统计学第八章课后题及答案解析
- 格式:doc
- 大小:66.00 KB
- 文档页数:6

167第八章 对比分析与统计指数思考与练习4. 指出下列哪一个数量加权算术平均数指数,恒等于综合指数形式的拉 氏数量指标指数(C )。
C. d.6. 编制数量指标综合指数所采用的同度量因素是( a ) a .质量指标b .数量指标C •综合指标d •相对指标7. 空间价格指数一般可以采用( C )指数形式来编制。
a .拉氏指数 b.帕氏指数 C.马埃公式d.平均指数二、问答题:1.报告期与基期相比,某城一、选择题:1.某企业计划要求本月每万元产值能源消耗率指标比去年同期下降 实际降低了2.5%,则该项计划的计划完成百分比为( d )。
d. 102.6%5%a. 50.0%b. 97.4%c. 97.6% 2. 下列指标中属于强度相对指标的是(a..产值利润率 C.恩格尔系数3. 编制综合指数时, a .指数化指标 b. b. d.应固定的因素是( b基尼系数 人均消费支出C )。
个体指数c.同度量因素 d.被测定的因素S k q q 。
P 1 」2k q q 1 p 1S k q q o P 0 」 S k q q t p o;b. --------- ; c. -------- ; d. -------- a .S q 。
P 1送 q i P i S q o P o Z q i P o 5.之所以称为同度量因素,是因为:它可使得不同度量单位的现象总体转化为数量上可以加总; 客观上体现它在实际经济现象或过程中的份额 ;是我们所要测定的那个因素; 它必须固定在相同的时期。
(a )。
a .市居民消费价格指数为110%,居民可支配收入增加了20 %,试问居民的实际收入水平提高了多少?解:(1+20% /110%-100%=109.10%-100%=9.10%2.某公司报告期能源消耗总额为28.8万元,与去年同期相比,所耗能源的价格平均上升了20%那么按去年同期的能源价格计算,该公司报告期能源消耗总额应为多少?解:28.8 -(1+20%)=24 万元3.编制综合指数时,同度量因素的选择与指数化指标有什么关系?同度量因素为什么又称为权数?它与平均指数中的权数是否一致?解:(略)4.结构影响指数的数值越小,是否说明总体结构的变动程度越小?一般说来,当总体结构发生什么样的变动时,结构影响指数就会大于1。

统计学复习笔记之南宫帮珍创作第七章第八章参数估计一、思考题1.解释估计量和估计值在参数估计中, 用来估计总体参数的统计量称为估计量.估计量也是随机变量.如样本均值, 样本比例、样本方差等.根据一个具体的样本计算出来的估计量的数值称为估计值. 2.简述评价估计量好坏的标准(1)无偏性:是指估计量抽样分布的期望值即是被估计的总体参数.(2)有效性:是指估计量的方差尽可能小.对同一总体参数的两个无偏估计量, 有更小方差的估计量更有效.(3)一致性:是指随着样本量的增年夜, 点估计量的值越来越接近被估总体的参数.3.怎样理解置信区间在区间估计中, 由样本统计量所构造的总体参数的估计区间称为置信区间.置信区间的论述是由区间和置信度两部份组成.有些新闻媒体报道一些调查结果只给出百分比和误差(即置信区间), 其实不说明置信度, 也不给出被调查的人数, 这是不负责的暗示.因为降低置信度可以使置信区间变窄(显得“精确”),有误导读者之嫌.在公布调查结果时给出被调查人数是负责任的暗示.这样则可以由此推算出置信度(由后面给出的公式), 反之亦然.4.解释95%的置信区间的含义是什么置信区间95%仅仅描述用来构造该区间上下界的统计量(是随机的)覆盖总体参数的概率.也就是说, 无穷次重复抽样所获得的所有区间中有95%(的区间)包括参数.不要认为由某一样本数据获得总体参数的某一个95%置信区间, 就以为该区间以0.95的概率覆盖总体参数.5.简述样本量与置信水平、总体方差、估计误差的关系.1.估计总体均值时样本量n为其中:2.样本量n与置信水平1-α、总体方差、估计误差E之间的关系为▪与置信水平成正比, 在其他条件不变的情况下, 置信水平越年夜, 所需要的样本量越年夜;▪与总体方差成正比, 总体的不同越年夜, 所要求的样本量也越年夜;▪与与总体方差成正比, 样本量与估计误差的平方成反比, 即可以接受的估计误差的平方越年夜, 所需的样本量越小.二、练习题1.从一个标准差为5的总体中采纳重复抽样方法抽出一个样本量为40的样本, 样本均值为25.1)样本均值的抽样标准差即是几多?2)在95%的置信水平下, 估计误差是几多?解: 1)已知σ = 5, n = 40, = 25∵∴2)已知∵2.某快餐店想要估计每位顾客午餐的平均花费金额, 在为期3周的时间里选取49名顾客组成了一个简单随机样本.1)假定总体标准差为15元, 求样本均值的抽样标准误差.2)在95%的置信水平下, 求估计误差.3)如果样本均值为120元, 求总体均值µ的95%的置信区间.解:1)已知σ = 15, n = 49∵∴2)已知∵3)已知 = 120∵ 置信区间为±E3.从一个总体中随机抽取n =100的随机样本, 获得 =104560, 假定总体标准差σ = 85414, 试构建总体均值µ的95%的置信区间.解:已知n =100, =104560, σ = 85414, 1-a=95% ,由于是正态总体, 且总体标准差已知.总体均值m在1-a置信水平下的置信区间为104560 ± 1.96×85414÷√1004.从总体中抽取一个n =100的简单随机样本, 获得 =81, s=12.要求:1)构建µ的90%的置信区间.2)构建µ的95%的置信区间.3)构建µ的99%的置信区间.解:由于是正态总体, 但总体标准差未知.总体均值m在1-a置信水平下的置信区间公式为81±×12÷√100 = 81±×????????4)= 25, σ = 3.5, n =60, 置信水平为95%5)=119, s =23.89, n =75, 置信水平为98%6)=3.149, s =0.974, n =32, 置信水平为90%解:∵∴ 1) 1-a=95% ,其置信区间为:25±1.96×3.5÷√602) 1-a=98% , 则a=0.02, a/2=0.01, 1-a/2=0.99,查标准正态分布表,可知:其置信区间为: 119±2.33×23.89÷√753) 1-a=90%,其置信区间为:3.149±1.65×0.974÷√325.利用下面的信息, 构建总体均值µ的置信区间:1)总体服从正态分布, 且已知σ = 500, n = 15, =8900, 置信水平为95%.解:N=15, 为小样本正态分布, 但σ已知.则1-a=95%, .其置信区间公式为∴置信区间为:8900±1.96×500÷√15=(8646.7 , 9153.2)2)总体不服从正态分布, 且已知σ = 500, n = 35, =8900,置信水平为95%.解:为年夜样本总体非正态分布, 但σ已知.则1-a=95%, .其置信区间公式为∴置信区间为:8900±1.96×500÷√35=(8733.9 9066.1)3)总体不服从正态分布, σ未知, n = 35, =8900, s =500, 置信水平为90%.解:为年夜样本总体非正态分布, 且σ未知, 1-a=90%,1.65.其置信区间为:8900±1.65×500÷√35=(8761 9039)4)总体不服从正态分布, σ未知, n = 35, =8900, s =500, 置信水平为99%.解:为年夜样本总体非正态分布, 且σ未知, 1-a=99%,2.58.其置信区间为:8900±2.58×500÷√35=(8681.9 9118.1)6.某年夜学为了解学生每天上网的时间, 在全校7500名学生中采用重复抽样方法随机抽取36人, 调查他们每天上网的时间, 获得下面的数据(单元:小时)(略).求该校年夜学生平均上网时间的置信区间, 置信水平分别为90%解:先求样本均值:= 3.32再求样本标准差:置信区间公式:7.从一个正态总体中随机抽取样本量为8的样本, 各样本值分别为:10, 8, 12, 15, 6, 13, 5, 11.求总体均值µ的95%置信区间.解:本题为一个小样本正态分布, σ未知.先求样本均值:= 80÷8=10再求样本标准差:于是 , 的置信水平为的置信区间是,已知, n = 8, 则,α/2=0.025, 查自由度为n-1 = 7的分布表得临界值所以, 置信区间为:10±2.45×3.4641÷√78.某居民小区为研究职工上班从家里到单元的距离, 抽取了由16个人组成的一个随机样本, 他们到单元的距离分别是:10, 3,14, 8, 6, 9, 12, 11, 7, 5, 10, 15, 9, 16, 13, 2.假设总体服从正态分布, 求职工上班从家里到单元平均距离的95%的置信区间.解:小样本正态分布, σ未知.