K-MEANS(K均值聚类算法,C均值算法)
- 格式:pptx
- 大小:4.53 MB
- 文档页数:31

kmeans 算法K-Means算法,也称为K均值聚类算法,是一种无监督机器学习方法,用于将数据集分成K个簇群。
该算法的核心思想是将数据点划分为不同的簇群,使得同一簇群内的点相似度尽可能高,而不同簇群之间的相似度尽可能低。
该算法可用于许多领域,如计算机视觉、医学图像处理、自然语言处理等。
1.工作原理K-Means算法的工作原理如下:1. 首先,从数据集中随机选择K个点作为初始簇群的中心点。
2. 接下来,计算每个数据点与K个中心点之间的距离,并将它们归入距离最近的簇群中。
这个过程称为“分配”。
3. 在所有数据点都被分配到簇群后,重新计算每个簇群的中心点,即将簇群中所有数据点的坐标取平均值得出新的中心点。
这个过程称为“更新”。
4. 重复执行2-3步骤,直到簇群不再发生变化或达到最大迭代次数为止。
2.优缺点1. 简单易懂,实现方便。
2. 可用于处理大量数据集。
1. 随机初始化可能导致算法无法找到全局最优解。
2. 结果受到初始中心点的影响。
3. 对离群值敏感,可能导致簇群数量不足或簇群数量偏多。
4. 对于非球形簇群,K-Means算法的效果可能较差。
3.应用场景K-Means算法可以广泛应用于许多领域,如:1. 机器学习和数据挖掘:用于聚类分析和领域分类。
2. 计算机视觉:用于图像分割和物体识别。
3. 自然语言处理:用于文本聚类和词向量空间的子空间聚类。
4. 财务分析:用于分析财务数据,比如信用评分和市场分析。
5. 医学图像处理:用于医学影像分析和分类。
总之,K-Means算法是一种简单有效的聚类算法,可用于处理大量数据集、连续型数据、图像和文本等多种形式数据。
但在实际应用中,需要根据具体情况选择合适的簇群数量和初始中心点,在保证算法正确性和有效性的同时,减少误差和提高效率。

kmeans色彩聚类算法
K均值(K-means)色彩聚类算法是一种常见的无监督学习算法,用于将图像中的像素分组成具有相似颜色的集群。
该算法基于最小
化集群内部方差的原则,通过迭代寻找最优的集群中心来实现聚类。
首先,算法随机初始化K个集群中心(K为预先设定的参数),然后将每个像素分配到最接近的集群中心。
接下来,更新集群中心
为集群内所有像素的平均值,然后重新分配像素直到达到收敛条件。
最终,得到K个集群,每个集群代表一种颜色,图像中的像素根据
它们与集群中心的距离被归类到不同的集群中。
K均值色彩聚类算法的优点是简单且易于实现,对于大型数据
集也具有较高的效率。
然而,该算法也存在一些缺点,例如对初始
集群中心的选择敏感,可能收敛于局部最优解,对噪声和异常值敏
感等。
在实际应用中,K均值色彩聚类算法常被用于图像压缩、图像
分割以及图像检索等领域。
同时,为了提高算法的鲁棒性和效果,
通常会结合其他技术和方法,如颜色直方图、特征提取等。
此外,
还有一些改进的K均值算法,如加权K均值、谱聚类等,用于解决
K均值算法的局限性。
总之,K均值色彩聚类算法是一种常用的图像处理算法,通过对图像像素进行聚类,实现了图像的颜色分组和压缩,具有广泛的应用前景和研究价值。

kmeans的聚类算法K-means是一种常见的聚类算法,它可以将数据集划分为K个簇,每个簇包含相似的数据点。
在本文中,我们将详细介绍K-means算法的原理、步骤和应用。
一、K-means算法原理K-means算法基于以下两个假设:1. 每个簇的中心是该簇内所有点的平均值。
2. 每个点都属于距离其最近的中心所在的簇。
基于这两个假设,K-means算法通过迭代寻找最佳中心来实现聚类。
具体来说,该算法包括以下步骤:二、K-means算法步骤1. 随机选择k个数据点作为初始质心。
2. 将每个数据点分配到距离其最近的质心所在的簇。
