(完整版)编译原理第五章作业参考答案
- 格式:docx
- 大小:24.16 KB
- 文档页数:9


编译原理-第5章-习题与答案2第五章习题5-1 设有文法G[S]:S→A/ A→aA∣AS∣/(1) 找出部分符号序偶间的简单优先关系。
(2) 验证G[S]不是简单优先文法。
5-2 对于算符文法G[S]:S→E E→E-T∣T T→T*F∣F F→-P∣P P→(E)∣i(1) 找出部分终结符号序偶间的算符优先关系。
(2) 验证G[S]不是算符优先文法。
5-3 设有文法G′[E]:E→E1 E1→E1+T1|T1 T1→T T→T*F|F F→(E)|i其相应的简单优先矩阵如题图5-3所示,试给出对符号串(i+i)进行简单优先分析的过程。
题图5-3 文法G′[E]的简单优先矩阵5-4 设有文法G[E]:E→E+T|TT→T*F|FF→(E)|i其相应的算符优先矩阵如题图5-4所示。
试给出对符号串(i+i)进行算符优先分析的过程。
题图5-4 文法G[E]的算符优先矩阵5-5 对于下列的文法,试分别构造识别其全部可归前缀的DFA和LR(0)分析表,并判断哪些是LR(0)文法。
(1) S→aSb∣aSc∣ab(2) S→aSSb∣aSSS∣c(3) S→A A→Ab∣a5-6 下列文法是否是SLR(1)文法?若是,构造相应的SLR(1)分析表,若不是,则阐明其理由。
(1) S→Sab∣bR R→S∣a(2) S→aSAB∣BA A→aA∣B B→b(3) S→aA∣bB A→cAd∣ε B→cBdd∣ε5-7 对如下的文法分别构造LR(0)及SLR(1)分析表,并比较两者的异同。
S→cAd∣b A→ASc∣a5-8 对于文法G[S]:S→A A→BA∣ε B→aB∣b(1) 构造LR(1)分析表;(2) 给出用LR(1)分析表对输入符号串abab的分析过程。
5-9 对于如下的文法,构造LR(1)项目集族,并判断它们是否为LR(1)文法。
(1) S→A A→AB∣ε B→aB∣b(2) S→aSa∣a第5章习题答案25-1 解:(1) 由文法的产生式和如答案图5-1(a)所示的句型A//a/的语法树,可得G中的部分优先关系如答案图5-1(b)所示。

何谓源程序、目标程序、翻译程序、编译程序和解释程序它们之间可能有何种关系一个典型的编译系统通常由哪些部分组成各部分的主要功能是什么选择一种你所熟悉的程序设计语言,试列出此语言中的全部关键字,并通过上机使用该语言以判明这些关键字是否为保留字。
选取一种你所熟悉的语言,试对它进行分析,以找出此语言中的括号、关键字END以及逗号有多少种不同的用途。
试用你常用的一种高级语言编写一短小的程序,上机进行编译和运行,记录下操作步骤和输出信息,如果可能,请卸出中间代码和目标代码。
第一章习题解答1.解:源程序是指以某种程序设计语言所编写的程序。
目标程序是指编译程序(或解释程序)将源程序处理加工而得的另一种语言(目标语言)的程序。
翻译程序是将某种语言翻译成另一种语言的程序的统称。
编译程序与解释程序均为翻译程序,但二者工作方法不同。
解释程序的特点是并不先将高级语言程序全部翻译成机器代码,而是每读入一条高级语言程序语句,就用解释程序将其翻译成一段机器指令并执行之,然后再读入下一条语句继续进行解释、执行,如此反复。
即边解释边执行,翻译所得的指令序列并不保存。
编译程序的特点是先将高级语言程序翻译成机器语言程序,将其保存到指定的空间中,在用户需要时再执行之。
即先翻译、后执行。
2.解:一般说来,编译程序主要由词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、代码优化程序、目标代码生成程序、信息表管理程序、错误检查处理程序组成。
3.解:C语言的关键字有:auto break case char const continue default do double else enum externfloat for goto if int long register return short signed sizeof static struct switch typedef union unsigned void volatile while。

第7 题证明下述文法G[〈表达式〉]是二义的。
