SPSS时间序列分析总结
- 格式:ppt
- 大小:1.86 MB
- 文档页数:70


SPSS时间序列:频谱分析⼀、频谱分析(分析-预测-频谱分析)“频谱图”过程⽤于标识时间序列中的周期⾏为。
它不需要分析⼀个时间点与下⼀个时间点之间的变异,只要按不同频率的周期性成分分析整体序列的变异。
平滑序列在低频率具有更强的周期性成分;⽽随机变异(“⽩噪声”)将成分强度分布到所有频率。
不能使⽤该过程分析包含缺失数据的序列。
1、⽰例。
建造新住房的⽐率是⼀个国家/地区经济的重要晴⾬表。
有关住房的数据开始时通常会表现出⼀个较强的季节性成分。
但在估计当前数字时,分析⼈员需要注意数据中是否呈现了较长的周期。
2、统计量。
正弦和余弦变换、周期图值和每个频率或周期成分的谱密度估计。
在选择双变量分析时:交叉周期图的实部和虚部、余谱密度、正交谱、增益、平⽅⼀致和每个频率或周期成分的相位谱。
3、图。
对于单变量和双变量分析:周期图和频谱密度。
对于双变量分析:平⽅⼀致性、正交谱、交叉振幅、余谱密度、相位谱和增益。
4、数据。
变量应为数值型。
5、假设。
变量不应包含任何内嵌的缺失数据。
要分析的时间序列应该是平稳的,任何⾮零均值应该从序列中删除。
平稳. 要⽤ARIMA 模型进⾏拟合的时间序列所必须满⾜的条件。
纯的MA 序列是平稳的,但AR 和ARMA 序列可能不是。
平稳序列的均值和⽅差不随时间改变。
⼆、频谱图(分析-预测-频谱分析)1、选择其中⼀个“频谱窗⼝”选项来选择如何平滑周期图,以便获得谱密度估计值。
可⽤的平滑选项有“Tukey-Hamming”、“Tukey”、“Parzen”、“Bartlett”、“Daniell(单元)”和“⽆”。
1.1、Tukey-Hamming. 权重为Wk = .54Dp(2 pi fk) + .23Dp (2 pi fk + pi/p) + .23Dp (2pi fk - pi/p),k = 0, ..., p,其中p 是⼀半跨度的整数部分,Dp 是阶数p 的Dirichlet 内核。
1.2、Tukey. 权重为Wk = 0.5Dp(2 pi fk) + 0.25Dp (2 pi fk + pi/p) + 0.25Dp(2 pi fk -pi/p),k = 0, ..., p,其中p 是⼀半跨度的整数部分,Dp 是阶数p 的Dirichlet 内核。


第十四章SPSS 的时间序列分析14.9 季节调整法一、时间序列的趋势分解:长期趋势(Trend ): 现象在较长时期内持续发展变化的一种趋向或状态由影响时间序列的基本因素作用形成是时间序列中最基本的构成要素可分为上升趋势、下降趋势、水平趋势或分为:线性趋势和非线性趋势。
周期变动(Periodicity) :这种因素的影响使现象呈现出以若干年为一周期、涨落相间、扩张与紧缩、波峰与波谷相交替的波动。
不同于长期趋势T 表现为单一方向的持续变动,P 表现为波浪式的涨落交替的变动。
季节变动(Seasonal Fluctuation ) :是一种使现象以一定时期(如一年、一月、一周等)为一周期呈现较有规律的上升、下降交替运动的影响因素通常表现为现象在一年内随着自然季节的更替而发生的较有规律的增减变化,有旺季和淡季之分是一种周期性的变化周期长度小于一年形成原因:有自然因素,也有人为因素不规则变动(Irregular Variations) :包括随机变动和突然变动。
随机变动――现象受到各种偶然因素影响而呈现出方向不定、时起时伏、时大时小的变动。
突然变动――战争、自然灾害或其它社会因素等意外事件引起的变动。
影响作用无法相互抵消,影响幅度很大。
一般只讨论有随机波动而不含突然异常变动的情况。
二、时间序列的分解模型Y= T×S×P×I 在加法模型中各种影响因素是相互独立的,均为与Y 同计量单位的绝对量。
季节变动和循环变动的数值在各自的周期时间范围内总和为零;不规则变动的数值从长时间来看,其总和也应为零。
加法模型中,各因素的分解是根据减法进行(如:Y。
