非参数统计试卷分析
- 格式:xls
- 大小:34.00 KB
- 文档页数:2

非参数统计答案范文1. 考察Mann-Whitney U检验:问题:对两组数据进行比较,数据不符合正态分布,要判断两组数据是否有显著差异。
如何选择合适的非参数检验方法?答案:Mann-Whitney U检验是一种适用于比较两组独立样本的非参数检验方法,适用于数据不符合正态分布的情况。
2. 考察Wilcoxon符号秩和检验:问题:对同一组数据进行配对比较,数据不符合正态分布,如何选择合适的非参数检验方法?答案:Wilcoxon符号秩和检验是一种适用于配对样本的非参数检验方法,适用于数据不符合正态分布的情况。
3. 考察Kruskal-Wallis检验:问题:有三组数据需要比较,但数据不符合正态分布,如何选择合适的非参数检验方法?答案:Kruskal-Wallis检验是一种适用于比较多组独立样本的非参数检验方法,适用于数据不符合正态分布的情况。
4. 考察Friedman检验:问题:有三组配对数据需要比较,但数据不符合正态分布,如何选择合适的非参数检验方法?答案:Friedman检验是一种适用于比较多组配对样本的非参数检验方法,适用于数据不符合正态分布的情况。
5. 考察Mood's中位数差异检验:问题:有两组独立样本数据需要比较,数据不符合正态分布,如何选择合适的非参数检验方法?答案:Mood's中位数差异检验是一种适用于比较两组独立样本的非参数检验方法,适用于数据不符合正态分布的情况。
6.考察符号检验:问题:对一组配对数据进行比较,但数据不符合正态分布,如何选择合适的非参数检验方法?答案:符号检验是一种适用于配对样本的非参数检验方法,适用于数据不符合正态分布的情况。
7.考察秩和检验:问题:有两组独立样本数据需要比较,如何选择合适的非参数检验方法?答案:秩和检验是一种适用于比较两组独立样本的非参数检验方法。
8. 考察Kolmogorov-Smirnov检验:问题:有一组数据需要验证其服从一些特定分布,如何进行检验?答案:Kolmogorov-Smirnov检验是一种非参数检验方法,可以用于验证数据是否符合一些特定分布。

王静龙《非参数统计分析》(1-8章)教案.引言一般统计分析分为参数分析与非参数分析,参数分析是指,知道总体分布,但其中几个参数的值未知,用统计量来估计参数值,但大部分情况,总体是未知的,这时候就不能用参数分析,如果强行用可能会出现错误的结果。
例如:分析下面的供应商的产品是否合格?合格产品的标准长度为(8.5±0.1),随即抽取n=100件零件,数据如下:表1.18.503 8.508 8.498 8.347 8.494 8.500 8.498 8.500 8.502 8.501 8.491 8.504 8.502 8.503 8.501 8.505 8.492 8.497 8.150 8.496 8.501 8.489 8.506 8.497 8.505 8.501 8.500 8.499 8.490 8.493 8.501 8.497 8.501 8.498 8.503 8.505 8.510 8.499 8.489 8.496 8.500 8.503 8.497 8.504 8.503 8.506 8.497 8.507 8.346 8.310 8.489 8.499 8.492 8.497 8.506 8.502 8.505 8.489 8.503 8.492 8.501 8.499 8.804 8.505 8.504 8.499 8.506 8.499 8.493 8.494 8.490 8.505 8.511 8.502 8.505 8.503 8.782 8.502 8.509 8.499 8.498 8.493 8.897 8.504 8.493 8.494 7.780 8.509 8.499 8.503 8.494 8.511 8.501 8.497 8.493 8.501 8.495 8.461 8.504 8.691经计算,平均长度为cm x 4958.8=,非常接近中心位置8.5cm ,样本标准差为()1047.0112=--=∑=ni i n x x s cm.一般产品的质量服从正态分布,),(~2δμN X 。

经济统计学中的非参数统计方法与分析经济统计学是研究经济现象的统计学科,它运用统计学的方法和技术,对经济数据进行收集、整理、分析和解释,从而揭示经济规律和发展趋势。
非参数统计方法是经济统计学中的一种重要工具,它与参数统计方法相对应,主要用于处理那些无法用参数模型刻画的经济现象。
本文将介绍非参数统计方法的基本原理和应用,并探讨其在经济统计学中的意义和局限。
一、非参数统计方法的基本原理非参数统计方法是一种不依赖于总体分布形态的统计分析方法。
与参数统计方法相比,非参数统计方法不对总体的概率分布进行任何假设,而是通过对样本数据的排序、秩次变换等非参数化处理,来进行统计推断。
