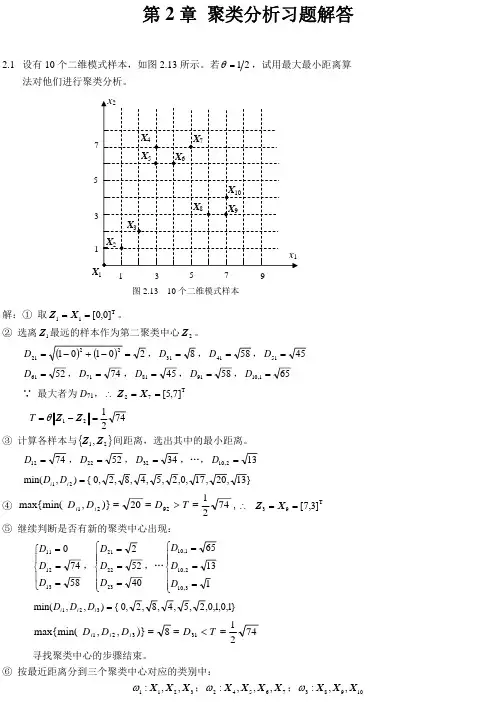
哈工大 模式识别第2章
- 格式:ppt
- 大小:1.48 MB
- 文档页数:111









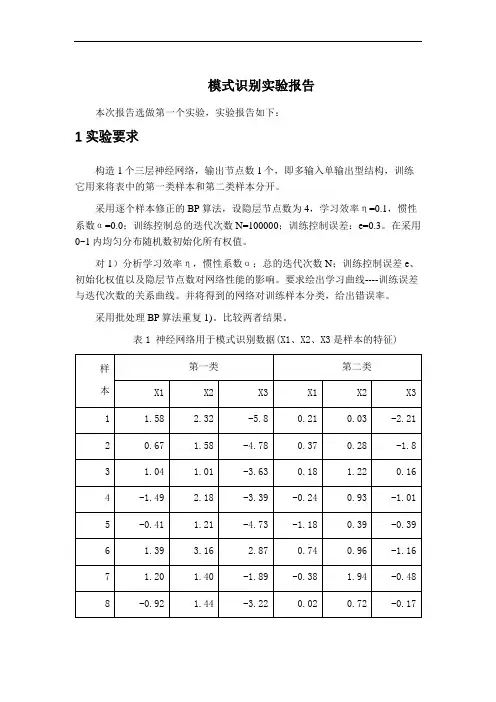
模式识别实验报告本次报告选做第一个实验,实验报告如下:1 实验要求构造1个三层神经网络,输出节点数1个,即多输入单输出型结构,训练它用来将表中的第一类样本和第二类样本分开。
采用逐个样本修正的BP算法,设隐层节点数为4,学习效率η=0.1,惯性系数α=0.0;训练控制总的迭代次数N=100000;训练控制误差:e=0.3。
在采用0~1内均匀分布随机数初始化所有权值。
对1)分析学习效率η,惯性系数α;总的迭代次数N;训练控制误差e、初始化权值以及隐层节点数对网络性能的影响。
要求绘出学习曲线----训练误差与迭代次数的关系曲线。
并将得到的网络对训练样本分类,给出错误率。
采用批处理BP算法重复1)。
比较两者结果。
表1 神经网络用于模式识别数据(X1、X2、X3是样本的特征)2 BP 网络的构建三层前馈神经网络示意图,见图1.图1三层前馈神经网络①网络初始化,用一组随机数对网络赋初始权值,设置学习步长η、允许误差ε、网络结构(即网络层数L 和每层节点数n l );②为网络提供一组学习样本; ③对每个学习样本p 循环a .逐层正向计算网络各节点的输入和输出;b .计算第p 个样本的输出的误差Ep 和网络的总误差E ;c .当E 小于允许误差ε或者达到指定的迭代次数时,学习过程结束,否则,进行误差反向传播。
d .反向逐层计算网络各节点误差)(l jp δ如果l f 取为S 型函数,即xl e x f -+=11)(,则 对于输出层))(1()()()()(l jp jdp l jp l jp l jp O y O O --=δ 对于隐含层∑+-=)1()()()()()1(l kj l jp l jp l jp l jp w O O δδe .修正网络连接权值)1()()()1(-+=+l ip l jp ij ij O k W k W ηδ式中,k 为学习次数,η为学习因子。
η取值越大,每次权值的改变越剧烈,可能导致学习过程振荡,因此,为了使学习因子的取值足够大,又不至产生振荡,通常在权值修正公式中加入一个附加动量法。
第一章 绪论1.什么是模式?具体事物所具有的信息。
模式所指的不是事物本身,而是我们从事物中获得的___信息__。
2.模式识别的定义?让计算机来判断事物。
3.模式识别系统主要由哪些部分组成?数据获取—预处理—特征提取与选择—分类器设计/ 分类决策。
第二章 贝叶斯决策理论1.最小错误率贝叶斯决策过程? 答:已知先验概率,类条件概率。
利用贝叶斯公式得到后验概率。
根据后验概率大小进行决策分析。
2.最小错误率贝叶斯分类器设计过程?答:根据训练数据求出先验概率类条件概率分布 利用贝叶斯公式得到后验概率如果输入待测样本X ,计算X 的后验概率根据后验概率大小进行分类决策分析。
3.最小错误率贝叶斯决策规则有哪几种常用的表示形式? 答:4.贝叶斯决策为什么称为最小错误率贝叶斯决策?答:最小错误率Bayes 决策使得每个观测值下的条件错误率最小因而保证了(平均)错误率 最小。
Bayes 决策是最优决策:即,能使决策错误率最小。
5.贝叶斯决策是由先验概率和(类条件概率)概率,推导(后验概率)概率,然后利用这个概率进行决策。
