2011年数据结构本科试题及答案
- 格式:doc
- 大小:108.50 KB
- 文档页数:6

全国2011年1月自学考试数据结构导论试题和答案课程代码:02142一、单项选择题(本大题共15小题,每小题2分,共30分)在每小题列出的四个备选项中只有一个是符合题目要求的,请将其代码填写在题后的括号内。
错选、多选或未选均无分。
1.在顺序表中查找第i个元素,时间效率最高的算法的时间复杂度为( )A.O(1)B.O(n)C.O(log2n)D.O(n)2.树形结构中,度为0的结点称为( )A.树根B.叶子C.路径D.二叉树3.已知有向图G=(V,E),其中V={V1,V2,V3,V4,V5,V6,V7},E={<V1,V2>,<V1,V3>,<V1,V4>,<V2,V5>,<V3,V5>,<V3,V6>,<V4,V6>,<V5,V7>,,<V6,V7>},则图G的拓扑序列是( )A.V1,V3,V4,V6,V2,V5,V7B.V1,V3,V2,V6,V4,V5,V7C.V1,V3,V4,V5,V2,V6,V7D.V1,V2,V5,V3,V4,V6,V74.有关图中路径的定义,表述正确的是( )A.路径是顶点和相邻顶点偶对构成的边所形成的序列B.路径是不同顶点所形成的序列C.路径是不同边所形成的序列D.路径是不同顶点和不同边所形成的集合5.串的长度是指( )A.串中所含不同字母的个数B.串中所含字符的个数C.串中所含不同字符的个数D.串中所含非空格字符的个数6.组成数据的基本单位是( )A.数据项B.数据类型C.数据元素D.数据变量7.程序段i=n;x=0;do{x=x+5*i;i--;}while (i>0);的时间复杂度为( )A.O(1)B.O(n)C.O(n2)D.O(n3)8.与串的逻辑结构不同的...数据结构是( )A.线性表B.栈C.队列D.树9.二叉树的第i(i≥1)层上所拥有的结点个数最多为( )A.2iB.2iC.2i-1D.2i-110.设单链表中指针p指向结点A,若要删除A的直接后继,则所需修改指针的操作为( )全国2011年1月自学考试数据结构导论试题和答案 1A.p->next=p->next->nextB.p=p->nextC.p=p->next->nextD.p->next=p11.下列排序算法中,某一趟结束后未必能选出一个元素放在其最终位置上的是( )A.堆排序B.冒泡排序C.直接插入排序D.快速排序12.设字符串S1=″ABCDEFG″,S2=″PQRST″,则运算S=CONCAT(SUBSTR(S1,2,LENGTH(S2)),SUBSTR(S1,LENGTH(S2),2))后S的结果为( )A.″BCQR″B.″BCDEF″C.″BCDEFG″D.″BCDEFEF″13.在平衡二叉树中插入一个结点后造成了不平衡,设最低的不平衡结点为A,并且A的左孩子的平衡因子为-1,右孩子的平衡因子为0,则使其平衡的调整方法为( )A.LL型B.LR型C.RL型D.RR型14.如果结点A有3个兄弟结点,而且B为A的双亲,则B的度为( )A.1B.3C.4D.515.数据表A中每个元素距其最终位置较近,则最省时间的排序算法是( )A.堆排序B.插入排序C.直接选择排序D.快速排序二、填空题(本大题共13小题,每小题2分,共26分)请在每小题的空格中填上正确答案。

武汉大学计算机学院2011年-2012学年第一学期“数据结构”考试试题(A)要求:所有的题目的解答均写在答题纸上,需写清楚题目的序号。
每张答题纸都要写上姓名和学号。
一、单项选择题(共20小题,每小题2分,共40分)1. 下列各选项中属于逻辑结构的是。
A.哈希表B.有序表C.单链表D.顺序表2. 对于数据结构,以下叙述中不正确的是。
A.数据的逻辑结构与数据元素本身的形式和内容无关B.数据的逻辑结构是数据的各数据项之间的逻辑关系C.数据元素是数据的基本单位D.数据项是数据的最小单位3. 某算法的时间复杂度为O(n2),表明该算法的。
A.问题规模是n2B.执行时间等于n2C.执行时间与n2成正比D.问题规模与n2成正比4. 通常在单链表中增加一个头节点,其目的是为了。
A.使单链表至少有一个节点B.标识表节点中首节点的位置C.方便单链表运算的实现D.说明单链表是线性表的链式存储5. 删除某个双链表中的一个节点(非首、尾节点),需要修改个指针域。
A.1B.2C.3D.46. 栈和队列是两种不同的数据结构,但它们中的元素具有相同的。
A.抽象数据类型B.逻辑结构C.存储结构D.运算7. 元素a、b、c、d、e依次进入初始为空的栈中,若元素进栈后可停留、可出栈,直到所有的元素都出栈,则所有可能的出栈序列中,以元素d开头的序列个数是。
A.3B.4C.5D.68. 设环形队列中数组的下标是0~N-1,其头尾指针分别为f和r(f指向队列中队头元素的前一个位置,r指向队尾元素的位置),则其元素个数为。
A.r-fB.r-f-1C.(r-f)%N+1D.(r-f+N)%N9. 已知循环队列存储在一维数组A[0..n-1]中,且队列非空时front和rear分别指向队头元素和队尾元素。
若初始时队列空,且要求第一个进入队列的元素存储在A[0]处,则初始时front和rear的值分别是。
A.0,0B.0,n-1C.n-1,0D.n-1,n-110. 对于n阶(n≥2)对称矩阵,采用压缩方法以行序优先存放到内存中,则需要个存储单元。



