判别分析三种方法
- 格式:doc
- 大小:433.00 KB
- 文档页数:11

肾炎的诊断摘要医院就诊时通过一些化验指标来判断就诊人员是否患病的问题,本题是在已知确诊为肾炎患者和健康人的化验数据的前提下,寻找判别的方法并确定方法的准确性,最后对30名就诊人员的化验结果进行预测判定。
我们在对问题分析的基础上,提出了如下模型进行问题一的求解。
模型一:0-1模糊决策指标。
以确诊为健康人的数据为训练样本,得出其均值与标准差,由此确定健康人体内各种元素的估计范围,对训练样本的每个数据进行对应范围确定的判断,得出健康人的平均指标系数为6.1,以相同的标准应用于患者数据,以患者的决策指标是否达到6.1作为我们检验该判断方法优劣的标准。
经过编程检验,最终得出该方法的正确性为57%。
模型二:标准离差法确定权重系数。
以确诊为健康人的数据为训练样本,得出各种元素的标准差,某种元素的标准差越大,表明该指标的变异程度越大,提供的信息量越多,其权重也越大,在基于该前提下,计算各元素的权重系数,确定正常人的健康综合值,以此权重系数作用于确诊的肾炎患者,可得出该模型的准确性为80%。
模型三:判别分析法。
以确诊为患者和健康人的各类前15组化验结果作为训练样本,利用SPSS软件进行判别分析,得出对应得Fisher函数,以判别分析法的原则进行回代,得出该模型的误判率为3%,以Fisher函数作为标准作用于剩余的确诊观测样本,得出该模型的正确性为83%。
问题二的求解建立在模型二,三的基础上,判断为健康人的序号见下表。
模型二模型三健康人序号70,71,74,81,86,88,89 62,63,66,67,70,77,80,81,82,86,88,89 问题三:我们在判别分析法的基础上,为了实现减少化验指标的目的,采用逐步判别分析,建立模型四,以确诊类别的各20组数据作为训练样本,利用SPSS 软件求解该逐步判别分析法的结果为取用化验指标为Cu,Fe,Ca,以该三项指标作为肾炎的主要影响因素。
得出Fisher判别函数,训练样本误判率为20%,以余下观测样本检验其正确性为95%。


一.单项选择题1.多因素方差分析中观测变量总的离差平方和不包括()A.多个控制变量单独作用引起的离差平方和B.多个控制变量交互作用引起的离差平方和C.其它随机因素引起的离差平方和D.观测变量的非自然因素引起的离差平方和2. SPSS默认的字符型变量的对齐方式是()A. 右对齐B. 中间对齐C. 左对齐D. 以上说法都不对3.下列函数分布中,单样本的K-S检验不能将一个变量的实际频数分布与之比较的是()A.泊松分布B.均匀分布C. 正态分布D. 二项分布4. SPSS中创建数据文件时不能用来作为变量名的是()A. allB. abc1C. nameD. allby5. 线性回归分析对回归方程的检验不包括()A. 拟合优度检验B. 回归方程的显著性检验C. 回归系数的显著性检验D. 回归系数的相关性检验6. SPSS曲线估计中没有提供的曲线方程有()A. 指数函数B. 三次多项式C. 幂函数D. 三角函数7. 一个生产罐头食品的公司,某批500瓶罐头的中位数为498g,其含义是(变形)A. 500 瓶罐头的平均含量为每瓶498gB. 500 瓶罐头中,含量为498g的瓶数最多C. 500 瓶罐头中含量最多的一瓶为498gD. 250 瓶罐头的含量小于等于498g8. 下列统计量中不属于描述样本数据离散程度的是()A. 方差B. 标准差C. 众数D. 极差9. SPSS是一个模块化的软件,其扩充模块不包括()A. SPSS Statistics Base模块B. Categories模块C. Advanced Statistics模块D. Conjoint模块10. 在交叉列联表分析中,SPSS提供的相关系数的检验方法不包括()A. 卡方统计检验B. 列联系数C. V系数D. S系数11. 在系统聚类分析中,衡量样本数据与小类、小类与小类之间亲疏程度的方法不包括()A. 最短距离法B. 中间距离法C. 离差平方和D. 平均距离法12. 再信度分析实质是求同一量表在两次测试的相关系数,下列说法中错误的是()A. 所测量的特质必须稳定B. 遗忘和练习的效果相同C. 