空间统计分析实验报告
- 格式:doc
- 大小:1.19 MB
- 文档页数:9

空间分析实践报告1. 引言本报告旨在对空间分析实践进行总结和分析。
空间分析是一种通过使用地理信息系统(GIS)软件和技术来研究和理解地理空间数据的方法。
本文将介绍空间分析的基本概念和方法,并结合实际案例展示空间分析的应用。
2. 空间分析基础知识2.1 空间数据空间数据是指与地理位置相关的数据。
常见的空间数据包括地图、地理坐标、地理区域等。
空间数据可通过全球定位系统(GPS)、遥感技术等手段获取。
2.2 空间分析方法空间分析方法是指用于处理和分析空间数据的技术和工具。
常见的空间分析方法包括:•空间查询:通过查询特定区域内的地理数据,以了解该区域的特征和属性。
•空间插值:通过已知的地理数据点来推断未知位置的数据值。
•空间关联:研究地理要素之间的空间关系,如距离、接近性等。
•空间模拟:通过模拟和模型构建,预测和分析未来的空间变化趋势。
•空间统计:通过统计方法对空间数据进行分析和解释。
3. 空间分析实践案例3.1 交通流量研究本案例旨在分析城市交通流量的分布情况,以便优化交通规划和道路设计。
通过收集城市各个路段的交通流量数据,并利用空间插值方法推断未知区域的交通流量,可以绘制出交通流量的热力图,便于决策者了解交通状况。
3.2 环境污染分析本案例旨在研究城市中不同区域的环境污染程度,以便采取相应的环境保护措施。
通过收集不同区域的污染排放数据,并利用空间统计方法对其进行分析,可以确定污染源的分布情况和影响范围,从而帮助环保部门制定有效的污染治理策略。
4. 空间分析的应用前景空间分析在许多领域都有广泛的应用前景。
以下是一些可能的应用领域:1.城市规划:利用空间分析方法,可以对城市的交通、环境、人口等进行综合研究,为城市规划提供科学依据。
2.自然资源管理:通过空间分析,可以对土地利用、水资源分布、森林覆盖等进行研究和管理,以实现可持续发展。
3.灾害风险评估:利用空间分析方法,可以对地震、洪水、火灾等自然灾害的潜在影响进行评估和预测,为灾害防治提供决策支持。

实验三空间统计分析引言:空间统计分析是地理信息科学中的一项重要技术,以空间数据为基础,通过空间统计模型和方法,研究地理现象在空间上的分布、关联、聚集和异质性等特征。
本实验将通过实例介绍空间统计分析的具体方法和步骤。
一、空间统计分析的数据准备1.空间数据的获取:空间统计分析的第一步是获取相关的空间数据,可以通过地理信息系统(GIS)软件或其他渠道获取。
2.数据准备:对于获取的空间数据,需要进行数据准备,包括数据清洗、数据格式转换等。
二、空间统计分析的基础1.空间数据的可视化:通过GIS软件将获取的空间数据进行可视化,以便更好地理解其分布特点。
2.空间数据的描述统计分析:对于空间数据的描述统计分析,可以计算其平均值、方差、标准差等统计指标,以及构建直方图、箱线图等统计图表以展现数据的分布特征。
三、空间结构分析1.空间自相关分析:空间自相关分析用于检验地理现象是否具有空间相关性。
常用的空间自相关分析方法包括莫兰指数、凝聚统计量等。
2.空间插值分析:空间插值分析用于通过已有的空间数据,推断未来或未知地点的空间属性。
常用的空间插值方法包括反距离加权插值法、克里金插值法等。
四、空间聚集分析1.点模式分析:点模式分析用于研究地理现象在空间上的聚集性,主要包括随机模式、聚集模式和离散模式等。
2.空间卷积分析:空间卷积分析用于确定地理现象的空间关联程度,并计算其空间关联程度指标。
五、空间异质性分析1.空间变差函数分析:空间变差函数分析用于研究地理现象在空间上的异质性。
常用的空间变差函数包括半方差函数、泰森多边形等。
2.空间回归分析:空间回归分析用于研究空间数据之间的关系,常用的方法包括普通最小二乘法、地理加权回归等。
六、实例分析:空气质量的空间分布分析本实例以城市不同监测点的空气质量数据为例,利用空间统计分析方法研究空气质量的空间分布特征。
1.数据获取和准备:从相关机构获取该城市不同监测点的空气质量数据,并进行数据清洗和格式转换。

第1篇一、实习背景随着我国经济的快速发展,地理信息产业已成为国家战略性新兴产业之一。
空间数据分析作为地理信息产业的核心技术之一,在资源管理、城市规划、环境保护、灾害预警等领域发挥着重要作用。
为了更好地了解空间数据分析在实际工作中的应用,提高自身专业技能,我于2021年7月至9月在XX公司进行了为期两个月的空间数据分析实习。
二、实习单位简介XX公司成立于2000年,是一家专业从事地理信息系统(GIS)技术研发、应用与服务的高新技术企业。
公司拥有丰富的项目经验,为客户提供从数据采集、处理、分析到可视化展示的一站式解决方案。
公司业务范围涵盖城市规划、土地管理、环境保护、交通运输等多个领域。
三、实习内容1. 实习岗位:空间数据分析实习生2. 实习工作内容:(1)数据采集与处理:学习如何从不同渠道获取空间数据,包括卫星遥感数据、地面调查数据、网络地图数据等,并掌握数据预处理方法,如数据清洗、坐标转换、数据压缩等。
(2)空间数据分析:学习空间分析基本原理,掌握常用空间分析工具,如缓冲区分析、叠加分析、网络分析等,并结合实际案例进行操作。
