《算法设计与分析基础(第3版)》部分习题答案
- 格式:docx
- 大小:206.44 KB
- 文档页数:7


算法设计与分析第三版第四章课后习题答案4.1 线性时间选择问题习题4.1问题描述:给定一个长度为n的无序数组A和一个整数k,设计一个算法,找出数组A中第k小的元素。
算法思路:本题可以使用快速选择算法来解决。
快速选择算法是基于快速排序算法的思想,通过递归地划分数组来找到第k小的元素。
具体步骤如下: 1. 选择数组A的一个随机元素x作为枢纽元。
2. 使用x将数组划分为两个子数组A1和A2,其中A1中的元素小于等于x,A2中的元素大于x。
3. 如果k等于A1的长度,那么x就是第k小的元素,返回x。
4. 如果k小于A1的长度,那么第k小的元素在A1中,递归地在A1中寻找第k小的元素。
5. 如果k大于A1的长度,那么第k小的元素在A2中,递归地在A2中寻找第k-A1的长度小的元素。
6. 递归地重复上述步骤,直到找到第k小的元素。
算法实现:public class LinearTimeSelection {public static int select(int[] A, int k) { return selectHelper(A, 0, A.length - 1, k);}private static int selectHelper(int[] A, int left, int right, int k) {if (left == right) {return A[left];}int pivotIndex = partition(A, left, righ t);int length = pivotIndex - left + 1;if (k == length) {return A[pivotIndex];} else if (k < length) {return selectHelper(A, left, pivotInd ex - 1, k);} else {return selectHelper(A, pivotIndex + 1, right, k - length);}}private static int partition(int[] A, int lef t, int right) {int pivotIndex = left + (right - left) / 2;int pivotValue = A[pivotIndex];int i = left;int j = right;while (i <= j) {while (A[i] < pivotValue) {i++;}while (A[j] > pivotValue) {j--;}if (i <= j) {swap(A, i, j);i++;j--;}}return i - 1;}private static void swap(int[] A, int i, int j) {int temp = A[i];A[i] = A[j];A[j] = temp;}}算法分析:快速选择算法的平均复杂度为O(n),最坏情况下的复杂度为O(n^2)。


算法设计与分析习题解答第一章作业1.证明下列Ο、Ω和Θ的性质1)f=Ο(g)当且仅当g=Ω(f)证明:充分性。
若f=Ο(g),则必然存在常数c1>0和n0,使得?n≥n0,有f≤c1*g(n)。
由于c1≠0,故g(n) ≥ 1/ c1 *f(n),故g=Ω(f)。
必要性。
同理,若g=Ω(f),则必然存在c2>0和n0,使得?n≥n0,有g(n) ≥ c2 *f(n).由于c2≠0,故f(n) ≤ 1/ c2*f(n),故f=Ο(g)。
2)若f=Θ(g)则g=Θ(f)证明:若f=Θ(g),则必然存在常数c1>0,c2>0和n0,使得?n≥n0,有c1*g(n) ≤f(n) ≤ c2*g(n)。
由于c1≠0,c2≠0,f(n) ≥c1*g(n)可得g(n) ≤ 1/c1*f(n),同时,f(n) ≤c2*g(n),有g(n) ≥ 1/c2*f(n),即1/c2*f(n) ≤g(n) ≤ 1/c1*f(n),故g=Θ(f)。