其基本原理是利用样本数据的内在结构和顺序信息,从而获得总体的分布特征和统计性质。
二、非参数统计方法的应用领域非参数统计方法在经济统计学中有广泛的应用。
首先,它可以用于经济数据的描述和总结。
例如,通过计算样本数据的中位数、分位数等非参数统计量,可以更准确地描述和解释经济现象的分布特征和变异程度。
其次,非参数统计方法可以用于经济数据的比较和推断。
例如,通过非参数的秩次检验方法,可以判断两个总体是否存在显著差异,从而进行经济政策的评估和决策。
此外,非参数统计方法还可以用于经济模型的估计和验证。
例如,通过非参数的核密度估计方法,可以对经济模型的参数进行非线性估计和模型检验,从而提高经济模型的拟合度和预测能力。
三、非参数统计方法的意义和局限非参数统计方法在经济统计学中具有重要的意义和价值。
首先,它能够更好地应对数据的非正态性和异方差性等问题,从而提高统计推断的效果和准确性。
其次,非参数统计方法能够更好地适应不完全信息和有限样本的情况,从而减少模型假设和参数估计的不确定性。
然而,非参数统计方法也存在一些局限性。
首先,由于非参数统计方法不假设总体的分布形态,因此通常需要更大的样本量才能获得稳健的统计推断结果。
其次,非参数统计方法在处理高维数据和复杂模型时,计算复杂度较高,需要更多的计算资源和时间。

非参数统计(R软件)参考答案本页仅作为文档封面,使用时可以删除This document is for reference only-rar21year.March内容:, ,上机实践:将MASS数据包用命令library(MASS)加载到R中,调用自带“老忠实”喷泉数据集geyer,它有两个变量:等待时间waiting和喷涌时间duration,其中…(1) 将等待时间70min以下的数据挑选出来;(2) 将等待时间70min以下,且等待时间不等于57min的数据挑选出来;(3) 将等待时间70min以下喷泉的喷涌时间挑选出来;(4) 将喷涌时间大于70min喷泉的等待时间挑选出来。
解:读取数据的R命令:library(MASS);#加载MASS包data(geyser);#加载数据集geyserattach(geyser);#将数据集geyser的变量置为内存变量(1) 依题意编定R程序如下:sub1geyser=geyser[which(waiting<70),1];#提取满足条件(waiting<70)的数据,which(),读取下标sub1geyser[1:5];#显示子数据集sub1geyser的前5行[1] 57 60 56 50 54(2) 依题意编定R程序如下:Sub2geyser=geyser[which((waiting<70)&(waiting!=57)),1];#提取满足条件(waiting<70& (waiting!=57)的数据.Sub2geyser[1:5];#显示子数据集sub1geyser的前5行[1] 60 56 50 54 60 ……原数据集的第1列为waiting喷涌时间,所以用[which(waiting<70),2](3)Sub3geyser=geyser[which(waiting<70),2];#提取满足条件(waiting<70)的数据,which(),读取下标Sub3geyser[1:5];#显示子数据集sub1geyser的前5行[1] ……原数据集的第2列为喷涌时间,所以用[which(waiting<70),2](4)Sub4geyser=geyser[which(waiting>70),1];#提取满足条件(waiting<70)的数据,which(),读取下标Sub4geyser[1:5];#显示子数据集sub1geyser的前5行[1] 80 71 80 75 77…….如光盘文件中的数据,一个班有30名学生,每名学生有5门课程的成绩,编写函数实现下述要求:(1) 以的格式保存上述数据;(2) 计算每个学生各科平均分,并将该数据加入(1)数据集的最后一列;(3) 找出各科平均分的最高分所对应的学生和他所修课程的成绩;(4) 找出至少两门课程不及格的学生,输出他们的全部成绩和平均成绩;(5) 比较具有(4)特点学生的各科平均分与其余学生平均分之间是否存在差异。