两次测试期间被试者对问题的熟悉情况没有差别D. 以上说法都不正确13. 时间序列分析中利用转换菜单中的替换缺失值命令对缺失值进行补充的方法不包括()A. 序列平均值B. 临近点均值法C. 线性插值法D. 临近点众数法14. 利用ANOV A 进行大、中、小城市的16岁女性青年的平均身高的比较,结果给出sig.=0.043,说明()A. 按照0.05显著性水平,三类城市16岁女性青年的身高没有显著差别B. 按照0.05显著性水平,三种城市16岁女性青年的身高有显著差异C. 大城市和中城市16岁女性青年的平均身高没有差别利用D. 大城市和小城市16岁女性青年的平均身高没有差别利用15. 做线性回归分析得如下的模型汇总表,则以下说法正确的是()A. 模型1的拟合程度最好B. 模型2的拟合程度最好C. 模型3的拟合程度最好D. 无法判断16.关于Recode和Automatic Recode的说法正确的是()A.前者的码字可以自己定义B.后者的码字可以自己定义C.前者的码字不可以自己定义D.以上说法都不对17. SPSS的主要变量类型不包括()A. 数值型B.字符型C. 日期型D. 英镑型λ=的泊松分布的有()18.下面能检验一个样本服从2A. T检验B.卡方检验C. K-S检验D. 游程检验19. 利用线性回归分析算得回归方程式:y=80x1-2.53x2+57x3,以下说法中错误的是()A.x1、x2和x3三个因素中,x2是对y 影响最小的因素B.在其它因素不变的情况下,x1 增加1个单位,y 增加80个单位C.x2和y变量为正直线相关D. x1、x2 和x3三个因素均对y有显著影响20.SPSS中无效的变量名有()A. @a1B. abc1#C.*homeD. cd_121.SPSS中的缺失值的替代方式不包括()A. 用变量的所有非缺失值的均数代替B. 用缺失值相邻点的非缺失值的中位数代替C. 用缺失值相邻两点的非缺失值的中点值代替D. 用线性插值方式确定替代值22. SPSS的基本运行方式不包括()A. 程序运行方式B. Include命令方式C. 完全窗口菜单运行方式D. 批处理运行方式23. 某公司生产的一批10000件产品质量的众数为498g,则()A. 10000 件产品的平均质量为498gB. 10000 件产品中,质量为498g的件数最多C. 10000 件产品中质量最大的为498gD. 10000 件产品中有5000件的质量小于等于498g24. 下列关于方差、峰度和偏度的说法中错误的是()A. 方差是所有变量值与平均数偏差平方的平均值B. 峰度是描述变量所有取值分布形态陡缓程度的统计量C. 偏度是描述变量所有取值分布对称性的统计量D. 除了偏度,方差和峰度都可以Analyze菜单的Descriptives计算25. 关于利用Sort by 对数据排序的描述错误的有()A. 排序变量可以是多个B. 排序变量最多一个C. 排序变量为多个时先按第一个排序,取值相同的再按第二个排,以此类推D. 观测个体所有变量的值都变到新位置26. SPSS作图中,下列不属于条形图的有()A. 简单条形图B. 堆栈条形图C. 复合条形图D. 差异区域图27. 关于样本的T 检验和非参数检验的说法正确的有 ( )A. T 检验要求样本服从或者近似服从正态分布B. 非参数检验要求样本服从或者近似服从正态分布C. 两种检验都要求样本服从或者近似服从正态分布D. 两种检验都不要求样本服从或者近似服从正态分布28. SPSS 软件的编辑窗口能打开的文件类型有 ( )A. *.stB. *.docC. *.xlsD. *.mat29. 两个独立样本的检验若采用cut point (如下图)对分类变量A 进行分组,并输入数值3,则分组的结果是 ( )A. 变量取值大于3的个案为一组,取值小于等于3的为一组B. 变量取值大于等于3的个案为一组,取值小于3的为一组C. 变量取值大于3的个案为一组,取值小于3的为一组D. 以上说法都不对30. 多个配对样本的非参数检验方法不包括 ( )A. Friendman 检验B. Kendall′s W 检验C. Cochran′s Q 检验D. Wilcoxon 检验31. 在合并a.sav 和b.sav 为ab.sav( 见下)时,是增加 。