已知, n = 16, , 则, α/2=0.025, 查自由度为n-1 = 15的分布表得临界值样本均值再求样本标准差:于是 , 的置信水平为的置信区间是?? ??????????????????±??×??÷√??9.从一批零件是随机抽取????个, 测得其平均长度是??????, 标准差是????.1)求确定该种零件平均长度的????August的置信区间.2)在上面估计中, 你使用了统计中的哪一个重要定理?请解释.解:)??这是一个年夜样天职布.已知N??????, ??????????????, S????????, α?? ????, .其置信区间为:149.5±1.96×1.93÷√36 2)中心极限定理论证:如果总体变量存在有限的平均数和方差, 那么, 不论这个总体的分布如何, 随着样本容量的增加, 样本均值的分布便趋近正态分布.在现实生活中, 一个随机变量服从正态分布未必很多, 可是多个随机变量和的分布趋于正态分布则是普遍存在的.样本均值也是一种随机变量和的分布, 因此在样本容量充沛年夜的条件下, 样本均值也趋近于正态分布, 这为抽样误差的概率估计理论提供了理论基础.10.某企业生产的袋装食品采纳自动打包机包装, 每袋标准重量为100克, 现从某天生产的一批产物中按重复抽样随机抽取50包进行检查, 测得每包重量如下:(略)已知食品包重服从正态分布, 要求:1)确定该种食品平均重量的95%的置信区间.2)如果规定食品重量低于100克属于分歧格, 确定该批食品合格率的95%的置信区间.解:1)本题为一个年夜样本正态分布, σ未知.已知N=50, µ=100, 1-α=0.95, .① 每组组中值分别为97、99、101、103、105, 即此50包样本平均值= (97+99+101+103+105)/5 = 101② 样本标准差为:③其置信区间为:101±1.96×1.666÷√502)∵ 分歧格包数(<100克)为2+3=5包, 5/50 = 10%(分歧格率), 即P = 90%.∴ 该批食品合格率的95%置信区间为:11.假设总体服从正态分布, 利用下面的数据构建总体均值μ的99%的置信区间.(略)解:样本均值样本标准差:尽管总体服从正态分布, 可是样本n=25是小样本, 且总体标准差未知, 应该用T统计量估计.1-α=0.99, 则α=0.01, α/2=0.005, 查自由度为n-1 =24的分布表得临界值的置信水平为的置信区间是,12.一家研究机构想估计在网络公司工作的员工每周加班的平均时间, 为此随机抽取了18个员工, 获得他们每周加班的时间数据如下(单元:小时):(略)假定员工每周加班的时间服从正态分布, 估计网络公司员工平均每周加班时间的90%的置信区间.解:① N = 18 < 30, 为小样本正态分布, σ未知.②样本均值样本标准差:=③ 1-α= 90%, α= 0.1, α/2= 0.05, 则查自由度为n-1 = 17的分布表得临界值④的置信水平为的置信区间是,13.利用下面的样本数据构建总体比例丌的置信区间:1)n =44, p = 0.51 , 置信水平为99%2)n =300, p = 0.82 , 置信水平为95%3)n =1150, p = 0.48, 置信水平为90%解: 1) 1-α= 99%, α= 0.01, α/2= 0.005, 1-α/2= 0.995, 查标准正态分布表, 则2)1-a=95%,3)1-a=90%,分别代入14.在一项家电市场调查中, 随机抽取了200个居民户, 调查他们是否拥有某一品牌的电视机, 其中拥有该品牌电视机的家庭占23%.求总体比例的置信区间, 置信水平分别为90%和95%.解: 1)置信水平90%, 1-a=90%, 1.65, N = 200, P = 23%.代入2)置信水平95%, 1-a=95%, , N = 200, P = 23%.代入15.一位银行的管理人员想估计每位顾客在该银行的月平均存款额.他假设所有顾客月存款额的标准差为1000元, 要求的估计误差在200元以内, 置信水平为99%.应选取多年夜的样本?解:已知 1-α = 99%, 则 2.58.E = 200, σ= 1000元.则N = (²×σ²)÷E²= (2.58²×1000²)÷200²≈167(得数应该是166.41, 不论小数后是几多, 都向上进位取整, 因此至少是167人)16.要估计总体比例丌, 计算下列条件下所需的样本量.1)E=0.02, 丌=0.40, 置信水平96%2)E=0.04, 丌未知, 置信水平95%3)E=0.05, 丌=0.55, 置信水平90%解: 1)已知 1-α = 96%, α/2 =0.02 , 则N = {²×丌(1-丌)}÷E²=2.06²×0.4×0.6÷0.02²≈25472)已知 1-α = 95%, α/2 =0.025 , 则丌未知,则取使丌(1-丌)最年夜时的0.5.N = {²×丌(1-丌)}÷E²=1.96²×0.5×0.5÷0.04²≈601 3)置信水平90%, 1-a=90%, 1.65,N = {²×丌(1-丌)}÷E²=1.65²×0.55×0.45÷0.05²≈27017.某居民小区共有居民500户, 小区管理者准备采纳一项新的供水设施, 想了解居民是否赞成.采用重复抽样方法随机抽取了50户, 其中有32户赞同, 18户反对.1)求总体中赞成该项改革的户数比例的置信区间(α=0.05)2)如果小区管理者预计赞成的比例能到达80%, 估计误差不超越10%, 应抽取几多户进行调查(α=0.05)解:1)已知N=50, P=32/50=0.64, α=0.05, α/2 =0.025 , 则置信区间:P±2)已知丌=0.8 , E = 0.1, α=0.05, α/2 =0.025 , 则N= ²丌(1-丌)/E²= 1.96²×0.8×0.2÷0.1²≈6218.根据下面的样本结果, 计算总体标准差σ的90%的置信区间:1)=21, S=2, N=502)=1.3, S=0.02, N=153)=167, S=31, N=22解:1)年夜样本, σ未知, 置信水平90%, 1-a=90%,21±1.65×2÷√502)小样本, σ未知, 置信水平90%, 1-a=90%, 则查自由度为n-1 = 14的分布表得临界值, = 1.3±1.761×0.02÷√153) 年夜样本, σ未知, 置信水平90%, 1-a=90%,167±1.65×31÷√2219.题目(略)1)构建第一种排队方式等候时间标准差的95%的置信区间2)构建第二种排队方式等候时间标准差的95%的置信区间3)根据1)和2)的结果, 你认为哪种排队方式更好?解:本题为小样本正态分布, σ未知, 应用公式,置信水平95%, 1-a=95%, 则查自由度为n-1 = 9的分布表得临界值1)= 7.15,其置信区间为7.15±2.31×0.48÷√102)= √0/9 = 0其置信区间为7.15±04)第二种排队方式更好.(19题是对总体方差的估计, 应该用卡方统计量进行估计, 20题是对两个总体参数的估计, 这二种类型老师未讲, 不是本次考试的内容, 不能用Z统计量像估计总体均值和比例那样去估计, 具体内容见书上P188――P194)第九章假设检验一、思考题1.假设检验和参数估计有什么相同点和分歧点?解:参数估计与假设检验是统计推断的两个组成部份.相同点:它们都是利用样本对总体进行某种推断.分歧点:推断的角度分歧.参数估计讨论的是用样本统计量估计总体参数的方法, 总体参数μ在估计前是未知的.而在假设检验中, 则是先对μ的值提出一个假设, 然后利用样本信息去检验这个假设是否成立.2.什么是假设检验中的显著性水平?统计显著是什么意思?解:显著性水平用α暗示, 在假设检验中, 它的含义是当原假设正确时却被拒绝的概率或风险, 即假设检验中犯弃真毛病的概率.它是由人们根据检验的要求确定的.(我理解的统计学意义, 统计显著是统计上专用的判定标准, 指在一定的概率原则下, 可以供认一种趋势或者合理性到达的水平, 到达为统计上水平显著, 达不到为统计上水平不显著)3.什么是假设检验中的两类毛病?解:弃真毛病(α毛病):当原假设为真时拒绝原假设, 所犯的毛病成为第I类毛病, 又称为弃真毛病.犯第I类毛病的概率常记作α.取伪毛病(β毛病):当原假设为假时没有拒绝原假设, 所犯的毛病称为第II类毛病, 又称取伪毛病.犯第II类毛病概率常记作β.发生第I类毛病的概率也常被用于检验结论的可靠性怀抱.假设检验中犯第I类毛病的概率被称为显著性水平, 记作α.4.两类毛病之间存在什么样的数量关系?在样本容量n一定的情况下, 假设检验不能同时做到犯α和β两类毛病的概率都很小.若减小α毛病, 就会增年夜犯β毛病的机会;若减小β毛病, 也会增年夜犯α毛病的机会.要使α和β同时变小只有增年夜样本容量.