模式识别计算
- 格式:ppt
- 大小:1.04 MB
- 文档页数:40

基于免疫计算的模式识别研究及应用随着信息技术的飞速发展,模式识别技术日益成为人们重要的研究领域之一。
在这方面,基于免疫计算的模式识别技术近年来引起了越来越多的关注。
本文将对基于免疫计算的模式识别研究及应用进行探讨。
一、基础理论免疫计算是一种仿生的计算方法,主要模拟了生物体免疫系统的特性和行为。
根据免疫学的基础理论,免疫系统具有学习能力和记忆功能,能够识别和区分外来抗原。
基于这种特点,免疫计算的基础理论主要包括免疫应答、抗原-抗体作用、克隆选择和免疫调节等。
在模式识别中,免疫计算主要利用免疫系统的抗原-抗体作用和克隆选择机制来实现特征提取和分类识别。
具体来说,抗体代表了样本的特征向量,抗原则代表待分类的样本。
通过计算抗体与抗原之间的相似度,可有效地实现样本的分类。
二、相关算法1. AIA算法AIA全称Artificial Immune Algorithm,是免疫计算中常用的一类算法。
AIA算法的基本思想是通过学习和适应来提高算法的性能,进而实现模式识别。
AIA算法包括了免疫克隆算法、免疫突变算法、抗体多峰分布算法等。
其中,免疫克隆算法是最为常见的一类算法。
2. AIS算法AIS全称Artificial Immune System,是免疫计算方法的一种。
AIS算法的特点在于能够自适应地生成、评估和修正抗体,具有强大的学习能力和记忆能力。
目前,AIS算法已经被广泛应用于模式识别以及其他领域,取得了一定的成果。
三、应用研究1. 图像识别图像识别是模式识别领域中的一个重要分支,也是免疫计算的重要应用领域之一。
图像识别需要对一幅或多幅图像进行分类和识别,其中最常见的分类方式是根据图片中的颜色、纹理和形状等特征来进行划分。
免疫计算中的AIS算法已经被应用于图像识别领域,取得了一定的成果。
2. 生物识别生物识别是通过生物信息来实现模式识别的一种技术,主要应用于安全、保密和身份认证等领域。
当前,生物识别技术主要包括指纹识别、面部识别、虹膜识别等。

什么是计算机模式识别请解释几种常见的算法什么是计算机模式识别?请解释几种常见的算法计算机模式识别是一种利用计算机技术来识别和分类不同模式的方法。
模式是指事物之间的某种形式、结构、特征或行为的概念。
计算机模式识别广泛应用于图像识别、语音识别、文字识别等领域,对人类视觉、听觉和认知等感知过程进行仿真,以实现机器对模式的自动识别和理解。
计算机模式识别中常见的算法有:1. 最近邻算法(K-Nearest Neighbors, KNN)最近邻算法是一种基本的分类算法。
它的思想是如果一个样本在特征空间中的K个最相似的样本中的大多数属于某个类别,那么该样本也可以划分为这个类别。
最近邻算法主要通过计算样本之间的距离来进行分类决策,距离可以使用欧氏距离、曼哈顿距离等。
2. 决策树算法(Decision Tree)决策树算法是一种基于树形结构的分类算法。
它通过一系列的判断问题构建一棵树,每个内部节点代表一个问题,每个叶子节点代表一个类别。
决策树算法通过划分样本空间,使得每个子空间内样本的类别纯度最大化。
常用的决策树算法包括ID3算法、C4.5算法、CART 算法等。
3. 支持向量机算法(Support Vector Machines, SVM)支持向量机算法是一种二类分类算法。
它通过构建一个超平面,使得离该超平面最近的一些样本点(即支持向量)到超平面的距离最大化。
支持向量机算法可以用于线性可分问题和非线性可分问题,通过核函数的引入可以将低维特征空间映射到高维特征空间,提高模型的表达能力。
4. 朴素贝叶斯算法(Naive Bayes)朴素贝叶斯算法是一种基于贝叶斯定理和特征条件独立性假设的分类算法。
它通过计算样本的后验概率来进行分类决策,选择后验概率最大的类别作为样本的分类结果。
朴素贝叶斯算法在文本分类、垃圾邮件过滤等任务中得到了广泛应用。
5. 神经网络算法(Neural Networks)神经网络算法是一种模拟人类神经系统进行学习和决策的模式识别算法。
![[数学]模式识别方法总结](https://uimg.taocdn.com/9bfe35a6a0116c175f0e484a.webp)

简便计算错题分析在学习数学的过程中,我们经常会遇到一些简便计算题目。