(3)空间可视化:学习地图设计与制作方法,掌握地图符号、颜色、注记等元素的使用,制作出美观、实用的地图产品。
(4)项目参与:参与公司实际项目,协助项目经理进行项目规划、实施与验收。
四、实习收获1. 专业技能提升:通过实习,我对空间数据分析的基本原理、方法与工具有了更深入的了解,掌握了数据采集、处理、分析、可视化等技能。
2. 实践经验积累:在实习过程中,我参与了多个项目,了解了项目实施的全过程,提高了自己的项目策划、执行与沟通能力。
3. 团队协作能力:在实习期间,我学会了与团队成员协作,共同完成项目任务,提高了自己的团队协作能力。
4. 行业认知:通过实习,我对地理信息产业有了更全面的了解,认识到空间数据分析在各个领域的应用价值。
五、实习总结1. 实习期间,我认真学习了空间数据分析的相关知识,掌握了基本技能,为今后的工作打下了坚实基础。

南阳师范学院本科学生实验报告姓名院(系)专业班级13级10班实验课程名称空间统计分析指导教师及职称范红艳讲师开课时间2013 至2014 学年二学期南阳师范学院教务处编印实验名称目录实验一:使用默认参数创建表面实验二:浏览数据实验三:绘制臭氧浓度图并进行模型比较实验四:对臭氧超出临界阈值的概率进行制图实验五:实验六:实验七:实验八:实验九:实验十:按钮。
8在图层属性对话框中,单击符号系统选项卡。
9在显示对话框中,单击数量,然后单击分级色彩。
10在字段框中,将值设置为OZONE。
11选择“黑色到白色”色带,以便这些点可以在本教程将要创建的颜色表面之上凸显出来。
符号系统对话框应如下所示:12单击确定。
请注意,最高的臭氧值出现在加利福尼亚州的中央峡谷(Central Valley) 地带,而最低值则出现在海岸沿线。
数据制图是探索数据和详细了解要进行建模的现象的第一步。
保存地图文档1在主菜单上,单击文件>保存。
2浏览至工作文件夹(例如,可创建下列文件夹来存储工作:C:\Geostatistical Analyst Tutorial)。
3在文件名文本框中,输入Ozone Prediction Map.mxd。
4单击保存。
您需要提供地图名称,因为这是对地图的第一次保存。
以后保存ArcMap文档时,只需单击保存即可使用默认选项创建表面1单击Geostatistical Analyst工具条上的Geostatistical Analyst箭头,然后单击地统计向导。
2在方法列表框中,单击克里金法/协同克里金法。
3单击源数据集箭头,然后单击O3_Sep06_3pm。
4单击数据字段箭头,然后单击OZONE属性。
5单击下一步。
默认情况下,普通(克里金法)和预测(地图)在对话框中处于选中状态。
选择臭氧表面的制图方法之后,即可单击完成来使用默认参数创建表面。
不过,步骤6 至10 会向您展示其他对话框。
在该向导的每一步中,可通过拖动内部面板(窗口)之间的分界线来调整它们的大小。

一、实验基本信息1. 实验名称:2. 实验时间:3. 实验地点:4. 实验人员:5. 实验指导教师:二、实验目的简要说明本次实验的目的,例如:- 掌握空间数据的基本概念和属性;- 熟悉常用的空间分析方法和技巧;- 通过实际案例分析,探索地理现象的空间分布规律;- 理解空间分析的原理及其在地理信息系统中的应用。
三、实验原理简要介绍实验所涉及的基本原理,例如:- 空间分析的定义和作用;- 常用的空间分析方法,如缓冲区分析、叠加分析、距离分析等;- 空间插值方法,如反距离权重插值法、样条插值法等。
四、实验数据1. 数据来源:说明实验所使用的数据来源,例如:地理信息系统(GIS)软件自带数据、公开数据平台、实地调查等。
2. 数据类型:说明实验所使用的数据类型,例如:矢量数据、栅格数据、点数据、线数据、面数据等。
3. 数据预处理:说明对原始数据进行处理的步骤,例如:数据清洗、数据转换、坐标系统转换等。
五、实验步骤1. 数据导入:将实验数据导入GIS软件。
2. 数据可视化:利用GIS软件进行数据可视化,例如:绘制地图、生成专题图等。
3. 空间分析:- 选择合适的空间分析方法,如缓冲区分析、叠加分析、距离分析等;- 设置分析参数,例如:缓冲区半径、叠加条件、距离阈值等;- 执行空间分析操作,生成分析结果。
4. 结果输出:将分析结果保存为图形文件或表格文件。
六、实验结果与分析1. 实验结果展示:展示实验结果,例如:缓冲区图、叠加图、距离分析图等。
2. 结果分析:对实验结果进行解释和分析,例如:- 分析地理现象的空间分布规律;- 解释空间分析结果对实际问题的意义;- 讨论实验结果与预期结果的差异。
七、实验总结1. 实验收获:总结本次实验的收获,例如:- 掌握了空间分析的基本方法;- 熟悉了GIS软件的操作;- 提高了地理信息分析能力。
2. 实验不足:分析实验过程中存在的问题和不足,例如:- 数据质量对实验结果的影响;- 空间分析方法的选择;- 实验操作技巧的掌握。

空间分析实验报告摘要本实验旨在通过空间分析方法探究不同空间特征对于人们行为和决策的影响。
通过对一组参与者进行实地调查和数据分析,我们得出了一些有关空间分析的重要结论。
本报告将详细介绍实验的设计、参与者的招募、数据的收集和分析过程,并呈现我们的主要发现。
介绍空间分析是地理学和城市规划等领域中重要的研究方法。