但样本容量增加要受人力、经费、时间等很多因素的限制, 无限制增加样本容量就会使抽样调查失去意义.因此假设检验需要慎重考虑对两类毛病进行控制的问题.5.解释假设检验中的P值.解:如果原假设为真, 所获得的样本结果会像实际观测结果那么极端或更极真个概率, 称为P值.也称为观察到的显著性水平.P值是反映实际观测到的数据与原假设H0之间纷歧致水平的一个概率值.P值越小, 说明实际观测到的数据与H0之间纷歧致水平就越年夜.6.显著性水平与P值有何区别?解:α(显著性水平)是一个判断的标准(当原假设为真, 却被拒绝的概率), 而P是实际统计量对应分位点的概率值(当原假设为真时, 所获得的样本观察结果或更极端结果呈现的概率).可以通过α计算置信区间, 然后与统计量进行比力判断, 也可以通过统计量计算对应的p值, 然后与α值比力判断.7.假设检验依据的基来源根基理是什么?解:假设检验利用的是小概率原理, 小概率原理是指发生概率很小的随机事件在一次试验中是几乎不成能发生的.根据这一原理, 可以先假设总体参数的某项取值为真, 也就是假设其发生的可能性很年夜, 然后抽取一个样本进行观察, 如果样本信息显示呈现了与事先假设相反的结果且与原假设分歧很年夜, 则说明原来假定的小概率事件在一次实验中发生了, 这是一个违背小概率原理的分歧理现象, 因此有理由怀疑和拒绝原假设;否则不能拒绝原假设.8. 你认为在单侧检验中原假设和备择假设的方向应该如何确定?解: 假设问题有两种情况, 一种是所考察的数值越年夜越好(左单侧检验或下限检验), 临界值和拒绝域均在左侧;另一种是数值越小越好(右单侧检验或上限检验), 临界值和拒绝域均在右侧.二、 练习题1. 已知某炼铁厂的含碳量服从正态分布N (4.55, 0.108²), 现在测定了9炉铁水, 其平均含碳量为4.484.如果估计方差没有变动, 可否认为现在生产的铁水平均含碳量为4.55(α=0.05)? 解: 已知μ0=4.55, σ²=0.108², N=9, =4.484,这里采纳双侧检验, 小样本, σ已知, 使用Z 统计.假定现在生产的铁水平均含碳量与以前无显著不同.则, α=0.05, α/2 =0.025 , 查表得临界值为计算检验统计量: = (4.484-4.55)/(0.108/√9) 决策:∵Z 值落入接受域, ∴在=0.05的显著性水平上接受H0. nx Z / σ - =μ0结论:有证据标明现在生产的铁水平均含碳量与以前没有显著不同, 可以认为现在生产的铁水平均含碳量为4.55.2. 一种元件, 要求其使用寿命不得低于700小时.现从一批这种元件中随机抽取36件, 测得其平均寿命为680小时.已知该元件寿命服从正态分布, σ=60小时, 试在显著性水平0.05下确定这批元件是否合格.解: 已知N=36, σ=60, =680, μ0=700这里是年夜样本, σ已知, 左侧检验, 采纳Z 统计量计算. 提出假设:假定使用寿命平均不低于700小时H0:μ≥700H1: μ < 700= 0.05, 左检验临界值为负, 查得临界值: -Z0.05=-1.645计算检验统计量: = (680-700)/(60/√36) = -2决策:∵Z 值落入拒绝域, ∴在=0.05的显著性水平上拒绝H0, 接受H1结论:有证据标明这批灯胆的使用寿命低于700小时, 为分歧格产物.3. 某地域小麦的一般生产水平为亩产250公斤, 其标准差是30公斤.现用一种化肥进行试验, 从25个小区抽样, 平均产量为n x Z / σ - = μ0270公斤.这种化肥是否使小麦明显增产(α=0.05)?解:已知μ0 =250, σ = 30, N=25, =270提出假设:假定这种化肥没使小麦明显增产.即 H0:μ≤250H1: μ>250计算统计量:Z = (结论:Z统计量落入拒绝域, 在α =0.05的显著性水平上, 拒绝H0, 接受H1.决策:有证据标明, 这种化肥可以使小麦明显增产.4.糖厂用自动打包机打包, 每包标准重量是100千克.每天开工后需要检验一次打包机工作是否正常.某日开工后测得9包重量(单元:千克)如下:(略)已知包重服从正态分布, 试检验该日打包机工作是否正常.(α =0.05)= 99.98提出假设, 假设打包机工作正常:即 H0:μ= 100H1: μ≠100计算统计量:决策:有证据标明这天的打包机工作正常.5. 某种年夜量生产的袋装食品, 按规定不得少于250克.今从一批该食品中任意抽取50袋, 发现有6袋低于250克.若规定不符合标准的比例超越5%就不得出厂, 问该批食品能否出厂(=0.05)?H0:丌≤5%H1:丌>5%(因为没有找到丌暗示的公式, 这里用P0暗示丌0)结论:因为Z 值落入拒绝域, 所以在=0.05的显著性水平上, 拒绝H0, 而接受H1.决策:有证据标明该批食品合格率不符合标准, 不能出厂. 6. 某厂家在广告中声称, 该厂生产的汽车轮胎在正常行驶条件下超越目前的平均水平25000公里.对一个由15个轮胎组成的随机样本做了试验, 获得样本均值和标准差分别为27000公里和5000公里.假定轮胎寿命服从正态分布, 问该厂家的广告是否真- = ns x t μ0实(=0.05)?解:N=15,H0:μ0 ≤25000H1:μ >25000结论:因为t 值落入接受域, 所以接受H0, 拒绝H1.决策:有证据标明, 该厂家生产的轮胎在正常行驶条件下使用寿命与目前平均水平25000公里无显著性不同, 该厂家广告不真实. 7. 某种电子元件的寿命x (单元:小时)服从正态分布.现测得16只元件的寿命如下:(略).问是否有理由认为元件的平均寿命显著地年夜于225小时(=0.05)? 解:= 241.5,H :μ??> ??创作时间:二零二一年六月三十日 - = ns x t - = ns x tμ0 μ0。


第八章 方差分析习题答案一、单选1.D ;2.B ;3.A ;4.C ;5.C ;6.C ;7.C ;8.A ;9.B ;10.A二、多选1.ACE ;2.ABD ;3.BE ;4.AD ;5.BCE6.ABCD ;7.ABCDE ;8.ABCE ;9.ACD ;10.ABD三、计算分析题1、运用EXCEL 进行单因素方差分析,有:方差分析:单因素方差分析SUMMARY组 观测数 求和 平均 方差列 1 5 1.21 0.242 2.45E-05列 2 5 1.38 0.276 0.00226列 3 5 1.31 0.262 1.35E-05方差分析差异源 SS df MS F P-value F crit 组间 0.00292 2 0.00146 1.906005 0.191058 3.885294 组内 0.009192 12 0.000766总计 0.012112 14由于P 值=1.906005>05.0=α,不拒绝原假设,没有证据表明3个总体的均值之间有显著差异。
(或用F 值判断,有同样结论)2、运用EXCEL 进行单因素方差分析,有:方差分析:单因素方差分析SUMMARY组 观测数 求和 平均 方差列 1 5 222 44.4 28.3列 2 5 150 30 10列 3 5 213 42.6 15.8方差分析差异源 SS df MS F P-value F crit 组间 615.6 2 307.8 17.06839 0.00031 3.885294 组内 216.4 12 18.03333总计 832 14由于由于P 值=0.00031<05.0=α,拒绝原假设,表明3个总体的均值之间有显著差异。
(或用F 值判断,有同样结论)进一步用LSD 方法见教材P2063、(1)按行依次为:420、2、1.478(第一行);27、142.07(第二行);4256(第三行)。
(2)由于P 值=0.245946>05.0=α,不拒绝原假设,没有证据表明3种方法组装产品数量有显著差异。
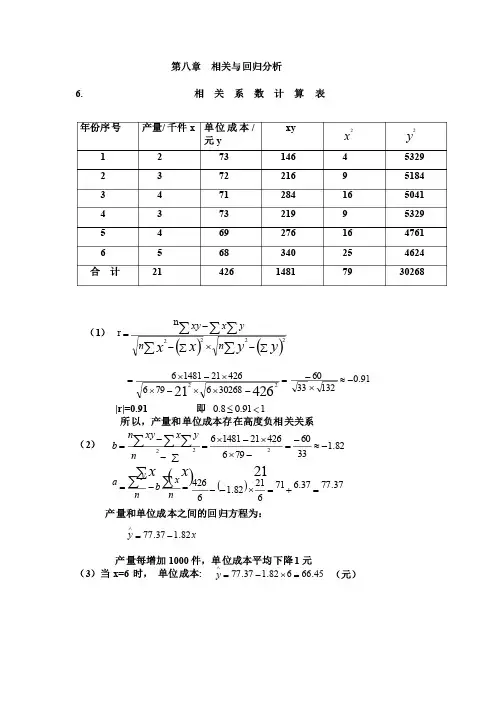
