Lucene开发实例教程01 课程介绍
- 格式:ppt
- 大小:2.72 MB
- 文档页数:15


昆明南天电脑系统有限公司 2019年8月LUCENE 开发部署指导手册昆明南天开发中心编者:陈俊第1章引言1.1前言●编制本手册的目的:1.描述Lucene用途,使开发人员依据本手册初步认识Lucene;2.描述Lucene的API,使开发人员可以快速认识并利用Lucene开发搜索引擎;3.描述Lucene和webdt的融合;4. 重点描述Lucene的应用,使开发人员可按照本手册的描述开发。
●本手册面向的读者:熟悉Java开发,并对WEBDT软件的特点(请参阅《技术白皮书》)具有初步认识的技术人员。
1.2概述本手册首先介绍了Lucene的概念,详细描述了简单快速地将Lucene融入WEBDT运行平台并进行实际开发的方法,使技术人员对Lucene有一个概要性的框架认识,为下一步开发工作奠定基础。
第2章LUCENE 简介2.1什么是LUNCENELucene是一套java API,就如同Servlet是一套API一样。
Lucene 不是一个独立的搜索引擎系统,但是你可以使用Luncene来开发搜索引擎系统。
这正如Servlet不是网站系统但是你可以用Servlet开发网站一样。
有人已经用Lucene开发出了独立的搜索引擎系统,你可以下载,然后不写一行代码就是用它。
Nutch是最出名的了。
Lucene是一个全文搜索框架,而不是应用产品。
因此它并不像baidu 或者google Desktop那么拿来就能用,它只是提供了一种工具让你能实现这些产品。
2.2LUNCENE能做什么要回答这个问题,先要了解Lucene的本质。
实际上Lucene的功能很单一,说到底,就是你给它若干个字符串,然后它为你提供一个全文搜索服务,告诉你你要搜索的关键词出现在哪里。
知道了这个本质,你就可以发挥想象做任何符合这个条件的事情了。
你可以把站内新闻都索引了,做个资料库;你可以把一个数据库表的若干个字段索引起来,那就不用再担心因为“%like%”而锁表了;你也可以写个自己的搜索引擎……2.3你该不该选择Lucene下面给出一些测试数据,如果你觉得可以接受,那么可以选择。
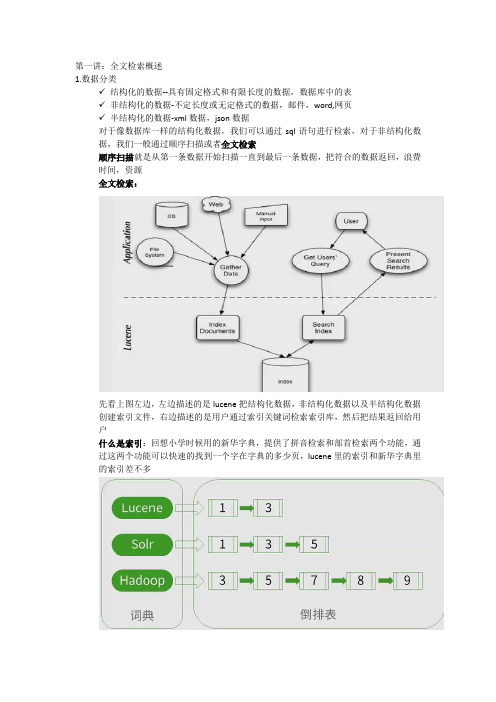
第一讲:全文检索概述1.数据分类✓结构化的数据--具有固定格式和有限长度的数据,数据库中的表✓非结构化的数据-不定长度或无定格式的数据,邮件,word,网页✓半结构化的数据-xml数据,json数据对于像数据库一样的结构化数据,我们可以通过sql语句进行检索,对于非结构化数据,我们一般通过顺序扫描或者全文检索顺序扫描就是从第一条数据开始扫描一直到最后一条数据,把符合的数据返回,浪费时间,资源全文检索:先看上图左边,左边描述的是lucene把结构化数据,非结构化数据以及半结构化数据创建索引文件,右边描述的是用户通过索引关键词检索索引库,然后把结果返回给用户什么是索引:回想小学时候用的新华字典,提供了拼音检索和部首检索两个功能,通过这两个功能可以快速的找到一个字在字典的多少页,lucene里的索引和新华字典里的索引差不多看上图:该图可表示为lucene这个词在第1篇和第3篇文档里出现过,Solr这个词在第1篇、第3篇文和第五篇文档里出现过,Hadoop这个词在第3篇、第5篇、第7篇、第8篇、第9篇文档里出现过。
图的左边可以看作是新华字典里的拼音或者部首索引,右边就是检索出词语的位置,这里的索引又叫反向索引反向索引:这种由字符串到文件的映射是文件到字符串映射的反向过程,文件到字符串的映射,比如我们有一片PPT,里面内容的标题就是“全文检索概述-索引定义”,那么我们就可以把这一片PPT看成一个文件,名字就是“全文检索概述-索引定义”,这也就说明“全文检索概述-索引定义”在这个文件里出现过2.全文索引过程✓创建检索创建检索三部曲:需要检索的数据(Documents),分词技术(Analyzer),索引创建(indexer)第一步:Documents事例数据●极客学院教程●Luence案例开发●Lucene实时搜索第二步:分词技术(这里采用标准分词)●极|客|学|院|教|程●Luence|案|例|开|发●Lucene|实|时|搜|索●标准分词就是把一段中文分成一个个独立的单词,对于英文就是把它转换成词根。

Lucene初级教程2007-12-26 15:24 点击次数:0 次1 lucene简介1.1 什么是luceneLucene是一个全文搜索框架,而不是应用产品。
因此它并不像 或者google Desktop那么拿来就能用,它只是提供了一种工具让你能实现这些产品。
2 lucene的工作方式lucene提供的服务实际包含两部分:一入一出。
所谓入是写入,即将你提供的源(本质是字符串)写入索引或者将其从索引中删除;所谓出是读出,即向用户提供全文搜索服务,让用户可以通过关键词定位源。
2.1写入流程源字符串首先经过analyzer处理,包括:分词,分成一个个单词;去除stopword(可选)。