它关注的是空间特征、空间交互和空间行为之间的关系。
了解这种关系可以帮助我们更好地理解人们在不同环境中的行为和决策。
在本实验中,我们选择了几个常见的空间特征,例如建筑高度、道路密度和公共设施的分布等,以探究它们对人们行为的影响。
我们预计不同的空间特征将通过对人们的感知和交互产生不同的影响。
方法实验设计我们在城市中选择了三个不同的位置进行实地调查。
这些位置具有不同的空间特征,例如高层建筑密集、道路繁忙或公共设施丰富。
每个位置都设有观察点,参与者需要在观察点停留并完成一系列任务。
参与者招募我们通过社交媒体和本地志愿者组织招募了一百名年龄在18至35岁之间的参与者。
参与者需具备一定的城市规划和地理学知识,以保证实验结果的可靠性。
数据收集参与者在实地调查期间,我们使用了问卷调查和行为观察两种方式来收集数据。
问卷调查包括了参与者对所处环境的感知、对特定空间特征的评价以及其行为和决策的原因等。
行为观察则记录了参与者在观察点停留时的行为表现。
数据分析我们使用统计分析软件对收集到的数据进行了分析。
主要的分析方法包括描述统计、相关性分析和回归分析。
通过这些分析,我们得出了不同空间特征与人们行为和决策之间的关联。
结果根据我们的数据分析,我们得出了以下重要结果: 1. 高层建筑密集的区域更容易引起参与者的注意,但也会造成一定的压迫感。
2. 道路密度较高的区域导致参与者行走速度加快,但也增加了交通事故的风险。
3. 公共设施丰富的区域使参与者更愿意在该地区停留和进行社交活动。
讨论与结论本实验通过空间分析方法探究了空间特征对人们行为和决策的影响。
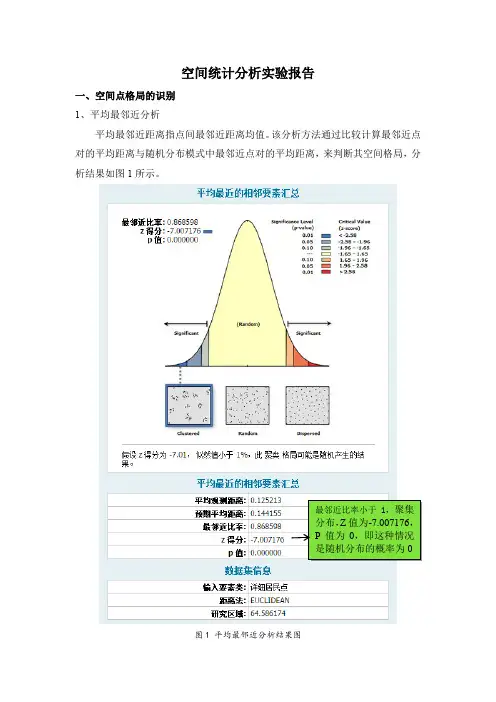
空间统计分析实验报告一、空间点格局的识别1、平均最邻近分析平均最邻近距离指点间最邻近距离均值。
该分析方法通过比较计算最邻近点对的平均距离与随机分布模式中最邻近点对的平均距离,来判断其空间格局,分析结果如图1所示。
图1 平均最邻近分析结果图最邻近比率小于1,聚集分布,Z值为-7.007176,P值为0,即这种情况是随机分布的概率为0计算结果共有5个参数,平均观测距离,预期平均距离,最邻近比率,Z 得分,P值。
P值就是概率值,它表示观测到的空间模式是由某随机过程创建而成的概率,P 值越小,也就是观测到的空间模式是随机空间模式的可能性越小,也就是我们越可以拒绝开始的零假设。
最邻近比率值表示要素是否有聚集分布的趋势,对于趋势如何,要根据Z值和P值来判断。
本实验中的最邻近比率小于1 ,聚集分布,Z值为-7.007176,P值为0,即这种情况是随机分布的概率为0,该结果说明云南省详细居民点的分布是聚集分布的,不存在随机分布。
2、多距离空间聚类分析基于Ripley's K 函数的多距离空间聚类分析工具是另外一种分析事件点数据的空间模式的方法。
该方法不同于此工具集中其他方法(空间自相关和热点分析)的特征是可汇总一定距离范围内的空间相关性(要素聚类或要素扩散)。
本实验中第一次将距离段数设为10,距离增量设为1,第二次将距离段数设为5,距离增量同样为1,得到如图2和图3所示的结果。
从图中可以看出,小于3千米的距离内,观测值大于预测值,居民点聚集,大于3千米,观测值小于预测值,居民点离散。
且聚集具有统计意义上的聚集,离散并未具有统计意义上的显著性。
图2 K函数聚类分析结果1小于3千米,居民点聚集,且聚集具有统计意义上的聚集,大于3千米,居民点离散,离散并未具有统计意义上的显著性图3 K函数聚类分析结果23、密度制图前面的最邻近分析和K函数聚类分析只能得到从数值上的出空间分布的状态,但并不能直观看到分布集聚或分散的位置、形状和大小。

实验二空间统计分析一、实验背景随着社会的飞速发展,GIS在各个领域的应用也不断扩展,特别是在流行病学、生物学、气象、地质等这些特殊的行业中,需要更深入的挖掘空间数据信息。
传统的GIS分析侧重于研究空间要素之间的关系,如相邻、叠加、以及要素之间的距离、连通性等,而这些特殊行业需要的则是根据多种采样的数据来研究空间事物的变化特征、分布特征等信息。
这些信息通常是一种统计分析的结果,而在空间上,事物的分布又是相互关联的。
所以,空间统计应运而生。
二、实验目的1、理解空间统计的含义,熟练利用ArcGIS9.3中的Spatial Statistics Tools进行空间统计相关操作,并理解其相关理论。
2、通过对ArcGIS9.3中Spatial Statistics Tools中部分功能的探索,培养学生利用ArcGIS 帮助文件及其它相关资料独立学习的能力。
三、实验数据1.全国县域点状矢量数据——countypoint.shp2.美国俄亥俄州县域面状矢量数据——ohcounties.shp实验数据下载地址:ftp:///空间分析实验课件四、实验内容所谓空间统计,就是将空间信息与属性信息进行统一的考虑,研究特定属性或属性之间与空间位置的关系。
空间统计主要的工作是研究空间自相关性(Spatial Autocorrelation),分析空间分布的模式,例如聚类(cluster)或离散(dispersed)。
空间分布模式分析(Analyzing Patterns)对于理解地理现象以及解决地理问题来说,识别地理模式是非常重要的。