王静龙《非参数统计分析》课后习题计算题参考答案习题一1. One Sample t-test for a MeanSample Statistics for xN Mea n Std. Dev. Std. Error26Hypothesis TestNull hypothesis: Mea n of x = 0Alternative: Mea n of x A= 0t Statistic Df Prob > t2595 % Con fide nee In terval for the MeanLower Limit:Upper Limit:则接受原假设认为一样习题二1.描述性统计习题二S+=13 n 39H0: me 6500 H1: me 6500PS 13 二BINOMDIST(13,39,0.5,1)=0.026625957另外:在excel2010中有公式(n,p,a) 返回一个数值,它使得累计二项式分布的函数值大于或等于临界值a的最小整数* 1 n m* nm inf m :2 i 0 iBINO M」N V(39,0.5,0.05)=14*n1 *d nd=sup d : m 1 132 i 0 iS+13 d 13以上两种都拒绝原假设,即中位数低于6500inf c* :n ** 1 m nm inf m :-2 i 0 iBINOM.INV(40,0.5,1 -0.025)=26 d=n-c=40-26=14 x145800 x266400me x206200=0 2.S +=40 n 70H 0: me 6500 H 1: me 6500 2P S 402*(1-BIN0MDIST(39,70,0.5,1))=0.281978922则接受原假设,即房价中位数是 6500S +=1552 n 1552 527 2079H o : p H 1: pn 比较大,则用正态分布近似*1 nnc inf c :2 i c * i 2n m **1 m n m inf m :2i 0im=BINOM.INV(2079,0.5,0.975)=1084则拒绝原假设,即相信孩子会过得更好的人多P 为认为生活更好的成年人的比例,则1522p 的比估计是:一 =0.746513 20794.S18154 n 157860H 0: F 0.906 65 H 1: P 0.90665p 1 0.906 0.094S ~b(n,p) P S 181541 BIN0MDIST(18153,157860,0.094,1)因为0〈则拒绝原假设P S 15521039.5-1552+0.5「519.75 =5.33E-112另外:S +=1552n 1552527 2079习题四1.符号秩和检验统计量:W+=6+8+10+1+4+12+9+11+2+7=70 p值为2P W+70,当n=12得C o.o25 =65 所以p值小于2P W+65 =0.05即拒绝原假设2.符号秩和检验统计量:W+=2.5+2.5+7+7+7+7+10.5+14+14+14+14+14+17.5+17.5+19+20+23+24=234.5p值为2P W+234.5,当n=25 得c°.°25=236所以p值小于2P W+236 =0.05即接受原假设符号检验:S+18 n 26H 0: me 0 H1 : me 02P S 18 2*(1-BIN0MDIST(17,25,0.5,1))=0.043285251 则拒绝原假设t检验:t 统计量=0.861 df=25 p=0.3976接受原假设3.(1)W+=5+2+2=9 n 8查表可得:C o.025 33d n(n D c 30.025 0.02522P(W+3) 0.052P(W+9) 0.05则接受原假设Walsh平均由小到大排列:50 55 60 65 65 70 70 70 75 75 75 80 80 80 80 80 80 80 85 85 85 8585 90 90 90 90 90 90 95 95 95 95 95 95 100 100 100 100 100 100 100 105 105105 105 105 110 110 110 110 110 115 115 120AN=55则对称中心为W N 1 /2 W28 90d n n 1 /4 0.5 U1 /2“j n n 1 2n 1 /24 27.5 0.5 1.96 10 11 21/24 7.77101146c n n 1 /4 0.5 U1 /2 [ n n 1 2n 1 /24 27.5 0.5 1.96 .10 11 21/24 47.22898853因为c不是整数,则L介于讽k)与w(k+i)之间,其中k表示比d大的最小整数即为8AL为70与75之间,即为则H-L的点估计为9095%的区间估计为72.5,105习题五22800 25200 26550 26550 26900 27350 28500 28950 29900 30150 30450 30450 30650 30800 31000 31300 31350 31350 31800 32050 32250 32350 32750 32900 33250 33550 33700 33950 34100 34800 35050 35200 35500 35600 35700 35900 36100 36300 36700 37250 37400 37750 38050 38200 38200 38800 39200 39700 40400 4100050个和在一起的中位数是( 33250+33550) /2=33400p i 1P(i,24,25,50) 0.005060988p值很小,则拒绝原假设即认为女职工的收入比男职工的低。
