运筹学软件(LINGO)简介
- 格式:pdf
- 大小:711.50 KB
- 文档页数:73




LINGO 程序设计介绍在运筹学中中会遇到如规划类的题型,在这种模型中总存在着一个目标,并希望这个目标的取值尽可能的大或小,同时与这个目标有关的一系列变量之间存在一些约束。
在构造出目标函数和约束条件的表达式后,我们需要对求出这个最值和各变量的取值。
一般我们用LINGO 来对模型进行求解,本文将通过举一个简单的例子,围绕这个例子逐步学习LINGO 的使用。
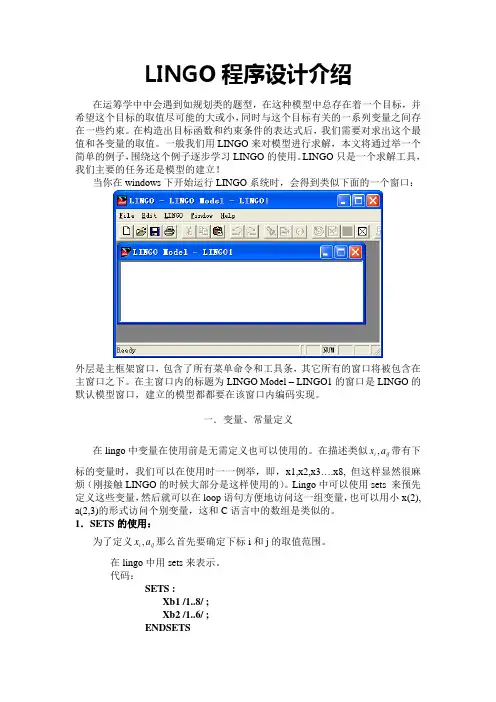
LINGO 只是一个求解工具,我们主要的任务还是模型的建立!当你在windows 下开始运行LINGO 系统时,会得到类似下面的一个窗口:外层是主框架窗口,包含了所有菜单命令和工具条,其它所有的窗口将被包含在主窗口之下。
在主窗口内的标题为LINGO Model – LINGO1的窗口是LINGO 的默认模型窗口,建立的模型都都要在该窗口内编码实现。
一.变量、常量定义在lingo 中变量在使用前是无需定义也可以使用的。
在描述类似ij i a x ,带有下标的变量时,我们可以在使用时一一例举,即,x1,x2,x3….x8, 但这样显然很麻烦(刚接触LINGO 的时候大部分是这样使用的)。
Lingo 中可以使用sets 来预先定义这些变量,然后就可以在loop 语句方便地访问这一组变量,也可以用小x(2), a(2,3)的形式访问个别变量,这和C 语言中的数组是类似的。
1.SETS 的使用:为了定义ij i a x ,那么首先要确定下标i 和j 的取值范围。
在lingo 中用sets 来表示。
代码:SETS :Xb1 /1..8/ ;Xb2 /1..6/ ;ENDSETS其中xb1、xb2分别为下标1..8 ,1..6的名字(sets_name),这些名字在loop语句中要使用。
对于sets_name一般将它命名为有意义的名称,这个sets_name必须以字母或下划线(_)开始。
二维下标是在两个一维下标定义的基础上给定的,定义a(i,j)下标的代码如下:SETS :Xb1 /1..8/;Xb2 /1..6/ ;Xb3 (xb1,xb2);ENDSETS现在下标已经定义完成了,定义数组变量时则需在下标后加上冒号再写上变量名,代码如下:SETS :Xb1 /1..8/:x,c,b ;Xb2 /1..6/ ;Xb3 (xb1,xb2):a;ENDSETS2.DATA的使用(常量定义):在lingo中把常量理解为已经被给定某常数的变量,在DATA 中对一些变量赋值,使之成为常量。

运筹学lingo实验报告(一)运筹学lingo实验报告介绍•运筹学是一门研究在给定资源约束下优化决策的学科,广泛应用于管理、工程、金融等领域。
•LINGO是一种常用的运筹学建模和求解软件,具有丰富的功能和高效的求解算法。
实验目的•了解运筹学的基本原理和应用。
•掌握LINGO软件的使用方法。
•运用LINGO进行优化建模和求解实际问题。
实验内容1.使用LINGO进行线性规划的建模和求解。
2.使用LINGO进行整数规划的建模和求解。
3.使用LINGO进行非线性规划的建模和求解。
4.使用LINGO进行多目标规划的建模和求解。
实验步骤1. 线性规划•确定决策变量、目标函数和约束条件。
•使用LINGO进行建模,设定目标函数和约束条件。
•运行LINGO求解线性规划问题。
2. 整数规划•在线性规划的基础上,将决策变量的取值限制为整数。
•使用LINGO进行整数规划的建模和求解。
3. 非线性规划•确定决策变量、目标函数和约束条件。
•使用LINGO进行非线性规划的建模和求解。
4. 多目标规划•确定多个目标函数和相应的权重。
•使用LINGO进行多目标规划的建模和求解。
实验结果•列举各个实验的结果,包括最优解、最优目标函数值等。
结论•运筹学lingo实验是一种有效的学习运筹学和应用LINGO的方法。
•通过本实验能够提高对运筹学概念和方法的理解,并掌握运用LINGO进行优化建模和求解的技能。
讨论与建议•实验过程中是否遇到困难或问题,可以进行讨论和解决。
•提出对于实验内容或方法的建议和改进方案。
参考资料•提供参考书目、文献、教材、网站等资料,以便学生深入学习和研究。
致谢•对与实验指导、帮助或支持的人员表示感谢,如老师、助教或同学等。
以上为运筹学lingo实验报告的基本框架,根据实际情况进行适当调整和补充。
实验报告应简洁明了,清晰表达实验目的、内容、步骤、结果和结论,同时可以加入必要的讨论和建议,以及参考资料和致谢等信息。