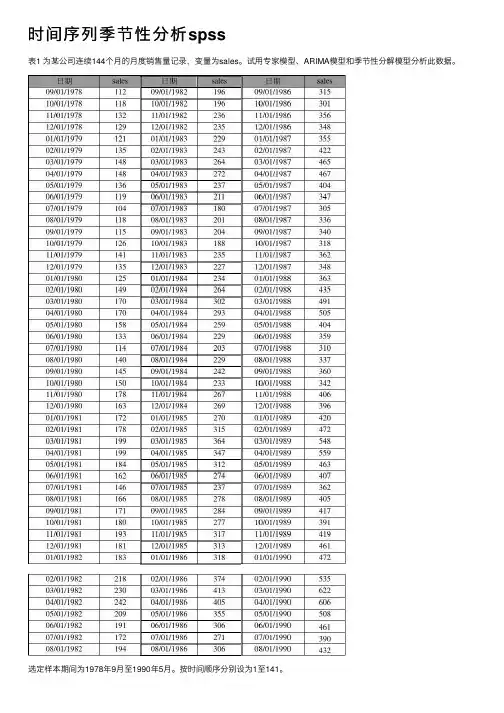
时间序列季节性分析spss表1 为某公司连续144个⽉的⽉度销售量记录,变量为sales。
试⽤专家模型、ARIMA模型和季节性分解模型分析此数据。
选定样本期间为1978年9⽉⾄1990年5⽉。
按时间顺序分别设为1⾄141。
⼀、画出趋势图,粗略判断⼀下数据的变动特点。
具体操作为:依次单击菜单“Analyz e→Forecasting→Sequence Chart”,打开“Sequence Chart”对话框,在打开的对话框中将sales选⼊“Variables”列表框,时间变量date选⼊“Time Axis Labels”,单击“OK”按钮,则⽣成如图2 所⽰的sales序列。
图1 “Sequence Chart”对话框从趋势图可以明显看出,时间序列的特点为:呈线性趋势、有季节性变动,但季节波动随着趋势增加⽽加⼤。
⼆、模型的估计(⼀)、季节性分解模型根据时间序列特点,我们选择带线性趋势的季节性乘法模型作为预测模型。
1、定义⽇期具体操作为:依次单击菜单“Data→Define Date”,打开“Define Date”对话框,在“Cases Are”列表框选择“Years,months”的⽇期格式,在对话框的右侧定义数据的起始年份、⽉份。
定义完毕后,单击“OK”按钮,在数据集中⽣成⽇期变量。
图3 “Define Date”对话框2、季节分解具体操作为:“Analyze→Forecasting→Seasonal Decomposition”打开“Seasonal Decomposition”对话框,将待分析的序列变量名选⼊“Variable”列表框。
在“Model Type”选择组中选择“Multiplicative”模型;在“Moving Average Weight”选择组中选择“Endpoints weighted by 0.5”。
单击“OK”按钮,执⾏季节分解操作。
图4 “Seasonal Decomposition”对话框3、画出序列图①原始序列和校正了季节因⼦作⽤的序列图图5为sales 序列和校正了季节因⼦作⽤的序列图。



SPSS作业关于时间序列分析时间序列分析是一种统计方法,用于研究随时间变化的数据,并从中提取出隐藏在数据背后的模式和趋势。
这种分析方法在经济学、金融学、天气预报、市场调研等领域经常被应用。
SPSS(Statistical Package for the Social Sciences)是一款广泛使用的统计分析软件,它提供了丰富的时间序列分析工具,可以用来处理和分析时间序列数据。
时间序列数据是根据时间顺序排列的一系列观测值,例如每天的股票价格、每月的销售额、每年的气温等等。
通过对这些时间序列数据进行分析,我们可以得到数据的趋势、季节性、周期性等信息,以及对未来数据的预测。
在SPSS中进行时间序列分析的第一步是导入数据。
通常,数据以文本文件的形式存在,我们需要将其导入到SPSS中进行后续操作。
导入数据完成后,我们可以开始对数据进行初步的探索和观察。
SPSS提供了一系列的统计工具,可以用于时间序列数据的分析。
其中最常用的是时间序列图,它可以帮助我们观察数据的趋势和季节性。
通过绘制时间序列图,我们可以更直观地了解数据的波动情况,找出可能的异常值和离群点。
除了时间序列图,SPSS还提供了许多其他的分析工具,如自相关函数、偏自相关函数、移动平均等。
自相关函数可以帮助我们研究数据之间的相关性,了解数据的滞后效应;偏自相关函数则可以帮助我们确定时间序列模型的阶数;移动平均则可以用于平滑时间序列数据,减少数据的随机波动。
时间序列分析的一个重要应用是预测。
通过对过去数据的分析,我们可以建立时间序列模型,并用此模型来预测未来的数据。
SPSS提供了各种预测模型,如ARIMA模型、指数平滑模型等。
通过选择合适的模型和参数,SPSS可以帮助我们进行准确的预测,并提供相应的置信区间和预测误差。
