版)赵力编著语音信号处理勾画要点语音信号处理(第2版)赵力编著重点考点第2章语音信号处理的基础知识1.语音(Speech)是声音(Acoustic)和语言(Language)的组合体。
可以这样定义语音:语音是由一连串的音组成语言的声音。
2.人的说话过程可以分为五个阶段:(1)想说阶段(2)说出阶段(3)传送阶段(4)理解阶段(5)接收阶段。
3.语音是人的发声器官发出的一种声波,它具有一定的音色,音调,音强和音长。
其中,音色也叫音质,是一种声音区别于另一种声音的基本特征。
音调是指声音的高低,它取决于声波的频率。
声音的强弱叫音强,它由声波的振动幅度决定。
声音的长短叫音长,它取决于发音时间的长短。
4.说话时一次发出的,具有一个响亮的中心,并被明显感觉到的语音片段叫音节(Syllable)。
一个音节可以由一个音素(Phoneme)构成,也可以由几个音素构成。
音素是语音发音的最小单位。
任何语言都有语音的元音(Vowel)和辅音(Consonant)两种音素。
5.元音的另一个重要声学特性是共振峰(Formant)。
共振峰参数是区别不同元音的重要参数,它一般包括共振峰频率(Formant Frequency)的位置和频带宽度(Formant Bandwidth)。
6.区分语音是男声还是女声、是成人声音还是儿童声音,更重要的因素是共振峰频率的高低。
7.浊音的声带振动基本频率称基音周期(或基音频率),F0表示。
8.人的听觉系统有两个重要特性,一个是耳蜗对于声信号的时频分析特性;另一个是人耳听觉掩蔽效应。
9.掩蔽效应分为同时掩蔽和短时掩蔽。
10.激励模型:一般分成浊音激励和清音激励。
浊音激励波是一个以基音周期为周期的斜三角脉冲串。
11.声道模型:一是把声道视为由多个等长的不同截面积的管子串联而成的系统。
按此观点推导出的叫“声管模型”。
另一个是把声道视为一个谐振腔,按此推导出的叫“共振峰模型”。
12.完整的语音信号的数字模型可以用三个子模型:激励模型、声道模型和辐射模型的串联来表示。

实验一基于 MATLAB 的语音信号时域特征分析操作:报告:一. 实验目的语音信号是一种非平稳的时变信号,它携带着各种信息。
在语音编码、语音合成、语音识别和语音增强等语音处理中无一例外需要提取语音中包含的各种信息。
语音信号分析的目的就在与方便有效的提取并表示语音信号所携带的信息。
语音信号分析可以分为时域和变换域等处理方法,其中时域分析是最简单的方法,直接对语音信号的时域波形进行分析,提取的特征参数主要有语音的短时能量,短时平均过零率,短时自相关函数等。
本实验要求掌握时域特征分析原理,并利用已学知识,编写程序求解语音信号的短时过零率、短时能量、短时自相关特征,分析实验结果,并能掌握借助时域分析方法所求得的参数分析语音信号的基音周期及共振峰。
二. 实验内容1.窗口的选择通过对发声机理的认识,语音信号可以认为是短时平稳的。
在 5~50ms 的范围内,语音频谱特性和一些物理特性参数基本保持不变。
我们将每个短时的语音称为一个分析帧。
一般帧长取 10~30ms。
我们采用一个长度有限的窗函数来截取语音信号形成分析帧。
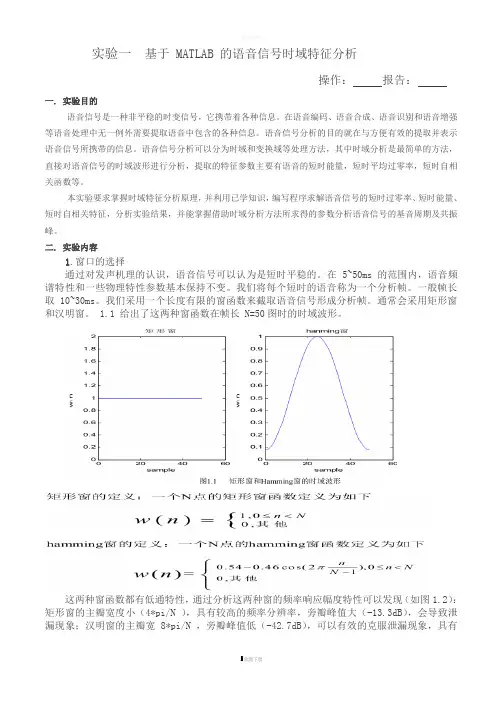
通常会采用矩形窗和汉明窗。
1.1 给出了这两种窗函数在帧长 N=50图时的时域波形。
这两种窗函数都有低通特性,通过分析这两种窗的频率响应幅度特性可以发现(如图1.2):矩形窗的主瓣宽度小(4*pi/N ),具有较高的频率分辨率,旁瓣峰值大(-13.3dB),会导致泄漏现象;汉明窗的主瓣宽 8*pi/N ,旁瓣峰值低(-42.7dB),可以有效的克服泄漏现象,具有更平滑的低通特性。
因此在语音频谱分析时常使用汉明窗,在计算短时能量和平均幅度时通常用矩形窗。
2. 短时能量由于语音信号的能量随时间变化,清音和浊音之间的能量差别相当显著。
因此对语音的短时能量进行分析,可以描述语音的这种特征变化情况。
定义短时能量为:在用短时能量反映语音信号的幅度变化时,不同的窗函数以及相应窗的长短均有影响。
hamming 窗的效果比矩形窗略好。

实验报告实验课程名称:语音信号处理实验姓名:班级: 20120811 学号:Array指导教师张磊实验教室 21B#293实验时间 2015年4月12日实验成绩实验一 语音信号的端点检测一、实验目的1、掌握短时能量的求解方法2、掌握短时平均过零率的求解方法3、掌握利用短时平均过零率和短时能量等特征,对输入的语音信号进行端点检测。
二、实验设备 HP 计算机、Matlab 软件 三、实验原理 1、短时能量语音信号的短时能量分析给出了反应这些幅度变化的一个合适的描述方法。
对于信号)}({n x ,短时能量的定义如下:∑∑∞-∞=∞-∞=*=-=-=m m n n h n x m n h m xm n w m x E )()()()()]()([2222、短时平均过零率短时平均过零率是指每帧内信号通过零值的次数。
对于连续语音信号,可以考察其时域波形通过时间轴的情况。
对于离散信号,实质上就是信号采样点符号变化的次数。
过零率在一定程度上可以反映出频率的信息。
短时平均过零率的公式为:∑∑-+=∞-∞=--=---=1)]1(sgn[)](sgn[21 )()]1(sgn[)](sgn[21N n nm w w m n m x m x m n w m x m x Z其中,sgn[.]是符号函数,即⎩⎨⎧<-≥=0)(10)(1)](sgn[n x n x n x3、端点检测原理能够实现这些判决的依据在于,不同性质语音的各种短时参数具有不同的概率密度函数,以及相邻的若干帧语音应具有一致的语音特性,它们不会在S 、U 、V 之间随机地跳来跳去。
要正确判断每个输入语音的起点和终点,利用短时平均幅度参数E 和短时平均过零率Z 可以做到这一点。
首先,根据浊音情况下的短时能量参数的概率密度函数)|(V E P 确定一个阈值参数H E ,H E 值一般定的较高。
当一帧输入信号的短时平均幅度参数超过H E 时,就可以判定该帧语音信号不是无声,而有相当大的可能是浊音。

设计报告课程名称语音信号处理任课教师设计题目班级姓名学号日期语音信号处理大作业用 Matlab 编程实现语音信号的短时分析一、目的1.在理论学习的基础上,进一步地理解和掌握语音信号短时分析的意义,短时时域分析的基本方法。
2.进一步理解和掌握语音信号短时平均能量函数及短时平均过零数的计算方法和重要意义。
二、原理及方法一定时宽的语音信号, 其能量的大小随时间有明显的变化。
其中清音段 (以清音为主要成份的语音段 , 其能量比浊音段小得多。
短时过零数也可用于语音信号分析中, 发浊音时, 其语音能量约集中于 3kHz 以下,而发清音时,多数能量出现在较高频率上,可认为浊音时具有较低的平均过零数, 而清音时具有较高的平均过零数, 因而, 对一短时语音段计算其短时平均能量及短时平均过零数, 就可以较好地区分其中的清音段和浊音段, 从而可判别句中清、浊音转变时刻,声母韵母的分界以及无声与有声的分界。
这在语音识别中有重要意义。
三、内容1.用 Matlab 语言完成程序编写工作。
2.程序应具有加窗(分帧、计算、以及绘制曲线等功能。
3.对录入的语音数据进行处理,并显示运行结果。
4.依据曲线对该语音段进行所需要的分析,并作出结论。
5.改变窗的宽度(帧长 ,重复上面的分析内容。
四、报告要求1.学习课本有关内容 , 理解和掌握短时平均能量函数及短时平均过零数函数的意义及其计算方法。
2.参考 Matlab 有关资料,设计并编写出具有上述功能的程序。
3.画出求得的短时分析曲线,注明语音段和所用窗函数及其宽度。
阐述所作分析和判断的过程,提出依据,得出判断结论。
附:所用语音信号文件名为 "shop.wav", 拷贝到 MATLAB 工作目录。