〈表达式〉∷=a|(〈表达式〉)|〈表达式〉〈运算符〉〈表达式〉〈运算符〉∷=+|-|*|/答案:可为句子a+a*a 构造两个不同的最右推导:最右推导1 〈表达式〉=>〈表达式〉〈运算符〉〈表达式〉=>〈表达式〉〈运算符〉a=>〈表达式〉* a=>〈表达式〉〈运算符〉〈表达式〉* a=>〈表达式〉〈运算符〉a * a=>〈表达式〉+ a * a=>a + a * a最右推导2 〈表达式〉=>〈表达式〉〈运算符〉〈表达式〉=>〈表达式〉〈运算符〉〈表达式〉〈运算符〉〈表达式〉=>〈表达式〉〈运算符〉〈表达式〉〈运算符〉a=>〈表达式〉〈运算符〉〈表达式〉* a=>〈表达式〉〈运算符〉a * a=>〈表达式〉+ a * a=>a + a * a第8 题文法G[S]为:S→Ac|aB A→ab B→bc该文法是否为二义的?为什么?答案:对于串abc(1)S=>Ac=>abc (2)S=>aB=>abc即存在两不同的最右推导。
所以,该文法是二义的。
或者:对输入字符串abc,能构造两棵不同的语法树,所以它是二义的。
第9 题考虑下面上下文无关文法:S→SS*|SS+|a(1)表明通过此文法如何生成串aa+a*,并为该串构造语法树。
(2)G[S]的语言是什么?答案:(1)此文法生成串aa+a*的最右推导如下S=>SS*=>SS*=>Sa*=>SS+a*=>Sa+a*=>aa+a*(2)该文法生成的语言是:*和+的后缀表达式,即逆波兰式。
第10 题文法S→S(S)S|ε(1) 生成的语言是什么?(2) 该文法是二义的吗?说明理由。
答案:(1)嵌套的括号(2)是二义的,因为对于()()可以构造两棵不同的语法树。
第11 题令文法G[E]为:E→T|E+T|E-T T→F|T*F|T/F F→(E)|i证明E+T*F 是它的一个句型,指出这个句型的所有短语、直接短语和句柄。

第五章习题解答5.1 设一NDPDA识别由下述CFG定义的语言,试给出这个NDPDA的完整形式描述。
S→SASCS→εA→AaA→bC→DcDD→d5.2 消除下列文法的左递归:① G[A]:A→BX∣CZ∣WB→Ab∣BcC→Ax∣By∣Cp② G[E]:E→ET+∣ET–∣TT→TF*∣TF/FF→(E)∣i③ G[X]:X→Ya∣Zb∣cY→ Zd∣Xe∣fZ→X e∣Yf∣a④ G[A]:A→Ba|Aa|cB→Bb|Ab|d5.3 设文法G[<语句>]:<语句>→<变量>: = <表达式>|if<表达式>then<语句>|if<表达式>then<语句>else<语句> <变量>→i<表达式>→<项>|<表达式>+<项><项>→<因子>|<项>*<因子><因子>→<变量>|′(′<表达式>′)′试构造该文法的递归下降子程序。
5.4 设文法G[E]:E→ TE'E'→ + E∣εT→ FT'T'→ T∣εF→ PF'F'→ *F∣εP→ (E)∣ a∣^①构造该文法的递归下降分析程序;②求该文法的每一个非终结符的FIRST集合和FOLLOW集合;③构造该文法的LL(1)分析表,并判断此文法是否为LL(1)文法。
5.5 设文法G[S]:S→ SbA∣aAB→ SbA→ Bc①将此文法改写为LL(1)文法;②求文法的每一个非终结符的FIRST集合和FOLLOW集合;③构造相应的LL(1)分析表。
5.6 设文法G[S]:S→ aABbcd∣εA→ ASd∣εB→ SAh∣eC∣εC→ Sf∣Cg∣εD→ aBD∣ε①求每一个非终结符的FOLLOW集合;②对每一个非终结符的产生式选择,构造FIRST集合;③该文法是LL(1)文法。

第二章高级语言的语法描述6、令文法G 6为:N →D|ND D → 0|1|2|3|4|5|6|7|8|9(1)G 6 的语言L (G 6)是什么?(2)给出句子01270127、、34和568的最左推导和最右推导。
解答:思路:由N N →→ D|ND 可得出如下推导N =>=>ND ND ND=>=>=>NDD NDD NDD=>…=>=>…=>=>…=>D D n(n >=1=1))可以看出,N 最终可以推导出1个或多个(也可以是无穷)D ,而D D →→ 0|1|2|3|4|5|6|7|8|9可知,每个D 为0~9中的任一个数字,所以,中的任一个数字,所以,N N N 最终推导出的就是由最终推导出的就是由0~9这10个数字组成的字符串。
(1)G 6 的语言L (G 6)是由0~9这10个数字组成的字符串个数字组成的字符串,,或{0{0,,1,1,……,9}+。
