教育统计学与SPSS-名解总结
- 格式:doc
- 大小:64.50 KB
- 文档页数:28


第一章导论〔阅览前必读:书上每个章节后的名解我全都列出来了,黑色字体的都是书上原文,量多,但有些不重要的名解没必要背,你挑着背不要被吓到。
绿色是章节题目,红色的就是我的一些说明、补充、吐槽,一个人打字很无聊啊有木有!一直自言自语啊有木有!并非书上的名词解释,看看就好,可删。
这段紫色的也删了哈。
接下来……正文,走你!〕统计学〔statistics〕:即研究统计原理与方法的科学。
教育统计学〔educational statistics〕:是专门研究如何搜集、整理、分析在心理和教育方面有实验或调查所获得的数字资料,如何根据这些资料所传递的信息,进展数学推论,找出客观规律的一门学科。
简言之,教育统计学是运用统计学的一般原理和方法研究教育科学领域数量关系的一门科学。
描述统计〔descriptiive statistics〕:是实验或调查所获得的数据加以整理〔如制表、绘图〕,并计算其各种代表量数〔如集中量数、差异量数、相关量数等〕,其根本思想是平均。
Or:是研究如何整理心理与教育科学实验或调查得来的大量数据,描述一组数据的全貌,表达一件事物的性质的一种统计方法。
推断统计〔inferencial statistics〕:又称抽样统计,它是根据对局部个体进展观测所得到的信息,通过概括性的分析、论证,在一定可靠程度上去推测相应的团体。
Or:是研究如何通过局部数据所提供的信息,运用概率的理论进展分析论证,在一定可靠程度上推论总体或全局情形的统计方法。
这是统计学中的主要内容。
实验设计〔e*perimental statistics〕:是研究如何更加合理、有效的获得观测资料,如何更正确、更经济、更有效的到达实验目的,以提醒实验中各种变量关系的实验方案。
Or:实验者为了提醒实验中自变量与因变量的关系,在实验之前所制定的实验方案,称为实验设计。
他是研究如何科学地、经济地以及更有效地进展实验。
统计常态法则:从总体中随机抽取一局部个体所组成的样本,差不多可以保持总体的特征。


《统计分析与SPSS的应用(第五版)》课后练习答案第一章练习题答案1、SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、SPSS的数据集:SPSS运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
活动数据集:其中只有一个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进行分析。
4、SPSS的三种基本运行方式:完全窗口菜单方式、程序运行方式、混合运行方式。
完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
混合运行方式:是前两者的综合。
5、.sav是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPSS分析结果文件的扩展名.sps是语法窗口中的SPSS程序6、SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。


教育统计学第一章绪论一、什么是教育统计学:教育统计学是运用数理统计的原理和方法,研究教育问题的一门应用科学。
主要任务是研究如何搜集、整理、分析由教育调查和教育试验所获得的数字资料,并以此为依据,进行科学推断,揭示教育现象所蕴含的客观规律。
二、统计学的分类:描述统计推断统计理论统计应用统计描述统计:描述统计就是对已获得的数据进行整理、概括,显现其分布特征的统计方法.推断统计:根据样本所提供的信息,运用概率的理论进行分析、论证,在一定可靠程度上,对总体分布特征进行估计、推测,这种统计方法称为推断统计。
(内容:参数估计和假设检验目的:对总体特征作出推断)三、具有以下三个特性的现象,称为随机现象第一,一次试验有多种可能结果,其所有可能结果是已知的;第二,试验之前不能预料哪一种结果会出现;第三,在相同的条件下可以重复试验。