(语音信号内容可自选 Matlab 编程实验步骤:1.新建 M 文件,扩展名为“.m”,编写程序;2.选择 File/Save命令,将文件保存在 F 盘中;3.在 Command Window窗中输入文件名,运行程序;Matlab 部分函数语法格式:读 wav 文件: x=wavread(`filename`数组 a 及 b 中对应元素相乘: a.*b创建图形窗口命令: figure绘图函数: plot(x坐标轴: axis([xmin xmax ymin ymax]坐标轴注解:xlabel(`…`ylabel(`…`图例注解:legend( `…`一阶高通滤波器: y=filter([1-0.09375],1,xvoicebox 工具箱介绍:分帧函数:f=enframe(x,len,incx为输入语音信号, len 指定了帧长, inc 指定帧移,函数返回为 n×len的一个矩阵, 每一行都是一帧数据。

实验二语音信号处理语音信号处理综合运用了数字信号处理的理论知识,对信号进行计算及频谱分析,设计滤波器,并对含噪信号进行滤波。
一、(1)语音信号的采集:利用Windows下的录音机,录制一段话音。
然后在Matlab软件平台下,利用函数wavread对语音信号进行采样,播放语音信号,并绘制原始语音信号;改变采样率为原来的1/2倍,1/4倍,1/20倍,1/50倍,1/100倍等,分别画出降采样前后的信号波形和频谱图,分析采样前后信号的变化。
程序:y=wavread('a.wav');>> [y,fs,bits]=wavread('a.wav');>> y1=wavread('a.wav',1000);>> y2=wavread('a.wav',[500,1500]);>> subplot(311);plot(y);title('读a的信号图');>> subplot(312);plot(y1);title('读取前1000点的采样值放在向量y中');>> subplot(313);plot(y2);title('读取从500点到1500点的采样值放在向量y中');y=wavread('a.wav');>> [y,fs,bits]=wavread('a.wav');>> y11=resample(y,1,2); %采样率变为原来的1/2倍y12=fft(y11);>> y21=resample(y,1,20);>> y22=fft(y21);>> subplot(211);plot(y11);title('采样率变为原来的1/2');subplot(212);plot(abs(y12));title('采样率变为原来的1/2');subplot(211);plot(y21);title('采样率变为原来的1/20');>> subplot(212);plot(abs(22));title('采样率变为原来的1/20的频谱');sound(y,22050,16); sound(y11,22050,16);二、重构原信号:降采样后,信号的采样率和采样点数同时变化。
实验二语音信号分析与处理2010第一篇:实验二语音信号分析与处理2010实验一语音信号分析与处理学号姓名注:1)此次实验作为《数字信号处理》课程实验成绩的重要依据,请同学们认真、独立完成,不得抄袭。
2)请在授课教师规定的时间内完成;3)完成作业后,请以word格式保存,文件名为:学号+姓名4)请通读全文,依据第2及第3 两部分内容,认真填写第4部分所需的实验数据,并给出程序内容。
1.实验目的(1)学会MATLAB的使用,掌握MATLAB的程序设计方法(2)掌握在windows环境下语音信号采集的方法(3)掌握MATLAB设计FIR和IIR滤波器的方法及应用(4)学会用MATLAB对语音信号的分析与处理方法2.实验内容录制一段自己的语音信号,对录制的语音信号进行采样,画出采样后语音信号的时域波形和频谱图,确定语音信号的频带范围;使用MATLAB产生白噪声信号模拟语音信号在处理过程中的加性噪声并与语音信号进行叠加,画出受污染语音信号的时域波形和频谱图;采用双线性法设计出IIR滤波器和窗函数法设计出FIR滤波器,画出滤波器的频响特性图;用自己设计的这两种滤波器分别对受污染的语音信号进行滤波,画出滤波后语音信号的时域波形和频谱图;对滤波前后的语音信号进行时域波形和频谱图的对比,分析信号的变化;回放语音信号,感觉与原始语音的不同。
3.实验步骤1)语音信号的采集与回放利用windous下的录音机或其他软件录制一段自己的语音(规定:语音内容为自己的名字,以wav格式保存,如wql.wav),时间控制再2秒之内,利用MATLAB提供的函数wavread对语音信号进行采样,提供sound函数对语音信号进行回放。
[y,fs,nbits]=wavread(file),采样值放在向量y中,fs表示采样频率nbits表示采样位数。
Wavread的更多用法请使用help命令自行查询。
2)语音信号的频谱分析利用fft函数对信号进行频谱分析3)受白噪声干扰的语音信号的产生与频谱分析①白噪声的产生:N1=sqrt(方差值)×randn(语音数据长度,2)(其中2表示2列,是由于双声道的原因)然后根据语音信号的频谱范围让白噪声信号通过一个带通滤波器得到一个带限的白噪声信号N2;带通滤波器的冲激响应为:hB(n)=ωc2πsinc(ωc2π(n-α))-ωc1πsinc(ωc1π(n-α))其中ωc1为通带滤波器的下截止频率,ωc2为通带滤波器的上截止频率。
最新语音信号处理实验报告实验二实验目的:本实验旨在通过实际操作加深对语音信号处理理论的理解,并掌握语音信号的基本处理技术。
通过实验,学习语音信号的采集、分析、滤波、特征提取等关键技术,并探索语音信号处理在实际应用中的潜力。
实验内容:1. 语音信号采集:使用语音采集设备录制一段时长约为10秒的语音样本,确保录音环境安静,语音清晰。
2. 语音信号预处理:对采集到的语音信号进行预处理,包括去噪、归一化等操作,以提高后续处理的准确性。
3. 语音信号分析:利用傅里叶变换等方法分析语音信号的频谱特性,观察并记录基频、谐波等特征。
4. 语音信号滤波:设计并实现一个带通滤波器,用于提取语音信号中的特定频率成分,去除噪声和非目标频率成分。
5. 特征提取:从处理后的语音信号中提取关键特征,如梅尔频率倒谱系数(MFCC)等,为后续的语音识别或分类任务做准备。
6. 实验总结:根据实验结果,撰写实验报告,总结语音信号处理的关键技术和实验中遇到的问题及其解决方案。
实验设备与工具:- 计算机一台,安装有语音信号处理相关软件(如Audacity、MATLAB 等)。
- 麦克风:用于采集语音信号。
- 耳机:用于监听和校正采集到的语音信号。
实验步骤:1. 打开语音采集软件,调整麦克风输入设置,确保录音质量。
2. 录制语音样本,注意控制语速和音量,避免过大或过小。
3. 使用语音分析软件打开录制的语音文件,进行频谱分析,记录观察结果。
4. 设计带通滤波器,设置合适的截止频率,对语音信号进行滤波处理。
5. 应用特征提取算法,获取语音信号的特征向量。
6. 分析滤波和特征提取后的结果,评估处理效果。
实验结果与讨论:- 描述语音信号在预处理、滤波和特征提取后的变化情况。
- 分析实验中遇到的问题,如噪声去除不彻底、频率成分丢失等,并提出可能的改进措施。
- 探讨实验结果对语音识别、语音合成等领域的潜在应用价值。
结论:通过本次实验,我们成功实现了语音信号的基本处理流程,包括采集、预处理、分析、滤波和特征提取。
语音信号处理实验报告实验一1 用Matlab读取一段话音(自己录制一段,最好其中含有汉语四种声调变化,该段话音作为本课实验原始材料),绘制原始语音波形图。
2. 用Matlab计算这段语音的短时平均过零率、短时平均能量和短时平均幅度,并将多个波形同步显示绘图。
3.观察各波形在不同音情况下的参数特点,并归纳总结其中的规律。