(2)(2)句子句子01270127、、34和568的最左推导分别为的最左推导分别为: : N =>=>ND ND ND=>=>=>NDD NDD NDD=>=>=>NDDD NDDD NDDD=>=>=>DDDD DDDD DDDD=>=>=>0DDD 0DDD 0DDD=>=>=>01DD 01DD 01DD=>=>=>012D 012D 012D=>=>=>0127 0127 N =>=>ND ND ND=>=>=>DD DD DD=>=>=>3D 3D 3D=>=>=>34 34N =>=>ND ND ND=>=>=>NDD NDD NDD=>=>=>DDD DDD DDD=>=>=>5DD 5DD 5DD=>=>=>56D 56D 56D=>=>=>568 568 句子01270127、、34和568的最右推导分别为的最右推导分别为: :N =>=>ND ND ND=>=>=>N7N7N7=>=>=>ND7ND7ND7=>=>=>N27N27N27=>=>=>ND27ND27ND27=>=>=>N127N127N127=>=>=>D127D127D127=>=>=>0127 0127 N =>=>ND ND ND=>=>=>N4N4N4=>=>=>D4D4D4=>=>=>34 34N =>=>ND ND ND=>=>=>N8N8N8=>=>=>ND8ND8ND8=>=>=>N68N68N68=>=>=>D68D68D68=>=>=>568 5687、写一个文法,使其语言是奇数集,且每个基数不以0开头。

第五章语法制导翻译及中间代码生成5.1说明属性文法与属性翻译文法有何异同?5.2考虑下面的属性文法:Z →sXattribution:Z.a=X.c;X.b=X.a;Z.p=X.b;Z →t Xattribution:X.b=X.d;Z.a=X.b;X →uattribution:X.d=1;X.c=X.d;X →Vattribuion:X.c=2;X.d=X.c;(1) 上述文法中的属性哪些是继承的?哪些是综合的?(2) 上述文法中的属性依赖是否出现了循环?5.3为什么说S属性文法一定是L属性文法?反之结论亦正确吗?5.4将下列中缀式改写为逆波兰式。
(1) -A*(B+C)↑(D-E)(2) ((a*d+c)/d+e)*f+g(3) a+x≤4∨(C∧d*3)(4) a∨b∧c+d*e↑f(5) s=0; i=1;while (i<=100) {s+=i*i; i++;}5.5将下列后缀式改写为中缀式。
(1) abc*+(2) abc-*cd+e/-(3) abc+≤a0>∧ab+0≠a0∧∨(4) ab<p1 BZ xab-c↑= p2 BR gh=↑↑p1p25.6设已给文法G[E]:E →E+T | -T | TT →T*F | FF →P ↑F | PP →(E) | i试设计一个递归下降分析器,要求此分析器在语法分析过程中,将所分析的符号串翻译成后缀式。
5.7设已给布尔表达式文法G[Z]:Z →EE →T{∨T}T →F{∧F}F → F | (E) | b试设计一个递归下降分析器,它把由G[Z]所描述的布尔表达式翻译为四元式序列。
5.8(1) 利用54节所给的属性翻译文法将赋值语句:X=A*(B+C)+D翻译成四元式序列,给出语法制导的翻译过程。
(2) 利用55节所给的属性翻译文法将布尔表达式:A∧(B∨(C∨D F))翻译成四元式序列,给出语法制导的翻译过程。
(3) 利用56节所给的属性翻译文法将语句:while A<C∧B>0 doif A=1 then C∶=C+1else while A<=D do A∶=A+2翻译成四元式序列,给出语法制导的翻译过程。


《编译原理》习题参考答案(六)第五章5.4 为下列类型写类型表达式:(a) 指向实数的指针数组,数组的下标从1到100。
(b) 两位数组(即数组的数组),他的行下标从1到10,列下标从1到20。
(c) 函数,他的定义域是从整数到整数的指针的函数,它的值域是从一个整数和一个字符组成的纪录。
Solution:(a) array ( 1 . . 100 , pointer ( real ) )(b) array ( 1 . . 10 , array ( 1 . . 20 , type ) )(c) ( integer →pointer(integer) )→record((i : integer) * ( c : char )) 假定作为值域的记录类型的两个域分别叫i和c。
5.6 下列文法定以字面常量表的表。
符号的解释和图5.2文法的那些相同,增加了类型list,它表示类型T的元素表。
→ D ; EP→ D ; D | id : TD→ list of T | char | integerTE→ ( L ) | literal | num | id→ E , L | EL写一个类似5.3节中的翻译方案,以确定表达式( E )和表( L )的类型。