将源中需要的信息加入Document的各个Field中,并把需要索引的Field索引起来,把需要存储的Field存储起来。
将索引写入存储器,存储器可以是内存或磁盘。
2.2读出流程用户提供搜索关键词,经过analyzer处理。
对处理后的关键词搜索索引找出对应的Document。
用户根据需要从找到的Document中提取需要的Field。
3 一些需要知道的概念3.1 analyzerAnalyzer是分析器,它的作用是把一个字符串按某种规则划分成一个个词语,并去除其中的无效词语,这里说的无效词语是指英文中的“of”、“the”,中文中的“的”、“地”等词语,这些词语在文章中大量出现,但是本身不包含什么关键信息,去掉有利于缩小索引文件、提高效率、提高命中率。
分词的规则千变万化,但目的只有一个:按语义划分。
这点在英文中比较容易实现,因为英文本身就是以单词为单位的,已经用空格分开;而中文则必须以某种方法将连成一片的句子划分成一个个词语。
具体划分方法下面再详细介绍,这里只需了解分析器的概念即可。
3.2 document用户提供的源是一条条记录,它们可以是文本文件、字符串或者数据库表的一条记录等等。
一条记录经过索引之后,就是以一个Document的形式存储在索引文件中的。

Lucene⼊门+实现Lucene简介详情见:()lucene实现原理其实⽹上很多资料表明了,lucene底层实现原理就是倒排索引(invertedindex)。
那么究竟什么是倒排索引呢?经过Lucene分词之后,它会维护⼀个类似于“词条--⽂档ID”的对应关系,当我们进⾏搜索某个词条的时候,就会得到相应的⽂档ID。
不同于传统的顺排索引根据⼀个词,知道有哪⼏篇⽂章有这个词。
图解:Lucene在搜索前⾃⾏⽣成倒排索引,相⽐数据库中like的模糊搜索效率更⾼!Lucene 核⼼API索引过程中的核⼼类1. Document⽂档:他是承载数据的实体(他可以集合信息域Field),是⼀个抽象的概念,⼀条记录经过索引之后,就是以⼀个Document的形式存储在索引⽂件中的。
2. Field:Field 索引中的每⼀个Document对象都包含⼀个或者多个不同的域(Field),域是由域名(name)和域值(value)对组成,每⼀个域都包含⼀段相应的数据信息。
3. IndexWriter:索引过程的核⼼组件。
这个类⽤于创建⼀个新的索引并且把⽂档加到已有的索引中去,也就是写⼊操作。
4. Directroy:是索引的存放位置,是个抽象类。
具体的⼦类提供特定的存储索引的地址。
(FSDirectory 将索引存放在指定的磁盘中,RAMDirectory ·将索引存放在内存中。
)5. Analyzer:分词器,在⽂本被索引之前,需要经过分词器处理,他负责从将被索引的⽂档中提取词汇单元,并剔除剩下的⽆⽤信息(停⽌词汇),分词器⼗分关键,因为不同的分词器,解析相同的⽂档结果会有很⼤的不同。
Analyzer是⼀个抽象类,是所有分词器的基类。
搜索过程中的核⼼类1. IndexSearcher :IndexSearcher 调⽤它的search⽅法,⽤于搜索IndexWriter 所创建的索引。
2. Term :Term 使⽤于搜索的⼀个基本单元。

一个经典Lucene入门模块及例子解析Lucene是一个很强大的全文搜索工具,许多公司或软件实现都用到它,如一些公司用它来查子网信息,再如Eclipse等软件就是用它来实现索引的。
这里给出Lucene的一个简单例子的代码来说明其大致使用流程模块,建立一个简单的Java搜索引擎。
首先我们给出大概模块的代码,实际应用中会视情况而修改。
Lucene实例代码:建立数据(data)的索引(Index)1.用IndexWriter建立一个Lucene index2.创建一个Lucene Document3.将 Lucene document放进 index 中4.优化(optimize)和关闭(close)index用IndexWriter建立Lucene indexString indexPath = "/path/to/whereYou/wantThe/IndexStored"; IndexWriter writer = null;try {// Make a lucene writer and create new Lucene index with arg3 = true writer = new IndexWriter(indexPath, new StandardAnalyzer(), true); } catch (IOException e){System.out.println("IOException opening Lucene IndexWriter: " +e.getMessage());}创建一个 Lucene documentString content = "This is the example text I want to have Lucene index"; Document doc = new