什么是市场营销调研市场营销调研的内容市场营销调研是针对企业特定的营销问题,采用科学的研究方法,系统地、客观地收集、整理、分析、解释和沟通有关市场营销各方面的信息,为营销管理者制定、评估和改进营销决策提供依据。
以下是由店铺整理关于什么是市场营销调研的内容,希望大家喜欢!市场营销调研的营销分析市场营销数据分析一、多变量统计技术(一)回归分析。
(二)判别分析。
将两个或两个以上的群体根据某特征予以明确分类,使任何一个群体都归属于某一类,目的在于发现重要的判别变量,使之组合成为可预测的公式。
这种解决问题的方法,就是判别分析。
(三)因素分析。
二、测定尺度测量尺度的四种类型:名义尺度、顺序尺度、间距尺度、比例尺度的涵义和用途。
需求测量一、市场需求测量企业从事需求测量,主要是进行市场需求和企业需求两方面的测量和预测。
市场需求和企业需求的测量都包括需求函数、预测和潜量等重要概念。
(一)市场需求某个产品的市场需求是指一定的顾客在一定的地理区域、一定的时间、一定的营销环境和一定的营销方案下购买该产品的总量。
即使没有任何需求刺激,不开展任何营销活动,市场对某种产品的需求仍会存在,我们把这种情形下的销售额称为基本销售量(也称市场底量)。
在营销费用超过一定数量后,即使营销费用进一步增加,但市场需求却不再随之增加,一般把市场需求的最高界限称为市场潜量。
可扩张的市场,如服装市场、家电电器市场等,其需求规模受营销费用水平的影响很大。
不可扩张的市场,如食盐市场等,几乎不受营销水平的影响,其需求不会因营销费用增长而大幅度增长。
(二)市场预测与市场潜量市场需求预测一般要经过三个阶段,即环境预测、行业预测和企业销售预测。
市场需求预测的主要方法有:购买者意向调查法、销售人员综合意见法、专家意见法、市场试验法、时间序列分析法、直线趋势法、统计需求分析法。
同计划的营销费用相对应的市场需求就称为市场预测。
市场预测是估计的市场需求,但它不是最大的市场需求。

判别分析的原理
判别分析是一种统计方法和机器学习算法,用于解决分类问题。
其原理是将数据样本划分为不同的类别,并通过计算样本特征与类别之间的关联性,对未知样本进行分类。
对于给定的训练样本和其类别标签,判别分析通过计算样本特征与类别之间的统计关系来构建分类模型。
它假设不同类别的样本在特征空间上具有不同的概率分布,并通过最小化错误率或最大化分类准确率来找到最佳的分类边界。
常用的判别分析方法包括线性判别分析(LDA)和二次判别
分析(QDA)。
线性判别分析假设各类别样本的协方差相等,并通过计算类别之间的最佳线性判别边界将样本投影到低维空间中进行分类。
二次判别分析则放宽了协方差相等的假设,通过计算类别之间的最佳二次判别边界对样本进行分类。
判别分析可以采用监督学习的方法进行模型训练,然后使用该模型对新样本进行分类预测。
在实际应用中,判别分析广泛用于模式识别、图像处理、生物信息学等领域。
它具有较高的分类准确率和灵活性,并且可以对多类别问题进行有效处理。
总之,判别分析是一种基于样本特征与类别之间统计关系的分类方法,通过构建分类模型来实现对未知样本的分类预测。
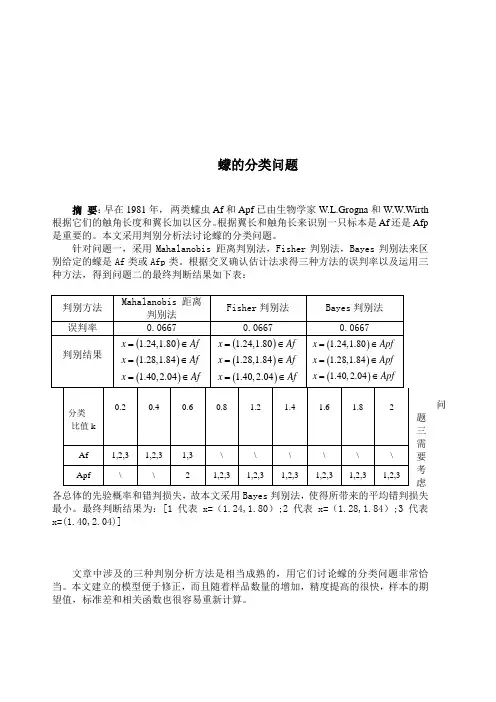
蠓的分类问题摘要:早在1981年,两类蠓虫Af和Apf已由生物学家W.L.Grogna和W.W.Wirth根据它们的触角长度和翼长加以区分。
根据翼长和触角长来识别一只标本是Af还是Afp是重要的。
本文采用判别分析法讨论蠓的分类问题。
针对问题一,采用Mahalanobis 距离判别法,Fisher判别法,Bayes判别法来区别给定的蠓是Af类或Afp类。
根据交叉确认估计法求得三种方法的误判率以及运用三种方法,得到问题二的最终判断结果如下表:问题三需要考虑各总体的先验概率和错判损失,故本文采用Bayes判别法,使得所带来的平均错判损失最小。
最终判断结果为:[1代表x=(1.24,1.80);2代表x=(1.28,1.84);3代表x=(1.40,2.04)]文章中涉及的三种判别分析方法是相当成熟的,用它们讨论蠓的分类问题非常恰当。
本文建立的模型便于修正,而且随着样品数量的增加,精度提高的很快,样本的期望值,标准差和相关函数也很容易重新计算。