除了基本的时间序列分析工具,SPSS还提供了其他高级功能,如自回归条件异方差模型(ARCH)、广义自回归条件异方差模型(GARCH)等。

SPSS时间序列一点总结(一)SPSS中"Time Series"包括4个时间序列分析子菜单:1.Exponential Smoothing指数平滑2.Autoregression自回归3.ARIMA自回归综合移动平均4.Seasonal Decomposition季节分散法(一)Exponential Smoothing指数平滑中的Model有四种:Simple、Holt、Winters、Custom. Simple法是在移动平均法基础上发展而来的一次指数平滑法,它假定所研究的时间序列数据集无趋势和季节变化.Simple法基本过程:1.首先定义变量、输入数据,至少要有一个变量,点出Data菜单中的Define Dates对话框,定义时间序列的周期.Define Dates可用来建立时间序列的周期性.共有20种可用来定义时间日期的变量.2.指定需要进行指数平滑处理的变量.从左侧变量名列表中选中需要进行指数平滑处理的变量,单击右面一个右箭头按钮,使变量名移到Variables框中.如果变量为多个,则计算完一个后,再输入另一个变量.3."Parameters"参数设定,选定指数平滑中的参数,误差修正权数 a(General(Alpha))的取值在默认状态下为0.1,其取值大小依赖于已知时间序列的性质,通常都使用在0.1至0.3之间的数值并产生一个依赖于大量的过去观测资料的预测.接近于1的值较少用,它将给出更加依赖于新近观察资料的预测.当a=1时,预测值等于最新的观测值.单击Grid Search选项,如不加改动,可让程序自动计算a从0.1到1的10个指数平滑结果,并将误差平方和最小的平滑结果暂时存放在数据库中,当然,在这里可重新设置a的开始值,以后每次的增加值及终止值.在本程序中,确定Initial Values初始值栏中的选择有两种方式,选择Automatic项,初始值用自动方式生成,程序自动取时间序列的总平均值为初始值:选择Custom项,可手工输入初始值及趋势值.单击"Save",最后单击"OK"并执行.Holt双参数线性指数平滑法适用于有线性趋势及无季节变化的时间序列的趋势.它可以用不同的参数对原时间序列的趋势进行平滑,具有很大的灵活性.在此法中要用到两个参数a、g(从0到1之间取值)和三个方程(略).Holt法基本过程1、首先按定义变量、输入数据,至少要有一个变量,在Data菜单的Define Dates设置; 指定需要Holt指数平滑法处理的变量.从左侧变量名列表中选中需要进行指数平滑处理的变量,如果变量为多个,则计算完一个后,再输入另一个变量.选定Holt选项.设置Parameters即指数平滑中的参数,参数a、g的取值在默认状态下都为0.1,它们都在0到1之间取值.其取值大小依赖于已知时间序列的性质,通常使用0.1至0.3之间的数值,并产生一个依赖于大量的过去观测资料的预测.接近于1的值较少用,它将给出更加依赖于新近观测资料的预测.不使用默认值,可通过单击Grid Search选项来自定义,如不加改动,可让程序自动计算a从0.1到1每次增加0.1、g从0.1到1每次增加0.2的10个指数平滑结果,并将误差平方和最小的平滑结果暂时存放在数据库中.当然,可以重新设置a、g的初始值、以后每次的增加值及终止值.在本程序中,确定初始值的选中有两种方式,选中Automatic项,初始值用自动方式生成,程序自动取时间序列的总平均值为初始值St并自动给出趋势值bt.选中Custom项,可手工输入初始值及趋势值.Winters线性和季节性指数平滑法适用于数据的变化含有季节性因素的时间序列的预测.选定指数平滑中的参数"Patameters",参数a、b、g的取值在默认状态下都为0.1,它们都在0到1之间取值,但都不包括0和1.采用Winters法的关键是如何确定a、b、g的值,以使均方差达到最小.