clc clc;[x,fs]=wavread('benpao.wav');figureplot(x);axis([0 length(x) min(x) max(x)]);title('原始语音波形')xlabel('时间')f=enframe(x,300,100);[m,n]=size(f);for i=1:menergy(i)=sum(f(i,1:n).^2);mn(i)=sum(abs(f(i,1:n)));endfigureplot(energy);axis([0 length(energy) min(energy) max(energy)]);title('短时能量')figureplot(mn);axis([0 length(mn) min(mn) max(mn)]);title('短时幅度')lingd=zeros(m);for x=1:mfor y=1:n-1temp=f(x,y)*f(x,y+1) ;if temp<= 0lingd(x)=lingd(x)+1;endend%temp1=num(x,1)/300;%count(x)=temp1;endfigureplot(lingd);%axis([0 length(lingd) min(lingd) max(lingd)]);title('短时过零率')子函数:function f=enframe(x,win,inc)%定义函数。
语音信号处理实验指导书实验一:语音信号的采集与播放实验目的:了解语音信号的采集与播放过程,掌握采集设备的使用方法。
实验器材:1. 电脑2. 麦克风3. 扬声器或者耳机实验步骤:1. 将麦克风插入电脑的麦克风插孔。
2. 打开电脑的录音软件(如Windows自带的录音机)。
3. 在录音软件中选择麦克风作为录音设备。
4. 点击录音按钮开始录音,讲话或者唱歌几秒钟。
5. 点击住手按钮住手录音。
6. 播放刚刚录制的语音,检查录音效果。
7. 将扬声器或者耳机插入电脑的音频输出插孔。
8. 打开电脑的音频播放软件(如Windows自带的媒体播放器)。
9. 选择要播放的语音文件,点击播放按钮。
10. 检查语音播放效果。
实验二:语音信号的分帧与加窗实验目的:了解语音信号的分帧和加窗过程,掌握分帧和加窗算法的实现方法。
实验器材:1. 电脑2. 麦克风3. 扬声器或者耳机实验步骤:1. 使用实验一中的步骤1-5录制一段语音。
2. 将录制的语音信号进行分帧处理。
选择合适的帧长和帧移参数。
3. 对每一帧的语音信号应用汉明窗。
4. 将处理后的语音帧进行播放,检查分帧和加窗效果。
实验三:语音信号的频谱分析实验目的:了解语音信号的频谱分析过程,掌握频谱分析算法的实现方法。
实验器材:1. 电脑2. 麦克风3. 扬声器或者耳机实验步骤:1. 使用实验一中的步骤1-5录制一段语音。
2. 将录制的语音信号进行分帧处理。
选择合适的帧长和帧移参数。
3. 对每一帧的语音信号应用汉明窗。
4. 对每一帧的语音信号进行快速傅里叶变换(FFT)得到频谱。
5. 将频谱绘制成图象,观察频谱的特征。
6. 对频谱进行谱减法处理,去除噪声。
7. 将处理后的语音帧进行播放,检查频谱分析效果。
实验四:语音信号的降噪处理实验目的:了解语音信号的降噪处理过程,掌握降噪算法的实现方法。
实验器材:1. 电脑2. 麦克风3. 扬声器或者耳机实验步骤:1. 使用实验一中的步骤1-5录制一段带噪声的语音。
语音信号处理实验班级:学号:姓名:实验一基于MATLAB的语音信号时域特征分析(2 学时)1)短时能量( 1)加矩形窗a=wavread('mike.wav');a=a(:,1);subplot(6,1,1),plot(a);N=32;for i=2:6h=linspace(1,1,2.^(i-2)*N);%形成一个矩形窗,长度为 2.^(i-2)*NEn=conv(h,a.*a);% 求短时能量函数Ensubplot(6,1,i),plot(En);if(i==2) ,legend('N=32' );elseif(i==3), legend('N=64' );elseif(i==4) ,legend('N=128' );elseif(i==5) ,legend('N=256' );elseif(i==6) ,legend('N=512' );endend1-10.5 1 1.5 2 2.54 x 102N=32 0 0.5 1 1.5 2 2.55 x 10N=64 0 0.5 1 1.5 2 2.510 x 1050.5 1 1.5 2 2.5 N=128 020 x 10100.5 1 1.5 2 2.5 N=256 040 x 1020N=5120 0.5 1 1.5 2 2.5x 10( 2)加汉明窗a=wavread('mike.wav');a=a(:,1);subplot(6,1,1),plot(a);N=32; 3 43 43 43 43 43 4for i=2:6h=hanning(2.^(i-2)*N);% 形成一个汉明窗,长度为 2.^(i-2)*NEn=conv(h,a.*a);% 求短时能量函数Ensubplot(6,1,i),plot(En);if(i==2), legend('N=32' );elseif(i==3), legend('N=64' );elseif(i==4) ,legend('N=128' );elseif(i==5) ,legend('N=256' );elseif(i==6) ,legend('N=512' );endend1-10.5 1 1.5 2 2.52 x 101N=32 0 0.5 1 1.5 2 2.54 x 102N=64 0 0.5 1 1.5 2 2.54 x 102N=128 0 0.5 1 1.5 2 2.510 x 105N=256 0 0.5 1 1.5 2 2.520 x 1010N=5120 0.5 1 1.5 2 2.5x 102)短时平均过零率a=wavread('mike.wav');a=a(:,1);n=length(a);N=320;subplot(3,1,1),plot(a);h=linspace(1,1,N);En=conv(h,a.*a); %求卷积得其短时能量函数Ensubplot(3,1,2),plot(En);for i=1:n-1if a(i)>=0 3 43 43 43 43 43 4elseb(i) = -1;endif a(i+1)>=0b(i+1)=1;elseb(i+1)= -1;endw(i)=abs(b(i+1)-b(i)); %求出每相邻两点符号的差值的绝对值endk=1;j=0;while (k+N-1)<nZm(k)=0;for i=0:N-1;Zm(k)=Zm(k)+w(k+i);endj=j+1;k=k+N/2; % 每次移动半个窗endfor w=1:jQ(w)=Zm(160*(w-1)+1)/(2*N); %短时平均过零率endsubplot(3,1,3),plot(Q),grid;1-100.51 1.52 2.5 34x 10201000.51 1.52 2.5 34x 100.50204060801001201401601803)自相关函数N=240y=wavread('mike.wav');y=y(:,1);x=y(13271:13510);x=x.