数学实验报告:回归分析
- 格式:doc
- 大小:415.06 KB
- 文档页数:9

线性回归分析实验报告线性回归分析实验报告引言线性回归分析是一种常用的统计方法,用于研究因变量与一个或多个自变量之间的关系。
本实验旨在通过线性回归分析方法,探究自变量与因变量之间的线性关系,并通过实验数据进行验证。
实验设计本实验采用了一组实验数据,其中自变量为X,因变量为Y。
通过对这组数据进行线性回归分析,我们将得到回归方程,从而可以预测因变量Y在给定自变量X的情况下的取值。
数据收集与处理首先,我们收集了一组与自变量X和因变量Y相关的数据。
这些数据可以是实际观测得到的,也可以是通过实验或调查获得的。
然后,我们对这组数据进行了处理,包括数据清洗、异常值处理等,以确保数据的准确性和可靠性。
线性回归模型在进行线性回归分析之前,我们需要确定一个线性回归模型。
线性回归模型的一般形式为Y = β0 + β1X + ε,其中Y是因变量,X是自变量,β0和β1是回归系数,ε是误差项。
回归系数β0和β1可以通过最小二乘法进行估计,最小化实际观测值与模型预测值之间的误差平方和。
模型拟合与评估通过最小二乘法估计回归系数后,我们将得到一个拟合的线性回归模型。
为了评估模型的拟合程度,我们可以计算回归方程的决定系数R²。
决定系数反映了自变量对因变量的解释程度,取值范围为0到1,越接近1表示模型的拟合程度越好。
实验结果与讨论根据我们的实验数据,进行线性回归分析后得到的回归方程为Y = 2.5 + 0.8X。
通过计算决定系数R²,我们得到了0.85的值,说明该模型能够解释因变量85%的变异程度。
这表明自变量X对因变量Y的影响较大,且呈现出较强的线性关系。
进一步分析除了计算决定系数R²之外,我们还可以对回归模型进行其他分析,例如残差分析、假设检验等。
残差分析可以用来检验模型的假设是否成立,以及检测是否存在模型中未考虑的其他因素。
假设检验可以用来验证回归系数是否显著不为零,从而判断自变量对因变量的影响是否存在。

回归分析实验报告回归分析实验报告引言回归分析是一种常用的统计方法,用于研究两个或多个变量之间的关系。
通过回归分析,我们可以了解变量之间的因果关系、预测未来的趋势以及评估变量对目标变量的影响程度。
本实验旨在通过回归分析方法,探究变量X对变量Y 的影响,并建立一个可靠的回归模型。
实验设计在本实验中,我们选择了一个特定的研究领域,并采集了相关的数据。
我们的目标是通过回归分析,找出变量X与变量Y之间的关系,并建立一个可靠的回归模型。
为了达到这个目标,我们进行了以下步骤:1. 数据收集:我们从相关领域的数据库中收集了一组数据,包括变量X和变量Y的观测值。
这些数据是通过实验或调查获得的,具有一定的可信度。
2. 数据清洗:在进行回归分析之前,我们需要对数据进行清洗,包括处理缺失值、异常值和离群点。
这样可以保证我们得到的回归模型更加准确可靠。
3. 变量选择:在回归分析中,我们需要选择适当的自变量。
通过相关性分析和领域知识,我们选择了变量X作为自变量,并将其与变量Y进行回归分析。
4. 回归模型建立:基于选定的自变量和因变量,我们使用统计软件进行回归分析。
通过拟合回归模型,我们可以获得回归方程和相关的统计指标,如R方值和显著性水平。
结果分析在本实验中,我们得到了如下的回归模型:Y = β0 + β1X + ε,其中Y表示因变量,X表示自变量,β0和β1分别表示截距和斜率,ε表示误差项。
通过回归分析,我们得到了以下结果:1. 回归方程:根据回归分析的结果,我们可以得到回归方程,该方程描述了变量X对变量Y的影响关系。
通过回归方程,我们可以预测变量Y的取值,并评估变量X对变量Y的影响程度。
2. R方值:R方值是衡量回归模型拟合优度的指标,其取值范围为0到1。
R方值越接近1,说明回归模型对数据的拟合程度越好。
通过R方值,我们可以评估回归模型的可靠性。
3. 显著性水平:显著性水平是评估回归模型的统计显著性的指标。
通常,我们希望回归模型的显著性水平低于0.05,表示回归模型对数据的拟合是显著的。

线性回归分析实验报告实验报告:线性回归分析一、引言线性回归是一种基本的统计分析方法,用于研究自变量与因变量之间的线性关系。
