用Lucene检索数据库
- 格式:doc
- 大小:49.50 KB
- 文档页数:10

用Lucene检索数据库1.写一段传统的JDBC程序,讲每条的用户信息从数据库读取出来2.针对每条用户记录,建立一个lucene documentDocument doc = new Document();并根据你的需要,将用户信息的各个字段对应luncene document中的field 进行添加,如:doc.add(newField("NAME","USERNAME",Field.Store.YES,Field.Index.UN_TOKENIZED));然后将该条doc加入到索引中,如:luceneWriter.addDocument(doc);这样就建立了lucene的索引库3.编写对索引库的搜索程序(看lucene文档),通过对lucene的索引库的查找,你可以快速找到对应记录的ID4.通过ID到数据库中查找相关记录用Lucene索引数据库Lucene,作为一种全文搜索的辅助工具,为我们进行条件搜索,无论是像Google,Baidu 之类的搜索引擎,还是论坛中的搜索功能,还是其它C/S架构的搜索,都带来了极大的便利和比较高的效率。
本文主要是利用Lucene对MS Sql Server 2000进行建立索引,然后进行全文索引。
至于数据库的内容,可以是网页的内容,还是其它的。
本文中数据库的内容是图书馆管理系统中的某个作者表-Authors表。
因为考虑到篇幅的问题,所以该文不会讲的很详细,也不可能讲的很深。
本文以这样的结构进行:1.介绍数据库中Authors表的结构2.为数据库建立索引3.为数据库建立查询功能4.在web界面下进行查询并显示结果1.介绍数据库中Authors表的结构字段名称字段类型字段含义Au_id Varchar(11) 作者号Au_name Varchar(60) 作者名Phone Char(12) 电话号码Address Varchar(40) 地址City Varchar(20) 城市State Char(2) 省份Zip Char(5) 邮编contract Bit(1) 外键(关系不大)表中的部分内容:2.为数据库建立索引首先建立一个类TestLucene.java。

基于Lucene全文检索系统的研究与实现[摘要] lucene是一个开放源代码的全文检索引擎工具包,利用它可以快速地开发一个全文检索系统。
利用lucene开发了一个全文检索系统,通过其特殊的索引结构,实现了传统数据库不擅长的全文索引机制,提供了对非结构化信息的检索能力。
[关键词] lucene 信息检索全文检索索引一、引言计算机技术及网络技术的迅速发展,使得internet成为人类有史以来资源最多、品种最全、规模最大的信息资源库。
如何在这海量的信息里面快速、全面、准确地查找所需要的资料信息已经成了人们关注的焦点,也成了研究领域内的一个热门课题。
这些信息基本上可以分做两类:结构化数据和非结构化数据(如文本文档、word 文档、pdf文档、html文档等)。
现有的数据库检索,是以结构化数据为检索的主要目标,实现相对简单。
但对于非结构化数据,即全文数据,由于复杂的数据事务操作以及低效的高层接口,导致检索效率低下。
随着人们对信息检索的要求也越来越高,而全文检索因为检索速度快、准确性高而日益受到广大用户的欢迎, lucene是一个用java写的全文检索引擎工具包,可以方便地嵌入到各种应用中实现针对应用的全文索引和检索功能。
这个开源项目的推出及发展,为任何应用提供了对非结构化信息的检索能力。
二、全文检索策略通常比较厚的书籍后面常常附关键词索引表(比如,北京:12,34页,上海:3,77页……),它能够帮助读者比较快地找到相关内容的页码。
而数据库索引能够大大提高查询的速度原理也是一样,由于数据库索引不是为全文索引设计的,因此,使用like “%keyword%”时,数据库索引是不起作用的,在使用like查询时,搜索过程又变成类似于一页页翻书的遍历过程了,所以对于含有模糊查询的数据库服务来说,like对性能的危害是极大的。
如果是需要对多个关键词进行模糊匹配:like“%keyword1%”and like “%keyword2%”……其效率也就可想而知了。

Lunene在Android sqlite数据库搜索中的应用Lucene是一套用于全文检索和搜寻的开源程式库,供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。
在Java开发环境里Lucene是一个成熟的免费开源工具,Lucene 使用Java语言写成的,因而就可以应用到Android开发上。
此处采用的Lucene版本为3.0.3。
一.在项目下导入需要的包(一开始我分别采用4.2和4.0版本,发现调试时连接不上模拟器或手机,对比一下4.2,4.0的包对于3.0大了一倍多,有一个达到了2M多,3.0的包没有一个超过1M。
难道是libs 下的包大小有限制吗?或者其他原因,当时搞了很久都没想清楚。
