数据库课程设计之无损连接性
- 格式:docx
- 大小:412.79 KB
- 文档页数:21
![[总结]关系数据库设计基础(函数依赖、无损连接性、保持函数依赖、范式、……)](https://uimg.taocdn.com/af34390811a6f524ccbff121dd36a32d7375c7be.webp)
[总结]关系数据库设计基础(函数依赖、⽆损连接性、保持函数依赖、范式、……)≏≎≟≗≖≍≭∼∽≁≃≂≅≊≈≉≇≳⪞⪆⋧⪊≵≲⪝⪅⋦⪉≴⊂ subset ⋐⊄⊊ ⊈⊃⊇ ⋑⊅⊋ ⊉≺⪯≼⋞≾⪷⋨⪵⪹⊀≻⪰≽⋟≿⪸⋩⪶⪺⊁ in ∋∉∌∝≬⊸函数依赖(Function Dependency)定义设关系模式R(U),属性集合U= {A1,A2,…,An},X,Y为属性集合U的⼦集,如果对于关系模式R(U)的任⼀可能的关系r,r中的任意两个元组u、v,若有 u[X]=v[X],就有u[Y]=v[Y],则称X函数决定Y,或称Y函数依赖于X。
⽤符号X→Y表⽰。
其中X为决定因素,Y为被决定因素。
若对于R(U)的任意⼀个可能的关系r,r中不可能存在两个元组在X上的属性值性等,⽽在Y上的属性值不等。
(1) 函数依赖是语义范畴的概念,只能根据语义来确定⼀个函数依赖关系。
(2) 函数依赖X→Y的定义要求关系模式R的任何可能的关系r中的元组都满⾜函数依赖条件。
术语 (1)若X→Y,则X称作决定因素(Determinant) (2)若X→Y,Y→X,称作X<->Y。
(3)若Y不函数依赖于X,称作X -/-> Y。
(4)X→Y,若Y不包含X,即X ⊄ Y,则称X→Y为⾮平凡的函数依赖。
正常讨论的都是⾮平凡的函数依赖。
(5)X→Y,若Y包含X,即X ⊂ Y,则称X→Y为平凡的函数依赖。
(6)完全函数依赖(full functional dependency):在R(U)中,设X、Y是关系模式R(U)中不同的属性⼦集(即X ⊂ U,Y ⊂ U), 若存在 X→Y,且不存在 X的任何真⼦集X'(即 X' ⊊ X),使得 X'→Y,则称Y完全函数依赖 ( full functional dependency ) 于X。
记作 X-F->Y。
(7)部分函数依赖:在关系模式R(U)中,X、Y是关系模式R(U)中不同的属性⼦集(即X ⊂ U,Y ⊂ U), 若X→Y成⽴,如果X中存在任何真⼦集X'(即 X' ⊊ X),⽽且有X'→Y也成⽴,则称Y对X是部分函数依赖,记作:X-P->Y。

数据库重难点(无损连接和范式)模式分解的几个重要事实:若只要求分解具有“无损连接性”,一定可以达到4NF;若要求分解要“保持函数依赖”,可以达到3NF,但不一定能达到BCNF;若要求分解既要“保持函数依赖”,又要具有“无损连接性”,可以达到3NF,但不一定能达到BCNF;试分析下列分解是否具有无损联接和保持函数依赖的特点:设R(ABC),F1={A→B} 在R上成立,ρ1={AB,AC}。
首先,检查是否具有无损联接特点:第1种解法--算法4.2:A B C AB a1 a2 b13 AC a1 b22 a3 A B C a1 a2 b13 a1 a2 a3(1) 构造表(2)根据A→B进行处理结果第二行全是a行,因此分解是无损联接分解。
第2种解法:(定理4.8)R1(AB)∩R2(AC)=AR2- R1=B∵A→B,∴该分解是无损联接分解。
然后,检查分解是否保持函数依赖πR1(F1)={A→B,以及按自反率推出的一些函数依赖}πR2(F1)={按自反率推出的一些函数依赖}F1被πR1(F1)所蕴涵,∴所以该分解保持函数依赖。
范式当查询涉及到针对“否定”特征含义的查询要求,如“不”、“没有”等字眼,一般要用差运算表示。
针对“全部”特征含义的查询要求,如“全部”、“至少”、“包含”等字眼,一般要用除法运算。
?1NF :R(A,B,C,D)依赖集(ab>c a->d) 因为d部分依赖于ab 所以属于1NF 不属于2NF 2NF :R(A,B,C,D)依赖集(ab>c c—>d)因为d传递依赖与AB 但是不存在部分依赖所以属于2N 不属3NF 3NF : R(A,B,C,D)依赖集(ab>c ab—>d,d->a) 因为即不存在部分依赖也不存在传递依赖所以属于3NF 但是因为d->a因为d是非主属性所以不属于BCNF1、第一范式(1NF):一个关系模式R的所有属性都是不可分的基本数据项。

2022年南华大学软件工程专业《数据库原理》科目期末试卷A(有答案)一、填空题1、在关系数据库的规范化理论中,在执行“分解”时,必须遵守规范化原则:保持原有的依赖关系和______。
2、采用关系模型的逻辑结构设计的任务是将E-R图转换成一组______,并进行______处理。
3、关系规范化的目的是______。
4、设在SQL Server 2000环境下,对“销售数据库”进行的备份操作序列如下图所示。
①出现故障后,为尽可能减少数据丢失,需要利用备份数据进行恢复。
首先应该进行的恢复操作是恢复_____,第二个应该进行的恢复操作是恢复_____。
②假设这些备份操作均是在BK设备上完成的,并且该备份设备只用于这些备份操作,请补全下述恢复数据库完全备份的语句RESTORE_____FROM BKWITH FILE=1,_____;5、安全性控制的一般方法有____________、____________、____________、和____________视图的保护五级安全措施。
6、在SQL语言中,为了数据库的安全性,设置了对数据的存取进行控制的语句,对用户授权使用____________语句,收回所授的权限使用____________语句。