尽管可以通过对要素绘图来了解它们的总体模式及其关联值,但通过计算统计数据能够将模式量化,更便于比较不同分布方式或不同时段的模式。
通过使用空间分布模式分析工具集,可以评估要素(或与要素关联的值)是形成一个聚类空间模式、离散空间模式还是随机空间模式。
1.平均最近邻点距离(Average Nearest Neighbor )最近邻点统计量最早是由Clark 和Evans (1954)这两位植物学家提出的,是基于各点与最靠近它的点之间距离的平均值计算出来的。
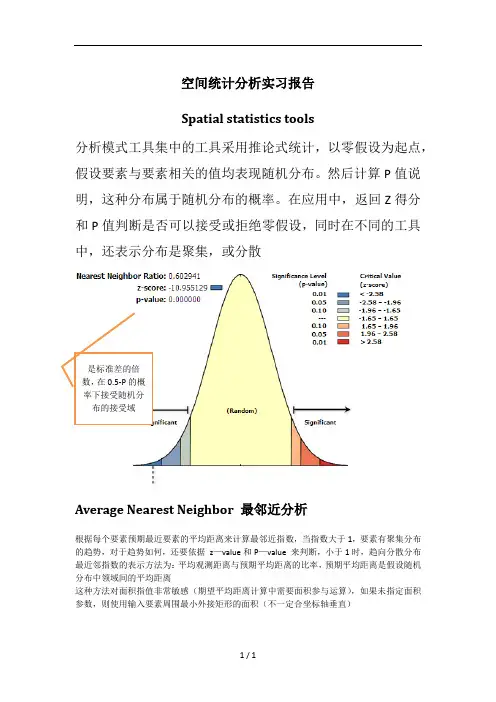
空间统计分析实习报告Spatial statistics tools分析模式工具集中的工具采用推论式统计,以零假设为起点,假设要素与要素相关的值均表现随机分布。
然后计算P值说明,这种分布属于随机分布的概率。
在应用中,返回Z得分和P值判断是否可以接受或拒绝零假设,同时在不同的工具中,还表示分布是聚集,或分散是标准差的倍数,在0.5-P的概率下接受随机分布的接受域Average Nearest Neighbor 最邻近分析根据每个要素预期最近要素的平均距离来计算最邻近指数,当指数大于1,要素有聚集分布的趋势,对于趋势如何,还要依据z—value和P—value 来判断,小于1时,趋向分散分布最近邻指数的表示方法为:平均观测距离与预期平均距离的比率,预期平均距离是假设随机分布中领域间的平均距离这种方法对面积指值非常敏感(期望平均距离计算中需要面积参与运算),如果未指定面积参数,则使用输入要素周围最小外接矩形的面积(不一定合坐标轴垂直)Spatial Autocorrelation (Morans I) 空间自相关分析更具要素位置的属性使用Global Moran’s I 统计量量测空间自相关性Moran’s I是计算所评估属性的均值和方差,然后将每个要素减去均值,得到与均值的偏差,将所有相邻要素的偏差相称,得到叉积。
统计量的分子便是这些叉积之和。
如果相邻要素的值均大于均值,这叉积为正,如果以要素小于均值而一要素大于均值,则为负如果数据集中的值倾向于在空间上集聚(高值聚集在高值附近,低值聚集在低值附近)则指数为正,如果高值排斥高值,倾向于低值,则指数为负之后,将计算期望指数值,将之与其比较,在给定的数据集中的要素个数和全部熟知的方差下,将计算Z得分和P值,用来指示次差异是否具有统计学上的显著性Multi-Distance Spatial Cluster Analysis K函数分析确定要素(后与之有关连的值)是否显示某一距离范围内统计意义显著的聚类或离散基于Ripley's K 函数的多距离空间聚类分析工具是另外一种分析事件点数据的空间模式的方法。

第1篇一、引言随着地理信息技术的快速发展,空间分析在各个领域中的应用日益广泛。
空间分析作为一种重要的数据处理方法,通过对地理空间数据进行挖掘和分析,可以揭示地理现象的空间分布规律和时空演变特征。
本报告旨在通过一次空间分析实践,探讨空间分析方法在实际问题中的应用,并总结经验与不足。
二、实践背景与目标1. 实践背景近年来,我国城市化进程不断加快,城市扩张对土地资源的需求日益增加。
如何合理规划土地利用,提高土地利用效率,成为城市规划和管理的重要课题。
本次实践以某城市土地利用规划为背景,通过空间分析技术,对城市土地利用现状进行分析,为土地利用规划提供科学依据。
2. 实践目标(1)分析城市土地利用现状,识别土地利用类型及其空间分布特征;(2)揭示城市土地利用变化规律,为土地利用规划提供决策支持;(3)评估土地利用变化对生态环境的影响,提出相应的生态保护措施。
三、数据来源与处理1. 数据来源本次实践所需数据主要包括以下几种:(1)土地利用现状数据:通过遥感影像解译和实地调查获取;(2)社会经济数据:包括人口、产业、基础设施等数据,从相关部门获取;(3)地形数据:通过地理信息系统(GIS)获取。
2. 数据处理(1)数据预处理:对原始数据进行质量检查、格式转换、坐标系统转换等;(2)数据集成:将不同来源的数据进行整合,形成统一的空间数据库;(3)空间分析:运用GIS软件进行空间分析,包括土地利用类型识别、空间分布分析、变化分析等。
四、空间分析过程1. 土地利用类型识别(1)遥感影像解译:利用遥感影像,通过人工解译和计算机辅助解译相结合的方法,识别土地利用类型;(2)土地利用分类:根据土地利用类型识别结果,对土地利用进行分类。
2. 空间分布分析(1)统计分析:对土地利用类型进行统计分析,包括面积、比例、分布密度等;(2)空间分布图:利用GIS软件,制作土地利用类型空间分布图,直观展示土地利用类型的空间分布特征。
3. 变化分析(1)变化检测:通过比较不同时期遥感影像,识别土地利用变化;(2)变化分析:分析土地利用变化的原因、影响和趋势。

空间分析课程实习报告一、实习目的与要求1. 实习目的通过本次空间分析课程实习,使学生掌握空间数据分析的基本方法,提高对地理信息系统(GIS)软件的操作能力,培养运用GIS技术解决实际问题的能力。
2. 实习要求(1)熟练掌握ArcGIS软件的基本操作;(2)了解空间数据的基本类型及处理方法;(3)掌握空间分析的方法,如缓冲区分析、叠加分析、路径分析等;(4)能够完成实际案例的空间分析操作。