总之换成3.0.3的就好了,其他的版本没有试过).二.为sqlite数据库创建索引public class Search {private MySQLiteHelper databaseHelper;private SQLiteDatabase db;private Directory dir;private String path;public Search(Context context) {this.context = context;try {path=android.os.Environment.getExternalStorageDirectory() + "/"+ context.getPackageName() + "/files/";//在SD卡上创建文件,如果没有SD卡则不会成功。
dir = new SimpleFSDirectory(new File(path));//获取路径下的目录new Thread(new Runnable() {public void run() {index();}}).start();} catch (IOException e) {e.printStackTrace();}}private void index() {/*** 在sd卡上创建与数据库相关的索引* */try {databaseHelper = new MySQLiteHelper(this.context);db = databaseHelper.getWritableDatabase();Cursor cursor = db.rawQuery("select * from "+ MySQLiteHelper.SEARCH_TABLE+ " where 1=1", null);IndexWriter indexWriter = new IndexWriter(dir,new StandardAnalyzer(Version.LUCENE_30), true,IndexWriter.MaxFieldLength.UNLIMITED);while (cursor.moveToNext()) {//创建索引,保存到SD卡path路径下Document doc = new Document();doc.add(new Field("title", cursor.getString(cursor.getColumnIndex("title")), Field.Store.YES,Field.Index.ANALYZED));doc.add(new Field("content", cursor.getString(cursor.getColumnIndex("content")), Field.Store.YES,Field.Index.ANALYZED));indexWriter.addDocument(doc);}indexWriter.optimize();indexWriter.close();cursor.close();db.close();databaseHelper.close();} catch (CorruptIndexException e) {e.printStackTrace();} catch (LockObtainFailedException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}三.搜索文本内容/*** 在索引上搜索最佳文本.field表示要搜索的数据库字段,content表示搜索的内容* */private void doSearch(String field, String content) { IndexSearcher indexSearch;TopDocs hits = null;Document doc = null;ScoreDoc sdoc;try {indexSearch = new IndexSearcher(dir);// 创建QueryParser对象,第一个参数表示Lucene的版本,第二个表示搜索Field的字段,第三个表示搜索使用分词器QueryParser queryParser=new QueryParser(Version.LUCENE_30, field,new StandardAnalyzer(Version.LUCENE_30));Query query = queryParser.parse(content);// 搜索结果 TopDocs里面有scoreDocs[]数组,里面保存着索引值hits = indexSearch.search(query, 10);// hits.totalHits表示一共搜到多少个Log.i("search", Integer.toString(hits.totalHits));// 循环hits.scoreDocs数据,并使用indexSearch.doc方法把Document还原,再拿出对应的字段的值for (int i=0;i<hits.scoreDocs.length-1;i++) {sdoc = hits.scoreDocs[i];doc = indexSearch.doc(sdoc.doc);Log.i("title",doc.get("title").toString());Log.i("content",doc.get("content").toString());}indexSearch.close();} catch (CorruptIndexException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} catch (ParseException e) {e.printStackTrace();}}例如,我要搜索内容为“大家好!”的字段则调用doSearch("content","大家好"); 在Log中可以看到与内容为“大家好!”相关分词搜索的结果。