关键字:Mahalanobis 距离判别法 Fisher判别法 Bayes判别法误判率错判损失先验概率一、问题重述两种蠓Af和Apf己由生物学家W.L.Grongan和W.W.Wirth(1981年)根据它们的触角长度和翼长加以区分(见图89A-1),6只Af蠓用“●”标记,9只Apf蠓用“○”标记。
问题一:给定一只Af或者Apf族的蠓,你如何正确地区分它属于哪一族?问题二:将你的方法用于触角长和翼长分别为(1.24,1.80)、(1.28,1.84)、(1.40,2.04)的三个标本。
问题三:设Af是宝贵的传粉益虫,Apf是某种疾病的载体,是否应该修改你的分类方法,若需修改,怎么改?二、模型假设与符号说明2.1模型假设1、两种蠓虫的触角长和翼长服从二元正态分布。
2、所给的样本数据是无误差的。
2.2符号说明2.2.1 问题一、二的符号说明Afx:Af族的均值向量Apfx:Apf族的均值向量AfS:Af族的协方差矩阵ApfS:Apf族的协方差矩阵X: 待判样本空间1G:Af族的总体2G:Apf族的总体2.2.2 文题三的符号说明:P总的误判概率;:L总的误判损失;(1/2):c把Apf误判为Af所引起的误判损失;(2/1):c把Af误判为Apf所引起的误判损失;1():f x类别Af的密度函数;2():f x类别Apf的密度函数;1:P类别Af的先验概率;2:P类别Apf的先验概率;三、问题分析3.1问题一、二的分析问题一要求根据某个个体的指标(触角长、翼长)值来判断该个体所属的类别。

经济师《工商管理》测试卷(含答案和解析)1、()影响税后利润。
A、债务杠杆B、总杠杆C、营业杠杆D、财务杠杆【参考答案】:D【解析】:营业杠杆影响税前利润,财务杠杆影响税后利润。
故选 D。
2、根据判别函数的形式,判别分析可以分为()。
A、逐步判别、序贯判别等B、线性判别和非线性判别C、距离判别、 Fisher 判别、 Bayes 判别等D、两组判别分析和多组判别分析【参考答案】:B【解析】:根据判别中的组数,可以分为两组判别分析和多组判别分析;根据判别函数的形式,可以分为线性判别和非线性判别;根据判别式处理变量的方法不同,可以分为逐步判别、序贯判别等;根据判别标准不同,可以分为距离判别、 Fisher 判别、 Bayes 判别等。
故选 B。
3、一家钢铁公司并购其原材料供应商—铁矿公司,属于()。
A、向前并购B、混合并购C、向后并购D、横向并购【参考答案】:C【解析】:纵向并购,即出于同类产品且不同产销阶段的两个或者多个企业所进行的并购。
这种并购可以是向前并购,也可以是向后并购。
向后并购,是指向其供应商的并购。
故选 C。
4、()是物流过程中“质”的升华。
A、运输B、储存C、流通加工D、包装【参考答案】:C【解析】:流通加工就是产品从生产到消费中间的一种加工活动,或者说是一种初加工活动。
它是社会化分工、专业化生产的新形式,是使物品发生物理性变化(如大小、形状数量等变化)的物流方式。
流通加工是物流过程中“质”的升华,使流通向更深层次发展。
故选 C。
5、如果问卷的预测试导致问卷产生较大的改动,应()。
A、进行正式问询调查B、进行第二次测试C、保持原问卷不变D、重新采集信息【参考答案】:B【解析】:问卷获得管理层的最终认可后,还必须进行预测试。
在没有进行预测试前,不应当进行正式的问询调查。
在预测试完成后,任何需要改变的地方应当切实修改。
在进行实地调研前应当再一次获得各方的认同。
如果预测试导致问卷产生较大的改动,应进行第二次测试。




判别分析与聚类分析判别分析与聚类分析是数据分析领域中常用的两种分析方法。
它们都在大量数据的基础上通过统计方法进行数据分类和归纳,从而帮助分析师或决策者提取有用信息并作出相应决策。
一、判别分析:判别分析是一种有监督学习的方法,常用于分类问题。
它通过寻找最佳的分类边界,将不同类别的样本数据分开。
判别分析可以帮助我们理解和解释不同变量之间的关系,并利用这些关系进行预测和决策。
判别分析的基本原理是根据已知分类的数据样本,建立一个判别函数,用来判断未知样本属于哪个分类。
常见的判别分析方法包括线性判别分析(LDA)和二次判别分析(QDA)。
线性判别分析假设各类别样本的协方差矩阵相同,而二次判别分析则放宽了这个假设。
