医学统计学第18章 Logistic回归思考与练习参考答案
- 格式:doc
- 大小:91.00 KB
- 文档页数:3
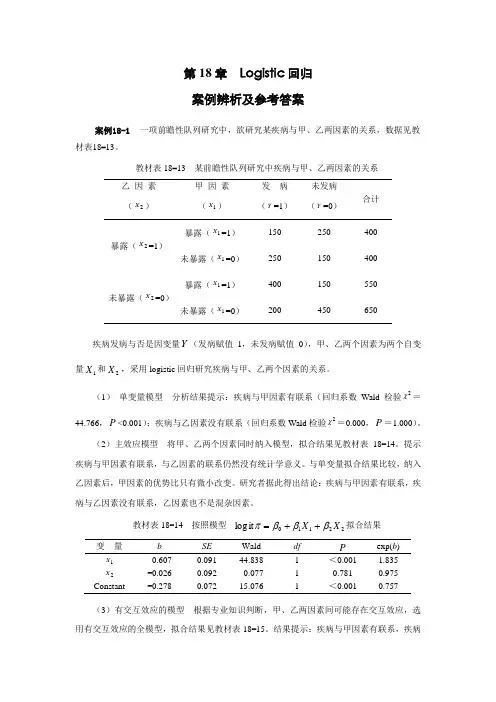
第18章 Logistic 回归 案例辨析及参考答案案例18-1 一项前瞻性队列研究中,欲研究某疾病与甲、乙两因素的关系,数据见教材表18-13。
教材表18-13 某前瞻性队列研究中疾病与甲、乙两因素的关系 乙 因 素 甲 因 素 发 病 未发病 合计(2X )(1X ) (Y =1) (Y =0) 暴露(2X =1)暴露(1X =1)150250400未暴露(1X =0) 250 150 400 未暴露(2X =0)暴露(1X =1)400150550未暴露(1X =0)200450650疾病发病与否是因变量Y (发病赋值1,未发病赋值0),甲、乙两个因素为两个自变量1X 和2X ,采用logistic 回归研究疾病与甲、乙两个因素的关系。
(1) 单变量模型 分析结果提示:疾病与甲因素有联系(回归系数Wald 检验2χ=44.766,P <0.001);疾病与乙因素没有联系(回归系数Wald 检验2χ=0.000,P =1.000)。
(2)主效应模型 将甲、乙两个因素同时纳入模型,拟合结果见教材表18-14。
提示疾病与甲因素有联系,与乙因素的联系仍然没有统计学意义。
与单变量拟合结果比较,纳入乙因素后,甲因素的优势比只有微小改变。
研究者据此得出结论:疾病与甲因素有联系,疾病与乙因素没有联系,乙因素也不是混杂因素。
教材表18-14 按照模型22110it log X X βββπ++=拟合结果变 量 b SE Wald df Pexp(b ) 1X 0.607 0.091 44.838 1 <0.001 1.835 2X -0.026 0.092 0.077 1 0.781 0.975 Constant-0.2780.07215.0761<0.0010.757(3)有交互效应的模型 根据专业知识判断,甲、乙两因素间可能存在交互效应,选用有交互效应的全模型,拟合结果见教材表18-15。
结果提示:疾病与甲因素有联系,疾病与乙因素也有联系,甲、乙两因素间还有交互效应。


第1章绪论思考与练习参考答案一、最佳选择题1. 研究中的基本单位是指( D)。
A.样本 B. 全部对象C.影响因素D. 个体E. 总体2. 从总体中抽取样本的目的是( B )。
A.研究样本统计量 B. 由样本统计量推断总体参数C.研究典型案例 D. 研究总体统计量E. 计算统计指标3. 参数是指( B )。
A.参与个体数 B. 描述总体特征的统计指标C.描述样本特征的统计指标 D. 样本的总和 E. 参与变量数4. 下列资料属名义变量的是(E)。
A.白细胞计数B.住院天数C.门急诊就诊人数D.患者的病情分级 E. ABO血型5.关于随机误差下列不正确的是(C)。
A.受测量精密度限制B.无方向性 C. 也称为偏倚D.不可避免 E. 增加样本含量可降低其大小二、名称解释(答案略)1. 变量与随机变量2. 同质与变异3. 总体与样本4. 参数与统计量5. 误差6. 随机事件7. 频率与概率三、思考题1. 生物统计学与其他统计学有什么区别和联系?答:统计学可细分为数理统计学、经济统计学、生物统计学、卫生统计学、医学统计学等,都是关于数据的学问,是从数据中提取信息、知识的一门科学与艺术。
而生物统计学是统计学原理与方法应用于生物学、医学的一门科学,与医学统计学和卫生统计学很相似,其不同之处在于医学统计学侧重于介绍医学研究中的统计学原理与方法,而卫生统计学更侧重于介绍社会、人群健康研究中的统计学原理与方法。
2. 某年级甲班、乙班各有男生50人。
从两个班各抽取10人测量身高,并求其平均身高。