第八章 相关与回归分析 6. 相 关 系 数 计 算 表 (1) ()()åååååå-´å--=y yx x n n yx xy 2222nr 91.0132336030268679642621148164262122-»´-=-´´-´´-´= |r|=0.91 即 191.08.0<£ 所以,产量和单位成本存在高度负相关关系(2) ()82.133********211481621222-»-=-´´-´=å--=ååååx x n y x xy n b =-=åånx b ny a ()37.7737.67162182.16426=+=´-- 产量和单位成本之间的回归方程为: x y 82.137.77-=Ù 产量每增加1000件,单位成本平均下降1元 (3)当x=6 时, 单位成本: 45.66682.137.77=´-=Ùy (元) 年份序号 产量/千件x 单位成本/元y xy x 2 y 2 1 2 73 146 4 5329 2 3 72 216 9 5184 3 4 71 284 16 5041 4 3 73 219 9 5329 5 4 69 276 16 4761 6 5 68 340 25 4624 合 计 21 426 1481 79 30268 7. 相 关 系 数 计 算 表 序号 汽车使用年限/年x 年维修费用/元y xy x 2 y 2 1 2 400 800 4 160000 2 2 540 1080 4 291600 3 3 520 1560 9 270400 4 4 640 2560 16 409600 5 4 740 2960 16 547600 65 600 3000 25 360000 7 5 800 4000 25 640000 86 700 4200 36 490000 9 6 760 4560 36 577600 10 6 900 5400 36 810000 11 8 840 6720 64 705600 12 9 1080 9720 81 1166400 合 计 608520465603526428800()()åååååå-´å--=y yx x n n yx xy 2222n r=89.045552006244752064288001235212852060465601285206022»´=-´´-´´-´|r|=0.89 即 189.08.0<£所以,汽车使用年限与其维修费用间存在高度正相关关系(2) ()15.766244752035212852060465601260222==-´´-´=å--=ååååxx n y x xy n b =-=åån x b n y a 25.32975.380710126015.76128520=-=´- 汽车使用年限与其维修费用的回归方程为: x y 15.7625.329+=Ù(3) 当x=15时, 维修费用为: 5.14711515.7625.329=´+=Ùy8. (1) 相 关 系 数 计 算 表 序号 母亲身高/厘米x 女儿身高/厘米y xy x 2y 21 158 159 25122 24964 25281 2 159 160 25440 25281 256003 160 160 25600 25600 256004 161 163 26243 25921 265695 161 159 25599 25921 252816 155 154 23870 24025 237167 162 159 25758 26244 25281 8 157 158 24806 24649 24964 9 162 160 25920 26244 25600 10 150 157 23550 22500 24649 合计1585 1589251908251349252541()()åååååå-´å--=yy x x n n y x xy 2222nr=158915852225254110251349101589158525190810-´´-´´-´655.0»|r|=0.655 所以,母亲与女儿之间的关系为显著正相关(2) ()41.012655152513491015891585251908101585222»=-´´-´=å--=ååååxx n y x xy n b =-=åånx b n y a 915.93985.649.15810158541.0101589=-=´- 母亲与女儿之间的回归方程为: x y 41.0915.93+=Ù(3) 当x=170时, 女儿的身高为: 615.16317041.0915.93=´+=Ùy 9.(1) 由题知 n=9 å=546x å=260y å=16918xy 343622=åx()92.01114210302343629260546169189546222»=-´´-´=å--=ååååx x n yx xy n b =-=åånx b ny a 92.26954692.09260-=´-银行存款余额的直线回归方程: x y 92.092.26+-=Ù(2) 当x=400时,银行存款余额08.34140092.092.26=´+-=Ùy。

姓名:潘方 学号:1106026 班级:金融一班8.2 解:根据题目的分析,本题采用左单侧检验:已知:μ0=700,x =680,σ=60, n=36,α=0.05则z α=1.645 其过程为: H 0:μ≥700 H 1:μ<700 x z ==-2 因为|z|>|z α|,Z 值位于拒绝域,故拒绝原假设,说明这批产品不合格。
因为2=Z ,且为左单侧检验,则()05.0022750132.0977249868.01=<=-=αP8.4 解:由excel 计算得:x =99.9778 S =1.21221H 0:μ=100 H 1:μ≠100 x t =-0.055 这是一个双侧检验,当α=0.05,自由度n -1=9时,得()29t α=2.262。
因为t <|2t α|,t 值位于接受区域,故接受原假设,说明打包机工作正常。
因为|Z|=0.055,且为双侧检验,由excel 得: P=0.95734>(α=0.05)8.9解:该题样本为,大样本,方差2σ已知、且不等,因此采用z 统计量 已知, 05.0=α、即96.12/=αZ ,811=n , 642=n ,σA=63*63 2σB=57*57 0:211≠-μμH 0:210=-μμH , ()()96.15.0645781630102010702222<≈+--=+---=BB A AB A B A n n x x Z σσμμ 因为|z|<|z α|,Z 值位于接受区域,故接受原假设,两厂生产材料抗压强度相同。
因为5.0=Z ,则()=-⨯=691462461.012P 0.617075078()05.0=>α8.13 解:此题为两个总体比例之差的假设H 0:π1≥π2;H 1:π1<π 2 α=0.05,即z α=1.6451100021==n n ,00945.0110001041==p ,01718.0110001892==pp p d z --=0.009450.017180--=-5 因为|z|>|z α|,Z 值位于拒绝域,故拒绝原假设,说明用阿司匹林可以降低心脏病发生率。

统计指数分析练习题一、填空题1. 是表明社会现象复杂经济总体的数量对比关系的相对数。
2. 指数按其指标的作用不同,可分为 和 。
3.总指数的编制方法,其基本形式有两种:一是 ,二是 。
4. 编制质量指标综合指数,一般是以 为同度量因素,并将其固定在 。
5. 编制数量指标综合指数,一般是以 为同度量因素,并将其固定在 。
二、选择1.设p 表示商品的价格,q 表示商品的销售量,1011q p q p ∑∑说明了( )。
A 在基期销售量条件下,价格综合变动的程度B 在报告期销售量条件下,价格综合变动的程度C 在基期价格水平下,销售量综合变动的程度D 在报告期价格水平下,销售量综合变动的程度2.某市居民以相同的人民币在物价上涨后少购商品15%,则物价指数为( )。
A 17.6% B 85% C 115% D 117.6%3. 某商店报告期与基期相比,商品销售额增长6.5%,商品销售量增长6.5%,则商品价格( )。
A 增长13%B 增长6.5%C 增长1%D 不增不减4.某种产品报告期与基期比较产量增长26%,单位成本下降32%,则生产费用支出总额为基期的( )。
A 166.32%B 85.68%C 185%D 54%5.某商店本年同上年比较,商品销售额没有变化,而各种商品价格上涨了7%,则商品销售量增的百分比为( )。
A -6.54%B –3%C 6.00%D 14.29% 三、判断题1.指数的实质是相对数,它能反映现象的变动和差异程度。
( ) 2.在实际应用中,计算价格指数通常以基期数量指标为同度量因素。
( ) 3.某企业职工人数比去年减少2%,而全员劳动生产率比去年提高5%,则企业总产值增长了7%。
( )4.拉氏价格指数和派氏价格指数计算结果不同,是因为拉氏价格指数主要受报告期商品结构的影响,而派氏价格指数主要受基期商品结构的影响。
( )5.如果各种商品的销售量平均上涨5%,销售价格平均下降5%,则销售额不变。

统计学概论课后答案第章统计指数习题解答 TTA standardization office【TTA 5AB- TTAK 08- TTA 2C】第八章 对比分析与统计指数思考与练习一、选择题:1.某企业计划要求本月每万元产值能源消耗率指标比去年同期下降5%,实际降低了%,则该项计划的计划完成百分比为( d )。
a. %b. %c. %d. %2.下列指标中属于强度相对指标的是( b )。
a..产值利润率b.基尼系数c. 恩格尔系数d.人均消费支出3.编制综合指数时,应固定的因素是(c )。