判别分析的应用广泛,比如在医学领域可以通过患者的各种特征数据(如生理指标、疾病症状等)来预测患者是否患有某种疾病;在金融领域可以用来判断客户是否会违约等。
二、聚类分析:聚类分析是一种无监督学习的方法,常用于对数据进行分类和归纳。
相对于判别分析,聚类分析不需要预先知道样本的分类,而是根据数据之间的相似性进行聚类。
聚类分析的基本思想是将具有相似特征的个体归为一类,不同类别之间的个体则具有明显的差异。
聚类分析可以帮助我们发现数据中的潜在结构,识别相似的群组,并进一步进行深入分析。
常见的聚类分析方法包括层次聚类分析(HCA)和k-means聚类分析等。
层次聚类分析基于样本间的相似性,通过逐步合并或分割样本来构建聚类树。
而k-means聚类分析则是通过设定k个初始聚类中心,迭代更新样本的分类,直至达到最优状态。
聚类分析在市场细分、社交网络分析、图像处理等领域具有广泛应用。
例如,可以将客户按照他们的消费喜好进行分组,以便为不同群体提供有针对性的营销活动。
总结:判别分析和聚类分析是两种常用的数据分析方法。
判别分析适用于已知分类的问题,通过建立判别函数对未知样本进行分类;聚类分析适用于未知分类的问题,通过数据的相似性进行样本聚类。
利用SPSS进行判别分析的几个问题的说明陈敏琼【摘要】判别分析是多元统计分析中最常用的方法之一,但由于其原理的复杂性与方法的多样性,使其成为《多元统计分析》课程学习特别是SPSS软件操作学习的难点之一。
为此,对判别分析的几种方法的原理进行总结,针对利用SPSS进行判别分析过程中常见的若干疑点,先从理论上做推导说明,结合例子对SPSS判别分析的步骤和输出结果作详细解释和说明。
%Discriminant analysis is one of the most commonly used methods in multivariate statistical analysis, but because of the complexity of its principle and methods of diversity, making it one of the difficulties in learning the course of Multivariate Statistical Analysis, in particular the learning of SPSS software operating. To do this, summaries the principle of several methods of discriminant analysis, according to the common problems of SPSS in the process, does the first theoretical derivation, combined with examples, explains the steps and output re-sults of SPSS discriminant analysis in details.【期刊名称】《现代计算机(普及版)》【年(卷),期】2015(000)002【总页数】7页(P34-39,50)【关键词】判别分析;SPSS判别分析;步骤;解释说明【作者】陈敏琼【作者单位】中山大学新华学院,广州 510520【正文语种】中文判别分析是根据观测到的样品的若干数量特征(称为因子或判别变量)对样品进行归类、识别,判断其属性的预报(预测)的一种多元统计分析方法。
2.实验内容(1)自选数据或者使用例题4-1、4-2数据完成判别分析。
(2)对判别分析结果进行分析。
(3)选定两个样本,对样本进行分类。
3.实验步骤例4-1:判别分析的一个重要应用是动植物的分类,最著名的一个例子是1936年费歇的鸢尾花数据。
鸢尾花为法国的国花,Setosa、erisolor、Virginica是三种有名的鸢尾花,其萼片是绚丽多彩的,和向上的花瓣不同,花萼是下垂的。
这三种鸢尾花很像,人们试图建立模型,根据萼片和花瓣的四个角度来对鸢尾花分类。
