数据库的关系与排序筛选
- 格式:ppt
- 大小:303.00 KB
- 文档页数:8
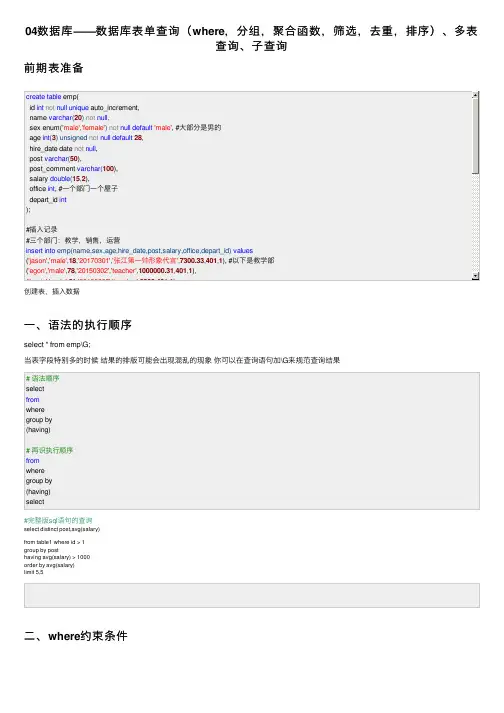
04数据库——数据库表单查询(where ,分组,聚合函数,筛选,去重,排序)、多表查询、⼦查询前期表准备('tank','male',73,'20140701','teacher',3500,401,1),('owen','male',28,'20121101','teacher',2100,401,1),('jerry','female',18,'20110211','teacher',9000,401,1),('nick','male',18,'19000301','teacher',30000,401,1),('sean','male',48,'20101111','teacher',10000,401,1),('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门('丫丫','female',38,'20101101','sale',2000.35,402,2),('丁丁','female',18,'20110312','sale',1000.37,402,2),('星星','female',18,'20160513','sale',3000.29,402,2),('格格','female',28,'20170127','sale',4000.33,402,2),('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门('程咬⾦','male',18,'19970312','operation',20000,403,3),('程咬银','female',18,'20130311','operation',19000,403,3),('程咬铜','male',18,'20150411','operation',18000,403,3),('程咬铁','female',18,'20140512','operation',17000,403,3);#ps :如果在windows 系统中,插⼊中⽂字符,select 的结果为空⽩,可以将所有字符编码统⼀设置成gbk 创建表,插⼊数据⼀、语法的执⾏顺序select * from emp\G;当表字段特别多的时候 结果的排版可能会出现混乱的现象 你可以在查询语句加\G 来规范查询结果# 语法顺序select fromwhere group by (having)# 再识执⾏顺序from wheregroup by (having)select#完整版sql 语句的查询select distinct post,avg(salary)from table1 where id > 1group by posthaving avg(salary) > 1000order by avg(salary)limit 5,5⼆、where 约束条件"""模糊匹配 like%:匹配多个任意字符 _:匹配⼀个任意字符三、group by 分组1.分组前戏 ——设置严格模式select * from emp group by post; # 报错select id,name,sex from emp group by post; # 报错select post from emp group by post; # 获取部门信息#查询详细信息报错,只能查询到分组的信息,说明设置成功强调:只要分组了,就不能够再“直接”查找到单个数据信息了,只能获取到组名2.聚合函数 max min avg sum count 以组为单位统计组内数据>>>聚合查询(聚集到⼀起合成为⼀个结果)如果⼀张表没有写group by 默认所有的数据就是⼀组#在分组后,即select 后⾯或者having 后⾯才能使⽤# 每个部门的最⾼⼯资select post,max(salary) from emp group by post;PS:给字段取别名(as 也可以省略,但是⼀般不要这样⼲)select post as 部门,max(salary) as 最⾼⼯资 from emp group by post;# 每个部门的最低⼯资select post,min(salary) from emp group by post;# 每个部门的平均⼯资select post,avg(salary) from emp group by post;# 每个部门的⼯资总和select post,sum(salary) from emp group by post;# 每个部门的⼈数总数select post,count(id) from emp group by post;在统计分组内个数的时候,填写任意⾮空字段都可以完成计数,推荐使⽤能够⾮空且唯⼀标识数据的字段,⽐如id 字段# 聚合函数max min sum count avg 只能在分组之后才能使⽤,也就是紧跟着select ⽤或者紧跟着having (分组后的⼆次where )select id,name,age from emp where max(salary) > 3000; # 报错!select max(salary) from emp;# 正常运⾏,不分组意味着每⼀个⼈都是⼀组,等运⾏到max(salary)的时候已经经过where,group by操作了,只不过我们都没有写这些条件3.group_concat 和 concatgroup_concat(分组之后⽤)不仅可以⽤来显⽰除分组外字段还有拼接字符串的作⽤1.group_concat 显⽰分组外字符 拼接字符串#查询分组之后的部门名称和每个部门下所有⼈的姓名select post,group_concat(name) from emp group by post;#在每个⼈的名字前后拼接字符select post,group_concat('D_',name,"_SB") from emp group by post;#group_concat()能够拿到分组后每⼀个数据指定字段(可以是多个)对应的值select post,group_concat(name,": ",salary) from emp group by post;2.concat拼接 as语法使⽤(不分组时⽤)就是⽤来拼接字符串达到更好的显⽰效果select name as 姓名,salary as 薪资from emp;select concat("NAME: ",name) as 姓名,concat("SAL: ",salary) as 薪资from emp;# 如果拼接的符号是统⼀的可以⽤ concat_wsselect concat_ws(':',name,age,sex) as info from emp;⼩技巧:concat就是⽤来帮你拼接数据,不分组情况下使⽤group_concat 分组之后使⽤,可以拼接数据也可以⽤来显⽰其他字段信息# 补充as语法既可以给字段起别名也可以给表起select emp.id, from emp as t1; # 报错因为表名已经被你改成了t1select t1.id, from emp as t1;3.查询四则运算# 查询每个⼈的年薪select name,salary*12 as annual_salary from emp;select name,salary*12 annual_salary from emp; # as可以省略4.练习题"""View Code8、统计各部门年龄在30岁以上的员⼯平均⼯资四、having 筛选跟where是⼀模⼀样的也是⽤来筛选数据但是having是跟在group by之后的where是对整体数据做⼀个初步的筛选⽽having是对分组之后的数据再进⾏⼀次针对性的筛选1、统计各部门年龄在30岁以上的员⼯平均⼯资,并且保留平均⼯资⼤于10000的部门select post,avg(salary) from emp where age > 30 group by post where avg(salary) > 10000; # 报错select post,avg(salary) from empwhere age >= 30group by posthaving avg(salary) > 10000;强调:having必须在group by后⾯使⽤select * from emp having avg(salary) > 10000; # 报错五、distinct 去重# 对有重复的展⽰数据进⾏去重操作#去重⼀定要满⾜数据是⼀模⼀样的情况下才能达到去重的效果#如果你查询出来的数据中包含主键字段,那么不可能去重成功#只要有⼀个不⼀样都不能算是的重复的数select distinct id,age from emp; #去重失败,id不⼀样,即使age⼀样也没⽑⽤select distinct post from emp; #成功六、limit 限制条数# 限制展⽰条数select * from emp limit 5; # 只展⽰数据的五条# 分页显⽰select * from emp limit 5,5; #第6条开始,往后展⽰5条当limit只有⼀个参数的时候表⽰的是只展⽰⼏条当limit有两个参数的时候第⼀个参数表⽰的起始位置,是索引第⼆个参数表⽰从起始位置开始往后展⽰的条数# 查询⼯资最⾼的⼈的详细信息select * from emp order by salary desc limit 1;七、regexp 正则# 在编程中只要看到reg开头的基本上都是跟正则相关select * from emp where name regexp '^j.*(n|y)$';re模块中findall:分组优先会将括号内正则匹配到的优先返回match:从头开始匹配匹配到⼀个就直接返回res = match('^j.