二、实习内容与过程1. 实习内容本次实习主要分为以下几个部分:(1)空间数据的导入与处理;(2)空间数据的拓扑处理;(3)缓冲区分析;(4)叠加分析;(5)路径分析;(6)成果输出与报告撰写。
2. 实习过程(1)空间数据的导入与处理首先,我们导入了南昌市的基础空间数据,包括道路、绿地、建筑物和湖泊等。
在ArcCatalog中建立数据集,对各个数据进行属性表的建立和编辑,确保数据的完整性和准确性。
(2)空间数据的拓扑处理利用ArcGIS的拓扑功能,对导入的空间数据进行拓扑处理。
根据实际需求,设置相应的拓扑规则,检查和修正数据中的错误,如道路的相交、缺失等。
(3)缓冲区分析以道路和湖泊为例,进行缓冲区分析。
设置适当的缓冲距离,生成缓冲区图层,并进行颜色和标签的设置,以便于观察和分析。
(4)叠加分析将缓冲区图层与原有的绿地、建筑物图层进行叠加分析。
通过设置不同的叠加方式,分析不同图层之间的空间关系,如相交、包含等。
(5)路径分析利用ArcGIS的Network Analyst Tools模块,对道路网络进行路径分析。
设置起终点,选择合适的路径算法,生成最优路径,以便于进行交通规划等实际应用。
(6)成果输出与报告撰写最后,我们将分析结果进行整理和输出,包括图表、图片等形式。
并根据实习过程和成果,撰写实习报告,总结实习经验和收获。
三、实习收获与反思通过本次实习,我对空间分析的方法和技巧有了更深入的了解,提高了在ArcGIS软件上的操作能力。
一、实验目的1. 理解空间分析的基本概念和原理;2. 掌握常用的空间分析方法,如空间叠加、缓冲区分析、网络分析等;3. 运用ArcGIS软件进行空间分析实验,解决实际问题。
二、实验内容1. 数据准备本次实验采用我国某地区的矢量数据,包括行政区划、交通网络、土地利用等数据。
2. 空间叠加分析(1)目的:分析行政区划与交通网络的相互关系。
(2)步骤:① 打开ArcGIS软件,加载行政区划和交通网络数据;② 选择“分析”工具栏下的“叠加”工具;③ 设置叠加类型为“交集”;④ 选择输出图层,保存结果。
(3)结果分析:通过空间叠加分析,可以看出行政区划与交通网络的分布情况,为城市规划提供依据。
3. 缓冲区分析(1)目的:分析某地区河流对周边土地利用的影响。
(2)步骤:① 打开ArcGIS软件,加载行政区划、交通网络和河流数据;② 选择“分析”工具栏下的“缓冲区”工具;③ 设置缓冲区距离为500米;④ 选择输出图层,保存结果。
(3)结果分析:通过缓冲区分析,可以看出河流对周边土地利用的影响范围,为土地利用规划提供参考。
4. 网络分析(1)目的:分析交通网络的通达性。
(2)步骤:① 打开ArcGIS软件,加载行政区划、交通网络和居民点数据;② 选择“分析”工具栏下的“网络分析”工具;③ 设置网络分析类型为“最短路径”;④ 选择起点和终点,保存结果。
(3)结果分析:通过网络分析,可以看出居民点到交通网络的通达性,为交通规划提供依据。
三、实验结果与讨论1. 通过空间叠加分析,可以看出行政区划与交通网络的分布情况,为城市规划提供依据。
例如,在城市规划中,可以根据交通网络的分布情况,合理规划住宅区、商业区等。
2. 通过缓冲区分析,可以看出河流对周边土地利用的影响范围,为土地利用规划提供参考。
例如,在土地利用规划中,可以根据河流的分布情况,合理规划湿地保护区、农田保护区等。
3. 通过网络分析,可以看出居民点到交通网络的通达性,为交通规划提供依据。
空间分析实验报告空间分析实验报告概述:本次实验旨在通过空间分析技术,对特定区域的地理数据进行分析,以探索其内在的空间关系和模式。
实验过程中,我们使用了地理信息系统(GIS)软件,对一组城市人口分布数据进行了处理和分析,以期发现城市人口分布的空间模式和相关因素。
数据收集与预处理:我们选择了某国家的20个城市作为研究对象,通过收集相关的城市人口分布数据,构建了一个城市人口分布数据集。
为了保证数据的准确性和可靠性,我们从政府公开的统计数据中获取了每个城市的人口数量,并将其转化为数字化的空间数据。
数据分析与结果:在进行空间分析之前,我们首先对数据进行了预处理。
通过GIS软件,我们将每个城市的人口数量数据与其对应的地理位置进行关联,并将其转化为矢量数据。
接着,我们利用空间插值技术对数据进行了插值处理,以填补数据中的空洞和缺失值。
在数据预处理完成后,我们进行了一系列的空间分析操作。
首先,我们使用空间聚类分析方法,对城市人口分布数据进行了聚类分析。
通过聚类分析,我们发现了一些明显的人口集聚区域,这些区域往往是经济发展较为繁荣的城市核心区。
同时,我们还发现了一些人口分散的区域,这些区域往往是相对较为偏远或经济发展相对较弱的地区。
接着,我们进行了空间自相关分析,以探索城市人口分布的空间相关性。
通过计算空间自相关指数,我们发现了城市人口分布的空间聚集程度。
结果显示,城市人口分布存在显著的空间自相关性,即人口数量较多的城市往往周围也有较多的人口数量。
这一结果表明了人口分布的空间集聚特征,与城市的经济、交通等因素密切相关。
进一步地,我们进行了空间回归分析,以探究城市人口分布与其他因素之间的空间关系。
通过建立空间回归模型,我们发现了一些影响城市人口分布的关键因素。