最佳方法是反复试验法.如不使用默认值,除直接修改a、b、g的值外,还可通过单击Grid Search来自定义.可让程序自动计算a从0.1到1每次增加0.1,b、g从0.1到1每次增加0.2的10个指数平滑结果,并将误差平方和最小的平滑结果暂时存放在数据库中,SPSS在商务管理中的应用,当然,在这里可重新设置a、b、g的开始只,以后每次的增加值及终止值.在本程序中,确定初始值的选择有两种方式,选择Automatic,初始值用自动方式生成,程序自动取时间序列的总平均值为初始值St并自动给出趋势值bt;选择Custom,可手工输入初始值及趋势值.。
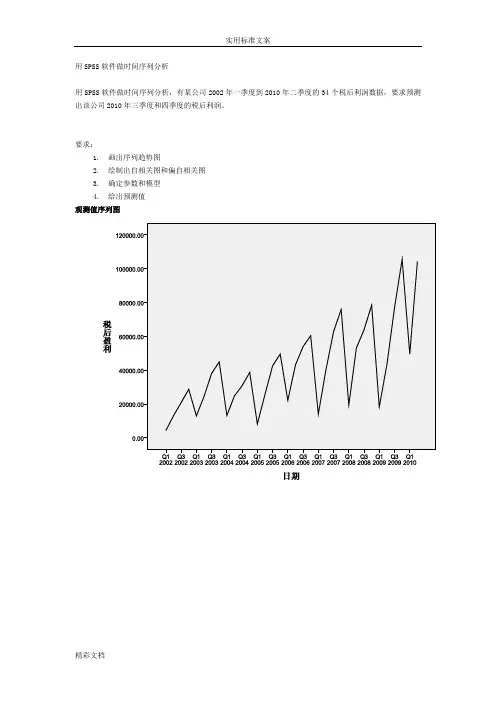
用SPSS软件做时间序列分析用SPSS软件做时间序列分析,有某公司2002年一季度到2010年二季度的34个税后利润数据,要求预测出该公司2010年三季度和四季度的税后利润。
要求:1.画出序列趋势图2.绘制出自相关图和偏自相关图3.确定参数和模型4.给出预测值观测值序列图2税后盈利自相关图序列:税后盈利滞后自相关标准误差aBox-Ljung 统计量值df Sig.b1 .306 .164 3.482 1 .0622 .198 .162 4.987 2 .0833 .185 .159 6.340 3 .0964 .542 .157 18.342 4 .0015 .084 .154 18.641 5 .0026 .067 .151 18.836 6 .0047 .094 .149 19.239 7 .0078 .458 .146 29.093 8 .0009 .041 .143 29.176 9 .00110 .016 .140 29.189 10 .00111 .012 .137 29.197 11 .00212 .236 .134 32.308 12 .00113 -.092 .131 32.806 13 .00214 -.094 .128 33.345 14 .00315 -.079 .125 33.745 15 .00416 .106 .121 34.510 16 .005a. 假定的基础过程是独立性(白噪音)。
b. 基于渐近卡方近似。
偏自相关序列:税后盈利滞后偏自相关标准误差1 .306 .1712 .115 .1713 .107 .1714 .503 .1715 -.279 .1716 -.010 .1717 .046 .1718 .268 .1719 -.130 .17110 -.054 .17111 -.053 .17112 -.081 .17113 -.040 .17114 -.051 .17115 -.027 .17116 -.062 .1713、确定参数和模型时间序列建模程序模型描述模型类型模型 ID 税后利润模型_1 ARIMA(0,1,0)(0,1,0) 模型摘要模型统计量模型预测变量数模型拟合统计量Ljung-Box Q(18)离群值数平稳的 R 方统计量DF Sig.税后利润-模型_1 0 5.502E-17 17.688 18 .476 04、给出预测值2010年第三季度 139621.02万元2010年第四季度170144.55万元剔除季节成分后,平滑处理及剔除循环波动因素的序列图SEASON、MOD_6、MUL、EQU、4 中税后利润的季节性调整序列自相关图序列:SEASON、MOD_6、MUL、EQU、4 中税后利润的季节性调整序列滞后自相关标准误差aBox-Ljung 统计量值df Sig.b1 .728 .164 19.633 1 .0002 .450 .162 27.383 2 .0003 .310 .159 31.169 3 .0004 .207 .157 32.911 4 .0005 .219 .154 34.941 5 .0006 .241 .151 37.484 6 .0007 .243 .149 40.168 7 .0008 .226 .146 42.571 8 .0009 .183 .143 44.213 9 .00010 .162 .140 45.551 10 .00011 .093 .137 46.012 11 .00012 .006 .134 46.015 12 .00013 -.047 .131 46.145 13 .00014 -.021 .128 46.172 14 .00015 -.022 .125 46.204 15 .00016 -.036 .121 46.294 16 .000a. 假定的基础过程是独立性(白噪音)。

