基于时间序列分析的ARIMA模型分析及预测
- 格式:pdf
- 大小:248.37 KB
- 文档页数:3
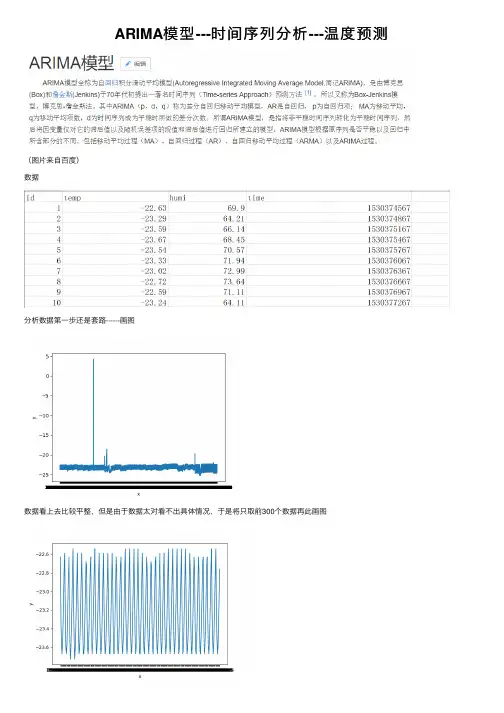
ARIMA模型---时间序列分析---温度预测(图⽚来⾃百度)数据分析数据第⼀步还是套路------画图数据看上去⽐较平整,但是由于数据太对看不出具体情况,于是将只取前300个数据再此画图这数据看上去很不错,感觉有隐藏周期的意思代码#coding:utf-8import csvimport matplotlib.pyplot as pltdef read_csv_data(aim_list_1, aim_list_2, file_name):i = 0csv_file = csv.reader(open(file_name,'r'))for data in csv_file:if (i == 0):i += 1continueaim_list_1.append(float(data[1]))aim_list_2.append(data[3])returndef plot_picture(x, y):plt.xlabel('x')plt.ylabel('y')plt.plot(x, y)plt.show()returnif__name__ == '__main__':temp = []tim = []file_name = 'C:/Users/lichaoxing/Desktop/testdata.csv'read_csv_data(temp, tim, file_name)plot_picture(tim[:300], temp[:300])使⽤ARIMA模型(ARMA)第⼀步观察数据是否是平稳序列,通过上图可以看出是平稳的如果不平稳,则需要进⾏预处理,⽅法有对数变换差分对于平稳的时间序列可以直接使⽤ARMA(p, q)模型进⾏拟合ARMA (p, q) : AR(p) + MA(q)此时参数p和q的确定可以通过观察ACF和PACF图来确定通过观察PACF图可以看出,阶数为9也就是p=9,这⾥ACF图看出⾃相关呈现震荡下降收敛,但是怎么决定出q,我没太明⽩,这⾥姑且拍脑袋才⼀个吧就q=3但是这⾥我遇到了⼀个问题,没有搞懂,就是平稳的序列,如果我进⾏⼀阶差分后应该仍然是平稳的序列,但是这个时候我⼜画了⼀个ACF 与PACF图,竟然是下图这样,lag的范围是-0.04到0.04(不懂)lag的范围是-0.04到0.04的问题原因(修改于再次使⽤此模型)原因:当时,我使⽤的是⼀阶差分,也就是让数据的后⼀个值减去前⼀个值得到新的值,这样就会导致第⼀个值变为缺失值(下⾯的数据是再此使⽤此模型时的数据,与原博客数据⽆关)就是因为此处的值为缺失值,导致绘制ACF与PACF时数据有问题⽽⽆法成功显⽰解决办法,在绘制上述图形前,将第⼀个数据去除:dta= dta.diff(1)dta = dta.truncate(before= ym[1])#删除第⼀个缺失值其实还有就是使⽤ADF检验,得到的结果如图,这个p值很⼩===》平稳画图代码def acf_pacf(temp, tim):x = timy = tempdta = pd.Series(y, index = pd.to_datetime(x))fig = plt.figure(figsize=(9,6))ax1 = fig.add_subplot(211)fig = sm.graphics.tsa.plot_acf(dta,lags=50,ax=ax1)ax2 = fig.add_subplot(212)fig = sm.graphics.tsa.plot_pacf(dta,lags=50,ax=ax2)show()ADF检验代码def test_stationarity(timeseries):dftest = adfuller(timeseries, autolag='AIC')return dftest[1]这⾥先使⽤ARMA(9,3)来实验测试⼀下效果,取前300个数据中的前250个作为train,后⾯的作为test 效果可以说这个模型是真的强⼤,预测的还是⼗分准确的代码def test_300(temp, tim):x = tim[0:300]y = temp[0:300]dta = pd.Series(y[0:249], index = pd.to_datetime(x[0:249]))fig = plt.figure(figsize=(9,6))ax1 = fig.add_subplot(211)fig = sm.graphics.tsa.plot_acf(dta,lags=30,ax=ax1)ax2 = fig.add_subplot(212)fig = sm.graphics.tsa.plot_pacf(dta,lags=30,ax=ax2)arma_mod = sm.tsa.ARMA(dta, (9, 3)).fit(disp = 0)predict_sunspots = arma_mod.predict(x[200], x[299], dynamic=True)fig, ax = plt.subplots(figsize=(9, 6))ax = dta.ix[x[0]:].plot(ax=ax)predict_sunspots.plot(ax=ax)show()其实,可以通过代码来⾃动的选择p和q的值,依据BIC准则,⽬标就是bic越⼩越好代码def proper_model(timeseries, maxLag):init_bic = 100000000init_properModel = Nonefor p in np.arange(maxLag):for q in np.arange(maxLag):model = ARMA(timeseries, order=(p, q))try:results_ARMA = model.fit(disp = 0, method='css')except:continuebic = results_ARMA.bicif bic < init_bic:init_properModel = results_ARMAinit_bic = bicreturn init_properModel遇到的问题,预测时predict函数没怎么使⽤明⽩当写于某些预测区间的时候,会报 “start”或“end”的相关错误,还有⼀个函数forcast,这个函数使⽤就是forcast(N):预测后⾯N个值返回的是预测值(array型)标准误差(array型)置信区间(array型)还有:对于构造时间序列,时间可以是时间格式:如 “2018-01-01” 或者就是个时间戳,在⽤时间戳的时候,其实在序列⾥它会⾃动识别时间戳,并加上起始时间1970-01-01 00:00:01形式附录(代码)预测⼀序列中某⼀点的值#coding:utf-8import csvimport timeimport pandas as pdimport numpy as npfrom statsmodels.tsa.arima_model import ARMAimport argparseimport warningswarnings.filterwarnings('ignore')def timestamp_datatime(value):value = time.localtime(value)dt = time.strftime('%Y-%m-%d %H:%M',value)return dtdef time_timestamp(my_date):my_date_array = time.strptime(my_date,'%Y-%m-%d %H:%M')my_date_stamp = time.mktime(my_date_array)return my_date_stampdef read_csv_data(aim_list_1, aim_list_2, file_name):i = 0csv_file = csv.reader(open(file_name,'r'))for data in csv_file:if (i == 0):i += 1continueaim_list_1.append(float(data[1])) #1:温度 2:湿度dt = int(data[3])aim_list_2.append(dt)returndef proper_model(timeseries, maxLag):init_bic = 100000000init_properModel = Nonefor p in np.arange(maxLag):for q in np.arange(maxLag):model = ARMA(timeseries, order=(p, q)) #bugtry:results_ARMA = model.fit(disp = 0, method='css')except:continuebic = results_ARMA.bicif bic < init_bic:init_properModel = results_ARMAinit_bic = bicreturn init_properModeldef test_300(temp, tim, time_in):x = []y = []end_index = len(tim)for i in range(0, len(tim)):if (time_in - (tim[i]) < 300):end_index = ibreakif (end_index < 100):x = tim[0: end_index]y = temp[0: end_index]else:x = tim[end_index - 100: end_index]y = temp[end_index - 100: end_index]tidx = pd.DatetimeIndex(x, freq='infer')dta = pd.Series(y, index = tidx)print(dta)arma_mod = proper_model(dta, 9)predict_sunspots = arma_mod.forecast(1)return predict_sunspots[0]def predict_temperature(file_name, time_in):temp = []tim = []read_csv_data(temp, tim, file_name)result_temp = test_300(temp, tim, time_in)return result_tempif__name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('-f', action='store', dest='file_name')parser.add_argument('-t', action='store', type = int, dest='time_')args = parser.parse_args()file_name = args.file_nametime_in = args.time_result_temp = predict_temperature(file_name, time_in)print ('the temperature is %f ' % result_temp)在上⾯的代码中,预测某⼀点的值我采⽤序列中此点的前100个点作为训练集如果给出待预测的多个点,由于每次都要计算模型的p和q以及拟合模型,时间会很慢,于是考虑将给定的待预测时间点序列切割成⼩段,使每⼀段中最⼤与最⼩的时间间隔在某⼀范围内在使⽤forcast(n)函数⼀次预测多点,然后在预测值中找到与待预测的时间值相近的值,速度⼤⼤提升,思路如图代码#coding:utf-8import csv#import timeimport pandas as pdimport numpy as npfrom statsmodels.tsa.arima_model import ARMAimport warningswarnings.filterwarnings('ignore')def proper_model(timeseries, maxLag):init_bic = 1000000000init_p = 1init_q = 1for p in np.arange(maxLag):for q in np.arange(maxLag):model = ARMA(timeseries, order=(p, q))try:results_ARMA = model.fit(disp = 0, method='css')except:continuebic = results_ARMA.bicif bic < init_bic:init_p = pinit_q = qinit_bic = bicreturn init_p, init_qdef read_csv_data(file_name, clss = 1):i = 0aim_list_1 = [] #temperature(1) or humidity(2)aim_list_2 = [] #timecsv_file = csv.reader(open(file_name,'r'))for data in csv_file:if (i == 0):i += 1continueaim_list_1.append(float(data[clss]))dt = int(data[3])aim_list_2.append(dt)tidx = pd.DatetimeIndex(aim_list_2, freq = None)dta = pd.Series(aim_list_1, index = tidx)init_p, init_q = proper_model(dta[:aim_list_2[100]], 9)return init_p, init_q, aim_list_2, dtadef for_kernel(p, q, tim, dta, tmp_time_list, result_dict):interval = 20end_index = len(tim) - 1for i in range(0, len(tim)):if (tmp_time_list[0]["time"] - tim[i] < tim[1] - tim[0]):end_index = ibreakif (end_index < 100):dta = dta.truncate(after = tim[end_index])else:dta = dta.truncate(before= tim[end_index - 101], after = tim[end_index])arma_mod = ARMA(dta, order=(p, q)).fit(disp = 0, method='css')#为未来interval天进⾏预测,返回预测结果,标准误差,和置信区间predict_sunspots = arma_mod.forecast(interval)####################################for tim_i in tmp_time_list:for tim_ in tim:if tim_i["time"] - tim_ >= 0 and tim_i["time"] - tim_ < tim[1] - tim[0]:result_dict[tim_i["time"]] = predict_sunspots[0][tim.index(tim_) - end_index] returndef kernel(p, q, tim, dta, time_in_list):interval = 20time_first = time_in_list[0]det_time = tim[1] - tim[0]result_dict = {}tmp_time_list = []for time_ in time_in_list:if time_first["time"] + det_time * interval > time_["time"]:tmp_time_list.append(time_)continuetime_first = time_for_kernel(p, q, tim, dta, tmp_time_list, result_dict)tmp_time_list = []tmp_time_list.append(time_first)for_kernel(p, q, tim, dta, tmp_time_list, result_dict)return result_dictdef predict_temperature(file_name, time_in_list, clss = 1):p, q, tim, dta = read_csv_data(file_name, clss)result_temp_dict = kernel(p, q, tim, dta, time_in_list)return result_temp_dictdef predict_humidity(file_name, time_in_list, clss = 2):p, q, tim, dta = read_csv_data(file_name, clss)result_humi_dict = kernel(p, q, tim, dta, time_in_list)return result_humi_dictif__name__ == '__main__':file_name = "testdata.csv"time_in = [{"time":1530419271,"temp":"","humi":""},{"time":1530600187,"temp":"","humi":""},{"time":1530825809,"temp":"","humi":""}] #time_in = [{"time":1530600187,"temp":"","humi":""},]result_temp = predict_temperature(file_name, time_in)print(result_temp)由于后续⼜改动了需求,需要预测温度以及湿度,完成了项⽬在github。

基于ARIMA模型的股价分析与预测——以招商银行为例基于ARIMA模型的股价分析与预测——以招商银行为例一、引言随着金融市场的发展和股票投资的普及,股票的价格波动成为投资者关注的焦点之一。
准确预测股票价格的变动对投资者而言具有重要意义。
在股票市场中,招商银行作为我国领先的银行之一,其股价走势备受关注。
通过对招商银行股票价格的分析与预测,可以帮助投资者做出更明智的投资决策。
二、ARIMA模型概述ARIMA模型是一种经典的时间序列预测模型,它结合了自回归(AR)模型、差分(I)模型和移动平均(MA)模型。
ARIMA模型的核心思想是对时间序列数据进行平稳化处理,然后利用自相关性和滑动平均相关性来进行预测。
三、数据收集与预处理为了分析与预测招商银行股价,首先需要获取相关的历史数据。