这些题目通常不涉及复杂的计算步骤,但也容易出现错误。
为了有效地分析这些错题,我们可以采取一些简便的方法。
本文将介绍几种常见的简便计算错题分析方法。
一、精确性分析在分析简便计算错题时,首要的任务是确定错误出现的原因。
一种常见的方法是进行精确性分析。
在这种分析中,我们逐步检查计算过程中的每一步,并比对计算结果与正确结果的差异。
例如,假设我们计算了一个简单的加法题目:245 + 147 = ? 如果我们得出的结果是392,但正确答案是392,那么我们就可以确定错误出现在个位数的相加上。
通过细致地检查计算过程,我们可以找出错误所在,然后采取相应的纠正措施。
二、规则遵循性分析简便计算题目通常遵循一定的计算规则。
在分析错题时,我们可以检查回答是否符合这些规则。
如果不符合,说明处理方式可能存在错误。
例如,当我们计算一个乘法题目时:7 × 8 = ? 如果我们得出的结果是14,但正确答案是56,那么我们可以确定错误出现在计算过程中对乘法规则的错误理解。
通过遵循计算规则,我们可以避免一些低级错误的发生,提高计算的准确性。
三、模式识别分析另一种常见的分析方法是模式识别。
在简便计算中,一些题目具有相似的解法模式,通过识别这些模式,我们可以更加高效地解决问题。
例如,我们计算一个平方数的差:92 - 72 = ? 如果我们得出的结果是47,但正确答案是16,那么我们可以确定错误出现在计算平方数的差的过程上。
通过熟悉常见的计算模式,我们可以加快求解过程,减少错误的发生。
四、反思总结分析简便计算错题可以帮助我们发现错误的原因,并从中吸取教训。
在分析完成后,我们应该进行反思总结,以便更好地改进我们的计算能力。
例如,我们可以总结出以下几点教训:- 注意精确计算,避免粗心造成的错误。
- 熟悉常见的计算规则,以免违背规则导致错误。
- 提高对计算模式的识别能力,加快解题速度。

大数据中的模式识别算法研究随着信息时代的到来,数据的规模呈现指数级增长,大数据成为了当前互联网时代的代名词。
大数据为我们提供了海量数据,但是这些数据仅仅是数字,对于我们来说并没有什么用处。
需要通过数据分析方法对数据进行挖掘,探究数据背后的价值。
这时候,大数据技术中的模式识别算法就发挥了重要作用。
模式识别算法是指在给定样本数据集的情况下,通过学习数据的特性、规律和属性,建立起分类器或者回归方程,用于对其他具有类似特性的未知数据进行预测的算法。
在大数据应用领域,模式识别算法可以从海量数据中挖掘出隐含的规律,并为业务提供可靠的决策支持。
一、模式识别算法的基本思路模式识别算法的基本思路是学习和分类。
具体来说,就是通过学习样本数据集的特征,确定分类器或者回归方程,然后用于对其他未知数据进行分类或者预测。
在学习和分类过程中,模式识别算法通常还需要评估模型的性能和泛化能力。
在模式识别算法中,最常用的算法包括支持向量机、决策树、神经网络等。
支持向量机是一种功能强大的分类器,能够对数据进行非线性分类。
决策树是一种很好的可解释性模型,它能够通过一系列简单的问题对样本进行分类。
神经网络是一种适用于非线性问题的分类器,具有非常强大的泛化能力。
除了传统的模式识别算法,深度学习算法也被广泛应用于大数据领域,如卷积神经网络、循环神经网络等。
这些算法在处理大数据方面能够提供更加精确的预测结果和更高的准确率。
二、模式识别算法在大数据中的应用模式识别算法在大数据中的应用非常广泛,主要包括数据分类、数据聚类和异常检测等方面。
1. 数据分类数据分类是指将数据按照特定的分类规则进行分类。
在大数据中,数据分类可以用于搜索引擎的网页分类、电商的用户分类等。
常用的算法包括支持向量机、决策树、神经网络等。
举个例子,互联网搜索引擎中,对于用户输入的查询关键词,需要对搜索结果进行严格的分类。
这时候,可以通过对大量用户检索的相关关键词进行分析和归类,确定不同的搜索结果分类,然后再将用户输入的关键词和对应的搜索结果分类进行匹配,最终返回给用户准确的搜索结果。

模式识别感知器算法求判别函数
y = sign(w · x + b)
其中,y表示分类结果(1代表一个类别,-1代表另一个类别),x 表示输入特征向量,w表示权重向量,b表示偏置项,sign表示取符号函数。
判别函数的求解过程主要包括以下几个步骤:
1.初始化权重向量和偏置项。