7、以子模式为框架的数据库是______________;以模式为框架的数据库是______________;以物理模式为框架的数据库是______________。
8、主题在数据仓库中由一系列实现。
一个主题之下表的划分可按______、______数据所属时间段进行划分,主题在数据仓库中可用______方式进行存储,如果主题存储量大,为了提高处理效率可采用______方式进行存储。
9、数据库管理系统的主要功能有______________、______________、数据库的运行管理以及数据库的建立和维护等4个方面。
10、____________和____________一起组成了安全性子系统。


数据库设计中的数据完整性和一致性保证方法在数据库设计和管理过程中,数据的完整性和一致性是非常重要的考虑因素。
数据的完整性指的是数据库中的数据必须满足预定义的规则和约束,以保证数据的准确性和可靠性;而数据的一致性则指的是数据库中的数据在任何时刻都必须保持一致状态,以避免数据冲突和不一致的情况发生。
为了保证数据的完整性,数据库设计人员可以采用多种方法。
首先,数据字段的定义应该清晰明确,每个字段的数据类型和长度都应该根据具体需求进行规定,避免数据类型的混乱和数据长度的限制。
例如,在设计一个用户表时,姓名字段的数据类型可以选择字符串,且长度限制为20个字符以内,以保证用户姓名的数据完整性。
其次,合理设置数据的约束条件也是保证数据完整性的重要手段。
在数据库中,可以使用各种约束条件来限制数据的取值范围和规则,如主键约束、外键约束、唯一约束等。
主键约束可以确保每条记录的唯一性,外键约束可以保证多个表之间的数据关联完整性,唯一约束可以限制某个字段的取值范围。
通过设置这些约束条件,可以有效地提高数据的完整性。
此外,数据库设计人员还可以采用触发器来保证数据的完整性。
触发器是一种在数据插入、修改或删除时自动触发的特殊存储过程,可以在操作数据之前或之后执行某些操作。
通过编写触发器,可以在数据操作之前对数据进行校验和验证,从而保证数据的完整性。
例如,在设计一个订单表时,可以在插入订单数据之前编写一个触发器来检查订单总金额是否大于0,以避免无效的订单数据。
除了数据完整性,数据的一致性也是数据库设计中需要重视的问题。
为了保证数据的一致性,数据库设计人员可以采用事务处理的方式。
事务是一组数据库操作的集合,这些操作要么全部成功,要么全部失败,保证了数据在进行一系列操作过程中的一致性。
在实际应用中,可以使用数据库的事务处理语句,如BEGIN、COMMIT和ROLLBACK等来处理数据的一致性问题。
通过合理设置事务的范围和粒度,可以有效地保证数据的一致性。

第一部分基本概念一,单项选择题1.在数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。
在这几个阶段中,数据独立性最高的是阶段。
AA.数据库系统 B.文件系统C.人工管理 D.数据项管理2.数据库系统与文件系统的主要区别是。
BA.数据库系统复杂,而文件系统简单B.文件系统不能解决数据冗余和数据独立性问题,而数据库系统可以解决C.文件系统只能管理程序文件,而数据库系统能够管理各种类型的文件D.文件系统管理的数据量较少,而数据库系统可以管理庞大的数据量3.数据库的概念模型独立于。
AA.具体的机器和DBMS B.E-R图C.信息世界 D.现实世界4.数据库是在计算机系统中按照一定的数据模型组织、存储和应用的①,支持数据库各种操作的软件系统叫②,由计算机、操作系统、DBMS、数据库、应用程序及用户等组成的一个整体叫做③。
BBB① A.文件的集合 B.数据的集合C.命令的集合 D.程序的集合② A.命令系统 B.数据库管理系统C.数据库系统 D.操作系统③ A.文件系统 B.数据库系统C.软件系统 D.数据库管理系统5.数据库的基本特点是。
BA.(1)数据可以共享(或数据结构化) (2)数据独立性(3)数据冗余大,易移植 (4)统一管理和控制B.(1)数据可以共享(或数据结构化) (2)数据独立性(3)数据冗余小,易扩充 (4)统一管理和控制C.(1)数据可以共享(或数据结构化) (2)数据互换性(3)数据冗余小,易扩充 (4)统一管理和控制D.(1)数据非结构化 (2)数据独立性(3)数据冗余小,易扩充 (4)统一管理和控制6.数据库具有①、最小的②和较高的③。
BAC① A.程序结构化 B.数据结构化C.程序标准化 D.数据模块化② A.冗余度 B.存储量C.完整性 D.有效性③ A.程序与数据可靠性 B.程序与数据完整性C.程序与数据独立性 D.程序与数据一致性7.在数据库中,下列说法是不正确的。

求最小函数依赖集分三步:1.将F中的所有依赖右边化为单一元素此题fd={abd->e,ab->g,b->f,c->j,cj->i,g->h};已经满足2.去掉F中的所有依赖左边的冗余属性.作法是属性中去掉其中的一个,看看是否依然可以推导此题:abd->e,去掉a,则(bd)+不含e,故不能去掉,同理b,d都不是冗余属性ab->g,也没有cj->i,因为c+={c,j,i}其中包含i所以j是冗余的.cj->i将成为c->iF={abd->e,ab->g,b->f,c->j,c->i,g->h};3.去掉F中所有冗余依赖关系.做法为从F中去掉某关系,如去掉(X->Y),然后在F中求X+,如果Y在X+中,则表明x->是多余的.需要去掉.此题如果F去掉abd->e,F将等于{ab->g,b->f,c->j,c->i,g->h},而(abd)+={a,d,b,f,g,h},其中不包含e.