非线性混合效应生长模型的拟合、随机效应预测和应变量预测间对应关系
- 格式:pdf
- 大小:488.14 KB
- 文档页数:8

基于混合效应模型及EBLUP预测杉木树高生长过程王明初;孙玉军【期刊名称】《浙江农林大学学报》【年(卷),期】2017(034)005【摘要】基于福建省将乐县国有林场15块标准地的30株杉木Cunninghamia lanceolata标准木的解析数据,首先对5个生长方程运用非线性最小二乘法进行拟合,选出拟合效果最好的模型作为基础模型,利用解析木数据构建非线性混合效应树高生长模型.以单株树木作为随机效应,通过变换混合效应参数个数,利用R软件选择赤池信息准则(AIC),贝叶斯信息准则(BIC)最小,对数似然函数(Loglik)值最大的混合效应模型作为最优模型,基于混合效应模型研究经验线性无偏最优预测法(EBLUP)预测树高生长过程的特点.结果表明:Weibull方程中,β1,β2和β3等3个参数都作为混合效应参数的模型模拟精度最高.观测次数相同时,延长观测间隔能够降低预测误差,提高预测精度;观测间隔相同时,增加观测次数,预测精度会提高.图2表9参23【总页数】9页(P782-790)【作者】王明初;孙玉军【作者单位】北京林业大学林学院,北京 100083;北京林业大学林学院,北京100083【正文语种】中文【中图分类】S797.27【相关文献】1.基于非线性混合模型的杉木标准树高曲线1) [J], 董云飞;孙玉军;许昊;梅光义2.基于线性混合效应模型的杉木树高-胸径模型 [J], 许崇华;崔珺;黄兴召;余鑫;徐小牛3.基于混合效应模型及EBLUP预测杉木树高生长过程 [J], 王明初;孙玉军;4.基于混合效应模型及EBLUP预测美国黄松林分优势木树高生长过程 [J], 祖笑锋;倪成才;Gorden Nigh;覃先林5.基于混合效应模型的杉木单木冠幅预测模型 [J], 符利勇;孙华因版权原因,仅展示原文概要,查看原文内容请购买。


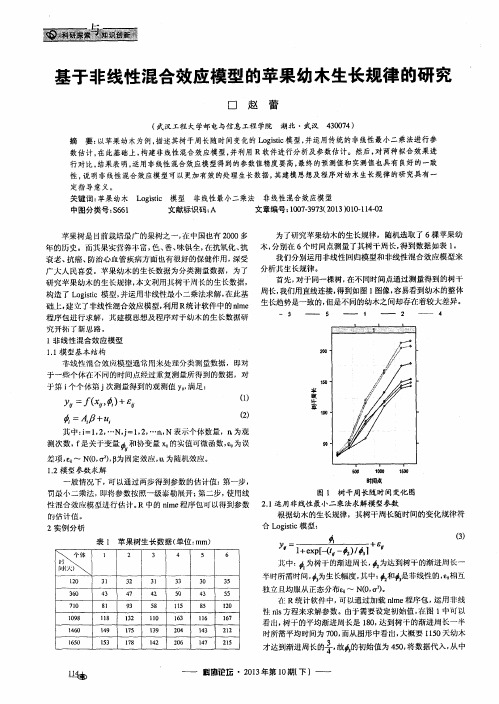


非线性混合效应生长模型的拟合、随机效应预测和应变量预测间对应关系祖笑锋;李秋实;倪成才;覃先林;Nigh Gorden【期刊名称】《林业科学》【年(卷),期】2016(052)010【摘要】Objective]Fitting non-linear mixed effects models (NLME),predicting the random effects parameters,as well as predicting the response variable,often involve a Taylor series expansion for linearization,based upon either the expected value of the random effects or final iterative value. In forestry,however,the linearization bases are not always consistent as they should be,and probably reduced the accuracy of prediction. In this paper,we investigated the tree height growth and discussed the effects of inconsistency among the linearization bases for fitting,predicting random effects the response.[Method]We randomly selected 49 trees for NLME-fitting and 30 trees for validation from 79 dominant trees of ponderosa pine in British Columbia,Canada. The base model was three-parameter Logistic. We used the nlme function in R and the nlmixed procedure in SAS for model fitting,respectively corresponding linearization based upon the expected value and the final iterative value. The IML procedure in SAS was employed for predicting the random effects and the response. Mean squared prediction error (MSPE),mean percentage error (MPE),and mean absolute percentage error ( MAPE) were used asevaluation criteria.