*n$','jason')print(res.group())search:整体匹配匹配到⼀个就直接返回⼋、order by 排序select * from emp order by salary asc; #默认升序排select * from emp order by salary desc; #降序排select * from emp order by age desc; #降序排#先按照age 降序排,在年纪相同的情况下再按照薪资升序排select * from emp order by age desc,salary asc;# 统计各部门年龄在10岁以上的员⼯平均⼯资,并且保留平均⼯资⼤于1000的部门,然后对平均⼯资进⾏排序select post,avg(salary) from empwhere age > 10group by posthaving avg(salary) > 1000order by avg(salary);九、多表查询(203,'运营');insert into emp(name,sex,age,dep_id) values('jason','male',18,200),('egon','female',48,201),('kevin','male',38,201),('nick','female',28,202),('owen','male',18,200),('jerry','female',18,204);# 当初为什么我们要分表,就是为了⽅便管理,在硬盘上确实是多张表,但是到了内存中我们应该把他们再拼成⼀张表进⾏查询才合理创建表当初为什么我们要分表,就是为了⽅便管理,在硬盘上确实是多张表,但是到了内存中我们应该把他们再拼成⼀张表进⾏查询才合理#笛卡尔积select * from emp,dep; # 左表⼀条记录与右表所有记录都对应⼀遍,即10*4=40条 >>>笛卡尔积# 将所有的数据都对应了⼀遍,虽然不合理但是其中有合理的数据,现在我们需要做的就是找出合理的数据# 查询员⼯及所在部门的信息select * from emp,dep where emp.dep_id = dep.id;#查询部门为技术部的员⼯及部门信息select * from emp,dep where emp.dep_id = dep.id and = '技术';其实将两张表关联到⼀起的操作,有专门对应的⽅法:内连接、左连接、右链接、全连接# 1、内连接:只链接两张表有对应关系的记录select * from emp inner join dep on emp.dep_id = dep.id;select * from emp inner join dep on emp.dep_id = dep.idwhere = "技术";# 2、左连接: 在内连接的基础上保留左表没有对应关系的记录,没有部门信息null 补全select * from emp left join dep on emp.dep_id = dep.id;# 3、右连接: 在内连接的基础上保留右表没有对应关系的记录,没有员⼯信息null 补全select * from emp right join dep on emp.dep_id = dep.id;# 4、全连接:在内连接的基础上保留左、右⾯表没有对应关系的的记录,空⽩全⽤null 补全# 只要将左连接和右连接的sql 语句中间加⼀个union 连起来就变成全连接select * from emp left join dep on emp.dep_id = dep.idunionselect * from emp right join dep on emp.dep_id = dep.id;⼗、⼦查询就是将⼀个查询语句的结果⽤括号括起来当作另外⼀个查询语句的条件去⽤,括号⾥⾯语句末尾不能加分号#最新⽇期作为条件select name,hire_date,post from emp where hire_date in (select max(hire_date) from emp group by post) ;# 查询平均年轻在25岁以上的部门名⽅法⼀:⼦查询select name from dep where id in(select dep_id from emp group by dep_id having avg(age)>25);⽅法⼆:连表查询select from emp inner join dep on emp.dep_id = dep.idgroup by having avg(age) > 25;"""记住⼀个规律,表的查询结果可以作为其他表的查询条件,也可以通过其别名的⽅式把它作为⼀张虚拟表去跟其他表做关联查询"""select * from emp inner join dep on emp.dep_id = dep.id;⼗⼀、exist(了解)EXISTS关字键字表⽰存在。

Access中的表格排序技巧Access中的表格排序技巧Microsoft Access是一款广泛使用的关系型数据库管理系统,它为用户提供了强大的数据管理和分析功能。
Access中的表格可以用来存储和组织数据,并且可以通过排序来方便地查找和分析数据。