全国2011年10月高等教育自学考试-----数据结构试题一、单项选择题(本大题共15小题,每小题2分,共30分)1、在数据的逻辑结构中,树结构和图结构都是()A.非线性结构B.线性结构C.动态结构D.静态结构2.在一个长度为n的顺序表中插入一个元素的算法的时间复杂度为()A.O(1)B.O(log n)C.O(n)D.O(n2)3.指针p1和p2分别指向两个无头结点的非空单循环链表中的尾结点,要将两个链表链接成一个新的单循环链表,应执行的操作为()A.p1->next=p2->next;p2->next=p1->next;B. p2->next=p1->next;p1->next=p2->next;C. p=p2->next; p1->next=p;p2->next=p1->next;D. p=p1->next; p1->next= p2->next;p2->next=p;4.设栈的初始状态为空,入栈序列为1,2,3,4,5,6,若出栈序列为2,4,3,6,5,1,则操作过程中栈中元素个数最多时为()A.2个B.3个C.4个D.6个5.队列的特点是()A.允许在表的任何位置进行插入和删除B.只允许在表的一端进行插入和删除C.允许在表的两端进行插入和删除D.只允许在表的一端进行插入,在另一端进行删除6.一个链串的结点类型定义为﹟define NodeSize 6typedef struct node{char data[NodeSize];struct node*next;}LinkStrNode;如果每个字符占1个字节,指针占2个字节,该链串的存储密度为()A.1/3B.1/2C.2/3D.3/47.广义表A=(a,B,(a,B,(a,B,……)))的长度为()A.1B.2C.3D.无限值8.已知10×12的二维数组A,按“行优先顺序”存储,每个元素占1个存储单元,已知A[1][1]的存储地址为420,则A[5][5]的存储地址为()A.470B.471C.472D.4739.在一棵二叉树中,度为2的结点数为15,度为1的结点数为3,则叶子结点数为()A.12B.16C.18D.2010.在带权图的最短路径问题中,路径长度是指()A.路径上的顶点数B.路径上的边数C.路径上的顶点数与边数之和D.路径上各边的权值之和11.具有n个顶点、e条边的无向图的邻接矩阵中,零元素的个数为()A.eB.2eC.n2-2eD.n2-112.要以O(n log n)时间复杂度进行稳定的排序,可用的排序方法是()A.归并排序B.快速排序C.堆排序D.冒泡排序13.若希望在1000个无序元素中尽快求得前10个最大元素,应借用()A.堆排序B.快速排序1 / 6C.冒泡排序D.归并排序14.对有序表进行二分查找成功时,元素比较的次数()A.仅与表中元素的值有关B.仅与表的长度和被查元素的位置有关C.仅与被查元素的值有关D.仅与表中元素按升序或降序排列有关15.散列文件是一种()A.顺序存取的文件B.随机存取的文件C.索引存取的文件D.索引顺序存取的文件二、填空题(本大题共10小题,每小题2分,共20分)16.若一个算法中的语句频度之和为T(n)=3n3-200nlog2n+50n,则该算法的渐近时间复杂度为__________.17.在单链表中,除了第1个元素结点外,任一结点的存储位置均由_____________指示。

1、以下属于顺序存储结构优点的是( A )。
A) 存储密度大B) 插入运算方便C)删除运算方便D)可方便地用于各种逻辑结构的存储表示2、若一棵二叉树具有10个度为2的结点,5个度为1的结点,则度为0的结点的个数是( B )。
A)9 B)11 C)15 D)不能确定3、数据结构研究的内容是( D )。
A)数据的逻辑结构 B)数据的存储结构C)建立在相应逻辑结构和存储结构上的算法 D)包括以上三个方面4、在数据结构中,从逻辑上可以把数据结构分为( C )。
A)动态结构和静态结构 B)紧凑结构和非紧凑结构C)线性结构和非线性结构 D)内部结构和外部结构5、队列的操作的原则是( A )。
A)先进先出 B) 后进先出C) 只能进行插入 D) 只能进行删除6、如果结点A有3个兄弟,而且B为A的双亲,则B的度为( B )。
A)3 B)4 C)5 D)17、设单链表中指针p指着结点A,若要删除A之后的结点(若存在),则需要修改指针的操作为( A )。
A)p->next=p->next->next B)p=p->nextC)p=p->nexe->next D)p->next=p8、队列的操作的原则是( A )。
A)先进先出 B) 后进先出C) 只能进行插入 D) 只能进行删除9、下面程序段的时间复杂度是( A )。
s =0;for( i =0; i<n; i++)for(j=0;j<n;j++)s +=B[i][j];sum = s ;A) O(n2) B) O(n)C) O(m*n) D)O(1)10、与无向图相关的术语有( C )。
A)强连通图 B)入度C)路径 D)弧11、有一个有序表{1,4,6,10,18,35,42,53,67,71,78,84,92,99}。
当用二分查找法查找键值为84的结点时,经( B )比较后查找成功。
A) 4 B)3 C)2 D)1212、数据结构研究的内容是( D )。


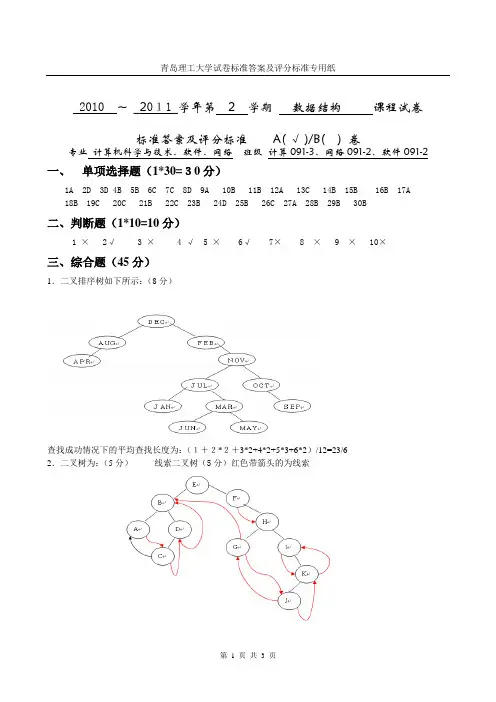
2010~_2011_学年第 2 学期数据结构课程试卷标准答案及评分标准A( √ )/B( ) 卷专业计算机科学与技术、软件、网络班级计算091-3、网络091-2、软件091-2 一、单项选择题(1*30=30分)1A 2D 3D 4B 5B 6C 7C 8D 9A 10B 11B 12A 13C 14B 15B 16B 17A18B 19C 20C 21B 22C 23B 24D 25B 26C 27A 28B 29B 30B二、判断题(1*10=10分)1 × 2√ 3 × 4 √ 5 × 6√ 7× 8 × 9 × 10×三、综合题(45分)1.二叉排序树如下所示:(8分)查找成功情况下的平均查找长度为:(1+2*2+3*2+4*2+5*3+6*2)/12=23/62.二叉树为:(5分)线索二叉树(5分)红色带箭头的为线索3.哈夫曼树如下(5分)带权路径长度为:WPL=(4+6+8+10)*4+(15+20)*3+(23+35)*2=333 (2分)成功查找情况下的平均查找长度为:ASL=(10*1+3*3)/13=19/135.