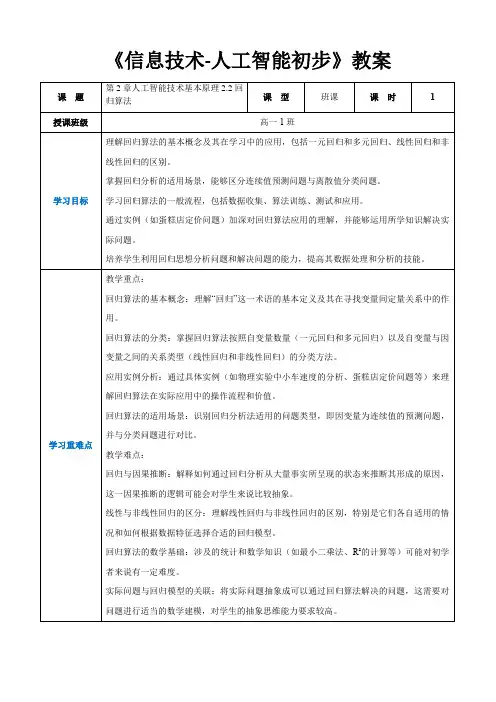
回归预测的知识与常用方法
- 格式:ppt
- 大小:247.50 KB
- 文档页数:36

回归分析的基本知识点及习题本周难点:(1)求回归直线方程,会用所学的知识对实际问题进行回归分析.(2)掌握回归分析的实际价值与基本思想.(3)能运用自己所学的知识对具体案例进行检验与说明.(4)残差变量的解释;(5)偏差平方和分解的思想;1.回归直线:如果散点图中点的分布从整体上看大致在一条直线附近,我们就称这两个变量之间具有线性相关关系,这条直线叫作回归直线。
求回归直线方程的一般步骤:①作出散点图(由样本点是否呈条状分布来判断两个量是否具有线性相关关系),若存在线性相关关系→②求回归系数→③写出回归直线方程,并利用回归直线方程进行预测说明.2.回归分析:对具有相关关系的两个变量进行统计分析的一种常用方法。
建立回归模型的基本步骤是:①确定研究对象,明确哪个变量是解释变量,哪个变量是预报变量;②画好确定好的解释变量和预报变量的散点图,观察它们之间的关系(线性关系).③由经验确定回归方程的类型.④按一定规则估计回归方程中的参数(最小二乘法);⑤得出结论后在分析残差图是否异常,若存在异常,则检验数据是否有误,后模型是否合适等.4.残差变量的主要来源:(1)用线性回归模型近似真实模型(真实模型是客观存在的,通常我们并不知道真实模型到底是什么)所引起的误差。
可能存在非线性的函数能够更好地描述与之间的关系,但是现在却用线性函数来表述这种关系,结果就会产生误差。
这种由于模型近似所引起的误差包含在中。
(2)忽略了某些因素的影响。
影响变量的因素不只变量一个,可能还包含其他许多因素(例如在描述身高和体重关系的模型中,体重不仅受身高的影响,还会受遗传基因、饮食习惯、生长环境等其他因素的影响),但通常它们每一个因素的影响可能都是比较小的,它们的影响都体现在中。
(3)观测误差。
由于测量工具等原因,得到的的观测值一般是有误差的(比如一个人的体重是确定的数,不同的秤可能会得到不同的观测值,它们与真实值之间存在误差),这样的误差也包含在中。

高三回归方程知识点汇总回归方程是数学中重要的数学模型,用于描述变量之间的关系和进行预测。
在高三阶段,学生需要掌握回归分析的基本知识和技巧。
本文将对高三数学中回归方程的知识点进行全面汇总,并提供一些实例和应用场景供参考。
一、线性回归方程1.1 线性关系与线性回归方程线性关系指的是两个变量之间存在直线关系,可用一条直线来近似表示。
线性回归方程是线性关系的数学表达式,常用形式为 y = kx + b,其中 k 表示直线的斜率,b 表示直线在 y 轴上的截距。
1.2 最小二乘法最小二乘法是确定线性回归方程中斜率 k 和截距 b 的常用方法。
它通过最小化观测值与回归直线的拟合误差平方和,找到最佳的拟合直线。
1.3 直线拟合与误差分析直线拟合是利用线性回归方程将观测数据点拟合到一条直线上。
误差分析可以评估回归方程的拟合优度,常用指标有决定系数R²、平均绝对误差 MAE 等。
二、非线性回归方程2.1 非线性关系与非线性回归方程非线性关系指的是两个变量之间的关系不能用一条直线来近似表示,而是需要使用曲线或其他非线性形式进行描述。
非线性回归方程可以是多项式方程、指数方程、对数方程等形式。
2.2 最小二乘法拟合非线性回归方程与线性回归相似,最小二乘法也可以用于拟合非线性回归方程。
但由于非线性方程的复杂性,通常需要借助计算工具进行求解,例如利用数学软件进行非线性拟合。
2.3 模型选择和拟合优度检验在选择非线性回归模型时,需要综合考虑模型的拟合优度和实际应用的需求。
常见的方法包括比较不同模型的决定系数 R²、检验残差分布等。