本文选择了招商银行从2010年至2020年的日交易数据作为分析对象。
通过对这些数据进行清洗和整理,得到一个连续的时间序列样本。
四、时间序列分析在进行ARIMA模型的应用之前,我们首先对招商银行股价的时间序列进行分析。
通过查看时间序列的图表、自相关函数(ACF)和偏自相关函数(PACF)可以初步了解招商银行股价的特点。
通过绘制招商银行股价的时间序列图,我们可以观察到其整体呈现出一定的趋势性,并具有一定的季节性。
这提示我们需要对数据进行平稳处理以满足ARIMA模型的要求。
接下来,我们绘制招商银行股价的自相关函数(ACF)和偏自相关函数(PACF)图,以便确定ARIMA模型的参数。
从ACF和PACF图可以看出,招商银行股价的自相关性和偏相关性均是相对较高的。
五、ARIMA模型拟合与评价在确定ARIMA模型的参数后,我们采用招商银行股价的时间序列数据进行模型的拟合。
通过计算拟合模型的残差序列的均值和方差,我们可以初步评估模型的拟合程度。
为了进一步评价模型的拟合效果,我们使用均方根误差(RMSE)和平均绝对误差(MAE)来衡量模型的预测精度。

基于ARIMA模型的股票价格预测分析1. ARIMA模型简介ARIMA模型是时间序列分析中一种非常常用的模型,其全称是Autoregressive Integrated Moving Average Model,即自回归、差分、移动平均模型。
ARIMA模型可以用于对时间序列的预测和分析,其基本假设是时间序列数据存在一定的趋势、季节性等特征,可以通过对这些特征进行建模来预测未来数据趋势。
ARIMA模型的核心是通过对时间序列数据的自相关系数和偏自相关系数进行分析,来建立适当的模型。
其中,自相关系数代表时间序列数据自身的相关性,而偏自相关系数则代表其对应的拖尾效应。
2. ARIMA模型在股票价格预测中的应用股票价格作为金融交易市场中的重要指标,其受到市场消息、宏观经济环境、公司业绩等多种因素的影响。
因此,利用ARIMA 模型对其进行建模,可以更好地预测未来股票价格的趋势和波动情况。
一般而言,股票价格的时间序列数据呈现出一定的趋势性和季节性。
利用经验法则对其进行建模的话,需要进行常数项调整,季节性调整等一系列复杂的操作。
而使用ARIMA模型,则可以更加方便地对这些因素进行建模。
在具体应用中,首先需要进行时间序列数据的预处理,包括去除非平稳因素、平稳检验、差分等。
然后,对处理后的数据进行自相关系数、偏自相关系数的分析,找出最适合的ARIMA模型。
最后,使用该模型进行预测,并进行误差检验。
3. 基于ARIMA模型的股票价格预测案例以某公司股票价格的预测为例,分析其未来60个交易日的股价波动情况。
首先,进行数据预处理。
使用包含该公司股票价格的时间序列数据,进行ADF检验和差分操作,得到平稳后的时间序列数据。
然后,使用ADF检验的结果,确定差分阶数,得到ARIMA(0,1,2)模型。
通过对该模型的自相关系数、偏自相关系数分析,得到ARIMA(0,1,2)模型。
最后,使用该模型进行未来60个交易日的股价预测,并进行误差检验。

基于ARIMA模型的时间序列预测分析时间序列预测分析是经济学和金融领域的重要应用之一,也是数据分析领域中非常基础的操作。
在实际的运用中,为了准确预测未来的数据趋势,我们必须有一种可靠的方法来对现有的时间序列数据进行建模和预测。
ARIMA模型,作为时间序列模型中的一个经典算法,可以解决这个问题。
ARIMA模型全称为自回归移动平均模型(Autoregressive Integrated Moving Average),是一种基于时间序列的统计分析方法,可以用于对非周期性、平稳时间序列样本的拟合与分析,以及预测其未来表现。
ARIMA模型的应用广泛,包括经济学、金融、气象、医学等领域,是时间序列预测中最常用的模型之一。
ARIMA模型的建立,需要对时间序列数据做许多处理和检验工作。
首先,我们需要检查所处理的时间序列数据是否符合ARIMA模型的假设:平稳性,即时间序列数据在不同时间段内的方差和均值都应该相等。
如果时间序列数据不符合平稳性假设,我们需要进行差分操作,将非平稳时间序列转化为平稳时间序列。
同时,根据检验结果,选择合适的阶数并确定ARIMA模型的系数。
阶数包括自回归阶数、差分阶数、移动平均阶数等,不同阶数的选择会影响ARIMA模型的预测效果。
ARIMA模型的预测目的是预测未来一段时间内的时间序列数据。
在进行模型预测时,我们需要确定预测的区间长度,根据之前的数据,计算需要预测的时间序列数据点所在的时间段内的均值和方差,并依照ARIMA模型的计算公式进行预测。
ARIMA模型在时间序列预测中的应用,已经非常成熟。
但是,ARIMA模型也有一些缺陷。
第一,ARIMA模型对于数据的通常要求非常苛刻,需要平稳且线性的时间序列数据;第二,ARIMA模型仅适用于描述非周期性时间序列数据,对于周期性和复杂时间序列数据,ARIMA模型效果欠佳。
因此,在实际预测中,我们需要针对数据的特点选择不同的方法和模型进行分析,以得到更加准确的预测结果。

⽤R做时间序列分析之ARIMA模型预测昨天刚刚把导⼊数据弄好,今天迫不及待试试怎么做预测,⽹上找的帖⼦跟着弄的。
第⼀步.对原始数据进⾏分析⼀.ARIMA预测时间序列指数平滑法对于预测来说是⾮常有帮助的,⽽且它对时间序列上⾯连续的值之间相关性没有要求。
但是,如果你想使⽤指数平滑法计算出预测区间,那么预测误差必须是不相关的,⽽且必须是服从零均值、⽅差不变的正态分布。
即使指数平滑法对时间序列连续数值之间相关性没有要求,在某种情况下,我们可以通过考虑数据之间的相关性来创建更好的预测模型。
⾃回归移动平均模型( ARIMA)包含⼀个确定(explicit)的统计模型⽤于处理时间序列的不规则部分,它也允许不规则部分可以⾃相关。
⼆.确定数据的差分ARIMA 模型为平稳时间序列定义的。
因此,如果你从⼀个⾮平稳的时间序列开始,⾸先你就需要做时间序列差分直到你得到⼀个平稳时间序列。
如果你必须对时间序列做 d 阶差分才能得到⼀个平稳序列,那么你就使⽤ARIMA(p,d,q)模型,其中 d 是差分的阶数。
我们以每年⼥⼈裙⼦边缘的直径做成的时间序列数据为例。
从 1866 年到 1911 年在平均值上是不平稳的。
随着时间增加,数值变化很⼤。
下⾯是.dat数据:下⾯进⼊预测。