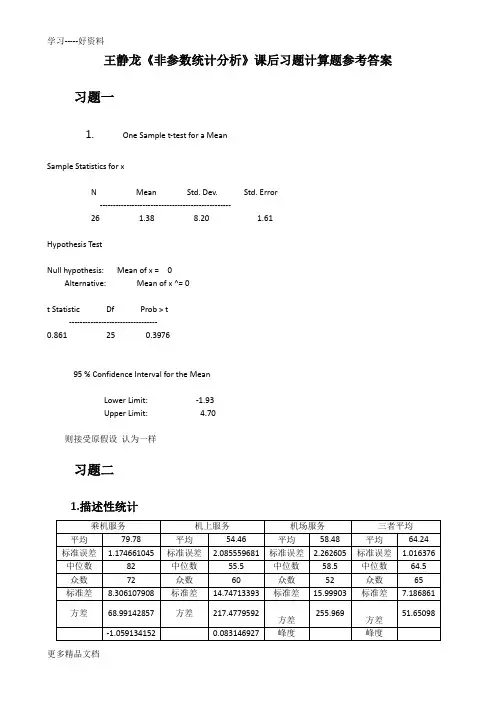
学习-----好资料更多精品文档王静龙《非参数统计分析》课后习题计算题参考答案习题一1.One Sample t-test for a MeanSample Statistics for xN Mean Std. Dev. Std. Error-------------------------------------------------26 1.38 8.20 1.61 Hypothesis TestNull hypothesis: Mean of x = 0Alternative: Mean of x ^= 0t Statistic Df Prob > t---------------------------------0.861 25 0.397695 % Confidence Interval for the MeanLower Limit: -1.93Upper Limit: 4.70则接受原假设认为一样习题二1.描述性统计更多精品文档习题三1.1{}+01=1339:6500:650013=BINOMDIST(13,39,0.5,1)=0.026625957S n H me H me P S +==<≤另外:在excel2010中有公式 BINOM.INV(n,p,a) 返回一个数值,它使得累计二项式分布的函数值大于或等于临界值a 的最小整数***0*0+1inf :2BINOM.INV(39,0.5,0.05)=141sup :1132S 1313n m i n d i n m m i n d d m i d αα==⎧⎫⎛⎫⎪⎪⎛⎫=≥⎨⎬⎪ ⎪⎝⎭⎝⎭⎪⎪⎩⎭⎧⎫⎛⎫⎪⎪⎛⎫≤=-=⎨⎬ ⎪ ⎪⎝⎭⎝⎭⎪⎪⎩⎭=≤=∑∑= 以上两种都拒绝原假设,即中位数低于65001.2学习-----好资料更多精品文档****01426201inf :221inf :122BINOM.INV(40,0.5,1-0.025)=26d=n-c=40-26=14580064006200nn i c n m i n c c i n m m i x x me x αα==⎧⎫⎛⎫⎪⎪⎛⎫=≤⎨⎬⎪ ⎪⎝⎭⎝⎭⎪⎪⎩⎭⎧⎫⎛⎫⎪⎪⎛⎫=≥-⎨⎬⎪ ⎪⎝⎭⎝⎭⎪⎪⎩⎭====∑∑2.{}+01=4070:6500:65002402*(1-BINOMDIST(39,70,0.5,1))=0.281978922S n H me H me P S +==≠≥=则接受原假设,即房价中位数是65003.1{}+01=15521552527207911::22n 1552=5.33E-112S n H p H p P S φ+=+==>≥≈比较大,则用正态分布近似**+**0:=1552155252720791inf :221inf :122m=BINOM.INV(2079,0.5,0.975)=1084nn i c n m i S n n c c i n m m i αα===+=⎧⎫⎛⎫⎪⎪⎛⎫=≤⎨⎬⎪ ⎪⎝⎭⎝⎭⎪⎪⎩⎭⎧⎫⎛⎫⎪⎪⎛⎫=≥-⎨⎬⎪ ⎪⎝⎭⎝⎭⎪⎪⎩⎭∑∑另外则拒绝原假设,即相信孩子会过得更好的人多3.2P 为认为生活更好的成年人的比例,则学习-----好资料更多精品文档1522=0.7465132079p 的比估计是:4.{}00.90610.90618154157860:65:6510.9060.094~(,)181541BINOMDIST(18153,157860,0.094,1)=0S n H P H P p S b n p P S +++===>=-=≥=-因为0〈0.05则拒绝原假设习题四1.()()++0.025+W =6+8+10+1+4+12+9+11+2+7=70p 2P W 70n=12c =65p 2P W 65=0.05≥≥符号秩和检验统计量:值为,当得所以值小于即拒绝原假设2.学习-----好资料更多精品文档()()++0.025+W =2.5+2.5+7+7+7+7+10.5+14+14+14+14+14+17.5+17.5+19+20+23+24=234.5p 2P W 234.5n=25 c =236p 2P W 236=0.05≥≥符号秩和检验统计量:值为,当得所以值小于即接受原假设{}011826:0:02182*(1-BINOMDIST(17,25,0.5,1))=0.043285251S n H me H me P S +===≠≥=+符号检验:则拒绝原假设学习-----好资料更多精品文档t t =0.861df=25 p=0.3976检验:统计量接受原假设3.