例如,城市的经济发展水平、交通便利程度、教育资源等因素都对城市人口分布产生了显著影响。
这些结果为城市规划和发展提供了重要的参考依据。
结论与展望:通过空间分析实验,我们深入了解了城市人口分布的空间模式和相关因素。
一、实习背景随着我国经济社会的快速发展,空间数据在地理信息系统(GIS)、城市规划、环境保护、资源管理等领域发挥着越来越重要的作用。
为了提高我国空间数据采集、处理、分析和管理水平,本人在XX大学地理信息科学专业进行了一次为期两周的空间数据实习。
二、实习目的1. 熟悉空间数据采集、处理、分析和管理的基本流程;2. 掌握常用空间数据采集设备的使用方法;3. 学会使用ArcGIS等GIS软件进行空间数据处理和分析;4. 提高空间数据质量,为后续研究提供可靠的数据支持。
三、实习内容1. 空间数据采集实习期间,我们学习了全站仪、RTK、无人机等常用空间数据采集设备的使用方法。
通过实地操作,我们掌握了全站仪的测量原理、操作步骤以及RTK、无人机等设备的定位原理和操作技巧。
2. 空间数据处理在ArcGIS软件中,我们学习了空间数据的导入、编辑、转换、投影等基本操作。
通过实际操作,我们掌握了空间数据的拓扑检查、缓冲区分析、叠加分析等常用空间分析方法。
3. 空间数据分析实习期间,我们以XX市XX区为例,利用采集到的空间数据进行了一系列分析。
主要包括以下内容:(1)地形分析:通过分析地形高程、坡度、坡向等数据,了解该地区的地形特征。
(2)土地利用分析:通过分析土地利用类型、面积、分布等数据,了解该地区的土地利用现状。
(3)城市规划分析:根据土地利用现状和地形特征,对该地区的城市规划进行可行性分析。
4. 空间数据管理实习期间,我们学习了空间数据管理的基本知识,包括数据存储、备份、恢复等操作。
同时,我们还了解了空间数据质量控制的方法和标准。
四、实习体会1. 空间数据采集的重要性:通过实习,我深刻认识到空间数据采集在地理信息系统中的重要性。
只有采集到准确、完整的空间数据,才能为后续的分析和应用提供可靠的基础。
2. 空间数据处理与分析的技巧:实习期间,我学会了使用ArcGIS等GIS软件进行空间数据处理和分析。
这对我今后的学习和工作具有重要意义。
一、实验背景随着科学技术的不断发展,空间数据在地理信息系统(GIS)中的应用越来越广泛。
空间分析作为GIS的核心功能之一,通过对空间数据的处理和分析,为城市规划、资源管理、环境监测等领域提供决策支持。
本实验旨在让学生掌握空间分析的基本原理和方法,提高在实际工作中应用空间分析技术的能力。
二、实验目的1. 理解空间分析的基本原理和概念;2. 掌握常用空间分析方法,如空间插值、空间叠加、缓冲区分析等;3. 学会利用ArcGIS软件进行空间分析实验;4. 培养学生独立思考、解决问题的能力。
三、实验内容1. 实验一:空间插值(1)实验目的:了解空间插值原理,掌握常用空间插值方法。
(2)实验内容:以某地区降水量数据为例,采用反距离权重插值法(IDW)和样条插值法(Spline)进行空间插值,生成连续的栅格表面。
(3)实验步骤:1)导入实验数据;2)选择插值方法;3)设置插值参数;4)执行插值操作;5)输出结果并进行分析。
2. 实验二:空间叠加(1)实验目的:了解空间叠加原理,掌握常用空间叠加方法。
(2)实验内容:以某地区土地利用数据和植被覆盖数据为例,进行空间叠加分析,生成叠加结果。
(3)实验步骤:1)导入实验数据;2)选择叠加类型;3)设置叠加参数;4)执行叠加操作;5)输出结果并进行分析。
3. 实验三:缓冲区分析(1)实验目的:了解缓冲区分析原理,掌握常用缓冲区分析方法。
(2)实验内容:以某地区交通线路为例,进行缓冲区分析,生成不同距离的缓冲区。
(3)实验步骤:1)导入实验数据;2)设置缓冲区参数;3)执行缓冲区操作;4)输出结果并进行分析。
四、实验结果与分析1. 实验一:通过空间插值实验,成功生成了某地区降水量的连续栅格表面,为后续的水资源管理、灾害预警等提供了数据支持。
2. 实验二:通过空间叠加实验,成功生成了土地利用和植被覆盖的叠加结果,为土地规划、生态环境监测等领域提供了数据基础。
3. 实验三:通过缓冲区分析实验,成功生成了不同距离的缓冲区,为交通规划、土地利用等提供了决策依据。
第1篇一、实验背景随着科学技术的不断发展,空间分析技术在疾病研究中的应用越来越广泛。
空间分析能够帮助我们揭示疾病在空间上的分布规律,为疾病的预防、控制和治疗提供科学依据。
本实验旨在运用空间分析方法研究某地区某种疾病的分布特征,分析其与地理环境、人口学特征等因素的关系。
二、实验目的1. 分析该地区某种疾病的时空分布特征;2. 探讨疾病分布与地理环境、人口学特征等因素的关系;3. 为疾病预防、控制和治疗提供科学依据。
三、实验方法1. 数据收集:收集该地区某种疾病的病例数据、地理环境数据、人口学数据等;2. 空间数据预处理:对收集到的数据进行整理、清洗和转换,确保数据质量;3. 空间统计分析:运用空间自相关分析、空间回归分析等方法,分析疾病分布与地理环境、人口学特征等因素的关系;4. 空间可视化:运用地理信息系统(GIS)技术,将疾病分布、地理环境、人口学特征等信息进行可视化展示。
四、实验结果1. 疾病时空分布特征:通过空间自相关分析,发现该地区某种疾病在空间上呈现出明显的聚集性,主要集中分布在某个区域。