所有不是多余的.同理(ab)+={a,b,f}也不包含g,故不是多余的.b+={b}不多余,c+={c,i}不多余c->i,g->h多不能去掉.所以所求最小函数依赖集为F={abd->e,ab->g,b->f,c->j,c->i,g->h};转换为3NF既具有无损连接性又保持函数依赖的分解算法:第一步:首先用算法1求出R的保持函数依赖的3NF分解,设为q={R1,R2,…,Rk}(这步完成后分解已经是保持函数依赖,但不一定具有保持无损连接)第二步:设X是R的码,求出p=q {R(X)}第三步:若X是q中某个Ri的子集,则在p中去掉R(X)第四步:得到的p就是最终结果例题:R(S#,SN,P,C,S,Z)F={S#→SN,S#→P,S#→C,S#→S,S#→Z,{P,C,S}→Z,Z→P,Z→C}•第一步:求出最小FD集:F={S# →SN, S# →P,S# →C, S#→S, {P,C,S→Z, Z →P,Z →C} // S# →Z冗余,FD:最小函数依赖按具有相同左部分组:q={R1(S#,SN,P,C,S), R2(P,C,S,Z), R3(Z,P,C)}R3是R2的子集,所以去掉R3q={R1(S#,SN,P,C,S), R2(P,C,S,Z)}•第二步:R的主码为S#,于是p=q {R(X)}={R1(S#,SN,P,C,S), R2(P,C,S,Z), R(S#)}•第三步:因为{S#}是R1的子集,所以从p中去掉R(S#)•第四步:p ={R1(S#,SN,P,C,S), R2(P,C,S,Z)}即最终结果判别一个分解的无损连接性举例2:已知R<U,F>,U={A,B,C,D,E},F={A→C,B→C,C→D,DE→C,CE→A},R的一个分解为R1(AD),R2(AB),R3(BE),R4(CDE),R5(AE),判断这个分解是否具有无损连接性。

模式分解的无损连接性之深入剖析1. 无损连接分解的形式定义无损连接分解的形式定义如下:设R是一个关系模式,F是R上的一个函数依赖(FD)集。
R分解成数据库模式δ={R1,……,Rk}。
如果对R中每一个满足F的关系r都有下式成立:那么称分解δ相对于F是“无损连接分解”,否则称为“损失连接分解”。
其中表示自然连接。
从上述形式定义中可知,若直接根据定义来判断某个分解是否具有无损连接性,那么就得“对R中每一个满足F的关系r”进行测试,看是否满足上面的等式,这显然不可操作,因为“对R中每一个满足F的关系r”进行测试就意味着“对R中所有满足F的关系r”进行测试,显然是不可能的。
这里所说的“关系”就是指一张具体的表。
因此,必须寻求其它的可操作性方法来判别分解的无损连接性。
2. 无损连接分解的普通判别方法——表格法设关系模式R=A1,…,An,R上成立的FD集F,R的一个分解p={R1,…,Rk}。
无损连接分解的判断步骤如下:(1)构造一张k行n列的表格,每列对应一个属性Aj(1≤j≤n),每行对应一个模式Ri(1≤i≤k)。
如果Aj在Ri中,那么在表格的第i行第j列处填上符号aj,否则填上符号bij。
(2)把表格看成模式R的一个关系,反复检查F中每个FD在表格中是否成立,若不成立,则修改表格中的元素。
修改方法如下:对于F中一个FD:X→Y,如果表格中有两行在X分量上相等,在Y分量上不相等,那么把这两行在Y分量上改成相等。
如果Y的分量中有一个是aj,那么另一个也改成aj;如果没有aj,那么用其中的一个bij替换另一个(尽量把ij改成较小的数,亦即取i值较小的那个)。
若在修改的过程中,发现表格中有一行全是a,即a1,a2,…,an,那么可立即断定p相对于F是无损连接分解,此时不必再继续修改。
若经过多次修改直到表格不能修改之后,发现表格中不存在有一行全是a的情况,那么分解就是有损的。
特别要注意,这里有个循环反复修改的过程,因为一次修改可能导致表格能继续修改。

数据库课程设计心得体会数据库课程设计心得体会(精选8篇)当在某些事情上我们有很深的体会时,不如来好好地做个总结,写一篇心得体会,这样有利于培养我们思考的习惯。
那么心得体会怎么写才能感染读者呢?下面是小编为大家整理的数据库课程设计心得体会,仅供参考,大家一起来看看吧。
数据库课程设计心得体会篇1一周的课程设计结束了,在这次的课程设计中不仅检验了我所学习的知识,也培养了我如何去把握一件事情,如何去做一件事情,又如何完成一件事情的方法和技巧。
在设计过程中,和同学们相互探讨,相互学习,相互监督。
我学会了运筹帷幄,学会了宽容,学会了理解,也学会了做人与处世,这次课程设计对我来说受益良多。
课程设计是我们专业课程知识综合应用的实践训练,着是我们迈向社会,从事职业工作前一个必不少的过程。
“千里之行始于足下”,通过这次课程设计,我深深体会到这句千古名言的真正含义。
我今天认真的进行课程设计,学会脚踏实地迈开这一步,就是为明天能稳健地在社会大潮中奔跑打下坚实的基础。
我这次设计的科目是数据结。
数据结构,是一门研究非数值计算的程序设计问题中计算机的操作对象(数据元素)以及它们之间的关系和运算等的学科,而且确保经过这些运算后所得到的新结构仍然是原来的结构类型。
“数据结构”在计算机科学中是一门综合性的专业基础课。
数据结构是介于数学、计算机硬件和计算机软件三者之间的一门核心课程。
数据结构这一门课的内容不仅是一般程序设计(特别是非数值性程序设计)的基础,而且是设计和实现编译程序、操作系统、数据库系统及其他系统程序的重要基础。
通过这次模具设计,我在多方面都有所提高。
在界面设置中使用函数调用while。