(1)邻接表如下(2分)(2)深度优先遍历序列:1,2,3,4,5(2分)广度优先遍历序列:1,2,4,5,3(2分)(3)最小生成树:(2分)最小生成树各边上的权值之和为:10五、算法设计题(7+8=15分)1.(共7分)void MergeList_L(LinkList &HA,LinkList &HB,LinkList &HC){ //按值递增排序的单链表LA,LB,归并为LC后也按值递增排序pa=HA-->next; pb=HB-->next; Lc=pc=HA; //初始化(1分)while(pa&&pb) //将pa 、pb结点按大小依次插入C中{ if(pa->data<=pb->data) (1分){pc->next=pa; pc=pa; pa=pa->next;} (2分) else {pc->next=pb; pc=pb; pb=pb->next} (2分) }pc->next = pa?pa:pb ; //插入剩余段(1分)free(HB); //释放Lb的头结点} //MergeList_L2.二叉链表存储的二叉树的层次遍历的算法:(共8分)void BFSTraverse(BiTree T) {InitQueue(Q); // 置空的辅助队列Qif (T) EnQueue(Q, T); // 根结点入队列(1分)while (!QueueEmpty(Q)) { (1分)DeQueue(Q, p); // 队头元素出队并置为p (1分)Visit(p); (1分)if (p->Lchild)EnQueue(Q, p->Lchild); // 左子树根入队列(2分)if (p->Rchild)EnQueue(Q, p->Rchild); // 右子树根入队列(2分)} // while}。


全国2011年1月高等教育自学考试数据结构试题(课程代码:02331)一、单项选择题(本大题共15小题,每小题2分,共30分)在每小题列出的四个备选项中只有一个是符合题目要求的,请将其代码填写在题后的括号内。
错选、多选或未选均无分。
1.下列选项中与数据存储结构无关的术语是()A.顺序表B.链表C.链队列D.栈2.将两个各有n个元素的有序表归并成一个有序表,最少的比较次数是()A.n-1B.nC.2n-1D.2n3.已知循环队列的存储空间大小为m,队头指针front指向队头元素,队尾指针rear指向队尾元素的下一个位置,则向队列中插入新元素时,修改指针的操作是()A.rear=(rear-1)%m;B.front=(front+1)%m;C.front=(front-1)%m;D.rear=(rear+1)%m;4.递归实现或函数调用时,处理参数及返回地址,应采用的数据结构是()A.堆栈B.多维数组C.队列D.线性表5.设有两个串p和q,其中q是p的子串,则求q在p中首次出现位置的算法称为()A.求子串B.串联接C.串匹配D.求串长6.对于广义表A,若head(A)等于tail(A),则表A为()A.( )B.(( ))C.(( ),( ))D.(( ),( ),( ))7.若一棵具有n(n>0)个结点的二叉树的先序序列与后序序列正好相反,则该二叉树一定是()A.结点均无左孩子的二叉树 B.结点均无右孩子的二叉树C.高度为n的二叉树D.存在度为2的结点的二叉树8.若一棵二叉树中度为l的结点个数是3,度为2的结点个数是4,则该二叉树叶子结点的个数是()A.4B.5C.7D.89.下列叙述中错误的是()A.图的遍历是从给定的源点出发对每一个顶点访问且仅访问一次B.图的遍历可以采用深度优先遍历和广度优先遍历C.图的广度优先遍历只适用于无向图D.图的深度优先遍历是一个递归过程10.已知有向图G=(V,E),其中V={V1,V2,V3,V4},E={<V1,V2>,<V1,V3>,<V2,V3>,<V2,V4>,<V3,V4>},图G的拓扑序列是()A.V1,V2,V3,V4B.V1,V3,V2,V4C.V1,V3,V4,V2D.V1,V2,V4,V311.平均时间复杂度为O(n log n)的稳定排序算法是()A.快速排序B.堆排序C.归并排序D.冒泡排序12.已知关键字序列为(51,22,83,46,75,18,68,30),对其进行快速排序,第一趟划分完成后的关键字序列是()A.(18,22,30,46,51,68,75,83)B.(30,18,22,46,51,75,83,68)C.(46,30,22,18,51,75,68,83)D.(30,22,18,46,51,75,68,83)13.某索引顺序表共有元素395个,平均分成5块。
第一章绪论1.1 简述下列概念:数据、数据元素、数据类型、数据结构、逻辑结构、存储结构、线性结构、非线性结构。
● 数据:指能够被计算机识别、存储和加工处理的信息载体。
● 数据元素:就是数据的基本单位,在某些情况下,数据元素也称为元素、结点、顶点、记录。
数据元素有时可以由若干数据项组成。
● 数据类型:是一个值的集合以及在这些值上定义的一组操作的总称。
通常数据类型可以看作是程序设计语言中已实现的数据结构。
● 数据结构:指的是数据之间的相互关系,即数据的组织形式。
一般包括三个方面的内容:数据的逻辑结构、存储结构和数据的运算。
● 逻辑结构:指数据元素之间的逻辑关系。
● 存储结构:数据元素及其关系在计算机存储器内的表示,称为数据的存储结构.● 线性结构:数据逻辑结构中的一类。
它的特征是若结构为非空集,则该结构有且只有一个开始结点和一个终端结点,并且所有结点都有且只有一个直接前趋和一个直接后继。
线性表就是一个典型的线性结构。
栈、队列、串等都是线性结构。
● 非线性结构:数据逻辑结构中的另一大类,它的逻辑特征是一个结点可能有多个直接前趋和直接后继。
数组、广义表、树和图等数据结构都是非线性结构。
1.2 试举一个数据结构的例子、叙述其逻辑结构、存储结构、运算三个方面的内容。