如果甲班的平均身高大于乙班,能否推论甲班所有同学的平均身高大于乙班?为什么?答:不能。
因为,从甲、乙两班分别抽取的10人,测量其身高,得到的分别是甲、乙两班的一个样本。
样本的平均身高只是甲、乙两班所有同学平均身高的一个点估计值。
即使是按随机化原则进行抽样,由于存在抽样误差,样本均数与总体均数一般很难恰好相等。
因此,不能仅凭两个样本均数高低就作出两总体均数熟高熟低的判断,而应通过统计分析,进行统计推断,才能作出判断。

第18章 Logistic 回归 思考与练习参考答案一、最佳选择题1. Logistic 回归与多重线性回归比较,( A )。
A .logistic 回归的因变量为二分类变量 B .多重线性回归的因变量为二分类变量C .logistic 回归和多重线性回归的因变量都可为二分类变量D .logistic 回归的自变量必须是二分类变量E .多重线性回归的自变量必须是二分类变量 2. Logistic 回归适用于因变量为( E )。
A .二分类变量B .多分类有序变量C .多分类无序变量D .连续型定量变量E .A 、B 、C 均可 3. Logistic 回归系数与优势比OR 的关系为( E )。
A .>β0等价于OR >1B .>β0等价于OR <1C .β=0等价于OR =1D .β<0等价于OR <1E .A 、C 、D 均正确 4. Logistic 回归可用于( E )。
A.影响因素分析 B .校正混杂因素 C .预测 D .仅有A 和C E .A 、B 、C 均可5. Logistic 回归中自变量如为多分类变量,宜将其按哑变量处理,与其他变量进行变量筛选时可用( D )。
A .软件自动筛选的前进法B .软件自动筛选的后退法C .软件自动筛选的逐步法D .应将几个哑变量作为一个因素,整体进出回归方程E .A 、B 、C 均可二、思考题1. 为研究低龄青少年吸烟的外在因素,研究者采用整群抽样,在某中心城区和远城区的初中学校,各选择初一年级一个班的全部学生进行调查,并用logistic 回归方程筛选影响因素。
试问上述问题采用logistic 回归是否妥当?答:上述问题采用logistic回归不妥当,因为logistic回归中参数的极大似然估计要求样本结局事件相互独立,而研究的问题中低龄青少年吸烟行为不独立。
2. 分类变量赋值不同对logistic回归有何影响? 分析结果一致吗?答:(1)若因变量交换赋值,两个logistic回归方程的参数估计绝对值相等,符号相反;优势比互为倒数,含义有所区别,实质意义一样;模型拟合检验与回归系数的假设检验结果相同。

医学统计学知到章节测试答案智慧树2023年最新湖南中医药大学第一章测试1.参数是指总体的统计指标。
()参考答案:对2.概率的取值范围为[-1,1]。
()参考答案:错3.统计学中资料类型包括()参考答案:等级资料;计数资料;计量资料4.医学统计学的研究内容包括研究设计和研究分析两个方面。
()参考答案:对5.样本应该对总体具有代表性。
()参考答案:对第二章测试1.抽样单位的数目越大,抽样误差越大。
()参考答案:错2.以下不属于概率抽样的是()参考答案:雪球抽样3.整群抽样的优点()参考答案:易于理解,简单易行4.概率抽样主要包括简单随机抽样、分层抽样、系统抽样、整群抽样和便利抽样。
()参考答案:错5.进行分层抽样时要求()参考答案:各群内差异越小越好第三章测试1.在正态性检验中,P>0.05时可认为资料服从正态分布。
()参考答案:对2.在两样本均数比较的t检验中,无效假设是()参考答案:两总体均数相等3.在两样本率比较的卡方检验中,无效假设是()参考答案:两总体率相等4.配对设计资料,若满足正态性和方差齐性。