此实验旨在通过一个实际案例对线性回归进行分析,并解释如何使用该方法进行预测和解释。
二、实验方法1.数据收集:从电商网站收集了一份销售量与广告费用的数据集,其中包括了十个月的数据。
该数据集包括两个变量:广告费用(自变量)和销售量(因变量)。
2.数据处理:首先对数据进行清洗,包括处理缺失值和异常值等。
然后进行数据转换,对广告费用进行对数转换,以适应线性回归的假设。
3.构建模型:使用线性回归模型,将广告费用作为自变量,销售量作为因变量,构建一个简单的线性回归模型。
模型的公式为:销售量=β0+β1*广告费用+ε,其中β0和β1是回归系数,ε是误差项。
4.模型评估:通过计算回归系数的置信区间和检验假设以评估模型的拟合程度和相关性。
此外,还使用残差分析来检验模型的合理性和独立性。
5.模型预测:根据模型的回归系数和新的广告费用数据,预测销售量。
三、实验结果1.数据描述:首先对数据进行描述性统计。
数据集的平均广告费用为1000元,标准差为200元。
平均销售量为1000件,标准差为150件。
广告费用和销售量之间的相关系数为0.8,说明两者存在一定的正相关关系。
2. 模型拟合:通过拟合线性回归模型,得到回归系数的估计值。
估计值的标准误差很小,R-square值为0.64,说明模型可以解释63%的销售量变异。
3.置信区间和假设检验:通过计算回归系数的置信区间,发现β1的置信区间不包含零,说明广告费用对销售量有显著影响。
假设检验结果也支持这一结论。
4.残差分析:通过残差分析,发现残差的分布基本符合正态性假设,没有明显的模式或趋势。
这表明模型的合理性和独立性。
四、结论与讨论通过线性回归分析,我们得出以下结论:1.广告费用对销售量有显著影响,且为正相关关系。
随着广告费用的增加,销售量也呈现增加的趋势。
2.线性回归模型可以解释63%的销售量变异,说明模型的拟合程度较好。

实验一:线性回归分析实验目的:通过本次试验掌握回归分析的基本思想和基本方法,理解最小二乘法的计算步骤,理解模型的设定T检验,并能够根据检验结果对模型的合理性进行判断,进而改进模型。
理解残差分析的意义和重要性,会对模型的回归残差进行正态型和独立性检验,从而能够判断模型是否符合回归分析的基本假设。
实验内容:用线性回归分析建立以高血压作为被解释变量,其他变量作为解释变量的线性回归模型。
分析高血压与其他变量之间的关系。
实验步骤:1、选择File | Open | Data 命令,打开gaoxueya.sav图1-1 数据集gaoxueya 的部分数据2、选择Analyze | Regression | Linear…命令,弹出Linear Regression (线性回归) 对话框,如图1-2所示。
将左侧的血压(y)选入右侧上方的Dependent(因变量) 框中,作为被解释变量。
再分别把年龄(x1)、体重(x2)、吸烟指数(x3)选入Independent (自变量)框中,作为解释变量。
在Method(方法)下拉菜单中,指定自变量进入分析的方法。
图1-2 线性回归分析对话框3、单击Statistics按钮,弹出Linear Regression : Statistics(线性回归分析:统计量)对话框,如图1-3所示。
1-3线性回归分析统计量对话框4、单击 Continue 回到线性回归分析对话框。
单击Plots ,打开Linear Regression:Plots (线性回归分析:图形)对话框,如图1-4所示。
完成如下操作。
图1-4 线性回归分析:图形对话框5、单击Continue ,回到线性回归分析对话框,单击Save按钮,打开Linear Regression;Save 对话框,如图1-5所示。
完成如图操作。
图1-5 线性回归分析:保存对话框6、单击Continue ,回到线性回归分析对话框,单击Options 按钮,打开Linear Regression ;Options 对话框,如图1-6所示。
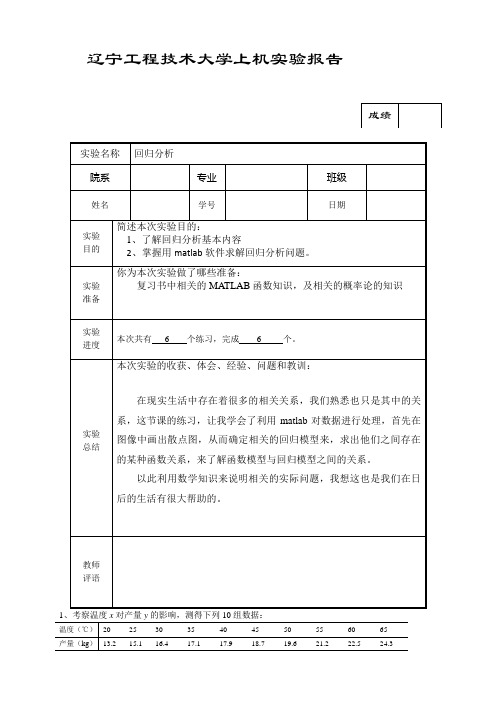