实验八spss11中的时间序列分析一、实验目的了解spss11中时间序列分析的简单方法二、实验原理介绍1.SPSS中时间序列分析简要介绍依时间顺序排列起来的一系列观测值称为时间序列,跟大部分的统计不同,这类资料的先后顺序是不能忽视的,更关键的是观测值之间不独立。
因此,这类数据不能用普通的统计方法解决。
时间序列分析(Time series)是专门用于分析这种时间序列资料的统计模型。
它考虑的不是变量之间的因果关系,而是重点考察变量在时间方面的发展变化规律,并为之建立数学模型。
时间序列分析的方法可以分为两大类:Time domain和Frequency domain。
前者将时间序列看成是过去一些点的函数,或者认为序列具有时间系统变化的趋势,它可以用不多的参数来加以描述,或者说可以通过差分、周期等还原成随机序列。
后者则认为时间序列是由数个正弦波成分叠加而成,当序列的确来自一些周期函数集合时,该方法特别有用。
不同的专业领域习惯用不同的方法:经济学习惯用Time domain,而电力工程专家则对Frequency domain更感兴趣。
下面讲述的都是Time domain由于时间序列模型的复杂性,它在spss中横跨了数据整理、统计分析和绘图三大部分,具体来说是:✧预处理模块:包括用于填充序列缺失值的Transform | replace Missing Values过程,建立时间变量的Data | Define dates过程和将序列平稳化的Transform | Create TimeSeries过程。
✧图形化观察/分析:时间序列在分析中高度依赖图形。
Spss为其提供了特有的观察工具:序列图(Sequence Chart)、自相关/偏自相关图(Autocorrelation Function,ACF & Autocorrelation Function,PACF)、交叉相关图(Crosscorrelation Function,CCF)、周期图(Periodogram)和谱密度图(Spectral Chart)。
用SPSS软件做时间序列分析用SPSS软件做时间序列分析,有某公司2002年一季度到2010年二季度的34个税后利润数据,要求预测出该公司2010年三季度和四季度的税后利润。
要求:1.画出序列趋势图2.绘制出自相关图和偏自相关图3.确定参数和模型4.给出预测值观测值序列图2税后盈利自相关图序列:税后盈利滞后自相关标准误差aBox-Ljung 统计量值df Sig.b1 .306 .164 3.482 1 .0622 .198 .162 4.987 2 .0833 .185 .159 6.340 3 .0964 .542 .157 18.342 4 .0015 .084 .154 18.641 5 .0026 .067 .151 18.836 6 .0047 .094 .149 19.239 7 .0078 .458 .146 29.093 8 .0009 .041 .143 29.176 9 .00110 .016 .140 29.189 10 .00111 .012 .137 29.197 11 .00212 .236 .134 32.308 12 .00113 -.092 .131 32.806 13 .00214 -.094 .128 33.345 14 .00315 -.079 .125 33.745 15 .00416 .106 .121 34.510 16 .005a. 假定的基础过程是独立性(白噪音)。