要对两样本均数的差别作比较,可选择()参考答案:配对t检验5.用最小二乘法确定直线回归方程的原则是各观测点距直线纵向距离平方和最小。
()参考答案:对第四章测试1.定量数据即计量资料()参考答案:对2.定量数据的统计描述包括集中趋势、离散趋势和频数分布特征。
()参考答案:对3.定量数据的总体均数的估计只有点估计这一种方法。
()参考答案:错4.定性数据是指计数资料。
()参考答案:错5.动态数列是以系统按照时间顺序排列起来的统计指标。
()参考答案:对第五章测试1.单个样本t检验要求样本所代表的总体服从正态分布、()参考答案:对2.配对t检验要求差值d服从正态分布。
()参考答案:对3.Wilcoxon符号秩和检验属于非参数检验。
()参考答案:对4.配对设计可以用于控制研究误差。
()参考答案:对5.配对t检验中,P<0.05时说明两处理组差异无统计学意义。



第一章:单选题(5/5 分数)1.统计学中所说的样本是指()。
.随意抽取的总体中任意部分.有意识的选择总体中的典型部分.依照研究者要求选取总体中有意义的一部分.依照随机原则抽取总体中有代表性的一部分.依照随机原则抽取总体中有代表性的一部分- 正确. 有目的的选择总体中的典型部分2.下列资料属等级资料的是()。
.白细胞计数.住院天数.门急诊就诊人数.病人的病情分级.病人的病情分级- 正确. ABO血型分类3.为了估计某年华北地区家庭年医疗费用的平均支出,从华北地区的5个城市随机抽样调查了1500户家庭,他们的平均年医疗费用支出是997元,标准差是391 元。
该研究中研究者感兴趣的总体是().华北地区1500户家庭.华北地区的5个城市.华北地区1500户家庭的年医疗费用.华北地区所有家庭的年医疗费用.华北地区所有家庭的年医疗费用- 正确. 全国所有家庭的年医疗费用4.欲了解研究人群中原发性高血压病(EH)的患病情况,某研究者调查了1043人,获得了文化程度(高中及以下、大学及以上)、高血压家族史(有、无)、月人均收入(元)、吸烟(不吸、偶尔吸、经常吸、每天)、饮酒(不饮、偶尔饮、经常饮、每天)、打鼾(不打鼾、打鼾)、脉压差(mmHg)、心率(次/分)等指标信息。
则构成计数资料的指标有().文化程度、高血压家族史吸烟、饮酒、打鼾.月人均收入、脉压差、心率.文化程度、高血压家族史、打鼾.文化程度、高血压家族史、打鼾- 正确.吸烟、饮酒. 高血压家族史吸烟、饮酒、打鼾5.总体是指().全部研究对象.全部研究对象中抽取的一部分.全部样本.全部研究指标. 全部同质研究对象的某个变量的值-正确第二章-单选题(10/10 分数)1.描述一组偏态分布资料的变异度,以()指标较好。
. 全距. 标准差. 变异系数. 四分位数间距. 四分位数间距- 正确.方差2.用均数和标准差可以全面描述()资料的特征。
. 正偏态分布. 负偏态分布. 正态分布. 正态分布- 正确. 对称分布.对数正态分布3.各观察值均加(或减)同一数后()。

医学统计学案例辨析及参考答案非凡文印提供松园7号楼目录目录 (2)第1章绪论 (3)第2章统计描述 (5)第3章概率分布 (9)第4章参数估计 (12)第5章假设检验 (14)第6章两样本定量资料的比较 (16)第7章多组定量资料的比较 (19)第8章定性资料的比较 (22)第9章关联性分析 (25)第10章简单线性回归分析 (27)第11章多重线性回归分析 (31)第12章实验设计 (34)第13章临床试验设计 (36)第14章调查设计 (37)第15章样本含量估计 (39)第16章随机区组设计和析因设计资料的分析 (42)第17章重复测量设计和交叉设计资料的分析 (44)第18章 Logistic回归 (47)第19章生存分析 (51)第20章对数线性模型在高维列联表资料分析中的应用 (54)第21章多元统计方法简介 (57)第22章时间序列分析 (58)第24章基因表达谱分析的生物信息学方法 (60)第25章 Meta分析 (61)第26章医学论文的统计学报告要求 (65)第1章绪论案例辨析及参考答案案例1-1某研究者的论文题目为“大学生身心健康状况及其影响因素研究”,以某地职业技术学院理、工、文、医学生(三年制)为研究对象,理、工、文、医学生分别挑选了60、38、19和46人,以问卷方式调查每位学生的一般健康状况、焦虑程度、抑郁程度等。