该数据给出150朵鸢尾花的萼片长(sepal length)、萼片宽(sepal length)、花瓣长(petal width)、花瓣宽(petal width)以及这些分别属于的种类共五个变量。
萼片和花瓣的长度为四个定量变量,而种类为分类变量。
这里三种鸢尾花各有50个观测值。
对数据进行判别分析的得到的分析结果如下:表1-1 分析觀察值處理摘要未加權的觀察值N 百分比有效150 100.0已排除遺漏或超出範圍群組代碼0 .0至少一個遺漏區別變數0 .0遺漏或超出範圍群組代碼及至0 .0少一個遺漏區別變數總計0 .0總計150 100.0输出结果表1-1分析的是各组变量的描述统计量和对各组均值是否相等的检验。
反应的是有效样本变量及变量缺失情况。
表1-2 群組統計資料被解释变量平均數標準偏差有效的 N (listwise)表1-5 測試結果Box's M 共變異等式檢定146.663F 近似值7.045df1 20df2 77566.751顯著性.000檢定相等母體共變異數矩陣的虛無假設。
输出结果1-4和表1-5是对各组协方差矩阵是否相等的Boxs’M检验。
表1-4反映协方差矩阵的秩和行列式的对数值。
由行列式值可以看出,协方差矩阵不是病态矩阵。
表1-5是对个总体协方差矩阵是否相等的统计检验。
由F值及其显著性水平,我们在0.05的显著性水平下拒绝原假设。
距离判别法、贝叶斯判别法和费歇尔判别法的异同引言在模式识别领域,判别分析是一种常用的方法,用于将数据样本划分到不同的类别中。
距离判别法、贝叶斯判别法和费歇尔判别法是判别分析中常见的三种方法。
本文将对这三种方法进行比较,探讨它们的异同。
一、距离判别法距离判别法是一种基于距离度量的判别分析方法。
它的基本思想是通过计算样本点与各个类别中心的距离,将样本划分到距离最近的类别中。
常见的距离判别法有欧氏距离判别法和马氏距离判别法。
1. 欧氏距离判别法欧氏距离判别法是一种简单直观的距离判别方法。
它通过计算样本点与各个类别中心之间的欧氏距离,将样本划分到距离最近的类别中。
算法步骤如下: 1. 计算各个类别的中心点,即各个类别样本点的均值向量。
2. 对于给定的待判样本点,计算其与各个类别中心点的欧氏距离。
3. 将待判样本点划分到距离最近的类别中。
2. 马氏距离判别法马氏距离判别法考虑了各个类别的协方差矩阵,相比于欧氏距离判别法更加准确。
它通过计算样本点与各个类别中心之间的马氏距离,将样本划分到距离最近的类别中。
算法步骤如下: 1. 计算各个类别的中心点,即各个类别样本点的均值向量。
2. 计算各个类别的协方差矩阵。
3. 对于给定的待判样本点,计算其与各个类别中心点之间的马氏距离。
4. 将待判样本点划分到距离最近的类别中。
二、贝叶斯判别法贝叶斯判别法是一种基于贝叶斯理论的判别分析方法。
它的基本思想是通过计算后验概率,将样本划分到具有最高后验概率的类别中。
常见的贝叶斯判别法有贝叶斯最小错误率判别法和贝叶斯线性判别法。
1. 贝叶斯最小错误率判别法贝叶斯最小错误率判别法是一种理论上最优的判别方法。
它通过计算后验概率,将样本划分到具有最高后验概率的类别中。
算法步骤如下: 1. 计算各个类别的先验概率。
2. 计算给定样本点在各个类别下的条件概率。
3. 计算给定样本点在各个类别下的后验概率。
4. 将待判样本点划分到具有最高后验概率的类别中。
作业一:
为研究1991年中国城镇居民月平均收入状况,按标准化欧氏平方距离、离差平方和聚类方法将30个省、市、自治区.分为两种类型。
试建立判别函数,判定广东、西藏分别属于哪个收入类型。
判别指标及原始数据见表9-4。
1991年30个省、市、自治区城镇居民月平均收人数据表
单位:元/人 x1:人均生活费收入 x6:人均各种奖金、超额工资(国有+集体) x2:人均国有经济单位职工工资 x7:人均各种津贴(国有+集体)
x3:人均来源于国有经济单位标准工资 x8:人均从工作单位得到的其他收入
x4:人均集体所有制工资收入 x9:个体劳动者收入
x5:人均集体所有制职工标准工资
一、距离判别法
解:变量个数p=9,两类总体各有11个样品,即n1=n2=11 ,有2个待判样品,假定两总体协差阵相等。
由spss可计算出:协方差和平均值
合计x1 123.2881 23.27817 22 22.000