答:例如有一张学生体检情况登记表,记录了一个班的学生的身高、体重等各项体检信息。
这张登记表中,每个学生的各项体检信息排在一行上。
这个表就是一个数据结构。
每个记录(有姓名,学号,身高和体重等字段)就是一个结点,对于整个表来说,只有一个开始结点(它的前面无记录)和一个终端结点(它的后面无记录),其他的结点则各有一个也只有一个直接前趋和直接后继(它的前面和后面均有且只有一个记录)。
这几个关系就确定了这个表的逻辑结构是线性结构。
这个表中的数据如何存储到计算机里,并且如何表示数据元素之间的关系呢? 即用一片连续的内存单元来存放这些记录(如用数组表示)还是随机存放各结点数据再用指针进行链接呢? 这就是存储结构的问题。
accesses.(C) Eliminate the recursive calls. (D) Reduce main memory use.(7) Given an array as A[m] [n]. Supposed that A [0] [0] is located at 644(10) and A [2][2] is stored at 676(10), and every element occupies one space. “(10)” means that thenumber is presented in decimals. Then the element A [1] [1](10) is at position:( D)(A) 692 (B) 695 (C) 650 (D) 660(8) If there is 1MB working memory, 4KB blocks, and yield 128 blocks for workingmemory. By the multi-way merge in external sorting, the average run size and the sorted size in one pass of multi-way merge on average are separately ( C)?(A) 1MB, 128 MB (B) 2MB, 512MB(C) 2MB, 256MB (D) 1MB, 256MB(9) In the following sorting algorithms, which is the best one to find the first 10biggest elements in the 1000 unsorted elements? ( B )(A) Quick-sort (B) Heap sort(C ) Insertion sort (D) Replacement selection(10) Assume that we have eight records, with key values A to H, and that they areinitially placed in alphabetical order. Now, consider the result of applying the following access pattern: F D F G E G F A D F G E if the list is organized by the Move-to-front heuristic, then the final list will be ( B).(A)F G D E A B C H (B) E G F D A B C H(C) A B F D G E C H (D) E G F A C B D H2. Fill the blank with correct C++ codes: (16 scores)(1)Given an array storing integers ordered by distinct value without duplicate, modify the binarysearch routines to return the position of the integer with the greatest value less than K when K itself does not appear in the array. Return ERROR if the lest value in the array is greater than K:(10 scores)// Return position of greatest element < Kint newbinary(int array[], int n, int K) {int l = -1;int r = n; // l and r beyond array boundswhile (l+1 != r) { // Stop when l and r meet___ int i=(l+r)/2_____;// Look at middle of subarrayif (K < array[i]) __ r=i ___; // In left halfif (K == array[i]) return i ; // Found itif (K > array[i]) ___ l=i ___ // In right half}// K is not in array or the greatest value is less than Kif K> array[0] (or l!