P→ D ; ED→ D ; DD→ id : T { addtype ( id.entry , T.type ) }T→ char { T.type := char }T→ integer { T.type := integer }T→ list of T1 { T.type := list ( T1.type ) }E→ literal { E.type := char }E→ num { E.type := integer }E→ id { E.type := lookup ( id.entry ) }E→ ( L ) { E.type := list ( L.type ) }L→E{L.type:=E.type}L→ E , L1 { L.type := if L1.type = E.type then E.typeelse type_error }5.16 对下面的每对表达式,找出最一般的合一代换:(a) α1 → ( α2 →α1 )(b) array ( β1 ) → ( pointer( β1 ) →β2 )(c) γ1 →γ2(d) δ1 →(δ1 →δ2 )Solution:S(α1) = array ( β1 ) S(α2) = pointer ( β1 ) S(β2) = array ( β1 ) (a)(c):S(γ1) = α1 S(γ2) = α2 → α1 (a)(d):S(α1) = S(α2) = S(δ1) = S(δ2) = α (b)(c):S(γ1) = array ( β1 ) S(γ2) = pointer ( β1 ) → β2 (b)(d): 无 (c)(d):S(γ1) = δ1 S(γ2) = δ1 → δ25.17 仿效例5.5,推到下面map 的多态类型: map: ∀ α . ∀ β . ( ( α → β ) * list ( α ) ) → list ( β ) map 的ML 定义是 fun map ( f , l ) = if null ( l ) then nilelse cons ( f ( hd ( l ) ) , map ( f , tl ( l ) ) );在这个函数体中,内部定义的标识符的类型是: null : ∀α . list (α ) → boolean ; nil : ∀α . list (α ) ;cons : ∀α . ( α * list (α ) ) → list (α ) ;hd:∀α . list (α ) →α;∀α . list (α ) → list (α ) ;tl:Solution:行定型断言代换规则(1) f : α( Exp Id )(2) l : β( Exp Id )(3) map : γ( Exp Id )(4) map ( f , l ) : δγ = ( α * β ) →δ(Exp Funcall)(5) null : list (α0) → boolean ( Exp Id ) 和( Type Fresh )(6) null ( l ) : boolean β = list (α0) (Exp Funcall)(7) nil : list (α1) ( Exp Id ) 和( Type Fresh )(8) l : list (α0) 由(2)可得(9) hd : list (α2) →α2( Exp Id ) 和( Type Fresh )(10) hd ( l ) : α0α2 = α0(Exp Funcall)(11) f ( hd ( l ) ) : α3α = α0→α3( Exp Id )(12) f : α0→α3由(1)可得(13) tl : list (α4)→ list (α4) ( Exp Id ) 和( Type Fresh )(14) tl ( l ) : list (α0) α4 = α0(Exp Funcall)(15) map : ((α0→α3)*list(α0))→δ由(3)可得(16) map ( f , tl ( l ) ) : δ(Exp Funcall)(17) cons : α5 * list(α5) → list(α5) ( Exp Id ) 和( Type Fresh ) (18) cons (…) : list (α3) α5 = α3 , δ=list(α3) (Exp Funcall)(19) if : boolean *α6 * α6→α6( Exp Id ) 和( Type Fresh )(20) if (…) : list (α1) α6 = α1 , α3 = α1(Exp Funcall)(21) match : α7 *α7 →α7( Exp Id ) 和( Type Fresh ) (22) match (…) : list (α1) α7 = list (α1) (Exp Funcall)至此有map : ( (α0→α1)*list(α0) )→list(α1)所以map : ∀α . ∀β . ( ( α→β ) * list ( α ) ) → list ( β )5.18 假定类型名link和cell如5.5节那样定义,下面的表达式中,那些结构等价?那些名字等价?(a) link(b) pointer ( cell )(c) pointer ( link )(d) pointer ( record ( ( info : integer ) * ( next : pointer ( cell ) ) ) ) Solution:(a)、(b)、(d)结构等价,无名字等价。
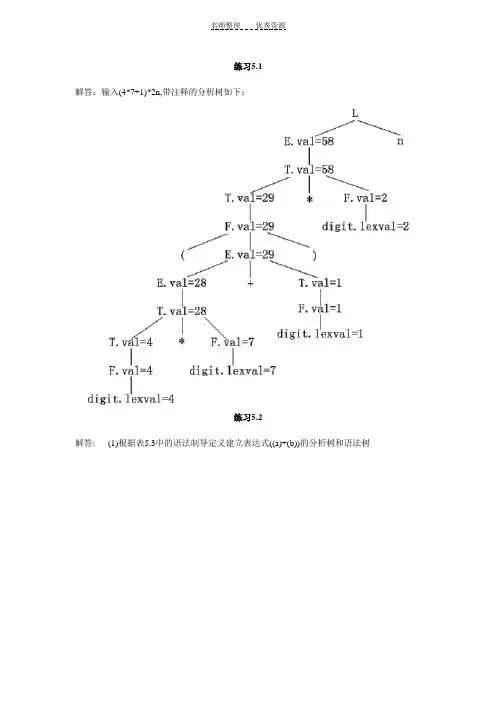
练习5.1解答:输入(4*7+1)*2n,带注释的分析树如下:练习5.2解答: (1)根据表5.3中的语法制导定义建立表达式((a)+(b))的分析树和语法树(2)根据图5.17的翻译模式构造((a)+(b))的分析树和语法树练习5.3解答:设置下面的函数和属性:expr1||expr2:把表达式expr2拼写在表达式expr1后面。
deletep(expr):去掉表达式expr左端的‘(’和右端的‘)’。
E.expr,T.expr,F.expr:属性变量,分别表示E,T,F的表达式。
E.add,T.add,F.add,属性变量,若为true,则表示其表达式中外层有‘+’号,否则无‘+’号。
E.pmark,T.pmark,F.pmark,属性变量,若为true,表示E,T,F的表达式中左端为‘(’,右端是‘)’。
语法制导定义如下:产生式语义规则E -> E1 +T if(T.pmark==true)THEN E.expr=E1.expr||'+'||deletep(T.expr) ELSE E.expr:=E1.expr||'+'||T.expr;E.add:=true;E.pmark:=false;E -> T if(T.pmark==true)THEN E.expr:=deletep(T.expr)ELSE E.expr:=T.expr;E.add:=T.add;E.pmark:=false;T -> T1*F T.expr:=T1.expr||'*'||F.expr; T.add:=false;T.pmark:=false;T -> F T.expr:=F.expr; T.add:=F.add;T.pmark:=F.pmark;F -> (E) if(E.add==false)THEN BEGINF.expr:=E.expr;F.add:=false;F.pmark:=false;ENDELSE BEGINF.expr:='('||E.expr||')';F.add:=true;F.pmark:=true;END;F -> id F.expr:=id.lexval;F.add:=false;F.pmark:=false;练习5.4解答: (1)语法制导定义如下:产生式语义规则E -> E1+T if(E1.type==int) AND (T.type==int) THEN E.type:=intELSE E.type:=real;E -> T E.type:=T.type;T -> num T.type:=int;T -> num.num T.type:=real;(2)设E.pf和T.pf分别是E和T的前缀形式,||是两个字符串的连接,语法制导定义如下:产生式语义规则E -> E1+T if(E1.type==int) AND (T.type==int)THEN E.type:=intELSE BEGINE.type:=real;if(E1.type==int) AND (T.type==real)THEN E1.pf:='inttoreal'||E1.pfELSE if(E1.type==real)AND(T.type==int)THEN T.pf:='inttoreal'||T.pfEND;E.pf:='+'||E1.pf||T.pf;E -> T E.type:=T.type; E.pf:=T.pf;T -> num T.type:=int; T.pf:=int.lexval;T ->num.numT.type:=real; T.pf:=real.lexval;练习5.5解答: (1)用综合属性决定s.val的语法制导定义:产生式语义规则S -> L S.val:=L.val;S ->L1.L2S.val:=L1.val+L2.val*L2.p;L -> B L.val:=B.val; L.p:=2-1;L -> L1B L.val:=L1.val*2+B.val; L.p:=L.p*2-1;B -> 0 B.val:=0;B -> 1 B.val:=1;注:L.p表示恢复L.val的因子。

第五章P138.1.解:由中缀表达式翻译成波兰前缀表达式的符号串翻译文法如下:①E→@+E+T ②E→T ③T→@*T*F④T→F ⑤F→(E) ⑥F→a@a⑦F→b@b ⑧F→c@c2.解:a)输入符号串的倒置:①S→@0S0 ②S→@1S1 ③S→1@1④S→0@0c)输入符号串本身:①S→S0@0 ②S→S1@1 ③S→1@1④S→0@03.解:该符号串翻译文法能将输入的符号序列“ENGLISH”翻译成动作序列“@C@HI@N@E@SE”,并执行该动作序列得到输出序列“CHINESE”。
4.解:根据活动序列将动作符号放到文法中适当位置得到该翻译文法为:①<s>→@q a<s>@x <s>@y ②<s>→@x @y b@z5.解:由该符号串翻译文法得到其输入文法为:①<s>→<A>c<B> ②<s>→dcb③<A>→<B>a ④<A>→d ⑤<B>→b由推导:s=><A>c<B>=><A>cb=>dcb 可得到对偶<dcb,xxy>由推导:s=>dcb 可得到对偶<dcb,yxz>由推导:s=><A>c<B>=><A>cb=><B>acb=>bacb可得到对偶<dcb,xyxxy>第六章符号表管理技术P185.4、下面是一个非分程序结构语言的程序段。
画出编译该程序段时将生成的有序符号表。
BLOCKREAL X,Y,Z1,Z2,Z3;INTEGER I,J,K,LASTI;STRING LIST-OF-NAMES;LOGICAL ENTRY-ON,EXIT-OFF;ARRAY REAL VAL(20);ARRAY INTEGER MIN-VAL-IND(20);...END OF BLOCK解:变量名类型维数ENTRY-ON LOGICAL 0EXIT-OFF LOGICAL 0I INTEGER 0J INTEGER 0K INTEGER 0LASTI INTEGER 0LIST-OF-NAMES STRING 0MIN-VAL-IND INTEGER 1VAL REAL 1X REAL 0Y REAL 0Z1 REAL 0Z2 REAL 0Z3 REAL 06、下面是一分程序结构的程序段。
第5-7章课后作业(含答案)1、将文法G[S] 改写为等价的G′[S],使G′[S]不含左递归和左公共因子。
G[S]:S→bSAe|bA A→Abd | dc | a【解】:G[S]:S→bS’S’→SAe|AA→(dc|a)A’A’→bd A’ |ε2、有文法G[S]:S→ABf A→BbS|e B→dAg|ε证明文法G是LL(1)文法,并构造预测分析表【解】:①计算FIRST、FOLLOW、SELECT集由上表可知:该文法中,所有相同左部不同右部的产生式SELECT集两两相交均为空集,所以该文法为LL(1)文法。
3、已知文法G[S]:S→(A)│a│b A→AcS│S 构造文法的算符优先矩阵,并判断该文法是否是算符优先文法。
【解】:①拓展该文法:S’→#S# S→(A)│a│b A→AcS│S②计算FIRSTVT与③计算算符优先关系:# =# ( = )# < FIRSTVT(S) ( < FIRSTVT(A) c< FIRSTVT(S)LASTVT(S) > # LASTVT(A) > ) LASTVT(A) > c④构造算符优先矩阵⑤因为该文法G为2型文法,且不含空产生式,没有形如 U …VW…的产生式,其中V,W∈V所以 G 为算符文法;又因为G 中任意两个终结符间至多有一种算N,符优先关系存在(算符优先矩阵无冲突,见上表),所以G 为算符优先文法。
4、课后习题P122:4(2)已知文法:S→S;G|G G→G(T)|H H→a|(S) T→T+S|S求句型a(T+S);H;(S) 的短语、直接短语、句柄、素短语与最左素短语。