一般可以将它们设置为0向量或者随机向量。
2.遍历训练集中的所有样本。
对于每个样本,计算判别函数的值。
4.如果分类错误,需要调整权重和偏置项。
具体做法是使用梯度下降法,通过最小化误分类样本到超平面的距离来更新权重和偏置项。
对于权重向量的更新,可以使用如下公式:
w(t+1)=w(t)+η*y*x
对于偏置项的更新,可以使用如下公式:
b(t+1)=b(t)+η*y
5.重复步骤2和步骤4,直到所有样本都分类正确或达到停止条件。
需要注意的是,如果训练集中的样本不是线性可分的,则判别函数可能无法达到100%的分类准确率。
此时,可以通过增加特征维度、使用非线性变换等方法来提高分类效果。
总结起来,模式识别感知器算法通过判别函数将输入数据分类为两个类别。
判别函数的求解过程是通过调整权重向量和偏置项,使用梯度下降法最小化误分类样本到超平面的距离。
这个过程是一个迭代的过程,直到所有样本都分类正确或达到停止条件。

什么是计算机模式识别请解释几种常见的算法计算机模式识别是一种利用计算机技术来识别、分类和理解图像、声音、文字等数据的技术。
在现代社会中,计算机模式识别被广泛应用于人脸识别、语音识别、医学影像分析、金融数据分析等领域。
这些应用都要求计算机能够自动地对输入的数据进行分类、识别和理解,以帮助人们更高效地处理和利用信息。
常见的计算机模式识别算法包括:K近邻算法(K-Nearest Neighbors, KNN)、支持向量机(Support Vector Machine, SVM)、决策树(Decision Tree)、神经网络(Neural Network)等。
下面,我将对这几种算法进行详细介绍:1. K近邻算法(K-Nearest Neighbors)K近邻算法是一种基本的分类算法,其原理是将未知数据与已知数据进行比较,将其归类为距离最近的K个数据所在的类别。
KNN算法简单易懂,适用于分类和回归问题,但在处理大规模数据时效率较低。
2. 支持向量机(Support Vector Machine)支持向量机是一种用于分类和回归问题的监督学习算法,其特点是能够有效地处理高维数据,并具有很好的泛化能力。
SVM通过寻找一个超平面来将数据分为不同类别,使得不同类别之间的间隔最大化。
支持向量机在图像识别、手写字符识别等领域有着广泛应用。
3. 决策树(Decision Tree)决策树是一种基于树状结构的分类算法,通过不断地对数据进行分裂,最终得到一个具有层级结构的分类模型。
决策树易于理解和解释,适用于处理大规模数据,并且能够处理具有缺失值的数据。
决策树算法在医学诊断、金融风控等领域具有较好的应用效果。
4. 神经网络(Neural Network)神经网络是一种模仿人类神经系统的学习模型,通过多个神经元之间的连接和权重调节来实现数据的分类和识别。
神经网络在模式识别领域有着广泛的应用,如图像识别、语音识别等。
深度学习中的深度神经网络已经在许多领域取得了显著的成果。


什么是计算机模式识别请解释几种常见的模式识别算法计算机模式识别是一种基于模式匹配和统计学方法,旨在从数据中自动识别和分类模式的技术。
它在图像处理、语音识别、自然语言处理、生物信息学等领域都有广泛的应用。
本文将解释计算机模式识别的定义,并介绍几种常见的模式识别算法。
一、计算机模式识别的定义计算机模式识别是指通过采集、处理、分析和理解数据,自动地从中学习和发现模式,并将其应用于模式识别和分类的过程。
它的主要目标是通过数学和统计学方法,为模式之间的相似性和差异性提供度量,并基于这些度量进行分类、识别或预测。
二、常见的模式识别算法1. K最近邻算法(K-Nearest Neighbors,简称KNN)K最近邻算法是一种简单而有效的模式分类算法。
它的基本思想是,将新的样本与已知的样本进行比较,找到其最近的K个邻居,然后根据这些邻居的类别进行分类。
KNN算法的优点是简单易懂、易于实现,但缺点是计算量大、对数据分布敏感。
2. 支持向量机(Support Vector Machine,简称SVM)支持向量机是一种常用的模式识别算法。
它的目标是找到一个超平面,将不同类别的样本分开,并使支持向量(距离超平面最近的样本点)最大化。
SVM算法的优点是可以处理高维数据、泛化能力强,但缺点是模型训练时间较长、对噪声敏感。