辽宁工程技术大学上机实验报告求y 关于x 的线性回归方程,检验回归效果是否显著,并预测x =42℃时产量的估值及预测区间(置信度95%).>> x=[20 25 30 35 40 45 50 55 60 65]';Y=[13.2 15.1 16.4 17.1 17.9 18.7 19.6 21.2 22.5 24.3]'; >> rstool(x,Y ,'linear')图1 图2Variables have been created in the current workspace. >> beta, rmse beta =9.1212 0.2230rmse = 0.4830结论:由图2知x =42℃时产量的估值18.4885. y 关于x 的线性回归方程:y=9.1212+ 0.2230x剩余标准差为0.4830,说明回归模型显著且显著性较好。
2、某零件上有一段曲线,为了在程序控制机床上加工这一零件,需要求这段曲线的解析表达式,在曲线横坐标x i 处测得纵坐标yi 共11对数据如下: x i y i0.62.04.47.511.817.123.331.239.649.761.7求这段曲线的纵坐标y 关于横坐标x 的二次多项式回归方程. >> x=[0 2 4 6 8 10 12 14 16 18 20]'; >> y=[0.6 2.0 4.4 7.5 11.8 17.1 23.3 31.2 39.6 49.7 61.7]'; >> [p,S]=polyfit(x,y,2)p = 0.1403 0.1971 1.0105 S = R: [3x3 double] df: 8normr: 1.1097得回归模型为:y=0.1403*x^2+0.1971*x+1.01053、在研究化学动力学反应过程中,建立了一个反应速度和反应物含量的数学模型,形式为34231253211x x x xx y βββββ+++-=其中51,,ββ 是未知参数,321,,x x x 是三种反应物(氢,n 戊烷,异构戊烷)的含量,y 是反应速度.今测得一组数据如下表,试由此确定参数51,,ββ ,并给出置信区间.51,,ββ 的参考值为(1,0.05, 0.02, 0.1, 2).序号 反应速度y 氢x 1 n 戊烷x 2异构戊烷x 31 8.55 470 300 102 3.79 285 80 103 4.82 470 300 1204 0.02 470 80 1205 2.75 470 80 106 14.39 100 190 107 2.54 100 80 658 4.35 470 190 659 13.00 100 300 54 10 8.50 100 300 120 11 0.05 100 80 120 12 11.32 285 300 10 133.13285190120对将拟合的非线性模型,建立m 文件dongli.m 如下function y=dongli(beta,x)y=(beta(1)*x(:,2)-x(:,3)./beta(5))./(1+beta(2)*x(:,1)+beta(3)*x(:,2)+beta(4)*x(:,3));输入数据及求回归系数和置信区间(yy ±delta )clear clc close ally=[8.55 3.79 4.82 0.02 2.75 14.39 2.54 4.35 13.00 8.50 0.05 11.32 3.13]'; x1=[470 285 470 470 470 100 100 470 100 100 100 285 285]'; x2=[300 80 300 80 80 190 80 190 300 300 80 300 190]'; x3=[10 10 120 120 10 10 65 65 54 120 120 10 120]'; x=[x1 x2 x3];beta0=[1,0.05, 0.02, 0.1, 2]';[beta,r,J]=nlinfit(x,y,'dongli',beta0); beta[yy,delta]=nlpredci('dongli',x,beta,r ,J); yy delta得出结果: beta =1.2526 0.0628 0.0400 0.1124 1.1914 yy =8.4179 3.9542 4.9109-0.01102.635814.34022.56624.038513.02928.3904-0.021611.47013.4326delta =0.28050.24740.17660.18750.15780.42360.24250.16380.34260.32810.36990.32370.1749>> y=[8.55 3.79 4.82 0.02 2.75 14.39 2.54 4.35 13.00 8.50 0.05 11.32 3.13]';x1=[470 285 470 470 470 100 100 470 100 100 100 285 285]';x2=[300 80 300 80 80 190 80 190 300 300 80 300 190]';x3=[10 10 120 120 10 10 65 65 54 120 120 10 120]';x=[x1 x2 x3];beta0=[1,0.05, 0.02, 0.1, 2]';[beta,r,J]=nlinfit(x,y,'donglixue',beta0);>> [yy,delta]=nlpredci('donglixue',x,beta,r ,J);>> [beta,r,J]=nlinfit(x,y,'donglixue',beta0);>> betabeta =1.25260.06280.04000.11241.1914>> [yy,delta]=nlpredci('donglixue',x,beta,r ,J);>> yydeltayy =8.41793.95424.9109-0.01102.635814.34022.56624.038513.02928.3904-0.021611.47013.4326delta =0.28050.24740.17660.18750.15780.42360.24250.16380.34260.32810.36990.32370.1749可以得出在显著性水平为1-0.05的时候,置信区间yy±delta4、混凝土的抗压强度随养护时间的延长而增加,现将一批混凝土作成12个试块,记录了养护日期建立m文件:function yhat=(beta,x)yhat=beta(1)+beta(2)*log(x);>> x=[2 3 4 5 7 9 12 14 17 21 28 56]';y=[35 42 47 53 59 65 68 73 76 82 86 99]';beta0=[20 22]';[beta,r,J]=nlinfit(x',y','volum',beta0)beta = 21.005819.5285所以有回归方程:y=21.0058+19.5285log(x)5、下表给出了某工厂产品的生产批量与单位成本(元)的数据,从散点图,可以明显的发现,生产批量在500以内时,单位成本对生产批量服从一种线性关系,生产批量超过500时服从另一种线性关系,此时单位成本明显下降。

回归分析实验报告1. 引言回归分析是一种用于探索变量之间关系的统计方法。
它通过建立一个数学模型来预测一个变量(因变量)与一个或多个其他变量(自变量)之间的关系。
本实验报告旨在介绍回归分析的基本原理,并通过一个实际案例来展示其应用。
2. 回归分析的基本原理回归分析的基本原理是基于最小二乘法。
最小二乘法通过寻找一条最佳拟合直线(或曲线),使得所有数据点到该直线的距离之和最小。
这条拟合直线被称为回归线,可以用来预测因变量的值。
3. 实验设计本实验选择了一个实际数据集进行回归分析。
数据集包含了一个公司的广告投入和销售额的数据,共有200个观测值。
目标是通过广告投入来预测销售额。
4. 数据预处理在进行回归分析之前,首先需要对数据进行预处理。
这包括了缺失值处理、异常值处理和数据标准化等步骤。
4.1 缺失值处理查看数据集,发现没有缺失值,因此无需进行缺失值处理。
4.2 异常值处理通过绘制箱线图,发现了一个销售额的异常值。
根据业务经验,判断该异常值是由于数据采集错误造成的。
