浅谈文字识别软件OCR
- 格式:doc
- 大小:32.00 KB
- 文档页数:3

ocr文字识别功能
ocr文字识别软件是现在比较流行的办公室软件,所以对于那些不太了解的人们来讲急于了解。
为了让广大的网友更多的了解ocr文字识别软件,下面给大家介绍软件的功能。
以捷速ocr文字识别软件为例,该软件是一个专门识别文字的软件,可以识别多种文件格式包括:JPG、GIF、PNG、BMP、TIF和PDF源文件、PDF扫描件等等。
软件采用的是先进的光学识别技术,该技术的特性是能够在短时间内对文字进行多层次深入的分析,这样提升了软件的识别正确率。
捷速ocr文字识别软件还有一个大亮点就是操作极其简单,只需要简单的几步就能完成复杂的识别过程,这都要归功于软件的研发人员,因为软件的研发人员加强了软件自身职能化建设,很多的识别程序都自动完成,不需要人工操作,最后落实到需要人工操作步骤就简单的几步:
1、打开下载好的软件,直接进入操作主界面,点击上方左起第一个“添加文件”按钮,将需要识别的文件按提示添加到软件中。
2、看到软件右下角的“浏览”按钮,点击选择识别结果存放的路径,也可以默认不选,这样就会存放在原文件夹内。
3、上方正中有一个“开始转换”按钮,一切准备就绪就可以点击,然后软件就会自动对文件进行识别,稍等片刻就能得到识别结果。
相信就上面这几个步骤每个网友都会使用,捷速ocr文字识别软件因为自身技能强就是这么任性,同时还支持批量识别,不限制文件的大小,全部添加完成后一次性完成识别工作,不但适合个人使用还适合企业使用。
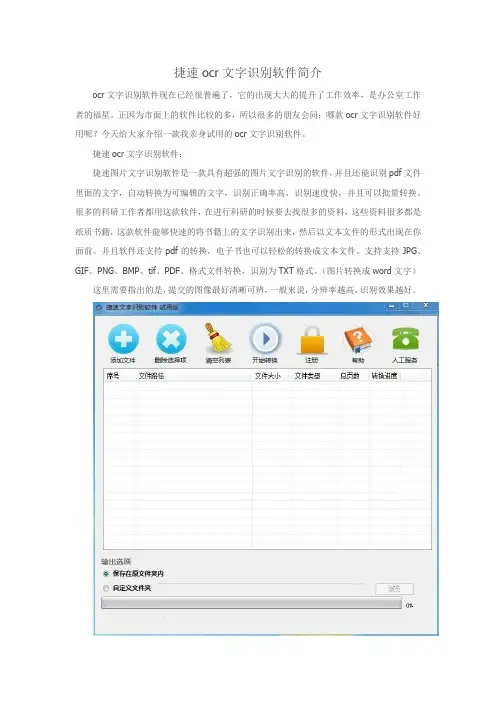
捷速ocr文字识别软件简介
ocr文字识别软件现在已经很普遍了,它的出现大大的提升了工作效率,是办公室工作者的福星。
正因为市面上的软件比较的多,所以很多的朋友会问:哪款ocr文字识别软件好用呢?今天给大家介绍一款我亲身试用的ocr文字识别软件。
捷速ocr文字识别软件:
捷速图片文字识别软件是一款具有超强的图片文字识别的软件,并且还能识别pdf文件里面的文字,自动转换为可编辑的文字,识别正确率高,识别速度快,并且可以批量转换。
很多的科研工作者都用这款软件,在进行科研的时候要去找很多的资料,这些资料很多都是纸质书籍,这款软件能够快速的将书籍上的文字识别出来,然后以文本文件的形式出现在你面前。
并且软件还支持pdf的转换,电子书也可以轻松的转换成文本文件。
支持支持JPG、GIF、PNG、BMP、tif、PDF、格式文件转换,识别为TXT格式。
(图片转换成word文字)这里需要指出的是,提交的图像最好清晰可辨,一般来说,分辨率越高,识别效果越好。

ocr文字识别技术总结OCR文字识别技术总结随着数字化时代的到来,大量的纸质文档需要转化为电子文件,使得OCR(Optical Character Recognition,光学字符识别)技术逐渐成为热门技术。
OCR技术的发展,为我们提供了一种高效、准确的方式来将纸质文档转化为可编辑的电子文件。
本文将对OCR文字识别技术进行总结,并探讨其应用领域和未来发展方向。
一、OCR文字识别技术简介OCR文字识别技术是指利用计算机对图像中的文字进行自动识别和转化为可编辑文本的技术。
其核心原理是通过对图像进行分析和处理,将图像中的文字转化为计算机可以识别和处理的字符编码。
OCR技术的发展经历了多个阶段,从最初的模板匹配,到现在的基于深度学习的方法。
随着计算机计算能力和算法的不断提升,OCR 技术的准确率和速度也得到了大幅提高。
二、OCR文字识别技术的应用领域1. 文档扫描与管理:OCR技术可以将纸质文档扫描后转化为可编辑的电子文件,实现文档的数字化管理,提高工作效率。
2. 自动化办公:OCR技术可以将图片中的文字提取出来,实现自动化的文字识别和处理,减少人工干预,提高工作效率。
3. 金融和证券业:OCR技术可以用于银行、证券公司等金融机构的票据识别和数据录入,提高数据处理的准确性和效率。
4. 物流和快递业:OCR技术可以用于快递单号的自动识别和跟踪,提供更准确、更及时的物流查询服务。
5. 图书馆和档案管理:OCR技术可以用于图书馆和档案馆的文献资料数字化和检索,方便用户获取所需信息。
三、OCR文字识别技术的优势和挑战1. 优势:a. 高准确率:随着深度学习的应用,OCR技术的准确率已经达到甚至超过人眼识别。
b. 高效率:OCR技术可以对大量的文档进行自动化处理,提高工作效率。
c. 数据可编辑:OCR技术可以将图像中的文字转化为可编辑的文本,方便后续的文字处理和编辑。
2. 挑战:a. 多样性处理:OCR技术需要应对各种复杂的图像情况,如不同字体、大小、颜色、倾斜程度等,需要不断进行算法优化。
Ocr文字识别软件有什么好处
你还在对着资料一个个打字输入电脑吗,那你就out了,能偷懒干吗要让自己受累呢,ocr文字识别软件是一款文字识别软件,能将图片上的文字转换为可编辑的文字,可以随自己喜欢的格式保存。