[Result]The results showed that inconsistent linearization bases between the random effects and the response significantly decreased the accuracy of the responseprediction.[Conclusion]The linearization bases between the random effects and the response had to be consistent,and enough for obtaining predictions as accurate as possible. The accuracy of prediction was invariant to the linearization base for model-fitting and to either the expected value or the final iterative value,which was used as a linearization base.%【目的】在非线性混合效应模型的拟合、随机效应预测和应变量预测3个环节上,常用一阶泰勒近似法将非线性模型线性化,泰勒近似的基点一般为随机效应参数的数学期望或迭代终值。
⽤R语⾔拟合籽粒⽣长模型⽤R语⾔拟合籽粒⽣长模型简介:⽣物的⽣长特征在多少情况下可以⽤S型曲线进⾏描述,即:起始阶段⽣长慢,然后进⼊⼀个快速增长期,最后⽣长速度再次变慢并逐渐接近⽣长极限。
⾕物籽粒的发育过程也可以⽤S型曲线进⾏描述,⽐如⽟⽶、⽔稻和⼩麦的籽粒⽣长特征⼀般⽤logistic⽅程进⾏描述。
logistic⽅程的特点是其曲线的拐点就是其中点,这样有⼀个好处,就是能够简化数据拟合过程。
但是,在⽣长过程中遭受胁迫时,⽣长曲线的拐点就不是曲线的中点,此时不再适⽤logistic⽅程。
除了logistic⽅程之外,还有两个常⽤⽅程即richards⽅程和gompertz ⽅程。
本⽂⽤⼩麦籽粒的⽣长数据讲解如何⽤R语⾔进⾏⾮线性模型的拟合,并⽐较3个⽣长曲线的优劣。
籽粒⽣长过程主要是籽粒内含物的填充过程,因此也称为籽粒灌浆。
在作物开花以后,籽粒开始形成粒重逐渐增加。
粒重与时间的关系不是线性关系,因此,⽤数学公式描述粒重随时间的变化动态也称为⾮线性模型拟合。
拟合的⽬的在于⽤严谨的数学公式描述粒重数据的变化规律,并给出公式的描述误差。
有了这个公式,就可以在籽粒⽣长结束之前预测籽粒的最终重量。
观测、拟合与预测是研究过程的3个阶段。
⾮线性模型分为简单⾮线性模型、⼀般⾮线性模型和⾮线性混合模型。
⾮线性混合模型⽤群体效应、群体和个体的差异描述⼀组试验数据,结构更加紧凑,模型参数更少,拟合过程也更加复杂。
所以,本⽂先介绍简单的⾮线性模型为⾮线性混合模型奠定基础。
关键词:R语⾔,籽粒⽣长,籽粒灌浆,⾮线性模型,模型拟合,⽣长模拟以⼩麦籽粒⽣长为例,在花后测量籽粒的⼲重,以粒重为因变量(y),以时间为⾃变量(t),研究粒重与时间的关系。
数据如下:表中daa为开花后天数,grainWeight为籽粒⼲重,单位是mg。
3个⽅程分别为:logistic = function(t, k, a, b){k/(1 + exp(a - b*t))} 其中K为最⼤粒质量,t为花后时间,a、b为待定系数。
随机效应模型与混合效应模型随机效应模型(Random Effects Model)和混合效应模型(Mixed Effects Model)是在统计学中常用的两种分析方法。
它们在研究中可以用来解决数据中存在的个体差异和组间差异的问题,从而得到更准确的结果。
一、随机效应模型随机效应模型适用于数据具有分层结构的情况。
它假设个体之间的差异是随机的,并且个体之间的差异可以用方差来表示。
在随机效应模型中,我们关心的是不同个体之间的差异以及它们对结果的影响。
随机效应模型的基本形式为:Yij = μ + αi + εij其中,Yij表示第i个个体在第j个时间点或者第j个条件下的观测值;μ表示总体均值;αi表示第i个个体的随机效应,它们之间相互独立且符合某种分布;εij表示个体内的随机误差。
随机效应模型通过估计不同个体的随机效应来刻画个体之间的差异,并且可以通过随机效应的显著性检验来判断个体之间的差异是否存在。
二、混合效应模型混合效应模型结合了固定效应和随机效应两个模型的优点,适用于数据同时具有组间差异和个体差异的情况。
在混合效应模型中,我们关心的是个体之间的差异以及不同组之间的差异,并且它们对结果的影响。