用JSP调用Lucene包来实现全文检索1 Tomcat+JSP+Lvcene1. 1 Tomcat的Web服务器Web服务器是在网络中为实现信息发布、资料查询、数据处理等诸多应用搭建基本平台的服务器。
Tomcat Server 是根据Servlet 和JSP 规范进行执行的,是一个十分有用的网络应用开发服务平台。
它的下载、安装、使用见网站:http :///1. 2 JSP(Java Server Pages)JSP(Java Server Pages) 是由Sun Microsystems 公司倡导、许多公司参与一起建立的一种动态网页技术标准。
JSP技术是用JAVA语言作为脚本语言的,JSP网页为整个服务器端的JAVA库单元提供了一个接口来服务于HTTP的应用程序。
中加入Java 程序在传统的网页HTML文件(*.htm,*.html)片段(Scriptiet) 和JSP标记(tag),就构成了JSP 网页(*.jsp)。
Web服务器在遇到访问JSP网页的请求时,首先执行其中的程序片段,然后将执行结果以HTM1格式返回给客户。
1. 3 LuceneLucene是Apache的开源项目,是用Java写的全文索引弓擎工具包。
它提供了许多简单实用的API,用这些API,就可以方便的嵌入到各种应用中,对任何基于文本的数据进行全文检Lucene 是用 Java 写的, 它的运行、 调试都需要有 JavaSDK 。
Lucene 的下载、安装、使用见网站: http :///2 全文检索的实现2.1 全文检索系统的结构全文检索系统是按照全文检索理论建立起来的用于提供全 文检索服务的软件系统。
一般来说, 全文检索需要具备建立索引 和提供查询的基本功能, 此外现代的全文检索系统还需要具有方 便的用户接口、面向 wwW 勺开发接口、二次应用开发接口等等。
结构上,全文检索系统核心具有索引引擎、查询引擎、文本分析 引擎、对外接口等等, 加上各种外围应用系统等共同构成了全文 检索系统。
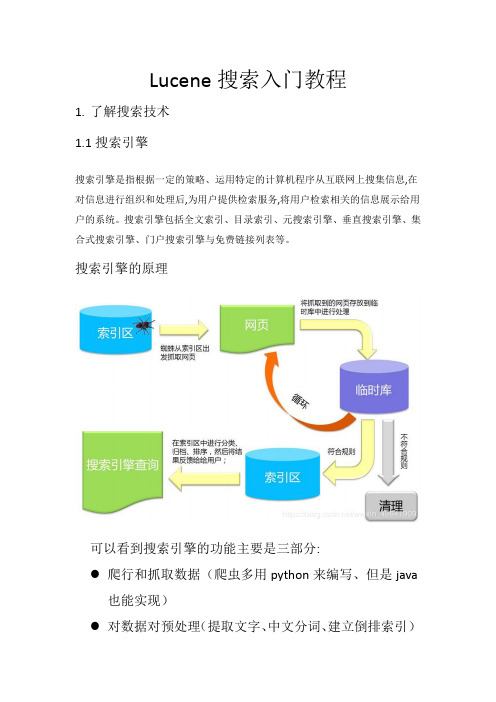
Lucene搜索入门教程1.了解搜索技术1.1搜索引擎搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。
搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
搜索引擎的原理可以看到搜索引擎的功能主要是三部分:●爬行和抓取数据(爬虫多用python来编写、但是java也能实现)●对数据对预处理(提取文字、中文分词、建立倒排索引)提供搜索功能(用户输入关键词后、去索引库搜索数据)在上述三个步骤中,java要解决的往往是后两个步骤:数据处理和搜索。
那么,我们之前学习的mysql知识也能实现数据的存储和搜索,为什么还要学新的东西呢?1.2传统数据库搜索的问题要实现类似百度的复杂搜索,或者京东的商品搜索,如果使用传统的数据库存储数据,那么会存在一系列的问题:●数据库数据单表存储能力有限,无法存储海量数据●解决大数据,可以进行分库分表。
但是分库分表会增加业务复杂度●搜索只能通过模糊匹配,效率极低●模糊搜索可能导致全表扫描,效率非常差在这里,比较棘手的其实是第二个问题:查询效率低,类似百度和京东这样的网站,对性能要求极高。
如果用户点击搜索需要很久才能拿到数据,没人愿意一直等待下去。
那么问题来了:如何才能提高模糊搜索时的效率呢?答案是:倒排索引技术1.3什么是倒排索引倒排索引是一种存储数据的方式,与传统查找有很大区别:●传统查找:采用数据按行存储,查找时逐行扫描,或者根据索引查找,然后匹配搜索条件,效率较差.概括来讲是先找到文档,然后看是否匹配.传统线性查找一个10MB的word文件,查找关键字如果在文档最后,大约3秒钟●倒排索引:首先对文档数据按照id进行索引存储,然后对文档中的数据分词,记录对词条进行索引,并记录词条在文档中出现的位置。
这样查找时只要找到了词条,就找到了对应的文档。
如何用Lucene索引数据库Lucene一个常见的用例是在一个或者多个数据库表进行全文检索。
虽然MySql有全文检索的功能,但是如果字段和数据量增加,MySql的性能会减低很快。
映射数据到Lucene通常情况下最需要解决的问题是怎么把你数据库的数据描述到Lucene里面,最可能的解决方法法就是把你的数据表放到平面的Lucence Document对象里面。