= -1)// the lest value in the array is greater than K with l updated return l ; // when K itself does not appear in the arrayelse return ERROR; // the integer with the lest value greater than K}(2) The number of nodes in a complete binary tree as big as possible with height h is 2h -1(suppose 1-node tree ’s height is 1) (3 scores)(3) The number of different shapes of binary trees with 6 nodes is _132. (3 scores)3. A certain binary tree has the post-order enumeration as EDCBIHJGFA and the in-order enumeration as EBDCAFIHGJ. Try to draw the binary tree and give the postorder enumeration. (The process of your solution is required!!!) (6 scores)preorder enumeration: ABECDFGHIJ4. Determine Θ for the following code fragments in the average case. Assume that all variables are of type int. (6 scores) (1) sum=0;for (i=0; i<5; i++) for (j=0; j<n; j++)sum++; solution : Θ___(n)_______(2) sum = 0;for(i=1;i<=n;i++) for(j=n;j>=i;j--)sum++; solution : Θ__(n 2)________(3) sum=0;if (EVEN(n))for (i=0; i<n; i++) sum++; elsesum=sum+n; solution : Θ___(n)_____5. Show the min-heap that results from running buildheap on the following values stored in an array: 4, 2, 5, 8, 3, 6, 10, 14. (6 scores)6. Design an algorithm to transfer the score report from 100-point to 5-point , the level E corresponding score<60, 60~69 being D, 70~79 being C, 80~89 as B ,score>=90 as A. The distribution table is as following. Please describe your algorithm using a decision tree and give the total path length. (9 scores)Score in 100-point 0-59 60-69 70-79 80-89 90-100 Distribution rate5%10%45%35%5%solution:the design logic is to build a Huffman treeTotal length: 4 * 10% +10% * 3 + 15 %* 3 + 35% * 2 + 45% = 2.25, the 0-false,1-true as thelogic branches.7. Assume a disk drive is configured as follows. The total storage is approximately 675M divided among 15 surfaces. Each surface has 612 tracks; there are 144 sectors/track, 512 byte/sector, and 16 sectors/cluster. The interleaving factor is 3. The disk turns at 7200rmp (8.3ms/r). The track-to-track seek time is 20 ms, and the average seek time is 80 ms. Now how long does it take to read all of the data in a 360 KB file on the disk? Assume that the file ’s clusters are spread randomly across the disk. A seek must be performed each time the I/O reader moves to a new track. Show your calculations. (The process of your solution is required!!!) (9 scores) Solution :A cluster holds 16*0.5K = 8K. Thus, the file requires 360/8=45clusters.The time to read a cluster is seek time to the cluster+ latency time + (interleaf factor × rotation time).Average seek time is defined to be 80 ms. Latency time is 0.5 *8.3, and cluster rotation time