本文将介绍Access中的表格排序技巧,以帮助用户更好地管理和利用数据。
一、使用“排序和筛选”功能进行排序Access提供了一个“排序和筛选”功能,可以快速对表格数据进行排序。
该功能可以按单个字段或多个字段进行排序,同时还可以指定升序或降序排序方式。
1.单字段排序单字段排序是最简单的排序方式,它只需要选择要排序的字段和排序方式即可。
具体步骤如下:(1)打开Access数据库并打开要排序的表格;(2)选中要排序的字段,单击表格标题栏中对应字段的标签,然后单击鼠标右键,在右键菜单中选择“排序”,或者点击“首页”选项卡上的“排序和筛选”按钮,在弹出的下拉菜单中选择“排序”;(3)在“排序”对话框中,选择要排序的字段和排序方式。
如果要按升序(A-Z或1-9)排序,选择“升序”选项;如果要按降序(Z-A或9-1)排序,选择“降序”选项。
点击“确定”即可开始排序。
2.多字段排序多字段排序需要按照多个字段进行排序。
例如,要先按照部门名称排序,然后在同一部门中按照工资金额排序。
具体步骤如下:(1)打开Access数据库并打开要排序的表格;(2)选中要排序的第一个字段,单击表格标题栏中对应字段的标签,然后单击鼠标右键,在右键菜单中选择“排序”,或者点击“首页”选项卡上的“排序和筛选”按钮,在弹出的下拉菜单中选择“排序”;(3)在“排序”对话框中,选择要排序的第一个字段和排序方式。
点击“添加级别”按钮,再选择要排序的第二个字段和排序方式。
点击“确定”即可开始排序。
3.撤销排序如果不满意排序结果,可以撤销排序并返回原始排序状态。
具体步骤如下:(1)单击表格底部的“恢复”按钮,或者点击“首页”选项卡上的“排序和筛选”按钮,在弹出的下拉菜单中选择“清除排序”的选项即可撤销排序。

关系型数据库与非关系型数据库的特点与应用比较随着数据的爆炸式增长和技术的不断发展,数据库管理系统的种类也越来越多。
其中,关系型数据库和非关系型数据库是常见的两种类型。
本文将分析关系型数据库和非关系型数据库的特点与应用,帮助读者更好地理解这两种数据库类型。
一、关系型数据库的特点与应用关系型数据库(Relational Database,简称RDB)通过使用关系模型来组织和存储数据。
它基于预定义的结构,由表格、行和列组成。
以下是关系型数据库的特点:1. 结构化数据:关系型数据库使用表格来存储数据,每个表格包含多个行和列,具有固定的结构。
这种结构化的数据适合针对特定要求进行查询和分析。
例如,客户数据库可以包含客户名称、联系方式、地址等列,方便对客户信息进行管理和检索。
2. 数据一致性:关系型数据库使用事务机制来保持数据的一致性。
它们支持原子性、一致性、隔离性和持久性(ACID)的特性,确保在任何情况下都能保持数据的完整性。
这对于金融系统、电子商务平台等需要高度可靠性和数据一致性的应用来说尤其重要。
3. 复杂查询:关系型数据库支持SQL(Structured Query Language)来查询和操作数据,非常适合复杂的查询和多表连接。
使用SQL语句,开发人员可以根据需要筛选、排序、连接和聚合数据。
这使得关系型数据库在需要进行复杂数据分析和报表生成的业务应用中得到广泛应用。
4. 数据完整性:关系型数据库通过定义约束来保证数据的完整性。
约束可以包括主键、外键、唯一性约束、检查约束等,帮助开发人员有效地控制数据的输入和修改,确保数据的准确性。
关系型数据库适用于需要处理结构化和事务性数据的应用场景,如企业管理系统、人力资源管理系统、金融系统和电子商务平台等。
二、非关系型数据库的特点与应用非关系型数据库(Non-relational Database,简称NoSQL)与关系型数据库的数据模型不同,它使用不同的存储方式和查询操作。

sql 条件的先后顺序摘要:1.SQL 条件的先后顺序概述2.关系型数据库中的SQL 条件3.条件顺序对查询结果的影响4.优化SQL 条件的顺序5.结论正文:1.SQL 条件的先后顺序概述在关系型数据库中,SQL 条件是用来筛选和排序查询结果的关键部分。
它们可以应用于SELECT 语句的WHERE 子句、GROUP BY 子句、HAVING 子句和ORDER BY 子句等。
在实际应用中,条件顺序的安排可能会影响到查询效率和结果的准确性。
2.关系型数据库中的SQL 条件在关系型数据库中,我们通常使用SQL 语句进行数据查询。
SQL 条件主要包括以下几种:- WHERE 子句:用于筛选数据,满足指定条件的记录才会被返回。
- GROUP BY 子句:用于对数据进行分组,通常与聚合函数(如COUNT、SUM 等)结合使用。
- HAVING 子句:用于对分组后的数据进行筛选,满足指定条件的分组才会被返回。
- ORDER BY 子句:用于对查询结果进行排序,可以按照指定的列或表达式进行升序或降序排列。
3.条件顺序对查询结果的影响条件顺序的安排可能会对查询结果产生影响。
在实际应用中,我们需要根据需求合理地安排条件顺序,以提高查询效率和获得准确的结果。
例如,假设我们有一个包含学生信息的表,我们希望查询成绩高于80 分的男生。