得出的结论是:“大学生身心健康状况不容乐观,学业问题、就业压力、身体状况差、人际交往不良、社会支持不力为主要影响因素”。
请问其结论合理吗?为什么?应该如何?案例辨析①样本不能代表总体。
总体是“大学生”,而样本仅为某地三年制职业技术学院学生;②社会学调查的样本含量显得不足;③“理、工、文、医学生分别挑选……”这种说法中隐含人为“挑选”的意思,不符合统计学要求。
正确做法应在论文的题目中明确调查的时间范围和地点,还应给“大学生”下一个明确的定义,以便确定此次调查的“总体”;对“大学生身心健康状况”可能有影响的因素很多,应结合具体问题拟定出少数最可能有影响的因素(如学科、在学年限等)进行分层随机抽样,以保证样本有较好的代表性;还应根据已知条件找到估计样本含量的计算公式,不可随意确定各学科仅调查几十人;当然,调查表中项目的设置也是十分重要的,此处从略。

《医学统计学》习题解答(最佳选择题和简答题)孙振球主编.医学统计学习题解答. 第2版. 北京:人民卫生出版社2005目录第二章计量资料的统计描述 (2)第三章总体均数的估计与假设检验 (3)第四章多个样本均数比较的方差分析 (6)第五章计数资料的统计描述 (7)第六章二项分布与Poisson分布 (9)第七章χ2检验 (11)第八章秩和检验 (13)第九章回归与相关 (14)第十章统计表与统计图 (17)第十一章多因素试验资料的方差分析 (19)第十二章重复测量设计资料的方差分析 (19)第十五章多元线性回归分析 (20)第十六章logistic回归分析 (22)第十七章生存分析 (23)第二十五章医学科学研究设计概述 (26)第二十六章观察性研究设计 (26)第二十七章实验研究设计 (28)第二十七章临床试验研究设计 (29)第二章 计量资料的统计描述(注:题号上有“方框” 的简答题为基本概念,下同)第三章总体均数的估计与假设检验简答题:第四章多个样本均数比较的方差分析简答题:第五章计数资料的统计描述简答题:第六章二项分布与Poisson分布简答题:第七章χ2检验简答题:1. 说明χ2检验的用途2. 两个样本率比较的u检验与χ2检验有何异同?3. 对于四格表资料,如何正确选用检验方法?4. 说明行×列表资料χ2检验应注意的事项?5. 说明R×C表的分类及其检验方法的选择。
第八章秩和检验简答题:5. 两独立样本比较的Wilcoxon秩和检验,当n1>10或n2-n1>10时用u检验,这时检验是属于参数检验还是非参数检验,为什么?6. 随机区组设计多个样本比较的Friedman M 检验,备择假设H1如何写?为什么?第九章回归与相关简答题:第十章统计表与统计图简答题:5. 统计表与统计图有何联系和区别?6. 茎叶图与频数分布图相比有何区别,有何优点?第十一章多因素试验资料的方差分析一、简答题1. 简述析因试验与正交试验的联系与区别。

第一章测试1.四组均数比较的方差分析,其备择假设H1应为()。
A:至少有两个样本均数不等B:C:D:各总体均数不全相等E:任两个总体均数间有差别答案:D2.随机区组设计的方差分析中,ν配伍等于()。
A:ν总-ν处理-ν误差B:ν总-ν处理+ν误差C:ν总-ν误差D:ν总+ν处理+ν误差E:ν总-ν处理答案:A3.当自由度(ν1, ν2)及检验水准α都相同时,方差分析的界值比方差齐性检验的界值()。