先导⼊数据:> skirts <- scan("/tsdldata/roberts/skirts.dat",skip=5) #导⼊在线数据,并跳过前5⾏Read 46 items #R控制台显⽰内容,表⽰共读取46⾏数据> skirts<- ts(skirts,start = c(1866)) #设定时间1866开始> plot.ts(skirts) #画出图我们可以通过键⼊下⾯的代码来得到时间序列(数据存于“skirtsts”)的⼀阶差分,并画出差分序列的图: > skirtsdiff<-diff(skirts,differences=1) #⼀阶差分> plot.ts(skirtsdiff) #画图从⼀阶差分的图中可以看出,数据仍是不平稳的。

ARIMA模型的参数估计与预测ARIMA模型是一种常用于时间序列分析和预测的统计模型。
它可以通过对历史时间序列数据的分析来估计未来的趋势和周期性。
在进行ARIMA模型的参数估计和预测之前,我们首先需要了解ARIMA模型的组成和基本原理。
ARIMA模型是由自回归(AR)、差分(I)、移动平均(MA)这三个部分组成的。
自回归部分表示当前值与一些过去值的相关关系,差分部分对时间序列进行平稳化处理,移动平均部分则表示当前值与过去观测误差的相关关系。
这三个部分的组合可以通过ARIMA(p,d,q)进行表示,其中p、d和q分别代表AR部分的阶数、差分部分的阶数和MA部分的阶数。
在进行ARIMA模型的参数估计时,我们首先需要确定模型的阶数。
一种常用的方法是通过观察自相关图(ACF)和偏自相关图(PACF)来选择合适的阶数。
ACF表示观测值与滞后值之间的相关性,PACF表示观测值与滞后值之间的纯相关性。
根据ACF和PACF的图形特征,我们可以识别出模型中的AR和MA部分的阶数。
确定模型阶数后,我们可以使用最大似然估计(MLE)方法对模型的参数进行估计。
MLE方法是一种常用的参数估计方法,通过最大化在观测值给定情况下参数的可能性来估计参数值。
在ARIMA模型中,MLE方法可以用来估计AR和MA模型中的系数。
通过最大似然估计,我们可以得到ARIMA模型的最佳参数估计值。
在进行ARIMA模型的预测时,我们可以使用模型的参数估计值和历史观测值来预测未来的值。
预测方法可以采用递归方式,即使用已知的观测值和模型参数来计算未知的观测值。
这样,我们可以根据已知的历史观测值来预测未来的趋势和周期性。
ARIMA模型的参数估计和预测可以应用于各种领域的时间序列数据分析,包括股票价格预测、经济指标分析、气象数据预测等。
通过对时间序列数据的建模和分析,我们可以预测未来的趋势和变化,为决策提供参考。
除了ARIMA模型,还有其他一些时间序列分析和预测的方法和模型,如指数平滑法、回归模型等。

基于ARIMA模型的时间序列预测时间序列预测是一种重要的预测方法,它在许多领域中都有广泛的应用,包括经济学、金融学、气象学、交通规划等。
基于ARIMA模型的时间序列预测是一种经典方法,它能够通过对历史数据的分析和模型拟合来预测未来的趋势和变化。
本文将介绍ARIMA模型的基本原理及其在时间序列预测中的应用,并通过一个实例来说明其有效性和局限性。
ARIMA模型是自回归移动平均自回归模型(Autoregressive Integrated Moving Average Model)的简称,它是一种常用于时间序列分析和预测的统计模型。
ARIMA模型基于以下几个假设:首先,时间序列数据应该是平稳的,即其均值和方差在不同时刻上保持不变;其次,时间序列数据之间存在一定程度上的相关性;最后,在建立ARIMA 模型之前需要对原始数据进行差分操作以消除非平稳性。
ARIMA模型包括三个部分:自回归(Autoregressive, AR)部分、差分(Integrated, I)部分和移动平均(Moving Average, MA)部分。
自回归部分表示当前时刻值与过去时刻值之间的线性关系,差分部分表示对原始数据进行差分操作以达到平稳性,移动平均部分表示当前时刻值与过去时刻的误差之间的线性关系。
这三个部分的组合构成了ARIMA模型。
在ARIMA模型中,参数的选择是非常重要的。
选择合适的参数可以提高模型的拟合度和预测准确度。
常用方法包括自相关函数(ACF)和偏自相关函数(PACF)图,以及信息准则(AIC、BIC等)来选择最佳参数。
ARIMA模型在时间序列预测中具有广泛应用。
例如,在经济学中,ARIMA模型可以用来预测股票价格、通货膨胀率等经济指标;在气象学中,ARIMA模型可以用来预测温度、降雨量等气象数据;在交通规划中,ARIMA模型可以用来预测交通流量、拥堵情况等。
然而,ARIMA模型也存在一些局限性。
首先,在时间序列数据中可能存在非线性关系或季节性变化,在这种情况下使用ARIMA模型可能无法达到理想效果;其次,在实际应用中,时间序列数据可能受到外部因素(如变化、自然灾害等)的影响,这些因素无法通过ARIMA模型来捕捉;最后,ARIMA模型的预测结果可能受到数据长度和质量的影响,因此在使用ARIMA模型进行预测时需要谨慎选择和处理数据。

基于时间序列分析的ARIMA模型分析及预测ARIMA(Autoregressive Integrated Moving Average)模型是一种常用于时间序列分析和预测的经典模型。
它结合了自回归(AR)、差分(I)和移动平均(MA)这三种方法,可以较好地处理非平稳时间序列数据。
ARIMA模型的基本思想是根据时间序列数据的自相关(AR)和趋势性(MA)来预测未来的值。
它的建模过程包括确定模型的阶数、参数估计和模型诊断。
首先,ARIMA模型的阶数由p、d和q这三个参数决定。
其中,p代表自回归阶数,d代表差分阶数,q代表移动平均阶数。
p和q决定了时间序列的自相关和移动平均相关的程度,而d决定了时间序列是否平稳。
确定这些参数可以通过观察ACF(自相关函数)和PACF(偏自相关函数)图来进行。
接下来,参数估计是ARIMA模型中关键的一步。
常用的估计方法有最小二乘法(OLS)和最大似然估计法(MLE)。
最小二乘法适用于平稳时间序列,最大似然估计法适用于非平稳时间序列。
完成参数估计后,还需要进行模型诊断。
模型诊断主要是通过残差序列来判断模型是否拟合良好。
通常,残差序列应满足如下条件:残差序列应是白噪声序列,即残差之间应该没有相关性;残差序列的均值应接近于零,方差应保持不变。
最后,通过使用ARIMA模型预测未来的值。
根据模型对未来的预测,我们可以得到未来一段时间内的时间序列预测结果。
ARIMA模型的优点是可以对非平稳时间序列进行建模和预测。