(延迟满足)四、样本容量(样本包含的个体数目大样本n>30小样本n<30五、参数和统计量参数(parameter)●描述总体特征的概括性数字度量,是研究者想要了解的总体的某种特征值。
●所关心的参数主要有总体均值(μ)、标准差(σ)、总体比例(π)等●总体参数通常用希腊字母表示统计量(statistic)●用来描述样本特征的概括性数字度量,它是根据样本数据计算出来的一些量,是样本的函数●所关心的样本统计量有样本均值(⎺x)、样本标准差(s)、样本比例(p)等●样本统计量通常用小写英文字母表示●参数与统计量的符号系统第二章数据的处理一、名义、顺序、等距、比率①名义变量:是指一事物与其他事物在属性、类别上不同。
1表示男,0表示女,但这里的1,0并不说明事物间差异的大小,只是分类的符号而已,即名称变量不说明事物之间差别的大小,作比较时,只能说明被比事物相同,还是不同顺序变量(ordinal variable)。
②顺序变量:是事物的某一属性的多少或大小按顺序排列起来的变量。
如教师按能力大小或成绩高低排列等级:1,2,3,……,这一系列数据表明“大于”某某,即第1高于第2,第2高于第3……,而相邻两个等级的间隔是不等距的,即1与2和2与3之间并不等距。

标准适用有关剖析一、两个变量的有关剖析:Bivariate1.有关系数的含义有关剖析是研究变量间亲密程度的一种常用统计方法。
有关系数是描绘有关关系强弱程度和方向的统计量,往常用 r 表示。
①有关系数的取值范围在 -1 和+1 之间,即:– 1≤ r ≤ 1 。
②计算结果,若 r为正,则表示两变量为正有关;若 r 为负,则表示两变量为负有关。
③有关系数 r 的数值越靠近于 1(– 1 或 +1),表示有关系数越强;越靠近于0,表示有关系数越弱。
假如r=1 或– 1,则表示两个现象完整直线性有关。
假如=0,则表示两个现象完整不有关(不是直线有关)。
④ r 0.3 ,称为轻微有关、 0.3 r 0.5 ,称为低度有关、0.5 r0.8 ,称为明显(中度)有关、0.8 r 1 ,称为高度有关⑤r 值很小,说明 X 与 Y 之间没有线性有关关系,但其实不意味着X 与 Y 之间没有其余关系,如很强的非线性关系。
⑥直线有关系数一般只合用与测定变量间的线性有关关系,若要权衡非线性有关时,一般应采纳有关指数R。
2.常用的简单有关系数(1)皮尔逊( Pearson)有关系数皮尔逊有关系数亦称积矩有关系数,1890 年由英国统计学家卡尔 ? 皮尔逊提出。
定距变量之间的有关关系丈量常用Pearson 系数法。
计算公式以下:nr( x i x )( y i y)i 1(1)n n( x i x) 2( y i y) 2i 1i 1(1)式是样本的有关系数。
计算皮尔逊有关系数的数据要求:变量都是服从正态散布,互相独立的连续数据;两个变量在散点图上有线性有关趋向;样本容量 n30 。
(2)斯皮尔曼( Spearman)等级有关系数Spearman有关系数又称秩有关系数,是用来测度两个定序数据之间的线性有关程度的指标。
当两组变量值以等级序次表示时,能够用斯皮尔曼等级有关系数反应变量间的关系亲密程度。
它是依据数据的秩而不是原始数据来计算有关系数的,其计算过程包含:对连续数据的排秩、对失散数据的排序,利用每对数据等级的差额及差额平方,经过公式计算获得有关系数。
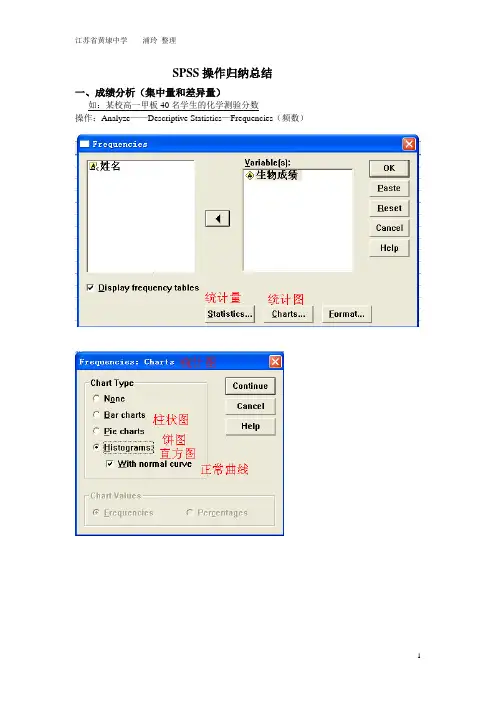
SPSS操作归纳总结一、成绩分析(集中量和差异量)如:某校高一甲板40名学生的化学测验分数操作:Analyze——Descriptive Statistics—Frequencies(频数)二、相关量1、积差相关系数如:40名学生的数学和化学成绩操作:Analyze——Correlate(相关)——BIvariate(双变量)结论:在0.01水平上学生的化学成绩与生物成绩相关,也就是说我们有99%的把握说学生的化学成绩与生物成绩密切相关。