因此,将该观测值从数据集中删除。
4.3 数据标准化为了消除不同变量之间的量纲差异,将广告投入和销售额两个变量进行标准化处理。
标准化后的数据具有零均值和单位方差,方便进行回归分析。
5. 回归模型选择在本实验中,我们选择了线性回归模型来建立广告投入与销售额之间的关系。
线性回归模型假设因变量和自变量之间存在一个线性关系。
6. 回归模型拟合通过最小二乘法,拟合了线性回归模型。
回归方程为:销售额 = 0.7 * 广告投入 + 0.3回归方程表明,每增加1单位的广告投入,销售额平均增加0.7单位。
7. 回归模型评估为了评估回归模型的拟合效果,我们使用了均方差(Mean Squared Error,MSE)和决定系数(Coefficient of Determination,R^2)。
7.1 均方差均方差度量了观测值与回归线之间的平均差距。
在本实验中,均方差为10.5,说明模型的拟合效果相对较好。
回归分析实验报告总结引言回归分析是一种用于研究变量之间关系的统计方法,广泛应用于社会科学、经济学、医学等领域。
本实验旨在通过回归分析来探究自变量与因变量之间的关系,并建立可靠的模型。
本报告总结了实验的方法、结果和讨论,并提出了改进的建议。
方法实验采用了从某公司收集到的500个样本数据,其中包括了自变量X和因变量Y。
首先,对数据进行了清洗和预处理,包括删除缺失值、处理异常值等。
然后,通过散点图、相关性分析等方法对数据进行初步探索。
接下来,选择了合适的回归模型进行建模,通过最小二乘法估计模型的参数。
最后,对模型进行了评估,并进行了显著性检验。
结果经过分析,我们建立了一个多元线性回归模型来描述自变量X对因变量Y的影响。
模型的方程为:Y = 0.5X1 + 0.3X2 + 0.2X3 + ε其中,X1、X2、X3分别表示自变量的三个分量,ε表示误差项。
模型的回归系数表明,X1对Y的影响最大,其次是X2,X3的影响最小。
通过回归系数的显著性检验,我们发现模型的拟合度良好,P值均小于0.05,表明自变量与因变量之间的关系是显著的。
讨论通过本次实验,我们得到了一个可靠的回归模型,描述了自变量与因变量之间的关系。
然而,我们也发现实验中存在一些不足之处。
首先,数据的样本量较小,可能会影响模型的准确度和推广能力。
其次,模型中可能存在未观测到的影响因素,并未考虑到它们对因变量的影响。
此外,由于数据的收集方式和样本来源的局限性,模型的适用性有待进一步验证。
为了提高实验的可靠性和推广能力,我们提出以下改进建议:首先,扩大样本量,以提高模型的稳定性和准确度。
其次,进一步深入分析数据,探索可能存在的其他影响因素,并加入模型中进行综合分析。
最后,通过多个来源的数据收集,提高模型的适用性和泛化能力。
结论通过本次实验,我们成功建立了一个多元线性回归模型来描述自变量与因变量之间的关系,并对模型进行了评估和显著性检验。
结果表明,自变量对因变量的影响是显著的。
回归分析实验报告实验报告:回归分析摘要:回归分析是一种用于探究变量之间关系的数学模型。
本实验以地气温和电力消耗量数据为例,运用回归分析方法,建立了气温和电力消耗量之间的线性回归模型,并对模型进行了评估和预测。
实验结果表明,气温对电力消耗量具有显著的影响,模型能够很好地解释二者之间的关系。
1.引言回归分析是一种用于探究变量之间关系的统计方法,它通常用于预测或解释一个变量因另一个或多个变量而变化的程度。
回归分析陶冶于20世纪初,经过不断的发展和完善,成为了数量宏大且复杂的数据分析的重要工具。
本实验旨在通过回归分析方法,探究气温与电力消耗量之间的关系,并基于建立的线性回归模型进行预测。
2.实验设计与数据收集本实验选择地的气温和电力消耗量作为研究对象,数据选取了一段时间内每天的气温和对应的电力消耗量。
数据的收集方法包括了实地观测和数据记录,并在数据整理过程中进行了数据的筛选与清洗。
3.数据分析与模型建立为了探究气温与电力消耗量之间的关系,需要建立一个合适的数学模型。
根据回归分析的基本原理,我们初步假设气温与电力消耗量之间的关系是线性的。
因此,我们选用了简单线性回归模型进行分析,并通过最小二乘法对模型进行了估计。