3. 计算每个簇内所有数据点的平均值,并将其作为新质心。
4. 重复步骤2和3直到质心不再变化或达到预定迭代次数。
三、K-means算法应用1. 数据挖掘:将大量数据分成几组可以帮助我们发现其中隐含的规律2. 图像分割:将图像分成几个部分,每个部分可以看做是一个簇,从而实现图像的分割。
3. 生物学:通过对生物数据进行聚类可以帮助我们理解生物之间的相似性和差异性。
四、K-means算法优缺点1. 优点:(1)简单易懂,易于实现。
(2)计算效率高,适用于大规模数据集。
(3)结果可解释性强。
2. 缺点:(1)需要预先设定簇数K。
(2)对初始质心的选择敏感,可能会陷入局部最优解。
(3)无法处理非球形簇和噪声数据。
五、K-means算法改进1. K-means++:改进了初始质心的选择方法,能够更好地避免陷入局部最优解。
2. Mini-batch K-means:通过随机抽样来加快计算速度,在保证精度的同时降低了计算复杂度。
K-means算法是一种常见的聚类算法,它通过迭代寻找最佳中心来实现聚类。
该算法应用广泛,但也存在一些缺点。
针对这些缺点,我们可以采用改进方法来提高其效果。

Matlab的K-均值聚类Kmeans函数K-means聚类算法采用的是将N*P的矩阵X划分为K个类,使得类内对象之间的距离最大,而类之间的距离最小。
使用方法:Idx=Kmeans(X,K)[Idx,C]=Kmeans(X,K)[Idc,C,sumD]=Kmeans(X,K)[Idx,C,sumD,D]=Kmeans(X,K)各输入输出参数介绍:X---N*P的数据矩阵K---表示将X划分为几类,为整数Idx---N*1的向量,存储的是每个点的聚类标号C---K*P的矩阵,存储的是K个聚类质心位置sumD---1*K的和向量,存储的是类间所有点与该类质心点距离之和D---N*K的矩阵,存储的是每个点与所有质心的距离[┈]=Kmeans(┈,’Param1’,’Val1’,’Param2’,’Val2’,┈)其中参数Param1、Param2等,主要可以设置为如下:1、’Distance’---距离测度‘sqEuclidean’---欧氏距离‘cityblock’---绝对误差和,又称L1‘cosine’---针对向量‘correlation’---针对有时序关系的值‘Hamming’---只针对二进制数据2、’Start’---初始质心位置选择方法‘sample’---从X中随机选取K个质心点‘uniform’---根据X的分布范围均匀的随机生成K个质心‘cluster’---初始聚类阶段随机选取10%的X的子样本(此方法初始使用’sample’方法)Matrix提供一K*P的矩阵,作为初始质心位置集合3、’Replicates’---聚类重复次数,为整数使用案例:data=5.0 3.5 1.3 0.3 -15.5 2.6 4.4 1.2 06.7 3.1 5.6 2.4 15.0 3.3 1.4 0.2 -15.9 3.0 5.1 1.8 15.8 2.6 4.0 1.2 0[Idx,C,sumD,D]=Kmeans(data,3,’dist’,’sqEuclidean’,’rep’,4)运行结果:Idx =123132C =5.0000 3.4000 1.35000.2500-1.00005.6500 2.6000 4.2000 1.200006.3000 3.0500 5.3500 2.1000 1.0000sumD =0.03000.12500.6300D =0.015011.452525.535012.09500.0625 3.5550 29.6650 5.75250.3150 0.015010.752524.9650 21.4350 2.39250.3150 10.20500.0625 4.0850。