进一步分析发现,该区域地理环境、人口学特征等因素与疾病分布存在一定的关联。
2. 疾病分布与地理环境的关系:通过空间回归分析,发现该地区某种疾病的分布与地形、气候、水文等因素密切相关。
例如,海拔较高的地区发病率较高,湿润的气候有利于疾病的传播。
3. 疾病分布与人口学特征的关系:通过空间回归分析,发现该地区某种疾病的分布与人口密度、年龄结构、职业等因素有关。
例如,人口密度较高的地区发病率较高,老年人群发病率较高。
五、实验讨论1. 疾病分布的聚集性可能与地理环境、人口学特征等因素有关。
例如,地形、气候、水文等因素会影响疾病的传播和流行;人口密度、年龄结构、职业等因素会影响人群的暴露程度和免疫力。
2. 空间分析方法有助于揭示疾病分布的规律,为疾病预防、控制和治疗提供科学依据。
例如,针对疾病高发区域,可以加强卫生防护和健康教育;针对不同人群,可以采取针对性的预防措施。
一、实验背景随着地理信息系统(GIS)技术的不断发展,空间量算分析在各个领域得到了广泛应用。
空间量算分析是指利用GIS软件对空间数据进行量算和计算,以获取空间信息、分析空间关系和预测空间变化的过程。
本实验旨在通过ArcGIS软件进行空间量算分析,掌握空间量算的基本原理和方法,提高空间数据处理和分析能力。
二、实验目的1. 理解空间量算的基本原理和方法。
2. 掌握ArcGIS软件中空间量算分析的操作步骤。
3. 通过实验,提高空间数据处理和分析能力。
三、实验内容1. 数据准备本实验使用的数据为某城市土地利用现状数据,包括矢量数据和栅格数据。
矢量数据包括土地利用类型、道路、河流等要素,栅格数据为土地利用类型栅格图。
2. 实验步骤(1)空间叠加分析空间叠加分析是将两个或多个空间数据集按照一定的规则进行叠加,生成新的空间数据集。
本实验以土地利用类型矢量数据和道路矢量数据为例,进行空间叠加分析。
操作步骤:1)打开ArcGIS软件,导入土地利用类型和道路矢量数据。
2)选择“分析”菜单下的“空间分析”工具,选择“叠加”工具。
3)在叠加工具中,选择“相交”作为叠加方式。
4)设置输出参数,选择输出文件路径。
5)点击“确定”执行叠加操作。
(2)空间缓冲区分析空间缓冲区分析是指以一个点、线或面要素为中心,按照一定的距离设置缓冲区。
本实验以道路矢量数据为例,进行空间缓冲区分析。
操作步骤:1)打开ArcGIS软件,导入道路矢量数据。
2)选择“分析”菜单下的“空间分析”工具,选择“缓冲区”工具。
3)在缓冲区工具中,设置缓冲距离为500米。
4)设置输出参数,选择输出文件路径。
5)点击“确定”执行缓冲区分析。
(3)空间分析计算空间分析计算是指对空间数据进行数学运算,以获取新的空间信息。
本实验以土地利用类型栅格数据和道路矢量数据为例,进行空间分析计算。
操作步骤:1)打开ArcGIS软件,导入土地利用类型栅格数据和道路矢量数据。
2)选择“分析”菜单下的“空间分析”工具,选择“栅格计算器”工具。
空间统计分析实验报告
一、空间点格局的识别
1、平均最邻近分析
平均最邻近距离指点间最邻近距离均值。
该分析方法通过比较计算最邻近点对的平均距离与随机分布模式中最邻近点对的平均距离,来判断其空间格局,分析结果如图1所示。
图1 平均最邻近分析结果图最邻近比率小于1,聚集分布,Z值为-7.007176,P值为0,即这种情况是随机分布的概率为0
计算结果共有5个参数,平均观测距离,预期平均距离,最邻近比率,Z 得分,P值。
P值就是概率值,它表示观测到的空间模式是由某随机过程创建而成的概率,P 值越小,也就是观测到的空间模式是随机空间模式的可能性越小,也就是我们越可以拒绝开始的零假设。
最邻近比率值表示要素是否有聚集分布的趋势,对于趋势如何,要根据Z值和P值来判断。
本实验中的最邻近比率小于1 ,聚集分布,Z值为-7.007176,P值为0,即这种情况是随机分布的概率为0,该结果说明省详细居民点的分布是聚集分布的,不存在随机分布。
2、多距离空间聚类分析
基于Ripley's K 函数的多距离空间聚类分析工具是另外一种分析事件点数据的空间模式的方法。
该方法不同于此工具集中其他方法(空间自相关和热点分析)的特征是可汇总一定距离围的空间相关性(要素聚类或要素扩散)。
本实验中第一次将距离段数设为10,距离增量设为1,第二次将距离段数设为5,距离增量同样为1,得到如图2和图3所示的结果。
从图中可以看出,小于3千米的距离,观测值大于预测值,居民点聚集,大于3千米,观测值小于预测值,居民点离散。
且聚集具有统计意义上的聚集,离散并未具有统计意义上的显著性。
图2 K函数聚类分析结果1
小于3千米,居民点聚集,且聚集具有统
计意义上的聚集,大于3千米,居民点离
散,离散并未具有统计意义上的显著性
图3 K函数聚类分析结果2
3、密度制图
前面的最邻近分析和K函数聚类分析只能得到从数值上的出空间分布的状态,但并不能直观看到分布集聚或分散的位置、形状和大小。
密度制图根据输入点要素的数值及其分布来计算整个区域的密度分布状况,并产生一个连续的栅格图形,利用密度制图可以通过密度显示点的聚集情况。
图4 核密度制图结果