b. 基于渐近卡方近似。
偏自相关序列:税后盈利滞后偏自相关标准误差1 .306 .1712 .115 .1713 .107 .1714 .503 .1715 -.279 .1716 -.010 .1717 .046 .1718 .268 .1719 -.130 .17110 -.054 .17111 -.053 .17112 -.081 .17113 -.040 .17114 -.051 .17115 -.027 .17116 -.062 .1713、确定参数和模型时间序列建模程序模型描述模型类型模型 ID 税后利润模型_1 ARIMA(0,1,0)(0,1,0) 模型摘要模型统计量模型预测变量数模型拟合统计量Ljung-Box Q(18)离群值数平稳的 R 方统计量DF Sig.税后利润-模型_1 0 5.502E-17 17.688 18 .476 04、给出预测值2010年第三季度 139621.02万元2010年第四季度170144.55万元剔除季节成分后,平滑处理及剔除循环波动因素的序列图SEASON、MOD_6、MUL、EQU、4 中税后利润的季节性调整序列自相关图序列:SEASON、MOD_6、MUL、EQU、4 中税后利润的季节性调整序列滞后自相关标准误差aBox-Ljung 统计量值df Sig.b1 .728 .164 19.633 1 .0002 .450 .162 27.383 2 .0003 .310 .159 31.169 3 .0004 .207 .157 32.911 4 .0005 .219 .154 34.941 5 .0006 .241 .151 37.484 6 .0007 .243 .149 40.168 7 .0008 .226 .146 42.571 8 .0009 .183 .143 44.213 9 .00010 .162 .140 45.551 10 .00011 .093 .137 46.012 11 .00012 .006 .134 46.015 12 .00013 -.047 .131 46.145 13 .00014 -.021 .128 46.172 14 .00015 -.022 .125 46.204 15 .00016 -.036 .121 46.294 16 .000a. 假定的基础过程是独立性(白噪音)。
时间序列分析预测——1961年至2008国民生产总值季度指标本文根据网上找的1961年至2008国民生产总值,利用SPSS软件对其进行一定的分析,得出一些结论和图像,进一步得到相关的指标。
一、基本概念在实际中的数据变量往往是受到大量随机因素的综合影响,曾现很强的随机性,因此这类变量关系不能用一个简单的函数来精确描述。
对于本文的数据问题,由于这类数据是由某一现象在不同时刻的状态所形成,通俗地讲,是某个数量指标在不同时间点上的数值,按照时间的先后顺序排列而成的数列,当其受到各种随机因素影响,从而表现出某种随机性。
时间序列数据的特点是按一定顺序排列,序列中的数据依赖于时间,其取值依赖于时间的变化,时间序列研究的系统是历史行为的客观记录,它包含了系统的结构特征及其运行规律。
本文时间序列分析的主要任务是:1、根据观察数据的特点为数据建立尽可能合理的统计模型。
2、利用模型的统计特性去解释数据来源系统的统计规律,以期达到预测或控制的目的。
这类模型的建模对象具有动态性(记忆性),即相邻观察值具有很强的依赖性,从统计的观点看,是指系统的现在行为与其历史的相关性。
下面就1961年至2008国民生产总值季度指标进行分析(不考虑数据中还包含的第一产业、第二产业和第三产业的GDP指标,因为与GDP总指标分析类同)。