3)Ο(f+g)= Ο(max(f,g)),对于Ω和Θ同样成立。
证明:设F(n)= Ο(f+g),则存在c1>0,和n1,使得?n≥n1,有F(n) ≤ c1 (f(n)+g(n))= c1 f(n) + c1g(n)≤ c1*max{f,g}+ c1*max{f,g}=2 c1*max{f,g}所以,F(n)=Ο(max(f,g)),即Ο(f+g)= Ο(max(f,g))对于Ω和Θ同理证明可以成立。
4)log(n!)= Θ(nlogn)证明:由于log(n!)=∑=ni i 1log ≤∑=ni n 1log =nlogn ,所以可得log(n!)= Ο(nlogn)。
由于对所有的偶数n 有,log(n!)= ∑=ni i 1log ≥∑=nn i i 2/log ≥∑=nn i n 2/2/log ≥(n/2)log(n/2)=(nlogn)/2-n/2。

习题5..证明等式gcd(m,n)=gcd(n,m mod n)对每一对正整数m,n都成立.Hint:根据除法的定义不难证明:如果d整除u和v, 那么d一定能整除u±v;如果d整除u,那么d也能够整除u的任何整数倍ku.对于任意一对正整数m,n,若d能整除m和n,那么d一定能整除n和r=m mod n=m-qn;显然,若d 能整除n和r,也一定能整除m=r+qn和n。
数对(m,n)和(n,r)具有相同的公约数的有限非空集,其中也包括了最大公约数。
故gcd(m,n)=gcd(n,r)6.对于第一个数小于第二个数的一对数字,欧几里得算法将会如何处理?该算法在处理这种输入的过程中,上述情况最多会发生几次?Hint:对于任何形如0<=m<n的一对数字,Euclid算法在第一次叠代时交换m和n, 即gcd(m,n)=gcd(n,m)并且这种交换处理只发生一次..对于所有1≤m,n≤10的输入, Euclid算法最少要做几次除法?(1次)b. 对于所有1≤m,n≤10的输入, Euclid算法最多要做几次除法?(5次)gcd(5,8)习题1.(农夫过河)P—农夫 W—狼 G—山羊 C—白菜2.(过桥问题)1,2,5,10---分别代表4个人, f—手电筒4. 对于任意实系数a,b,c, 某个算法能求方程ax^2+bx+c=0的实根,写出上述算法的伪代码(可以假设sqrt(x)是求平方根的函数)算法Quadratic(a,b,c)描述将十进制整数表达为二进制整数的标准算法a.用文字描述b.用伪代码描述解答:a.将十进制整数转换为二进制整数的算法输入:一个正整数n输出:正整数n相应的二进制数第一步:用n除以2,余数赋给Ki(i=0,1,2...),商赋给n第二步:如果n=0,则到第三步,否则重复第一步第三步:将Ki按照i从高到低的顺序输出b.伪代码算法 DectoBin(n).n]中i=1while n!=0 do {Bin[i]=n%2;n=(int)n/2;i++;}while i!=0 do{print Bin[i];i--;}9.考虑下面这个算法,它求的是数组中大小相差最小的两个元素的差.(算法略)对这个算法做尽可能多的改进.算法 MinDistance(A[0..n-1])n-1]a.应用该算法对列表”60,35,81,98,14,47”排序b.该算法稳定吗?c.该算法在位吗?解:a. 该算法对列表”60,35,81,98,14,47”排序的过程如下所示:b.该算法不稳定.比如对列表”2,2*”排序c.该算法不在位.额外空间for S and Count[]4.(古老的七桥问题)习题1.请分别描述一下应该如何实现下列对数组的操作,使得操作时间不依赖数组的长度.a.删除数组的第i个元素(1<=i<=n)b.