a .指数化指标 b.个体指数 c.同度量因素 d.被测定的因素4.指出下列哪一个数量加权算术平均数指数,恒等于综合指数形式的拉氏数量指标指数(c )。
a .1010p q p q k q ∑∑;b.1111p q p q k q ∑∑;c.000p q p q k q ∑∑; d.101p q p q k q ∑∑5.之所以称为同度量因素,是因为:(a )。
a. 它可使得不同度量单位的现象总体转化为数量上可以加总;b. 客观上体现它在实际经济现象或过程中的份额;c. 是我们所要测定的那个因素;d. 它必须固定在相同的时期。
6.编制数量指标综合指数所采用的同度量因素是(a ) a . 质量指标 b .数量指标 c .综合指标 d .相对指标7.空间价格指数一般可以采用( c )指数形式来编制。
a .拉氏指数 b.帕氏指数 c.马埃公式 d.平均指数二、问答题:1.报告期与基期相比,某城市居民消费价格指数为110%,居民可支配收入增加了20%,试问居民的实际收入水平提高了多少?解:(1+20%)/110%-100%=%-100%=%2.某公司报告期能源消耗总额为万元,与去年同期相比,所耗能源的价格平均上升了20%,那么按去年同期的能源价格计算,该公司报告期能源消耗总额应为多少?解:÷(1+20%)=24万元3.编制综合指数时,同度量因素的选择与指数化指标有什么关系同度量因素为什么又称为权数它与平均指数中的权数是否一致解:(略)4.结构影响指数的数值越小,是否说明总体结构的变动程度越小?一般说来,当总体结构发生什么样的变动时,结构影响指数就会大于1。

8.1解:建立假设: H0:μ=4.55;H1:μ≠4.55这是双侧检验,并且方差已知,检验的统计量 Z 值为:=-1.833而=1.96>|-1.833|,因此不能拒绝原假设,即可认为现在生产的铁水平均含碳量为 4.558.2解:建立假设: H0:μ≥700;H1:μ<700这是左侧检验,并且方差已知,检验统计量 Z 为:Z==-2而-=-1.645>-2,因此拒绝原假设,即在显著性水平 0.05 下这批元件是不合格的。
8.3解:建立假设: H0:μ≤250;H1:μ>250这是右侧检验,并且方差已知,检验的统计量 Z 值为:Z==3.33 而=1.645<3.33,因此拒绝原假设,即这种化肥使小麦明显增产。
8.4解:建立假设: H0:μ=100;H1:μ≠1009/108.055.4484.4−=Z Z 025.036/60700680−Z 05.025/30250270−Z05.0由样本数据可得: ==99.978S===1.212这是双侧检验,并且方差未知,又是小样本,故采用 t 统计量,检验统计量的值为: t==-0.054而(8)=2.306>|-0.054|,因此不拒绝原假设,即该日打包机工作正常8.5、由题意先建立假设,显然不符合标准的比例越小越好,由于采用的是产品质量抽查,即使总体不合标准的比例没有超过5%,属于合格范围,采用右单侧检验。
P=6/50=12%属于单侧检验,当α=0.05时,有,因此拒绝原假设,即认为该批食品不能出厂n X ni ix∑==195.100....7.983.99+++1)(12−−∑=n x ni i x 8)978.995.100(...978.99-7.98978.99-3.99222−+++)()(9/2122.1100-978.99t025.0%5:%,5:1>≤ππH H o 27.250%)51(%5%5%12=−−−=Z 27.2645.105.0<=Z8.6、由题意建立假设:单侧检验,并且方差未知,n=15,属于小样本,故采用t 统计量,检验统计量的值为:α=0.05,,因此不能拒绝原假设,认为该厂家的广告不真实8.7、建立假设:,由样本数据可以得出,这是单侧检验,并且方差未知,是小样本,因此采用t 检验量,检验统计量的值为25000:,25000:10>≤μμH H 549.115/50002500027000/0=−=−=n s x t μ549.1761.1)14(05.0>=t 225,22510>≤H H 5.24116170485 (2121012801591)=++++++==∑=nxx ni i7.9815)5.241170(....)5.241280()5.241159(12221=−++−+−=−=∑=n xs ni in s x t /μ−=669.016/7.982255.241=−=通过查表可得出,,因此不能拒绝原假设,没有理由认为元件的平均寿命显著地大于225小时。

《统计学概论》第八章课后练习答案一、思考题1.什么是相关系数它与函数关系有什么不同P237- P2382.什么是正相关、负相关、无线性相关试举例说明。
P238- P2393.相关系数r的意义是什么如何根据相关系数来判定变量之间的相关系数P2454.简述等级相关系数的含义及其作用P2505.配合回归直线方程有什么要求回归方程中参数a、b的经济含义是什么P2566.回归系数b与相关系数r之间有何关系P2587.回归分析与相关分析有什么联系与区别P2548.什么是估计标准误差这个指标有什么作用P261【9.估计标准误差与相关系数的关系如何P258-P26410.解释判定系数的意义和作用。
P261二、单项选择题1.从变量之间相互关系的方向来看,相关关系可以分为()。
A.正相关和负相关B.直线关系与曲线关系C.单相关和复相关D.完全相关和不完全相关2.相关分析和回归分析相比较,对变量的要求是不同的。
回归分析中要求()。
A.因变量是随机的,自变量是给定的B.两个变量都是随机的C.两个变量都不是随机的D.以上三个答案都不对3.如果变量x与变量y之间的相关系数为-1,这说明两个变量之间是()。
'A.低度相关关系B.完全相关关系C.高度相关关系D.完全不相关4.初学打字时练习的次数越多,出现错误的量就越少,这里“练习次数”与“错误量”之间的相关关系为()。
A.正相关B.高相关C.负相关D.低相关5.假设两变量呈线性关系,且两变量均为顺序变量,那么表现两变量相关关系时应选用()。
A.简单相关系数r B.等级相关系数r sC.回归系数b D.估计标准误差S yx6.变量之间的相关程度越低,则相关系数的数值()。
A.越大B.越接近0…C.越接近-1 D.越接近17.下列各组中,两个变量之间的相关程度最高的是()。
A.商品销售额和商品销售量的相关系数是0.9B.商品销售额和商品利润率的相关系数是0.84C.产量与单位成本之间的相关系数为-0.94D.商品销售价格与销售量的相关系数为-0.918.相关系数r的取值范围是()。

第八章时间序列分析思考与练习1.举例说明时间序列的含义时间序列是同一现象在不同时间上的相继观察值排列而成的序列,一般包括两个基本要素,反映客观现象特征的数值以及观测值所属的时间。
例如,2000年1月份-2013年12月份的社会消费品零售总额当月值,1978年-2013年的当年GDP不变价增速等,均是时间序列。
2.时间序列分析的目的是什么?根据时间序列数据,进行时间序列分析,较为精确地找出该序列的内在统计特征和发展规律性,尽可能多地从中提取出我们所需要的信息,并对未来进行预测。
3.时间序列分析方法有哪几类?第一、数据图法,采用图形直接观察序列的总体趋势和周期变化以及异常点、升降转折点等;第二、指标法,通过计算一系列核心指标来反映所研究序列的动态特征,核心指标如发展速度、增长速度、平均指标、变异指标等;第三、模型法,对给定的时间序列,根据统计理论和数学方法,建立描述该序列的适应统计模型,并进行预测或控制,比如时间序列分解预测模型、指数平滑法、ARMA模型等。
4.根据影响因素,通常将时间序列分解为哪几种成分?根据时间序列的影响因素,通常将时间序列的构成成分区分为长期趋势、季节变动、循环变动和不规则变动四种。
一个时间序列往往是以下几类变化形式的叠加或耦合。
a. 长期趋势(T)。
长期趋势是指时间序列朝着一定的方向持续上升或下降,或停留在t某一水平上的倾向,它反映了客观事物的主要变化趋势。
例如,随着资金和劳动力的增加,技术的不断进步以及劳动生产率的不断提高,我国的经济不断增长,呈向上发展趋势。
b. 季节变动(S)。
季节变动指一年或更短的时间之内,由于受某种固定周期性因素的t影响而呈现出有规律的周期性波动。
比如,多数商品的销售量随季节交替出现的周期性波动。
c. 循环变动(C)。
通常是指周期为一年以上的有规律的波动。
比如经济发展周期等。
t循环变动与季节变动不同,它的波动周期较长,周期的长短不一,变动的规则性和稳定性较差。