【解】:①该句型的对应的语法树如下:②短语: a T+S H (S) a(T+S);H a(T+S);H;(S)直接短语: a T+S H (S)句柄:a素短语: a T+S (S)最左素短语:a5. 给定文法G[A]:A→(A)│a,构造出该文法的LR(1)分析表。
第五章自顶向下语法分析方法1.对文法G[S]S→a|∧|(T)T→T,S|S(1)给出(a,(a,a))和(((a,a),∧,(a)),a)的最左推导。
(2)对文法G,进行改写,然后对每个非终结符写出不带回溯的递归子程序。
(3)经改写后的文法是否是LL(1)的?给出它的预测分析表。
(4)给出输入串(a,a)#的分析过程,并说明该串是否为G的句子。
解:(1) (a,(a,a))的最左推导为S→(T)→(T,S)→(S,S)→(a,(T))→(a,(T,S))→(a,(S,a))→(a,(a,a))(((a,a),∧,(a)),a)的最左推导为S→(T)→(T,S)→(S,a)→((T),a)→((T,S),a)→((T,S,S),a)→((S,∧,(T)),a)→(((T),∧,(S)),a) →(((T,S),∧,(a)),a)→(((S,a),∧,(a)),a)→(((a,a),∧,(a)),a)(2)由于有T→T,S的产生式,所以消除该产生式的左递归,增中一个非终结符U有新的文法G/[S]:S→a|∧|(T)T→SUU→,SU|ε分析子程序的构造方法对满足条件的文法按如下方法构造相应的语法分析子程序。
(1) 对于每个非终结号U,编写一个相应的子程序P(U);(2) 对于规则U::=x1|x2|..|xn,有一个关于U的子程序P(U),P(U)按如下方法构造:IF CH IN FIRST(x1) THEN P(x1)ELSE IF CH IN FIRST(x2) THEN P(x2)ELSE ......IF CH IN FIRST(xn) THEN P(xn)ELSE ERROR其中,CH存放当前的输入符号,是一个全程变量;ERROR是一段处理出错信息的程序;P(xj)为相应的子程序。
(3) 对于符号串x=y1y2...yn;p(x)的含义为:BEGINP(y1);P(y2);...P(yn);END如果yi是非终结符,则P(yi)代表调用处理yi的子程序;如果yi是终结符,则P(yi)为形如下述语句的一段子程序IF CH=yi THEN READ(CH) ELSE ERROR即如果当前文法中的符号与输入符号匹配,则继续读入下一个待输入符号到CH中,否则表明出错。
第5章自顶向下语法分析方法第1题对文法G[S]S→a||(T)∧T→T,S|S(1) 给出(a,(a,a))和(((a,a),,(a)),a)∧的最左推导。
(2) 对文法G,进行改写,然后对每个非终结符写出不带回溯的递归子程序。
(3) 经改写后的文法是否是LL(1)的?给出它的预测分析表。
(4) 给出输入串(a,a)#的分析过程,并说明该串是否为G的句子。
答案:也可由预测分析表中无多重入口判定文法是LL(1)的。
的。
是文法的句子。
可见输入串(a,a)#是文法的句子。
第3题已知文法G[S]:S→MH|aH→LSo|εK→dML|εL→eHfM→K|bLM分析表。
判断G是否是LL(1)文法,如果是,构造LL(1)分析表。
第7题对于一个文法若消除了左递归,提取了左公共因子后是否一定为LL(1)文法?试对下面文法进行改写,并对改写后的文法进行判断。
法进行改写,并对改写后的文法进行判断。
(1)A→baB|εB→Abb|a(2) A→aABe|aB→Bb|d(3) S→Aa|bA→SBB→ab答案:答案:(1)先改写文法为:先改写文法为:0) A→baB1) A→ε→ε2) B→baBbb3) B→bb4) B→a再改写文法为:再改写文法为:0) A→baB1) A→ε→ε2) B→bN3) B→a4) N→aBbb5) N→b文法: A→aABe|a B→Bb|d(2)文法:提取左公共因子和消除左递归后文法变为: 提取左公共因子和消除左递归后文法变为:0) A→a N1) N→A B e2) N→ε3) B→d N14) N1→b N15) N1→ε(3)文法:)文法: S→Aa|b A→SB B→ab种改写:第1种改写:得: 用A的产生式右部代替S的产生式右部的A得:S→SBa|b B→ab消除左递归后文法变为:消除左递归后文法变为:0) S→b N1) N→B a N2) N→ε3) B→a b的。