它几乎可以应用于任何时间序列数据,如股票价格、气温、销售量等。
然而,ARIMA模型也有一些限制。
首先,ARIMA模型假设时间序列的结构是稳定的,但实际上很多时间序列数据都是非稳定的。
其次,ARIMA 模型对数据的准确性和完整性有较高的要求,如果数据中存在缺失值或异常值,建模的准确性会受到影响。
总结来说,ARIMA模型是一种经典的时间序列分析和预测方法。
它能够处理非平稳时间序列数据,并且可以通过确定阶数、参数估计和模型诊断来进行预测。

基于ARIMA模型算法的频谱时间序列预测分析摘要:结合频谱时间序列的特点,选择ARIMA模型作为预测模型,通过ARIMA模型算法的流程分析,初步论证预测模型及预测精度的可靠性。
关键词:ARIMA模型频谱时间序列时间序列就是按时间顺序取得的一系列观测值,具有如下特点:首先,时间序列的数据或数据点的位置依赖于时间,即数据的取值依赖于时间的变化,但不一定是时间t的严格函数;其次,每一时刻上的取值或数据点的位置具有一定的随机性,不可能完全准确地用历史值进行预测;第三,前后时刻(不一定是相邻时刻)的数值或数据点的位置有一定的相关性,这种相关性就是系统的动态规律性。
1 频谱时间序列的特点由于电磁环境的复杂多样性以及许多未知因素和不确定因素的影响,频谱占用是一个复杂多变的过程,频谱数据具有高度的非线性特点。
目前多数学者认为,频谱时间序列一般由确定分量和随机分量组成,确定分量具有一定的物理含义,随机分量由不规则的振荡和随机影响造成,具有高度的非线性特点,在进行频谱数据分析时,应根据频谱时间序列的特点找出一种精度较高的预测模型。
2 基于ARIMA模型算法的流程分析ARIMA模型算法分析流程图如图1所示。
2.1 平稳性检验平稳时间序列因为有很好的统计特性,首先检验所观测样本的平稳性,然后根据其是否具有平稳性来建立相适应的模型,主要使用自相关系数和自相关图检验。
运用自相关分析图判定时间序列平稳性的一般准则是:若时间序列的自相关系数基本上(通常为p>3时)都落入置信区间,且逐渐趋于零,则该时间序列具有平稳性;若时间序列的自相关系数更多的落在置信区间外面,则该时间序列就不具有平稳性。
2.2 纯随机性检验如果序列值之间没有任何相依性,过去的行为对将来的发展没有任何丝毫影响,这种序列称为纯随机序列。
从统计的观点来看,纯随机序列是没有任何分析价值的序列,因此需要对平稳序列进行纯随机性检验。
就说明该序列不是纯随机序列,该序列间隔k期的序列值之间存在着一定程度的相互影响关系,统计上称为相关信息。

基于ARIMA模型的时间序列预测章节一:引言1.1 背景介绍时间序列是指通过时间间隔进行记录和测量的数据序列。
时间序列分析是一种重要的统计方法,用于预测未来数据的趋势和模式。
ARIMA (自回归滑动平均)模型是一种常用的时间序列分析方法,被广泛应用于金融、经济、天气等领域的预测与分析。
本文将介绍基于ARIMA 模型的时间序列预测原理、建模步骤以及应用案例。
1.2 目的和意义时间序列预测是许多领域中重要的数据分析任务。
通过预测未来数据的趋势和模式,我们可以更好地制定决策和规划,从而提高效率和减少风险。
ARIMA模型作为一种经典的时间序列分析方法,其在预测准确性和稳定性方面表现出色,因此被广泛应用。
本文旨在介绍ARIMA模型的原理和应用,帮助读者理解和运用该方法。
章节二:ARIMA模型原理2.1 自回归模型(AR模型)AR模型用于描述时间序列与其过去值的线性关系。
AR(p)模型表示当前观测值与过去p个观测值之间存在线性关联,公式如下:y(t) = c + φ1*y(t-1) + φ2*y(t-2) + ... + φp*y(t-p) + ε(t)其中,c是常数,φ1, φ2, ... , φp是模型的参数,ε(t)是表示误差的白噪声随机变量。
2.2 滑动平均模型(MA模型)MA模型用于描述时间序列与其误差项(白噪声)的线性关系。
MA(q)模型表示当前观测值与过去q个误差项之间存在线性关联,公式如下:y(t) = c + θ1*ε(t-1) + θ2*ε(t-2) + ... + θq*ε(t-q) +ε(t)其中,c是常数,θ1, θ2, ... , θq是模型的参数,ε(t)是表示误差的白噪声随机变量。
2.3 差分模型(I模型)差分模型用于将非平稳时间序列转化为平稳时间序列。
差分运算可以通过对观测值进行减法运算得到,表示为Δy(t) = y(t) - y(t-1)。
I(d)模型表示将时间序列进行d阶差分运算后得到平稳时间序列。

时序预测中的ARIMA模型详解一、引言时序预测是指根据一系列时间上连续的数据,对未来时间点或时间段内的数据进行预测。
这种预测方法在经济、金融、气象、交通等领域都有着广泛的应用。
而在时序预测中,ARIMA模型是一种常用的方法,本文将对ARIMA模型进行详细解读。
二、ARIMA模型概述ARIMA模型是自回归移动平均模型(Autoregressive Integrated Moving Average Model)的缩写,它是一种基于时间序列数据的预测模型。
ARIMA模型包含三个部分,分别为自回归(AR)、差分(I)和移动平均(MA)。
ARIMA模型的基本思想是,通过将非平稳的时间序列数据进行差分,使其成为平稳序列,然后建立ARMA模型进行预测。
三、ARIMA模型的建模过程1. 根据数据特征确定模型参数在建立ARIMA模型之前,首先需要对时间序列数据进行分析。
通过观察数据的自相关性和偏自相关性函数图,确定ARIMA模型的阶数。
自相关性函数图可以帮助我们找到时间序列数据的自相关性模式,从而确定AR模型的阶数。
偏自相关性函数图则可以帮助我们确定MA模型的阶数。
2. 数据平稳化ARIMA模型要求时间序列数据是平稳的,因此如果数据是非平稳的,需要对其进行差分处理。
差分的目的是使数据的均值和方差保持不变,从而使其成为平稳序列。
3. 模型训练和预测在确定了ARIMA模型的阶数和对数据进行平稳化后,就可以进行模型的训练和预测。
模型的训练是指利用历史数据对ARIMA模型的参数进行估计,然后利用训练好的模型进行未来数据的预测。
四、ARIMA模型的优缺点ARIMA模型作为一种经典的时序预测模型,具有以下优点:1. 适用性广泛:ARIMA模型适用于各种类型的时间序列数据,包括具有趋势和季节性的数据。
2. 参数可解释性强:ARIMA模型的参数具有明确的统计学意义,便于解释和理解。
然而,ARIMA模型也有一些缺点:1. 对数据要求高:ARIMA模型要求时间序列数据是平稳的,而有些实际数据不满足这一条件,需要进行差分处理。