用伪代码表示:String sql = “select id, firstname, lastname, phone, email from person”;ResultSet rs = stmt.executeQuery(sql);while (rs.next()) {Document doc = new Document();doc.add(new Field(”id”, rs,getString(”firstname”), Field.Store.YES, Field.Index.UN_TOKENIZED));doc.add(new Field(”firstname”, rs,getString(”firstname”), Field.Store.YES, Field.Index.TOKENIZED));// …repeat for each column in result setwriter.addDocument(doc);}显示搜索结果当显示搜索结果给用户时,你有两个选择:1.因为你的Table已经扁平化到了Lucene里面,所以只需要用Document里面的Field.因为Lucene也非常快,这样会大大减低你的数据库的压力。
2.如果你要显示另外的数据到你的搜索结果页,你只需要在Hits里面收集他们的ID,然后从数据库去数据再根据结果组装搜索结果页。
要搜索的东西以上列出的方式都是假设把整个结果集放到内存里面,这样在数据集大的话会很容易造成问题,你需要在你的SQL里面做一些分页或者offset你还需要在你的结果集里面做一个try/catch,这样当添加一个Document出错的时候不会影响整个过程。
Lucene学习总结之一:全文检索的基本原理一、总论根据/java/docs/index.html定义:Lucene是一个高效的,基于Java的全文检索库。
所以在了解Lucene之前要费一番工夫了解一下全文检索。
那么什么叫做全文检索呢?这要从我们生活中的数据说起。
我们生活中的数据总体分为两种:结构化数据和非结构化数据。
●结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
●非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等。
当然有的地方还会提到第三种,半结构化数据,如XML,HTML等,当根据需要可按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理。
非结构化数据又一种叫法叫全文数据。
按照数据的分类,搜索也分为两种:●对结构化数据的搜索:如对数据库的搜索,用SQL语句。
再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。
●对非结构化数据的搜索:如利用windows的搜索也可以搜索文件内容,Linux下的grep命令,再如用Google和百度可以搜索大量内容数据。
对非结构化数据也即对全文数据的搜索主要有两种方法:一种是顺序扫描法(Serial Scanning):所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。
如利用windows的搜索也可以搜索文件内容,只是相当的慢。
如果你有一个80G硬盘,如果想在上面找到一个内容包含某字符串的文件,不花他几个小时,怕是做不到。
Linux下的grep命令也是这一种方式。
大家可能觉得这种方法比较原始,但对于小数据量的文件,这种方法还是最直接,最方便的。
但是对于大量的文件,这种方法就很慢了。
有人可能会说,对非结构化数据顺序扫描很慢,对结构化数据的搜索却相对较快(由于结构化数据有一定的结构可以采取一定的搜索算法加快速度),那么把我们的非结构化数据想办法弄得有一定结构不就行了吗?这种想法很天然,却构成了全文检索的基本思路,也即将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
使用Apache Lucene进行全文检索和信息检索随着数据量的日益增长,信息的获取和管理也变得越来越困难。
在这样的背景下,全文检索技术备受关注。
全文检索是指通过对文本内容进行扫描和分析,快速地查找出包含指定关键字或短语的文本,以满足用户的需求。
Apache Lucene是一款强大的全文检索引擎,具有高效、可靠、易于扩展等特点,广泛被运用于信息检索、文本分类、数据挖掘等领域。
一、Lucene的基本原理Lucene是一款基于Java语言的全文检索引擎,能够快速地在海量数据中查找指定的文本。
Lucene的检索原理可以简单地描述为:将需要检索的文本输入Lucene,Lucene建立索引文件,用户查询文本时,Lucene在索引文件中查找匹配结果,返回用户所需的信息。
Lucene的基本原理如下:1. 建立索引建立索引是Lucene进行全文检索的第一步。
在索引过程中,Lucene会对文本进行解析、分词、词语过滤等处理,然后将这些处理后的词语和其所在的文档信息存储到索引文件中。
通过如此的操作,Lucene做到了在指定时间内,快速地查找指定文本。
2. 查询当用户输入需要检索的文本时,Lucene会对该文本进行同样的预处理,得到其中的每个单独词语,并在索引文件中查找与该词语相匹配的文档。
Lucene采用了先搜索后排名的检索策略,即先找到与关键词匹配的文档,然后再通过算法对得到的结果进行排序,得出匹配度最高的文档。
3. 返回结果Lucene的返回结果是一个文档对象,其中包含了原始文本、关键词匹配的位置和得分等信息。
在大多数情况下,返回的文档对象并不是用户真正想要的结果,需要进行二次过滤和排序,才能得出目标结果。