lingo在运筹学中的运用
Lingo在运筹学中是一类特别有用的工具,它是一种针对非线性优
化问题的建模语言。
它提供了一种实现复杂求解过程的有效方法,可
以帮助企业创建可衡量的、可控的模型,本质上提高解决难题的能力。
Lingo在运筹学中的应用如下:
一、数据建模
Lingo可以帮助企业更好地利用数据分析,通过数据可视化,实时监测,以及建立超级等式和复合对象,更好地实现数据建模。
这样可以提高
数据管理能力,让企业能够更好地组织、管理、分析及设计数据模型。
二、决策模型
Lingo可以帮助企业构建复杂的决策模型,允许运筹学家在多变量制约
条件下建立决策模型。
Lingo可以在多种应用场景中使用,从传统的精
确方程求解到组合优化多目标问题,从分布式系统的模拟到深度学习
的应用模型,Lingo都有着重要的用途。
三、数学优化
Lingo可以帮助企业有效地实现数学优化目标,在模型本身的表述上,Lingo具有更快的执行速度,并且可以处理大量的数量和变量,可以表
示复杂的最优化目标函数,从而提供最佳的运行数值。
四、机器学习
Lingo在运筹学中也可以应用于机器学习领域,可以用来构建收敛性更
强的机器学习模型,比如基于复杂决策树的模型,或者用Lingo设计的模型来处理视觉捕获和多机实时分析的问题。
总结:Lingo在运筹学中具有重要的作用,它可以帮助企业更加有效地实现数据建模、决策模型、数学优化和机器学习等方面的目标,进而提高企业的解决问题的能力。

LINGO 软件简介LINGO 软件是一个处理优化问题的专门软件,它尤其擅长求解线性规划、非线性规划、整数规划等问题.一个简单示例有如下一个混合非线性规划问题:⎪⎩⎪⎨⎧≥≤≤+++---+为整数2132121321322212121,;0,,210022..15023.027798max x x x x x x x x x x t s x x x x x x x .LINGO 程序模型:max =98x1+277x2-x1^2-0.3x1x2-2x2^2+150x3; x1+2x2+2x3<=100; x1<=2x2;gin x1;gin x2; Lingo 默认变量非负注意:binx 表示x 是0-1变量;ginx 表示x 是整数变量;bndL,x,U表示限制LxU ;freex 表示取消对x 的符号限制,即可正、可负.结果:Global optimal solution found.Objective value: 9561.200 Extended solver steps: 0 Total solver iterations: 45 Variable Value Reduced CostX1 6.000000 -76.70000X2 31.00000 -151.2000X3 16.00000 -150.0000Row Slack or Surplus Dual Price1 9561.200 1.0000002 0.000000 0.0000003 56.00000 0.000000———————— 非常简单在LINGO 中使用集合为了方便地表示大规模的规划问题,减少模型、数据表示的复杂程度,LINGO 引进了“集合”的用法,实现了变量、系数的数组化下标表示.例如:对⎪⎪⎩⎪⎪⎨⎧==-++-==≤++∑=.,,;10)0(;4,3,2,1),()())()1()(;4,3,2,1,20)(..)}(20)(450)(400{min4,3,2,1均非负INV OP RP INV I I DEM I OP I RP I INV I INV I I RP t s I INV I OP I RP I求解程序:model :sets :mark/1,2,3,4/:dem,rp,op,inv;也可以vmark/1..4/:dem,rp,op,inv;endsetsmin=sum mark:400rp+450op+20inv;也可以markI:400rpI+450opI+20invI;for markI: rpI<40;for markI|Igt1: invI=invI-1+rpI+opI-demI;inv1=10+rp1+op1-dem1;data:dem=40,60,75,35;enddataend上面程序在model…end之间有1集合定义、2数据输入和3其他三部分内容.集合定义部分从sets:到endsets:定义了一个指标集合mark可以理解为数组下标及其范围和其4个属性dem、rp、op、inv用此向量的数组变量.数据输入部分从data:到enddata依次给出常量dem的值.