r语言的kmeans方法R语言中的k均值聚类方法(k-means clustering)是一种常用的无监督学习方法,用于将数据集划分为K个不相交的类别。
本文将详细介绍R语言中的k均值聚类算法的原理、使用方法以及相关注意事项。
原理:k均值聚类算法的目标是将数据集划分为K个簇,使得同一簇内的样本点之间的距离尽可能小,而不同簇之间的距离尽可能大。
算法的基本思想是:首先随机选择K个初始质心(簇的中心点),然后将每个样本点分配到与其最近的质心所在的簇中。
接下来,计算每个簇的新质心,再次将每个样本点重新分配到新的质心所在的簇中。
不断重复这个过程,直到质心不再发生变化或达到最大迭代次数。
最终,得到的簇就是我们需要的聚类结果。
实现:在R语言中,我们可以使用kmeans(函数来实现k均值聚类。
该函数的基本用法如下:kmeans(x, centers, iter.max = 10, nstart = 1)-x:要进行聚类的数据集,可以是矩阵、数据框或向量。
- centers:指定聚类的个数K,即要划分为K个簇。
- iter.max:迭代的最大次数,默认为10。
- nstart:进行多次聚类的次数,默认为1,选取最优结果。
聚类结果:聚类的结果包含以下内容:- cluster:每个样本所属的簇的编号。
- centers:最终每个簇的质心坐标。
- tot.withinss:簇内平方和,即同一簇内各个样本点到质心的距离总和。
示例:为了更好地理解k均值聚类的使用方法,我们将通过一个具体的示例来进行演示:```R#生成示例数据set.seed(123)x <- rbind(matrix(rnorm(100, mean = 0), ncol = 2),matrix(rnorm(100, mean = 3), ncol = 2))#执行k均值聚类kmeans_res <- kmeans(x, centers = 2)#打印聚类结果print(kmeans_res)```上述代码中,我们首先生成了一个包含两个簇的示例数据集x(每个簇100个样本点),然后使用kmeans(函数进行聚类,指定了聚类的个数为2、最后,通过print(函数来打印聚类的结果。

聚类是属于非监督学习中的应用。
非监督的意思是,我不知道label是什么,有什么。
其实在现实生活,给数据集标label的成本过高,所以大多数数据集是没有label,这也可以知道非监督学习的重要性。
这次给大家分享:K-means聚类、均值漂移聚类、基于密度的聚类、基于分布的聚类(本文用高斯分布做例子)、层次聚类。
1. K-means 聚类1)过程:S1. 选定K,K是最终聚类的数目。
这需要一定的先验知识,如果没有的话,可能需要随机试再用交叉验证看分类效果哪个更好,就选定那个K。
S2. 选取K个初始的质心,最好不要选太近的质心,因为初始质心的选择虽然不会影响最终结果,但是影响算法运行的时间。
S3. 计算每个样本离这些质心的距离,选择最近的质心并与它结合为一类。
S4. 得到K个类之后,重新计算每一个类中新的质心,重复以上步骤,直至质心不再改变。
2)K-Means的主要优点有:a. 原理比较简单,实现也是很容易,收敛速度快。
b. 聚类效果较优。
c. 算法的可解释度比较强。
d. 主要需要调参的参数仅仅是簇数k。
3)K-Means的主要缺点有:a. K值的选取不好把握b. 只能处理球形的簇c. 对于不是凸的数据集比较难收敛d. 如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳。
e. 采用迭代方法,得到的结果只是局部最优。
f. 对噪音和异常点比较的敏感(因为质心的选择基于均值,所以之后也有K-median聚类算法,这样可以减小噪音和异常点的影响,但运行速度变得更慢)。