如果我们按照以下顺序设置条件:```SELECT * FROM student WHERE gender = "male" AND score > 80;```那么,只有满足性别为男且成绩高于80 分的学生记录会被返回。
如果我们调换条件顺序:```SELECT * FROM student WHERE score > 80 AND gender = "male";```此时,只有满足成绩高于80 分的学生记录会被返回,而不考虑性别。
因此,条件顺序的安排对查询结果具有重要影响。


如何在MySQL中实现分组与排序操作MySQL是一种广泛使用的关系型数据库管理系统,具有强大的分组和排序功能。
本文将介绍如何在MySQL中实现分组和排序操作,通过使用合适的SQL语句以及相关函数和关键字,提高数据处理和查询的效率。
1. 分组操作分组操作是将数据按照指定的列进行分组,常用于统计和汇总数据。
在MySQL中,可以使用GROUP BY语句来实现分组操作。
下面是一个示例:```SELECT category, COUNT(*)FROM productsGROUP BY category;```上述语句将按照产品的类别(category)进行分组,并统计每个类别下产品的数量。
通过使用COUNT(*)函数,可以直接统计每个分组中的记录数。
另外,还可以使用HAVING子句来对分组结果进行筛选。
例如,以下示例将会筛选出产品数量大于10的类别:```SELECT category, COUNT(*)FROM productsGROUP BY categoryHAVING COUNT(*) > 10;```通过使用GROUP BY和HAVING,可以灵活地进行数据的分组和筛选,使得数据分析和查询更加简单高效。
2. 排序操作排序操作是将查询结果按照指定的列进行排序,常用于获取特定顺序的数据。
在MySQL中,可以使用ORDER BY语句来实现排序操作。
下面是一个示例:```SELECT *FROM productsORDER BY price DESC;```上述语句将按照产品的价格(price)降序排列,从高到低显示产品的信息。
通过使用DESC关键字,可以指定降序排序。
如果要进行升序排序,则不需要使用任何关键字,默认为升序。
此外,ORDER BY语句还可以指定多个列进行排序。
例如,以下示例将首先按照产品的类别排序,然后再按照价格排序:```SELECT *FROM productsORDER BY category ASC, price DESC;```上述语句将首先按照产品的类别(category)升序排列,如果类别相同则按照价格(price)降序排列。

如何使用MySQL进行数据的排序和过滤使用MySQL进行数据的排序和过滤在进行数据处理和分析时,对数据进行排序和过滤是一项非常常见且重要的任务。
MySQL作为一种关系型数据库管理系统,提供了强大的排序和过滤功能,可以帮助我们快速准确地从海量数据中提取出需要的结果。
本文将介绍如何使用MySQL进行数据的排序和过滤,并提供一些实际应用案例。
一、排序排序是将一组数据按照特定的规则进行排列的过程。
在MySQL中,我们可以使用ORDER BY子句来对结果进行排序。
ORDER BY子句后面跟着一个或多个列名,用于指定排序的规则。
下面是一个简单的示例:SELECT * FROM table_name ORDER BY column_name;在这个示例中,我们从名为table_name的表中查询并按照名为column_name的列进行升序排序。
如果希望进行降序排序,可以添加关键字DESC:SELECT * FROM table_name ORDER BY column_name DESC;除了单个列的排序,我们还可以按照多个列进行排序。
当存在多个列时,MySQL会按照指定的列顺序进行排序。
例如:SELECT * FROM table_name ORDER BY column1, column2;这个例子中,我们先按照column1进行排序,如果存在相同的值,则按照column2进行排序。
排序时,我们还可以使用特殊的函数。
例如,如果想按照字符串的长度进行排序,可以使用LENGTH函数:SELECT * FROM table_name ORDER BY LENGTH(column_name);这样可以将长度短的字符串排在前面。
除了直接排序,我们还可以在排序过程中指定条件。
例如,我们可以通过WHERE子句过滤出需要排序的数据:SELECT * FROM table_name WHERE condition ORDER BY column_name;这个示例中,我们通过WHERE子句指定了条件,然后对符合条件的数据按照column_name进行排序。

SQL查询与数据筛选技巧第一章简介1.1 SQL的定义与作用SQL(Structured Query Language)是一种用于管理关系型数据库系统的标准化语言。
它可以用于创建数据库、定义表格以及执行各种类型的查询和操作。