3. 决策树算法(Decision Tree)决策树算法是一种基于树状结构的模式识别算法。
它通过将数据集分割成不同的子集,构建决策树,并根据特征的取值来进行分类。
决策树算法的优点是可解释性强、适用于处理大规模数据,但缺点是容易过拟合、对噪声和缺失值敏感。
4. 人工神经网络(Artificial Neural Network,简称ANN)人工神经网络是一种模拟人脑神经网络结构和功能的模式识别算法。
它由多个神经元组成的层级结构,并通过学习调整神经元之间的连接权重来实现模式识别和分类。
人工神经网络的优点是适应能力强、可以处理非线性问题,但缺点是需要大量的训练样本、计算量较大。
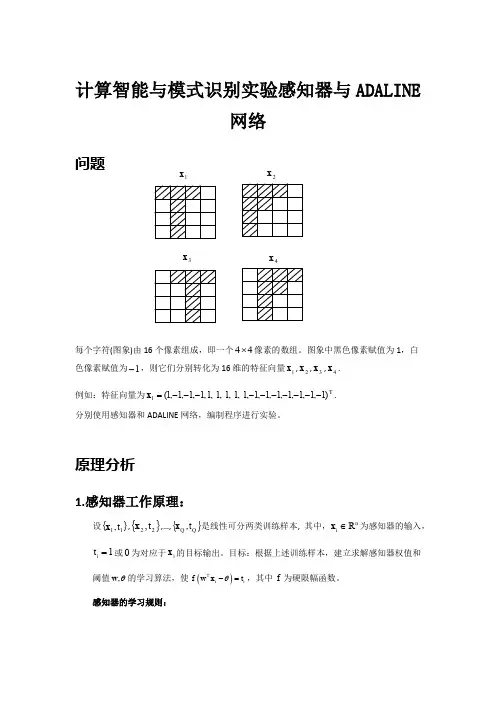
计算智能与模式识别实验感知器与ADALINE网络问题每个字符(图象)由16个像素组成,即一个44⨯像素的数组。
图象中黑色像素赋值为1,白色像素赋值为1-,则它们分别转化为16维的特征向量1x ,2x ,3x ,4x . 例如:特征向量为T 1)1,1,1,1,1,1,1,1 ,1 ,1 ,1 ,1 ,1,1,1,1(----------=x . 分别使用感知器和ADALINE 网络,编制程序进行实验。
原理分析1.感知器工作原理:设{}11,t x ,{}22,t x ,…,{}Q Q t ,x 是线性可分两类训练样本, 其中,ni R ∈x 为感知器的输入,1i t =或0为对应于i x 的目标输出。
目标:根据上述训练样本,建立求解感知器权值和阈值,θw 的学习算法,使()T i i f t θ-=w x ,其中f 为硬限幅函数。
感知器的学习规则:(1)()()()(1)()()()()()k k e k k k k e k e k t k y k θθ+=+⎧⎪+=-⎨⎪=-⎩w w x 其中,()()[]()()()()()()()0(0)1,1T t k k y k f k k k k f θθ⎧⎪⎪=-⎨⎪-⎪⎩x w x x w 是的目标输出为的实际输出,为硬限幅函数初值,取较小的随机数,如在中随机选取单神经元感知器---两类线性分类器设 {}{}12(1)(1)(1)12(12)(2)(2)12,,,class A ,,,class B Q Q ⎧⊂⎪⎨⊂⎪⎩x x x x x x n R ⊂是线性可分两个类的训练样本,则存在超平面将这两类分开:因此,可使用一个n 个输入的单神经元感知器将这两类训练样本分开:选取感知器的权值与阈值分别为()12,,Tn w w w =w ,θ,则()1)1(1 ,1Q i f i T ≤≤=-θx w ,()(2)20, 1T i f i Q θ-=≤≤w x从而,单神经元感知器可实现线性可分的两类分类。

例2.2>> x=[ 0 0; 0 1;1 0; 0.5 4;1 3;1 5;1.5 4.5;6 4;6.5 5;7 4;7.5 7; 8 6;8 7];>> K=2;iter_max=80;sita_c=1;sita_s=0.7;sita_N=1; %各参数>> [y,z]=ISODATA(x,2,sita_N,sita_s,sita_c,iter_max) %算法函数y = 2 2 2 2 2 2 2 1 1 1 1 1 1%各样本对应的类别z =7.1667 5.5000 %聚类中心0.7143 2.5000>> K=4;>> y=ISODATA(x,4,sita_N,sita_s,sita_c,iter_max)y = 4 4 4 3 3 3 3 2 2 2 1 1 1%各样本对应的类别例2.5>> load mydata;>>a1=mean(x1);st1=std(x1); a2=mean(x2);st2=std(x2);>> x1=(x1-a1(ones(5,1),:))./st1(ones(5,1),:);>> x2=(x2-a2(ones(7,1),:))./st2(ones(7,1),:);>> re1=pcares(x1,1); re2=pcares(x2,1);%各类的残差>> s01=sum(sum1(re1))/(5-1-1)/(4-1)%第1类的总方差s01 =0.7147>> s02=sum(sum1(re2))/(7-1-1)/(4-1)%第2类的总方差s02 =0.7130>> s11=(sum1(re1')/3)'; s21=(sum1(re2')/3)';%每个样本的方差>> f01=((5/(5-1-1)).