OCR实际上是让计算机认字,实现文字自动输入。
扫描文件可以使用OCR文字识别软件转换为文本文件,再插入Word进行编辑,它是一种快捷、省力、高效的文字输入方法。
在这里我们以“捷速ocr文字识别软件为例,简单的介绍一下该款软件。
ocr文字识别软件两大优势:
1. 直接提取图片文字的信息,减少手工输入文字的次数。
2. 节约录入时间,减轻工作量,提高工作效率。
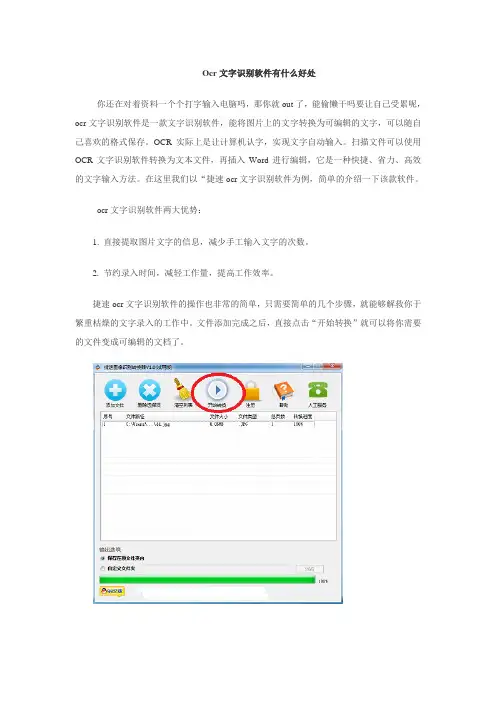
捷速ocr文字识别软件的操作也非常的简单,只需要简单的几个步骤,就能够解救你于繁重枯燥的文字录入的工作中。
文件添加完成之后,直接点击“开始转换”就可以将你需要的文件变成可编辑的文档了。

几款OCR识别软件介绍汉王OCR在最近几年中,OCR识别技术随着扫描仪的普及得到了飞速的发展,扫描、识别软件的性能不断强大并向智能化不断升级发展。
OCR 是英文Optical Character Recognition的缩写,意思为光学字符识别,通称为文字识别,它的工作原理为通过扫描仪或数码相机等光学输入设备获取纸张上的文字图片信息,利用各种模式识别算法分析文字形态特征,判断出汉字的标准编码,并按通用格式存储在文本文件中,由此可以看出,OCR实际上是让计算机认字,实现文字自动输入。
它是一种快捷、省力、高效的文字输入方法。
汉王OCR 是针对机关单位、企业及有文字录入需求的个人用户,在日常的工作中,快速的对书刊、报纸、公文、宣传页等印刷稿件中内容进行录入的应用需求而推出的。
本产品集成了汉王科技顶尖的文字识别技术,对印刷文稿录入的识别率高达99.5%,能够识别百余种印刷字体和各种中英繁表图混排格式的文本,。
是理想的文字、表格、图像录入系统。
这样一来,就不用再手工输入大量的资料了,只要扫进去,像那种抓英文的工具一样,让软件自动地转成WORD文档。
即可将图片变成可编辑的文挡格式。
这是目前破解最完美的汉王OCR软件。
丹青中英日文OCR 辩识白金版4.5安装序列号:MXRD450-7DMN-MM7M-CFCB功能简介原文重现尽在瞬间◎提供繁中、简中和日文三种操作介面◎可辨识繁中、简中、英文及日文四种文件◎辨识后的文件可储存成各种常用档案格式再编辑◎超高辨识速率及辨识率再提升,快速原文重现各式文件产品说明影像扫瞄1. 可处理彩色、灰阶或黑白的文件影像。
2. 倾斜校正:自动侦测文件影像倾斜角度,并提供旋转影像之功能。
辨识文件1. 自动辨识:轻按一钮,即可自动分析、辨识、校对影像文件,图文分离,并转换成可编辑的文件档案。
2. 设定辨识字集:不需切换语文环境,即可辨识繁中、简中、纯英文及日文四种文件。
3. 高辨识速率:在Pentium III 667MHz个人电脑环境下,每秒钟能辨识高达150个中文字。

软件开发中的OCR技术介绍OCR技术是软件开发领域中非常有利的一项技术。
它是Optical Character Recognition(光学字符识别)的缩写,是一项用于将图像或PDF文件中的文字转换为可以搜索、编辑和存储的文本数据的技术。
在本文中,我将介绍OCR技术的优点、应用场景以及相关软件开发工具。
一、OCR技术的优点1. 提高生产效率采用OCR技术可以帮助减少人工数据输入工作量。
传统的手动输入方法往往需要耗费大量的时间和人力,而OCR技术可以帮助用户更快地完成数据导入,从而提高生产效率。
2. 减少错误率手动输入数据时往往会出现打错字、漏打、重复等错误,而OCR技术几乎可以完全避免这些错误。
此外,OCR技术可以快速发现和纠正错误,从而提高数据精度。
3. 可自动处理大量数据OCR技术可以快速自动处理大量数据。
无论是数字输入或是手写文字,OCR技术都能够快速识别出来并进行处理,大大提高了处理速度。
二、OCR技术的应用场景1. 商务OCR技术可以用于处理商务文件,如合同、发票等。
当用户需要在相同的文档中进行数据重复输入时,OCR技术可以自动识别出相同的字段,从而快速完成数据输入。
2. 医疗保健OCR技术可以用于患者的电子病历记录。
医生可以使用手写笔,将病历信息记录到电子表格中,稍后使用OCR技术自动识别这些信息并完成数据输入。
3. 教育OCR技术可用于批量处理试卷,减少人工评卷时间。
学生将试卷放在扫描仪上,OCR技术可以自动识别试卷上的答案,并快速计算分数。
三、相关软件开发工具1. Abbyy FinereaderABBYY FineReader是一款出色的OCR软件,可转换PDF、图像文件和扫描到可搜索的文档格式。
它还包括自动矫正、批量扫描、文本编辑和PDF转换功能,使得OCR识别和文档传输变得更加简单和高效。
2. Google Cloud VisionGoogle Cloud Vision是一种快速和高效的OCR解决方案,可用于将PDF和图像转换为上下文有意义的文本。