删除有序数组的第i个元素(依然有序)hints:a. Replace the ith element with the last element and decrease the array size of 1b. Replace the ith element with a special symbol that cannot be a value of the array’s element., 0 for an array of positive numbers ) to mark the ith position is empty. (“lazy deletion”)习题1欧几里得算法的时间复杂度欧几里得算法, 又称辗转相除法, 用于求两个自然数的最大公约数. 算法的思想很简单, 基于下面的数论等式gcd(a, b) = gcd(b, a mod b)其中gcd(a, b)表示a和b的最大公约数, mod是模运算, 即求a除以b的余数. 算法如下:输入: 两个整数a, b输出: a和b的最大公约数function gcd(a, b:integer):integer;if b=0 return a;else return gcd(b, a mod b);end function欧几里得算法是最古老而经典的算法, 理解和掌握这一算法并不难, 但要分析它的时间复杂度却并不容易. 我们先不考虑模运算本身的时间复杂度(算术运算的时间复杂度在Knuth的TAOCP中有详细的讨论), 我们只考虑这样的问题: 欧几里得算法在最坏情况下所需的模运算次数和输入的a和b的大小有怎样的关系?我们不妨设a>b>=1(若a<b我们只需多做一次模运算, 若b=0或a=b模运算的次数分别为0和1), 构造数列{un}: u0=a, u1=b, uk=uk-2 mod uk-1(k>=2), 显然, 若算法需要n次模运算, 则有un=gcd(a, b), un+1=0. 我们比较数列{un}和菲波那契数列{Fn}, F0=1<=un, F1=1<=un-1, 又因为由uk mod uk+1=uk+2, 可得uk>=uk+1+uk+2, 由数学归纳法容易得到uk>=Fn-k, 于是得到a=u0>=Fn, b=u0>=Fn-1. 也就是说如果欧几里得算法需要做n次模运算, 则b必定不小于Fn-1. 换句话说, 若 b<Fn-1, 则算法所需模运算的次数必定小于n. 根据菲波那契数列的性质, 有Fn-1>n/sqrt(5), 即b>n/sqrt(5), 所以模运算的次数为O(lgb)---以b为底数 = O(lg(2)b)---以2为底数,输入规模也可以看作是b的bit位数。

Program算法设计与分析基础中文版答案习题1.15..证明等式gcd(m,n)=gcd(n,m mod n)对每一对正整数m,n都成立.Hint:根据除法的定义不难证明:●如果d整除u和v, 那么d一定能整除u±v;●如果d整除u,那么d也能够整除u的任何整数倍ku.对于任意一对正整数m,n,若d能整除m和n,那么d一定能整除n和r=m mod n=m-qn;显然,若d能整除n和r,也一定能整除m=r+qn和n。
数对(m,n)和(n,r)具有相同的公约数的有限非空集,其中也包括了最大公约数。
故gcd(m,n)=gcd(n,r)6.对于第一个数小于第二个数的一对数字,欧几里得算法将会如何处理?该算法在处理这种输入的过程中,上述情况最多会发生几次?Hint:对于任何形如0<=m<n的一对数字,Euclid算法在第一次叠代时交换m和n, 即gcd(m,n)=gcd(n,m)并且这种交换处理只发生一次.7.a.对于所有1≤m,n≤10的输入, Euclid算法最少要做几次除法?(1次)b. 对于所有1≤m,n≤10的输入, Euclid算法最多要做几次除法?(5次)gcd(5,8)习题1.21.(农夫过河)P—农夫W—狼G—山羊C—白菜2.(过桥问题)1,2,5,10---分别代表4个人, f—手电筒4. 