*rectwin(240);R=zeros(1,240);for k=1:240for n=1:240-kR(k)=R(k)+x(n)*x(n+k);endendj=1:240;plot(j,R);grid;2.521.510.5-0.5-1-1.5050100150200250实验二基于 MATLAB 分析语音信号频域特征1)短时谱cleara=wavread('mike.wav');a=a(:,1);subplot(2,1,1),plot(a);title('original signal');gridN=256;h=hamming(N);for m=1:Nb(m)=a(m)*h(m)endy=20*log(abs(fft(b)))subplot(2,1,2)plot(y);title('短时谱 ');gridoriginal signal10.5-0.5-100.51 1.52 2.5 34x 10短时谱10.500.20.40.60.81 1.2 1.4 1.6 1.8 22)语谱图[x,fs,nbits]=wavread('mike.wav')x=x(:,1);specgram(x,512,fs,100);xlabel('时间 (s)');ylabel('频率 (Hz)' );title('语谱图 ');语谱图50004000)zH3000(率频200010000.51 1.5 2时间 (s) 3)倒谱和复倒谱(1)加矩形窗时的倒谱和复倒谱cleara=wavread('mike.wav',[4000,4350]);a=a(:,1);N=300;h=linspace(1,1,N);for m=1:Nb(m)=a(m)*h(m);endc=cceps(b);c=fftshift(c);d=rceps(b);d=fftshift(d);subplot(2,1,1)plot(d);title( '加矩形窗时的倒谱')subplot(2,1,2)plot(c);title( '加矩形窗时的复倒谱')加矩形窗时的倒谱1-1-2050100150200250300加矩形窗时的复倒谱105-5-10050100150200250300(2)加汉明窗时的倒谱和复倒谱 cleara=wavread('mike.wav',[4000,4350]);a=a(;,1);N=300;h=hamming(N);for m=1:Nb(m)=a(m)*h(m);endc=cceps(b);c=fftshift(c);d=rceps(b);d=fftshift(d);subplot(2,1,1)plot(d);title( '加汉明窗时的倒谱')subplot(2,1,2)plot(c);title( '加汉明窗时的复倒谱')加汉明窗时的倒谱1-1-2-3050100150200250300加汉明窗时的复倒谱105-5-10050100150200250300实验三基于 MATLAB 的 LPC 分析MusicSource = wavread('mike.wav');MusicSource=MusicSource(:,1);Music_source = MusicSource';N = 256; % window length, N = 100 -- 1000;Hamm = hamming(N); % create Hamming windowframe = input( '请键入想要处理的帧位置= ' );% origin is current frameorigin = Music_source(((frame - 1) * (N / 2) + 1):((frame - 1) * (N / 2) + N));Frame = origin .* Hamm';%%Short Time Fourier Transform%[s1,f1,t1] = specgram(MusicSource,N,N/2,N);[Xs1,Ys1] = size(s1);for i = 1:Xs1FTframe1(i) = s1(i,frame);endN1 = input( '请键入预测器阶数= ' ); % N1 is predictor's order[coef,gain] = lpc(Frame,N1); % LPC analysis using Levinson-Durbin recursionest_Frame = filter([0 -coef(2:end)],1,Frame); % estimate frame(LP)FFT_est = fft(est_Frame);err = Frame - est_Frame; % error% FFT_err = fft(err);subplot(2,1,1),plot(1:N,Frame,1:N,est_Frame,'-r');grid;title('原始语音帧 vs.预测后语音帧 ')subplot(2,1,2),plot(err);grid;title('误差 ');pause%subplot(2,1,2),plot(f',20*log(abs(FTframe2)));grid;title('短时谱 ')%%Gain solution using G^2 = Rn(0) - sum(ai*Rn(i)),i = 1,2,...,P%fLength(1 : 2 * N) = [origin,zeros(1,N)];Xm = fft(fLength,2 * N);X = Xm .* conj(Xm);Y = fft(X , 2 * N);Rk = Y(1 : N);PART = sum(coef(2 : N1 + 1) .* Rk(1 : N1));G = sqrt(sum(Frame.^2) - PART);A = (FTframe1 - FFT_est(1 : length(f1'))) ./ FTframe1 ; % inverse filter A(Z)subplot(2,1,1),plot(f1',20*log(abs(FTframe1)),f1',(20*log(abs(1 ./ A))),'-r');grid;title('短时谱 ');subplot(2,1,2),plot(f1',(20*log(abs(G ./ A))));grid;title( 'LPC谱 ');pause%plot(abs(ifft(FTframe1 ./ (G ./ A))));grid;title('excited')%plot(f1',20*log(abs(FFT_est(1 : length(f1')) .* A / G )));grid;%pause%%find_pitch%temp = FTframe1 - FFT_est(1 : length(f1'));%not move higher frequncepitch1 = log(abs(temp));pLength = length(pitch1);result1 = ifft(pitch1,N);% move higher frequncepitch1((pLength - 32) : pLength) = 0;result2 = ifft(pitch1,N);%direct do real cepstrum with errpitch = fftshift(rceps(err));origin_pitch = fftshift(rceps(Frame));subplot(211),plot(origin_pitch);grid;title( '原始语音帧倒谱 (直接调用函数 )');subplot(212),plot(pitch);grid;title( '预测误差倒谱 (直接调用函数 )');pausesubplot(211),plot(1:length(result1),fftshift(real(result1)));grid;title('预测误差倒谱 (根据定义编写,没有去除高频分量)');subplot(212),plot(1:length(result2),fftshift(real(result2)));grid;title('预测误差倒谱 (根据定义编写,去除高频分量 )');原始语音帧 vs. 