SPSS软件应用教程第七讲
- 格式:doc
- 大小:142.50 KB
- 文档页数:7



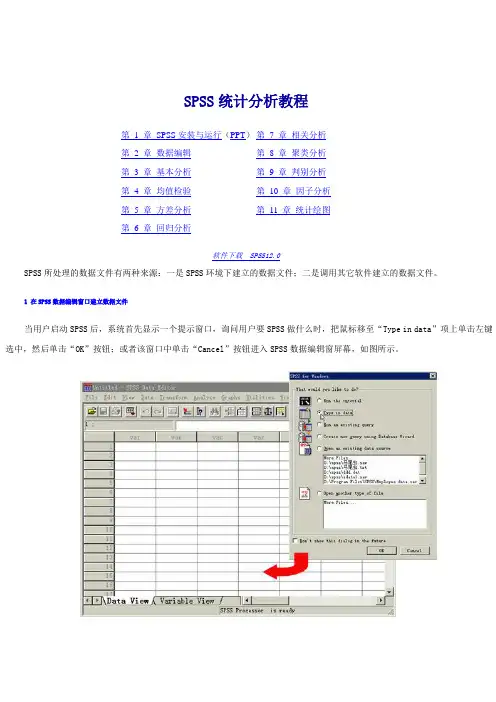
SPSS统计分析教程第1 章SPSS安装与运行(PPT)第7 章相关分析第 2 章数据编辑第8 章聚类分析第 3 章基本分析第9 章判别分析第 4 章均值检验第10 章因子分析第 5 章方差分析第11 章统计绘图第 6 章回归分析软件下载SPSS12.0SPSS所处理的数据文件有两种来源:一是SPSS环境下建立的数据文件;二是调用其它软件建立的数据文件。
1 在SPSS数据编辑窗口建立数据文件当用户启动SPSS后,系统首先显示一个提示窗口,询问用户要SPSS做什么时,把鼠标移至“Type in data”项上单击左键选中,然后单击“OK”按钮;或者该窗口中单击“Cancel”按钮进入SPSS数据编辑窗屏幕,如图所示。
图进入SPSS数据编辑器(1) 数据编辑(SPSS Data Editor)界面介绍窗口名显示栏:在窗口的顶部,显示窗口名称和编辑的数据文件名,没有文件名时显示为“Untitled-SPPS Data Editor”。
窗口控制按钮:在窗口的顶部的右上角,第一个按钮是窗口最小化,第二个按钮是窗口最大化,第三个按钮是关闭窗口。
SPSS主菜单:在窗口显示的第二行上,有:File文档,Edit编辑,View显视,Data数据,Transform转换,Analyze分析,Graphs 图形,Utilities公用项,Windows视窗。
图 SPSS窗口界面常用工具按钮:在窗口显示的第三行上,有:打开文档,保存文档,打印,对话检索,取消当前操作,重做操作,转到图形窗口,指向记录,指定变量操作,查找,在当前记录的上方插入新的空白记录,在当前变量的左边插入新的空白变量,切分文件,设置权重单元,标记单元,显示价值标签。
数据单元格信息显示栏:在编辑显示区的上方,左边显示单元格和变量名(单元格:变量名),右边显示单元里的内容。
编辑显示区:在窗口的中部,最左边列显示单元序列号,最上边一行显示变量名称,缺省为“Var”。







《SPSS软件应用》教案
●复习一:数据库结构建立
Name(名称)必须定义,最好是问卷题目。
●复习二:数据合并
有两种:一种是添加个案,基于相同的变量结构而言;一种是添加变量,基于相同的个案而言。
●复习三:定距数据的分组
有两种方法:一是在transform下的visual bander(可视离散化)栏完成;一是在transform转换中的compute计算变量来完成。
通常采取Visual Bander来实现。
●复习四:数据编码和计数
Recode的重新编码功能:一般要求重新编码为一个新变量,目的是为了保持原有变量数据;不受变量层次限制,可以对所有变量进行重新编码;将原变量值按照“一对一”、“多对一”的对应关系生成新变量值。
Count(计数):计算标示值或者某些值在一个或多个变量取值中出现的次数;变量的取值原则上应当具有一致性。
●复习五:统计报表
OLAP Cubes过程(online Analytical Processing Cubes,在线分析处理立方)和Case Summaries(个案汇总)过程,是按照分组变量对摘要变量按照不同的分组水平进行统计的常用定量描述。
前者产生多层标,后者是全表。
第七讲简单描述统计(中)
上次我们讲了Analyze Descriptive Statistics中的两个子菜单,分别是Frequencies过程和Descriptives过程。
Frequencies过程不受测量层次限制;可以实现简单的集中、离散等基本统计描述,还可以实现百分位统计和频率统计;
Descriptive菜单只适合(虚拟)定距变量集中、离散和分布统计。
(三)Explore(探索分析)过程
目的:由于收集到的数据分布并不清楚,因此,需要对数据进行初步探索,
以便确定选择的统计方法。
目的是为了发现数据中的错误,探索变量分布特征。
实现路径:Analyze→Descriptive Statistic→Explore,就打开explore对话窗口。
[界面解释]
Dependent list(因变量列表):用来分析的(虚拟)定距变量。
Factor list(因子列表):也就是分组变量,一般为定类/序或分组定距变量。
Label Cases by(标注个案):选择一个变量,其取值将作为每条记录的标签。
Display:统计量(statistics)或绘制图( plots)或两者都显示
[例题:请尝试比较分析不同城市居民的建筑面积居住情况]
第一,具体操作流程如下:
将“城市”变量移入“Factor list(因子列表)”框内;
将“建筑面积”移入“Dependent list(因变量列表)”内;