对于任意实系数a,b,c, 某个算法能求方程ax^2+bx+c=0的实根,写出上述算法的伪代码(可以假设sqrt(x)是求平方根的函数)算法Quadratic(a,b,c)//求方程ax^2+bx+c=0的实根的算法//输入:实系数a,b,c//输出:实根或者无解信息If a≠0D←b*b-4*a*cIf D>0temp←2*ax1←(-b+sqrt(D))/tempx2←(-b-sqrt(D))/tempreturn x1,x2else if D=0 return –b/(2*a)else return “no real roots”else //a=0if b≠0 return –c/belse //a=b=0if c=0 return “no real numbers”else return “no real roots”5.描述将十进制整数表达为二进制整数的标准算法a.用文字描述b.用伪代码描述解答:a.将十进制整数转换为二进制整数的算法输入:一个正整数n输出:正整数n相应的二进制数第一步:用n除以2,余数赋给Ki(i=0,1,2...),商赋给n第二步:如果n=0,则到第三步,否则重复第一步第三步:将Ki按照i从高到低的顺序输出b.伪代码算法DectoBin(n)//将十进制整数n转换为二进制整数的算法//输入:正整数n//输出:该正整数相应的二进制数,该数存放于数组Bin[1...n]中i=1while n!=0 do {Bin[i]=n%2;n=(int)n/2;i++;}while i!=0 do{print Bin[i];i--;}9.考虑下面这个算法,它求的是数组中大小相差最小的两个元素的差.(算法略) 对这个算法做尽可能多的改进.算法MinDistance(A[0..n-1])//输入:数组A[0..n-1]//输出:the smallest distance d between two of its elements习题1.31.考虑这样一个排序算法,该算法对于待排序的数组中的每一个元素,计算比它小的元素个数,然后利用这个信息,将各个元素放到有序数组的相应位置上去.a.应用该算法对列表”60,35,81,98,14,47”排序b.该算法稳定吗?c.该算法在位吗?解:a. 该算法对列表”60,35,81,98,14,47”排序的过程如下所示:b.该算法不稳定.比如对列表”2,2*”排序c.该算法不在位.额外空间for S and Count[] 4.(古老的七桥问题)习题1.41.请分别描述一下应该如何实现下列对数组的操作,使得操作时间不依赖数组的长度. a.删除数组的第i 个元素(1<=i<=n)b.删除有序数组的第i 个元素(依然有序) hints:a. Replace the i th element with the last element and decrease the array size of 1b. Replace the ith element with a special symbol that cannot be a value of the array ’s element(e.g., 0 for an array of positive numbers ) to mark the i th position is empty. (“lazy deletion ”)第2章 习题2.17.对下列断言进行证明:(如果是错误的,请举例) a. 如果t(n )∈O(g(n),则g(n)∈Ω(t(n)) b.α>0时,Θ(αg(n))= Θ(g(n)) 解:a. 这个断言是正确的。




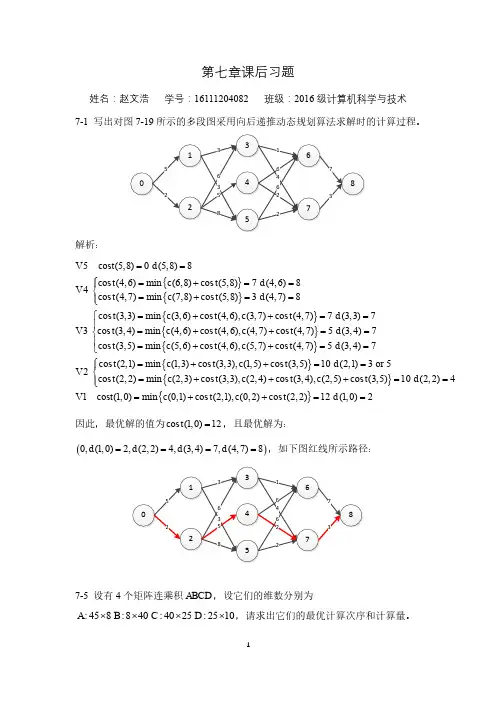
第3章作业解答设有4个矩阵连乘积ABCD ,设它们的维数分别为A:45×8,B:8×40,C:40×25,D:25×10,请求出它们的最优计算次序及对应的最少计算量。
解:设A 1=A, A 2=B, A 3=C, A 4=Dp 0=45,p 1=8,p 2=40,p 3=25,p 4=10 ,用两个二维数组m 和s 记录中间结果,其中,m[i][j]记录矩阵连乘积A[i:j]的最少计算量,s[i][j]记录A[i:j]的最优断开位置。