*s11./s01)'%类内样本分类的检验f01 = 2.2772 0.3195 1.1022 1.6946 0.3411>> f02=((7/(7-1-1)).*s21./s02)'f02 =1.5933 0.4055 0.2276 0.8672 1.6677 0.4185 1.8204>> [pc1,da1]=princomp(x1);%各类的主成分分解>> [pc2,da2]=princomp(x2);>> t1=(x3-a1(ones(3,1),:))*da1';%对未知样本计算得分向量值>> e1=x3-t1*da1;%未知样本残余向量>> s1=sum(e1')/3%未知样本残余方差s1 = 0.2976 3.0370 5.8752>> f=3.86*s01%判别计算式,3.86为F检验临界值f= 2.7692function y=sum1(x)[r,c]=size(x);if r==1y=0;for i=1:c;y=y+x(i)^2;endelsefor j=1:c;y(j)=0;for i=1:r;y(j)=y(j)+x(i,j)^2;end;endend例2.8>>load x; y1=aknn(x(1:5,:),x(6:10,:),sample)y1 =1 即来自乙地function y=aknn(x1,y1,sample) %ALKNN法函数d1=squareform(pdist(x1));d2=squareform(pdist(y1));a1=sort(d1,2);a2=sort(d2,2);[r1,c1]=size(x1);r2=size(y1,1);r3=size(sample,1);m=c1;for i=2:r1-1; g_k1(i-1)=0;for j=1:r1r=a1(j,i+1); v1=2*pi^(m/2)*r^m/(m*mfun('gamma',m/2)); p1(i,j)=(i-1)/((r1-1)*v1);g_k1(i-1)=g_k1(i-1)+log(p1(i,j));endg_k2(i-1)=0;for j=1:r2-1r=a2(j,i+1);v1=2*(2*pi)^(m/2)*r^m/(m*mfun('gamma',m/2));p2(i,j)=(i-1)/((r2-1)*v1);k2(i-1)=g_k2(i-1)+log(p2(i,j));endend[g_max1,k1]=max(g_k1);k1=k1+1; [g_max2,k2]=max(g_k2);k2=k2+1;%对各类求K值for i=1:r3a_sample=[sample(i,:);x1]; d1=squareform(pdist(a_sample));a_sample1=sort(d1,2);r_1=a_sample1(1,k1+1);v1=2*pi^(m/2)*r_1^m/(m*mfun('gamma',m/2));p1(i)=(k1-1)/((r1)*v1);b_sample=[sample(i,:);y1];d2=squareform(pdist(b_sample));b_sample1=sort(d2,2);r_2=b_sample1(1,k2+1);v2=2*pi^(m/2)*r_2^m/(m*mfun('gamma',m/2));p2(i)=(k2-1)/((r2)*v2);y(i)=p1(i)/(p1(i)+p2(i)); if y(i)>0.5;y(i)=0; else;y(i)=1;endend例2.10function y=f(x1,x2) %两类分类函数,返回分类函数系数r1=size(x1,1);r2=size(x2,1);xx=[x1;x2];y=[x1(1,:) 1];k1=0;c=size(y,1);flag=1;while k1<(r1+r2)if flag==1; s=2;else;s=1;endfor i=s:r1+r2t=0;for j=1:c; m=k(y(j,1:end-1),xx(i,:));t=t+y(j,end)*m;end %分类函数值if i<=r1 ;if t>0;k1=k1+1;else; y=[y;xx(i,:) 1];k1=0;end%第一类样本elseif t<0;k1=k1+1;else;y=[y;xx(i,:) -1];k1=0;end%第二类样本endc=size(y,1);endflag=2;endfunction y=k(x1,x2)%势函数y=exp(-sum((x1-x2).