时间序列分析中的ARIMA算法介绍及应用案例分析时间序列分析是一种从历史数据中提取信息并预测未来趋势的方法,它在金融、经济、气象等领域有广泛的应用。
而ARIMA模型则是时间序列分析中最常用的一种模型。
本文将介绍ARIMA模型的原理及应用案例。
一、ARIMA模型的原理ARIMA模型全称为AutoRegressive Integrated Moving Average Model,即自回归积分滑动平均模型。
它是一种将自回归模型和滑动平均模型结合在一起的时间序列模型,用于对非平稳时间序列进行建模和预测。
ARIMA模型可以表示为ARIMA(p, d, q),其中p表示自回归项数,d表示差分次数,q表示滑动平均项数。
如果时间序列是平稳的,可以使用ARMA模型,而非平稳时间序列则需要使用ARIMA模型。
ARIMA模型的建立一般有三个步骤:确定阶数,估计系数,检验模型。
首先,我们需要通过观察时间序列的自相关图和偏自相关图来确定p和q的值。
自相关图可以反映时间序列的自相关性,即同一时间点前后的样本值之间的相关性。
而偏自相关图是指当与其他滞后时期的影响被移除后,两个时期之间的相关性。
如图1所示:图1 自相关图和偏自相关图在确定p和q的值之后,我们需要进行差分运算,将非平稳序列转换为平稳序列,以确保ARIMA模型的有效性。
当d=1 时,表示进行一次一阶差分运算,将原来时间序列的差分序列变为平稳序列。
当然也有可能需要进行多阶差分。
最后,我们需要通过最大似然估计法或最小二乘法来估计ARIMA模型的系数,进而用模型进行预测。
二、ARIMA模型的应用案例为了更好地理解ARIMA模型的应用,我们可以通过一个实际案例来进行分析。
案例:某导购商城每天的销售额某月份的数据如下:日期销售额(万元)2020-06-01 1022020-06-02 892020-06-03 772020-06-04 622020-06-05 812020-06-06 932020-06-07 1042020-06-08 982020-06-09 762020-06-10 702020-06-11 672020-06-12 932020-06-13 93 2020-06-14 111 2020-06-15 93 2020-06-16 77 2020-06-17 72 2020-06-18 56 2020-06-19 81 2020-06-20 99 2020-06-21 110 2020-06-22 104 2020-06-23 81 2020-06-24 75 2020-06-25 59 2020-06-26 84 2020-06-27 95 2020-06-28 112 2020-06-29 92 2020-06-30 77通过观察时间序列的图像,我们可以看出该序列的趋势、季节性和噪声。
利用ARIMA模型进行市场时间序列预测ARIMA(Autoregressive Integrated Moving Average)模型是一种常用于时间序列预测的经典模型。
它结合了自回归(AR)模型和滑动平均移动平均(MA)模型,其中还包括差分整合(I)的步骤。
ARIMA模型在金融市场、经济学领域以及其他许多领域中被广泛应用。
本文将介绍ARIMA模型的原理与应用,并探讨如何使用ARIMA模型进行市场时间序列的预测。
首先,我们来了解ARIMA模型的三个重要组成部分:自回归(AR)模型、滑动平均移动平均(MA)模型和差分整合(I)步骤。
AR模型是指将当前值与过去一段时间的值进行线性回归。
AR模型假设当前值与过去的值之间存在相关性,可以通过计算自相关系数(ACF)和偏自相关系数(PACF)来确定AR模型的阶数。
ACF描述了当前值与过去值之间的相关性,而PACF描述了当前值与过去值之间消除了其他中间变量的相关性。
MA模型是指当前值与过去的误差项之间的关系。
MA模型假设误差项具有滑动平均的性质,可以通过计算残差的自相关系数(ACF)和偏自相关系数(PACF)来确定MA模型的阶数。
通常,MA模型的PACF截尾到零,这意味着误差项与过去的值之间没有长期相关性。
差分整合(I)步骤是为了对非平稳时间序列进行处理,使其变得平稳。
若时间序列不平稳,ARIMA模型的预测结果可能不准确。
差分整合可以通过对时间序列进行取差分或一阶差分的方式来实现。
取差分即减去前一个值得到差分序列,一阶差分即减去当前值和前一个值的差分序列。
通过差分整合后,时间序列中的趋势和季节性因素被消除,使其平稳化。
接下来,我们将介绍如何使用ARIMA模型进行市场时间序列的预测。
首先,我们需要收集市场相关的时间序列数据。
这可以是某个特定商品或股票的价格、交易量等。
我们可以使用Python或R等编程语言中的相应库来进行数据获取和处理。
接着,我们可以使用自相关图(ACF)和偏自相关图(PACF)来确定ARIMA模型的参数。
时间序列数据预测的ARIMA模型研究时间序列分析是利用数据时间性质的统计学方法。
时间序列是指按照时间先后次序排列的数据。
时间序列分析是针对时间序列数据的一种方法。
时间序列中的数据通常都有一个趋势和季节性,一般形式如下图:[插入一张样例时间序列数据的图]在实际生活中,针对时间序列数据进行预测是非常常见的需求。
例如,股票价格、气温、人口数等等。
ARIMA(Autoregressive Integrated Moving Average)模型是一种常用的时间序列分析模型,它结合了自回归模型和移动平均模型的特点,同时也考虑到了序列的差分。
ARIMA模型包含了三个重要的参数:AR,I,MA。
其中AR为自回归,指时间序列因子在不同时期自己的滞后期的影响,I为整合,指对时间序列的差分,MA为滑动平均,指较长期的随机扰动。
ARIMA模型的应用非常广泛,在金融领域、气象领域等都有很多应用。
下面我们将结合一个例子来详细说明ARIMA模型的应用。
例子:用ARIMA模型预测气温[插入气温时间序列数据的图]上图展示了从2011年到2019年日本东京的每日气温数据。
我们想要预测未来几天的气温,以方便人们的出行计划或选衣搭配等方面的决策。
首先,我们需要进行数据的差分。
差分是ARIMA模型的一个重要概念,也就是将原时间序列数据转化为一个新的序列,新序列的每一项数据都是原序列中当前项和前一项之间的差值。
可以看出,差分后的数据比原数据更加稳定,波动性更小。
接下来,我们要进行一系列的统计检验来确定最终的模型参数。