1.2 数据筛选的重要性数据筛选是SQL查询中的必要环节,它能帮助我们从海量的数据中迅速找出所需的信息。
正确使用数据筛选技巧可以提高查询效率,减少资源浪费。
第二章数据排序与筛选2.1 SELECT语句详解SELECT语句用于从数据库中检索信息。
它可以通过使用WHERE子句实现数据筛选、ORDER BY子句实现数据排序。
2.2 WHERE子句的使用WHERE子句用于指定条件,只有满足条件的数据才会被返回。
我们可以使用比较运算符(如=、<、>)、逻辑运算符(如AND、OR)以及通配符(如LIKE)进行条件的组合。
2.3 ORDER BY子句的使用ORDER BY子句用于对结果集进行排序。
可以根据单个或多个列进行排序,并指定升序或降序。
例如,ORDER BY age DESC可以按照年龄从高到低排序。
第三章数据分组与聚合3.1 GROUP BY子句的使用GROUP BY子句用于对结果集进行分组。
通过指定一个或多个列,可以将数据按照指定的列进行分组,并进行分组统计。
例如,SELECT department, COUNT(*) FROM employees GROUP BY department可以统计每个部门的员工人数。
3.2 HAVING子句的使用HAVING子句用于过滤分组后的结果集。
它类似于WHERE子句,但可以在分组后的结果集上进行筛选。
例如,SELECT department, COUNT(*) FROM employees GROUP BY department HAVING COUNT(*) > 10可以筛选出员工人数大于10的部门。
第四章连接查询与子查询4.1 连接查询的基本概念连接查询用于从多个表中获取相关联的数据。

教案数据的排序和筛选第一章:数据排序的基本概念1.1 数据排序的定义和作用1.2 排序算法的分类和特点1.3 排序算法的应用场景第二章:简单排序算法2.1 冒泡排序算法2.1.1 冒泡排序算法的原理和步骤2.1.2 冒泡排序算法的时间和空间复杂度分析2.2 选择排序算法2.2.1 选择排序算法的原理和步骤2.2.2 选择排序算法的时间和空间复杂度分析2.3 插入排序算法2.3.1 插入排序算法的原理和步骤2.3.2 插入排序算法的时间和空间复杂度分析第三章:高级排序算法3.1 归并排序算法3.1.1 归并排序算法的原理和步骤3.1.2 归并排序算法的时间和空间复杂度分析3.2 快速排序算法3.2.1 快速排序算法的原理和步骤3.2.2 快速排序算法的时间和空间复杂度分析3.3.1 堆排序算法的原理和步骤3.3.2 堆排序算法的地和空间复杂度分析第四章:数据筛选的基本概念4.1 数据筛选的定义和作用4.2 筛选算法的分类和特点4.3 筛选算法的应用场景第五章:常见筛选算法5.1 冒泡筛选算法5.1.1 冒泡筛选算法的原理和步骤5.1.2 冒泡筛选算法的地和空间复杂度分析5.2 选择筛选算法5.2.1 选择筛选算法的原理和步骤5.2.2 选择筛选算法的地和空间复杂度分析5.3 插入筛选算法5.3.1 插入筛选算法的原理和步骤5.3.2 插入筛选算法的地和空间复杂度分析第六章:排序算法的选择与优化6.1 排序算法选择的标准6.2 不同数据规模下的算法性能比较6.3 排序算法的优化技巧第七章:数据排序的实际应用案例7.2 商品销量排序7.3 数据库中的排序操作第八章:数据筛选的实际应用案例8.1 筛选合格产品8.2 数据预处理中的筛选8.3 在线教育平台学生数据筛选第九章:排序与筛选算法的并行与分布式处理9.1 并行排序算法的基本概念9.2 分布式排序算法的基本概念9.3 排序与筛选算法在分布式系统中的应用10.1 数据排序和筛选的重要性和应用范围10.2 主要学习点和技能要求10.3 进一步学习资源和拓展方向重点和难点解析重点环节一:数据排序的基本概念数据排序的定义和作用排序算法的分类和特点排序算法的应用场景重点环节二:简单排序算法冒泡排序算法的原理和步骤冒泡排序算法的时间和空间复杂度分析选择排序算法的原理和步骤选择排序算法的时间和空间复杂度分析插入排序算法的原理和步骤插入排序算法的时间和空间复杂度分析重点环节三:高级排序算法归并排序算法的原理和步骤归并排序算法的时间和空间复杂度分析快速排序算法的原理和步骤快速排序算法的时间和空间复杂度分析堆排序算法的原理和步骤堆排序算法的时间和空间复杂度分析重点环节四:数据筛选的基本概念数据筛选的定义和作用筛选算法的分类和特点筛选算法的应用场景重点环节五:常见筛选算法冒泡筛选算法的原理和步骤冒泡筛选算法的时间和空间复杂度分析选择筛选算法的原理和步骤选择筛选算法的地和空间复杂度分析插入筛选算法的原理和步骤插入筛选算法的地和空间复杂度分析重点环节六:排序算法的选择与优化排序算法选择的标准不同数据规模下的算法性能比较排序算法的优化技巧重点环节七:数据排序的实际应用案例学绩排序商品销量排序数据库中的排序操作重点环节八:数据筛选的实际应用案例筛选合格产品数据预处理中的筛选在线教育平台学生数据筛选重点环节九:排序与筛选算法的并行与分布式处理并行排序算法的基本概念分布式排序算法的基本概念排序与筛选算法在分布式系统中的应用数据排序和筛选的重要性和应用范围主要学习点和技能要求进一步学习资源和拓展方向本文主要介绍了数据排序和筛选的基本概念、算法原理、应用场景以及优化技巧。