其他部分:给出优化目标及约束.一般而言,LINGO中建立优化模型的程序可以由五部分组成,或称为五段section:1集合段SETS:这部分以“SETS:”开始,以“ENDSETS”结束,作用在于定义必要的集合变量SET及其元素member,含义类似于数组的下标和属性attribute,含义类似于数组.2目标与约束段:这部分实际上定义了目标函数、约束条件等,但这部分没有段的开始和结束标记;该段一般常用到LINGO内部函数,尤其是和集合相关的求和函数SUM和循环函数FOR等.3数据段DATA:这部分以“DATA:”开始,以“ENDDATA”结束,作用在于对集合的属性数组输入必要的常数数据.格式为:attribute属性=value_list常数列表;常数列表中的数据之间可以用逗号、空格或回车符分隔.如果想要在运行时才对参数赋值,可以在数据段使用输入语句,其格式为“变量名=;”,但仅限对单个变量赋值,而不能用于属性变量数组的单个元素.4初始段INIT:这部分以“INIT:”开始,以“ENDINIT”结束,作用在于对集合的属性数组定义初值因为求解算法一般是迭代算法,提供一个较好的初值,能提高计算效果.定义初值的语句格式为:attribute属性=value_list常数列表;这与数据段中的用法类似.5计算段CALC:这部分以“CALC:”开始,以“ENDCALC”结束,作用在于对一些原始数据进行预处理加工,使其成为模型直接需要的数据.该段中通常是计算赋值语句.基本集合与派生集合为了处理二维数组变量等有多个下标的问题,LINGO引入了“派生集”的概念.我们把直接列出元素的指标集合叫“基本集合”,而基于其他集合派生出来的二维或多维指标集合称为“派生集”.派生集的定义格式为:派生集名原始集合1,原始集合2,…,原始集合n:属性变量列表;实际上就是笛卡儿积的意思,即:派生集={i1,i2, (i)n| i1集合1, i2集合2,…, in集合n}.1一个应用例子布局问题:某些建筑工地的位置用平面坐标a,b表示及水泥日用量d已知.现有A、B两临时料场位于P5,1、Q2,7,日储量20.问A、B两料场分别向各工地运输多少吨水泥,使总吨公里数最小若重新安排两料场的位置,应怎样安排才能使总吨公里数最小这样安排可节省多少吨公里设工地位置ai ,bi,水泥日用量为dii=1,2,…,6;料场位置xi,yi,日储量ej,j=1,2;从料场j向工地i运送量为cij.该问题的数学模型为:LINGO求解程序为:MODEL:sets:Imark/1..6/:a,b,d;Jmark/1,2/:x,y,e;IJmarkImark,Jmark:c;endsetsdata:Location for demand需求点位置;a=1.25,8.75,0.5,5.75,3,7.25;b=1.25,0.75,4.75,5,6.5,7.75;Quantities of the demand and supply供需量;d=3,5,4,7,6,11;e=20,20;enddatainit:Initial location for the supply初始点;x,y=5,1,2,7;endinitObjective function目标;OBJ min=sum IJmarki,j: ci,jxj-ai^2+yj-bi^2^1/2; demand contraints需求约束;for Imarki:DEMAND_CON SUM Jmarkj:ci,j=di;; supply constrains供给约束;for Jmarkj:SUPPLY_CON SUM Imarki:ci,j<=ej;;for Jmark: free x;free y;;2一个动态规划的例子:最短路问题从S城市到T城市之间找一条最短路径,道路情况如下:数学模型为:LINGO求解程序:model:sets:cities/s,a1,a2,a3,b1,b2,c1,c2,t/:L; 属性Li表示城市S到城市i的最优行驶路线的里程;roadscities,cities/ 派生集合roads表示的是网络中的道路;s,a1 s,a2 s,a3 由于并非所有城市间都有道路直接连接,所以将路具体列出;a1,b1 a1,b2 a2,b1 a2,b2 a3,b1 a3,b2b1,c1 b1,c2 b2,c1 b2,c2 属性Di,j是城市i到城市j的直接距离已知;c1,t c2,t/:D;endsetsD= 6 3 36 5 8 67 46 7 8 95 6;L=0,,,,,,,,; 因为Ls=0;enddatafor citiesi|igt index s: 这行中"indexs"可以直接写成"1";Li=min roadsj,i:Lj+Dj,i;; 这就是最短路关系式;endVariable ValueL S0.000000L A16.000000L A23.000000L A33.000000L B110.00000L B27.000000L C115.00000L C216.00000L T20.00000最短路径为: S-〉A3-〉B2-〉C1-〉T3指派问题设有6个人做6件事.