2. 均值漂移聚类1)原理a. 假定样本空间中的每个聚类均服从某种已知的概率分布规则b. 用不同的概率密度函数拟合样本中的统计直方图,不断移动密度函数的中心(均值)的位置,直到获得最佳拟合效果为止。
c. 这些概率密度函数的峰值点就是聚类的中心,再根据每个样本距离各个中心的距离,选择最近聚类中心所属的类别作为该样本的类别。

简述k均值聚类算法的流程K均值聚类算法(K-meansClusteringAlgorithm,简称KMC)是一种基于数据集合分类的机器学习算法,在当今的机器学习领域中,KMC算法是分类,建模和发现深度结构常用的机器学习算法之一。
它通过将各种数据点分为K个聚类,来获得数据特征,从而方便对数据进行分析。
KMC算法的核心流程可以分成四步:第一步:划分K个中心点。
首先,在给定数据集中选择K个点作为聚类的中心,这些点称为中心点,可以是任意的点或者选择某个算法来选择随机的中心点;第二步:计算每个点到中心点的距离。
计算每个点和K个中心点之间的距离,并把此计算结果存储为K维数组,即K维数组;第三步:根据每个点到K个中心点的距离,将每一个点划分到离它最近的中心点的聚类中;第四步:重新计算中心点的坐标,重新计算每个聚类的中心点,以当前的聚类项的坐标为新的中心点,重复上述的第二步和第三步,如此反复,直到聚类不再发生变化为止,这就是KMC算法的核心思想。
KMC算法是一种基于数据集应用算法,旨在快速将数据集中的数据进行分类、建模和发现数据深层次结构的机器学习算法。
它的核心流程特别简单,以选择K个中心点为起点,计算每个点到K个中心点的距离,将每个点划分至离它最近的中心点的聚类中,重新计算中心点的坐标,直到聚类不再发生变化,此过程可以十分有效地为用户提供相关建模和发现数据深层次结构的机器学习算法。
KMC算法的应用非常广泛,有两个重要的场景,一个是用于文本摘要,另一个是用于推荐系统,用于文本摘要时,KMC算法会将文章中的信息做聚类分析,将聚类结果作为文摘;而在推荐系统中,KMC 算法可以将用户的操作行为聚类,根据用户行为的分类特征,可以对用户进行推荐。
KMC算法可以说是一种令人不可思议的算法,它的简易性和效率在当今的机器学习领域中非常受重视,它的优势是可以以简单的方式快速实现结果,为机器学习中分类、建模和发现深度结构提供了很多便利。

K-means聚类算法1. 概述K-means聚类算法也称k均值聚类算法,是集简单和经典于⼀⾝的基于距离的聚类算法。
它采⽤距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越⼤。
该算法认为类簇是由距离靠近的对象组成的,因此把得到紧凑且独⽴的簇作为最终⽬标。
2. 算法核⼼思想K-means聚类算法是⼀种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中⼼,然后计算每个对象与各个种⼦聚类中⼼之间的距离,把每个对象分配给距离它最近的聚类中⼼。
聚类中⼼以及分配给它们的对象就代表⼀个聚类。
每分配⼀个样本,聚类的聚类中⼼会根据聚类中现有的对象被重新计算。
这个过程将不断重复直到满⾜某个终⽌条件。
终⽌条件可以是没有(或最⼩数⽬)对象被重新分配给不同的聚类,没有(或最⼩数⽬)聚类中⼼再发⽣变化,误差平⽅和局部最⼩。
3. 算法实现步骤1、⾸先确定⼀个k值,即我们希望将数据集经过聚类得到k个集合。
2、从数据集中随机选择k个数据点作为质⼼。
3、对数据集中每⼀个点,计算其与每⼀个质⼼的距离(如欧式距离),离哪个质⼼近,就划分到那个质⼼所属的集合。
4、把所有数据归好集合后,⼀共有k个集合。
然后重新计算每个集合的质⼼。
5、如果新计算出来的质⼼和原来的质⼼之间的距离⼩于某⼀个设置的阈值(表⽰重新计算的质⼼的位置变化不⼤,趋于稳定,或者说收敛),我们可以认为聚类已经达到期望的结果,算法终⽌。
6、如果新质⼼和原质⼼距离变化很⼤,需要迭代3~5步骤。