第八章一、单项选择题1.时间数列的构成要素是()A.变量和次数 B.时间和指标数值C.时间和次数 D.主词和时间2.编制时间数列的基本原则是保证数列中各个指标值具有()A.可加性 B.连续性C.一致性 D.可比性3.相邻两个累积增长量之差,等于相应时期的()A.累积增长量 B.平均增长量C.逐期增长量 D.年距增长量4.统计工作中,为了消除季节变动的影响可以计算()A.逐期增长量 B.累积增长量C.平均增长量 D.年距增长量5.基期均为前一期水平的发展速度是()A.定基发展速度 B.环比发展速度C.年距发展速度 D.平均发展速度6.某企业2003年产值比1996年增长了1倍,比2001年增长了50%,则2001年比1996年增长了()A.33% B.50%C.75% D.100%7.关于增长速度以下表述正确的有()A.增长速度是增长量与基期水平之比 B.增长速度是发展速度减1C.增长速度有环比和定基之分 D.增长速度只能取正值8.如果时间数列环比发展速度大体相同,可配合()A.直线趋势方程 B.抛物线趋势方程C.指数曲线方程 D.二次曲线方程二、多项选择题1.编制时间数列的原则有()A.时期长短应一致 B.总体范围应该统一C.计算方法应该统一 D.计算价格应该统一E.经济内容应该统一2.发展水平有()A.最初水平 B.最末水平C.中间水平 D.报告期水平E.基期水平3.时间数列水平分析指标有()A.发展速度 B.发展水平C.增长量 D.平均发展水平E.平均增长量4.测定长期趋势的方法有()A.时距扩大法 B.移动平均法C.序时平均法 D.分割平均法E.最小平方法三、填空题1.保证数列中各个指标值的_______是编制时间数列的最主要规则。
2.根据采用的基期不同,增长量可以分为逐期增长量和_______增长量两种。
3.累积增长量等于相应的_______之和。
两个相邻的_______之差,等于相应时期的逐期增长量。
第八章练习题
一、单项选择
(1)当自变量的数值确定后,因变量的数值也随之完全确定,这种关系属于( )。
A.相关关系
B.函数关系
C.回归关系
D.随机关系
(2)相关系数的取值范围是( )。
A. 0≤r ≤1
B. -1<r <1
C. -1≤r ≤1
D. -1≤r ≤0
(3)一元线性回归方程y=12+3.6x,如x每增加1个单位,则y平均增加( )。
A. 12个单位
B. 15.6个单位
C. 3.6个单位
D. 8.4个单位
(4)一元线性回归方程中的两个变量( )。
A.都是随机变量
B.地位是对等的
C.都是给定的量
D.一个是自变量,另一个是因变量
二、多项选择题
(5)相关系数表明两变量之间的关系( )。
A.线性关系
B.因果关系
C.变异关系
D.相关方向
E.相关的密切程度
(6)如果两个变量之间的相关系数是1,则这两个变量是( )。
A.负相关关系
B.正相关关系
C.完全相关关系
D.不完全相关关系
E.零相关
(7)在一元线性回归分析中( )。
A.自变量是可控变量,因变量是随机变量
B.两个变量不是对等的关系
C.利用回归方程,两个变量可以相互推算
D.根据回归系数可判定相关的方向
E.自变量是随机变量,因变量是可控变量
(8)利用一元线性回归方程,可以( )。
A.进行两个变量的互相推算
B.用自变量推算因变量
C.用因变量推算自变量
D.确定两个变量的变动关系
E.研究两个变量之间的密切程度。
1. 解:根据题意建立原假设和备择假设:01:700;:700H H μμ≥<2x Z ===- 由于-2<-1.645,所以Z Z α<-,Z 值位于原假设0H 的拒绝域,所以拒绝0H ,即在显著性水平0.05下该批元件不合格。
2. 根据题意建立原假设和备择假设:01:250;:250H H μμ≤>20 3.336x t ====,0.05(24) 1.7109t =, 由于0.05(24),.t t t t α>>所以t 值位于原假设H 0,即在显著性水平0.05下该种化肥使得水稻明显增产。
3. 解:已知 0620.157,0.155,0.05, 1.96.400p p Z αα===== 根据题意建立原假设和备择假设:01:0.157;:0.157H P H P =≠0.10995P Z ===- -0.10995>-1.96,所以Z 值位于原假设H 0的接受域。
即在显著性水平0.05下随机调查的结果支持该市老年人口比重为15.7%。
4. 解:已知 09,100,99.98, 1.2122n x s μ====。
根据题意建立原假设和备择假设:01:100;:100H H μμ=≠0.020.04950.4041x t -====- -0.0495>-2.306,所以t 位于原假设H 0的接受域,即在显著性水平0.05下,打包机打包正常。
5. 解:已知00.05200,20,208.5,30,(19) 1.7291n x S t μ=====。
根据题意建立原假设和备择假设:01:200;:200H H μμ≤>8.5 1.2676.7083x t ==== t t α<,所以t 值位于原假设H 0的接受域,即在显著性水平0.05下,接受原假设,即在特定时间内每小时经过该地的汽车数量小于200辆。
6. 解:已知015,40,14.5, 2.3,0.05, 1.645n x S Z αμα======。
8.01 已知某炼铁厂的含碳量服从正态分布N(4.55, 0.108),现在测定了9炉铁水,其平均含碳量为4.484。
如果估计方差没有变化,可否认为现在生产的铁水平均含碳量为4.55 (a=0.05) 。
H0: = 4.55H1: ¹ 4.55= 0.05 n = 9临界值(s): -1.96,1.96 在-1.96~1.96之间接受;否则拒绝检验统计量: =(4.484-4.55)/(0.33/3 )= -0.6 -0.6∈(-1.96,1.96)决策:在 = 0.05的水平上接受H0结论: 有证据表明现在生产的铁水平均含碳量为4.558.02 一种元件,要求其使用寿命不得低于700小时。
现从一批这种元件中随机抽取36件,测得其平均寿命为680小时。
已知该元件寿命服从正态分布,s=60小时,试在显著性水平a=0.05下确定这批元件是否合格。
H0: <700H1: ≥700= 0.05 n = 36临界值(s):1.645 <1.645接受;否则拒绝检验统计量: =(680-700)/(60/6)=-2 -2<1.645决策:在 = 0.05的水平上接受H0结论: 有证据表明元件不合格8.03 某地区小麦的一般生产水平为亩产250公斤,其标准差为30公斤。
现用一种化肥进行试验,从25个小区抽样结果,平均产量为270公斤。
问这种化肥是否使小麦明显增产?(a=0.05) H0: ≤250H1: >250= 0.05 n = 25临界值(s):1.645 <1.645接受;否则拒绝检验统计量: =(270-250)/(30/5)=3.33 3.33>1.645决策:在 = 0.05的水平上拒绝H0结论: 有证据表明这种化肥使小麦明显增产8.04 糖厂用自动打包机打包,每包标准重量是100公斤。
每天开工后需要检验一次打包机工作是否正常。
某日开工后测得9包重量如下:99.3 98.7 100.5 101.2 98.3 99.7 99.5 102.1 100.5已知包重服从正态分布,试检验该日打包机工作是否正常?(a=0.05)H0: =100H1: ≠100= 0.05 n = 9 s=1.21 =99.98临界值(s): -2.31,2.31 在-2.31~2.231之间接受;否则拒绝检验统计量: =(99.98-100)/(1.21/3)=0.50 0.50∈(-2.31,2.31)决策:在 = 0.05的水平上接受H0结论: 有证据表明试检验该日打包机工作正常8.05 某种大量生产的袋装食品,按规定不得少于250克。