(1)+0.0250.0250.025++=5+2+2=9833(1)322(3)0.052(9)0.05W n c n n d c P W P W ==+=-=≤=≤>查表可得:则 接受原假设Walsh 平均由小到大排列:50 55 60 65 65 70 70 70 75 75 75 80 80 80 80 80 80 80 85 85 85 8585 90 90 90 90 90 90 95 95 95 95 95 95 100 100 100 100 100 100 100 105 105学习-----好资料 更多精品文档105 105 105 110 110 110 110 110 115 115 120N=55 则对称中心为()()^281/290N W W θ+===()()1/1/1/40.527.50.5 1.967.771011461/40.527.50.5 1.9647.22898853d n n U c n n U αα--=+--=--==+++=++=因为c 不是整数,则^+1k d L k k w w θ()()介于与之间,其中表示比大的最小整数即为8 ^L θ为70与75之间,即为72.5 []-%72.5,105H L 则的点估计为90 95的区间估计为习题五1.171(,24,25,50)0.005060988i p P i p ===∑值很小,则拒绝原假设即认为女职工的收入比男职工的低。


非参数统计实验报告南邮概要非参数统计实验报告。
南邮概要。
在本次实验中,我们使用了非参数统计方法来分析数据,这些方法不依赖于总体参数的假设,适用于各种类型的数据分布。
我们的实验目的是研究南京邮电大学学生对校园生活满意度的情况。
首先,我们收集了一份问卷调查数据,包括学生对食堂、图书馆、宿舍等校园设施的满意度评分。
然后,我们使用了非参数统计方法,如Wilcoxon秩和检验和Mann-Whitney U检验,来分析这些数据。
这些方法可以帮助我们比较不同组之间的差异,而不需要假设数据服从特定的分布。
通过实验分析,我们发现学生对食堂的满意度评分显著高于对宿舍的评分,而对图书馆的评分则与宿舍的评分没有显著差异。
这些结果为学校改进校园设施提供了有益的参考。
总的来说,本次实验使用非参数统计方法成功地分析了南京邮
电大学学生对校园生活满意度的情况,为学校改进提供了有力的数据支持。
非参数统计方法的灵活性和适用性使得它们在实际应用中具有重要的价值,我们希望能够进一步探索和应用这些方法来解决更多的实际问题。

非参数考试题及答案一、单项选择题(每题2分,共10题)1. 非参数统计方法主要处理的是:A. 正态分布数据B. 非正态分布数据C. 离散型数据D. 连续型数据答案:B2. 斯皮尔曼等级相关系数适用于:A. 正态分布数据B. 非正态分布数据C. 有序分类数据D. 有序连续数据答案:B3. 曼-惠特尼U检验用于比较:A. 两个独立样本的均值B. 两个独立样本的中位数C. 两个配对样本的均值D. 两个配对样本的中位数答案:B4. 克鲁斯卡尔-瓦利斯检验用于:A. 单样本方差分析B. 双样本方差分析C. 多样本方差分析D. 配对样本方差分析答案:C5. 弗里德曼检验适用于:A. 单因素方差分析B. 双因素方差分析C. 多因素方差分析D. 配对样本方差分析答案:D6. 威尔科克森符号秩检验用于:A. 两个独立样本的比较B. 两个配对样本的比较C. 多个独立样本的比较D. 多个配对样本的比较答案:B7. 非参数检验中,不需要假设数据分布的是:A. t检验B. 方差分析C. 卡方检验D. 克鲁斯卡尔-瓦利斯检验答案:D8. 斯皮尔曼等级相关系数的取值范围是:A. -1到1B. 0到1C. -1到0D. 0到-1答案:A9. 以下哪个检验不是非参数检验:A. 曼-惠特尼U检验B. 克鲁斯卡尔-瓦利斯检验C. 弗里德曼检验D. 单样本t检验答案:D10. 非参数检验中,用于比较两个独立样本的秩次差异的是:A. 威尔科克森符号秩检验B. 弗里德曼检验C. 克鲁斯卡尔-瓦利斯检验D. 曼-惠特尼U检验答案:D二、多项选择题(每题3分,共5题)1. 以下哪些是非参数检验:A. 曼-惠特尼U检验B. 单样本t检验C. 克鲁斯卡尔-瓦利斯检验D. 威尔科克森符号秩检验答案:ACD2. 以下哪些检验适用于两个独立样本的比较:A. 曼-惠特尼U检验B. 威尔科克森符号秩检验C. 弗里德曼检验D. 克鲁斯卡尔-瓦利斯检验答案:AD3. 以下哪些检验适用于多个独立样本的比较:A. 威尔科克森符号秩检验B. 克鲁斯卡尔-瓦利斯检验C. 弗里德曼检验D. 曼-惠特尼U检验答案:BC4. 以下哪些检验适用于配对样本的比较:A. 单样本t检验B. 威尔科克森符号秩检验C. 弗里德曼检验D. 曼-惠特尼U检验答案:BC5. 以下哪些检验不需要假设数据的分布:A. 单样本t检验B. 曼-惠特尼U检验C. 克鲁斯卡尔-瓦利斯检验D. 威尔科克森符号秩检验答案:BCD三、简答题(每题5分,共2题)1. 请简述非参数检验与参数检验的主要区别。

非参数统计期末总结非参数统计方法的应用非常广泛,特别是在现实生活中遇到缺乏足够样本和总体分布不明确的情况下。