常用的统计检验包括ADF(Augmented Dickey Fuller)测试、K-S(Kolmogorov-Smirnov)检验等。
[插入各种统计检验的结果图]经过检验,我们确定了最终的模型参数:ARIMA(2, 1, 2)这表示我们用两次差分来消除序列的趋势,用过去两个时期的数据来回归当前值,并考虑了波动性随时间变化的情况。
基于ARIMA模型的时间序列预测准确优化时间序列预测是指根据过去的数据模式和趋势,去预测未来一段时间内的数值变化。
ARIMA(自回归积分滑动平均模型)是最常用的时间序列预测方法之一。
它通过对时间序列数据的自相关性和偏相关性进行分析,构建出能够预测未来数值变化的模型。
然而,ARIMA模型在实际应用中存在一定的准确性问题,需要进行优化。
一、ARIMA模型的基本原理ARIMA模型采用的是线性回归方法,建立一个自回归模型,同时,通过差分操作对时间序列进行平稳化处理。
ARIMA模型具有三个参数:p、d和q,分别表示自回归阶数、差分阶数和滑动平均阶数。
1. 自回归(AR)模型自回归模型是基于时间序列的过去数值进行预测未来数值的方法。
其中,p表示自回归阶数,即使用前p个时间步长的数值进行预测。
2. 积分(I)模型积分模型是为了平稳化时间序列而进行的差分操作。
差分操作可以消除时间序列的季节性和趋势性,使其更容易建立模型进行预测。
3. 滑动平均(MA)模型滑动平均模型是基于时间序列的过去数值与误差项的滞后值进行的线性组合。
其中,q表示滑动平均阶数,即使用前q个误差项的滞后值进行预测。
二、ARIMA模型准确性问题的原因尽管ARIMA模型在时间序列预测中被广泛应用,但其准确性在一些特定情况下可能存在问题。
以下是几个可能导致ARIMA模型准确性问题的原因:1. 数据质量问题ARIMA模型的准确性很大程度上依赖于数据的质量。
存在异常值、缺失值或离群值等数据质量问题可能会对ARIMA模型的准确性产生较大影响。
2. 趋势性和季节性变动ARIMA模型在处理具有趋势性和季节性变动的时间序列时,预测较为困难。
这是因为ARIMA模型是基于线性回归的方法,对于非线性趋势和季节变动的数据,准确性会有所下降。
3. 参数选择问题ARIMA模型的准确性还受参数选择的影响。
确定ARIMA模型的参数(例如p、d和q)需要根据经验和模型拟合的结果来调整,不同的参数选择可能会导致不同的预测效果。
报告中的时间序列模型与ARIMA分析时间序列模型是一种用于分析和预测时间序列数据的统计模型。
ARIMA(自回归移动平均)是常用的时间序列模型之一,可以用于描述和预测时间序列数据中的趋势、季节性和随机性成分。
在本文中,我们将对报告中的时间序列模型与ARIMA分析进行详细讨论,包括其基本原理、建模方法和应用案例。
一、时间序列模型的基本原理时间序列模型是基于时间序列数据的统计模型,其基本原理是假设数据中存在一定的内在结构和规律,可以通过建立数学模型来揭示和利用这些结构和规律。
时间序列模型通常用于分析和预测具有时间先后顺序的数据,如股票价格、气温变化等。
它可以帮助我们理解数据的变化趋势、周期性和随机性,并提供预测未来数值的方法。
二、ARIMA模型的基本原理ARIMA模型是一种广泛应用的时间序列模型,其基本原理是通过自回归(AR)、差分(I)和移动平均(MA)的组合来描述和预测时间序列数据。
ARIMA模型假设时间序列数据既受到其自身过去值的影响,又受到随机误差的影响,通过建立自回归项、差分项和移动平均项的组合来捕捉这些影响。
三、ARIMA建模方法ARIMA建模包括模型识别、参数估计和模型检验三个步骤。
模型识别主要是通过观察时间序列图和自相关函数(ACF)和偏自相关函数(PACF)图来确定模型的阶数。
参数估计采用最大似然估计方法来估计模型的参数。
模型检验主要包括残差的白噪声检验和模型拟合程度的评估。
四、ARIMA模型的应用案例ARIMA模型在各个领域都有广泛应用。
例如,在经济学中,ARIMA模型可以用于预测经济指标的变化,如 GDP、通货膨胀率等。
在环境学中,ARIMA模型可以用于预测大气污染物浓度的变化。
在医学中,ARIMA模型可以用于预测传染病的发展趋势。
在金融领域,ARIMA模型可以用于预测股票价格变动。
这些应用案例充分展示了ARIMA模型在时间序列分析和预测中的重要作用。
五、ARIMA模型的改进和扩展ARIMA模型在实际应用中存在一些局限性,如对数据的平稳性要求较高、无法很好地处理长期依赖等。
金融时间序列预测中的ARIMA模型及改进金融市场的波动性一直以来都是投资者的关注焦点之一。
准确地预测金融时间序列的走势对于投资者来说具有重要意义,能够指导他们制定合理的投资策略。
而ARIMA(自回归移动平均)模型作为一种基于统计的时间序列分析方法,被广泛应用于金融时间序列的预测中。
本文将重点介绍ARIMA模型及其在金融时间序列预测中的应用,并结合实际问题提出了一些对ARIMA模型的改进方法。
I. ARIMA模型简介ARIMA模型是一种将时间序列分解为趋势、季节性和随机成分的经典模型。
其中,AR(自回归)表示变量和自身的滞后值之间存在线性关系,MA(移动平均)表示变量和随机误差的滞后值之间存在线性关系,I(差分)表示通过将原始序列进行差分,将非平稳序列转化为平稳序列。
II. ARIMA模型在金融时间序列预测中的应用金融时间序列通常包含多种特征,例如长期趋势、季节性以及非线性的波动性。
ARIMA模型能够有效地捕捉这些特征,提供准确的预测结果。
在金融领域,ARIMA模型广泛应用于股票价格预测、汇率波动预测等方面。
III. ARIMA模型的改进方法尽管ARIMA模型在金融时间序列预测中表现出色,但在实际应用中也存在一些问题。
为了进一步提高预测的准确性,研究者们提出了许多对ARIMA模型的改进方法。
以下是一些常见的改进方法:1. 季节性ARIMA模型(SARIMA):在ARIMA模型的基础上加入季节性因素,用以更好地捕捉时间序列数据中的季节性变化。
2. 长短期记忆网络(LSTM):LSTM模型是一种基于深度学习的神经网络模型,具有较强的记忆能力和非线性建模能力,能够更好地应对非线性时间序列的预测。
3. 波动率模型:金融时间序列通常具有波动性的特征,传统的ARIMA模型难以捕捉到这一特征。
因此,研究者们提出了一系列基于波动率模型的改进方法,如ARCH、GARCH等。
4. 多变量ARIMA模型:金融市场的波动性往往受到多个因素的影响,单一的时间序列模型难以全面考虑这些因素。