分析:若Sig.(2-tailed)的值<0.05,则相关程度密切若Sig.(2-tailed)的值<0.01,则相关程度非常密切若Sig.(2-tailed)的值>0.05,则相关程度不密切2、点双列相关系数如:求若干名考生的生物成绩与性别之间的相关系数,并判断他们之间有无相关关系?操作:Analyze——Correlate(相关)——BIvariate(双变量)分析:Sig.(2-tailed)的值>0.05,则相关程度不密切。
结论:在0.05水平上学生的生物成绩与性别无密切相关,也就是说我们没有95%的把握说学生的生物成绩与性别密切相关,或者说学生的生物成绩和性别无密切关系。
3、等级相关系数如:高考总分与生物等级、化学等级的相关操作:Analyze ——Correlate (相关)——BIvariate (双变量)注:相关系数为负值,说明为负相关,正值为正相关,而且绝对值越大,相关性越大。
该题中男表示为1,女表示为0,该结果为负值,说明女的成绩好,而男的成绩不好。
分析:Sig.(2-tailed)的值>0.05,则相关程度不密切。
结论:在0.05水平上学生的三科总分与物理等级无密切相关,也就是说我们没有95%的把握说学生的三科总分与物理等级密切相关,或者说学生的三科总分与物理等级无密切关系。
补充:“物理等级”转换成“等级数”操作:Transform——Recode——Into different variables三、考试质量的分析1、难度分析(P)Analyze——Descriptive Statistics—Frequencies结论:客观题的难度P ——直接看得分的valid percent主观题的难度P——mean 除以该题的总分值2、区分度分析(1)用相关系数法求试题的区分度某一题的得分与该生总分的相关程度作为该题的区分度。

spss统计的名词解释统计学在现代社会中起着重要的作用,它能够帮助我们理解和解释数据背后的现象和趋势。
SPSS(Statistical Package for the Social Sciences)统计软件则是一个强大而广泛使用的工具,它能够帮助研究人员进行数据分析和统计计算。
本文将解释一些与SPSS统计相关的重要名词,帮助读者更好地理解和使用这个软件。
一、数据预处理数据预处理是任何统计分析的重要步骤,它包括数据清洗、数据缺失的处理、异常值的检测和数据变换等。
在SPSS中,可以使用多种方法来进行数据预处理。
例如,数据清洗可以通过删除重复值、处理无效数据等方式实现。
对于缺失数据,可以通过插补(如均值插补或回归插补)或删除缺失值的方式进行处理。
当有异常值出现时,可以使用箱线图或离群值分析来检测和处理异常值。
另外,SPSS还提供了数据变换的功能,如对数变换、标准化等,以满足不同分析需求。
二、描述统计描述统计是对收集到的数据进行总结和描述的方法。
SPSS提供了众多描述统计的指标,包括均值、中位数、众数、标准差、方差、偏度和峰度等。
这些指标可以帮助我们了解数据的分布情况和集中趋势,从而更好地理解数据。
在SPSS中,我们可以使用“统计”菜单下的“描述统计”来生成这些统计量。
三、t检验t检验是一种常用的假设检验方法,用于比较两组样本均值是否存在显著差异。
SPSS提供了不同类型的t检验,包括独立样本t检验和配对样本t检验。
独立样本t检验用于独立的两组样本,而配对样本t检验用于配对的两组样本。
这些检验可以帮助研究人员判断两组样本是否具有显著差异。
四、方差分析方差分析是一种用于比较多个样本均值是否存在显著差异的方法。
它可以用于比较两个以上的样本组,以确定是否存在组间差异。
在SPSS中,我们可以使用“分析”菜单下的“方差分析”来进行此类分析。
方差分析还可以进行多因素的分析,以探索多个因素对于因变量的影响。
五、回归分析回归分析是用于研究自变量和因变量之间关系的一种统计方法。

学习SPSS在教育统计中的应用心得体会一、什么是SPSS?为什么要学习SPSS?新学期开始时,在信息化教育测量与评价的课程中第一次接触到SPSS这个软件,作为本科是计算机专业出身的我,当时只知道SPSS是一套统计软件,就是一套根据统计学原理所编写出来的统计分析软件,至于统计什么?分析什么?我一无所知,尤其是看到老师推荐的《SPSS在教育统计中的应用》这本书的时候,就简单的把它理解为用SPSS软件来统计、分析与教育相关的数据,最终得出想要的结论而已,而现在看来,我当初的想法未免有点简单与无知。