三、应用实例3.1 人口增长模型以某地区的人口数据为例,通过拟合合适的回归方程,可以预测未来的人口增长趋势,为城市规划和社会发展提供决策依据。
3.2 经济增长模型回归方程可以用于分析经济数据,例如拟合国民生产总值与时间的关系,预测未来的经济增长态势,为政府制定经济政策提供参考。
3.3 科学实验数据分析在科学研究中,常常需要利用回归方程对实验数据进行拟合和分析。

回归系数的估计方法-回复回归系数的估计方法是在回归分析中使用的一种统计技术。
回归分析用于研究因变量与自变量之间的关系,并且可以预测因变量的值。
回归系数是用来衡量自变量对因变量的影响程度的指标。
本文将介绍常用的回归系数估计方法,并对每个方法进行详细说明和比较。
回归系数的估计方法主要有:最小二乘法、最大似然估计和贝叶斯估计。
最小二乘法是回归分析中最常用的估计方法。
该方法的基本思想是通过最小化观测数据与回归线之间的残差平方和来估计回归系数。
残差是预测值与实际观测值之间的差异,在最小二乘法中,我们尝试找到一条回归线,使得所有观测值与该回归线的残差平方和最小。
通过最小二乘法估计的回归系数具有良好的统计性质,包括无偏性和最小方差性。
最小二乘法适用于线性回归和非线性回归模型。
最大似然估计是另一种常用的回归系数估计方法。
该方法的基本思想是找到一组回归系数,使得对观测数据的似然函数达到最大。
似然函数是描述观测数据在给定模型下出现的概率,通过最大化似然函数,我们可以得到最有可能生成观测数据的回归系数估计。
最大似然估计方法通常需要对数据的分布做出一些假设,例如正态分布假设。
与最小二乘法不同,最大似然估计方法能够提供回归系数的置信区间,用于评估回归系数的统计显著性。
贝叶斯估计是一种基于贝叶斯统计理论的回归系数估计方法。
该方法的特点是将先验分布与观测数据进行结合,得到后验分布,并且通过后验分布来估计回归系数。
在贝叶斯估计中,先验分布可以是任意的概率分布,可以通过专家知识或历史数据进行设定。
通过后验分布,我们可以得到回归系数的点估计和区间估计,并且可以对不确定性进行概括。
贝叶斯估计方法通常需要进行模型的较复杂的计算,但在面对数据不完备或先验不确定的情况下具有一定的优势。
在实际应用中,选择适合的回归系数估计方法取决于具体的问题和数据特征。
最小二乘法是一种简单直观的估计方法,适用于大多数的回归问题。
最大似然估计方法对数据的概率分布做出假设,可以提供回归系数的统计显著性。

非线性回归分析的入门知识在统计学和机器学习领域,回归分析是一种重要的数据分析方法,用于研究自变量和因变量之间的关系。
在实际问题中,很多情况下自变量和因变量之间的关系并不是简单的线性关系,而是呈现出一种复杂的非线性关系。
因此,非线性回归分析就应运而生,用于描述和预测这种非线性关系。
本文将介绍非线性回归分析的入门知识,包括非线性回归模型的基本概念、常见的非线性回归模型以及参数估计方法等内容。
一、非线性回归模型的基本概念在回归分析中,线性回归模型是最简单和最常用的模型之一,其数学表达式为:$$Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + ... + \beta_pX_p +\varepsilon$$其中,$Y$表示因变量,$X_1, X_2, ..., X_p$表示自变量,$\beta_0, \beta_1, \beta_2, ..., \beta_p$表示模型的参数,$\varepsilon$表示误差项。
线性回归模型的关键特点是因变量$Y$与自变量$X$之间呈线性关系。
而非线性回归模型则允许因变量$Y$与自变量$X$之间呈现非线性关系,其数学表达式可以是各种形式的非线性函数,例如指数函数、对数函数、多项式函数等。