6.利用乘法法则和全概率公式证明贝叶斯公式答:∑====mj Aj p Aj B p B p A p A B p B p B A p AB p 1)()|()()()|()()|()(所以推出贝叶斯公式7.朴素贝叶斯方法的条件独立假设是(P(x| ωi) =P(x1, x2, …, xn | ωi)⎩⎨⎧∈>=<211221_,)(/)(_)|()|()(w w x w p w p w x p w x p x l 则如果∑==21)()|()()|()|(j j j i i i w P w x P w P w x P x w P 2,1),(=i w P i 2,1),|(=i w x p i ∑==21)()|()()|()|(j j j i i i w P w x P w P w x P x w P ∑===Mj j j i i i i i A P A B P A P A B P B P A P A B P B A P 1)()|()()|()()()|()|(= P(x1| ωi) P(x2| ωi)… P(xn| ωi))8.怎样利用朴素贝叶斯方法获得各个属性的类条件概率分布?答:假设各属性独立,P(x| ωi) =P(x1, x2, …, xn | ωi) = P(x1| ωi) P(x2| ωi)… P(xn| ωi) 后验概率:P(ωi|x) = P(ωi) P(x1| ωi) P(x2| ωi)… P(xn| ωi)类别清晰的直接分类算,如果是数据连续的,假设属性服从正态分布,算出每个类的均值方差,最后得到类条件概率分布。
一、实验背景随着计算机科学和信息技术的飞速发展,模式识别技术在各个领域得到了广泛应用。
模式识别是指通过对数据的分析、处理和分类,从大量数据中提取有用信息,从而实现对未知模式的识别。
本实验旨在通过实践操作,加深对模式识别基本概念、算法和方法的理解,并掌握其应用。
二、实验目的1. 理解模式识别的基本概念、算法和方法;2. 掌握常用的模式识别算法,如K-均值聚类、决策树、支持向量机等;3. 熟悉模式识别在实际问题中的应用,提高解决实际问题的能力。
三、实验内容本次实验共分为三个部分:K-均值聚类算法、决策树和神经网络。
1. K-均值聚类算法(1)实验目的通过实验加深对K-均值聚类算法的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组二维数据,包括100个样本,每个样本包含两个特征值;② 初始化聚类中心:随机选择K个样本作为初始聚类中心;③ 计算每个样本到聚类中心的距离,并将其分配到最近的聚类中心;④ 更新聚类中心:计算每个聚类中所有样本的均值,作为新的聚类中心;⑤ 重复步骤③和④,直到聚类中心不再变化。
(3)实验结果通过实验,可以得到K个聚类中心,每个样本被分配到最近的聚类中心。
通过可视化聚类结果,可以直观地看到数据被分成了K个类别。
2. 决策树(1)实验目的通过实验加深对决策树的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组具有分类标签的二维数据,包括100个样本,每个样本包含两个特征值;② 选择最优分割特征:根据信息增益或基尼指数等指标,选择最优分割特征;③ 划分数据集:根据最优分割特征,将数据集划分为两个子集;④ 递归地执行步骤②和③,直到满足停止条件(如达到最大深度、叶节点中样本数小于阈值等);⑤ 构建决策树:根据递归分割的结果,构建决策树。
(3)实验结果通过实验,可以得到一棵决策树,可以用于对新样本进行分类。
3. 神经网络(1)实验目的通过实验加深对神经网络的理解,掌握其基本原理和实现方法。