下面就来让我们了解一下SPSS。
SPSS软件是一组专业的、通用的统计软件包,同时它也是一个组合式软件包,兼有数据管理、统计分析、统计绘图和统计报表功能。
它广泛用于教育、心理、医学、市场、人口、保险等研究领域,也用于产品质量控制、人事档案管理和日常统计报表等。
SPSS软件对计算机硬件系统的要求较低;对运行的软件环境要求宽松,有各种版本可运行在WINDOWS XP、WIN7系统环境下,SPSS统计软件采用电子表格的方式输入与管理数据,能方便地从其他数据库中读入数据(如Dbase,Excel,Lotus等)。
我为什么要学习SPSS呢?其实很简单,一方面,做为一名研究生,要具备一定的科研能力,如今量化研究的方法大行其道,一切要以事实说话、要以数据说话,有了数据支持的研究才能更容易被认可、被推论。
另一方面,根据对AECT94定义的理解,教育技术学研究的对象是学习过程和学习资源,包含大量的偶然现象和非精确现象。
因此,要深入研究教育技术现象及其规律,必须运用统计描述、统计分析方法和模糊数学分析方法,才可能使这门学科达到真正完善的地步。
教育技术学研究的现象多数是偶然的现象,其变化发展往往具有几种不同的可能性,究竟出现哪一种结果,那是带有偶然性的,是随机的。
这类偶然现象是遵循统计规律的,当随机现象是由大量的成份组成,或者随机现象出现大量的次数时,就能体现统计平均规律。
教育统计学课后作业P118 1题目:10位大一学生平均每周所花的学习时间与他们的期末考试成绩见表6-17.试问:(1)学习时间与考试成绩之间是否相关?(2)比较两组数据谁的差异程度大一些?(3)比较学生2与学生9的期末考试测验成绩。
表6-17学习时间与期末考试成绩解题步骤:(1)第一步:定义变量:“xuexishijian”、“xuexichengji”后,输入数据.如下图:第二步:单击选择“分析(Analyze) ”中的“相关(Correlate)”中的“双变量(Bivariate Correlations)”,将上图中的“ xuexishijian”和“xuexichengji”添加到右边变量框中,如下图:第三步:点击“确定“后,输出结果如下图:相黄性水在03水平(敢侧)上显著相关。
第四步:分析结果由上图可知:学习时间与学习成绩之间的pearson 相关系数为0.714, p (双侧)为0.20。
自由度df=10-2=8时,查“皮尔逊积差相关系数显著临界值表”知:r 0.05= 0.623 ; r 0.01=0.765。
因为 0.765 > 0.714 >0.623 ,所以在 0.05水平上学习时间和学习成绩是相关显著的。
(2) SPSS 软件分析结果如下图:由上图可知:学习时间标准差和平均值为: S 1=12.037 X 1= 29.00 ;学习时间标准差和平均值为:S 2=12.437 X 2=56.00 根据差异系数公式可知: S100% =12.037/29.00X 100%=41.51%XS100% =12.437/56.00X 100%= 22.27%X有上述结果可知学习时间差异程度大于学习成绩差异程度。
(4) 把学生2和学生9的期末考试成绩转化成标准分数:Z 2=(X - X) /S= (73—56)/ 12.437=1.367 Z 9=(X- X)/S=(68— 56)/ 12.437=0.965由上计算可知:学生2期末考试测验成绩优于学生9的期末考试测验成绩。
SPSS复习知识点及题⽬只是分享教育统计与测量(SPSS)复习第⼀章:概述1.什么是信息?简单地讲,通过信息,可以告诉我们某件事情,可以使我们增加⼀定的知识。
英语中的信息是“information”,表⽰信息可以让受者产⽣某种形式的变化,这种变化可以让受者从认识上的不完全、不理解、不确定变为完全、理解和确定。