Excel中如何处理和分析大量数据的技术方法Excel是一款功能强大的电子表格软件,广泛应用于数据处理和分析领域。
在处理和分析大量数据时,我们可以借助Excel提供的各种技术方法来提高工作效率和准确性。
本文将介绍一些常用的Excel数据处理和分析技巧。
1. 数据导入和清洗在处理大量数据之前,首先需要将数据导入Excel中,并进行清洗。
可以使用Excel的数据导入功能,将数据从外部文件或数据库中导入到Excel中。
在导入数据时,可以选择合适的数据源和导入方式,如从文本文件导入、从数据库查询导入等。
导入数据后,需要对数据进行清洗,包括删除重复数据、填充缺失值、去除异常值等。
2. 数据排序和筛选在处理大量数据时,经常需要对数据进行排序和筛选。
Excel提供了强大的排序和筛选功能,可以按照特定的条件对数据进行排序和筛选。
可以根据某一列的数值大小进行升序或降序排序,也可以根据某一列的文本内容进行排序。
同时,可以使用筛选功能,根据指定的条件筛选出符合条件的数据,以便进一步分析。
3. 数据透视表数据透视表是Excel中非常实用的数据分析工具,可以帮助我们快速对大量数据进行分析和汇总。
通过数据透视表,可以对数据进行分类、汇总、计算和分析。
可以根据需要选择不同的字段放置在行、列和值区域,以及应用不同的汇总函数,如求和、计数、平均值等。
数据透视表可以帮助我们从大量数据中提取出关键信息,发现数据之间的关系和趋势。
4. 条件格式化条件格式化是Excel中一种强大的数据可视化技术,可以根据指定的条件对数据进行格式化,使数据更加直观和易于理解。
可以根据数值大小、文本内容、日期等条件来设置格式,如颜色填充、字体加粗、图标显示等。
通过条件格式化,可以快速识别出数据中的异常值、趋势和模式,提高数据分析的效率和准确性。
5. 数据图表数据图表是Excel中常用的数据可视化工具,可以将大量数据以图表的形式展示出来,更加直观和易于理解。

数据的筛选与排序方法1. 数据筛选方法:使用筛选函数或筛选工具,根据特定条件筛选出符合要求的数据,如Excel的筛选功能可以帮助用户快速筛选数据。
2. 数据排序方法:可以通过排序函数或排序工具对数据进行升序或降序排列,以便更好地分析和理解数据的趋势和规律。
3. 筛选条件设置:在进行数据筛选时,需要设置筛选条件,通常是基于数据的特定数值、文本内容或日期等属性进行筛选。
4. 排序规则设定:排序时需要设定排序规则,包括升序或降序排列,以及特定字段的优先级等,以确保数据排序符合预期。
5. 筛选与排序联合应用:可以将筛选和排序方法结合,先筛选出符合条件的数据,然后再对这些数据进行排序,以得到更加精确和有意义的结果。
6. 高级筛选技巧:使用逻辑运算符和多个筛选条件,实现更复杂的数据筛选,满足更多复杂的业务需求。
7. 自定义排序规则:根据特定需求,可以自定义排序规则,比如按照特定字段的自定义顺序排列,而非简单的升序或降序排列。
8. 多字段排序:在进行数据排序时,可以根据多个字段进行排序,以实现更为精细的数据排序。
9. 排序稳定性:在进行排序时需要考虑排序算法的稳定性,以确保排序结果符合预期。
10. 在大数据量下的排序优化:针对大规模数据集,需要考虑排序算法的效率和性能,避免排序过程的大量资源消耗。
11. 使用索引进行排序:在数据库中,可以通过对字段建立索引,以提高排序效率,特别是针对大规模数据集的排序操作。
12. 数据预处理与排序:在进行数据分析前,可以先对数据进行预处理,包括筛选和排序,以便后续的分析操作更加高效和准确。
13. 排序算法选择:针对不同的数据特点和需求,可以选择合适的排序算法,如快速排序、归并排序等,以获得更好的排序效果。
14. 数据分组排序:对数据进行分组后再分别进行排序,可以更好地呈现出数据之间的关系和规律。
15. 基于用户需求的排序:在进行数据排序时,需要充分了解用户的需求和关注点,以确保排序结果更符合用户的实际需求。
《数据的排序和筛选》教学设计一、教学目标:知识与技能:1、掌握在ACCESS中进行筛选和排序的基本操作2、能灵活运用所掌握的信息技术解决常见的数据处理问题过程与方法:1、让学生理解排序、筛选的意义2、深入领会排序和筛选在数据管理中的作用情感态度价值观:1、初步培养学生分析数据、并利用数据的排序和筛选解决生活实际问题的能力,并让学生在网络学习环境下自主性、探究性的学习,从而提高学生的科研能力和自我学习意识。
2、培养学生信息管理意识,知道使用ACCESS能规范、高效地管理数据,激发学生学习用ACCESS管理数据的的兴趣,通过网络环境下的自主、探究性学习,培养学生乐于钻研的精神和勇于挑战自我的竞争意识。
二、教材分析:该门课的教学重点是通过ACCESS平台来学习数据库基本原理和技术,体验和感受数据库技术的功能和作用,进而解决生活学习中的相关问题。
本节课是这门选修课的核心部分“使用数据库”这章的第一节课,因此本课的学习将为后面学习数据查询等重要内容奠定理论和知识基础。