4. 算法步骤图解上图a表达了初始的数据集,假设k=2。
在图b中,我们随机选择了两个k类所对应的类别质⼼,即图中的红⾊质⼼和蓝⾊质⼼,然后分别求样本中所有点到这两个质⼼的距离,并标记每个样本的类别为和该样本距离最⼩的质⼼的类别,如图c所⽰,经过计算样本和红⾊质⼼和蓝⾊质⼼的距离,我们得到了所有样本点的第⼀轮迭代后的类别。
此时我们对我们当前标记为红⾊和蓝⾊的点分别求其新的质⼼,如图d所⽰,新的红⾊质⼼和蓝⾊质⼼的位置已经发⽣了变动。

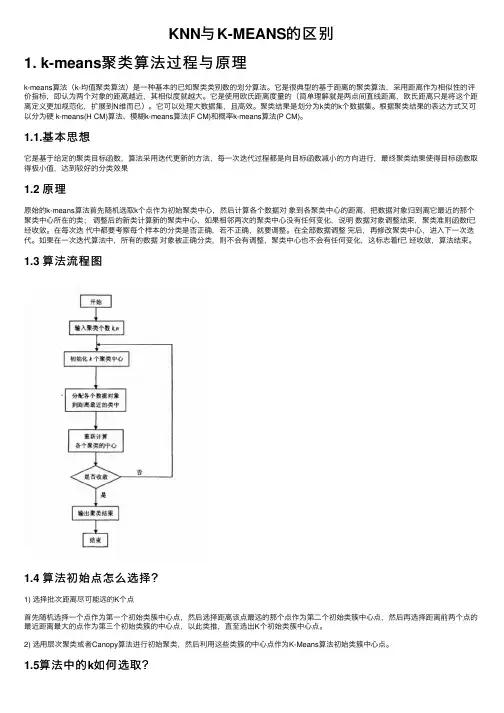
KNN与K-MEANS的区别1. k-means聚类算法过程与原理k-means算法(k-均值聚类算法)是⼀种基本的已知聚类类别数的划分算法。
它是很典型的基于距离的聚类算法,采⽤距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越⼤。
它是使⽤欧⽒距离度量的(简单理解就是两点间直线距离,欧⽒距离只是将这个距离定义更加规范化,扩展到N维⽽已)。
它可以处理⼤数据集,且⾼效。
聚类结果是划分为k类的k个数据集。
根据聚类结果的表达⽅式⼜可以分为硬 k-means(H CM)算法、模糊k-means算法(F CM)和概率k-means算法(P CM)。
1.1.基本思想它是基于给定的聚类⽬标函数,算法采⽤迭代更新的⽅法,每⼀次迭代过程都是向⽬标函数减⼩的⽅向进⾏,最终聚类结果使得⽬标函数取得极⼩值,达到较好的分类效果1.2 原理原始的k-means算法⾸先随机选取k个点作为初始聚类中⼼,然后计算各个数据对象到各聚类中⼼的距离,把数据对象归到离它最近的那个聚类中⼼所在的类;调整后的新类计算新的聚类中⼼,如果相邻两次的聚类中⼼没有任何变化,说明数据对象调整结束,聚类准则函数f已经收敛。
在每次迭代中都要考察每个样本的分类是否正确,若不正确,就要调整。
在全部数据调整完后,再修改聚类中⼼,进⼊下⼀次迭代。
如果在⼀次迭代算法中,所有的数据对象被正确分类,则不会有调整,聚类中⼼也不会有任何变化,这标志着f已经收敛,算法结束。
1.3 算法流程图1.4 算法初始点怎么选择?1) 选择批次距离尽可能远的K个点⾸先随机选择⼀个点作为第⼀个初始类簇中⼼点,然后选择距离该点最远的那个点作为第⼆个初始类簇中⼼点,然后再选择距离前两个点的最近距离最⼤的点作为第三个初始类簇的中⼼点,以此类推,直⾄选出K个初始类簇中⼼点。
2) 选⽤层次聚类或者Canopy算法进⾏初始聚类,然后利⽤这些类簇的中⼼点作为K-Means算法初始类簇中⼼点。

kmeans算法公式K均值聚类算法(K-means clustering algorithm)是一种常用的无监督学习算法,用于将一组数据点划分为K个不同的组或聚类。
该算法的目标是最小化数据点与其所属聚类中心之间的平方距离。
算法步骤如下:1. 随机选择K个数据点作为初始聚类中心。
2. 将每个数据点分配给距离最近的聚类中心。
3. 更新每个聚类中心的位置,将其设为该聚类中所有点的均值。
4. 重复步骤2和3,直到聚类中心不再改变或达到最大迭代次数。
具体而言,K均值算法可用以下公式表示:1. 选择K个聚类中心:C = {c1, c2, ..., ck}其中,ci表示第i个聚类中心。
2. 分配数据点到最近的聚类中心:使用欧氏距离作为度量衡量数据点xi与聚类中心cj之间的距离:dist(xi, cj) = sqrt((xi1 - cj1)^2 + (xi2 - cj2)^2 + ... + (xid - cjd)^2)其中,d表示数据点的维度。
将每个数据点xi分配给最近的聚类中心:ci = arg minj(dist(xi, cj))3. 更新聚类中心的位置:计算每个聚类中心包含的数据点的均值,作为新的聚类中心的位置。