预测后语音帧0.40.2-0.2-0.4050100150200250300误差0.20.1-0.1-0.2050100150200250300短时谱50-50-100010203040506070LPC 谱100806040010203040506070原始语音帧倒谱(直接调用函数)0.5-0.5-1050100150200250300预测误差倒谱(直接调用函数)0.5-0.5-1050100150200250300预测误差倒谱(根据定义编写,没有去除高频分量)0.2-0.2-0.4-0.6050100150200250300预测误差倒谱(根据定义编写,去除高频分量)0.1-0.1-0.2-0.3050100150200250300预测误差倒谱(根据定义编写,没有去除高频分量)0.2-0.2-0.4-0.6050100150200250300预测误差倒谱(根据定义编写,去除高频分量)0.1-0.1-0.2-0.3050100150200250300预测误差倒谱(根据定义编写,没有去除高频分量)0.2-0.2-0.4-0.6050100150200250300预测误差倒谱(根据定义编写,去除高频分量)0.1-0.1-0.2-0.3050100150200250300实验四基于 VQ 的特定人孤立词语音识别研究1、mfcc.mfunction ccc = mfcc(x)bank=melbankm(24,256,8000,0,0.5,'m' );bank=full(bank);bank=bank/max(bank(:));for k=1:12n=0:23;dctcoef(k,:)=cos((2*n+1)*k*pi/(2*24));endw = 1 + 6 * sin(pi * [1:12] ./ 12);w = w/max(w);xx=double(x);xx=filter([1 -0.9375],1,xx);xx=enframe(xx,256,80);for i=1:size(xx,1)y = xx(i,:);s = y' .* hamming(256);t = abs(fft(s));t = t.^2;c1=dctcoef * log(bank * t(1:129));c2 = c1.*w';m(i,:)=c2';enddtm = zeros(size(m));for i=3:size(m,1)-2dtm(i,:) = -2*m(i-2,:) - m(i-1,:) + m(i+1,:) + 2*m(i+2,:);enddtm = dtm / 3;ccc = [m dtm];ccc = ccc(3:size(m,1)-2,:);2、vad.mfunction [x1,x2] = vad(x)x = double(x);x = x / max(abs(x));FrameLen = 240;FrameInc = 80;amp1 = 10;amp2 = 2;zcr1 = 10;zcr2 = 5;maxsilence = 8; % 6*10ms = 30msminlen = 15; % 15*10ms = 150msstatus = 0;count = 0;silence = 0;tmp1 = enframe(x(1:end-1), FrameLen, FrameInc);tmp2 = enframe(x(2:end) , FrameLen, FrameInc);signs = (tmp1.*tmp2)<0;diffs = (tmp1 -tmp2)>0.02;zcr = sum(signs.*diffs, 2);amp = sum(abs(enframe(filter([1 -0.9375], 1, x), FrameLen, FrameInc)), 2); amp1 = min(amp1, max(amp)/4);amp2 = min(amp2, max(amp)/8);x1 = 0;x2 = 0;for n=1:length(zcr)goto = 0;switch statuscase {0,1}if amp(n) > amp1x1 = max(n-count-1,1);status = 2;silence = 0;count= count + 1;elseif amp(n) > amp2 | ...zcr(n) > zcr2status = 1;count = count + 1;elsestatus = 0;count= 0;endcase 2,if amp(n) > amp2 | ...zcr(n) > zcr2count = count + 1;elsesilence = silence+1;if silence < maxsilence count = count + 1;elseif count < minlenstatus = 0;silence = 0;count= 0;elsestatus = 3;endendcase 3,break;endendcount = count-silence/2;x2 = x1 + count -1;3、codebook.m%clear;function xchushi= codebook(m) [a,b]=size(m);[m1,m2]=szhixin(m);[m3,m4]=szhixin(m2);[m1,m2]=szhixin(m1);[m7,m8]=szhixin(m4);[m5,m6]=szhixin(m3);[m3,m4]=szhixin(m2);[m1,m2]=szhixin(m1);[m15,m16]=szhixin(m8);[m13,m14]=szhixin(m7);[m11,m12]=szhixin(m6);[m9,m10]=szhixin(m5);[m7,m8]=szhixin(m4);[m5,m6]=szhixin(m3);[m3,m4]=szhixin(m2);[m1,m2]=szhixin(m1);chushi(1,:)=zhixinf(m1);chushi(2,:)=zhixinf(m2);chushi(3,:)=zhixinf(m3);chushi(4,:)=zhixinf(m4);chushi(5,:)=zhixinf(m5);chushi(6,:)=zhixinf(m6);chushi(7,:)=zhixinf(m7);chushi(8,:)=zhixinf(m8);chushi(9,:)=zhixinf(m9);chushi(10,:)=zhixinf(m10);chushi(11,:)=zhixinf(m11);chushi(12,:)=zhixinf(m12);chushi(13,:)=zhixinf(m13);chushi(14,:)=zhixinf(m14);chushi(15,:)=zhixinf(m15);chushi(16,:)=zhixinf(m16);sumd=zeros(1,1000);k=1;dela=1;xchushi=chushi;while(k<=1000)sum=ones(1,16);for p=1:afor i=1:16d(i)=odistan(m(p,:),chushi(i,:));enddmin=min(d);sumd(k)=sumd(k)+dmin;for i=1:16if d(i)==dminxchushi(i,:)=xchushi(i,:)+m(p,:);sum(i)=sum(i)+1;endendendfor i=1:16xchushi(i,:)=xchushi(i,:)/sum(i); endif k>1dela=abs(sumd(k)-sumd(k-1))/sumd(k); endk=k+1;chushi=xchushi;endreturn4、 testvq.mclear;disp('这是一个简易语音识别系统,请保证已经将您的语音保存在相应文件夹中') disp('正在训练您的语音模版指令,请稍后...')for i=1:10fname = sprintf(海儿的声音\\%da.wav' ,i-1);x = wavread(fname);[x1 x2] = vad(x);m = mfcc(x);m = m(x1:x2-5,:);ref(i).code=codebook(m);enddisp('语音指令训练成功,恭喜!)