x2 80.4895 22.04796 22 22.000
x3 50.8709 6.14867 22 22.000
x4 10.1450 3.11887 22 22.000
x5 6.0659 2.72297 22 22.000
x6 14.6060 6.73264 22 22.000
x7 15.7215 6.64603 22 22.000
x8 8.7895 3.02700 22 22.000
x9 1.5291 1.31496 22 22.000
知道了均值和协方差可利用matlab计算线性判别函数W(x)的判别系数a和判别常数。
程序如下:
v=[1.000,0.217,0.299,0.045,-0.054,0.688,0.212,0.121,-0.245;.217,1,.102,-.234,-.211,. 136,-.052,.116,.154;.299,.102,1,-.296,-.062,.091,-.017,-.607,-.034;.045,-.234,-.296,1,. 762,-.172,-.297,.103,-.554;-.054,-.211,-.062,.762,1,-.156,-.342,.022,-.654;.688,.136,.0 91,-.172,-.156,1,.235,.384,-.098;.212,-.052,-.017,-.297,-.342,.235,1,-.040,.424;.121,.1 16,-.607,.103,.022,.384,-.040,1,-.071;-.245,.154,-.034,-.554,-.654,-.098,.424,-.071,1]; >>
m1=[139.2664;93.0918;53.9882;11.2073;6.7645;17.9345;17,8327;11.0018;1.6736];m 2=[107.3099;67.8873;47.7536;9.0827;5.3673;11.2775;13.6102;6.5773;1.3845];
>> m=(m1+m2)/2;
>> arfa=inv(v)*(m1-m2);
二、Fisher判别方法
1、操作步骤:
1)录入数据,选择菜单项Analyze→Classify→Discriminate,打开Discriminate Analysis对话框,如图2-1。
图2-1
2)单击Statistics按钮,在跳出的Statistics子对话框中指定输出的描述统计量和判别函数系数。
如图2-2
图2-2
3)单击Classify按钮,打开Classification子对话框,对它的先验概率、输
出以及图等的选择。
如图2-3
图2-3
4)单击Save按钮,打开Save子对话框,如图2-4,指定在数据文件中生成代表判别分类结果和判别函数值的新变量。
图2-4
5)单击‘OK’即可。
2、结果分析
1)表2-1是Fisher判别函数的特征值表。
特征值为相应Fisher判别函数的特征值,等于判别函数值组间平方和与组内平方和之比,该值越大表明判别函数效果越好。
特征值的个数与Fisher判别函数的个数相等,由于本例中总体只有两
类,所以至多有一个Fisher判别函数。
正则相关性为典型相关系数,等于组间平方和与组内平方和之比的平方根。
表2-1Fisher判别函数特征值
2)表2-2给出了Fisher判别函数有效性检验结果。
该检验的原假设是不同组的平均Fisher判别函数值不存在显著差异。
从表中给出的α值来看,05
.0
000
.0≤
=
α说明在0.05的显著性水平下有理由拒绝原假设,即应认为不同组的平均Fisher判别函数值存在显著差异,这意味着判别函数是有效的。
表2-2Fisher判别函数有效性检验
3)表2-3和表2-4分别给出了标准化的Fisher判别函数和未标准化的Fisher 判别函数。
标准化的Fisher判别函数是由标准化的自变量通过Fisher判别法得到的,所以要得到标准化的Fisher判别函数值,代入该函数的自变量必须是经过标准化的。
而未标准化的Fisher判别函数系数由于可以将实测的样品观测值直接代入求出判别函数值,所以该系数使用起来比标准化的系数要方便一些。
由表2-4可知,Fisher判别函数为:
582
.