混合效应模型的基本形式为:Yij = μ + αi + βj + εij其中,Yij表示第i个个体在第j个组下的观测值;μ表示总体均值;αi表示个体的随机效应;βj表示组的固定效应;εij表示个体内的随机误差。
通过混合效应模型,我们可以同时估计个体的随机效应和组的固定效应,并且可以通过对这些效应的显著性检验来判断个体和组之间的差异是否存在。
三、随机效应模型和混合效应模型的比较随机效应模型和混合效应模型在数据分析中都具有重要作用,但在不同的研究场景下选择合适的模型是非常重要的。
1. 数据结构:如果数据存在明显的分层结构,即个体之间的差异比组之间的差异更为重要,那么随机效应模型是更好的选择。
2. 因变量类型:如果因变量是连续型变量,那么随机效应模型和混合效应模型都可以使用;如果因变量是二分类或多分类变量,那么混合效应模型是更好的选择。
带混杂项的线性模型研究及其应用导言线性模型是统计学中一种非常重要的分析方法,广泛应用于自然科学、社会科学及工程学等领域。
然而,实际应用中会存在各种混杂项的干扰,如测量误差、随机效应等,影响了线性模型的精度和可靠性。
因此,如何应对混杂项,提高线性模型的预测准确率成为了一个重要课题。
本文将介绍带混杂项的线性模型研究及其应用,包括混合效应模型、随机系数模型和广义线性混合模型等,以及这些模型的实际应用案例。
混合效应模型混合效应模型是解决混杂项问题的一种常见方法。
该模型将影响自变量与随机误差之外的影响(如个体差异、区域差异等)纳入考虑,并将这些影响建模为一个或多个随机效应。
随机效应通常是指个体间差异和/或个体内的变异,其中个体间差异指的是不同个体之间的差异,如物种差异、品种差异等;个体内的变异是指同一物种、品种或群体中,由于环境等原因而导致的差异。
在混合效应模型中,假设随机效应服从特定的概率分布,如正态分布或Gamma分布。
这样,模型既可以捕捉到自变量对因变量的影响,又可以考虑到其他因素的影响,从而提高了模型预测的准确性和可靠性。
随机系数模型随机系数模型是混合效应模型的一种扩展形式。
该模型认为,自变量系数(即回归系数)是随机变量,可以包括在随机效应中。
随机系数模型的建立需要对各个随机效应的分布进行假设,并使用贝叶斯推断的方法进行参数估计。
需要注意的是,随机系数的估计通常比固定系数更加复杂,需要使用高级的统计计算方法来进行求解。
广义线性混合模型广义线性混合模型是将混合效应模型和广义线性模型相结合的一种方法。
该模型可以在考虑数据的随机变异和随机效应的基础上,建立自变量与因变量之间的非线性关系。
广义线性混合模型包括广义线性模型和混合效应模型两个部分。
其中,广义线性模型可以包括线性回归、逻辑回归、Poisson回归、Probit回归等多种形式,而混合效应模型则可以包括多种随机效应。
广义线性混合模型中的随机效应可以包括不同的层次,如个体层面、区域层面、群体层面等,从而可以解决各种随机效应的问题。
统计学中的混合效应模型统计学中的混合效应模型是一种重要的统计工具,广泛应用于各个领域的数据分析中。
它能够解决多层级数据结构的建模问题,同时考虑了个体变异和群体变异之间的关系。
本文将对混合效应模型的概念、应用以及建模步骤进行详细介绍。
一、混合效应模型的概念与作用混合效应模型是一种扩展的线性回归模型,它允许在回归模型中引入随机效应,以考虑数据层级结构的影响。
在混合效应模型中,个体之间的变异归因于个体的特征,而群体之间的变异则归因于群体的特征。
通过引入个体和群体的随机效应,混合效应模型能够更准确地描述和解释数据。
混合效应模型在许多领域中都有广泛应用。
例如,在教育研究中,研究者常常需要考虑学生之间的个体差异和学校之间的群体差异对学生成绩的影响。
混合效应模型可以同时考虑学生和学校的特征,提供更有效的分析结果。
此外,在医学研究、社会科学、经济学等领域,混合效应模型也都具有广泛的应用。
二、混合效应模型的建模步骤1. 确定数据结构:首先需要确定数据的层级结构,即哪些层级上存在个体变异和群体变异。
例如,在教育研究中,学生可以看作是第一层级,学校可以看作是第二层级。
2. 设计随机效应:根据确定的数据结构,设计合适的随机效应结构。
随机效应可以考虑不同层级的个体和群体特征对结果的影响。
3. 建立固定效应模型:在混合效应模型中,除了随机效应外,还需要考虑自变量和结果之间的关系。
建立合适的固定效应模型是混合效应模型中的关键一步。
4. 估计参数与模型选择:使用合适的参数估计方法,对模型进行参数估计,并进行模型选择。
常用的参数估计方法包括最大似然估计、贝叶斯估计等。
5. 模型诊断与解释:对估计得到的混合效应模型进行诊断,评估模型的拟合优度,并解释模型中的固定效应和随机效应。
三、混合效应模型的应用实例以一项教育研究为例,假设研究者对不同学校的学生成绩进行调查。
首先,确定数据结构,学生为第一层级,学校为第二层级。
然后,设计随机效应结构,考虑学生和学校的特征对学生成绩的影响。