⼏款OCR识别软件介绍⼏款OCR识别软件介绍汉王OCR在最近⼏年中,OCR识别技术随着扫描仪的普及得到了飞速的发展,扫描、识别软件的性能不断强⼤并向智能化不断升级发展。
OCR 是英⽂Optical Character Recognition的缩写,意思为光学字符识别,通称为⽂字识别,它的⼯作原理为通过扫描仪或数码相机等光学输⼊设备获取纸张上的⽂字图⽚信息,利⽤各种模式识别算法分析⽂字形态特征,判断出汉字的标准编码,并按通⽤格式存储在⽂本⽂件中,由此可以看出,OCR实际上是让计算机认字,实现⽂字⾃动输⼊。
它是⼀种快捷、省⼒、⾼效的⽂字输⼊⽅法。
汉王OCR 是针对机关单位、企业及有⽂字录⼊需求的个⼈⽤户,在⽇常的⼯作中,快速的对书刊、报纸、公⽂、宣传页等印刷稿件中内容进⾏录⼊的应⽤需求⽽推出的。
本产品集成了汉王科技顶尖的⽂字识别技术,对印刷⽂稿录⼊的识别率⾼达99.5%,能够识别百余种印刷字体和各种中英繁表图混排格式的⽂本,。
是理想的⽂字、表格、图像录⼊系统。
这样⼀来,就不⽤再⼿⼯输⼊⼤量的资料了,只要扫进去,像那种抓英⽂的⼯具⼀样,让软件⾃动地转成WORD⽂档。
即可将图⽚变成可编辑的⽂挡格式。
这是⽬前破解最完美的汉王OCR软件。
丹青中英⽇⽂OCR 辩识⽩⾦版4.5安装序列号:MXRD450-7DMN-MM7M-CFCB功能简介原⽂重现尽在瞬间◎提供繁中、简中和⽇⽂三种操作介⾯◎可辨识繁中、简中、英⽂及⽇⽂四种⽂件◎辨识后的⽂件可储存成各种常⽤档案格式再编辑◎超⾼辨识速率及辨识率再提升,快速原⽂重现各式⽂件产品说明影像扫瞄1. 可处理彩⾊、灰阶或⿊⽩的⽂件影像。
2. 倾斜校正:⾃动侦测⽂件影像倾斜⾓度,并提供旋转影像之功能。
辨识⽂件1. ⾃动辨识:轻按⼀钮,即可⾃动分析、辨识、校对影像⽂件,图⽂分离,并转换成可编辑的⽂件档案。
2. 设定辨识字集:不需切换语⽂环境,即可辨识繁中、简中、纯英⽂及⽇⽂四种⽂件。

Office软件的OCR文字识别OCR(Optical Character Recognition)文字识别技术是一种通过计算机识别和理解图像中的文字信息的技术。
在Office软件中,OCR文字识别技术能够帮助用户将扫描或拍摄的图片文件中的文字内容转换成可编辑的文本文件,极大方便了用户对文字信息的处理和管理。
本文将从OCR文字识别的基本原理、Office软件中的应用、优缺点及未来发展方向等方面进行详细探讨,以便读者对该项技术有进一步的了解。
一、OCR文字识别的基本原理OCR文字识别的基本原理是通过对图像进行预处理,提取出图像中的文字信息,然后利用字符识别技术将提取出的文字信息转换成可编辑的文本文件。
其主要步骤包括图像预处理、文字分割和字符识别三个过程。
在图像预处理环节,需要对图像进行灰度化、二值化、去噪等操作,以便提高后续文字信息的识别效果。
文字分割环节即将提取出的文字进行切割,以便字符识别技术对每个文字进行识别。
最后是字符识别环节,利用模式识别和机器学习等算法对提取出的文字进行识别并转换成文本文件。
二、Office软件中的OCR文字识别应用在Office软件中,OCR文字识别技术主要应用于扫描仪和拍照文档的文字转换。
用户可以通过OCR文字识别功能将扫描或拍摄的图片文件中的文字内容直接转换成可编辑的文本文件,并进行编辑、修改或者复制粘贴等操作。
这一功能在处理扫描版合同、拍摄版书籍、图片版文件等方面具有很大的实用价值,也方便了用户对文字信息的管理和利用。
三、OCR文字识别的优缺点优点:1.方便用户处理图片文件中的文字信息,提高工作效率。
2.能够将图片文件中的文字信息转换为可编辑的文本文件,方便进行编辑和管理。
3.对于扫描版合同、拍摄版书籍等具有重要实用价值的文件起到了极大的便利作用。
缺点:1.对于复杂的图像和文字特征不明显的文档,识别效果可能不佳。
2.非结构化的文档识别困难,需要人工干预进行修正。

OCR文字识别软件是一个利用光学字符识别的原理设计出的一种工具,它可以通过图像处理,文字录入等功能进行的图片与文字转换的操作。
具体操作:
第一步:打开迅捷OCR文字识别软件,在OCR文字识别工具中,有多种功能供我们选择,比如说图片转文字的功能、身份证识别一类型的功能、语音转文字的功能等等。
第二步:在OCR文字识别工具中,我们可以选择语音识别,这个功能就是将语音文件转换成成文字的形式。
第三步:在语音识别的页面内,我们可以先对该功能进行添加语音文件,然后方便我们去对其他的的设置进行调整。
第四步:在语音识别的右侧设置区域,我们需要对输出目录进行调整,在输出目录的位置选择的时候,一定要记牢,以免后期找不到语音转换成文字的文件。
第五步:输出目录调整好之后,就可以点击“开始识别”,如果没有翻译成外文的需要的话可以直接点击“保存为TXT”。
第六步:我们在识别完成后,可以去查看一下保存的TXT文件内容与识别的内容是否一致!