A:小B:不一定C:大D:相等答案:A4.完全随机设计方差分析的检验假设是()。
A:各处理组样本均数相等B:各处理组样本均数不相等C:各处理组总体均数相等D:各处理组总体均数不相等答案:C5.关于方差分析,下列说法正确的是()。
A:只要是定量资料,均能选用方差分析B:方差分析只能用于多组定量资料均数的比较C:只要各组例数相等,定量资料均数的比较可采用随机区组设计方差分析D:方差分析的基本思想是将数据均方与自由度进行分解E:方差分析可适用于多组正态且等方差的定量资料均数比较答案:E6.当组数等于2时,对于同一资料,方差分析结果与t检验结果相比()。
A:方差分析结果更为准确B:t检验结果更为准确C:两者结果可能出现矛盾D:完全等价且答案:D7.完全随机设计、随机区组设计的SS和及自由度各分解为几部分()。
A:2,2B:2,3C:2,4D:3,3答案:B8.完全随机设计方差分析中,组间均方主要反映()。
A:处理因素的作用B:系统误差的影响C:抽样误差大小D:n个数据的离散程度E:随机误差的影响答案:A9.三组以上某实验室指标观测数据服从正态分布且满足参数检验的应用条件。
任两组分别进行多次t检验代替方差分析,将会()。
A:使均数相差更为显著B:明显增大犯I型错误的概率C:使结论更加具体D:明显增大犯II型错误的概率E:使均数的代表性更好答案:B10.在完全随机设计的方差分析中,必然有()。
A:MS组间> MS组内B:MS总 = MS组间 + MS组内C:SS总= SS组间 + SS组内D:MS组间< MS组内E:SS组内< SS组间答案:C第二章测试1.2×2析因试验设计表述正确的是()。
《医学统计学》资料整理:医学统计学课程思考题及答案医学统计学课程思考题及答案(注:红色字体表示已经改正,多余表示删除的内容)一.名词解释1.Population and Sample总体:根据研究目的确定的同质研究对象某观测值的集合。
样本:从总体中随机抽取的有代表性的部分研究对象其观测值的集合。
2.Cross-over design交叉设计:每个受试者随机地在两个或多个不同试验阶段分别接受指定的处理(试验药或对照药)。
3.Variance方差:离均差平方和的均数,反映一组同质计量资料的离散趋势大小。
4.Power of test检验效能:常用1-β表示,其意义是当两个总体存在差异时,使用统计检验发现总体间差异的能力,一般在0.8左右5.Relative ration相对数、相对比:二.选择题1、分析母亲体重与婴儿的出生体重的关系,宜绘制( C )A. 直方图B. 圆图C. 散点图D. 直条图2、统计推断包括( D )A、统计描述B、参数估计C、估计抽样误差D、参数估计和假设检验3、两样本率比较,经χ2检验,差别无显著性时,P值越大小,说明(B C )A.两样本率差别越大B.两总体率相同的可能性越大C.越有理由认为两总体率不同D.越有理由认为两样本率不同4、调查某地1000人,记录每人的血压值,所得的资料是一份( B A)。
A、计量资料B、计数资料C、还不能决定是计量资料还是计数资料D、可看作计量资料,也可看作计数资料5、某医师用A药治疗25例病人,治愈20人;用B药治疗30例病人,治愈10人;比较两药疗效时,可选用的最适当的方法是( A )。
A、χ2检验B、 u检验C、校正χ2检验D、确切概率法χ2检验:推断两个或两个以上总体率(或构成比)之间有无差别及两分类变量间有无相关关系等。
因为T=25*25/55>=5,n>=40,所以采用四格表专用公式。
u检验:两完全随机设计两总体均数比较,样本量很大,且总体的方差已知。
医学统计学练习及参考答案《医学统计学》练习题及参考答案一、填空题:1、频数分布通常具有集中趋势、离散趋势两个基本特征。