^2));例2.15function y=order(x)r=length(x);for i=1:r-1;for j=i+1:r;xx=[];xx=[xx x(i:j)];y(j,i)=f(xx);end;endy(end,r)=0;s=zeros(r-2,r-2);for k=2:r-1for l=k+1:rfor j=k:l;if k==2;d1(j)=y(j-1,1)+y(l,j);else;d1(j)=s(j-1,k-1)+y(l,j);end;endd1(1:k-1)=[];[s(l,k) g(l,k)]=min(d1);g(l,k)=g(l,k)+k-1;endends(1:2,:)=[];s(:,1)=[];g(1:2,:)=[];g(:,1)=[];for i=p-1:-1:1if i==p-1;g_order=g(end,i);for k=g_order:r;result(k)=i+1;endelse[a,b]=min(s(i+1:end,i));g_order1=g(b+2,i);for k=g_order1:g_order-1;result(k)=i+1;end g_order=g_order1;endendfor k=1:g_order-1;result(k)=k;endfunction y=f(x) %求直径函数r=length(x); x_mean=mean(x); y=0; for k=1:r;y=y+(x(k)-x_mean)^2; end。
课程设计任务书学生姓名:肖遥专业班级:通信1103班指导教师:周建新工作单位:信息工程学院题目: 模式识别初始条件:MATLAB 软件,模式识别知识要求完成的主要任务:1、利用BP(Back-propagation)网络对于10个阿拉伯数字(用七段码表示)进行训练,将训练好的网络对于污染的数字进行识别。
2、要求:学习BP算法;将数字用7维矢量表示;设计BP网络(7输入1输出);参考matlab神经网络工具箱参考书:[1] 周开利,康耀红编著.《神经网络模型及其MATLAB仿真程序设计》.2006:10-43[2] 魏海坤.《神经网络结构设计的理论与方法》.国防工业出版社,2005.9:20-30[3] 徐远芳,周旸,郑华.《基于MATLAB的BP神经网络实现研究》[J]. 微型电脑应用, 2006,(08)时间安排:1、理论讲解,老师布置课程设计题目,学生根据选题开始查找资料;2、课程设计时间为2周。
(1)确定技术方案、电路,并进行分析计算,时间2天;(2)选择元器件、安装与调试,或仿真设计与分析,时间6天;(3)总结结果,写出课程设计报告,时间2天。
指导教师签名:2014 年12月10日系主任(或责任教师)签名:年月日目录摘要 (I)Abstract (II)1 绪论 (1)1.1 BP神经网络的介绍 (1)1.2 神经网络理论的应用 (1)2 BP神经网络 (2)2.1神经网络的定义简介 (2)2.2 BP网络的特点 (2)2.3 BP模型的基本原理 (2)2.4 BP神经网络的训练 (3)3 基本BP算法的应用 (5)3.1基本BP算法公式推导 (5)3.2 BP网络的设计 (8)3.2.1 网络的层数 (8)3.2.2 隐含层的神经元数 (8)3.2.3 初始权值的选取 (8)3.2.4 学习速率 (8)3.3 BP 网络学习算法的计算步骤 (9)4 MATLAB 神经网络部分 (10)4.1 几种BP 神经网络中的重要函数和基本功能 (10)5 程序设计及仿真结果 (11)5.1 利用BP网络对污染数字的识别 (11)5.1.1 问题的提出 (11)5.1.2 将数字矢量表示 (11)5.1.3 网络的建立 (12)5.1.4 网络训练 (12)5.1.5 网络测试 (13)5.1.6用含噪声和不含噪声的数字样本进行训练 (13)5.1.7 测量网络容错性 (14)5.1.8 对污染数字进行识别 (15)5.2 仿真分析 (17)5.2.1隐含神经元数目对仿真的影响: (17)5.2.2传递函数对仿真的影响 (18)6 心得与体会 (20)参考文献 (21)附录 (22)摘要随着模式识别技术在当代高科技领域的发展,人工神经网络技术也有了突飞猛进的进步,并在各个领域有了广泛的应用,字符识别是模式识别理论的一个重要应用领域,是实现智能人机接口的重要途径。