其中文本显示颜色和背景颜色都可以任意按照自己的喜好,任意改变,但改变的时候必须采用标准英文大写,同时在制作显示菜单的窗口,大小根据菜单条数设计。
最后采用printf输出程序设计界面。
这次的程序软件基本上运行成功,可以简单的建立链式循环链表,并进行输出,及循环语句的运用和选择语句的控制。

1.模式分解的准则:模式分解具有无损连接特性,模式分解能够保持函数依赖特性。
无损连接是指分解后的关系通过自然连接可以恢复成原来的关系;保持函数依赖分解是指在模式的分解过程中,函数依赖不能丢失的特性,即模式分解不能破坏原来的语义。
2.如果R(U,F) ∈1NF,并且R中的每个非主属性都完全函数依赖于关键字,则R(U,F) ∈2NF 。
3.如果R(U,F) ∈2NF,并且所有非主属性都不传递依赖于关键字,则R(U,F) ∈3NF 。
4.关系模式R(U,F) ∈1NF,X→Y是F上的任意函数依赖,并且Y不属于X,U 完全函数依赖于X,则R(U,F) ∈ BCNF 。
5.如果要求分解保持函数依赖,那么模式分解总可以达到3NF ,但是不一定能达到BCNF ;6.如果要求分解具有无损连接的特性,那么一定可以达到BCNF ;7.如果要求分解既保持函数依赖、又具有无损连接的特性,那么分解可以达到3NF ,但是不一定能达到 BCNF 。
8.数据库设计有广义和狭义两个定义。
广义的定义是指基于数据库的应用系统或管理信息系统的设计,它包括应用设计和数据库结构设计两部分内容。
狭义的定义则专指数据库模式或结构的设计。
9.数据库设计的基本任务就是根据用户的信息需求,处理需求和数据库的支撑环境(包括DBMS、操作系统、硬件),设计一个结构合理、使用方便、效率较高的数据库。
信息需求是指在数据库中应该存储和管理哪些数据对象;处理需求是指需要进行哪些业务处理和操作,如对数据对象的查询、增加、删除、修改、统计等操作。
10.数据库设计步骤:需求分析阶段、概念结构设计阶段、逻辑结构设计阶段、物理结构设计阶段、数据库实施阶段、数据库运行和维护阶段。
11.概念模型设计的结果是得到数据库的概念结构,或称概念模型。
(1)先设计面向全局应用的全局概念结构的初步框架,即先建立起整个系统的总体框架;(2)然后根据部门或功能划分成局部应用;(3)依据划分后的局部应用完成局部E-R图的设计;(4)最后将局部E-R图合并、转换成全局E-R图,完成概念模型的设计。
《数据库系统原理与技术》试题库选择题1.对关系模型叙述错误的是(D)。
A、建立在严格的数学理论、集合和谓词演算公D式上的基础之上B、微机DBMS绝大部分采取关系数据模型C、用二维表表示关系模型是其一大特点D、不具有连接操作的DBMS也可以是关系数据库系统1.一个关系数据库文件中的各条记录(B)。
A.前后顺序不能任意颠倒,一定要按照输入的顺序排列B.前后顺序可以任意颠倒,不影响库中的数据关系C.前后顺序可以任意颠倒,但排列顺序不同,统计处理的结果就可能不同D前后顺序不能任意颠倒,一定要按照关键字段值的顺序排列3.在下列对关系的描述中,错误的是( B )A.关系中的列称为属性B.关系中允许有相同的属性名C.关系中的行称为元组D.属性的取值范围称为域4.关系模型中,实现实体之间联系是通过(C)A.关系B.指针C.表D.公共字段5.将ER模型转换成关系模型的过程属于数据库的(C)A.需求分析 B. 概念设计C.逻辑设计 D. 物理设计6.在E-R模型转换成关系模型的过程中,下列叙述不正确的是(C)。
A.每个实体类型转换成一个关系模式B.每个M∶N联系类型转换一个关系模式C.每个联系类型转换成一个关系模式D.在处理1∶1和1∶N联系类型时,不生成新的关系模式。
7.在关系理论中称为“元组”的概念,在关系数据库中称为(A)A.记录B.表C.属性D.字段8.下列叙述正确的是(C)A.关系中元组没有先后顺序,属性有先后顺序B.关系中元组有先后顺序,属性没有先后顺序C.关系中元组没有先后顺序,属性也没有先后顺序D.关系中元组有先后顺序,属性也有先后顺序9.在基本的关系中,下列说法正确的是(C)A.行列顺序有关B.属性名允许重名C.任意两个元组不允许重复D.列是非同质的2.关系中任何一列的属性取值(C)A.可以再分成更小的数据项,并可取自不同域中的数据B.可以再分成更小的数据项,不能取自不同域中的数据C.是不可再分的数据项,只能取自同一域中的数据D.是不可再分的数据项,可取自不同域中的数据3.在通常情况下,下面的关系中不可以作为关系的是(D)。
第7章关系规范化理论一、单项选择题1.关系规范化中的删除操作异常是指①,插入操作异常是指②。
A.不该删除的数据被删除 B.不该插入的数据被插入C.应该删除的数据未被删除 D.应该插入的数据未被插入答案:①A ②D2.设计性能较优的关系模式称为规范化,规范化主要的理论依据是。
A.关系规范化理论 B.关系运算理论C.关系代数理论 D.数理逻辑答案:A3.规范化理论是关系数据库进行逻辑设计的理论依据。
根据这个理论,关系数据库中的关系必须满足:其每一属性都是。
A.互不相关的 B.不可分解的C.长度可变的 D.互相关联的答案:B4.关系数据库规范化是为解决关系数据库中问题而引入的。
A.插入、删除和数据冗余 B.提高查询速度C.减少数据操作的复杂性 D.保证数据的安全性和完整性答案:A5.规范化过程主要为克服数据库逻辑结构中的插入异常,删除异常以及的缺陷。
A.数据的不一致性 B.结构不合理C.冗余度大 D.数据丢失答案:C6.当关系模式R(A,B)已属于3NF,下列说法中是正确的。
A.它一定消除了插入和删除异常 B.仍存在一定的插入和删除异常C.一定属于BCNF D.A和C都是答案:B7. 关系模式1NF是指_________。