P412、统计表一般需有标题、线条(横线)、标目、数字四个基本结构。
3、四格表应用基本公式进行卡方检验的条件是:n≥40 、T≥5 。
4、正态分布的两个决定参数是:位置参数μ、形状参数。
P535、正态分布中央95%的观察值的分布区间是(μ-1.96σ,μ+1.96 σ)。
P536、概率抽样三个基本原则是:随机化原则、同质性原则、 n足够大。
7、实验设计的三大原则是对照、随机化、重复。
P20二、单项选择题:1.下面的变量中,属于分类变量的是---B--.A.脉搏 B.血型 C.肺活量 D.血压2. 已知我国部分县1988年死因构成比资料如下:心脏疾病11.41%,损伤与中毒11.56%,恶性肿瘤15.04%,脑血管病16.07%,呼吸系统病25.70%,其他20.22%.为表达上述死因的构成的大小,根据此资料应绘制统计图为--D---.A.线图 B.直方图 C.直条图 D.百分条图 E.统计地图 3. 在一项研究的最初检查中,人们发现30~40岁男女两组人群的冠心病患病率均为4%,于是,认为该年龄组男女两性发生冠心病的危险相同.这个结论是---C--. A.正确的B. 不正确的,因为没有可识别的队列人群 C.不正确的,因为没有区分发病率与患病率D.不正确的,因为用百分比代替率来支持该结论 E.不正确的,因为没有设立对照组 4. sx表示---C--.A.总体均数 B. 总体均数离散程度 C. 样本均数的标准差 D.变量值x的离散程度 E.变量值x的可靠程度5.做两个总体均数比较t检验,计算t>t0.01,(n1+n2-2时,可以认为-B----.A.反复随机抽样时,出现这种大小的均数差异的可能性大于0.01B.样本均数差异是由随机抽样误差所致的可能性小于0.01,可认为两总体有差别。
医学统计学课后习题答案第一章医学统计中的基本概念练习题一、单向选择题1. 医学统计学研究的对象是A. 医学中的小概率事件B. 各种类型的数据C. 动物和人的本质D. 疾病的预防与治疗E.有变异的医学事件2. 用样本推论总体,具有代表性的样本指的是A.总体中最容易获得的部分个体 B.在总体中随意抽取任意个体C.挑选总体中的有代表性的部分个体 D.用配对方法抽取的部分个体E.依照随机原则抽取总体中的部分个体3. 下列观测结果属于等级资料的是A.收缩压测量值 B.脉搏数C.住院天数 D.病情程度E.四种血型4. 随机误差指的是A. 测量不准引起的误差B. 由操作失误引起的误差C. 选择样本不当引起的误差D. 选择总体不当引起的误差E. 由偶然因素引起的误差5. 收集资料不可避免的误差是A. 随机误差B. 系统误差C. 过失误差D. 记录误差E.仪器故障误差答案: E E D E A二、简答题常见的三类误差是什么?应采取什么措施和方法加以控制?[参考答案]常见的三类误差是:(1)系统误差:在收集资料过程中,由于仪器初始状态未调整到零、标准试剂未经校正、医生掌握疗效标准偏高或偏低等原因,可造成观察结果倾向性的偏大或偏小,这叫系统误差。
要尽量查明其原因,必须克服。
(2)随机测量误差:在收集原始资料过程中,即使仪器初始状态及标准试剂已经校正,但是,由于各种偶然因素的影响也会造成同一对象多次测定的结果不完全一致。
譬如,实验操作员操作技术不稳定,不同实验操作员之间的操作差异,电压不稳及环境温度差异等因素造成测量结果的误差。
对于这种误差应采取相应的措施加以控制,至少应控制在一定的允许范围内。
一般可以用技术培训、指定固定实验操作员、加强责任感教育及购置一定精度的稳压器、恒温装置等措施,从而达到控制的目的。
(3)抽样误差:即使在消除了系统误差,并把随机测量误差控制在允许范围内,样本均数(或其它统计量)与总体均数(或其它参数)之间仍可能有差异。