is 3 * (16/144)*8.3.Seek time for the total file read time is 45* (80 + 0.5 * 8.3+ 3 * (16/144)*8.3 ) = 3911.258. Using closed hashing, with double hashing to resolve collisions, insert the following keys into a hash table of eleven slots (the slots are numbered 0 through 10). The hash functions to be used are H1 and H2, defined below. You should show the hash table after all eight keys have been inserted. Be sure to indicate how you areusing H1 and H2 to do the hashing. ( The process of your solution is required!!!) H1(k) = 3k mod 11 H2(k) = 7k mod 10+1Keys: 22, 41, 53, 46, 30, 13, 1, 67.(9 scores)Solution :H1(22)=0, H1(41)=2, H1(53)=5, H1(46)=6, no conflictWhen H1(30)=2, H2(30)=1 (2+1*1)%11=3,so 30 enters the 3rd slot; H1(13)=6, H2(13)=2 (6+1*2)%11=8, so 13 enters the 8th slot;H1(1)=3, H2(1)=8 (3+5*8)%11= 10 so 1 enters 10 (pass by 0, 8, 5, 2 );9. You are given a series of records whose keys are chars. The records arrive in the following order: C, S, D, T, A, M, P, I, B, W, N, G , U, R. Show the 2-3 tree that results from inserting these records. (the process of your solution is required!!!) (9 scores) Solution :MSBD PU A C GI N R T W 10.The following graph is a communication network in some area, whose edge presents the channel between two cities with the weight as the channel ’s cost. How to choose the cheapest path that can connect all cities? And how to get cheapest paths scores)Solution :1,C to A: 4 (C,A); CF: 5(C,F); CD: 6(C,A,D); CB: 12(C,A,D,B); CG:11 (C,F,G); CE: 13(C,A,D,B,E)2. Draw the MST: It is a Hamilton path.。
第2章线性表2.算法设计题(1)将两个递增的有序链表合并为一个递增的有序链表。
要求结果链表仍使用原来两个链表的存储空间, 不另外占用其它的存储空间。
表中不允许有重复的数据。
void MergeList_L(LinkList &La,LinkList &Lb,LinkList &Lc){pa=La->next; pb=Lb->next;Lc=pc=La; //用La的头结点作为Lc的头结点while(pa && pb){if(pa->data<pb->data){ pc->next=pa;pc=pa;pa=pa->next;}else if(pa->data>pb->data) {pc->next=pb; pc=pb; pb=pb->next;}else {// 相等时取La的元素,删除Lb的元素pc->next=pa;pc=pa;pa=pa->next;q=pb->next;delete pb ;pb =q;}}pc->next=pa?pa:pb; //插入剩余段delete Lb; //释放Lb的头结点}(2)将两个非递减的有序链表合并为一个非递增的有序链表。
要求结果链表仍使用原来两个链表的存储空间, 不另外占用其它的存储空间。
表中允许有重复的数据。
void union(LinkList& La, LinkList& Lb, LinkList& Lc, ) {pa = La->next; pb = Lb->next; // 初始化Lc=pc=La; //用La的头结点作为Lc的头结点Lc->next = NULL;while ( pa || pb ) {if ( !pa ) { q = pb; pb = pb->next; }else if ( !pb ) { q = pa; pa = pa->next; }else if (pa->data <= pb->data ) { q = pa; pa = pa->next; }else { q = pb; pb = pb->next; }q->next = Lc->next; Lc->next = q; // 插入}delete Lb; //释放Lb的头结点}(3)已知两个链表A和B分别表示两个集合,其元素递增排列。