其中cij表示第i人做第j事的收益;设第i人做第j事时xij =1,否则xij=0.该问题的规划模型:说明:其中“-”表示某人无法做该事.可令其为-表示绝对不行或0领薪不用干活LINGO求解程序:MODEL:sets:Imark/1..6/:i;Jmark/1..6/:j;IJmarkImark,Jmark:c,x;endsetsdata:第i人做第j事的收益;c=20,15,16,5,4,717,15,33,12,8,69,12,18,16,30,1312,8,11,27,19,14-99,7,10,21,10,32-99,-99,-99,6,11,13;enddataOBJ max=sum IJmarki,j: cx;每人做一项工作;for Imarki: SUM Jmarkj:xi,j=1;;每事一人做;for Jmarkj: SUM Imarki:xi,j=1;;for IJmark: bin x;本约束可以不要,因为有解时必为0或1; END4生产与销售计划问题某公司用两种原油A 和B 混合加工成两种汽油甲和乙.甲、乙两种汽油含原油A 的最低比例分别为50%和60%,每吨售价分别是4800元和5600元.该公司现有原油A 和B 的库存量分别为500吨和1000吨,还可以从市场上买到不超过1500吨的原油A.原油A 的市场价为:购买量不超500吨时单价为10000元/吨;购买量超过500吨但不超1000吨时,超过500吨部分单价为8000元/吨;购买量超过1000吨部分的单价是6000元/吨.该公司应如何安排原油的采购和加工以获得最大利润数学模型: 设原油A 用于生产甲、乙两种汽油的数量分别是x11和x12,原油B 用于生产甲、乙两种汽油的数量分别是x21和x22;购买原油A 的数量是x 吨,采购支出为cx 千元/吨.为了处理分段函数cx,将原油采购量x 分解为对应价格10千元/吨的采购量x1、对应对应价格8千元/吨的采购量x2和对应价格6千元/吨的采购量x3,它们应满足:0)500(21=-x x 表示要么x1=500要么x2=0,即x1的量不达到500时x2=00)500(32=-x x 表示要么x2=500要么x3=0,即x2的量不达到500时x3=0此时采购支出3216810)(x x x x c ++=模型改变为:LINGO 求解程序:model :init:x1=500;x2=500;x3=0;x12=1500;x22=1000;x11=0;x21=0;endinitmax=4.8x11+4.8x21+5.6x12+5.6x22-10x1-8x2-6x3; x11+x12<=x+500;x21+x22<=1000;0.5x11-0.5x21>=0;0.4x12-0.6x22>=0;x=x1+x2+x3;x1-500x2=0;x2-500x3=0;bnd0,x1,500;bnd0,x2,500;bnd0,x3,500;。



(1) LINGO 软件介绍LINGO 是一种专门用于求解数学规划问题的软件包。
LINGO 主要用于求解线性规划、非线性规划、二次规划、动态规划和整数规划等问题,也可以用于求解一些线性和非线性方程组及代数方程求根等。
LINGO 中包含了一种建模语言和大量的常用函数,可供使用者在建立数学规划问题的模型时调用。
(2) 示例例如,用LINGO 求解线性规划问题:⎪⎪⎪⎪⎩⎪⎪⎪⎪⎨⎧==≥≥+≥+≥+≥+≥+++≥++++++++++=4,3,2,1;2,1,01002001100170010002000..153751511572521min 241423132212211124232221141312112423222114131211j i x x x xx x x x x x x x x x x x x t s x x x x x x x x z ij只需要打开LINGO ,然后按照下面的操作进行即可。
1、 模型的输入当打开LINGO 后,屏幕将出现如图1所示的窗口。
标题为“LINGO ”的窗口是主窗口,它包含所有的其他窗口以及所有命令菜单和工具栏。