在spss中的输入结果为:时间年限美国GDP1,961.00 5,296.001,961.00 5,483.001,962.00 5,897.001,963.00 6,222.001,964.00 6,686.001,965.00 7,244.001,966.00 7,928.001,967.00 8,378.001,968.00 9,159.001,969.00 9,905.001,970.00 10,447.001,971.00 11,344.001,972.00 12,464.001,973.00 13,949.001,974.00 15,150.001,975.00 16,507.001,976.00 18,414.001,977.00 20,504.001,978.00 23,153.001,979.00 25,945.001,980.00 28,225.001,981.00 31,598.001,982.00 32,897.001,983.00 35,747.001,984.00 39,658.001,985.00 42,440.001,986.00 44,777.001,987.00 47,540.001,988.00 51,238.001,989.00 55,081.001,990.00 58,350.001,991.00 60,220.001,992.00 63,714.001,993.00 66,985.001,994.00 71,092.001,995.00 74,444.001,996.00 78,701.001,997.00 83,558.001,998.00 88,100.001,999.00 93,817.002,000.00 99,898.002,001.00 103,381.002,002.00 106,914.002,003.00 112,108.002,004.00 119,590.002,005.00 127,355.002,006.00 134,712.002,007.00 141,933.002,008.00 145,833.00注:单位:万亿美元,数据表示一年中截止该季度时的国民生产总值。
《一周总结,底稿供参考》我们通过案例来说明:假设我们拿到一个时间序列数据集:某男装生产线销售额。
一个产品分类销售公司会根据过去10 年的销售数据来预测其男装生产线的月销售情况。
现在我们得到了10年120个历史销售数据,理论上讲,历史数据越多预测越稳定,一般也要24个历史数据才行!大家看到,原则上讲数据中没有时间变量,实际上也不需要时间变量,但你必须知道时间的起点和时间间隔。
当我们现在预测方法创建模型时,记住:一定要先定义数据的时间序列和标记!这时候你要决定你的时间序列数据的开始时间,时间间隔,周期!在我们这个案例中,你要决定季度是否是你考虑周期性或季节性的影响因素,软件能够侦测到你的数据的季节性变化因子。
定义了时间序列的时间标记后,数据集自动生成四个新的变量:YEAR、QUARTER、MONTH 和DATE(时间标签)。
接下来:为了帮我们找到适当的模型,最好先绘制时间序列。
时间序列的可视化检查通常可以很好地指导并帮助我们进行选择。
另外,我们需要弄清以下几点:•此序列是否存在整体趋势?如果是,趋势是显示持续存在还是显示将随时间而消逝?•此序列是否显示季节变化?如果是,那么这种季节的波动是随时间而加剧还是持续稳定存在?这时候我们就可以看到时间序列图了!我们看到:此序列显示整体上升趋势,即序列值随时间而增加。
上升趋势似乎将持续,即为线性趋势。
此序列还有一个明显的季节特征,即年度高点在十二月。
季节变化显示随上升序列而增长的趋势,表明是乘法季节模型而不是加法季节模型。
此时,我们对时间序列的特征有了大致的了解,便可以开始尝试构建预测模型。
时间序列预测模型的建立是一个不断尝试和选择的过程。
spss提供了三大类预测方法:1-专家建模器,2-指数平滑法,3-ARIMA指数平滑法指数平滑法有助于预测存在趋势和/或季节的序列,此处数据同时体现上述两种特征。
创建最适当的指数平滑模型包括确定模型类型(此模型是否需要包含趋势和/或季节),然后获取最适合选定模型的参数。