不选择标注个案。
点击statistic后,出现统计窗口Explore:Statistics(探索:统计量)窗口
1) M-estimators (描述集中趋势的稳健极大似然估计量):这些估计量的值在用于观测值时分配于不同的权重而得到的,极端值权重小于或接近于中心观测值的权重,对具有长尾的对称分布或有极端值时,其给出比平均值或中位数更好的均值估计。
如果该估计值离均值和中位值较远,则说明数据中可能存在异常值,此时宜用该估计值代替均值反映集中趋势。
会输出Huber 稳健估计;Hampel 非降稳健估计;Andrew 波估计;Tukey 复权重估计。
2)Descriptives: confidence interval for Mean:95%( 95%置信度下的均值置信区
间):指 ⎪⎪⎭⎫
⎝⎛σ+σ-ααn Z x ,n Z x 22; 3)Outliers (界外值):输出五个最大值和最小值;
4)Percentiles (百分位):输出5%、10%、25%、50%、75%、90%、95%分位数。
点击plots (绘制)后,出现绘图窗口;
Boxplots (箱图):按照factor level together(因子水平分组)、Dependent together(因变量分组)、none(无);
Descriptive(描述):Stem and leaf(茎叶图)、histogram(直方图);
normality plots by tests (正态检验);
Spread 或Level with Levene Test (扩展或水平检验):none(无)、P ower estimate (幂估计)、Transformed(已转换)可以选择各种形式的幂(如自然对数)。
这部分属于高级分析功能,当选入Factor List 的分组变量时可用,其目的是判断各组间的离散程度是否相同,并寻找一个比较合适的变量变换方法;可以进行稳健的Levene 方差齐性检验。
第二,输出结果呈现
解释:广州调查样本的平均建筑面积为59.63平方米,比韶关的平均建筑面积少21.08平方米;广州在95%置信度下的均值置信区间的上限值远小于韶关的下限值;去掉5%的尾数值,所计算出来的广州平均建筑面积依然比韶关的要少21.83;韶关的中位值比广州的大20.50平方米,由此可以初步判断广州居民的居住面积普遍偏低,与韶关相比偏低。
从标准差来看,韶关的为31.702,广州的威37.493,韶关的最大最小值差为269平米,广州的最大最小值差为389平方米,这些数据95%置信度下的均值间距区间 5%切尾均值 四分位差
说明广州居民内部的居住面积差异比韶关的要大。
通过广州和韶关的集中与离散趋势分析,发现建筑面积在区域之间是存在显著差异的,因此,我们在日后分析过程中,可以考虑将区域变量与建筑面积进行交互分析,看二者之间的相关强度到底有多高?或者是将区域变量作为Layer 层控制变量。
解释:从表中的4个M估计值来看,M估计值的值与韶关和广州的实际观测样本中位值77.50和57.00相差不太大;但是离均值80.71和59.63却相对较远,因此可以认为建筑面积这一变量的分布不具合理的正态性。
解释:这是极端值表,给出了在不同区域的调查者建筑面积对应的最高和最低的5个调查对象对应的面积数。
极端值表能够直观地告诉我们数据的极端分布
情况。
解释:建筑面积的方差齐性检验表,无论是基于平均值、中位值、调整自由度的中位值还是切尾均值,所计算出来的Levene统计值都通过了显著性检验,Sig .栏的P=0.000,小于0.05,原假定(韶关和广州的建筑面积的方差相等)的假定被否定,从而说明韶关和广州的建筑面积在均值和中位值的差异显著,正态曲线拟和差。
解释:这是正态性检验表,原假定(虚无假设)假设韶关和广州的建筑面积的分布具有正态性。
但是K-S和S-W的统计检验值的显著性水平P都小于0.05,从而否定了原假定,由此认为数据具有正态分布的虚无假设被否定,进而
得出结论,无论是广州还是韶关的建筑面积变量数据的正态曲线拟和差。
解释:这是将建筑面积以10为组距,每一叶代表1个个案而形成的茎叶图,从图形中我们可以在226个广州调查样本中有214个样本的建筑面积集中分布在10-100平方米之间。
解释:上图是韶关和广州的建筑面积箱形图,主要是最小值、25%、50%、75%和最大值这五数总和,我们可以看到广州的75%位值-25%位值的差距比韶关的要大,由此可以说明广州建筑面积的离散程度比韶关强。
[学生练习]
请尝试分析不同教育程度(a6.1)的去年平均月总收入(c14)的分布情况。
(提示:可以尝试对教育程度进行重新编码后再进行分析),然后Crosstab分析不同教育程度与去年平均月总收入之间的相关关系程度,并写一份实验报告。