统计学人教版第五版7,8,10,11,13,14章课后题答案第七章 参数估计7.1 (1)79.0405===nx σσ (2)由于1-α=95% α=5% 96.12=αZ所以 估计误差55.140596.12≈⨯=nZ σα7.2 (1)14.24915===nx σσ (2)因为96.12=αZ 所以20.4491596.12≈⨯=nZ σα(3)μ的置信区间为20.41202±=±nZ x σα7.3 由于96.12=αZ 104560=x 85414=σ n=100所以μ的95%置信区间为14.167411045601008541496.11045602±=⨯±=±nZ x σα7.4(1)μ的90%置信区间为97.18110012645.1812±=⨯±=±n s Z x α(2)μ的95%置信区间为35.2811001296.1812±=⨯±=±n s Z x α(3)μ的99%置信区间为096.3811001258.2812±=⨯±=±n s Z x α7.5 (1)89.025605.396.1252±=⨯±=±nZ x σα(2)416.66.1197589.23326.26.1192±=⨯±=±n s Z x α(3)283.0419.332974.0645.1419.32±=⨯±=±n s Z x α7.6 (1)035.25389001550096.189002±=⨯±=±nZ x σα(2)650.16589003550096.189002±=⨯±=±nZ x σα(3)028.139890035500645.189002±=⨯±=±n s Z x α(4)583.196890035500326.289002±=⨯±=±n s Z x α7.7 317.31==∑i x nx ()609.1113612=--=∑=i ix x n s 90%置信区间为441.0317.336609.1645.1317.32±=⨯±=±n s Z x α95%置信区间为526.0317.336609.196.1317.32±=⨯±=±n s Z x α99%置信区间为6908.0317.336609.1576.2317.32±=⨯±=±n s Z x α7.8 101==∑i x nx ()464.311812=--=∑=i ix x n s 所以95%置信区间为()896.2108464.33646.21012±=⨯±=±-n s t x n α7.9 375.91==∑i x n x 由于()131.2)15(025.012==-t t n α ()113.4112=--=∑x x n s i 所以95%置信区间为()191.2375.916113.4131.2375.912±=⨯±=±-n s t x n α7.10 (1)63.05.1493693.196.15.1492±=⨯±=±n s Z x α(2)中心极限定理 7.11 (1)132.10150665011=⨯==∑i x nx ()641.188.131491112=⨯=--=∑x x n s i 455.032.10150641.196.132.1012±=⨯±=±n s Z x α(2)由于9.05045==p 所以 合格率的95%置信区间为()083.09.0501.09.096.19.012±=⨯⨯±=-±n p p Z p α7.12 由于128.161==∑i x n x ()745.3)24(005.012==-t t n α ()8706.0112=--=∑x x n s i所以99%置信区间为653.028.161258706.0745.328.161)1(2±=⨯±=-±n s n t x α 7.13 7396.1)17()1(05.02==-t n t α 556.131==∑i x nx ()800.7112=--=∑x x n s i所以90%置信区间为198.3556.13188.77396.1556.13)1(2±=⨯±=-±n s n t x α 7.14(1)()194.051.04449.051.0576.251.012±=⨯⨯±=-±n p p Z p α(2)()0435.082.030018.082.096.182.012±=⨯⨯±=-±n p p Z p α(3)()024.048.0115052.048.0645.148.012±=⨯⨯±=-±n p p Z p α7.15(1)90%置信区间为()049.023.020077.023.0645.123.012±=⨯⨯±=-±n p p Z p α(2)95%置信区间为()058.023.020077.023.096.123.012±=⨯⨯±=-±n p p Z p α7.16 89.1652001000576.222222222=⨯=⎪⎪⎭⎫ ⎝⎛=⇒=E Z n nZ E σδαα所以n 为166 7.17(1)()13.25302.06.04.0054.2122222=⨯⨯=-⎪⎪⎭⎫⎝⎛=E Z n ππα 所以n 为254 (2)()0625.15004.05.05.096.1122222=⨯⨯=-⎪⎪⎭⎫⎝⎛=E Z n ππα 所以n 为151(3)()89.26705.045.055.0645.1122222=⨯⨯=-⎪⎪⎭⎫⎝⎛=E Z n ππα 所以n 为268 7.18(1)64.05032==p (2)()46.611.02.08.096.1122222=⨯⨯=-⎪⎪⎭⎫⎝⎛=E Z n ππα 所以n 为62 7.19(1)()()339.661501205.022=-=-χχαn()()930.331501295.0221=-=--χχαn ()()2212222211ααχσχ--≤≤-s n s n所以()()40.272.1293.33492339.66491122122≤≤⇒⨯≤≤⨯⇒-≤≤--σσχσχααs n s n(2)()()6848.231151205.022=-=-χχαn()()5706.61151295.0221=-=--χχαn()()043.0015.002.05.61470602.06848.23141122122≤≤⇒⨯≤≤⨯⇒-≤≤--σσχσχααs n s n (3)()()6706.321221205.022=-=-χχαn()()5913.111221295.0221=-=--χχαn ()()725.4185.24315913.112131706.36211122122≤≤⇒⨯≤≤⨯⇒-≤≤--σσχσχααs n s n 7.20(1)15.71==∑i x n x ()4767.0112=--=∑x x n s i ()()0228.1911012025.022=-=-χχαn ()()7004.211012975.0221=-=--χχαn ()()87.0328.04767.07004.294767.00228.1991122122≤≤⇒⨯≤≤⨯⇒-≤≤--σσχσχααs n s n(2)()()326.3253.1822.17004.29822.10228.1991122122≤≤⇒⨯≤≤⨯⇒-≤≤--σσχσχααs n s n7.21 2)1()1(212222112-+-+-=n n s n s n s p=442.981910268.9613≈⨯+⨯ (1)21μμ-的90%置信区间为: 212122111)2()(n n s n n t x x p+-+±-α=⨯⨯±442.98729.18.971141+ =9411.78.9± (2)21μμ-的95%置信区间为: 212122111)2()(n n s n n t x x p+-+±-α=⨯⨯±442.9893.028.971141+ =13.698.9± (3)21μμ-的99%置信区间为: ⨯⨯±442.98609.828.971141+=40.1138.9± 7.22(1)2122121221)(n s n s z x x +±-α=36.096.12⨯±=176.12±(2)2)1()1(212222112-+-+-=n n s n s n s p=18209169⨯+⨯=18212122111)2()(n n s n n t x x p+-+±-α=5118.122⨯⨯±=8.932± (3)1)(1)()(222221212122122121-+-+=n n s n n s n s n s ν=17.78 2122121221)(t )(n s n s x x +±-να=6.31.22⨯±=98.32±(4)048.2)28(t 025.0=2)1()1(212222112-+-+-=n n s n s n s p=18.714 212122111)2()(n n s n n t x x p+-+±-α=20110114.71848.022+⨯⨯± =3.432±(5)1)(1)()(222221212122122121-+-+=n n s n n s n s n s ν1919.61)20201016(222++==20.05 086.2)(t =να2122121221)(t )(n s n s x x +±-να=1.61086.22+⨯±=64.332± 7.23(1)47d = 1)(2--=∑n d ds id =48332=917.6(2)n s n t d )1(d -±α=185.447± 7.24 6216.2)1(2=-n t α 11=d ,53197.6=d s d μ的置信区间为:ns n t d )1(d 2-±α=1053197.66216.211⨯±=4152.511±7.25(1)222111221)1()1()(p n p p n p p z p -+-±-α=25076.03.02506.04.0645.11.0⨯+⨯⨯±=0698.01.0± (2)222111221)1()1()(p n p p n p p z p -+-±-α=25076.03.02506.04.096.11.0⨯+⨯⨯±=0831.01.0± 7.26 241609.01=s 076457.02=s)1,1(21--n n F α=)20,20(025.0F =2.464 )20,20(975.0F =0.40576212221222122221αασσ-≤≤F s s F s s 40576.0986.9446.2986.92221≤≤σσ 611.240528.42221≤≤σσ7.27 222)1()(Ez n ππα-==2204.098.002.096.1⨯⨯=47.06 所以 n =487.282222)(E z n σα==2222012096.1⨯=138.30所以 n =139第8章 假设检验二、练习题(说明:为了便于查找书后正态分布表,本答案中,正态分布的分位点均采用了下侧分位点。