一般来说,非线性回归模型可以表示为:$$Y = f(X, \beta) + \varepsilon$$其中,$f(X, \beta)$表示非线性函数,$\beta$表示模型的参数。
非线性回归模型的关键在于确定合适的非线性函数形式$f(X,\beta)$以及估计参数$\beta$。
二、常见的非线性回归模型1. 多项式回归模型多项式回归模型是一种简单且常见的非线性回归模型,其形式为: $$Y = \beta_0 + \beta_1X + \beta_2X^2 + ... + \beta_nX^n +\varepsilon$$其中,$X^2, X^3, ..., X^n$表示自变量$X$的高次项,$\beta_0, \beta_1, \beta_2, ..., \beta_n$表示模型的参数。

高考文科线性回归知识点高考文科数学考试中,线性回归是一个重要的知识点。
线性回归是一种统计分析方法,通过建立一个数学模型来描述两个变量之间的关系。
在文科领域,线性回归常常被用来分析人文社科问题,预测社会现象的趋势和发展。
一、线性回归的基本概念线性回归是通过一条直线来描述两个变量之间的关系。
其中,自变量是独立变量,也叫做解释变量;因变量是被解释变量,也叫做预测变量。
线性回归的模型可以表示为:Y = α + βX + ε,其中Y是因变量,X是自变量,α是截距,β是斜率,ε是误差项。
线性回归的目标是找到最佳的α和β,使得模型的预测误差最小。
二、线性回归的假设条件线性回归有几个基本的假设条件。
首先,自变量和因变量之间的关系是线性的;其次,误差项是独立同分布的,即没有自相关性;最后,误差项的方差是常数。
三、线性回归的参数估计线性回归需要通过样本数据来估计模型的参数。
通常采用最小二乘法来估计α和β。
最小二乘法的基本原理是使得观测值与模型的预测值的平方差最小。
通过求导可以得到最小二乘估计的解析解。
四、线性回归的评估指标在线性回归中,评估模型的好坏是十分重要的。
常用的评估指标包括拟合优度R²、均方根误差RMSE、平均绝对误差MAE等。
拟合优度R²表示模型解释变量的变异程度,取值范围为0到1,越接近1表示模型的拟合程度越好。
均方根误差RMSE和平均绝对误差MAE表示模型的预测误差大小,一般来说,误差越小表示模型的预测能力越好。
五、线性回归的应用领域线性回归是一种广泛应用于社科领域的统计方法。
以经济学为例,线性回归可以用来分析不同变量之间的关系,比如GDP与人均收入、失业率与通货膨胀等。
通过线性回归分析,可以为经济政策的制定提供科学依据。
此外,线性回归还可以应用于社会学、心理学、教育学等领域,帮助研究人员发现变量之间的关系。
六、线性回归的局限性线性回归虽然在很多领域有广泛应用,但也有一定的局限性。



U4 违背基本假设的情况一、异方差产生的原因在建立实际问题的回归分析模型时,经常会出现某一因素或一些因素随着解释变量观测值的变化而对被解释变量产生不同的影响,导致随机误差项产生不同的方差。
即:)var()var(j i εε≠,当j i ≠时。
样本数据为截面数据时容易出现异方差性。
二、异方差性带来的问题1、参数估计值虽然是无偏的,但不是最小方差线性无偏估计。
2、参数的显著性检验失效。
3、回归方程的应用效果极不理想。
三、异方差性的检验1、残差图分析法残差图分析法是一种只管、方便的分析方法。
它以残差i e 为纵坐标,以其他适宜的变量为横坐标画散点图。
常用的横坐标有三种选择:(1)以拟合值yˆ为横坐标;(2)以i x (p i ,,2,1 =)为横坐标;(3)以观测时间或序号为横坐标。
(a)线性关系成立;(b)x 加入二次方项;(c)存在异方差,需要改变x 形式 (d)残差与时间t 有关。
可能遗漏变量或者存在序列相关,需要引入变量。
2、等级相关系数法等级相关系数又称斯皮尔曼(Spearman)检验,是一种应用较广泛的方法。