由动态规划思想,得递归式为:⎪⎩⎪⎨⎧<+++==-<≤j i p p p j k m k i m j i j i m j k i }],1[],[{min 0],[1jk i 其中,k 的取值有j-i 种可能:i,i+1,...,j-1. 计算过程如下: (1) m[i][i]=0, i=1,2,3,4 (2) 求m[i][i+1], i=1,2,3m[1][2]= p 0×p 1×p 2=45×8×40=14400 s[1][2]=1 m[2][3]= p 1×p 2×p 3=8×40×25=8000 s[2][3]=2 m[3][4]= p 2×p 3×p 4=40×25×10=10000 s[3][4]=3 (3) 求m[i][i+2], i=1,2m[1][3]=min{m[1][1]+m[2][3]+p 0×p 1×p 3, m[1][2]+m[3][3]+p 0×p 2×p 3 } =min{8000+45×8×25,14400+45×40×25} =min{17000, 59400} =17000 s[1][3]=1m[2][4]=min{m[2][2]+m[3][4]+p1×p2×p4, m[2][3]+m[4][4]+p1×p3×p4 }=min{10000+8×40×10,8000+8×25×10}=min{13200, 10000} =10000s[2][4]=3(4) 求m[i][i+3], i=1m[1][4]=min{m[1][1]+m[2][4]+p0×p1×p4 ,m[1][2]+m[3][4]+p0×p2×p4 ,m[1][3]+m[4][4]+p0×p3×p4 }=min{10000+45×8×10, 14400+10000+45×40×10, 17000+45×25×10 }=min{13600, 42400, 28250} =13600s[1][4]=1根据以上结果可得数组m, s如下:m[1][4]即A[1:4]的最少计算量,也即ABCD连乘积的最少计算量为13600。
作业一学号:_____ 姓名:_____说明:1、正文用宋体小四号,1.5倍行距。
2、报告中的图片、表格中的文字均用宋体五号,单倍行距。
3、图片、表格均需要有图片编号和标题,均用宋体五号加粗。
4、参考文献用宋体、五号、单倍行距,请参照参考文献格式国家标准(GB/T 7714-2005)。
5、公式请使用公式编辑器。
P144.用伪代码写一个算法来求方程ax2+bx+c=0的实根,a,b,c 是任意实系数。
(可以假设sqrt(x)是求平方根的函数。
)算法:Equate(a,b,c)//实现二元一次方程求解实数根//输入:任意系数a,b,c//输出:方程的实数根x1,x2或无解If a≠0p←b2−4acIf p>0x1←−b+sqrt(p)2ax2←−b−sqrt(p)2areturn x1,x2else if p=0return −b2aelsereturn “no real roots”elseif b≠0return −cbelseif c≠0return “no real numbers”elsereturn “no real roots”5.写出将十进制正整数转换为二进制整数的标准算法。
a.用文字描述。
b.用伪代码描述。
a.解:输入:一个正整数n输出:正整数n相应的二进制数第一步:用n 除以2,余数赋给K[i](i=0,1,2...),商赋给n第二步:如果n=0 ,则到第三步,否则重复第一步第三步:将K[i]按照i从高到低的顺序输出b.解:算法:DecToBin(n)//实现正整数十进制转二进制//输入:一个正整数n//输出:正整数n对应的二进制数组K[0..i]i ←1while n≠0 doK[i]←n%2n←(int)n/2i ++while i≠0doprint K[i]i - -p462.请用O,Ω 和θ的非正式定义来判断下列断言是真还是假。
a. n(n+1)/2∈O(n3)b. n(n+1)/2∈O(n2)c. n(n+1)/2∈θ(n3)d. n(n+1)/2∈Ω(n)解:断言为真:a,b,d断言为假:cP535.考虑下面的算法。
作业一
学号:______ 姓名:________
P135
2.