信息论的奠基者⾹农将信息定义为熵的减少,即信息可以消除⼈们对事物认识的不确定性,并将消除不确定程度的多少作为信息量的量度。
信息的价值因⼈⽽异。
所谓有⽤的信息,因⼈⽽异。
是否是信息,不是由传者,⽽是由受者所决定。
2.教育信息数量化的特点表⽰教育信息的数量与各种物理测量的数量有着明显的不同,在教育信息的统计处理中,应根据教育信息数量化的⽅法、特点不同,决定对这种信息进⾏统计处理的具体⽅法。
这是进⾏教育信息处理的重要关键。
3.教育信息数量化的尺度(1)名义尺度(nominal scale) :名义尺度的数值仅具符号的意义。
名义尺度的数字多⽤于表⽰不同的数别,它为教育信息的表⽰,存贮带来了很⼤的⽅便。
(2)序数尺度(ordinal scale) :序数尺度的数字多⽤于表⽰某些现象的排列顺序,可⽐较其⼤⼩,但不能进⾏四则运算,所以对这类数字的数值群的处理较多。
(3)距离尺度(interval scale,equal unit scale):距离尺度⼜称间隔尺度,是指数值间的距离(间隔),具有加法性。
距离尺度要求具有等价的单位,但不要求确定的零点位置。
对距离尺度的数字可以计算算术平均值、计算标准差,求相关系数等各种统计处理。
(4)⽐例尺度(ratio scale) :⽐例尺度是⼀种具有绝对零度的距离尺度值。
表⽰⾝长、体重的数值是⽐例尺度值。
对⽐例尺度的数字可进⾏各种统计处理。
4.数据的类型(1)定类数据(也称名义级数据),是数据的最低级。
(性别、编号)(2)定序数据(也称序次级数据),是数据的中间级。
(名次、优秀良好及格、有顺序的)(3)定距数据(也称间距级数据),是具有⼀定单位的实际测量值。
教育统计学与SPSS-名解总结第一章导论(阅览前必读:书上每个章节后的名解我全都列出来了,黑色字体的都是书上原文,量多,但有些不重要的名解没必要背,你挑着背不要被吓到。
绿色是章节题目,红色的就是我的一些说明、补充、吐槽,一个人打字很无聊啊有木有!一直自言自语啊有木有!并非书上的名词解释,看看就好,可删。
这段紫色的也删了哈。
接下来……正文,走你!)统计学(statistics):即研究统计原理与方法的科学。
教育统计学(educational statistics):是专门研究如何搜集、整理、分析在心理和教育方面有实验或调查所获得的数字资料,如何根据这些资料所传递的信息,进行数学推论,找出客观规律的一门学科。
简言之,教育统计学是运用统计学的一般原理和方法研究教育科学领域数量关系的一门科学。
描述统计(descriptiive statistics):是实验或调查所获得的数据加以整理(如制表、绘图),并计算其各种代表量数(如集中量数、差异量数、相关量数等),其基本思想是平均。
Or:是研究如何整理心理与教育科学实验或调查得来的大量数据,描述一组数据的全貌,表达一件事物的性质的一种统计方法。
推断统计(inferencial statistics):又称抽样统计,它是根据对部分个体进行观测所得到的信息,通过概括性的分析、论证,在一定可靠程度上去推测相应的团体。
Or:是研究如何通过局部数据所提供的信息,运用概率的理论进行分析论证,在一定可靠程度上推论总体或全局情形的统计方法。
这是统计学中的主要内容。
实验设计(experimental statistics):是研究如何更加合理、有效的获得观测资料,如何更正确、更经济、更有效的达到实验目的,以揭示实验中各种变量关系的实验计划。
Or:实验者为了揭示实验中自变量与因变量的关系,在实验之前所制定的实验计划,称为实验设计。
他是研究如何科学地、经济地以及更有效地进行实验。
统计常态法则:从总体中随机抽取一部分个体所组成的样本,差不多可以保持总体的特征。
小数永存法则:从总体中抽取的第一个样本中所表现的特性,在其他样本中也会存在。
大量惰性原则:某一事物的某一性质或状态,在反复观察或试验中是保持不变的。
有效数字:是指能影响测量准确性的数字。
随机变量(random variable):在统计学中把在取值之前不能预料到取什么值的量称为变量(随机变量)。
数据(data):如果一旦某个数值被取定了,成这个数值为随机变量的一个观察值,即数据。