这种检验方法既可用于大样本,也可以用于小样本。
进行等级相关系数检验通常有三个步骤:第一步,做y 关于x 的普通最小二乘回归,求出i ε的估计值,即i e 的值 第二步,取i e 的绝对值,即|i e |,把i x 和|i e |按递增或递减的次序排列后分成等级,按下式计算出等级相关系数:∑=--=n i i s d n n r 122)1(61,其中,n 为样本容量,i d 为对应于i x 和|i e |的等级的差数。
第三步,做等级相关系数的显著性检验。
在n>8的情况下,用下式对样本等级相关系数s r 进行t 检验,检验统计量为:212s sr r n t --=,如果)2(-≤n t t α可以认为异方差性问题不存在,如果)2(2->n t t α,说明i x 与|i e |之间存在系统关系,异方差性问题存在。

回归分析方法
回归分析是一种统计学方法,用于研究自变量与因变量之间的关系。
在实际应用中,回归分析可以帮助我们预测未来的趋势,分析变量之间的影响关系,以及找出影响因变量的主要因素。
本文将介绍回归分析的基本概念、常见方法和实际应用。
首先,回归分析可以分为简单线性回归和多元线性回归两种基本类型。
简单线性回归是指只有一个自变量和一个因变量的情况,而多元线性回归则是指有多个自变量和一个因变量的情况。
在进行回归分析时,我们需要先确定自变量和因变量的关系类型,然后选择合适的回归模型进行拟合和预测。
常见的回归模型包括最小二乘法、岭回归、Lasso回归等。
最小二乘法是一种常用的拟合方法,通过最小化残差平方和来找到最佳拟合直线或曲线。
岭回归和Lasso回归则是在最小二乘法的基础上引入了正则化项,用于解决多重共线性和过拟合的问题。
选择合适的回归模型可以提高模型的预测准确性和稳定性。
在实际应用中,回归分析可以用于市场营销预测、金融风险评估、医学疾病预测等领域。
例如,我们可以利用回归分析来预测产
品销量与广告投放的关系,评估股票收益率与市场指数的关系,或
者分析疾病发病率与环境因素的关系。
通过回归分析,我们可以更
好地理解变量之间的关系,为决策提供可靠的依据。
总之,回归分析是一种强大的统计工具,可以帮助我们理解变
量之间的关系,预测未来的趋势,并进行决策支持。
在实际应用中,我们需要选择合适的回归模型,进行数据拟合和预测分析,以解决
实际问题。
希望本文对回归分析方法有所帮助,谢谢阅读!。
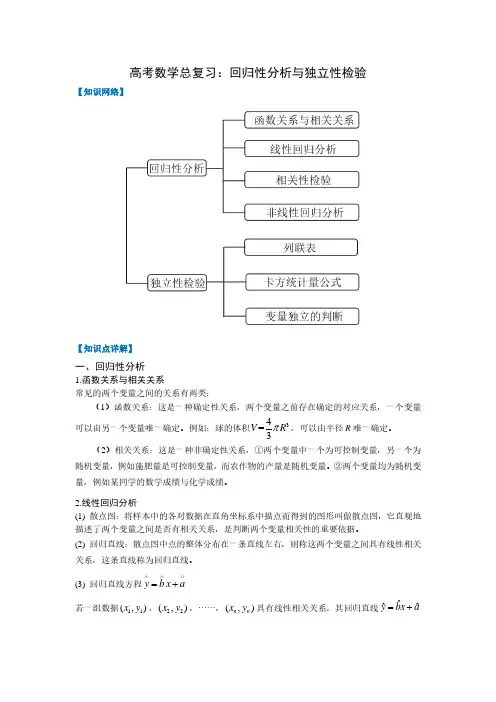
回归分析知识点总结一、回归分析的基本概念1.1 回归分析的概念回归分析是一种通过数学模型建立自变量与因变量之间关系的方法。
该方法可以用来预测数据、解释变量之间的关系以及发现隐藏的模式。
1.2 回归分析的类型回归分析主要可以分为线性回归和非线性回归两种类型。
线性回归是指因变量和自变量之间的关系是线性的,而非线性回归则是指因变量和自变量之间的关系是非线性的。
1.3 回归分析的应用回归分析广泛应用于各个领域,例如经济学、金融学、生物学、医学等。
在实际应用中,回归分析可以用于市场预测、风险管理、医疗诊断、环境监测等方面。
二、回归分析的基本假设2.1 线性关系假设线性回归分析假设因变量和自变量之间的关系是线性的,即因变量的变化是由自变量的变化引起的。
2.2 正态分布假设回归分析假设误差项服从正态分布,即残差在各个预测点上是独立同分布的。
2.3 同方差假设回归分析假设误差项的方差是恒定的,即误差项的方差在不同的自变量取值上是相同的。
2.4 独立性假设回归分析假设自变量和误差项之间是独立的,即自变量的变化不受误差项的影响。
三、回归分析的模型建立3.1 简单线性回归模型简单线性回归模型是最基础的回归分析模型,它只包含一个自变量和一个因变量,并且自变量与因变量之间的关系是线性的。