四、回归分析 15分可能涉及范围:多元线性回归、logistic 回归。
要求: 1、提供某一资料,选择统计分析方法2、偏回归系数、标准偏回归系数、决定系数、校正决定系数、OR 等常用指标的意义与应用3、列回归方程例 27名糖尿病人的血清总胆固醇、甘油三脂、空腹胰岛素、糖化血红蛋白、空腹血糖的测量值如下表:(1)欲分析影响空腹血糖浓度的有关因素,宜采用什么统计分析方法?多元线性回归分析(2)已知甘油三酯(X2)、胰岛素(X3)和糖化血红蛋白(X4)是主要影响因素,现欲比较上述因素对血糖浓度的相对影响强度,应计算何种指标?标准偏回归系数可用来比较各自变量Xj 对Y 的影响强度,有统计意义下,回归系数绝对值越大,对Y 的作用越大。
SPSS 输出的多元回归分析结果中给出的各变量的标准偏回归系数,比较三个标准偏回归系数:甘油三脂0.354: 胰岛素0.360: 糖化血红蛋白0.413≈1:1.02:1.17(倍) 糖化血红蛋白对血糖的影响强度大小依次为:糖化血红蛋白X4、胰岛素X3、甘油三脂X2(3)分析其回归模型的好坏宜选用何种指标?校正决定系数( R 2a )作为评价标准一般说决定系数(R 2)越大越优,但由于R 2是随自变量的增加而增大,因此,不能简单地以R 2作为评价标准,而是用校正决定系数( R 2a )作为评价标准。
R 2a 不会随无意义的自变量增加而增大。
(4)根据给出SPSS 结果,做出正确的结论。
空腹血糖浓度与总胆固醇无关,与甘油三脂、空腹胰岛素、糖化血红蛋白线性相关。
(5)列出回归方程。
最优回归方程为:432663.0287.0402.05.6ˆX X X y+-+= Model Summary(最终模型的拟合优度检验验表)相关分析【完全分析答案】jszb1、此资料包含有四个变量,属于多变量计量资料,为多因素设计。
要分析多因素对空腹血糖浓度的影响,宜采用 多元线性回归分析。
2、根据样本数据求得模型参数β0, β1, β2, β3,β4的估计值b0,b1,b2,b3,b4β0又称为截距,β1, β2, …,βm 称为偏回归系数(partial regressin coefficient )或简称为回归系数。
考题题型举例50例急性淋巴细胞白血病病人,在入院时白细胞数X 1(×10/L ),淋巴结浸润度X 2(记为0、1、2三级),缓解出院后巩固治疗X3(巩固治疗时赋值1,无巩固治疗时赋值0)。
随访1年取得每例病人是否死亡Y (死亡赋值1,存活赋值0)的资料。
(1)欲筛选哪些因素是影响急性淋巴细胞白血病病人一年内死亡的的主要因素,应选择何种统计分析方法?(2)经统计分析得如下结果,请列出其回归方程?(3)解释X3对应的Exp(B)=0.062的含义。
)解析:(1)欲筛选哪些因素是影响急性淋巴细胞白血病病人一年内死亡的的主要因素,应选择何种统计分析方法?答案:Logistic 回归考点:多因素分析统计方法的选择(2)经统计分析得如下结果,请列出其回归方程?ln (P/1-P )=1.642+0.707X2-2.781X3考点:回归方程的建立(3)解释X3对应的Exp(B)=0.062的含义。
巩固治疗比不巩固治疗危险因素下降0.062倍考点:OR 值的意义内容精要概念非条件Logistic 回归logistic 回归模型Logistic 回归是一种适用于应变量为分类值多因素曲线模型。
非条件Logistic 回归:成组设计,Y 为二项分类。
又称Binary Logistic 回归条件Logistic 回归:配对设计,Y 为二项分类。
多分类Logistic 回归:Y 为多分类。
Binary Logistic 适用于应变量为二项分类的资料。