总体(population):指客观存在的,并在同一性质的基础上结合起来的许多个别单位的整体,即具有某一特性的一类事物的全体,又叫母体或全域。
个体(individual): 构成总体的基本单位或单元,又称元素或个案。
样本(sample):从总体中抽取的一部分个体。
参数(parameter):表示总体特征的量数。
统计量(statistic):是直接从样本计算出的量数,代表样本的特征。
名称变量(nominal variable):指一事物与其他事物在属性、类别上不同。
其数据形式是计数数据。
顺序变量(ordinal variable):指事物的某一属性的多少或大小按顺序排列起来的变量。
等距变量(interval variable):指只具有相等的单位,而没有绝对的零点的变量。
比率变量(ratio variable):是一种既有相等的单位,又有绝对零点的变量,又称等比变量。
连续变量(continuous variable):指取值可以是某区间内任一数值的随机变量,它是指测量单位之间可以划分成无限多个细的小单位的,其数字形式多取小数。
离散变量(discrete variable):指测量单位之间不能再细分的数字资料,其数字形式常取整数。
计数数据(attribute data):即计算人或物的个数所获得的数据。
度量数据(quantitative data):用一定的测量工具或测量标准测量时所获得的数据。
指标(index):表明总体数量特征的概念和具体数值,又称统计指标。
标志(mark):指统计总体中各个个体共同具有的属性和特征,它是说明个体属性和特征的名称。
绝对数(absolute number):是用来表明在一定时间、地点条件下某种教育、心理现象的总体规模和发展水平的统计指标,又称总量指标。
相对数(relative number):教育与心理现象中两个单位相同的相互联系的指标数值的比率。
品质标志:主要是日常工作中的记录和统计报表等。
(p17 第四段里)数量标志:是在一定时限内所收集有关问题的资料,来源主要有调查、测量和实验。
(p17 第四段里)第二章数据的收集、整理与表达次数(frequency):某一事件在某一类别中出现的数目,又叫频数,用f表示。
频率(relative frequency):指每一组的数据个数除以数据的总和,又称相对次数,用p表示。
百分频率:是频率与百分数的乘积,即p%.组中值(class mid-value):每一组的中点值,表示常用m或xc全距(range \Rg):是全部数据的距离,也称极差,用最大值减去最小值。
组距(interval):指每一组所包含的间隔或数据单位,用i表示。
组限(boundaries of group):是每一组的起止点或每一组的界限。
统计表(statistical table):以表格的形式表达统计资料数量关系的方式或工具。
统计图(statistical graph):是以几何图形和形象图形表示统计资料数量关系的工具。
次数分布:(搞不清……)累积次数(cumulative frequency):以简单次数为基础,从最低组开始逐级累加直至最高组,或从最高组开始逐级累加直至最低组。
累积百分频率:(无视……)一时性资料:(p24倒数第二段里)经常性资料:(p24倒数第一段里)直条图(thermometer chart):用直条(或矩形)的长短表示统计数据多少的图形。
直方图(histogram):以矩形面积表示连续变量的统计图。
折线图(line chart):以纵轴的高度表示次数,并将各点用线段连接的统计图性。
散点图(scatter diagram):用于表示事物相互关系的统计图。
圆形图(pie diagram):用圆的面积表示一组数据的整体,用扇形表示各组成部分所占比重或百分比的统计图。
第三章集中量数集中量数(central measures):(p42里)集中趋势(central tendency):(p42里)(算数)平均数(arithmetic mean):是所有观测值(或变量值)的总和除以总数所得的商。