?'disp('正在测试您的测试语音指令,请稍后...')for i=1:10fname = sprintf(海儿的声音\\%db.wav' ,i-1);x = wavread(fname);[x1 x2] = vad(x);mn = mfcc(x);mn = mn(x1:x2-5,:);%mn = mn(x1:x2,:)test(i).mfcc = mn;endsumsumdmax=0;sumsumdmin=0;disp('对训练过的语音进行测试')for w=1:10sumd=zeros(1,10);[a,b]=size(test(w).mfcc);for i=1:10for p=1:afor j=1:16d(j)=odistan(test(w).mfcc(p,:),ref(i).code(j,:));enddmin=min(d);sumd(i)=sumd(i)+dmin; %×üê§??endendsumdmin=min(sumd)/a;sumdmin1=min(sumd);sumdmax(w)=max(sumd)/a;sumsumdmin=sumdmin+sumsumdmax;sumsumdmax=sumdmax(w)+sumsumdmax;disp('正在匹配您的语音指令,请稍后...')for i=1:10if (sumd(i)==sumdmin1)switch (i)case 1fprintf( '您输入的语音指令为:%s; 识别结果为 %s\n' ,'前 ', '前 ');case2fprintf( '您输入的语音指令为:%s; 识别结果为 %s\n' ,'后 ', '后 ');case3fprintf( '您输入的语音指令为:%s; 识别结果为 %s\n' ,'左 ', '左 ');case4fprintf( '您输入的语音指令为a:%s;识别结果为 %s\n' ,'右 ', '右 ');case5fprintf( '您输入的语音指令为:%s; 识别结果为 %s\n' ,'东 ', '东 ');case6fprintf( '您输入的语音指令为:%s; 识别结果为 %s\n' ,'南 ', '南 ');case7fprintf( '您输入的语音指令为:%s; 识别结果为 %s\n' ,'西 ', '西 ');case8fprintf( '您输入的语音指令为:%s; 识别结果为 %s\n' ,'北 ', '北 ');case9fprintf( '您输入的语音指令为a:%s;识别结果为 %s\n' ,'上 ', '上 ');case10fprintf( '您输入的语音指令为a:%s;识别结果为 %s\n' ,'下 ', '下 ');otherwisefprintf( 'error');endendendenddelamin=sumsumdmin/10;delamax=sumsumdmax/10;disp('对没有训练过的语音进行测试')disp('正在测试你的语音,请稍后...')for i=1:10fname = sprintf(o£ ?ùμ ?éùò?\\%db.wav' ,i-1);x = wavread(fname);[x1 x2] = vad(x);mn = mfcc(x);mn = mn(x1:x2-5,:);%mn = mn(x1:x2,:)test(i).mfcc = mn;endfor w=1:10sumd=zeros(1,10);[a,b]=size(test(w).mfcc);for i=1:10for p=1:afor j=1:16d(j)=odistan(test(w).mfcc(p,:),ref(i).code(j,:));enddmin=min(d);sumd(i)=sumd(i)+dmin; %×üê§??endendsumdmin=min(sumd);z=0;for i=1:10if (((sumd(i))/a)>delamax)||z=z+1;endenddisp('正在匹配您的语音指令,请稍后...')if z<=3for i=1:10if (sumd(i)==sumdmin)switch (i)case 1fprintf( '您输入的语音指令为:%s; 识别结果为%s\n' ,'前 ', '前 ');case2fprintf( '您输入的语音指令为 :%s; 识别结果为 %s\n' ,'后 ', '后 ');case3fprintf( '您输入的语音指令为 :%s; 识别结果为 %s\n' ,'左 ', '左 ');case4fprintf( '您输入的语音指令为a:%s;识别结果为%s\n' ,'右 ', '右 ');case5fprintf( '您输入的语音指令为:%s; 识别结果为%s\n' ,'东 ', '东 ');case6fprintf( '您输入的语音指令为:%s; 识别结果为%s\n' ,'南 ', '南 ');case7fprintf( '您输入的语音指令为:%s; 识别结果为%s\n' ,'西 ', '西 ');case8fprintf( '您输入的语音指令为 :%s; 识别结果为 %s\n' ,'北 ', '北 ');case9fprintf( '您输入的语音指令为a:%s;识别结果为%s\n' ,'上 ', '上 ');case10fprintf( '您输入的语音指令为a:%s;识别结果为%s\n' ,'下 ', '下 ');otherwisefprintf( 'error');endendendelsefprintf( '您输入的语音无效?\n'£)?endend(此文档部分内容来源于网络,如有侵权请告知删除,文档可自行编辑修改内容,供参考,感谢您的配合和支持)。
语音信号处理的发展历程及发展趋势201105028摘要:文章简要介绍了语音信号处理这一分支学科形成和发展的历史过程.指出了它在现代信息科学技术中的地位和作用.介绍了语音信号处理在应用领域的一些重要课题,如语音的低速率编码,语音的规则合成和文-语转换系统,语音识别和人-机语音对话等,这些仍然是当前研究的热点.文章最后展望了语音信号处理的发展前景,指出在这个领域还有很多难题等待人们去研究探索.关键词语音信号处理,语音低速编码,语音识别发展历程声学是物理学的一个分支学科,而语言声学又是声学的一个分支学科.它主要的研究方向是人的发声器官机理,发声器官的类比线路和数学模型,听觉器官的特性(如听阈、掩蔽、临界带宽、听力损失等),听觉器官的数学模型,语音信号的物理特性(如频谱特性、声调特性、相关特性、概率分布等),语音的清晰度和可懂度等.当今通信和广播的发展非常迅速,而语言通信和语言广播仍然是最重要的部分,语言声学则是这些技术科学的基础.语言声学的发展和电子学、计算机科学有着非常密切的关系.在它发展的过程中,有过几次飞跃.第一次飞跃是1907年电子管的发明和1920年无线电广播的出现.因为有了电子管放大器,很微弱的声音也可以放大,而且可以定量测量.从而使电声学和语言声学的一些研究成果,扩展到通信和广播部门.第二次飞跃应该是在20世纪70年代初,由于电子计算机和数字信号处理的发展,人们发现:声音信号特别是语音信号,可以通过模数转换器(A/D)采样和量化,它们转换为数字信号后,能够送进计算机.这样就可以用数字计算方法,对语音信号进行处理和加工.例如频谱分析可以用傅里叶变换或快速傅里叶变换(FFT)实现,数字滤波器可以用差分方程实现.在这个基础上,逐渐形成了一门新学科)))语音信号处理.它的发展很快,在通信、自动控制等领域,解决了很多用传统方法难以解决的问题.在信息科学中占有很重要的地位.语音信号处理在信息科学中的地位和作用众所周知,语音在人类社会中起了非常重要的作用.在现代信息社会中,小至人们的日常生活,大到国家大事、世界新闻、社会舆论和各种重要会议,都离不开语言和文字.近年来,普通电话、移动电话和互联网已经普及到家庭.在这些先进的工具中,语音信号处理中的语音编码和语音合成就有很大贡献.再进一步,可以预料到的口呼打字机(又称听写机,它能把语音转换为文字)、语音翻译机(例如输入为汉语,输出为英语,或者相反),已经不是梦想而是提到日程上的研究工作了.人们早就希望用语音指挥机器,机器的执行情况也能用语音回答.这在某些领域已经部分地实现了.