3.2 多元线性回归模型多元线性回归模型包含多个自变量和一个因变量,它可以更好地描述多个因素对因变量的影响。
3.3 非线性回归模型当因变量和自变量之间的关系不是线性的时候,可以使用非线性回归模型对其进行建模。
非线性回归模型可以更好地捕捉因变量和自变量之间的复杂关系。
四、回归分析的模型诊断4.1 线性回归模型的拟合优度拟合优度是评价线性回归模型预测能力的指标,它可以用来衡量模型对数据的拟合程度。
4.2 回归系数的显著性检验在回归分析中,通常需要对回归系数进行显著性检验,以确定自变量对因变量的影响是否显著。
4.3 多重共线性检验多重共线性是指自变量之间存在高度相关性,这可能导致回归系数估计不准确。
回归直线知识点总结回归直线的基本概念回归直线通常表示为y = β0 + β1x,其中y是因变量,x是自变量,β0和β1分别是截距和斜率。
这条直线能够最好地拟合自变量和因变量之间的关系,使得预测结果和实际观测值的差异最小。
通过回归直线,我们可以得到对于自变量的变化,因变量的预测值,从而进行数据分析和预测。
模型的拟合方法回归直线的拟合通常使用最小二乘法来进行。
最小二乘法是一种常用的参数估计方法,它通过求解使得残差平方和最小的参数值来拟合模型。
残差是观测值与拟合值之间的差异,残差平方和就是所有残差平方的和。
通过最小二乘法,我们可以得到最优的回归直线参数估计值。
参数估计在回归直线模型中,我们通常使用最小二乘法来进行参数估计。
最小二乘法通过最小化残差平方和来估计模型的参数值,得到截距和斜率的估计值。
这些参数估计值反映了自变量和因变量之间的关系,可以用来进行预测和模型分析。
模型评估在回归直线模型中,模型的拟合度是一个非常重要的指标。
我们通常使用R方值来评估模型的拟合度,R方值越接近1,说明模型拟合度越好,预测结果与实际观测值的差异越小。
除了R方值,我们还可以使用残差分析、假设检验等方法来评估模型的拟合度和参数的显著性。
应用领域回归直线在实际应用中有着广泛的应用。
在经济学中,回归直线可以用来预测商品价格、需求量等变量之间的关系,在金融学中,可以用来预测股票价格、汇率等变量之间的关系,在医学中,可以用来预测疾病的发展趋势等。
回归直线的应用领域非常广泛,可以用来进行数据的分析和预测。
总结回归直线是统计学中一个非常重要的概念,它在数据分析、模型拟合、预测等领域都有着广泛的应用。
通过回归直线,我们可以得到自变量和因变量之间的关系,进行数据分析和预测。
回归直线的拟合方法通常使用最小二乘法进行,参数估计和模型评估是回归直线分析的重要步骤。
回归直线在经济学、金融学、医学等领域有着广泛的应用,可以用来预测价格、需求量、股票价格、疾病趋势等。
高考线性回归知识点线性回归是高考数学中的一个重要知识点,它是一种统计学上常用的方法,用于分析两个变量之间的线性关系。
在高考中,线性回归经常被应用于解决实际问题和预测未知数据。
本文将介绍线性回归的基本概念、公式以及应用示例,帮助大家更好地理解和应用这一知识点。
一、线性回归的基本概念线性回归是建立一个自变量X和一个因变量Y之间的线性关系模型,通过最小化实际观测值与模型预测值之间的误差,来拟合和预测因变量Y的值。
线性回归的模型可以表示为:Y = β0 + β1*X + ε其中,Y是因变量,X是自变量,β0是截距,β1是斜率,ε是误差项,代表模型无法准确拟合数据的部分。
二、线性回归的公式1. 简单线性回归如果模型中只有一个自变量X,称为简单线性回归。
简单线性回归的公式为:Y = α + βX + ε其中,α表示截距,β表示斜率,ε为误差项。
我们利用给定的数据集,通过最小二乘法来估计α和β的值,从而得到一条最佳拟合直线。
2. 多元线性回归如果模型中有多个自变量X1、X2、X3...,称为多元线性回归。