简称平均数、均数或均值。
中数\中位数(Median):是位于按一定顺序排列的一组数中央位置的数值,用符号Mdn或Md表示。
众数(Mode):是指一群数据中出现次数最多的那个数值,又称范数,用符号Mo表示。
几何平均数(geometric mean):几个变量值乘积的n次方根。
调和平均数(harmonic mean):指一群数据倒数的算术平均数的倒数,又称倒数平均数。
百分位数(Percentile):(呃……任意百分位上的数。
)四分位数:即四分之一位置和四分之三位置上的数。
第四章差异量数离中趋势(divergence tendency):(p62最后一段里)差异量数(divergence measures):(p62最后一段里)方差(variable):是离均差平方的算术平均数,表示一列数据平均差距的平方,其样本方差用符号S2表示,总体方差用符号σ2表示。
标准差(Standard Deviation):方差的算术平方根,表示一列数据的平均差距。
样本标准差用符号S或SD表示,总体标准差则用符号σ表示。
中心动差:以均数为原点计算的统计动差叫做中心动差。
平均差(Average Deviation):是以离差绝对值的和除以总次数所得的商。
平均差用符号AD 表示。
全距(Range):一列数据中最大数与最小数的差距,又称极差。
用符号Rg表示。
偏态量:(p73只可意会)峰态量:(p73不可言传)百分位差(Percentile deviation):表示某两个百分位数之间差异程度的指标。
常用的百分位差如:P93-P7,P90-P10.四分位差(Quartile deviation):(p70)统计动差:(p72中间)第五章相对量数相对地位量数:(p80中间)相对差异量数(Coefficient of Variation):指差异量数与集中量数的百分比,又称作差异系数,用符号CV表示。
百分等级(Percentile Rank):指把一组观测值先按高低次序排列起来,然后计算出某个个体的分数在百分位上超出多少人,或是在此分数下占多少百分比的一种量数,用符号PR 表示。
标准分数(standard scare):(p84标准分数有许多变形,其中最典型的标准分数为Z分数或称基分数。
没发现ta的定义)Z标准分数是以标准差为单位所表示的“原始分数”与平均数的偏差,亦即原始分数与其平均数之差除以标准差所得的商。
标准差系数:是标准差与平均数的百分比,用符号CV表示。
S第六章相关量数相关量数:(不认得)正相关(positive correlation):指一列变量由大而小或由小而大变化时,另一列变量亦由大而小或由小而大的变化,即两列变量是同方向变化的,属“同增共减”的关系。
负相关(negative correlation):指一列变量由大而小或由小而大的变化,另一列变量却反由小而大或由大而小的变化,即两列变量的变化方向是相反的,属“此增彼减”的关系。
零相关(zero correlation):又称无相关,是一列变量由大而小或由小而大变化时,另一列变量则或大或小的变化,即两列变量的变化看不出一定的趋势,甚至毫无关系。
相关系数(correlation coefficient):表示相关方向和大小的一种数值,用符号r表示。
其取值范围为-1≤r≤+1。
直线相关(line correlation):指两列变量中的一列变量在增加时,另一列变量随之而增加;或一列变量在增加,另一列变量却相应地减少,形成一种直线关系。
曲线相关(curve correlation):指两列相伴随变化的变量,未能形成直线关系。
简(单)相关(simple correlation):指只有两个变量的相关。
复(杂)相关(complex correlation):指有三个或三个以上变量的相关。
积差相关(product moment correlation):又叫均方相关、积矩相关或皮尔逊相关用符号rXY表示。
是利用离差乘积的关系来说明事物的关系,是将原始记分转换为离差乘积(即积差),再转换为标准积差后所求得的标准积差的平均数。