A. 不存在传递依赖现象B. 不存在部分依赖现象C.不存在非主属性 D. 不存在组合属性答案:D8. 关系模式中2NF是指_______。
A.满足1NF且不存在非主属性对关键字的传递依赖现象B.满足1NF且不存在非主属性对关键字部分依赖现象C.满足1NF且不存在非主属性D.满足1NF且不存在组合属性答案:B9. 关系模式中3NF是指___________。
A.满足2NF且不存在非主属性对关键字的传递依赖现象B.满足2NF且不存在非主属性对关键字部分依赖现象C.满足2NF且不存在非主属性D.满足2NF且不存在组合属性答案:A10.关系模型中的关系模式至少是。
A.1NF B.2NF C.3NF D.BCNF答案:A11.关系模式中,满足2NF的模式,。
课程设计说明书设计题目:数据库课程设计专业:计算机科学与技术班级: 2010级5班设计人:王露山东科技大学2012年04月07 日摘要:本次课程设计,研究了如何判断输入的模式分解是否保持无损连接性,提示用户输入关系模式的属性集,函数依赖集以及模式分解,利用算法 6.的表格法,运行程序,输出是否具有无损连接性。
用java语言实现,在eclipse上运行,且只考虑了分解的无损连接性而没有考虑函数依赖的保持性。
目录:任务书-------------------------------------------------------------------------------------2教师评语---------------------------------------------------------------------------------3摘要---------------------------------------------------------------------------------------4题目要求--------------------------------------------------------------------------------4需求分析--------------------------------------------------------------------------------4程序设计--------------------------------------------------------------------------------6结果分析--------------------------------------------------------------------------------15实验总结--------------------------------------------------------------------------------20附录(使用说明)-------------------------------------------------------------------21正文:1. 题目:选择一种高级语言实现判别一个分解的无损连接性输入:某一个关系模式的属性集、函数依赖集和该关系模式的一个分解 输出:分解是否保持无损连接性要求:(1)按算法6.2和6.4实现(P190)(2)能给出根据模式的分解形成初始表格(3)给出根据每一个函数依赖表格的变化情况(4)提供课程设计报告2.需求分析1.关系模式R(U,F),r={R 1(U 1,F 1),R 2(U 2,F 2),…, R k (U k ,F k )}是R(U,F)的一组子集,若U 1ÈU 2È…ÈU k =U ,则称 r 是R(U,F)的一个分解(Decomposition)。
第7章关系规范化理论一、单项选择题1.关系规范化中的删除操作异常是指①,插入操作异常是指②。
A.不该删除的数据被删除 B.不该插入的数据被插入C.应该删除的数据未被删除 D.应该插入的数据未被插入答案:①A ②D2.设计性能较优的关系模式称为规范化,规范化主要的理论依据是。
A.关系规范化理论 B.关系运算理论C.关系代数理论 D.数理逻辑答案:A3.规范化理论是关系数据库进行逻辑设计的理论依据。
根据这个理论,关系数据库中的关系必须满足:其每一属性都是。
A.互不相关的 B.不可分解的C.长度可变的 D.互相关联的答案:B4.关系数据库规范化是为解决关系数据库中问题而引入的。
A.插入、删除和数据冗余 B.提高查询速度C.减少数据操作的复杂性 D.保证数据的安全性和完整性答案:A5.规范化过程主要为克服数据库逻辑结构中的插入异常,删除异常以及的缺陷。
A.数据的不一致性 B.结构不合理C.冗余度大 D.数据丢失答案:C6.当关系模式R(A,B)已属于3NF,下列说法中是正确的。
A.它一定消除了插入和删除异常 B.仍存在一定的插入和删除异常C.一定属于BCNF D.A和C都是答案:B7. 关系模式1NF是指_________。
A. 不存在传递依赖现象B. 不存在部分依赖现象C.不存在非主属性 D. 不存在组合属性答案:D8. 关系模式中2NF是指_______。
A.满足1NF且不存在非主属性对关键字的传递依赖现象B.满足1NF且不存在非主属性对关键字部分依赖现象C.满足1NF且不存在非主属性D.满足1NF且不存在组合属性答案:B9. 关系模式中3NF是指___________。
A.满足2NF且不存在非主属性对关键字的传递依赖现象B.满足2NF且不存在非主属性对关键字部分依赖现象C.满足2NF且不存在非主属性D.满足2NF且不存在组合属性答案:A10.关系模型中的关系模式至少是。