以上关于OCR文字识别的作用与操作大家了解了吗?如果小编哪个地方说的不够详细的话,记得和小编留言哈!。

Office软件的OCR文字识别OCR(Optical Character Recognition)文字识别技术是一种将图像中的文字转换为可编辑文本的技术,它可以帮助用户快速高效地转换图片或扫描件中的文字内容。
在Office软件中,OCR文字识别可以极大地提高工作效率,本文将就Office软件中的OCR文字识别功能进行探讨,并探讨其优势和应用场景。
一、OCR文字识别的基本原理OCR文字识别的基本原理是通过图像处理和模式识别技术,将图片中的文字信息转换成计算机可以识别和编辑的文字信息。
首先,OCR软件会对输入的图片进行预处理,包括图像增强、去噪等操作,然后通过分析像素点的颜色、形状和分布等信息,识别出文字区域,并将其转换成文本信息。
最后,通过文字识别引擎对文本信息进行识别和矫正,生成可编辑的文本文件。
二、Office软件中的OCR文字识别功能在Office软件中,如Word、Excel等,用户可以通过插件或集成的OCR功能,将扫描件或图片中的文字内容进行识别和转换。
OCR识别完成后,用户可以直接在Office软件中编辑、保存和分享识别出的文本内容,极大地提高了办公效率。
通过OCR的识别,用户可以将纸质文档快速转换为电子文档,实现数字化管理。
三、OCR文字识别的优势1.提高工作效率:通过OCR文字识别,用户可以快速将图片或扫描件中的文字内容转换成可编辑文本,省去了手动输入的麻烦,极大地提高了工作效率。
2.实现纸质文档的数字化管理:通过OCR技术,用户可以将纸质文档快速转换为电子文档,方便进行存储、管理和检索。
3.便于编辑和分享:识别后的文本内容可以直接在Office软件中进行编辑、格式调整和分享,方便用户进行后续处理和传播。
四、OCR文字识别的应用场景1.文档扫描和整理:用户可以通过OCR技术将扫描件中的文字内容转换为可编辑文本,实现文档的数字化整理和管理。
2.会议记录和笔记整理:用户可以利用OCR技术将会议记录和手写笔记快速转换为电子文本,并进行整理和归档。

自动识别文字软件的原理
自动识别文字软件的原理基于光学字符识别(OCR)技术。
OCR技术是一种将印刷体或手写体文字转换成可编辑文本的方法,可以从图像或扫描文件中自动识别出文字的过程。
通常,自动识别文字软件的工作流程包括以下几个步骤:
1. 图像预处理:对输入的图像进行预处理,包括去除噪声、调整图像的对比度、亮度、旋转等操作,以提高后续的文字识别准确率。
2. 字符分割:通过一系列的图像处理算法,将输入的图像中的文字进行分割,将每个字符或单词单独提取出来。
字符分割通常是通过边界检测、连通性分析等算法实现。
3. 特征提取:提取每个字符的特征,用于后续的识别。
常用的特征提取方法包括形状特征、轮廓特征、灰度特征等。
4. 字符识别:使用分类算法对提取的字符特征进行识别。
常用的分类算法包括支持向量机(SVM)、最近邻分类器(K-NN)、人工神经网络(ANN)等。
5. 文本重构:将识别出的字符按照顺序组合成文本。
在这一步骤中,软件可能需要进行文字校正、拼接修复等操作。
总的来说,自动识别文字软件通过对输入图像进行预处理,将文字进行分割并提取特征,然后使用分类算法进行识别,并最终将识别结果重构为可编辑的文本。
这一过程需要依赖于先进的图像处理算法和机器学习算法。
Office软件的OCR文字识别随着信息化时代的到来,我们所需要处理和管理的文本数量越来越大。
尤其是在工作中,办公文档与我们息息相关,我们需要时常处理与编辑PDF、WORD等文档格式。
随着OCR技术的快速发展,现如今的Office软件也可以通过OCR技术实现对文档中文字的识别和提取。
Office软件的OCR文字识别已成为我们平时办公的一大利器。
一、OCR技术简介OCR (Optical Character Recognition)技术是一种将图像中的字符转换成文本的技术。
OCR单元应该是一个输入图像,将其数字化并生成字符的文本数据。
OCR技术已经有超过100年的时间了,但一直没有完全满足人们的期望。
但随着近年来计算机,图像处理,机器学习等技术的高速发展,OCR技术已经大有作为。
现在,OCR技术已经能够在各个领域发挥巨大的作用,例如银行票据识别、数字识别、车辆牌照识别等。
二、Office软件的OCR文字识别功能Office软件作为文档编辑与处理的重要软件,其OCR文字识别功能无疑更加方便了我们的工作。
它通过OCR技术识别文档中的文字,实现了将图像信息转换成为文本。
这样,用户可以在Office软件上轻松地处理OCR工作。
【具体示例】以微软Word为例,其OCR文字识别功能提供在“转换文字”菜单下。
我们可以通过以下步骤使用该功能:第一步:打开Word软件并加载需要OCR文字识别的文档第二步:选择需要转换的内容,点击“转换文字”第三步:Word会开始转换并显示可编辑的文本第四步:以文本的形式编辑文档不难看出,这样我们在处理文档时非常方便。
一旦有需要将图片转换成为文本的需求,我们可以轻松地一键操作,就可以进行文本编辑。
三、OCR文字识别的应用范围OCR技术在各个领域都已经得到广泛的应用。
在医药,银行,出版,发票,票房等领域中,使用OCR技术已经成为一种不可或缺的工具。
【OCR在医学中的应用】病历记录是医生工作中的重要内容,而OCR可帮助医生快速而精准地转换医疗文件报告,从而使患者得到更好的治疗。
扫描的文档可以转换为可编辑word文档扫描文字.结果以图片格式(.bmp)存入电脑.然后使用ORC识别系统进行转换.最终用WORD进行修改编辑.下面教你如何使用ORC:OCR是英文Optical Character Recognition的缩写.翻译成中文就是通过光学技术对文字进行识别的意思. 是自动识别技术研究和应用领域中的一个重要方面.它是一种能够将文字自动识别录入到电脑中的软件技术.是与扫描仪配套的主要软件.属于非键盘输入范畴.需要图像输入设备主要是扫描仪相配合.现在OCR主要是指文字识别软件.在1996年清华紫光开始搭配中文识别软件之前.市场上的扫描仪和OCR软件一直是分开销售的。