目前计算机芯片的集成度和运算能力,每18个月就提高一倍,而成本又不断降低,因此,它已经广泛地应用于在社会生产和生活的各个方面.然而计算机接收信息的外围设备和主机相比,要逊色得多.能说能听的计算机还不能普遍使用.也就是说:语音识别、语音理解和语音合成等课题,还有很多理论问题和技术问题没有解决,需要继续深入研究.科学家们深入研究后认为,要解决人-机语音对话这样的难题,做出真正实用的语音机器,必须开展跨学科的研究,如声学、语言学、语音学、生理学、数字信号处理、人工智能和计算机科学等.要真正赋予微电脑以语言功能,必须彻底了解语言是如何产生、感知,以及人类的语言通信是如何进行的?图1给出了从语言产生到语音感知全过程中的几个重要环节.从图1可以看到,要使这个问题得到满意的解决,需要深入研究人类发声器官和听觉器官机理,建立能反映客观真实情况的物理模型和数学模型.图1人类语音通信的过程语音信号所包含的信息量[1,2]语音信号中到底包含了多少信息量,需要多少比特才能够无失真地表示它们,这对于语音编码、语音合成和语音识别的研究都是很有用的.但是这也是一个很复杂的问题,它涉及到对于信号失真的评价.下面列举了三种评价,其中两种是由弗累雷格(F lanagan)给出的,另一种是由约翰斯登(Johnston)提出的.它们是建立在下面三种不同的失真评价上:(1)语音信号的信噪比;(2)接收语音信号时,信号由听觉外围处理以后,人们在主观上能够感觉到的失真;(3)人在接收语音信号时,不正确接收音素的数目和正确接收音素数目的比值.在所有的三种情况下,所得到的比特率是首先选择能够接受的失真等级,然后,计算该失真等级所需的比特率.在测量音素失真的情况下(第三种),可以把接受的失真级设置为零.如果所有的音素都能正确传送,就是所期望的最好性能.假设相邻的音素之间不出现相关,则平均信息速率很容易计算.按照仙农(Shannon)的信息理论,每一个符号需要的平均比特数为I=-2()log i ii p p (1)式中pi 为每一个符号i 的概率,英语有42个音素(符号),汉语的音素有48个,其中辅音22个,单元音13个,复元音13个.在正常情况下,谈话速率大约是每秒钟10个音素.使用音素出现的相对概率表,能够计算出每一个符号的信息量大约是5bit,得到的全部信息速率大约是50bit/s.请注意,自然的静寂也包含在这个比特速率内.而系统仅仅传送音素序列,缺少发音人声音的个性特征(也就是声带的形状和对声道的描述).在另一方面,相邻音素之间的相关也被忽视了.考虑到这些音素后,把这一估计作为语音信息所需要的比特率低限,或者人们感知语音信号的最低要求,还是有一些道理的.其次,把语音信号的信噪比作为失真评价(第一种),在不考虑编码器结构的情况下,可以得到语音信号信息速率的高限.在具有电话带宽的信号中,估计最大信息速率时,必须要考虑合理的噪声等级.令P是信号的平均功率,W是信号的带宽,G是附加的噪声信号功率,假设附加的噪声信号是高斯白噪声,令C表示最大的信息速率,由仙农的理论,对于包含了附加噪声G的信号,C可由下式计算.2(1)log pc wG=+ (2) 在上式中,如果语音信号的带宽为3.5kHz,信噪比(SNR)为30dB,则它所包含的最大信息速率为35kb/s.这是语音所需要的信息速率的上限.在上面的公式中,对于语音信号所存在的短期相关和长期相关,都没有考虑.而信号中所存在的结构性相关,就意味着冗余度.它能够在传输之前除去,从而降低信息速率.下面所讨论的估计,要包括人的感知和理解.声音信号由人的听觉器官处理以后,它的信息率就降低了.声音信号的某些特点,会由于人听觉系统的掩蔽效应而不能被注意到.例如在一个特有频率上的低幅度纯音,可以被一个靠近该频率更响的纯音掩蔽.在除去了人们在感觉上不能区分的特点以后,再来考虑信号的信息速率是恰当的.如果把理解失真评价的阈值也设置到零(不能听到失真).则首先计算语音信号的傅里叶变换,然后按频带进行计算,要求的量化器步长应该使量化噪声在掩蔽阈值以下.掩蔽阈值和频带宽度都是建立在听觉系统知识的基础上,所得到的信息速率估计称为理解熵.对于电话带宽的语音,理解熵估计大约为10kb/s.这是对于连续语音的,相当于执行透明的语音编码所需的平均速率.上面讨论表明,人的感知和理解在语音处理中有很重要的作用.语音信号的中、低速率编码[1,5,6]按照语音产生的简化模型,可以构成低速率的语音编码器(又称声码器).最早的模拟声码器和以后的数字声码器LPC-10、LPC-10e都是根据这个模型设计的.激励源使用二元激励,在同一时间只能用一种激励方式,即白噪声或脉冲串.声道传输函数可用一组带通滤波器模拟,在更多的情况下,是把声门脉冲形状、嘴辐射和声道等因素结合起来,用一个全极点滤波器模拟.因为人的发声器官是机械系统,运动缓慢,传送这些慢变化的控制参量,可以用速率比较低的数码.它和传送波形所需要的数码相比,能够压缩许多倍,不但节约了频带,而且有利于保密.在第二次世界大战中,美国和德国都使用过这种保密电话.随着电子技术的进步,这种声码器经过精心设计和不断优化,在 2.4kbit/s的速率下,可以产生完全可懂的语音.美国军方和北大西洋公约组织一直用作保密电话.但音质和自然度很差,其原因是二元激励模型有局限性,不符合客观实际情况.科学家们经过深入研究,提出了合成-分析法(AbS),比较满意地解决了这个问题.AbS方法并不是惟一的用于语音编码,而是估计和验证领域的通用技术.它的基本概念如下:首先,假设产生信号模型的方式如图3所示.这个模型受一些参量控制,改变这些参量就能够产生不同的观测信号.要使所表示的模型和真正的信号模型有同样的形式,能够使用一个试探程序或误差程序,采用有规则的方法改变模型参量,从而可以找到一组参量,它所产生的合成信号,能够以最小误差与真正的信号相匹配(假设模型开始就是有效的).因此,当计算到这样的匹配时,模型的参量就可以认为是真正信号的参量.图2使用合成-分析法的语音编码方框图(采用AbS-LPC编码方案)AbS-LPC方案(使用合成―分析法的线性预测编码)的基本操作如下:(1)将LPC和音调滤波器(时-变滤波器)的内容,初始化到预定的值(通常是置到零或低量级无规噪声).(2)缓冲一帧语音样品,在该帧上使用LPC分析算法,计算出一组LPC系数.(3)使用计算得到的LPC系数,构成一个反滤波器,计算非量化的残差信号.(4)为了有效地分析激励信号,把分析帧再分为整数子帧.对于每一个子帧:(i)计算音调滤波器(长期预测器)的参量,也就是延迟S和与它联系的标量因子 .(ii)按照图2中的级联滤波器,则最优的辅助激励可以按照合成语音和原始语音之间的最小误差方法确定.(5)最后的合成语音,是由最优辅助激励通过具有初始存储内容的级联滤波器产生的(初始存储内容是从以前子帧合成过程中残留下来的).这种方案运算量很大,但话音质量好,数码率也可以做得很低(16k)4.8kbit/s).它有多种类型.例如多脉冲激励线性预测编码器(MPE-LPC)、规则脉冲激励线性预测编码器(RPE-LPC)、码激励线性预测编码器(CELP)等.多带激励线性预测编码器,也使用合成-分析法(AbS),改进了二元激励.它能够在2.4kbit/s的速率下,得到较好的语音质量.所有这些语音编码器都能够在单一DSP(数字信号处理器)芯片上实现.由于DSP芯片的运算能力不断增强,而价格又逐年降低,它不仅用于保密通信,而且广泛用于卫星通信、移动通信、短波通信和网络电话等很多方面.语音的规则合成和文-语转换系统[3,7]语音的规则合成是通过语音学规则产生语音的机器.该系统内存储了较小的语音单位(如音素、双音素、半音节和音节)的声学参数,以及由音素组成音节,再由音节组成词和句子的各种规则.当输入文字时,该系统利用规则自动地将它们转换为连续的语音.目前,汉语合成技术大体上可以分为两类:时域合成或称语音的波形合成这种方案通常以音节为合成单位.汉语共有1280多个单音节,可以从引导句中截取,经过适当的数据压缩后,构成一个汉语合成音节库.