尤其在医学、环境科学、社会科学等领域,非参数统计更是不可或缺的工具。
下面我将总结一下非参数统计的相关知识和方法,并讨论它们在不同领域中的应用。
首先,非参数统计的最基本的方法是秩和检验(rank sum test)。
这种方法是通过对两个或多个独立样本的观测值进行排序和比较,来推断差异的统计显著性。
秩和检验可以用来检验两组样本的中位数是否有显著差异,例如比较两种不同药物治疗某种疾病的效果。
当然,在样本容量较大、总体分布近似正态时,也可以使用参数检验方法,例如t检验。
但是,当样本容量较小或者总体分布不明确时,秩和检验是一种更可靠的方法。
其次,非参数统计还包括Wilcoxon符号秩检验(Wilcoxon signed-rank test)、Kruskal-Wallis检验和Mann-Whitney U检验等。
这些方法分别用于比较配对样本、多个独立样本和两个独立样本的差异。
Wilcoxon符号秩检验可以用于比较两种不同治疗方法对同一组患者的疗效;Kruskal-Wallis检验可以用于比较多个组别的样本中位数是否有差异;Mann-Whitney U检验可以用于比较两组独立样本中位数是否有差异。
另外,非参数统计还可以用于对数据进行拟合和模型选择。
例如,通过对数据进行分组、拟合和调整,可以用非参数统计方法估计一个连续概率分布的分位数或者密度函数。
这对于描述和预测数据中的异常值、极端观测和长尾分布非常有用。
此外,非参数统计方法还可以用于衡量两个或多个总体之间的相关性和关联性,例如Spearman秩相关系数和Kendall秩相关系数。
非参数统计方法在医学研究中的应用非常广泛。
例如,在药物研发过程中,非参数统计可以用于比较不同剂量的药物对患者疗效的影响。
在临床试验中,非参数统计方法可以用于比较新药物和对照组的差异。

桂林电子科技大学试卷2012—2013学年第 2 学期课号课程名称非参数统计分析(机试)适用班级(或年级、专业)统计学考试时间95 分钟班级学号姓名一、(25分) 桂林市12年3月和13年6月出售的部分精品楼盘均价(单位:千元/平方米)数据分别如下所示:12年3月:7.0,4.3,8.0,4.2,8.5,4.2,8.2,4.2,4.15,4.6,3.5,3.8,4.5,8.7,4.3,5.513年6月:4.2,4.6,6.5,9.0,7.0,6.8,6.2,7.0,8.9,5.5,7.24.6试问:桂林市一年来楼盘价格是否有变化?解:用统计软件Minitab进行Mood中位数检验的步骤如下:1)输入数据:将3月的16指数点值数据输入到C1列的第1到第16个单元格,将6月的12个指数点值数据输入到C1列的第17到28个单元格中:2)输入数据的类别:在C2列中与C1列的数据相对应的第1到第16个单元格都输入“1”,在C2列中与C1列的数据相对应的的第17到28个单元格对输入“2”;结果如下图。
3)选择Stat下拉菜单中选择Nonparametrics选项;4)在Nonparametrics的下拉菜单中选Mood’s Median Test择子选项;5)在对话框的Response方框内键入C1,Factor方框内键入C2.单击OK即可。
主要运行结果及分析:图 1 Mood 中位数检验的输出结果从上图的输出结果可知,整体的中位数为5.5,此时在四格表中5.511 N 的个数是11,检验的p 值为0.063.所以认为桂林市一年来楼盘价格没有变化。
二、(25分) 某汽车驾驶员记录了使用5种不同牌子的汽油每5加仑行驶的距离(哩),数据如下:牌1: 38.5 32.3 31.6 31.5 牌2: 35.3 31.6 34.3 37.2 牌3: 39.0 39.9 44.4 45.9 牌4: 35.8 43.5 42.7 41.2 牌5: 40.3 31.9 36.5 35.8这些数据是否说明这5种牌子的汽油每加仑平均行驶的里程数全相等?解:用统计软件Minitab 进行Kruskal-Wallis 秩和检验的步骤如下:a.输入数据(如将来自牌1、牌2和牌3,牌4,牌5的数据输入到C1列的第1到第4个单元格、第5到第8个单元格和第9到第12个单元格,第13到第16单元格,第17到第20单元格);b.输入数据的类别(如与C1列的数据相对应,在C2列的第1个到第4个单元格都输入“1”,第5到第8个单元格输入“2”,第9到第12个单元格输入“3”,第13到第16个单元格输入“4”,第,17到第20个单元格输入“5”);c.选择Stat下拉菜单;d.选择Nonparametrics选项中的Kruskal-Wallis子选项;e.在Kruskal-Wallis对话框的Response方框中选择C1,Factor方框中选择C2,如下图。
非参数统计分析如果根据实践经验,人们知道产生数据的总体具有某种分布(例如正态分布),只是其中的参数值未知,那么在这种类型假设条件下的数据分析称为参数型的。