A.1NF B.2NF C.3NF D.BCNF答案:A11.关系模式中,满足2NF的模式,。
课程设计说明书设计题目:数据库课程设计专业:计算机科学与技术班级:2010级5班设计人:王露山东科技大学2012年04月07 日摘要:本次课程设计,研究了如何判断输入的模式分解是否保持无损连接性,提示用户输入关系模式的属性集,函数依赖集以及模式分解,利用算法6.的表格法,运行程序,输出是否具有无损连接性。
用java语言实现,在eclipse上运行,且只考虑了分解的无损连接性而没有考虑函数依赖的保持性。
目录:任务书-------------------------------------------------------------------------------------2教师评语---------------------------------------------------------------------------------3摘要---------------------------------------------------------------------------------------4题目要求--------------------------------------------------------------------------------4需求分析--------------------------------------------------------------------------------4程序设计--------------------------------------------------------------------------------6结果分析--------------------------------------------------------------------------------15实验总结--------------------------------------------------------------------------------20附录(使用说明)-------------------------------------------------------------------21正文:1. 题目:选择一种高级语言实现判别一个分解的无损连接性输入:某一个关系模式的属性集、函数依赖集和该关系模式的一个分解 输出:分解是否保持无损连接性 要求:(1)按算法6.2和6.4实现(P190)(2)能给出根据模式的分解形成初始表格(3)给出根据每一个函数依赖表格的变化情况 (4)提供课程设计报告2.需求分析1.关系模式R(U,F),ρ={R 1(U 1,F 1),R 2(U 2,F 2),…, R k (U k ,F k )}是R(U,F)的一组子集,若U 1⋃U 2⋃…⋃U k =U ,则称 ρ 是R(U,F)的一个分解(Decomposition)。
分解有两个准则,无损连接性和函数依赖的保持性。
无损连接性的定义为 设关系模式R(U,F), ρ={R 1,R 2,…,R k }是分解R 所得的一组关系模式,对于R 的满足F 的任一个关系实例r ,都有:成立。
即r 等于它在R i 上投影的自然连接,则称此分解为满足F 的具有无损连接性的分解。
2.分解的无损连接性判断定理6.4:设关系模式R(U,F), ρ={R 1,R 2}是R 的一个分解,当且仅当U 1⋂U 2→U 1-U 2或 U 1⋂U 2→U 2-U 1∈F +时,则分解ρ具有无损连接性。
3.算法6.2 {判断分解ρ的无损连接性} 输入:R(U,F),U=A 1A 2…A n ; ρ={R 1,R 2,…,R k }输出:如果ρ具有无损连接性,输出True ,否则输出False 。
(1) 构造一个n 列k 行的二维表T 。
若A j ∈R i ,则T ij =a j ;否则T ij =b ij 。
(2) flag:=True; Do While Flag Flag:=False;For 每一个X →Y ∈F DoFor T 中的任意两行t j ,t m Do)()()(21r r r r k R R R ∏∞∞∏∞∏=If t j[X]=t m[X] And t j[Y]≠t m[Y] ThenEQUAY(t j,t m);Flag:=True;(3) For T的每一行t DoIf t=a1a2…a n Then Return(True);Return(False).故根据定理6.2和6.4的算法和定理,可以得出判断关系模式的分解是否保持无损连接性的充分必要条件是U1⋂U2→U1-U2或U1⋂U2→U2-U1∈F+时,则分解ρ具有无损连接性。
所以问题转变成为集合的并差问题,然后根据6.2算法再加以完善,就可以编写程序来实现这一功能了。
当然,关系模式分解的另一个准则是函数依赖的保持性,这两个准则虽然没有什么直接的关系,却决定了一个关系模式可以达到哪一个范式,不能单一的进行讨论,都需要进行分析,现在,为简便起见,我们只讨论一个关系模式的分解是否保持着无损连接性,暂时不讨论其函数依赖的保持性3.程序设计3.1粗略设计根据算法6.2,利用表格法进行判断,以下是表格法的详细步骤。