使用时,根据要求的信息,从语音库中取出音节的波形数据,串接或编辑到一起,再经过重音、韵律、持续时间等修正,就可以输出连续的合成语音.20世纪80年代末,提出了基音同步叠加算法(PSOLA算法),使得在波形数据的编辑过程中,能够方便地改变音调、重音、持续时间等物理特征,从而在组成词和句子时,能够方便地加入相应的规则,并转换为自然的、连续的语音.这种语音合成技术,占用计算机的存储量较大,但合成语音清晰自然,目前使用比较广泛.频域合成或语音的参量合成仍以单音节、半音节为基本合成单元,首先从引导句中截取这些单音节、半音节的波形,并进行分析,计算出它们的物理特征参数.主要的特征参数有:控制音强的幅度、控制音高(音调)的基频、控制音色的频谱(可以使用短时傅里叶变换或线性预测系数等).线性预测系数也可以转换为共振峰频率和带宽,这样从语音学的观点考虑,更为直观.这些参数经过编码压缩后,组成语音合成的参数库.使用时,根据要求的信息,从参数库中取出相应的特征参数,经过编辑和连接,并加入语音合成所需要的规则,顺序送入到语音合成器.在合成器里,这些参数控制着电子发声器官的相应部分,能够产生连续的语音.这种合成技术所需要的存储器容量较小,但运算比较复杂.为了改进合成语音的质量,也可以使用音调同步重叠相加的方法.由于可以控制的参数比较多,而且和实验语音学联系紧密,也有很好的发展前景.目前的语音质量正在不断地得到改善.文-语转换系统是上述语音合成系统的进一步发展.它输入的文字串是通常的文本字串,系统中的文本分析器根据发音词典,将输入的文字串分解为带有属性标记的词和相应的读音符号,再根据语义规则和语音规则,为每一个词、每一个音节确定重音等级、语句结构、语调、以及各种停顿等.这样,文字串就转换为发出声音的代码串,合成系统就可以据此合成出具有抑、扬、顿、挫和不同语气的语句.目前,这种系统已经被广泛地应用于社会生活的各个方面.例如自动报时、自动报气象、电话咨询系统,以及用电话转发电子邮件等.然而,人类的语音交流是涉及语言学、社会学、心理学、生理学等领域的复杂处理过程.要使文-语转换系统能和播音员一样,具有情感并有很高的自然度,仍然是非常困难的问题.它要求计算机对所朗读的文本,要有正确的理解.这就要求计算机内要有一个丰富的知识库,还要有相当强的智能.这是目前还没有解决的问题,有待今后深入研究.语音识别和人-机语音对话[6]语音识别包括发音人识别和语音识别两大类:发音人识别要从一群发音人中,找出预知他(她)声音的某一特定人.它又分为与文本有关和与文本无关两种,前者要求发音人所说的文本是预先指定的,而后者要求文本是任意的和不受任何限制的,很显然,后者的难度更大.语音识别有多种分类方法:按照词汇量的大小可划分为:小词汇语音识别(词数通常小于100);中等词汇语音识别(词数在100到500之间);大词汇语音识别(词数在500以上).目前已经做到好几万词汇.按照发音的方式,可分为孤立词语音识别和连续语音识别.孤立词识别是指发音者每次只说一个词或一条命令,它在词汇表中作为一个独立的识别单元,由识别系统来识别.连续语音识别是指发音人按照正常自然的发音方式发音,由识别系统来识别.按照服务对象可划分为:依赖于发音人和不依赖于发音人两种,即特定人工作方式和非特定人工作方式.凡识别系统只针对一个用户,即按照某一个特定发音人的特征而设计的,称为特定人工作方式.识别系统是根据很多发音人的共有特征设计的,允许任何人使用,则称为非特定人工作方式.这些分类方法也可组合起来,形成多种语音识别系统.很显然,特定人、小词汇、孤立词语音识别系统是最简单的方式,比较容易实现.而非特定人、大词汇、连续语音识别则很复杂,虽然,目前国内有很多大学和研究所开发了可供表演的样机,美国IBM公司还推出了汉语连续语音识别软件.但是都还存在很多问题,没有得到推广和普及,未取得商业上的成功.特定人、小词汇、孤立词语音识别系统大都采用简单的模板匹配原理.在训练阶段,用户将词汇表中的每一个词依次说一遍,并将它的特征矢量序列存入模板库中.识别时,将输入语音的特征矢量,依次与模板库中的每一个模板作相似度比较,相似度最高者就是识别的结果.但由于发音人在训练时和识别时,他们的说话速度不会完全一致,使得识别率难以提高,而使用动态时间伸缩算法(简称DTW算法),可以动态调整说话速度,从而找到最佳的模式匹配,使识别率提高.这种系统的识别率能达到98%以上,目前已经在一些自控装置、机器人等领域中应用.非特定人、大词汇、连续语音识别系统的原理如图3所示.在预处理单元中,除了反混叠滤波器、模数转换器、自动增益控制外,还包括自动分段和识别基元选择.对于汉语,识别基元可用音素即声母-韵母,或者使用考虑了受前后发音影响的声母-韵母变体.一般地说,有限词汇量的识别基元应该选得大一些,而无限词汇量的识别基元应该选得小一些.声学参数可用倒谱系数,或者使用模拟人耳听觉特性的MEL谱,还需要加上能量、过零率、音调等特征.测度估计通常使用隐马尔柯夫模型(HMM).连续发音时,每一个音节甚至每一个音素都会受前后发音的影响,使得它的物理特征发生很大变化.再者,人们的发声器官都会有一些差异,不同音人发出同一声音的物理特征,会有一些不同.这对于人的听觉器官来说,分辨语音信号的共性和个性,听懂和理解都能满意解决.但对计算机来说,却是很难的课题.目前最广泛使用的算法是隐马尔柯夫模型(HMM).马尔柯夫过程是一个双重的随机过程,人的语言过程就是这样一种双重随机过程.语言本身是一个可观察的随机序列,它是由大脑(不可观察的)根据语言需要和语法知识(状态选择)所发音素(或音节、词、句)的参数流.所以语音信号的模型可以用马尔柯夫模型来描述.马尔柯夫模型定义为K=F(A,B,P).在这三个模型参数中,P是事件(语音的参数流,可表示为矢量序列)的初始概率分布,B是某状态下事件的概率分布,它就是外界观察到的事件符号的概率,A是状态转移概率的分布.图3非特定人、大词汇、连续语音识别系统的原理图使用HMM作语音识别时,假设要识别的音素(或音节、词)有V个,为每一个音素(或音节、词)设计一个HMM模型.先用VQ技术设计一个尺寸为M(M为观察的符号数)的码本,然后用该音素(或音节、词)多次发音的语音数据,对它进行训练,得到最优的模型参数.与此同时,用最佳准则得到状态数为N的状态转移序列.最后,对实际要识别的语音信号用上面训练所得到的模型进行评估,吻合概率最大的那个音素(或音节、词)就是识别的结果.结论和展望本文简要介绍了‘语音信号处理’这一分支学科的形成过程.并指出了它在现代信息科学中的地位.有一些基础的理论问题和技术问题还在继续研究和发展中.在信息科学的应用领域,例如语音的低速率编码,语音的规则合成和文-语转换系统,语音识别和人-机语音对话等,仍然是当前研究的热点.有的已经解决了,有的只是部分解决了,还有很多难题等待我们去研究探索.这些难题是:(1)听觉器官的物理模型和数学表示,目前还没有一套权威的理论和成熟算法.虽然有多种设计,但实验结果都不够充分.特别是从听觉前端处理器所得到的波形特征,经过更高一级的处理,最后的信息速率只有50 bit/s,这是人们理解和感知语音信号的最低限度.而这一过程在人脑中是怎样完成的?目前还不太清楚.它是一个非常复杂的问题,需要进一步研究探索.(2)语音识别的子课题很多,其中最难的是非特定人、大词汇量、连续语音识别.近年来这个课题已经取得很大的进展.世界上有很多权威实验室推出了可供表演的识别系统,有些公司还推出了商品.但是由于不同人的发音差别很大,再加上环境噪声等影响,系统的正确识别率和顽健性离实际使用还有很大距离.目前,人们所期望的口呼打字机或听写机还没有得到推广.(3)语音的规则合成和文-语转换系统,已经取得了一批可以实用的成果.然而要使它能和优秀的播音员一样,具有不同风格、情感、很高的自然度,仍然是非常困难的问题.关键技术是如何根据一段文章的语境和语义,自动生成计算机可以识别的韵律符号.这涉及到机器对自然语音的理解,目前还在研究中.(4)语音增强包括从强噪声中提取语音信号,或者从几个人同时说话的混合波形中,分离出各自的语音信号,这类研究虽然理论上有一些算法,但效果均不理想,还没有达到可以实用的水平。