扫描仪厂商现在已把专业的OCR软件搭配自己生产的扫描仪出售.OCR技术的迅速发展与扫描仪的广泛使用是密不可分的.近两年随着扫描仪逐渐普及和OCR技术的日臻完善.OCR己成为绝大多数扫描仪用户的得力助手.一.OCR技术的发展历程自20世纪60年代初期出现第一代OCR产品开始.经过30多年的不断发展改进.包括手写体的各种OCR技术的研究取得了令人瞩目的成果.人们对OCR产品的功能要求也从原来的单纯注重识别率.发展到对整个OCR系统的识别速度.用户界面的友好性.操作的简便性.产品的稳定性.适应性.可靠性和易升级性.售前售后服务质量等各方面提出更高的要求.IBM公司最早开发了OCR产品.1965年在纽约世界博览会上展出了IBM公司的OCR产品--IBMl287.当时的这款产品只能识别印刷体的数字.英文字母及部分符号.并且必须是指定的字体.20世纪60年代末.日立公司和富士通公司也分别研制出各自的OCR产品.全世界第一个实现手写体邮政编码识别的信函自动分拣系统是由日本东芝公司研制的.两年后NEC公司也推出了同样的系统.到了1974年.信函的自动分拣率达到92%左右.并且广泛地应用在邮政系统中.发挥着较好的作用.1983年日本东芝公司发布了其识别印刷体日文汉字的OCR系统OCRV595.其识别速度为每秒70-100个汉字.识别率为99.5%.其后东芝公司又开始了手写体日文汉字识别的研究工作.中国在OCR技术方面的研究工作相对起步较晚.在20世纪70年代才开始对数字.英文字母及符号的识别技术进行研究.20世纪70年代末开始进行汉字识别的研究.1986年.国家863计划信息领域课题组织了清华大学.北京信息工程学院.沈阳自动化所三家单位联合进行中文OCR软件的开发工作.至*****.清华大学率先推出了国内第一套中文OCR软件--清华文通TH-OCR1.0版.至此中文OCR正式从实验室走向了市场.清华OCR印刷体汉字识别软件其后又推出了TH-OCR 92高性能实用简/繁体.多字体.多功能印刷汉字识别系统.使印刷体汉字识别技术又取得重大进展.到1994年推出的TH-OCR 94高性能汉英混排印刷文本识别系统.则被专家鉴定为[是国内外首次推出的汉英混排印刷文本识别系统.总体上居国际领先水平".上个世纪90年代中后期.清华大学电子工程系提出并进行了汉字识别综合研究.使汉字识别技术在印刷体文本.联机手写汉字识别.脱机手写汉字识别和脱机手写数字符号识别等领域全面地取得了重要成果.具有代表性的成果是TH-OCR 97综合集成汉字识别系统.它可以完成多文种(汉.英.日)印刷文本.联机手写汉字.脱机手写汉字和手写数字的识别输入.几年来.除清华文通TH-OCR外.其它如尚书SH-OCR等各具风格的OCR软件也相继问世.中文OCR市场稳步扩大.用户遍布世界各地.可以说目前印刷体OCR的识别技术已经达到较高水平.OCR产品已由早期的只能识别指定的印刷体数字.英文字母和部分符号.发展成为可以自动进行版面分析.表格识别.实现混合文字.多字体.多字号.横竖混排识别的强大的计算机信息快速录入工具.对印刷体汉字的识别率达到98%以上.即使对印刷质量较差的文字其识别率也达到95%以上.可识别宋体.黑体.楷体.仿宋体等多种字体的简.繁体.并且可以对多种字体.不同字号混合排版进行识别.对手写体汉字的识别率达到70%以上.特别是我国的汉字OCR技术经过十几年的努力.克服了起步晚.汉字字符集异常庞大等困难.单字的识别速度(指在单位时间内所完成的从特征提取到识别结果输出的字数)可以达到70字/秒以上.由于印刷体OCR汉字识别技术已经比较成熟.所以OCR产品被广泛地应用在新闻.印刷.出版.图书馆.办公自动化等各个行业.专业型OCR产品多是面向特定的行业.即适用于每天需处理大量表格信息录入的部门.如邮政.税务.海关.统计等等.这种面向特定行业的专业型OCR系统.格式较为固定.识别的字符集相对较小.经常与专用的输入设备结合使用.因此具有速度快.效率高等特点.比如邮件自动分拣系统等.手写文稿的识别直到1996.1997年才开始有产品问世.而且是作为印刷文稿识别产品的一项附加功能提供的.由于人写字的习惯千差万别.实现自由手写体识别相当困难.所以手写体OCR技术的使用领域是联机手写体识别.即人一边写.计算机一边识别.是一种实时识别方式.二.OCR的基本原理简单地说.OCR的基本原理就是通过扫描仪将一份文稿的图像输入给计算机.然后由计算机取出每个文字的图像.并将其转换成汉字的编码.其具体工作过程是.扫描仪将汉字文稿通过电荷耦合器件CCD将文稿的光信号转换为电信号.经过模拟/数字转换器转化为数字信号传输给计算机.计算机接受的是文稿的数字图像.其图像上的汉字可能是印刷汉字.也可能是手写汉字.然后对这些图像中的汉字进行识别.对于印刷体字符.首先采用光学的方式将文档资料转换成原始黑白点阵的图像文件.再通过识别软件将图像中的文字转换成文本格式.以便文字处理软件的进一步加工.其中文字识别是OCR的重要技术.1.OCR识别的两种方式与其它信息数据一样.在计算机中所有扫描仪捕捉到的图文信息都是用0.1这两个数字来记录和进行识别的.所有信息都只是以0.1保存的一串串点或样本点.OCR 识别程序识别页面上的字符信息.主要通过单元模式匹配法和特征提取法两种方式进行字符识别.单元模式匹配识别法(Pattern Matching)是将每一个字符与保存有标准字体和字号位图的文件进行不严格的比较.如果应用程序中有一个已保存字符的大数据库.则应用程序会选取合适的字符进行正确的匹配.软件必须使用一些处理技术.找出最相似的匹配.通常是不断试验同一个字符的不同版本来比较.有些软件可以扫描一页文本.并鉴别出定义新字体的每一个字符.有些软件则使用自己的识别技术.尽其所能鉴别页面上的字符.然后将不可识别的字符进行人工选择或直接录入.特征提取识别法(Feature Extraction)是将每个字符分解为很多个不同的字符特征.包括斜线.水平线和曲线等.然后.又将这些特征与理解(识别)的字符进行匹配.举个简单的例子.应用程序识别到两条水平横线.它就会[认为"该字符可能是[二".特征提取法的优点是可以识别多种字体.例如中文书法体就是采用特征提取法实现字符识别的.多数OCR应用软件都加入了语法智能检查功能.这种功能进一步提高了识别率.它主要通过上下文检查法实现拼写和语法的纠正.在文字识别时.OCR应用程序会做多次的上下文衔接性检查.根据程序中已经存在的词组.固定的用词顺序.对应的检查字符串的用词字.比较高级的应用软件会自动用它[认为"正确的词语替换错误词语.纠正语句意思.2.文字识别的几个步骤文字识别包括以下几个步骤:图文输入.预处理.单字识别和后处理等.(1)图文输入是指通过输入设备将文档输入到计算机中.也就是实现原稿的数字化.