算法:ρ={R1<U1,F1>,R2<U2,F2>,...,R k<U k,F k>}是关系模式R<U,F>的一个分解,U={A1,A2,...,A n},F={FD1,FD2,...,FD p},并设F是一个最小依赖集,记FD i为X i →A lj,其步骤如下:①建立一张n列k行的表,每一列对应一个属性,每一行对应分解中的一个关系模式。
若属性A j U i,则在j列i行上真上a j,否则填上b ij;②对于每一个FD i做如下操作:找到X i所对应的列中具有相同符号的那些行。
考察这些行中l i列的元素,若其中有a j,则全部改为a j,否则全部改为b mli,m 是这些行的行号最小值。
如果在某次更改后,有一行成为:a1,a2,...,a n,则算法终止。
且分解ρ具有无损连接性,否则不具有无损连接性。
对F中p个FD逐一进行一次这样的处理,称为对F的一次扫描。
③比较扫描前后,表有无变化,如有变化,则返回第步,否则算法终止。
如果发生循环,那么前次扫描至少应使该表减少一个符号,表中符号有限,因此,循环必然终止。
举例1:已知R<U,F>,U={A,B,C},F={A→B},如下的两个分解:①ρ1={AB,BC}②ρ2={AB,AC}判断这两个分解是否具有无损连接性。
用无损连接的定理来解。
方法一:因为AB∩BC=B,AB-BC=A,BC-AB=C所以B→A F+,B→C F+故ρ1是有损连接。
方法二:因为AB∩AC=A,AB-AC=B,AC-AB=C所以A→B F+,A→C F+故ρ2是无损连接。
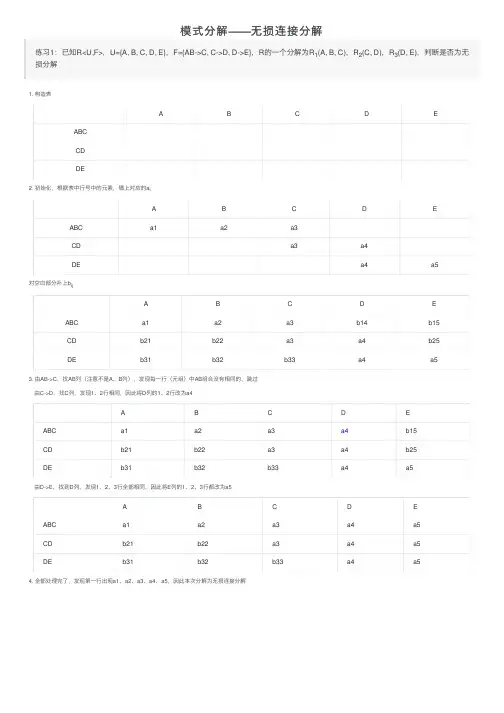
下面举个例子来说明表格法【例】已知R<U,F>,U={A,B,C,D,E},F={A→C,B→C,C→D,DE→C,CE→A},R的一个分解为R1(AD),R2(AB),R3(BE),R4(CDE),R5(AE),判断这个分解是否具有无损连接性。
解:用判断无损连接的算法来解。
①构造一个初始的二维表,若“属性”属于“模式”中的属性,则填a j,否则填b ij。
见表1.表1.②根据A→C,对上表进行处理,由于属性列A上第1、2、5行相同均为a1,所以将属性列C上号b13(取行号最小值)。
③根据B→C,对上表进行处理,由于属性列B上第2、3行相同均为a2,所以将属性列C上的b行号最小值)。
表4.④根据C→D,对上表进行处理,由于属性列C上第1、2、3、5行相同均为b13,所以将属性列上的值均改为同一个符号a4。
表5.⑤根据DE→C,对上表进行处理,由于属性列DE上第3、4、5行相同均为a4a5,所以将属性列。
表73⑤根据CE→A,对上表进行处理,由于属性列CE上第3、4、5行相同均为a3a5,所以将属性列。
1⑦通过上述的修改,使第三行成为a1a2a3a4a5,则算法终止。
且分解具有无损连接性。
3.2详细设计(2000)要使本程序正确运行下去,需要解决的问题很多,下面,举个例子,来演示本程序的运行。
【例】已知R<U,F>,U={A,B,C,D,E},F={A→C,B→C,C→D,DE→C,CE→A},R的一个分解为R1(AD),R2(AB),R3(BE),R4(CDE),R5(AE),判断这个分解是否具有无损连接性。
(1)首先,需要解决的问题是关系模式属性集,关系模式函数依赖集,模式分解的输入,此时需要有个用户说明书,告诉用户该怎么输入,输入什么,输入的东西是什么格式的,例如,必须输入U={ A,B,C,D,E},定义一个字符型数组stringAttribute[],InputStreamReader isra=newInputStreamReader(System.in);char[]stringAttribute=new char[20];isra.read(stringAttribute);依次存入ABCDE五个属性。
为了方便输出,定义一个字符型变量comma=’,’还有定义一个字符型数组brace[]为左右大括号。
其次定义字符数组dependence[]来储存输入的函数依赖,modecomposition[]来储存输入的模式分解。
最后在用一个isra.read(stringAttribute)输出就好了。
(2)为了确保输入的信息是否正确,依次输出System.out.println(“您输入的模式的属性集为:”+new String(stringAttribute));System.out.println(“您输入的模式的属性集为:”+new String(dependence));System.out.println(“您输入的模式的属性集为:”+newString(modecomposition));提示用户检查是否输入正确System.out.print("输入是否正确?y/n");Scanner scanner = new Scanner(System.in);char character = (char) scanner.nextByte();if (scanner.equals('y')) {System.out.print("go on");continue label;}else {System.out.print("error");Break;}若是输入正确,则执行表格生成Table.java 见结果分析中的截图4.Package TableChangepublic class Table {public static void main( String args[])throws DBFException, IOException {DBFField field = new DBFField();field.setName("Table"); // give a name to the