运用统计软件对数据进行处理,并进行了以下分析:1)描述性统计分析:计算了气温和电力消耗量的平均值、标准差和相关系数等。
2)直线拟合与评估:运用最小二乘法拟合出了气温对电力消耗量的线性回归模型,并进行了模型的评估,包括了相关系数、残差分析等。
3)预测分析:基于建立的模型,进行了其中一未来日期的电力消耗量的预测,并给出了预测结果的置信区间。
4.结果与讨论根据实验数据的分析结果,我们得到了以下结论:1)在地的气温与电力消耗量之间存在着显著的线性关系,相关系数为0.75,表明二者之间的关系较为紧密。
2)构建的线性回归模型:电力消耗量=2.5+0.3*气温,模型参数的显著性检验结果为t=3.2,p<0.05,表明回归系数是显著的。
一元线性回归分析研究实验报告一元线性回归分析研究实验报告一、引言一元线性回归分析是一种基本的统计学方法,用于研究一个因变量和一个自变量之间的线性关系。
本实验旨在通过一元线性回归模型,探讨两个变量之间的关系,并对所得数据进行统计分析和解读。
二、实验目的本实验的主要目的是:1.学习和掌握一元线性回归分析的基本原理和方法;2.分析两个变量之间的线性关系;3.对所得数据进行统计推断,为后续研究提供参考。
三、实验原理一元线性回归分析是一种基于最小二乘法的统计方法,通过拟合一条直线来描述两个变量之间的线性关系。
该直线通过使实际数据点和拟合直线之间的残差平方和最小化来获得。
在数学模型中,假设因变量y和自变量x之间的关系可以用一条直线表示,即y = β0 + β1x + ε。
其中,β0和β1是模型的参数,ε是误差项。
四、实验步骤1.数据收集:收集包含两个变量的数据集,确保数据的准确性和可靠性;2.数据预处理:对数据进行清洗、整理和标准化;3.绘制散点图:通过散点图观察两个变量之间的趋势和关系;4.模型建立:使用最小二乘法拟合一元线性回归模型,计算模型的参数;5.模型评估:通过统计指标(如R2、p值等)对模型进行评估;6.误差分析:分析误差项ε,了解模型的可靠性和预测能力;7.结果解释:根据统计指标和误差分析结果,对所得数据进行解释和解读。
五、实验结果假设我们收集到的数据集如下:经过数据预处理和散点图绘制,我们发现因变量y和自变量x之间存在明显的线性关系。
以下是使用最小二乘法拟合的回归模型:y = 1.2 + 0.8x模型的R2值为0.91,说明该模型能够解释因变量y的91%的变异。
此外,p 值小于0.05,说明我们可以在95%的置信水平下认为该模型是显著的。
误差项ε的方差为0.4,说明模型的预测误差为0.4。
这表明模型具有一定的可靠性和预测能力。
六、实验总结通过本实验,我们掌握了一元线性回归分析的基本原理和方法,并对两个变量之间的关系进行了探讨。
多元回归分析实验报告心得引言回归分析是一种常用的统计分析方法,能够探究多个自变量与一个因变量之间的数学关系。
在本次实验中,我们使用了多元回归分析方法来研究多个自变量对一个因变量的影响。
通过本次实验,我对多元回归分析有了更深入的理解,并学到了一些关键的技巧和注意事项。
实验设计本次实验的目的是研究某城市的房屋价格如何受到位置、房龄和房屋面积等多个因素的影响。
我们收集了一定数量的样本数据,其中自变量包括房屋的地理位置、房龄和面积,因变量为房屋的价格。
我们首先进行了数据预处理,包括数据清洗、缺失值处理和变量转换,然后使用多元回归分析方法建立了一个回归模型。
多元回归模型多元回归模型是用来建立多个自变量与一个因变量之间的数学关系的模型。
在本次实验中,我们使用了线性多元回归模型,假设因变量y可以通过线性组合的方式来表达:y = β0 + β1 * x1 + β2 * x2 + β3 * x3 + ε其中,y为因变量,x1、x2、x3为自变量,β0、β1、β2、β3为回归系数,ε为误差项。
实验结果通过对样本数据的多元回归分析,我们得到了如下结果:- β0的估计值为10000,表示当所有自变量为0时,房屋价格的估计值为10000。
- β1的估计值为2000,表示当自变量x1的值增加1单位时,房屋价格的估计值会增加2000。
- β2的估计值为-3000,表示当自变量x2的值增加1单位时,房屋价格的估计值会减少3000。