现在用得比较普遍的设备是扫描仪.文档图像的扫描质量是OCR软件正确识别的前提条件.恰当地选择扫描分辨率及相关参数.是保证文字清楚.特征不丢失的关键.此外.文档尽可能地放置端正.以保证预处理检测的倾斜角小.在进行倾斜校正后.文字图像的变形就小.这些简单的操作.会使系统的识别正确率有所提高.反之.由于扫描设置不当.文字的断笔过多可能会分检出半个文字的图像.文字断笔和笔画粘连会造成有些特征丢失.在将其特征与特征库比较时.会使其特征距离加大.识别错误率上升.(2)预处理扫描一幅简单的印刷文档的图像.将每一个文字图像分检出来交给识别模块识别.这一过程称为图像预处理.预处理是指在进行文字识别之前的一些准备工作.包括图像净化处理.去掉原始图像中的显见噪声(干扰).主要任务是测量文档放置的倾斜角.对文档进行版面分析.对选出的文字域进行排版确认.对横.竖排版的文字行进行切分.每一行的文字图像的分离.标点符号的判别等.这一阶段的工作非常重要.处理的效果直接影响到文字识别的准确率.版面分析是对文本图像的总体分析.是将文档中的所有文字块分检出来.区分出文本段落及排版顺序.以及图像.表格的区域.将各文字块的域界(域在图像中的始点.终点坐标).域内的属性(横.竖排版方式)以及各文字块的连接关系作为一种数据结构.提供给识别模块自动识别.对于文本区域直接进行识别处理.对于表格区域进行专用的表格分析及识别处理.对于图像区域进行压缩或简单存储.行字切分是将大幅的图像先切割为行.再从图像行中分离出单个字符的过程.(3)单字识别单字识别是体现OCR文字识别的核心技术.从扫描文本中分检出的文字图像.由计算机将其图形.图像转变成文字的标准代码.是让计算机[认字"的关键.也就是所谓的识别技术.就像人脑认识文字是因为在人脑中已经保存了文字的各种特征.如文字的结构.文字的笔画等.要想让计算机来识别文字.也需要先将文字的特征等信息储存到计算机里.但要储存什么样的信息及怎样来获取这些信息是一个很复杂的过程.而且要达到非常高的识别率才能符合要求.通常采用的做法是根据文字的笔画.特征点.投影信息.点的区域分布等进行分析.中国汉字常用的就有几千.识别技术就是特征比较技术.通过和识别特征库的比较.找到特征最相似的字.提取该文字的标准代码.即为识别结果.比较是人们认识事物的一种基本方法.汉字识别也是通过比较找出汉字之间的相同.相似.相异.把握其量和质的关系.以及时间与空间的关系等.对于大字符集的汉字一般采用多级分类.多特征.全方位动态匹配求相似集.以保证分类率高.适应性强.稳定性好,细分类重点在于对相似集求异匹配.加权处理.结构判别.定量.定性分析.以及前后联接词的关系.最后进行判别.汉字识别实质上是比较科学或认知科学在人工智能方面的应用.其关键技术是识别特征库.计算机有了这样的一个特征库.才能完成认字的功能.在图像文档的版面中.除了有文字.图片.有时还会有表格存在.为了使识别后的表格数字化.需要在版面分析过程中.对表格域进行特殊的处理.它包括对表格线的结构信息的提取.对表格内文字域的分检.完成对表格线和对文字域的识别.并根据表格线的数字化生成不同的文件格式.由于文档中的表格随意性大.格式多样.有封闭式的.也有开放式的.特别是表格中的斜线.给表格分析造成一定的困难.(4)后处理后处理是指对识别出的文字或多个识别结果采用词组方式进行上下匹配.即将单字识别的结果进行分词.与词库中的词组进行比较.以提高系统的识别率.减少误识率.汉字字符识别是文字识别领域最为困难的问题.它涉及模式识别.图像处理.数字信号处理.自然语言理解.人工智能.模糊数学.信息论.计算机.中文信息处理等学科.是一门综合性技术.近几年来.印刷汉字识别系统的单字识别正确率已经超过95%.为了进一步提高系统的总体识别率.扫描图像.图像的预处理以及识别后处理等方面的技术也都得到了深入的研究.并取得了长足的进展.有效地提高了印刷汉字识别系统的总体性能.清华大学在此方面的研究成果突出.已经成为世界上的最具权威的机构之一.目前.清华紫光的全系列扫描仪中都配装了清华OCR千禧版软件.它在识别率.表格识别甚至规范手写体的识别方面.均达到了较高水平.三.OCR文字识别技巧在最近几年中.OCR识别技术随着扫描仪的普及得到了飞速的发展.扫描.识别软件的性能不断强大并向智能化不断升级发展.但是要想快速地获取正确的扫描结果.得到高效率的文字录入.必须认真学习有关知识.结合实践经验.摸索出自己的全套解决方案.有时我们在作文字识别工作时识别率非常低.根本达不到软件所说的95%以上.请先不要责怪硬件或软件.其实这是没有掌握好扫描及OCR识别技巧的原因.下面是文字识别操作中经常用到了一些方法和技巧.1.分辨率的设置是文字识别的重要前提.一般来讲.扫描仪提供较多的图像信息.识别软件比较容易得出识别结果.但也不是扫描分辨率设得越高识别正确率就越高.选择300dpi或400dpi分辨率.适合大部分文档扫描.注意文字原稿的扫描识别.设置扫描分辨率时千万不要超过扫描仪的光学分辨率.不然会得不偿失.下面是部分典型设置.仅供参考.(1)1.2.3号字的文章段.推荐使用200dpi.(2)4.小4.5号字的文章段.推荐使用300dpl(3)小5.6号字的文章段.推荐使用400dpl(4)7.8号字的文章段.推荐使用600dpi.2. 扫描时适当地调整好亮度和对比度值.使扫描文件黑白分明.这对识别率的影响最为关键.扫描亮度和对比度值的设定以观察扫描后的图像中汉字的笔画较细但又不断开为原则.进行识别前.先看看扫描得到的图像中文字质量如何.如果图像存在黑点或黑斑时或文字线条很粗很黑.分不清笔画时.说明亮度值太小了.应该增加亮度值在试试,如果文字线条凹凸不平.有断线甚至图像中汉字轮廓严重残缺时.说明亮度值太大了.应减小亮度后再试试.3.选好扫描软件.选一款好的适合自己的OCR软件是作好文字识别工作的基础.一般不要使用扫描仪自带的OEM软件.OEM的OCR软件的功能少.效果差.有的甚至没有中文识别.经过比较.我认为清华紫光OCR2003专业版和尚书OCR6.0文本自动识别输入系统的识别能力与使用功能更突出一些.再选一个图像软件.OCR软件不是有扫描接口吗?为什么还找图像软件?第一.OCR软件不能识别所有的扫描仪,第二.也是最关键的.利用图像软件的扫描接口扫描出来的图像便于处理,一般选用PHOTOSHOP.4.如果要进行的文本是带有格式的.如粗体.斜体.首行缩进等.部分OCR软件识别不出来.会丢失格式或出现乱码.如果必须扫描带有格式的文本.事先要确保使用的识别软件是否支持文字格式的扫描.也可以关闭样式识别系统.使软件集中注意力查找正确的字符.不再顾及字体和字体格式.。