2013–2014 学年度第 一 学期 模式识别原理 课程期末考试试题(考试方式:□√开卷 □闭卷;考试时间: 120 分钟)一、计算题 (共20分)在目标识别中,假定类型1ω为敌方目标,类型2ω为诱饵(假目标),已知先验概率P (1ω)=0.2和P (2ω)=0.8,类概率密度函数如下:⎪⎩⎪⎨⎧≤≤-<≤=其它021210)(1x x x xx p ω⎪⎩⎪⎨⎧≤≤-<≤=其它0323211-)(2x x x x x p ω1、求贝叶斯最小误判概率准则下的判决域,并判断样本x =1.5属于哪一类;2、求总错误概率p (e );3、假设正确判断的损失λ11=λ22=0,误判损失分别为λ12和λ21,若采用最小损失判决准则,λ12和λ21满足怎样的关系时,会使上述对x =1.5的判断相反?解:(1)应用贝叶斯最小误判概率准则如果)()()(2112ωω=x p x p x l <>)()(12ωωP P 则判 ⎩⎨⎧ωω∈21x (2分)得 l 12(1.5)=1 <)()(12ωωP P =4,故 x=1.5属于ω2 。
(2分)(2)P(e)= 212121)()()(εω+εω=P P e P⎰⎰ΩΩωω+ωω=12)()()()(2211xd x p P x d x p P=dxx x x ⎰⎰-+- 1.2121.210.8d )2(0.2)(=0.08(算式正确2分,计算错误扣1~2分)(3) 两类问题的最小损失准则的似然比形式的判决规则为:如果))(())(()()(111212221221λ-λωλ-λω<>ωωP P x p x p则判⎩⎨⎧ωω∈21x 带入x=1.5得到 λ12≥4λ21(算式正确2分,计算错误扣1~2分)二、证明题(共20分)设p(x)~N (μ,σ),窗函数ϕ(x)~N (0,1),试证明Parzen 窗估计11ˆ()()NiN i NNx x p x Nh h ϕ=-=∑有如下性质:22ˆ[()](,)N N E p x N h μσ+。
模式识别算法在人工智能领域中的应用人工智能是一门涉及模拟、推理和学习等领域的学科,其目的是使计算机系统能够智能地模仿人类的思维和行为。
模式识别算法是人工智能中的重要组成部分,它能够从大量的数据中自动提取和识别模式,并帮助计算机系统进行决策和处理。
在人工智能领域中,模式识别算法广泛应用于图像识别、语音识别、自然语言处理、生物信息学等方面。
下面,我将分别介绍这些领域中模式识别算法的应用。
首先是图像识别领域。
图像识别是指通过分析图像中的像素数据,自动识别出图像中的对象或场景。
模式识别算法在图像识别中起到了至关重要的作用。
例如,卷积神经网络(CNN)是一种广泛应用于图像识别中的模式识别算法,它可以从大量的图像数据中学习出不同对象的特征,并能够准确地识别出图片中的物体。
其次是语音识别领域。
语音识别是指通过分析语音信号,将语音转换为可理解的文本或命令。
模式识别算法在语音识别中发挥着重要的作用。
例如,隐马尔可夫模型(HMM)是一种常用的模式识别算法,它可以将语音信号与特定的说话人或语音命令进行匹配,实现语音识别的功能。
然后是自然语言处理领域。
自然语言处理是指对人类语言的处理和理解。
模式识别算法在自然语言处理中扮演了关键角色。
例如,支持向量机(SVM)是一种常用的模式识别算法,它可以从大量的文本中学习出不同词汇和句法结构的特征,并能够实现文本分类、情感分析等任务。
最后是生物信息学领域。
生物信息学是指利用计算机科学和信息学的方法来解决生物学问题。
模式识别算法在生物信息学中有着广泛的应用。
例如,基因序列分析是生物信息学中的关键任务之一,而模式识别算法可以帮助识别出基因序列中的重要模式或序列,从而对基因功能进行预测和分析。
除了上述领域,模式识别算法还被广泛应用于数据挖掘、智能交通系统、金融风控等方面。
通过对大数据进行模式识别,可以帮助人工智能系统做出更准确的决策和预测。