二、Lucene的基本使用Lucene的使用可以简单地分为以下几个步骤:1. 创建索引创建索引是Lucene进行全文检索的第一步,也是最重要的一步。
在创建索引前,需要准备好需要检索的文本文件。
Lucene支持的文本格式包括txt、doc、pdf等。
全文检索lucene研究本文由美白面膜排行榜/doc/4616316215.html,整理全文检索lucene研究1 Lucene简介Lucene是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎。
Lucene以其方便使用、快速实施以及灵活性受到广泛的关注。
它可以方便地嵌入到各种应用中实现针对应用的全文索引、检索功能,本总结使用lucene3.0.02 Lucene 的包结构1、analysis对需要建立索引的文本进行分词、过滤等操作2、standard是标准分析器3、document提供对Document和Field的各种操作的支持。
4、index是最重要的包,用于向Lucene提供建立索引时各种操作的支持5、queryParser提供检索时的分析支持6、search负责检索7、store提供对索引存储的支持8、util提供一些常用工具类和常量类的支持Lucene中的类主要组成如下:1)org.apache.1ucene.analysis语言分析器,主要用于的切词Analyzer是一个抽象类,管理对文本内容的切分词规则。
2)org.apache.1uceene.document索引存储时的文档结构管理,类似于关系型数据库的表结构。
3)document包相对而言比较简单,document相对于关系型数据库的记录对象,Field主要负责字段的管理。
4)org.apache.1ucene.index索引管理,包括索引建立、删除等。
索引包是整个系统核心,全文检索的根本就是为每个切出来的词建索引,查询时就只需要遍历索引,而不需要去正文中遍历,从而极大的提高检索效率。
5)org.apache.1ucene.queryParser查询分析器,实现查询关键词间的运算,如与、或、非等。
6)org.apache.1ucene.search检索管理,根据查询条件,检索得到结果。
7)org.apache.1ucene.store数据存储管理,主要包括一些底层的I/0操作。
用Lucene检索数据库1.写一段传统的JDBC程序,讲每条的用户信息从数据库读取出来2.针对每条用户记录,建立一个lucene documentDocument doc = new Document();并根据你的需要,将用户信息的各个字段对应luncene document中的field 进行添加,如:doc.add(newField("NAME","USERNAME",Field.Store.YES,Field.Index.UN_TOKENIZED));然后将该条doc加入到索引中,如:luceneWriter.addDocument(doc);这样就建立了lucene的索引库3.编写对索引库的搜索程序(看lucene文档),通过对lucene的索引库的查找,你可以快速找到对应记录的ID4.通过ID到数据库中查找相关记录用Lucene索引数据库Lucene,作为一种全文搜索的辅助工具,为我们进行条件搜索,无论是像Google,Baidu 之类的搜索引擎,还是论坛中的搜索功能,还是其它C/S架构的搜索,都带来了极大的便利和比较高的效率。
本文主要是利用Lucene对MS Sql Server 2000进行建立索引,然后进行全文索引。
至于数据库的内容,可以是网页的内容,还是其它的。
本文中数据库的内容是图书馆管理系统中的某个作者表-Authors表。
因为考虑到篇幅的问题,所以该文不会讲的很详细,也不可能讲的很深。
本文以这样的结构进行:1.介绍数据库中Authors表的结构2.为数据库建立索引3.为数据库建立查询功能4.在web界面下进行查询并显示结果1.介绍数据库中Authors表的结构字段名称字段类型字段含义Au_id Varchar(11) 作者号Au_name Varchar(60) 作者名Phone Char(12) 电话号码Address Varchar(40) 地址City Varchar(20) 城市State Char(2) 省份Zip Char(5) 邮编contract Bit(1) 外键(关系不大)表中的部分内容:2.为数据库建立索引首先建立一个类TestLucene.java。
这个类就是对数据库进行建立索引,编写查询条件等。
当然,最开始就是建立数据库连接。
连接代码这里就省略了。
^_^接着,新建一个方法getResutl(String),它返回的是数据库表Authors的内容。
具体代码如下:public ResultSet getResult(String sql){try{Statement stmt = conn.createStatement();ResultSet rs = stmt.executeQuery(sql);return rs;}catch(SQLException e){System.out.println(e);}return null;}然后,为数据库建立索引。
首先要定义一个IndexWriter(),它是将索引写进Lucene自己的数据库中,它存放的位置是有你自己定义的。