我们很多人都知道OCR文字识别软件是一种识别工具,那它到底能做些什么呢?大家其实可以深入的了解一下。
今天小编就详细的给大家具体的分享一下OCR文字识别软件的功能。
功能一:极速识别
极速识别是一种识别图片的功能,它可以将图片文字识别出来,并且可以选择是识别的格式是word格式还是TXT格式。
功能二:票证识别
票证识别可以识别多种票据,比如说身份证、银行卡、驾驶证、发票等票证识别。
功能三:语音识别
语音识别是一种将音频文件转换成文字文件的识别,并且支持多种格式的音频文件。
比如说MP3、MAV、M4A、WMA、AC3、M4R等。
功能四:高级识别
高级识别也是一种图片转换的功能,他可以将图片内容转化成word格式或者是图片格式。
功能五:图片局部识别
图片局部识别可以将添加成功的图片进行局部截取,选取我们需要的部分进行识别。
功能六:截图识别
截图识别是一种现场截图就可以进行识别的功能,打开图片,点击我们的“开始截图”就可以进行截图。
以上就是我们该OCR文字识别软件几种功能的具体介绍了,大家可以了解一下哦!。
ocr识别概述OCR(Optical Character Recognition,光学字符识别)是一种技术,旨在将图像或手写文本转化为可编辑的文本文档。
它是一种重要的信息处理技术,被广泛用于数字化文档、自动化数据输入、文档管理和信息检索等领域。
以下是OCR识别的概述:OCR工作原理:OCR系统通过分析输入的图像或扫描的文档,检测和识别其中的字符、字母、数字和标点符号。
OCR软件使用图像处理技术,如文本分割、字符识别、校正等,将图像中的文本转化为计算机可编辑的文本数据。
OCR的应用领域:OCR技术在各种领域都有广泛的应用,包括但不限于以下几个方面:1. 文档数字化:OCR可用于将纸质文档、书籍、报纸等转化为电子文本。
2. 数据输入:OCR可用于自动化数据输入,如扫描票据、护照、驾驶证等。
3. 文档管理:OCR帮助管理和分类大量文档,提高检索效率。
4. 图书馆和档案:OCR用于数字化保留的历史文件、档案和书籍。
5. 自动识别车牌和手写文本:OCR还用于车牌识别和手写文字识别等应用。
OCR的挑战:OCR技术在处理印刷文本时通常表现出色彩一致、清晰度高的图像上非常出色,但在以下情况下可能面临挑战:1. 手写文本:手写文本的识别比印刷文本更具挑战性。
2. 低质量图像:模糊、有噪音或低分辨率的图像可能导致错误的识别结果。
3. 多语言和多字体:一些OCR系统需要处理多种语言和字体。
OCR的发展趋势:OCR技术不断发展,新的趋势包括:1. 深度学习:利用深度学习技术,OCR系统在字符和字体识别上取得了巨大进展。
2. 多语言支持:新一代OCR系统支持多种语言,从而满足全球化需求。
3. 移动应用:OCR应用已广泛用于移动设备,帮助用户扫描文档并将其转化为可编辑文本。
总之,OCR技术在数字时代发挥着越来越重要的作用,为文档处理和信息管理提供了高效的解决方案,减少了大量繁重的手工数据输入工作,提高了工作效率。
ocr文字识别详解一、概述OCR(Optical Character Recognition)技术是一种将图像中的文字转换成可编辑和可搜索的文本的技术。
OCR技术广泛应用于各种领域,如文档处理、图像分析、自动化识别等。
本文将详细介绍OCR技术的原理、应用、优缺点以及常见的OCR软件。
二、OCR原理OCR技术的基本原理是通过光学扫描设备将纸质文档或图像中的文字转换为电子化的文字。
具体来说,OCR系统通常包括以下几个步骤:1. 图像预处理:对原始图像进行去噪、灰度化、二值化等处理,以提高文字识别的准确性。
2. 文字定位:通过识别图像中的字符形状,确定文字区域。
3. 特征提取:对文字区域中的字符进行特征提取,如笔画、边界等。
4. 匹配与识别:根据提取的特征,将字符与数据库中的标准字符进行匹配,识别出具体的文字。
OCR技术的核心是文本检测和识别算法。
文本检测算法用于确定文字区域,常用的算法有边缘检测算法、霍夫变换等。
识别算法则根据提取的特征,将字符与数据库中的标准字符进行匹配,常用的算法有基于模板匹配、神经网络等。
三、OCR应用OCR技术的应用非常广泛,包括但不限于以下领域:1. 文档处理:将纸质文档转换为电子化文档,便于存储、传输和编辑。
2. 图像分析:通过对图像中的文字进行识别,提取关键信息,如车牌号码、人脸识别等。
3. 自动化识别:在生产线、物流等领域,通过OCR技术实现自动化识别和分拣。
四、OCR优缺点OCR技术的优点:1. 提高了文字识别的准确性,降低了人为误判的可能性。
2. 降低了对硬件设备的要求,如打印机、扫描仪等。
3. 实现了文字的无纸化传输和编辑,方便了信息的共享和利用。
OCR技术的缺点:1. 对扫描质量的要求较高,扫描质量差可能导致识别错误。
2. 对文字的字体、字号和排版有要求,不同的字体和字号可能需要不同的识别算法。
3. 对复杂背景和干扰因素(如阴影、反光等)的抵抗力较弱。
五、常见OCR软件介绍目前市面上有很多OCR软件可供选择,以下介绍几款常用的OCR 软件:1. Adobe Acrobat:Adobe Acrobat是Adobe公司的一款产品,它提供了OCR功能,可以将扫描后的图像中的文字转换为可编辑的文本。
浅谈OCR图像转换成文字的工具--文档识别
当我们好不容易找到一篇自己喜欢的文章,就因为是纸质的,无法在电脑或者手机上操作,必须用手去录入;就因为是PDF或其他电子格式,有的甚至进行了加密,无法编辑和排版,只能望文兴叹。
文档最终只有转换成word和txt文档,才能任自己随便编辑。
在这个背景下,我们一起去了解一下一款文档识别软件-云脉文档识别的软件。
云脉文档识别利用摄像头、扫描仪及高拍仪拍摄或扫描文档(打印文件、报纸、杂志、书本等)图像的方式,自动识别图像上的文字信息,并可立即在线翻译,发电邮、发短信、发微博、网络搜索、网络翻译等,同时为学习或工作提供便利。
还可利用识别后的文字快捷检索文档图像。
用“云脉文档识别”软件可以将书籍,报纸等纸质上面的文字转换成文本文字。
识别后的文字可以剪切复制,可以任意编辑。
识别率很高。
这款文档识别的“记事本”可以随时随地为你记录所需的信息,省时便捷。
对于喜欢看书看报做笔记的朋友,真是必备的神器!