总结起来,模式识别算法在人工智能领域中起着重要的作用。
模式识别中距离方法名称及算法流程1.最常见的距离方法是欧氏距离,它是通过两个点之间的直线距离来计算它们之间的相似性。
The most common distance method is Euclidean distance, which calculates the similarity between two points by the straight-line distance between them.2.切比雪夫距离是通过两个点之间的最大差值来表示它们之间的不相似度。
Chebyshev distance represents the dissimilarity between two points by the maximum difference between them.3.曼哈顿距离是通过两个点在各个维度上的差值的绝对值之和来计算它们之间的距离。
Manhattan distance calculates the distance between two points by the sum of the absolute differences in each dimension.4.闵可夫斯基距离是欧氏距离和曼哈顿距离的一般化表示形式,具有一个参数p用于调节计算过程。
Minkowski distance is a generalization of Euclidean distance and Manhattan distance with a parameter p to adjust the calculation process.5.马氏距离考虑了各个维度之间的相关性,通过协方差矩阵的逆来调整欧氏距离的计算结果。
Mahalanobis distance takes into account the correlation between dimensions and adjusts the calculation of Euclidean distance using the inverse of the covariance matrix.6.汉明距离是用来衡量两个等长字符串之间的不同之处的度量,即它们在相应位置上的不同字符的个数。
距离平方的定义模式识别距离平方的定义在模式识别领域中是非常重要的。
距离度量是一种度量两个样本之间相似性或差异性的方法。
平方距离是其中一种常用的距离度量方法之一、在本文中,我们将详细介绍距离平方的定义及其在模式识别中的应用。
首先,让我们来定义距离平方。
给定两个向量X和Y,它们的距离平方可以通过以下公式来计算:d²(X,Y)=Σ(x_i-y_i)²其中,x_i和y_i分别表示向量X和Y的第i个元素,Σ表示对所有元素求和。
将距离平方的定义应用于向量X和Y的每个对应的元素,然后对结果取平方和即可得到距离平方。
距离平方在模式识别中的应用非常广泛。
在模式分类和聚类中,我们常常需要比较不同样本之间的相似性或差异性。
距离平方提供了一种有效的度量方法来量化样本之间的距离,从而帮助我们确定它们之间的相似性。
在模式分类中,距离平方常用于计算特征向量之间的距离,用来判断不同样本属于哪个类别。
我们可以通过计算样本向量与每个类别的均值向量之间的距离平方来确定样本的分类。
具体而言,分类器首先计算每个类别的均值向量,然后将待分类样本与每个均值向量进行距离计算,最后将样本分配到与其距离平方最小的类别。
在聚类中,距离平方可以用来衡量不同样本之间的相似性,从而将它们划分为不同的类别。
常见的聚类算法,如k-means和层次聚类,都使用距离平方作为样本之间距离的度量方法。
这些算法通过计算样本之间的距离平方来确定最接近的样本,并将它们归为同一类别。
除了模式分类和聚类外,距离平方还可以用于模式检索。
模式检索是指根据一个给定的查询模式,在数据库中检索出与之相似的模式。
距离平方可以用来计算查询模式与数据库中所有模式之间的距离,然后返回与查询模式距离平方最小的模式作为检索结果。
总结起来,距离平方在模式识别中扮演着关键的角色。
它是一种度量两个样本之间差异性的有效方法,并广泛应用于模式分类、聚类和检索等方面。
通过对向量每个元素之差的平方求和,距离平方可以提供一个定量的指标来帮助我们衡量和比较样本之间的相似性。