参数数据分析方法即利用数据的信息,又利用产生数据总体的信息,所以它是一个很有效的分析方法。
但是在实践中可能发生这样的情况,人们没有足够的实践经验,或者情况比较特殊,难以假设总体具有某种分布。
这时如果仍然使用参数数据分析方法,其统计分析的结果显然是不可信的,甚至有可能使错误的。
例题1:某工厂产品的零件由某个供应商供应。
合格零件标准长度为)1.05.8(±cm,即长度在8.4~8.6之间的零件是合格的。
抽100个数据检验,(数据见数据表)。
经计算,4958.8=x cm ,非常接近所要求的中心位置8.5cm.样本标准差为1047.0=s cm .一般来说,产品的质量指标往往服从正态分布。
因此,工厂使用参数数据分析方法来评估零件是否合格。
假设),(~2σμN X ,则(8.48.6)((8.68.4957)/0.1047)((8.48.4958)/0.1047)66%P X ≤≤=Φ--Φ-≈ 约有三分之一不合格。
这个统计分析与数据不符,因为有91%的产品是合格的。
例2:这里有22名企业职工,其中的12名职工来自企业1,另外的10名职工来自企业2,他们的工资如下:企业1 企业2113 124 135 146 157 168 179 1810 1930 2050 4060显然企业1的工资高。
假如假设企业1,企业2的工资分别服从正态分布,则这两个企业的职工工资的比较问题就化为一个参数的假设检验问题,b a H b a H >↔=::10。
由于两样本t 检验的统计量的值282.1=t ,显著性水平05.0=α的临界值为725.1)20(95.0=t ,所以我们不能拒绝原假设。
这个结论与数据不符。
因为,一般来说,工资、收入等的分布是不对称的,并且由于有一部分的收入比较高,所以分布的右边有比较长的尾巴,假设为正态分布不合适。
非参数统计分析习题四答案非参数统计分析习题四答案在统计学中,非参数统计方法是一种不依赖于总体分布形态的统计分析方法。
与参数统计方法相比,非参数方法更加灵活,适用范围更广。
本文将针对一些非参数统计分析习题提供详细的答案和解析。
1. 问题描述:某研究人员对一批新药进行了测试,得到了一组数据:[25, 30, 32, 28, 35, 27, 29, 31, 26, 34]。
现在需要对这组数据进行非参数的中位数检验,以验证该新药是否具有显著效果。
解答:中位数检验是一种常用的非参数检验方法,用于判断两个样本的中位数是否存在显著差异。
首先,我们需要对原始数据进行排序,得到:[25, 26, 27, 28, 29, 30, 31, 32, 34, 35]。
接下来,我们需要计算两组数据的中位数。
在这个例子中,我们只有一组数据,因此只需计算一次中位数。
根据数据的个数,中位数的计算方法有所不同。
当数据个数为奇数时,中位数即为排序后的中间值;当数据个数为偶数时,中位数为排序后的中间两个数的平均值。
根据以上方法,我们可以得到该组数据的中位数为29.5。
接下来,我们需要进行中位数检验。
中位数检验的零假设是两组数据的中位数相等,备择假设是两组数据的中位数不相等。
在这个例子中,我们只有一组数据,因此无法进行中位数检验。
2. 问题描述:某超市对两种不同品牌的牛奶进行了销售额的统计,得到了以下数据:品牌A:[120, 130, 110, 140, 150, 130, 160, 140, 150, 130]品牌B:[110, 120, 130, 140, 130, 150, 140, 160, 130, 150]现在需要对这两组数据进行非参数的Wilcoxon秩和检验,以验证两个品牌的销售额是否存在显著差异。
解答:Wilcoxon秩和检验是一种常用的非参数检验方法,用于判断两个相关样本之间的差异是否显著。
首先,我们需要对两组数据进行合并,并进行排序,得到:[110, 110, 120, 130, 130, 130, 130, 140, 140, 150, 150, 160]。
《非参数统计》试卷注意事项:1.本试卷适用于经济统计专业学生使用。
2.本试卷共6 页,满分100分,答题时间120分钟。
题号 一 二 三 四 总分 得分一、 选择题(本大题共10小题,每小题1分,共10分)1、以下对非参数检验的描述,哪一项是错误的( )。
A.非参数检验方法不依赖于总体的分布类型 B.应用非参数检验时不考虑被研究对象的分布类型 C.非参数检验的假定条件比较宽松D.非参数检验比较简便2、秩和检验又叫做( )A 、参数检验B 、Wilcoxon 检验C 、非参数检验D 、近似正态检验 3、( )同分校正后,统计量会变小。
A. Kruskal-Wallis 检验B.弗里德曼(Friedman )检验C. Mann-Whitney 检验D. Spearman 等级相关检验 4、配对比较的秩和检验的基本意思是:如果检验假设成立,则对样本来说( )。