一、单项选择题
1.时间数列的构成要素是()
A.变量和次数 B.时间和指标数值
C.时间和次数 D.主词和时间
2.编制时间数列的基本原则是保证数列中各个指标值具有()
A.可加性 B.连续性
C.一致性 D.可比性
3.相邻两个累积增长量之差,等于相应时期的()
A.累积增长量 B.平均增长量
C.逐期增长量 D.年距增长量
4.统计工作中,为了消除季节变动的影响可以计算()
A.逐期增长量 B.累积增长量
C.平均增长量 D.年距增长量
5.基期均为前一期水平的发展速度是()
A.定基发展速度 B.环比发展速度
C.年距发展速度 D.平均发展速度
6.某企业2003年产值比1996年增长了1倍,比2001年增长了50%,则2001年比1996年增长了()
A.33% B.50%
C.75% D.100%
7.关于增长速度以下表述正确的有()
A.增长速度是增长量与基期水平之比 B.增长速度是发展速度减1
C.增长速度有环比和定基之分 D.增长速度只能取正值
8.如果时间数列环比发展速度大体相同,可配合()
A.直线趋势方程 B.抛物线趋势方程
C.指数曲线方程 D.二次曲线方程
二、多项选择题
1.编制时间数列的原则有()
A.时期长短应一致 B.总体范围应该统一
C.计算方法应该统一 D.计算价格应该统一
E.经济内容应该统一
2.发展水平有()
A.最初水平 B.最末水平
C.中间水平 D.报告期水平
E .基期水平
3.时间数列水平分析指标有( )
A .发展速度
B .发展水平
C .增长量
D .平均发展水平
E .平均增长量
4.测定长期趋势的方法有( )
A .时距扩大法
B .移动平均法
C .序时平均法
D .分割平均法
E .最小平方法 三、填空题
1.保证数列中各个指标值的_______是编制时间数列的最主要规则。
2.根据采用的基期不同,增长量可以分为逐期增长量和_______增长量两种。
3.累积增长量等于相应的_______之和。
两个相邻的_______之差,等于相应时期的逐期增长量。
4.各个环比发展速度的连乘积等于_______。
5. 相邻两个定基发展速度之商,等于相应的_______发展速度。
6.平均发展速度是各个时期_______的序时平均数。
7.在实际工作中,为了消除季节变动的影响,常计算_______发展速度。
8.用最小平方法拟合趋势直线,要求满足两个条件:(1)0)(=-∑c y y ;(2)_______。
四、判断题
1.时点指标的数值与时点间隔成正比。
( )
2.相对指标可以直接平均。
( )
3.平均增长量等于累计增长量除以逐期增长量的个数。
( )
4.环比发展速度的连乘积等于定基发展速度。
( )
5.平均增长速度是通过平均发展速度求得的。
( )
6.将逐期增长速度直接平均可以求得平均增长速度。
( )
7.将各期平均数简单平均,可以求得总平均数。
( ) 五、名词解释 1.时点数列 2.平均发展速度 3.平均增长速度 4. 长期趋势 六、简答题
1.简述时间数列在统计和经济分析中的重要作用。
2.简述计算平均发展速度的水平法与累计法的区别。
3.测定长期趋势有什么作用?
4.为什么要测定季节变动?
七、计算题
1.某工业企业2013年1月1日产品库存1800吨,3月1日为2000吨,6月1日为2100吨,6月30日为1940吨。
问该产品上半年平均库存是多少?
2.某企业2013年第一季度职工人数及产值资料如下:
单位 1月 2月 3月 4月
总产值月初人数百元
人
4000
60
4200
64
4500
68
4800
67
要求:(1)编制第一季度各月劳动生产率的动态数列;
(2)计算第一季度的月平均劳动生产率;
(3)计算第一季度的劳动生产率。
3.已知某企业2008年至2012年产值资料如下:单位:万元2008 2009 2010 2011 2012
逐期增长量
累积增长量 60 21
120 123
71
要求:(1)填充上表空缺数字;
(2)用水平法和总和法计算年平均增长量。
4.某工厂各月人数资料如下:单位:人 1月 2月 3月 4月 5月 6月 7月
月初职工人数月平均人数 500 510 514 526
533549 564 577
试计算:(1)表中空缺数字;
(2)第一、第二季度及上半年的平均人数。
第八章时间数列分析
一、单项选择:
2. D 4. D 5. B 6. A 7. D 8. C
二、多项选择:
1. ABCDE
2. ABCDE
3. BCDE
三、填空:
1. 可比性
2.累积
3. 逐期增长量 累积增长量
4. 定基发展速度
5. 环比发展速度
6. 环比发展速度
7. 年距
8. 最小2
=-∑)(c y y
四、判断
1. ×
2. ×
3. √
4. √
5. √
6. ×
7. ×
五、名词解释:
1.时间数列的每个总量指标数值都是现象在某一时刻上所达到的绝对数水平值时,这种数列为时点数列。
2.平均发展水平是对时间数列中不同时间上的指标值加以平均所得的平均数,又称序时平均数。
3.平均增长速度是时间数列中各期环比增长速度的代表值,它用以表明现象在较长时间内平均递增或递减的一般程度。
平均增长速度不能根据各期环比增长速度来直接进行序时平均,因为各期环比增长速度的连乘积不等于总增长速度。
若计算平均增长速度必须还原为发展速度,求出平均发展速度(x ),平均发展速度再减1求得平均增长速度。
4.长期趋势是指现象在一段相当长的时期内持续发展变化的趋势。
六、简答:
1.(1)可以反映社会经济现象发展变化过程及其历史状况;
(2)可以计算各种动态分析指标,反映现象发展变化的方向、速度、趋势及其变化的规律性;
(3)根据时间数列发展变化的趋势,可以预测社会经济现象未来的变化状况; (4)将互相联系的时间数列对比,可以研究现象的联系程度。
2.两种方法除了数理论据计算方法不同外,在应用上尚有三个区别:(1)考察重点不同;(2)影响因素不同;(3)适用对象不同。
)正确反映现象发展变化的趋势,认识并掌握现象发展变化的规律性,为决策者制定经营决策和长远规划提供依据;
(2)为统计预测提供必要的条件;
(3)消除长期趋势的影响,更好地研究季节变动,为季节预测提供条件。
4.(1)测定季节变动的目的,在于认识和掌握季节变动规律,从而克服它的不良影响,更好地指导生产和经营活动,安排好人民生活,提高社会经济效益; (2)可根据季节变动规律,配合适当的数学模型,进行季节预测;
(3)有利于消除时间数列中季节变动的影响,正确地评价工作成绩,进行经济分析。
七、计算: 1.解:
1
211
123212
1222---+++⋅+++⋅++⋅+=
n n n n f f f f a a f a a f a a a ΛΛ
万吨)
(19951
32121940
210032210020002220001800=++⨯++⨯++⨯+=
2.解:(1)
(2))(16.64962676864260450042004000元/人=+++++==
b a c
(3))(49.1948817.65450042004000元/人=++=∑=
b
a c
或)(48.1948816.64963元/人=⨯=c n 4.解:(1)
(2)第一季度:(人)
33.5123
===n a 第二季度:(人)
67.5483
564
549533=++=∑=n a a 上半年:(人)5
.5302
67
.54833.512=+=∑=n a a 5.
解:
国家统计局发布了2014年国民经济和社会发展统计公报,其中,国内生产总值636463亿元,已知2013年全年国内生产总值568845亿元,要求:
(1)2014年比2013年增长了636463-568845=67618亿元,增长率=(636463/568845)*100%-100%=%。
(2)2015年3月5日上午,李克强总理在人大会议上做了“政府工作报告”,2015年的各项经济指标正式公布,国内生产总值比上年增长%。
预计2015年全年国内生产总值将达到636463亿元*(1+%)=636463亿元*%=亿元。