第七章 无约束优化7(1)
- 格式:pdf
- 大小:3.21 MB
- 文档页数:11


第七讲无约束优化一阶方法1.最速下降法的由来最速下降法考虑无约束问题其中,函数具有一阶连续偏导数.),(min x f ,n R x 人们在处理这类问题是,总希望从某一点出发,选择一个目标函数值下降最快的方法,以利于尽快达到极小点. 基于此愿望,1847年法国数学家Cauchy 提出了最速下降法. 后来,Curry 等人作了进一步的研究,得到现在众所周知的一种最基本的方法.最速下降法利用负梯度为方向作为搜索方向.设在附近连续可微,为搜索方向向量,,由泰勒展开式得那么目标函数在处沿着方向下降的变化率如下所示:)(k k x f d -∇=)(x f k x k d )(k k x f g ∇=,0),()()(>++=+ααααo d g x f d x f k Tk k k k )(x f k x k d其中为与夹角. 要使得变化率最小,只有当值为时才能达到,也就是取得负梯度方向.ααα)()(lim 0k k k x f d x f -+→αααα)(lim 0o d g k Tk +=→θcos k T k k T k d gd g ==θk g k d k d 1-)(x f ∇)(x f ∇-cos事实上,最速下降方向也可以这样来考虑。
因为目标函数在处沿方向的变化率为,故最速下降的单位方向是如下非线性规划问题的解.根据Schwartz 不等式,有去掉绝对值符号,可以得到.由上式知,当时等号成立. 因此负梯度方向为最速下降方向.d g T k )(x f k x d d dmin d g T k ..t s 1≤d kk T k g d g d g ≤≤k T kg d g -≥k k g g d -=3.最速下降法计算步骤1.给定初始点,容许误差,令2. 计算搜索方向;3. 若,则停止计算,输出作为近似最优解;否则从出发,沿进行一维线搜索,确定步长因子,使得4. 令,令,转步骤2.n R x ∈00>ε1:=k )(k k x f d -∇=ε≤k d k x k x k d k αk k k k d x x α+=+11:+=k k 0()min ()k k k k k k k f x d f x d ααα≥+=+4.最速下降法的锯齿现象由步骤3,为求出从出发沿方向的极小点,令由此得出.即方向与正交.这表明迭代产生的序列所循路径是“之”字形的。




凸优化之⽆约束优化(⼀维搜索⽅法:⼆分法、⽜顿法、割线法)1、⼆分法(⼀阶导)⼆分法是利⽤⽬标函数的⼀阶导数来连续压缩区间的⽅法,因此这⾥除了要求 f 在 [a0,b0] 为单峰函数外,还要去 f(x) 连续可微。
(1)确定初始区间的中点 x(0)=(a0+b0)/2 。
然后计算 f(x) 在 x(0) 处的⼀阶导数 f'(x(0)),如果 f'(x(0)) >0 , 说明极⼩点位于 x(0)的左侧,也就是所,极⼩点所在的区间压缩为[a0,x(0)];反之,如果 f'(x(0)) <0,说明极⼩点位于x(0)的右侧,极⼩点所在的区间压缩为[x(0),b0];如果f'(x(0)) = 0,说明就是函数 f(x) 的极⼩点。
(2)根据新的区间构造x(1),以此来推,直到f'(x(k)) = 0,停⽌。
可见经过N步迭代之后,整个区间的总压缩⽐为(1/2)N,这⽐黄⾦分割法和斐波那契数列法的总压缩⽐要⼩。
1 #ifndef _BINARYSECTION_H_2#define _BINARYSECTION_H_34 typedef float (* PtrOneVarFunc)(float x);5void BinarySectionMethod(float a, float b, PtrOneVarFunc fi, float epsilon);67#endif1 #include<iostream>2 #include<cmath>3 #include "BinarySection.h"45using namespace std;67void BinarySectionMethod(float a, float b, PtrOneVarFunc tangent, float epsilon)8 {9float a0,b0,middle;10int k;11 k = 1;12 a0 = a;13 b0 = b;14 middle = ( a0 + b0 )/2;1516while( abs(tangent(middle)) - epsilon > 0 )17 {18 #ifdef _DEBUG19 cout<<k++<<"th iteration:x="<<middle<<",f'("<<middle<<")="<<tangent(middle)<<endl;20#endif2122if( tangent(middle) > 0)23 {24 b0 = middle;25 }26else27 {28 a0 = middle;29 }30 middle =( a0+b0)/2;31 }3233 cout<<k<<"th iteration:x="<<middle<<",f'("<<middle<<")="<<tangent(middle)<<endl;34 }1 #include<iostream>2 #include "BinarySection.h"345float TangentFunctionofOneVariable(float x)6 {7return14*x-5;//7*x*x-5*x+2;8 }910int main()11 {12 BinarySectionMethod(-50, 50, TangentFunctionofOneVariable, 0.001);13return0;14 }1th iteration:x=0,f'(0)=-52th iteration:x=25,f'(25)=3453th iteration:x=12.5,f'(12.5)=1704th iteration:x=6.25,f'(6.25)=82.55th iteration:x=3.125,f'(3.125)=38.756th iteration:x=1.5625,f'(1.5625)=16.8757th iteration:x=0.78125,f'(0.78125)=5.93758th iteration:x=0.390625,f'(0.390625)=0.468759th iteration:x=0.195312,f'(0.195312)=-2.2656210th iteration:x=0.292969,f'(0.292969)=-0.89843811th iteration:x=0.341797,f'(0.341797)=-0.21484412th iteration:x=0.366211,f'(0.366211)=0.12695313th iteration:x=0.354004,f'(0.354004)=-0.043945314th iteration:x=0.360107,f'(0.360107)=0.041503915th iteration:x=0.357056,f'(0.357056)=-0.001220716th iteration:x=0.358582,f'(0.358582)=0.020141617th iteration:x=0.357819,f'(0.357819)=0.0094604518th iteration:x=0.357437,f'(0.357437)=0.0041198719th iteration:x=0.357246,f'(0.357246)=0.0014495820th iteration:x=0.357151,f'(0.357151)=0.0001144412、⽜顿法(⼆阶导)前提:f 在 [a0,b0] 为单峰函数,且[a0,b0] 在极⼩点附近,不能离的太远否则可能⽆法收敛。
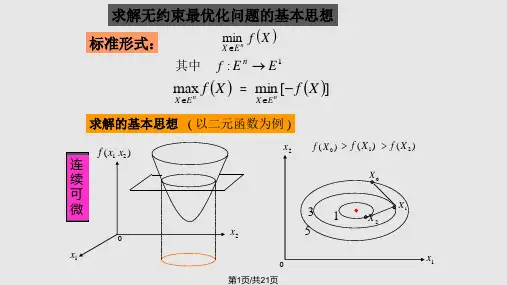



无约束优化算法无约束优化算法问题,是指优化问题的可行集为,无约束的标准形式为:∙最优性条件∙极小值点的一阶必要条件设为连续可微函数,如果为局部极小值点,则为驻点,即梯度。
∙极小值的二阶必要条件设为二阶连续可微函数,如果为局部极小值点,则为驻点,即梯度,二阶半正定。
∙极小值点的二阶充分条件设为二阶连续可微函数,如果梯度,二阶正定,则为的局部极小值点,。
以上三个定理为搜索最优点以及判断一个点是否为最优点的基本依据。
经典的优化算法的停止条件为,例如在程序中,即在导数范数小于某特定误差限时停止。