教学重点:1、掌握数据的排序和筛选的操作方法;2、灵活运用排序和筛选解决常见的数据处理问题教学难点:1、数据的高级筛选;2、灵活运用排序和筛选解决常见的数据处理问题三、教学对象分析:学生有一定的信息技术操作基础和分析问题的能力,通过前面几章的学习,已经熟悉了ACCESS环境,也初步掌握了建立ACCESS数据库的方法,因此这节课的教学应在学生较易掌握操作的基础上,联系实际生活,最大限度地调动学生分析问题、探索问题的积极性,以提高其信息素养。
四、教学策略设计1、教学方法设计:创设情境,在教学中充分调动学生自主学习、合作学习的积极性,在老师的引导下自主构建知识体系,采用任务驱动法、基于问题学习法、自主探究法、协作探究法等进行教学,设计不同的教学任务,层层深入,使全体学生都能达到课标的要求,能将已有的知识与技能,运用于解决实际生活中的问题。
2、关于教学流程和教学活动的设计思路:3、学生上机操作安排和教师应用信息技术的情况(1)学生上机操作的任务和目标;教师应注意哪些方面的巡视指导?学生在上机操作时,主要完成教师给出的从易到难的任务:数据的排序以及数据的筛选,教师要即时、适时地表扬学生,引导学生,鼓励学生,提倡学生互相帮助,完成任务。
材料编号材料名称密度比热导热系数234567纯铝2710904236706090铝合金M2670904107706290铝合金S2660871162716095纯铜8930386398702095青铜880034324.8706395黄铜84403771091.将工作表表一全部内容复制到sheet1中的相应位置,并将sheet1更名为“材料比热表”。
2.筛选出表一中密度大于7000且密度小于8900的记录。
3.将“材料比热表”中“材料编号”和“材料名称”分别改为“编号”和“名称”。
4.将“材料比热表”以“比热”为主要关键字进行升序排列,以“导热系数”为次要关键字进行降序排本题参考操作步骤如下:1.先选择区域A1:E7,执行命令“编辑/复制”将所选内容放入剪贴板,单击表格标签Sheet1,单击单元执行命令“编辑/粘贴”将剪贴板上的内容粘贴到Sheet1的起始处;双击标签Sheet1并输入文字2.单击表格标签“表一”,单击单元格C1,执行命令“数据/筛选”并选择“自动筛选”,单击字段名“下拉列表框,单击“自定义”打开自定义自动筛选方式对话框,在“密度”下的第一个框中选择选择“与”选项,在“密度”下的第二个框中选择小于,在“小于”右边的框中输入8900,单击“确定3.单击表格标签“材料比热表”,双击A1单元格删除材料两个字,双击单元格B1删除材料两个字。
4.单击D1单元格,执行命令“数据/排序”打开排序对话框,在“主要关键字”框中选择比热并设置为递增导热系数并设置为递减,单击“确定”按钮。
次要关键字进行降序排列。
标签Sheet1,单击单元格A1,入文字“材料比热表”。
筛选”,单击字段名“密度”右侧的按钮打开中选择大于,在“大于”右边的框中输入7000,8900,单击“确定”按钮。
除材料两个字。
选择比热并设置为递增,在“次要关键字”框中选择。
MySQL数据分析技术与应用MySQL 数据分析技术与应用随着信息时代的快速发展,数据变得越来越重要。
数据分析作为一种强大的工具,可以帮助企业和组织根据数据做出更明智的决策。
在数据库管理系统中,MySQL 是最广泛使用的开源关系型数据库。
本文旨在探讨 MySQL 数据分析技术的原理和应用。
一、MySQL 数据分析技术概述数据分析是指通过收集、处理和解释数据,以发现其中的模式、趋势、关联等信息。
MySQL 作为一个成熟的关系型数据库管理系统,提供了丰富的数据分析功能,包括数据查询、统计和聚合函数、复杂查询和子查询等等。
1.1 数据查询在 MySQL 中,通常使用 SQL 查询语言进行数据分析。
SQL(Structured Query Language,结构化查询语言)是一种特定用途的编程语言,可用于管理关系型数据库中的数据。
通过 SELECT 语句,可以从表中提取所需的数据。
例如,可以使用以下语句查询某个表中的所有记录:SELECT * FROM table_name;1.2 统计和聚合函数MySQL 提供了一系列统计和聚合函数,用于分析数据并计算统计结果。
常用的函数包括 COUNT、SUM、AVG、MIN 和 MAX 等等。
这些函数可以根据需要对数据进行求和、平均值、最大值、最小值等计算。
1.3 复杂查询和子查询为了更精确地分析数据,MySQL 支持复杂查询和子查询。
复杂查询是指包含多个条件和连接操作的查询语句,以便从多个表中检索数据并进行更精细的分析。
而子查询是指嵌套在主查询中的查询语句,用于从一个查询结果中提取数据,作为另一个查询的条件或结果。
二、MySQL 数据分析实例为了更好地理解 MySQL 数据分析技术的应用,下面将通过几个实际案例来展示其用途和效果。
2.1 数据分组与排序数据分组和排序是数据分析中常见的操作。
MySQL 提供了 GROUP BY 和ORDER BY 子句,用于对数据进行分组和排序。