在核密度分析中,落入搜索区的点具有不同的权重,靠近网格搜索中心的点会被赋予较大的权重,随着与其网格中心距离的加大,权重降低。
图4中的值为详细居民点之间的距离的密度,从图中可以看出居民点密集的地方核密度分析的值越大,居民点越密集,如上图中用红色椭圆圈出来的区域,该地区位于滇东南,居民点比较密集,可能与该地区的地形、气候等因素有关。
二、中心位置测度分析
本实验中的测度分析包括省居民点的中心要素、平均中心和中位数中心,结果如图5所示。
中心要素表示居民点中处在最中心的居民点,平均中心计算的是所有居民点质心的平均中心,中位数中心计算的是可使所有居民点的欧式距离达到最小的点。
平均中心和中位数中心的计算以GDP为权重,所以计算出来的平均中心和中位数中心为省的经济中心,而中位数中心在计算的时候受异常值的影响较小,所以计算经济中心时一般以中位数中心为准,如图5中以GDP为权重计算出的中位数中心位于市,与市是省的经济中心相一致。
图5 中心位置测度分析结果中心要素平均中心中位数中心
三、离散度的测度分析
图6 离散度测度分析结果
离散度测度分析的结果如图6所示,本实验中的离散度分析采用的是标准距离和标准差椭圆。
标准距离创建的是一个包含以平均中心点为中心的圆面,半径为标准距离值,表示要素集中分布的围;标准差椭圆创建的椭圆的中心同样为平均中心,有两个不同的标准距离,表示要素集中分布的趋势。
本实验中的离散度分析以GDP为权重来进行分析,结果如图6所示。
图中的数据显示省居民点主要集中分布在中部和东部地区,是一个以安宁市为中心,半径为198千米的圆,说明省经济较发达的区域集中在以安宁市为中心的,半径为198千米的圆,集中分布的趋势为东北西南走向。
四、空间自相关和事物属性的空间分布格局
某类事物的出现(例如犯罪、某类用地、某居住空间等)是否造成了周边同类或异类事物或现象的出现,即空间是否自相关;找到某类事物或现象异常聚集的空间位置(例如低收入阶层聚集),以利于分析聚集的原因。
空间自相关是指分布于不同空间位置的地理事物,热门的某一属性存在同价相关性,通常距离越近的两值之间的相关性越大,具体可分为空间正相关和负相关,常用Moran指数来表示。
本实验通过分析来判断是否存在高收入和高收入聚集,低收入和低收入聚
集,或者高低收入相邻分布。
一般情况下,适度的集聚可以更有效地满足不同阶层人的需求,但过度的高高收入和低低收入聚集会加剧居住空间分异,阶层对立,也容易引发各类环境问题及社会矛盾,同时集聚也关乎社会资源的分配。
1、全局自相关统计
存在空间自相关
聚集分布
图7 全局自相关统计报表
对于Global Moran's I统计量,零假设声明,所分析的属性在研究区域的要素之间是随机分布的;换句话说,用于促进观察值模式的空间过程是随机的。
本实验中的z值为2.671575,大于0,表示省经济状况存在着空间自相关,存在
着聚集分布的趋势,即经济发达的地区周围的区域还是经济发达,经济落后区域周的区域还是经济落后,但是光靠Moran指数还无从判断是高高聚集还是低低聚集,可进一步采用高低聚类分析来判断是高高收入聚集还是低低收入聚集。
2、高、低聚类(Getis-Ord General G)
由于Moran's I指数不能判断空间数据是否显示高聚集还是低聚集,该分析也是用z值来检验空间自相关的统计显著性,但不同的是,z值得分为正值是意味着高高集聚,为负值意味着低低集聚。
高值聚集
图7 高、低聚类报表
最后得到的结果z值为4.519258,大于0,说明省的经济情况分布不均衡,存在着高高聚集的状态,正常情况下应该高低值都有,过于不均衡的聚集会导
致社会矛盾的出现,本实验中出现这个现象的原因可能是因为数据的问题,但
也不能排除这种高值聚集现象的出现。
应该看高值出现的区域具体是在哪里,根据该地区的情况来分析高值出现的原因。
五、空间模式分析—局部空间自相关
1、聚类和异常值分析
聚类和异常值分析, 用于发现局域空间是否存在空间自相关,他计算每一个空间单元与邻近单元就某一属性的相关程度。
HH为高高聚集,HL为高低聚集,LL为低低聚集。
从下图中可以看出,在和出现了几个高高聚集的点,其他的点均为无效的点,说明在省存在着一定的居民收入分布不均的情况,高收入主要集中在市、安宁市和市。
地区不用说是省的政治经济文化中心,其产业的发展是全省较好的,所以出现了高值;市距较近,交通发达,其烟草行业带动了该地区的经济发展,使得该地区的居民收入增加。
图8 聚类和异常值分析结果图
2、热点分析
热点分析是可以较准确地探测出局域空间自相关的有效方法,它能较准确地探测出聚集区域,而聚类和异常值分析(Anselin Local Moran I)对聚集围的识别偏差较大,能大致他侧出聚集区域的中心,但探测出的围小于实际围。
在上述聚类和异常值分析的实验中,实验结果表明市市区和安宁市以及市存在着高高聚集的,但是热点分析做出来的实验结果表明高高聚集这个状态的围更广,存在于市大大部分地区、市的少数地区以及市的武定县,而不是只有之前的三个地方。
p值小,z得分越大,高值聚集;z得分越小,低值聚集。
在下图中,热点分析值表示的市z得分下图表明,在省不存在者低低聚集的情况,这和实际有一定的区别,肯可能与实验的数据有关。
除了在和地区存在着高高聚集外,在市也存在着高高聚集,但是其聚集的显著情况低于和地区。
图9 热点分析结果图。