a.为一个分治算法编写伪代码,该算法同时求出一个n元素数组的最大元素和
最小元素的值。
解:算法:EXTREMUM(A[m..n],EXTREMUM_MAX, EXTREMUM_MIN)
//递归调用EXTREMUM函数来找出数组A[m..n]的最大元素和
最小元素。
//输入:数值数组A[m..n]
//输出:最大值EXTREMUM_MAX和最小值EXTREMUM_MIN
if(m=n) //只有一个元素
EXTREMUM_MAX←A[m];
EXTREMUM_MIN←A[n];
else
if n−m=1 //有两个元素
if A[m]≤A[n]
EXTREMUM_MAX←A[n]; EXTREMUM_MIN←A[m]; else
EXTREMUM_MAX←A[m]; EXTREMUM_MIN←A[n]; else
EXTREMUM(A[m..(m+n)/2],EXTREMUM_MAX_01,
EXTREMUM_MIN_01);
EXTREMUM(A[(m+n)/2..n],EXTREMUM_MAX_02,
EXTREMUM_MIN_02);
if EXTREMUM_MAX_01< EXTREMUM_MAX_02
EXTREMUM_MAX = EXTREMUM_MAX_02;
If EXTREMUM_MIN_02< EXTREMUM_MIN_01
EXTREMUM_MIN = EXTREMUM_MIN_02;
b. 假设n=2k,为该算法的键值比较次数建立递推关系式并求解。
解:C(n)=C(2k)=2C(2k−1)+2
=2[2C(2k−2)+2]+2
=22[2C(2k−3)+2]+22+2=2k−1C(2)+2k−1+2k−2+...+2
=3n
2
−2
c.将该算法与解决同样问题的蛮力法做一个比较
蛮力法时间时间复杂度为2n-2,分治算法的为3n/2-2,虽然都属于Θ(n)级别,但是分治算法速度要比蛮力算法快。
5.1.3
a.为一个分治算法编写伪代码,该算法用来计算指数函数a n的值,其中a>0, n
是一个正整数。
//该算法使用分治法来计算a n
Pow(a,n)
If n = 1
return a
else
p←pow(a,n/2);
If n mod 2 = 1
return p*p*a;
else
return p*p;
b.建立该算法执行的乘法次数的递推关系式并求解
C(n)=C(n
2
)+2,C(1)=0
C(n)=C(n
2
)+2=C(
n
4
)+2+2=C(
n
n
)+2∗log2n=2∗log2n
c.将该算法与解决同样问题的蛮力法做一个比较
蛮力法时间复杂度为n,分治法为2∗log2n,分治法速度明显要高于蛮力法。
5.2
3.举例说明快速排序不是一个稳定的排序算法
解:从小到大的快速排序:问题中给出的数据为从大到小,每次选择第一个数作中间值。
例:数据9,7,6,7,10,7,7,3,2,1,当选择第一个数我中间操作数时,9和第 4个7交换,元素7的稳定性就乱了。
6.4
11.任选一种语言实现三种高级排序算法——合并排序,快速排序和堆排序,然
后针对规模为n=103,104,105,106的数组研究它们的性能。
对于每种规模,再考虑以下三种情况:
a.[1..n]区间内的整数所构成的随机生成文件。
b.整数1,2,…,n的升序文件。
c.整数n,n−1,…,1的降序文件。
合并排序:
图1.1
合并排序算法效率分析:
合并排序算法时间复杂度为O(NLogN),运行效率比较高,是一个稳定的排序算法。
N=106时,时间也在1s左右。
快速排序:
图2.1 1000量级
图2.2 10000量级
图2.3 100000量级
图2.4 1000000量级
快速排序算法效率分析。
对于数据规模n<=104,程序能在1S内运行出来,对于n=105程序运行随机数据能在1S内运行出来,如果数据具有一定的顺序,则运行速度大大下降,对于n=106的数据,程序运行不出来。
对于快排,平均复杂度为O(NLogN),最坏情况为O(N2)。
堆排序。
运行结果:
堆排序算法复杂度分析
对N个元素建堆的时间复杂度为O(N),删除堆顶元素的时间复杂度为
O(logN),尽管随着元素的不断删除,堆的调度越来越小,但是总的而言,删除堆所有元素的时间复杂度为O(NlogN)
故堆排序的时间复杂度为O(NlogN),空间复杂度为O(1)
其实,堆排序是一个非常稳定的算法,最坏和平均情况下的时间复杂度都为
O(NlogN)
此外,对于堆排序而言,数据的初始顺序对它的复杂度没有影响。
不管数组初始时就是有序的还是逆序的,它都会先建堆,变成了堆序的性质。