cj = (1/|ci|) * sum(xi)其中,|ci|表示聚类中心ci包含的数据点数量,sum(xi)表示所有聚类中心ci包含的数据点xi的和。
4. 重复步骤2和3,直到聚类中心不再改变或达到最大迭代次数。
K均值算法的优点是简单而高效,适用于大规模数据集。
然而,它也存在一些限制,比如对初始聚类中心的敏感性和对数据点分布的假设(即聚类簇的凸性)。
此外,当数据点的维度较高时,K均值算法的性能可能下降。
参考内容:- Christopher M. Bishop, "Pattern Recognition and Machine Learning". Springer, 2006.- Richard O. Duda, Peter E. Hart, David G. Stork, "Pattern Classification". Wiley, 2001.- Machine Learning, Tom Mitchell, "Machine Learning". McGraw-Hill, 1997.- Kevin P. Murphy, "Machine Learning: A Probabilistic Perspective". MIT Press, 2012.- Sebastian Raschka, Vahid Mirjalili, "Python Machine Learning". Packt Publishing, 2017.这些参考内容提供了对K均值算法的详细解释、数学推导和实际应用示例,对于深入理解和使用该算法非常有帮助。
KMEANSK均值聚类算法C均值算法K-means和C-means是两种常用的均值聚类算法。
它们都是通过计算数据点之间的距离来将数据划分为不同的簇。
K-means算法的基本思想是先随机选择K个初始聚类中心,然后迭代地将数据点分配到最近的聚类中心,并更新聚类中心的位置,直到聚类中心不再发生变化或达到预设的迭代次数。
具体步骤如下:1.随机选择K个初始聚类中心。
2.对每个数据点,计算其到每个聚类中心的距离,将其分配到距离最近的聚类中心的簇。
3.更新每个聚类中心的位置为该簇中所有数据点的均值。
4.重复步骤2和3,直到聚类中心不再发生变化或达到预设的迭代次数。
K-means算法的优点是简单易懂,计算复杂度较低。
但缺点是需要事先确定聚类的数量K,并且对初始聚类中心的选择比较敏感,可能会陷入局部最优解。
C-means算法是一种模糊聚类算法,与K-means算法类似,但每个数据点可以属于多个簇,而不是只属于一个确定的簇。
C-means算法引入了一个模糊权重因子,用于描述数据点与每个聚类中心的相似程度。
具体步骤如下:1.随机选择C个初始聚类中心。
2.对每个数据点,计算其与每个聚类中心的相似度,并计算出属于每个聚类中心的隶属度。
3.更新每个聚类中心的位置为该簇中所有数据点的加权均值,其中权重为隶属度的指数。
4.重复步骤2和3,直到聚类中心不再发生变化或达到预设的迭代次数。
C-means算法的优点是可以更灵活地表示数据点与聚类中心之间的关系,并且对于模糊性较强的数据集有更好的效果。
但缺点是计算复杂度较高,且需要事先确定聚类的数量C和模糊权重因子。
在实际应用中,K-means和C-means算法经常用于数据挖掘、模式识别和图像分割等领域。
它们都有各自的优缺点,需要根据具体问题的需求选择合适的算法。
此外,还可以通过改进算法的初始值选择、距离度量和迭代停止条件等方面来提高聚类的效果。
基因表达数据分析中聚类算法的使用教程与生物学意义解读基因表达数据分析是生物学研究中的重要环节之一,它可以帮助我们理解基因的功能及其在不同生理条件下的调控机制。
而聚类算法作为一种常用的数据分析方法,可以帮助我们对基因表达数据进行分类和分组,进而揭示出隐藏在数据中的生物学意义。
本文将介绍常见的聚类算法及其在基因表达数据分析中的应用,并解读其生物学意义。