多元线性回归的公式为:Y = α + β1*X1 + β2*X2 + β3*X3 + ... + ε同样,我们利用最小二乘法来估计α和每个β的值,从而得到一个最佳拟合的平面或超平面。
三、线性回归的应用示例线性回归在实际问题中有广泛的应用。
下面通过一个简单的例子来说明线性回归的具体应用过程。
例:某城市的房价与面积的关系假设我们要研究某个城市的房价与房屋面积之间的关系。
我们收集了一些房屋的信息,包括房屋的面积和对应的价格。
我们可以使用线性回归来建立一个房价和面积之间的模型,从而预测未知房屋的价格。
1. 数据收集首先,我们收集了一些房屋的面积和价格数据,得到一个数据集。
2. 模型建立根据数据集,我们可以建立一个线性回归模型:价格= α + β*面积+ ε通过最小二乘法,估计出α和β的值。
3. 模型评估为了评估模型的好坏,我们需要计算误差项ε。
数据分析知识:数据分析中的网络回归方法网络回归是数据分析中常用的一种方法。
其主要目的是通过建立模型来预测目标变量。
网络回归是一种有监督学习的方法,其通过使用带权重的连接来组成一个神经网络来实现预测。
网络回归是建立在人工神经网络(ANN)结构上的一种回归分析方法。
人工神经网络专门模拟生物神经网络的特征,由大量基本处理元素(称为神经元)组成,并且通过学习从大量样本中获取数据,并通过调整模型参数,使其产生监督学习,以预测未来的标签。
通过解决大量的数据,用户可以得到预测值,这对于建立基于数据的决策模型是非常有效的。
在网络回归中,一组输入参数被输入到神经网络中,同时神经网络会生成输出结果。
网络回归的基本原理是利用历史数据来训练网络,以便神经网络可以对新数据进行预测。
训练过程涉及批量梯度下降,反向传播等。
其过程基本如下所示:(1)初始化随机权重(2)将数据分为训练数据和测试数据集(3)通过梯度下降进行权重更新(4)重复执行步骤2和步骤3(5)评估训练的标准和参数调整后的模型在网络回归中,最常用的是多层感知器网络(MLP)。
MLP是一种前馈神经网络,其中输入可以连接到隐藏层,而隐藏层可以连接到输出层。
通过使用隐藏层,MLP可以执行非线性函数逼近。
这意味着MLP可以模拟任何非线性函数,从而使其成为数据建模的有效工具。
网络回归的优劣网络回归有很多优点。
首先,由于使用的是人工神经网络,它可以模拟几乎任何非线性函数,这使其非常灵活,可以处理各种各样的数据。
其次,通过训练网络,可以建立非常准确的预测模型。
这对于打造基于模型的企业和制定基于数据的决策非常重要。
最后,网络回归可以处理非常大的数据集。
这是因为其可以并行计算,而且每个神经元都可以处理多个输入。
然而,网络回归也存在一些缺点。
首先,训练网络需要许多计算资源,特别是在处理大数据集时。
此外,还需要大量的培训时间。
此外,网络回归通常需要优化调整。
这意味着在使用网络回归时需要更多的技能,特别是在数据分析领域。
初中数学如何进行数据的回归分析
在初中数学中,进行数据的回归分析通常是通过简单线性回归来进行的。
简单线性回归通常包括以下几个步骤:
1. 收集数据:首先,需要收集一组相关数据,通常是两组数据,一组作为自变量(x),另一组作为因变量(y)。
2. 绘制散点图:将收集到的数据绘制成散点图,以观察数据的分布情况和可能的线性关系。
3. 计算相关系数:计算自变量和因变量之间的相关系数,来衡量两组数据之间的线性关系强弱。
4. 拟合直线:利用最小二乘法,拟合一条直线来表示两组数据之间的线性关系,这条直线称为回归线。
5. 预测数值:利用回归线,可以进行数值的预测,例如根据一个自变量的数值,预测对应的因变量的数值。
这些是初中数学中常见的进行数据回归分析的步骤,希望能帮助你更好地理解。
如果有任何问题,请随时提出。