K-means聚类算法课件
- 格式:ppt
- 大小:945.50 KB
- 文档页数:16

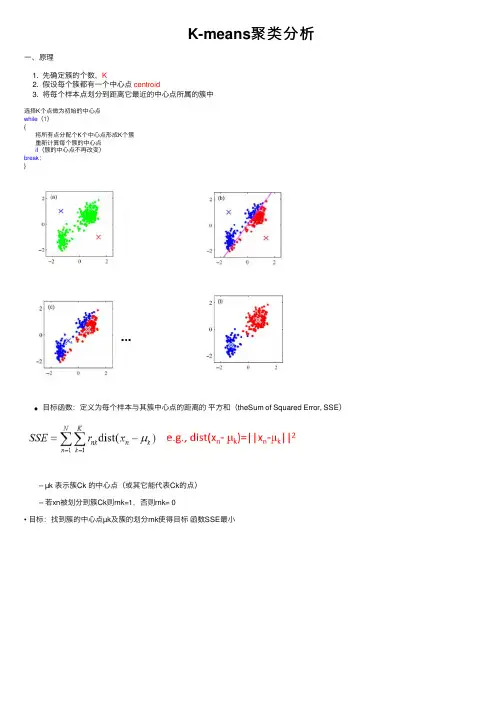
K-means聚类分析⼀、原理1. 先确定簇的个数,K2. 假设每个簇都有⼀个中⼼点centroid3. 将每个样本点划分到距离它最近的中⼼点所属的簇中选择K个点做为初始的中⼼点while(1){将所有点分配个K个中⼼点形成K个簇重新计算每个簇的中⼼点if(簇的中⼼点不再改变)break;}⽬标函数:定义为每个样本与其簇中⼼点的距离的平⽅和(theSum of Squared Error, SSE) – µk 表⽰簇Ck 的中⼼点(或其它能代表Ck的点) – 若xn被划分到簇Ck则rnk=1,否则rnk= 0• ⽬标:找到簇的中⼼点µk及簇的划分rnk使得⽬标函数SSE最⼩初始中⼼点通常是随机选取的(收敛后得到的是局部最优解)不同的中⼼点会对聚类结果产⽣不同的影响:1、2、此时你⼀定会有疑问:如何选取"较好的"初始中⼼点?1. 凭经验选取代表点2. 将全部数据随机分成c类,计算每类重⼼座位初始点3. ⽤“密度”法选择代表点4. 将样本随机排序后使⽤前c个点作为代表点5. 从(c-1)聚类划分问题的解中产⽣c聚类划分问题的代表点 结论:若对数据不够了解,可以直接选择2和4⽅法需要预先确定K Q:如何选取K SSE⼀般随着K的增⼤⽽减⼩A:emmm你多尝试⼏次吧,看看哪个合适。
斜率改变最⼤的点⽐如k=2总结:简单的来说,K-means就是假设有K个簇,然后通过上⾯找初始点的⽅法,找到K个初始点,将所有的数据分为K个簇,然后⼀直迭代,在所有的簇⾥⾯找到找到簇的中⼼点µk及簇的划分rnk使得⽬标函数SSE最⼩或者中⼼点不变之后,迭代完成。
成功把数据分为K类。
预告:下⼀篇博⽂讲K-means代码实现。




第⼆讲聚类Kmeans算法跟运⽤(K-meanscluster)CLEMENTINE 1212 CLEMENTINE--SEGMENTATION(K-MEANS)何谓集群分析何谓集群分析((CLUSTERING ANALYSIS )集群分析是⼀种将样本观察值进⾏分析,具有某些共同特性者予以整合在⼀起,再将之分配到特定的群体,最后形成许多不同集群的⼀种分析⽅法。
Clementine 12.0中提供的集群分析⽅法有三种:1. K-means2. Two-step3. KohonenK-MEANS的理论背景K-Means是集群分析(Cluster Analysis)中⼀种⾮阶层式((Nonhierarchical))的演算⽅法,由J. B. Mac Queen于1967年正式发表,也是最早的组群化计算技术。
其中,⾮阶层式则是指在各阶段分群过程中,将原有的集群予以打散,并重新形成新的集群。
K-Means是⼀种前设式群集算法,也就是说必须事前设定群集的数量,然后根据此设定找出最佳群集结构。
⽽K-Means算法最主要的概念就是以集群内资料平均值为集群的中⼼。
计算距離并分群的中⼼点重新计算新的距離并分群不断重复步骤三四,直到所设计的停⽌条件发⽣。
⼀般是以没有任何对象变换所属集群为停⽌绦件,也就是所谓的s q u a r e -e r r o r c r i t e r i o n :代表集群的中⼼(平均数),是集群内的物件,则代表集群。
210iKi p CiE p m =∈=?=∑∑i m i p i iC iK-MEANS的基本需求与优缺点建⽴K-means模型的要求:需要⼀个以上的In字段。
⽅向为Out、Both、None的字段将被忽略。
优点:建⽴K-means模型不需要分组数据。
对于⼤型数据集,K-means模型常常是最快的分群⽅法。
缺点:对于初始值的选择相当敏感,选择不同的初始值,可能会导致不同的分群结果。




机器学习算法day02_Kmeans聚类算法及应用课程大纲Kmeans聚类算法原理Kmeans聚类算法概述Kmeans聚类算法图示Kmeans聚类算法要点Kmeans聚类算法案例需求用Numpy手动实现用Scikili机器学习算法库实现Kmeans聚类算法补充算法缺点改良思路课程目标:1、理解Kmeans聚类算法的核心思想2、理解Kmeans聚类算法的代码实现3、掌握Kmeans聚类算法的应用步骤:数据处理、建模、运算和结果判定1.Kmeans聚类算法原理1.1概述K-means算法是集简单和经典于一身的基于距离的聚类算法采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。
该算法认为类簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
1.2算法图示假设我们的n个样本点分布在图中所示的二维空间。
从数据点的大致形状可以看出它们大致聚为三个cluster,其中两个紧凑一些,剩下那个松散一些,如图所示:我们的目的是为这些数据分组,以便能区分出属于不同的簇的数据,给它们标上不同的颜色,如图:1.3算法要点1.3.1核心思想通过迭代寻找k个类簇的一种划分方案,使得用这k个类簇的均值来代表相应各类样本时所得的总体误差最小。
k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
k-means算法的基础是最小误差平方和准则,其代价函数是:式中,μc(i)表示第i个聚类的均值。
各类簇内的样本越相似,其与该类均值间的误差平方越小,对所有类所得到的误差平方求和,即可验证分为k类时,各聚类是否是最优的。
上式的代价函数无法用解析的方法最小化,只能有迭代的方法。
1.3.2算法步骤图解下图展示了对n个样本点进行K-means聚类的效果,这里k取2。
1.3.3算法实现步骤k-means算法是将样本聚类成k个簇(cluster),其中k是用户给定的,其求解过程非常直观简单,具体算法描述如下:1)随机选取k个聚类质心点2)重复下面过程直到收敛{对于每一个样例i,计算其应该属于的类:对于每一个类j,重新计算该类的质心:}其伪代码如下:********************************************************************创建k个点作为初始的质心点(随机选择)当任意一个点的簇分配结果发生改变时对数据集中的每一个数据点对每一个质心计算质心与数据点的距离将数据点分配到距离最近的簇对每一个簇,计算簇中所有点的均值,并将均值作为质心2.Kmeans分类算法Python实战2.1需求对给定的数据集进行聚类本案例采用二维数据集,共80个样本,有4个类。