聚类算法是一种无监督学习方法,通过将相似的样本归为一类,将不相似的样本归为不同类别,从而将数据集划分为多个簇。
在基因表达数据分析中,聚类算法可以帮助我们发现具有相似表达模式的基因及其可能的生物学功能。
常见的聚类算法包括层次聚类、k-means聚类和模糊C-均值聚类。
层次聚类是一种基于距离的聚类算法,它可以将样本逐步合并成不同规模的簇。
在基因表达数据分析中,我们可以使用层次聚类算法将基因按照其表达模式进行分组。
首先,我们需要选择一个相似性度量指标,如欧氏距离或相关系数,来衡量基因间的距离。
然后,使用层次聚类算法将基因逐步合并,直到形成最终的聚类结果。
通过观察聚类结果,我们可以发现具有相似表达模式的基因并对其进行功能注释和生物学意义解读。
k-means聚类是一种基于中心点的聚类算法,它根据样本与中心点的距离来划分簇。
在基因表达数据分析中,k-means聚类可以帮助我们将基因分为指定数量的簇。
首先,我们需要选择一个合适的k值,即簇的数量。
然后,根据基因间的相似性度量指标,如欧氏距离或相关系数,运用k-means聚类算法将基因划分为k个簇。
最后,我们可以通过分析聚类结果来揭示不同簇中基因的生物学意义,如同一簇中的基因可能具有相似的功能或参与相同的生物过程。
模糊C-均值聚类是一种基于模糊理论的聚类算法,它可将样本划分为多个簇,并对样本和簇的隶属度进行建模。
在基因表达数据分析中,模糊C-均值聚类可以帮助我们识别具有模糊表达模式的基因。
首先,我们需要选择合适的簇数和模糊隶属度的阈值。
kmeans算法原理K-Means算法,又叫k均值算法,是一种比较流行的数据聚类算法,它是一种迭代聚类算法,旨在将数据分为K个聚类,每个聚类具有最相似的数据点。
K-Means算法最初被使用于一些研究领域,例如音频处理和图像处理,但是在数据挖掘和机器学习领域中,K-Means 算法也被广泛使用,用于挖掘和识别隐藏的模式和结构,以及比较大型数据集的好处。
K-Means算法的基本原理K-Means算法是一种基于迭代的聚类算法,它利用距离公式将数据集分为k个不同的聚类,每个聚类具有最相似的数据点。
K-Means 算法的基本流程如下:(1)首先,确定数据集中簇的数量K。
(2)然后,将数据集中的每个数据点分配到K个不同的聚类。
(3)最后,按照每个聚类的平均值更新每个聚类的中心点,并将每个数据点根据距离新的聚类中心点的距离重新分配到新的聚类中。
K-Means算法的优点(1)K-Means算法的计算容易,它的时间复杂度较低,可以在大数据集上应用。
(2)可以用来快速对大型数据集进行聚类,可以轻松发现隐藏在数据中的模式和结构。
(3)K-Means算法也可以用来进行压缩,K-Means算法可以确定数据元素的聚类,从而减少数据集的大小。
(4)K-Means算法也可以用来发现预测模型,K-Means可以用来挖掘和识别隐藏的模式和结构,从而发现预测模型。
K-Means算法的缺点(1)K-Means算法为聚类选择的K值敏感,只有当K值适当时,K-Means算法才能得到最佳结果。
(2)K-Means算法在处理非球形数据集时效果不佳,K-Means算法会将数据分配到最近的聚类中心,但是对于非球形数据集来说,最近的聚类中心并不能很好的表示数据。
(3)K-Means算法在选择聚类中心的时候也有一定的局限性,K-Means算法选择的聚类中心受到初始值的影响,因此算法的结果受初始值的影响。
结论K-Means算法可以有效的将大型数据集分割成不同的聚类,是聚类分析中一种最常用的算法。
k均值聚类(k-meansclustering)k均值聚类(k-means clustering)算法思想起源于1957年Hugo Steinhaus[1],1967年由J.MacQueen在[2]第⼀次使⽤的,标准算法是由Stuart Lloyd在1957年第⼀次实现的,并在1982年发布[3]。