《数据结构》部分一、简答题(20 分,每题 5 分)1、请给出4 类常用的基本数据结构类型。
(课本p5第6行)答:根据数据元素之间关系的不同特征,通常有下列4类的基本结构:(1)集合。
(2)线性结构。
(3)树形结构。
(4)图状结构或网状结构。
2、什么是哈希表?(课本P253第2行)答:根据设定的哈希函数H(key)和处理冲突的方法,将一组关键字映射到一个有限的、连续的地址集(区间)上,并以关键字在地址集上的“像”作为记录在表中的存储位置,这种表便称为哈希表。
3、请比较简单排序、快速排序、堆排序、归并排序的算法效率和稳定性。
(课本P289)(算法效率的概念P14;稳定性的概念P263;简单排序也就是除希尔排序之外的所有插入排序P265;快速排序P272;堆排序P279;归并排序P283)答:4、请比较普里姆算法与克鲁斯卡尔算法解决图最小生成树问题的时间复杂度。
(课本P175)(最小生成树:P173;普里姆算法P173;克鲁斯卡尔算法P175)答:普里姆算法的时间复杂度为O(n2)(假设网中有n个顶点),与网中的边数无关,因此适用于求边稠密的网的最小生成树。
而克鲁斯卡尔算法恰恰相反,它的时间复杂度为O(eloge)(e为网中边的数目),因此它相对于普里姆算法而言,适合于求边稀疏的网的最小生成树。
二、应用题(50 分)1、已知二叉树的前序遍历、中序遍历的结果分别是:ABDEFGCHIJ 和DBFEGAHCIJ,请画出对应的二叉树,给出后序遍历的结果,并将它转换成等价的树或森林。
(10 分)(二叉树的前序遍历、中序遍历P128;树P137;森林P138)答:2、某带权有向图及它的邻接表如下:(1)试写出它的深度优先搜索序列。
(深度优先搜索P167;邻接表P163;广度优先搜素P169)答:A-->B-->D-->C-->F-->E-->G--H(提示:不要画图,直接根据邻接表画)(2)根据普里姆(Prim)算法,求它的从顶点A 出发的最小生成树。
武汉大学计算机学院2011年-2012学年第一学期“数据结构”考试试题(A)要求:所有的题目的解答均写在答题纸上,需写清楚题目的序号。
每张答题纸都要写上姓名和学号。
一、单项选择题(共20小题,每小题2分,共40分)1. 下列各选项中属于逻辑结构的是。
A.哈希表B.有序表C.单链表D.顺序表2. 对于数据结构,以下叙述中不正确的是。
A.数据的逻辑结构与数据元素本身的形式和内容无关B.数据的逻辑结构是数据的各数据项之间的逻辑关系C.数据元素是数据的基本单位D.数据项是数据的最小单位3. 某算法的时间复杂度为O(n2),表明该算法的。
A.问题规模是n2B.执行时间等于n2C.执行时间与n2成正比D.问题规模与n2成正比4. 通常在单链表中增加一个头节点,其目的是为了。
A.使单链表至少有一个节点B.标识表节点中首节点的位置C.方便单链表运算的实现D.说明单链表是线性表的链式存储5. 删除某个双链表中的一个节点(非首、尾节点),需要修改个指针域。
A.1B.2C.3D.46. 栈和队列是两种不同的数据结构,但它们中的元素具有相同的。
A.抽象数据类型B.逻辑结构C.存储结构D.运算7. 元素a、b、c、d、e依次进入初始为空的栈中,若元素进栈后可停留、可出栈,直到所有的元素都出栈,则所有可能的出栈序列中,以元素d开头的序列个数是。
A.3B.4C.5D.68. 设环形队列中数组的下标是0~N-1,其头尾指针分别为f和r(f指向队列中队头元素的前一个位置,r指向队尾元素的位置),则其元素个数为。
A.r-fB.r-f-1C.(r-f)%N+1D.(r-f+N)%N9. 已知循环队列存储在一维数组A[0..n-1]中,且队列非空时front和rear分别指向队头元素和队尾元素。
若初始时队列空,且要求第一个进入队列的元素存储在A[0]处,则初始时front和rear的值分别是。
A.0,0B.0,n-1C.n-1,0D.n-1,n-110. 对于n阶(n≥2)对称矩阵,采用压缩方法以行序优先存放到内存中,则需要个存储单元。
A.n(n+1)/2B.n(n-1)/2C.n2D.n2/211. 一棵度为4的树T中,若有20个度为4的节点,10个度为3的节点,1个度为2的节点,10个度为1的节点,则树T的叶子节点个数是。
A.41B.82C.113D.12212. 一个具有n(n≥2)个顶点的无向图,至少有①个连通分量,最多有②个连通分量。
A.0B.1C.n-1D.n13. 含有n(n≥2)个顶点的无向图的邻接矩阵必然是一个。
A.对称矩阵B.零矩阵C.上三角矩阵D.对角矩阵14. 对如图1所示的无向图,从顶点A出发得到的广度优先序列可能是。
A.ABECDB.ACBDEC.ACDBED.ABDEC图1 一个无向图15. 设有100个元素的有序顺序表,用折半查找时,成功时最大的比较次数是。
A.25B.50C.10D.716. 已知一个长度为16的顺序表,其元素按关键字有序排序,若采用折半查找法查找一个不存在的元素,则平均关键字比较的次数是。
A.70/17B.70/16C.60/17D.60/1617. 以下关于m阶B-树的叙述中正确的是。
A.每个节点至少有两棵非空子树B.树中每个节点至多有⎡m/2⎤-1个关键字C.所有叶子节点均在同一层上D.当插入一个关键字引起B-树节点分裂时,树增高一层18. 为提高散列(哈希)表的查找效率,可以采取的正确措施是。
Ⅰ.增大装填(载)因子Ⅱ.设计冲突(碰撞)少的散列函数Ⅲ.处理冲突(碰撞)时避免产生聚集(堆积)现象A.仅ⅠB.仅ⅡC.仅Ⅰ、ⅡD.仅Ⅱ、Ⅲ19. 数据序列{8,9,10,4,5,6,20,1,2}只能是的两趟排序后的结果。
A.简单选择排序B.冒泡排序C.直接插入排序D.堆排序20. 用某种排序方法对顺序表{24,88,21,48,15,27,69,35,20}进行排序,各趟元素序列的变化情况如下:(1){24,88,21,48,15,27,69,35,20}(2){20,15,21,24,48,27,69,35,88}(3){15,20,21,24,35,27,48,69,88}(4){15,20,21,24,27,35,48,69,88}则所采用的排序方法是。