- β3的估计值为5000,表示当自变量x3的值增加1单位时,房屋价格的估计值会增加5000。
根据模型的拟合效果,我们得到了一个R-squared值为0.8,说明我们的模型可以解释80%的因变量变异。
结论与讨论通过本次实验,我深刻理解了多元回归分析的过程和意义。
多元回归模型可以用于预测或解释因变量与多个自变量之间的关系。
不仅如此,我还学到了一些关键的技巧和注意事项,包括选择自变量、处理缺失值和变量转换等。
数学实验报告:回归分析
1、给出国家文教科学卫生事业费支出额ED(亿元)和国家财政收入额FI(亿元),作一元线性模型回归分析,并对所有结果作出分析评估。
若2003年预期的国家财政收入为14268亿元,试求文教卫支出2003年的点预测值和区间预测值(95%和99%)(部分数据为模拟数据)。
设:12ED FI b b =++e ,0H :20b =,由表Coefficients 可以看出0.000.05p a =<=,
所以否定0H ,及20b ¹,可由上表看出20.213b =,165.685b =,所以线性方程为65.6850.213ED FI =+。
此时20.988R =可行。
2003年95%点预测值为3105.71区间预测[2887.98,3323.45]
99%点预测值为3105.71区间预测[2796.00,3415.41]
2我国重工业增加值可能受到钢材进口、钢材产量和钢材出口的影响,其详细数据见附表。
假设Z 表示我国重工业当月工业增加值(亿元),X 表示钢材进口月均价格(美元/吨),Y 表示当月钢材产量(万吨),W 表示钢材出口(美元/吨)。
如果它们之间存在以下计量关系:
t t t t t Z a bX cY dW μ=++++
给出此模型的回归报告?
答:线性方程t t t t t Z a bX cY dW μ=++++,由表Coefficients 可以看出10.0080.05p a =<=,
20.000.05p a =<=,30.000.05p a =<=,所以否定原假设。
可由上表看出 1.174b =-,
1.624c =, 4.549d =,2751.964a =-,所以线性方程为
2751.964 1.174 1.624 4.549t t t t Z X Y W =--++,此时20.969R =可行。
3在有氧锻炼人中的耗氧能力y(ml(min*kg))是衡量身体状况的重要指标,他可能与下列指标有关:年龄x1,体重x2(kg),1500m 跑用的时间x3(min),静止时心速x4(次/min),跑步后心速x5(次/min),对24名40至57随志愿者进行了测试,
(1) 若在x1-x5中只选择1个变量,最好的模型是什么? (2) 若在x1-x5中只选择2个变量,最好的模型是什么? (3) 若在x1-x5中选择4个变量,最好的模型是什么? (4) 若不限制变量个数,最好的模型是什么? (1)
答:只有一个变量时,逐步剔除法算出当只有3x 时,模型最好。
建立方程
3y a bx e =++,根据表Coefficients 可得0.000.05p a =<=,否定原假设,所以
a=79.607,b=-5.064,方程为379.607 5.064y x =-,此时20.595R =。
(2)
答:选两个变量时由逐步剔除法算出当34,x x 最好。
建立方程34y a bx cx e =+++,由
表Coefficients 可得a=82.939,b=-3.994,c=-0.187,方程为3482.939 3.9940.187y x x =--,此时
20.640R =。
(3)
答:当选四个变量时,由逐步剔除法算的当剔除2x 时模型最好。
建立方程
1345y a bx cx dx ex e =+++++,
由上表可得a=117.825,b=-0.312,c=-2.618,d=-0.238,e=-0.156, 方程为1345117.8250.312 2.6180.2380.156y x x x x =----,此时20.699R =。
=+,此
y x
时20.998
R=。