Document(); doc.add(Field.Text("content",content));将上述创建的document加进 index中try {writer.addDocument(doc);} catch (IOException e) {System.out.println("IOException adding Lucene Document: " +e.getMessage());}优化(optimize)和关闭( close)IndexWritertry {writer.optimize();writer.close();}catch (IOException e) {System.out.println("IOException closing Lucene IndexWriter: " +e.getMessage());}Lucene实例代码: 建立搜索(Search)步骤打开一个 Lucene IndexSearcher许多Lucene刚开始使用者都不注意从用IndexWriter的问题。
Lucene教程详解Lucene-3.0.0配置一、Lucene开发环境配置step1.Lucene开发包下载step2.Java开发环境配置step3.Tomcat安装step4.Lucene开发环境配置解压下载的lucene-3.0.0.zip,可以看到lucene-core-3.0.0.jar和lucene-demos-3.0.0.jar这两个文件,将其解压(建议放在安装jdk的lib文件夹内),并把路径添加到环境变量的classpath。
二、Lucene开发包中Demo调试控制台应用程序step1.建立索引>java org.apache.lucene.demo.IndexFiles [C:\Java](已经存在的任意文件路径)将对C:\Java下所有文件建立索引,同时,在当前命令行位置将生成“index”文件夹。
step2.执行查询>java org.apache.lucene.demo.SearchFiles将会出现“Query:”提示符,在其后输入关键字,回车,即可得到查询结果。
Web应用程序step1.将lucene-core-3.0.0.jar和lucene-demos-3.0.0jar这两个文件复制到安装Tomcat 的\common\lib中step2.解压下载的lucene-3.0.0.zip,可以看到luceneweb.war文件。
将该文件复制到安装Tomcat的\webappsstep3.重启Tomcat服务器。
step4.建立索引>java org.apache.lucene.demo.IndexHTML -create -index [索引数据存放路径] [被索引文件路径](如:D:\lucene\temp\index D:\lucene\temp\docs)step5.打开安装Tomcat的\webapps\luceneweb\configuration.jsp文件,找到String indexLocation = "***",将"***"改为第四步中[索引数据存放路径],保存关闭。
Lucene搜索入门教程1.了解搜索技术1.1搜索引擎搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。
搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
搜索引擎的原理可以看到搜索引擎的功能主要是三部分:●爬行和抓取数据(爬虫多用python来编写、但是java也能实现)●对数据对预处理(提取文字、中文分词、建立倒排索引)提供搜索功能(用户输入关键词后、去索引库搜索数据)在上述三个步骤中,java要解决的往往是后两个步骤:数据处理和搜索。
那么,我们之前学习的mysql知识也能实现数据的存储和搜索,为什么还要学新的东西呢?1.2传统数据库搜索的问题要实现类似百度的复杂搜索,或者京东的商品搜索,如果使用传统的数据库存储数据,那么会存在一系列的问题:●数据库数据单表存储能力有限,无法存储海量数据●解决大数据,可以进行分库分表。
但是分库分表会增加业务复杂度●搜索只能通过模糊匹配,效率极低●模糊搜索可能导致全表扫描,效率非常差在这里,比较棘手的其实是第二个问题:查询效率低,类似百度和京东这样的网站,对性能要求极高。
如果用户点击搜索需要很久才能拿到数据,没人愿意一直等待下去。
那么问题来了:如何才能提高模糊搜索时的效率呢?答案是:倒排索引技术1.3什么是倒排索引倒排索引是一种存储数据的方式,与传统查找有很大区别:●传统查找:采用数据按行存储,查找时逐行扫描,或者根据索引查找,然后匹配搜索条件,效率较差.概括来讲是先找到文档,然后看是否匹配.传统线性查找一个10MB的word文件,查找关键字如果在文档最后,大约3秒钟●倒排索引:首先对文档数据按照id进行索引存储,然后对文档中的数据分词,记录对词条进行索引,并记录词条在文档中出现的位置。
这样查找时只要找到了词条,就找到了对应的文档。