在定义IndexWriter 是需要指定它的分析器。
Lucene自己自带有几个分析器,例如:StandarAnalyzer(),SimpleAnalyzer(), StopAnalyzer()等。
它作用是对文本进行分析,判断如何进行切词。
接着,要定义一个Document。
Document相当于二维表中一行数据一样。
Document 里包含的是Field字段,Field相当于数据库中一列,也就是一个属性,一个字段。
最后应该对IndexWriter进行优化,方法很简单,就是writer.optimize().具体代码如下:public void Index(ResultSet rs){try{IndexWriter writer = new IndexWriter("d:/index/", getAnalyzer(), true);while(rs.next()){Document doc=new Document();doc.add(Field.Keyword("id",rs.getString("au_id")));doc.add(Field.Text("name",rs.getString("au_name")));doc.add(Field.UnIndexed("address",rs.getString("address")));doc.add(Field.UnIndexed("phone",rs.getString("phone")));doc.add(Field.Text("City",rs.getString("city")));writer.addDocument(doc);}writer.optimize();writer.close();}catch(IOException e){System.out.println(e);}catch(SQLException e){System.out.println(e);}}public Analyzer getAnalyzer(){return new StandardAnalyzer();}3.为数据库建立查询功能在类TestLucene中建立一个新的方法searcher(String),它返回的是一个搜索的结构集,相当于数据库中的ResultSet一样。
它代的参数是你要查询的内容。
这里,我把要查询的字段写死了。
你可以在添加一个参数表示要查询的字段。
这里主要有两个对象IndexSearcher和Query。
IndexSearcher是找到索引数据库,Query是处理搜索,它包含了三个参数:查询内容,查询字段,分析器。
具体代码如下:public Hits seacher(String queryString){Hits hits=null;;try{IndexSearcher is = new IndexSearcher("D:/index/");Query query=QueryParser.parse(queryString,"City",getAnalyzer());hits=is.search(query);}catch(Exception e){System.out.print(e);}return hits;}4.在web界面下进行查询并显示结果这里建立一个Jsp页面TestLucene.jsp进行搜索。
在TestLucene.jsp页面中首先引入类<%@ page import="lucenetest.LucentTest"%><%@ page import="org.apache.lucene.search.*,org.apache.lucene.document.*" %> 然后定义一个LuceneTest对象,获取查询结果集:LucentTest lucent=new LucentTest();Hits hits=lucent.seacher(request.getParameter("queryString"));定义一个Form,建立一个查询环境:<form action="TestLucene.jsp"><input type="text" name="queryString"/><input type="submit" value="搜索"/></form>显示查询结果:<table><%if(hits!=null){%><tr><td>作者号</td><td>作者名</td><td>地址</td><td>电话号码</td></tr><% for(int i=0;i<hits.length();i++){Document doc=hits.doc(i);%><tr><td><%=doc.get("id") %></td><td><%=doc.get("name") %></td><td><%=doc.get("address") %></td><td><%=doc.get("phone") %></td></tr><% }}%></table>用Lucene-1.3-final为网站数据库建立索引下是看了lnboy写的《用lucene建立大富翁论坛的全文检索》后写的测试代码。