20
252
.0
618
.0
051
.0
064
.0 011
.0
217
.0
225
.0
009
.0
005
.0
9
8
7
6
5
4
3
2
1
-
+
+
+
-
-
+
+
+
=
x
x
x
x
x
x
x
x
x
y Wilks 的 Lambda
函数检验Wilks 的
Lambda 卡方df Sig.
1 .135 31.003 9 .000
表表2-4
将1x 、2x 代入判别函数得出1y 、2y ,从而求出临街值y 。
将样本一的数据代入判别函数得:
y y <1, y y <2
1) 表2-5可知,在这次判别中并没有误判情况,即是误判的概率为0。
表2-5
标准化的典型判别式函
数系数
函数 1 x1 .085 x2 .159 x3 1.214 x4 .649 x5 -.029 x6 -.383 x7 .326 x8 1.272 x9
.337
三、Bayes判别法
1、操作过程
1)录入数据,选择菜单项Analyze→Classify→Discriminate,打开Discriminate
Analysis对话框,如图3-1。
如图3-1
2)单击Statistics按钮,在跳出的Statistics子对话框中指定输出的描述统
计量和判别函数系数。
如图3-2
图3-2
3)单击Classify按钮,打开Classification子对话框,对它的先验概率、输
出以及图等的选择。
如图3-3
4)单击Save按钮,打开Save子对话框,如图3-4,指定在数据文件中生成代
表判别分类结果和判别函数值的新变量。
5)单击‘OK’即可。
2、结果分析:
1)表3-1给出了各类总体的先验概率。
由于我们在Classification子对话框
的Prior Probabilities选项栏中选择了默认的All groups equal选项,所以系统自动给每类分配了0.5的先验概率。
组的先验概率
VAR00010 先验
用于分析的案例
未加权的已加权的
1.00 .500 11 11.000
2.00 .500 11 11.000
合计 1.000 22 22.000
表3-1
2)表3-2给出了Bayes线性判别函数的系数。
表中的每一列表示样品判入相应
类的Bayes判别函数系数。
分类函数系数
VAR00010
1.00
2.00
x1 -.022 -.046
x2 .147 .106
x3 6.268 5.182
x4 6.588 5.544
x5 -1.521 -1.469
x6 -1.560 -1.250
x7 1.237 .993
x8 13.638 10.660
x9 5.862 4.649
(常量) -283.959 -184.744
Fisher 的线性判别式函数
表3-2
在本例中,各类的Bayes判别函数如下:
第一类:y1=-0.022x1+0.147x2+6.268x3+6.588 x4-1.251 x5-1.560 x6+1.237
x7+13.638 x8+5.826 x9-283.959;
第二类:y2=-0.046x1+0.106x2+5.182x3+5.544 x4-1.469 x5-1.250 x6+0.993
x7+10.660 x8+4.649 x9-184.744;
3)表3-3给出了模型的错判矩阵。
从表中可以看到这一次所取的样本并不存在
误判情况,即误判的概率为0。
表3-3
11。