软件功能:
云脉文档识别支持Android、iOS等手机操作系统,利用手机直接拍摄或导入已有文档图像的方式,自动识别图像上的文字信息,并可即时在线翻译,或通过电邮、短信等方式分享给好友。
- 利用手机摄像头拍摄文档(报纸、杂志、书本、路牌等),自动识别图像
- 可导入手机中已有的文档图像进行软件处理
- 可在识别结果界面编辑,或直接在线翻译,或发送E-mail、彩信等
对于经常需要详细的文档录入的朋友,云脉文档识别这款应用在功能、使用体验及识别率上,都有着相当不错的表现。
有这方面使用需求的推荐使用。
软件截图:。
浅谈文字识别软件OCR
汉字识别软件的任务是研究如何使计算机能够“识字”,该系统通常是采用光电转换装置将汉字或字符转换成电信号,并送入计算机,由计算机自动辨认、阅读,因此称其为光学字符识别(OpticalCharacterRecognition),简称为OCR)。
OCR的发展简况
OCR的概念是在1929年由德国科学家Tausheck最先提出来的,后来美国科学家Handel也提出了利用技术对文字进行识别的想法。
而最早对印刷体汉字识别进行研究的是IBM公司的Casey和Nagy,1966年他们发表了第一篇关于汉字识别的文章,采用了模板匹配法识别了1000个印刷体汉字。
20世纪70年代初,日本的学者开始研究汉字识别,并做了大量的工作。
我国研究汉字识别的起步比较晚,20世纪70年代末才开始进行OCR的研究工作。
早期的OCR软件,由于识别率及产品化等多方面的因素,未能达到实际要求。
同时,由于硬件设备成本高、运行速度慢,也没有达到实用的程度。
只有个别部门,如信息部门、新闻出版单位等使用OCR软件。
1986年以后我国的OCR研究有了很大进展,在汉字建模和识别方法上都有所创新,在系统研制和开发应用中都取得了丰硕的成果,不少单位相继推出了中文OCR产品。
进入20世纪90年代以后,随着平台式扫描仪的广泛应用,以及我国信息自动化和办公自动化的普及,大大推动了OCR技术的进一步发展,使OCR的识别正确率、识别速度满足了广大用户的要求。
目前,比较流行的OCR软件很多,英文OCR主要有OmniPage,中文OCR 主要有清华紫光OCR、清华文通OCR、汉王OCR、中晶尚书OCR、丹青OCR、蒙恬OCR等。
尽管汉字字量大、字形复杂,但OCR技术已经走向成熟。
许多OCR 软件不仅能识别黑白印刷体汉字,还能识别灰度和彩色印刷体汉字,识别速度很快,识别正确率达到了99%以上;可识别宋体、黑体、楷体等多种字体的简、繁体;
可对多种字体、不同字号的混排进行识别;有些OCR软件还能识别图像、表格。
与此同时,对于手写体汉字识别的研究也取得了很大进展,正确识别率已达到了70%以上。
OCR软件的应用
在扫描仪市场上,许多类型的办公和家用扫描仪均配有OCR软件,如紫光的扫描仪配备了紫光OCR,中晶的扫描仪配备了尚书OCR,Mustek的扫描仪配备了丹青OCR等。
扫描仪与OCR软件共同承担着从文稿的输入到文字识别的全过程。
文稿扫描在办公领域中经常用到,即将报纸、杂志等媒体上刊载的有关文稿通过扫描仪进行扫描,随后进行OCR识别,或存储成图像文件,留待以后进行OCR 识别,将图像文件转换成文本文件或Word文件进行存储。
此外,数字化信息的存储、传输,不仅成本低、效率高,而且能够适应排版、网络传输等不断发展的需要。
目前我国有很多历史遗留下来的大量图书、报刊、杂志等纸质珍品,急需将其转换成电子信息。
如电子图书馆的建立,就需要将图书逐页扫描,加上OCR软件的识别,更替代了人工键入文字的工作,大大缩短了录入时间,减轻了劳动强度,节省了人力且降低了费用,提高了录入正确率、工作效率和现代办公自动化程度。
目前OCR软件与扫描仪的搭配已应用到信息化时代的多个领域,如数字化图书馆,各种报表的识别,以及银行、税务系统票据的识别等。
随着网络化、信息化的发展与普及,其应用范围将越来越广泛。
OCR系统的组成
汉字识别软件OCR的功能是将各种录入汉字、印刷体或手写体中每个汉字的图形或图像通过计算机辨认出来,并标出汉字类别代码。
因此,汉字识别归根结底是一个图像识别问题。
由于汉字信息量很大,具有不同的字形、字体,而且结构复杂,因此汉字识别的过程极其复杂。
由于扫描仪的普及与广泛应用,OCR软件只需提供与扫描仪的接口,利用扫描仪驱动软件即可。
因此,OCR软件主要是由图像处理模块、版面划分模块、文字识别模块和文字编辑模块等4部分组成。
1.图像处理模块
图像处理模块主要具有文稿扫描、图像缩放、图像旋转等功能。
通过扫描仪输入后,文稿形成图像文件,图像处理模块可对图像进行放大,去除污点和划痕,如果
图像放置不正,可以手工或自动旋转图像,目的是为文字识别创造更好的条件,使识别率更高。
2.版面划分模块
版面划分模块主要包括版面划分、更改划分,即对版面的理解、字切分、归一化等,可选择自动或手动两种版面划分方式。
目的是告诉OCR软件将同一版面的文章、表格等分开,以便于分别处理,并按照怎样的顺序进行识别。
3.文字识别模块
文字识别模块是OCR软件的核心部分,文字识别模块主要对输入的汉字进行“阅读”,但不能一目多行,必须逐行切割,对于汉字通常也是一个字一个字地辨认,即单字识别,再进行归一化。
文字识别模块通过对不同样本汉字的特征进行提取,完成识别,自动查找可疑字,具有前后联想等功能。
4.文字编辑模块
文字编辑模块主要对OCR识别后的文字进行修改、编辑,如系统识别认为有误,则文字会以醒目的红色或蓝色显示,并提供相似的文字供选择,选择编辑器供输出等。
OCR软件的使用方法
OCR软件的种类虽然很多,但其使用方法大同小异。
首先要对文稿进行扫描,然后进行OCR识别。
OCR软件的使用方法如下:
1.文稿扫描
为了利用OCR软件进行文字识别,可直接在OCR软件中扫描文稿。
运行OCR 软件后,会出现OCR软件界面。
如使用中晶尚书OCR。