A.快速排序B.简单选择排序C.直接插入排序D.归并排序二、问答题(共3小题,每小题10分,共30分)1. 一棵二叉排序树按先序遍历得到的关键字序列为:(50,38,30,45,40,48,70,60,75,80)。
回答以下问题:(1)画出该二叉排序树。
(2)求在等概率条件下的查找成功的平均查找长度。
2. 有一个无向带权图如图2所示,采用Dijkstra算法求顶点0到其他顶点的最短路径和最短路径长度,要求给出求解过程(即给出求最短路径中各步骤的S、dist和path值)。
图2 一个无向图3. 简要叙述堆和二叉排序树的区别,并给出关键字序列{3,26,12,61,38,40,97,75,53,87}调整为大根堆后的结果(直接画出调整后的大根堆)。
三、算法设计题(共3小题,每小题10分,共30分)1.有一个线性表(a1,a2,…,a n),采用带头节点的单链表L存储,设计一个就地算法将其所有元素逆置。
所谓就地算法是指算法的空间复杂度为O(1)。
2.假设二叉树采用二叉链存储结构,设计一个算法把一棵含有n个节点的二叉树b复制到另一棵二叉树t中。
给出你所设计算法的时间和空间复杂度。
3. 假设一个不带权的有向图G采用邻接表存储,设计一个算法判断图G中是否存在顶点i到顶点j的边,若存在这样的边返回1,否则返回0。
武汉大学计算机学院2011年-2012学年第一学期“数据结构”考试试题参考答案(A)要求:所有的题目的解答均写在答题纸上,需写清楚题目的序号。
每张答题纸都要写上姓名和序号。
一、单项选择题(每小题2分,共40分)1. B2. B3. C4. C5. B6. B7. B8. D9. B 10. A11. B 12. ①B ②D 13. A 14. B 15. D16. A 17. C 18. D 19. C 20. A二、问答题(共3小题,共30分)1.答(1)先序遍历得到的序列为:(50,38,30,45,40,48,70,60,75,80),中序序列是一个有序序列,所以为:(30,38,40,45,48,50,60,70,75,80),由先序序列和中序序列可以构造出对应的二叉树,如下图所示。
(2)ASL成功=(1×1+2×2+4×3+3×4)/10=2.9。
【评分说明】(1)占8分,(2)占2分。
2. 答:对应的邻接矩阵如下:0 7 11 ∞∞∞7 0 10 9 ∞∞11 10 0 5 7 8∞9 5 0 ∞∞∞∞7 ∞0 6∞∞8 ∞ 6 0求解过程如下:S dist path0 1 2 3 4 5 0 1 2 3 4 5数据结构试题 5{0} 0 7 11 ∞∞∞0 0 0 -1 -1 -1 {01} 0 7 11 16 ∞∞0 0 0 1 -1 -1 {0 1 2} 0 7 11 16 18 19 0 0 0 1 2 2{0 1 2 3} 0 7 11 16 18 19 0 0 0 1 2 2{0 1 2 3 4} 0 7 11 16 18 19 0 0 0 1 2 2{0 1 2 3 4 5} 0 7 11 16 18 19 0 0 0 1 2 2求解结果如下:从0到1的最短路径长度为:7 路径为:0,1从0到2的最短路径长度为:11 路径为:0,2从0到3的最短路径长度为:16 路径为:0,1,3从0到4的最短路径长度为:18 路径为:0,2,4从0到5的最短路径长度为:19 路径为:0,2,5【评分说明】结果为5分,过程为5分。
3. 简要叙述堆和二叉排序树的区别,并给出关键字序列{3,26,12,61,38,40,97,75,53,87}调整为大根堆后的结果(直接画出调整后的大根堆)。
答:以小根堆为例,堆的特点是双亲节点的关键字必然小于等于孩子节点的关键字,而两个孩子节点的关键字没有次序规定。
而二叉排序树中,每个双亲节点的关键字均大于左子树节点的关键字,每个双亲节点的关键字均小于右子树节点的关键字,也就是说,每个双亲节点的左、右孩子的关键字有次序关系。
关键字序列{3,26,12,61,38,40,97,75,53,87}调整为大根堆后的结果如下:【评分说明】两小题各占5分。
三、算法设计题(每小题10分,共30分)1.解:对应的算法如下:void Reverse1(LinkList *&L){ LinkList *p=L->next,*q; //p指向开始节点L->next=NULL;while (p!=NULL){ q=p->next;p->next=L->next; //将*p节点插入到新建链表的前面L->next=p;p=q;}}【评分说明】单链表类型可自行设计。
2.解:对应的递归算法如下:void Copy(BTNode *b,BTNode *&t){ if (b==NULL)t=NULL;else{ t=(BTNode *)malloc(sizeof(BTNode));t->data=b->data; //复制一个根节点*tCopy(b->lchild,t->lchild); //递归复制左子树Copy(b->rchild,t->rchild);//递归复制右子树}}算法的时间复杂度为O(n),空间复杂度为O(n)。
【评分说明】二叉链类型可自行设计。
【评分说明】算法的时间和空间复杂度各占1分。
3. 解:对应的算法如下:int HasArc(AGraph *G,int i,int j) //判断图G中是否存在边<i,j> { ArcNode *p;p=G->adjlist[i].firstarc;while (p!=NULL && p->adjvex!=j)p=p->nextarc;if (p==NULL)return 0;elsereturn 1;}【评分说明】邻接表类型可自行设计。