里面的空白窗口用于输入LINGO 的程序代码,代码格式如下:MODEL:图1min=21*x11+25*x12+7*x13+15*x14+51*x21+51*x22+37*x23+15*x24; x11+x12+x13+x14>=2000; x21+x22+x23+x24>=1000; x11+x21>=1700;x12+x22>=1100;x13+x23>=200; x14+x24>=100; END2、 执行从Solve 菜单选择Solve 命令,或者在窗口顶部的工具栏里按Solve 按钮,LINGO 就会先对模型进行编译,检查模型是否具有数学意义以及是否符合语法要求。
如果模型不能通过这一步检查,会看到报错信息,并指出出错的语句。
Lingo、lindo简介一、软件概述 (1)二、快速入门 (4)三、Mathematica函数大全--运算符及特殊符号 (11)参见网址: /一、软件概述(一)简介LINGO软件是由美国LINDO系统公司研发的主要产品。
LINGO是Linear Interactive and General Optimizer的缩写,即交互式的线性和通用优化求解器。
LINGO可以用于求解非线性规划,也可以用于一些线性和非线性方程组的求解等,功能十分强大,是求解优化模型的最佳选择。
其特色在于内置建模语言,提供十几个内部函数,可以允许决策变量是整数(即整数规划,包括 0-1 整数规划),方便灵活,而且执行速度非常快。
能方便与EXCEL,数据库等其他软件交换数据。
LINGO实际上还是最优化问题的一种建模语言,包括许多常用的函数可供使用者建立优化模型时调用,并提供与其他数据文件(如文本文件、Excel 电子表格文件、数据库文件等)的接口,易于方便地输入、求解和分析大规模最优化问题。
(二)LINGO的主要特点:Lingo 是使建立和求解线性、非线性和整数最佳化模型更快更简单更有效率的综合工具。
Lingo 提供强大的语言和快速的求解引擎来阐述和求解最佳化模型。
1 简单的模型表示LINGO 可以将线性、非线性和整数问题迅速得予以公式表示,并且容易阅读、了解和修改。
LINGO的建模语言允许您使用汇总和下标变量以一种易懂的直观的方式来表达模型,非常类似您在使用纸和笔。
模型更加容易构建,更容易理解,因此也更容易维护。
2 方便的数据输入和输出选择LINGO 建立的模型可以直接从数据库或工作表获取资料。
同样地,LINGO 可以将求解结果直接输出到数据库或工作表。
使得您能够在您选择的应用程序中生成报告。
3 强大的求解器LINGO拥有一整套快速的,内建的求解器用来求解线性的,非线性的(球面&非球面的),二次的,二次约束的,和整数优化问题。
LINGO目录简介步骤LINGO 综述编辑本段简介LINGO是Linear Interactive and General Optimizer的缩写,即“交互式的线性和通用优化求解器”,由美国LINDO系统公司(Lindo System Inc.)推出的,可以用于求解非线性规划,也可以用于一些线性和非线性方程组的求解等,功能十分强大,是求解优化模型的最佳选择。
其特色在于内置建模语言,提供十几个内部函数,可以允许决策变量是整数(即整数规划,包括0-1 整数规划),方便灵活,而且执行速度非常快。
能方便与EXCEL,数据库等其他软件交换数据。
编辑本段步骤一般地,使用LINGO 求解运筹学问题可以分为以下两个步骤来完成:1)根据实际问题,建立数学模型,即使用数学建模的方法建立优化模型;2)根据优化模型,利用LINGO 来求解模型。
主要是根据LINGO 软件,把数学模型转译成计算机语言,借助于计算机来求解。
例题:在线性规划中的应用max Z =5 X1+3 X2+6X3,s.t. X1 +2 X2 + X3 ≤182 X1 + X2 +3 X3 =16X1 + X2 + X3 =10X1 ,X2 ≥0 , X3 为自由变量应用LINGO 来求解该模型,只需要在lingo窗口中输入以下信息即可:max=5•x1 +3•x2 +6•x3 ;x1 +2•x2 + x3 <=18 ;2•x1 + x2+3•x3 =16 ;x1 + x2 + x3 =10 ;@free( x3) ;然后按运行按钮,得到模型最优解,具体如下:Objective value: 46.00000Variable Value Reduced Costx1 14.00000 0.000000x2 0.000000 1.000000x3 -4 .000000 0.000000由此可知,当x1 =14 , x2 =0 , x3 =-4 时,模型得到最优值,且最优值为46。