A.正秩和的绝对值小于负秩和的绝对值 B.正秩和的绝对值大于负秩和的绝对值C.正秩和的绝对值与负秩和的绝对值不会相差很大D.正秩和的绝对值与负秩和的绝对值相等5、成组设计多个样本比较的秩和检验,当组数大于3时,统计量H 近似( )分布A 、正态B 、2C 、FD 、二项 6、Wilcoxon 符号秩检验不适用于( )。
A 位置的检验 B 连续总体 C 随机性的检验 D 配对样本的检验7、成组设计两样本比较的秩和检验中,描述不正确的是( )。
A .遇有相同数据,若在同一组,取平均秩次 B .遇有相同数据,若在同一组,按顺序编秩2.本评卷人C .遇有相同数据,若不在同一组,按顺序编秩D .遇有相同数据,若不在同一组,取其秩次平均值8、m=4,n=7,Tx=14的双侧检验,则( ) A. Ty=41,在显著性水平0.05时接受原假设 B. Ty=41,在显著性水平0.05时拒绝原假设 C. Ty=42,在显著性水平0.05时拒绝原假设 D. Ty=42,在显著性水平0.05时接受原假设 9、序列3 5 2 7 9 8 6的一致对数目为( )。
非参数统计真题答案及解析统计学作为一门重要的学科,对于量化研究各种现象和问题具有重要的作用。
在统计学中,参数统计和非参数统计是两个重要的分支。
参数统计是指根据总体的参数,通过样本数据对总体进行估计或假设检验。
而非参数统计则是在对总体参数没有明确假设的情况下,通过对样本数据的分析来进行统计推断。
本文将通过一些非参数统计的真题来深入讨论非参数统计的方法和应用。
一、Wilcoxon符号秩检验Wilcoxon符号秩检验是一种非参数的假设检验方法,用于比较两个相关配对样本的中位数是否存在差异。
该检验不依赖于数据的分布情况,适用于非正态分布的数据。
举例来说,某研究人员想要评估某种治疗方法对患者疼痛程度的影响。
该研究人员收集了30位患者的治疗前后的疼痛分数数据。
他们想知道,是否存在治疗前后的疼痛分数差异。
于是,他们可以使用Wilcoxon符号秩检验来判断。
在Wilcoxon符号秩检验中,我们的零假设(H0)是两组样本的中位数没有差异,而备择假设(H1)则是两组样本的中位数存在差异。
通过对样本数据进行计算,得到检验统计量的值,进而得到相应的p 值。
若p值小于给定的显著性水平(通常为0.05),则我们可以拒绝零假设,认为两组样本的中位数存在显著差异。
二、Mann-Whitney U检验Mann-Whitney U检验,又称为Wilcoxon秩和检验,是一种非参数的假设检验方法,用于比较两组独立样本的总体中位数是否存在差异。
该检验同样不依赖于数据的分布情况。
假设某研究人员想要比较两种不同的药物对患者血压的影响。
他们随机选择了一组患者,将他们分为两组,分别给予不同药物的治疗。
然后,他们测量了两组患者的血压数据,以了解是否存在差异。
在这种情况下,研究人员可以使用Mann-Whitney U检验进行分析。
在Mann-Whitney U检验中,我们的零假设(H0)是两组样本的中位数没有差异,而备择假设(H1)则是两组样本的中位数存在差异。
非参数统计试题及答案一、选择题1. 非参数统计方法是指在统计分析中不依赖于数据的分布形态的统计方法。
以下哪项不是非参数统计方法的特点?A. 不需要预先假定总体分布B. 对数据的分布形态要求严格C. 适用于小样本数据D. 可用于顺序变量和计数数据答案:B2. 以下哪个统计量是用来检验两个独立样本的中位数是否有显著差异的?A. t检验B. 方差分析C. Wilcoxon秩和检验D. 卡方检验答案:C3. 在非参数统计中,如果样本量很小,以下哪个方法可以用来估计总体分布?A. 直方图B. 箱线图C. 核密度估计D. 以上都是答案:D二、简答题1. 请简述非参数统计方法相对于参数统计方法的优势。
答案:非参数统计方法的优势在于它们不依赖于数据的分布形态,因此对于不符合正态分布的数据集也能适用。
此外,非参数方法通常对异常值不敏感,适用于小样本数据,并且可以处理顺序变量和计数数据。
2. 描述一下Kruskal-Wallis H检验的基本原理及其适用场景。
答案:Kruskal-Wallis H检验是一种非参数方法,用于比较三个或更多个独立样本的中位数是否存在显著差异。
其基本原理是将所有数据合并并进行秩次排序,然后比较各组的秩和。
如果所有组的中位数相同,则各组的秩和应该大致相等。
如果发现某个组的秩和显著高于或低于其他组,则该组的中位数可能与其他组存在显著差异。
该检验适用于样本量不均等、数据不满足正态分布或未知分布的情况。
三、计算题1. 假设有四个独立样本的数据如下,使用Kruskal-Wallis H检验来检验这四个样本的中位数是否有显著差异。
样本1: 10, 12, 8样本2: 15, 18, 20, 17样本3: 22, 25, 23, 24, 21样本4: 30, 28, 29, 27, 26答案:首先,将所有数据合并并进行秩次排序。
然后计算每个样本的秩和,接着使用Kruskal-Wallis H检验的公式计算H值。