第四章时间序列分析由于反映社会经济现象的大多数数据是按照时间顺序记录的,所以时间序列分析是研究社会经济现象的指标随时间变化的统计规律性的统计方法。
.为了研究事物在不同时间的发展状况,就要分析其随时间的推移的发展趋势,预测事物在未来时间的数量变化。
因此学习时间序列分析方法是非常必要的。
本章主要内容:1. 时间序列的线图,自相关图和偏自关系图;2. SPSS 软件的时间序列的分析方法−季节变动分析。
§4.1 实验准备工作§4.1.1 根据时间数据定义时间序列对于一组示定义时间的时间序列数据,可以通过数据窗口的Date菜单操作,得到相应时间的时间序列。
定义时间序列的具体操作方法是:将数据按时间顺序排列,然后单击Date →Define Dates打开Define Dates对话框,如图4.1所示。
从左框中选择合适的时间表示方法,并且在右边时间框内定义起始点后点击OK,可以在数据库中增加时间数列。
图4.1 产生时间序列对话框§4.1.2 绘制时间序列线图和自相关图一、线图线图用来反映时间序列随时间的推移的变化趋势和变化规律。
下面通过例题说明线图的制作。
例题4.1:表4.1中显示的是某地1979至1982年度的汗衫背心的零售量数据。
试根据这些的数据对汗衫背心零售量进行季节分析。
(参考文献[2])解:根据表4.1的数据,建立数据文件SY-11(零售量),并对数据定义相应的时间值,使数据成为时间序列。
为了分析时间序列,需要先绘制线图直观地反映时间序列的变化趋势和变化规律。
具体操作如下:1. 在数据编辑窗口单击Graphs→Line,打开Line Charts对话框如图4.2.。
从中选择Simple单线图,从Date in Chart Are 栏中选择Values of individual cases,即输出的线图中横坐标显示变量中按照时间顺序排列的个体序列号,纵坐标显示时间序列的变量数据。
《统计软件实验报告》SPSS软件的上机实践应用时间序列分析数学与统计学学院一、实验内容:时间序列是指一个依时间顺序做成的观察资料的集合。
时间序列分析过程中最常用的方法是:指数平滑、自回归、综合移动平均及季节分解。
本次实验研究就业理论中的就业人口总量问题。
但人口经济的理论和实践表明,就业总量往往受到许多因素的制约,这些因素之间有着错综复杂的联系,因此,运用结构性的因果模型分析和预测就业总量往往是比较困难的。
时间序列分析中的自回归求积分移动平均法 (ARIMA )则是一个较好的选择。
对于时间序列的短期预测来说,随机时序ARIMA 是一种精度较高的模型。
我们已辽宁省历年( 1969-2005)从业人员人数为数据基础建立一个就业总量的预测时间序列模型,通过SPSS建立模型并用此模型来预测就业总量的未来发展趋势。
二、实验目的:1.准确理解时间序列分析的方法原理2.学会实用SPSS建立时间序列变量3.学会使用SPSS绘制时间序列图以反应时间序列的直观特征。
4.掌握时间序列模型的平稳化方法。
5.掌握时间序列模型的定阶方法。
6.学会使用SPSS建立时间序列模型与短期预测。
7.培养运用时间序列分析方法解决身边实际问题的能力。
三、实验分析:总体分析:先对数据进行必要的预处理和观察,直到它变成稳态后再用SPSS对数据进行分析。
数据的预处理阶段,将它分为三个步骤:首先,对有缺失值的数据进行修补,其次将数据资料定义为相应的时间序列,最后对时间序列数据的平稳性进行计算观察。
数据分析和建模阶段:根据时间序列的特征和分析的要求,选择恰当的模型进行数据建模和分析。
四、实验步骤:SPSS的数据准备包括数据文件的建立、时间定义和数据期间的指定。
SPSS的时间定义功能用来将数据编辑窗口中的一个或多个变量指定为时间序列变量,并给它们赋予相应的时间标志,具体操作步骤是:1.选择菜单:Date f Define Dates出现窗口:单击【ok(确认)】按钮,此时完成时间的定义,SPSS将在当前数据编辑窗口中自动生成标志时间的变量。