为数据库cwb.mdb建立全文索引的indexdb.jsp<%@ page import ="org.apache.lucene.analysis.standard.*" %><%@ page import="org.apache.lucene.index.*" %><%@ page import="org.apache.lucene.document.*" %><%@ page import="lucene.*" %><%@ page contentType="text/html; charset=GBK" %><%long start = System.currentTimeMillis();String aa=getServletContext().getRealPath("/")+"index";IndexWriter writer = new IndexWriter(aa, new StandardAnalyzer(), true);try {Class.forName("sun.jdbc.odbc.JdbcOdbcDriver").newInstance();String url = "jdbc:odbc:driver={Microsoft Access Driver (*.mdb)};DBQ=d:\\Tomcat 5.0\\webapps\\zz3zcwbwebhome\\WEB-INF\\cwb.mdb"; Connection conn = DriverManager.getConnection(url);Statement stmt = conn.createStatement();ResultSet rs = stmt.executeQuery("select Article_id,Article_name,Article_intro from Article");while (rs.next()) {writer.addDocument(mydocument.Document(rs.getString("Article_id"), rs.getString("Article_name"),rs.getString("Article_intro")));}rs.close();stmt.close();conn.close();out.println("索引创建完毕");writer.optimize();writer.close();out.print(System.currentTimeMillis() - start);out.println(" total milliseconds");}catch (Exception e) {out.println(" 出错了 " + e.getClass() +"\n 错误信息为: " + e.getMessage());}%>用于显示查询结果的aftsearch.jsp<%@ page import="org.apache.lucene.search.*" %><%@ page import="org.apache.lucene.document.*" %><%@ page import="lucene.*" %><%@ page import = "org.apache.lucene.analysis.standard.*" %><%@ page import="org.apache.lucene.queryParser.QueryParser" %><%@ page contentType="text/html; charset=GBK" %><%String keyword=request.getParameter("keyword");keyword=new String(keyword.getBytes("ISO8859_1"));out.println(keyword);try {String aa=getServletContext().getRealPath("/")+"index";Searcher searcher = new IndexSearcher(aa);Query query = QueryParser.parse(keyword, "Article_name", new StandardAnalyz er());out.println("正在查找: " + query.toString("Article_name")+"<br>");Hits hits = searcher.search(query);System.out.println(hits.length() + " total matching documents");java.text.NumberFormat format = java.text.NumberFormat.getNumberInstance(); for (int i = 0; i < hits.length(); i++) {//开始输出查询结果Document doc = hits.doc(i);out.println(doc.get("Article_id"));out.println("准确度为:" + format.format(hits.score(i) * 100.0) + "%");out.println(doc.get("Article_name")+"<br>");// out.println(doc.get("Article_intro"));}}catch (Exception e) {out.println(" 出错了 " + e.getClass() +"\n 错误信息为: " + e.getMessage());}%>辅助类:package lucene;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.document.DateField;public class mydocument {public static Document Document(String Article_id,String Article_name,String Article_ intro){Document doc = new Document();doc.add(Field.Keyword("Article_id", Article_id));doc.add(Field.Text("Article_name", Article_name));doc.add(Field.Text("Article_intro", Article_intro));return doc;}public mydocument() {}}用lucene为数据库搜索建立增量索引用 lucene 建立索引不可能每次都重新开始建立,而是按照新增加的记录,一次次的递增建立索引的IndexWriter类,有三个参数IndexWriter writer = new IndexWriter(path, new StandardAnalyzer(),isEmpty);其中第三个参数是bool型的,指定它可以确定是增量索引,还是重建索引.对于从数据库中读取的记录,譬如要为文章建立索引,我们可以记录文章的id号,然后下次再次建立索引的时候读取存下的id号,从此id后往下继续增加索引,逻辑如下.建立增量索引,主要代码如下public void createIndex(String path){Statement myStatement = null;String articleId="0";//读取文件,获得文章id号码,这里只存最后一篇索引的文章idtry {FileReader fr = new FileReader("**.txt");BufferedReader br = new BufferedReader(fr); articleId=br.readLine();if(articleId==null||articleId=="")articleId="0";br.close();fr.close();} catch (IOException e) {System.out.println("error343!");e.printStackTrace();}try {//sql语句,根据id读取下面的内容String sqlText = "*****"+articleId;myStatement = conn.createStatement();ResultSet rs = myStatement.executeQuery(sqlText);//写索引while (rs.next()) {Document doc = new Document();doc.add(Field.Keyword("**", DateAdded));doc.add(Field.Keyword("**", articleid));doc.add(Field.Text("**", URL));doc.add(Field.Text("**", Content));doc.add(Field.Text("**", Title));try{writer.addDocument(doc);}catch(IOException e){e.printStackTrace();}//将我索引的最后一篇文章的id写入文件try {FileWriter fw = new FileWriter("**.txt");PrintWriter out = new PrintWriter(fw);out.close();fw.close();} catch (IOException e) {e.printStackTrace();}}ind.Close();System.out.println("ok.end");}catch (SQLException e){e.printStackTrace();}finally {//数据库关闭操作}}然后控制是都建立增量索引的时候根据能否都到id值来设置IndexWriter的第三个参数为true 或者是falseboolean isEmpty = true;try {FileReader fr = new FileReader("**.txt");BufferedReader br = new BufferedReader(fr);if(br.readLine()!= null) {isEmpty = false;}br.close();fr.close();} catch (IOException e) {e.printStackTrace();}writer = new IndexWriter(Directory, new StandardAnalyzer(),isEmpty);。