fieldfield.setDataType( DBFField.FIELD_TYPE_C); // and set its typefield.setFieldLength( 5); // and length of the field DBFField fields[]=new DBFField[5];fields[0] = new DBFField();fields[0].setName("A");fields[0].setDataType( DBFField.FIELD_TYPE_C);fields[0].setFieldLength( 5);再依次fields[1] = new DBFField();fields[1].setName("B");fields[1].setDataType( DBFField.FIELD_TYPE_C);fields[1].setFieldLength( 5);fields[2] = new DBFField();fields[2].setName("C");fields[2].setDataType( DBFField.FIELD_TYPE_C);fields[2].setFieldLength( 5);fields[3] = new DBFField();fields[3].setName("D");fields[3].setDataType( DBFField.FIELD_TYPE_C);fields[3].setFieldLength( 5);fields[4] = new DBFField();fields[4].setName("E");fields[4].setDataType( DBFField.FIELD_TYPE_C);fields[4].setFieldLength( 5);public class Function{public static void main(string[] args){//这个函数的目的是用来判断用输出表格中的数据Char [][] data=new char[3][5]; //二维数组记录表格中的数据System.out.print("属性 " );for(int temp=0;temp<5;temp++)System.out.print(" "+stringAttribute[temp]);System.out.print("\n");System.out.println("--------------------------------------");这样输出的结果就是属性 A B C D E--------------------------------------表格的最左边是函数依赖dependence[]若“属性”属于“模式”中的属性,则填a j,否则填b ijSystem.out.print(dependence[0]);for(int j=0;j<5;j++){if(stringAttribute[0]==dependence[j])//判断属性是否属于模式中的属性,若是,则填a jdata[0][j]='a[j]';elsedata[0][j]='b[i][j]';//若不属于,则填b ij}for(int i=0;i<5;i++){System.out.print(" ");if(data[0][i]=='a'){System.out.print(data[0][i]);System.out.print(i);}else{System.out.print(data[0][i]);System.out.print("0"+i);}}System.out.print("\n");这样执行输出结果为第二行AB→C a1 a2 a3 b14 b15依次判断关系依赖集中的各个属性System.out.print(dependence[1]);for(int j=0;j<5;j++){if(stringAttribute[1]==dependence[j])data[1][j]='a[j]';elsedata[1][j]='b[i][j]';}for(int i=0;i<5;i++){System.out.print(" ");if(data[1][i]=='a'){System.out.print(data[1][i]);System.out.print(i);}else{System.out.print(data[1][i]);System.out.print("1"+i);}}System.out.print("\n");同理,输出第三行C→D b12 b22 a3 a4 b25System.out.print(dependence[2]);for(int j=0;j<5;j++){if(stringAttribute[2]==dependence[j])data[2][j]='a[j]';elsedata[2][j]='b[i][j]';}for(int i=0;i<5;i++){System.out.print(" ");if(data[2][i]=='a'){System.out.print(data[2][i]);System.out.print(i);}else{System.out.print(data[2][i]);System.out.print("2"+i);}}System.out.print("\n");D→E b31 b32 b33 a4 a5在Function函数中直接输出,见图1.图1.(3)改表对于每一个FD i做如下操作:找到X i所对应的列中具有相同符号的那些行。