误差限较大,则算法迭代次数减少,计算时间缩短,但解得质量降低;误差限较小,则算法迭代次数增加,计算时间增加,但解的质量提高;误差限一般为,可以根据实际情况设定合适的误差限。
当然,还有极小值点的二阶必要条件与极小值点的二阶充分条件,对的判断,由于目标函数比较复杂,二阶导数矩阵的计算量极大,所以一般算法都在迭代过程中对进行修正,得到,在修正的过程中始终保持的正定性,以此方法解决极小值点的二阶条件问题。
一、最速下降法(1) 算法原理最速下降法是早期的优化算法,其理论根据函数的一阶泰勒展开:由得到根据下降要求故实际中要求根据上式选取合适的,得。
最速下降法取。
由于近似的有:取,则由知:最速下降法有全局收敛性,并且是线性收敛的,算法比较简单。
一般来说,在实际计算中,最速下降法在开始迭代时效果较好,有时能很快地找到最优解得附近,但是当局继续迭代时,常常发生扭摆现象,以致不能达到最优解。
(2) 算法步骤给定控制误差。
步骤1:取初始点,令步骤2:计算。
步骤3:若,则,停止计算;否则,令,由一维搜索步长,使得步骤4:令,,转步骤2。
二、黄金分割法(1) 算法思想通过不断缩小区间的长度来搜索目标函数的极小值点,且是按照可行域全长的0.618(及0.382)选取新点,而不断更新区间进行的.(2) 算法流程步骤ε>.设函数发f(x),初始区间为[a,b],0步骤1:取两点x1,x2(x1<x2),x2=a+0.618(b-a),x1=a+b-x2或x1=a+0.382(b-a),x2=a+b-x1 计算f(x1),f(x2);步骤2: 若f(x1)<f(x2);则去掉[x2,b],则a=a,b=x2,x2=x1,x1=a+b-x2,步骤3: 若f(x1)>f(x2);则去掉[a,x1],则a=x1,b=b,x1=x2,x2=a+b-x1,步骤4: 若f(x1)=f(x2);则去掉[a,x1]和[x2,b],则a=x1,b=x2,重复步骤1.步骤5: 在每一次缩小区间时,判断|b-a|≤ε是否成立,若成立则结束.三、共轭梯度法(1) 算法思想共轭梯度法的基本思想是把共轭性与最速下降方法相结合,利用已知点处的梯度构造一组共轭方向,并沿这组方向进行搜素,求出目标函数的极小点。
无约束优化方法1.坐标轮换法2.鲍威尔法3.梯度法4.牛顿法5.变尺度法1.坐标轮换法坐标轮换发是一种不计算函数梯度,而是通过函数值本身,即可求出寻优方向,因而也称为直接寻优法.在以后提到的鲍威尔法(Powell)法也属于直接寻优法。
对于坐标轮换法,我们做个比喻:如果我们在北京的老城区找一个地方,我们可以沿着经纬线去找。
这个比喻为我们提供了一种思路,既可以取坐标的方向为寻优的方向,这就是坐标轮换法。
它在每次搜索中,只允许一个变量的变化,其余量保持不变,即沿着坐标方向轮流进行搜索的方法。
该方法把多变量的优化问题轮流转化成一系列单变量的优化问题。
对应于n 个变量的寻优函数,若在第轮沿第k 个坐标第i 个坐标方向ki i S e =进行搜索,则迭代公式为1(0,1,...,1,2,...,)k k k k i i i i X X S k i n α-=+==其中搜索方向取坐标方向,即k i i S e =(1,2,...,i n =)。
若0k k n X X -‖‖<ε,则*kn X X ←,否则10k kn X X +←,进行下一轮的搜索,一直到满足精度要求为止。
其搜索路径如图所示这种方法的收敛效果与目标函数等值线形有很大关系。
如果目标函数为二元二次函数,其等值线为圆或长轴平行于坐标轴的椭圆时,此方法很有效,经过两次搜索即可以达到最优点,如图所示。
如果等值线为长轴不平行于坐标轴的椭圆,则需多次迭代才能达到最优点,但因坐标轮换法是坐标方向搜索而不是沿脊线搜索,所以就终止到脊线上而不能找到最优解。
从上述分析可以看出,采用坐标轮换法只能轮流沿着坐标的方向搜索,尽管也能使函数值步步下降,但经过曲折迂回的路径才能达到极值点;尤其极值点附近步长很小,收敛很慢,所以坐标轮换法不是一种很好的搜索方法。
但是可以构造很好的搜索策略,下面讨论的鲍威尔法就是这种情况。
例题:已知22121212()10460f X x x x x x x =+---+,设初始点:(0)[0,0]T X=,精度0.1=ε,用最优步长法的坐标轮换法求目标函数的最优解。