简单讲,k-means clustering是⼀个根据数据的特征将数据分类为k组的算法。
k是⼀个正整数。
分组是根据原始数据与聚类中⼼(cluster centroid)的距离的平⽅最⼩来分配到对应的组中。
例⼦:假设我们有4个对象作为训练集,每个对象都有两个属性见下。
可根据x,y坐标将数据表⽰在⼆维坐标系中。
object Atrribute 1 (x):weight indexAttribute 2 (Y):pHMedicine A11Medicine B21Medicine C43Medicine D54表⼀原始数据并且我们知道这些对象可依属性被分为两组(cluster 1和cluster 2)。
问题在于如何确定哪些药属于cluster 1,哪些药属于cluster 2。
k-means clustering实现步骤很简单。
刚开始我们需要为各个聚类中⼼设置初始位置。
我们可以从原始数据中随机取出⼏个对象作为聚类中⼼。
然后k means算法执⾏以下三步直⾄收敛(即每个对象所属的组都不改变)。
1.确定中⼼的坐标2.确定每个对象与每个中⼼的位置3.根据与中⼼位置的距离,每个对象选择距离最近的中⼼归为此组。
图1 k means流程图对于表1中的数据,我们可以得到坐标系中的四个点。
1.初始化中⼼值:我们假设medicine A和medicine B作为聚类中⼼的初值。
⽤c1和c2表⽰中⼼的坐标,c1=(1,1),c2=(2,1)。
2对象-中⼼距离:利⽤欧式距离(d = sqrt((x1-x2)^2+(y1-y2)^2))计算每个对象到每个中⼼的距离。
7种常用的聚类方法聚类是一种常用的数据挖掘算法,它的目的是将大量数据中的对象以类的形式进行分类。
在机器学习领域,聚类有着广泛的应用,本文将介绍7种常用的聚类方法,并针对其优势与劣势进行介绍。
第一种聚类方法是K均值(K-means)聚类。
K均值聚类是最常用的聚类算法之一,它利用数据对象之间的距离来划分聚类,通过不断重新计算距离,最终形成最佳聚类。
K均值聚类具有算法简单,分类速度快等优点,但同时具有聚类结果较为粗糙等劣势。
第二种聚类方法是层次聚类。
层次聚类是一种根据样本间的相似性对对象进行划分的方法,它首先把每个样本看做一个类,然后不断地把相似的类合并,直到满足某一条件为止。
层次聚类的优点是可以有效地进行大规模的数据分析,分析结果比较准确,在给定的聚类数目里能够得到最优结果,但是层次聚类的运行时间较长,且无法处理数据缺失等问题。
第三种聚类方法是模糊c均值聚类(FCM)。
模糊c均值聚类是基于K均值聚类的一种改进算法,它允许每一个数据对象同时属于多个不同的类。
FCM可以解决K均值聚类的不确定性和模糊性问题,具有可以提高分类准确性,可以处理非球形类等优势,但同时具有复杂度高,难以精确参数等劣势。
第四种聚类方法是基于密度的聚类(DBSCAN)。
DBSCAN可以有效地将数据点按照其密度划分为不同的类,它将空间距离和密度作为划分数据点的方式,把低密度区域划分为噪声点,把具有较高密度的区域划分为聚类,DBSCAN具有算法简单,可以识别异常点的优点,但同时需要用户设置一个密度阈值,而且难以处理数据缺失等问题。
第五种聚类方法是基于分布的聚类(GMM)。
GMM是一种概率模型,它利用一个混合参数模型来表达数据的分布,其中每一个组分表示一个聚类类别。
GMM有着较高的准确度,处理多分量分布,不需要自行调整参数等优点,但同时具有计算量大,对运行环境要求较高等劣势。
第六种聚类方法是平衡迭代聚类(BIRCH)。
BIRCH是一种基于树结构的聚类算法,其目的是通过构建CF树来细分由大量数据点组成的类,BIRCH的优势在于其运行速度较快,能够处理大规模的数据,但同时具有聚类结果与K均值聚类结果相比较模糊,计算空间要求较高等劣势。