应变量(Y )在一组自变量(X )的作用下所发生的结果赋值规则为:出现阳性的结果——1,其概率用P 来表示;出现阴性的结果——0,其概率用Q 或(1–P )来表示比数比OR第i 个观察对象的发病概率比数(odds)为Pi/Qi ,第l 个观察对象的发病概率比数为Pl/Ql 。
这两个观察对象的发病概率比数之比值即称为比数比OR (odds ratio)。
对比数比取自然对数,可得:()()()lp ip p 2l 2i 21l 1i 1l l i i x x b x x b x x b )OR ln(Q P Q P ln −++−+−==⎟⎟⎠⎞⎜⎜⎝⎛⋯式中:x ij -x lj ——同一因素x j 的不同暴露水平之差。
第18章 Logistic 回归 思考与练习参考答案
一、最佳选择题
1. Logistic 回归与多重线性回归比较,( A )。
A .logistic 回归的因变量为二分类变量 B .多重线性回归的因变量为二分类变量
C .logistic 回归和多重线性回归的因变量都可为二分类变量
D .logistic 回归的自变量必须是二分类变量
E .多重线性回归的自变量必须是二分类变量 2. Logistic 回归适用于因变量为( E )。
A .二分类变量
B .多分类有序变量
C .多分类无序变量
D .连续型定量变量
E .A 、B 、C 均可 3. Logistic 回归系数与优势比OR 的关系为( E )。
A .>β0等价于OR >1
B .>β0等价于OR <1
C .β=0等价于OR =1
D .β<0等价于OR <1
E .A 、C 、D 均正确 4. Logistic 回归可用于( E )。
A.影响因素分析 B .校正混杂因素 C .预测 D .仅有A 和C E .A 、B 、C 均可
5. Logistic 回归中自变量如为多分类变量,宜将其按哑变量处理,与其他变量进行变量筛选时可用( D )。
A .软件自动筛选的前进法
B .软件自动筛选的后退法
C .软件自动筛选的逐步法
D .应将几个哑变量作为一个因素,整体进出回归方程
E .A 、B 、C 均可
二、思考题
1. 为研究低龄青少年吸烟的外在因素,研究者采用整群抽样,在某中心城区和远城区的初中学校,各选择初一年级一个班的全部学生进行调查,并用logistic 回归方程筛选影响因素。
试问上述问题采用logistic 回归是否妥当?
答:上述问题采用logistic回归不妥当,因为logistic回归中参数的极大似然估计要求样本结局事件相互独立,而研究的问题中低龄青少年吸烟行为不独立。
2. 分类变量赋值不同对logistic回归有何影响? 分析结果一致吗?
答:(1)若因变量交换赋值,两个logistic回归方程的参数估计绝对值相等,符号相反;优势比互为倒数,含义有所区别,实质意义一样;模型拟合检验与回归系数的假设检验结果相同。
(2)若改变自变量参照类或哑变量设置方法,logistic回归方程形式、参数含义虽有不同,但是模型实质与应用结果相同,可以根据研究需要选择不同赋值方法。
Logistic回归结果报告中,一定要说明分类变量赋值方法及其参照,否则无法理解模型意义。
3. 例18-6研究性别对吸烟行为的影响,采用logistic回归校正了年龄对居民吸烟行为的影响,请考虑有无其他混杂因素需要校正?
答:例18-6的主要目的是研究吸烟行为与性别的联系及其强度,例题采用logistic回归只校正了年龄对居民吸烟行为的影响。
事实上,除年龄外,仍有其他因素会影响吸烟行为与性别的联系强度,如家庭人均年收入、受教育程度、主动获取保健知识等。
建立回归模型时,首先应根据专业知识确定可能的影响因素,再采用logistic回归,将性别作为强制引入变量,对其他可能的影响因素进行变量筛选,最后将性别与筛选出的因素作为自变量建立logistic回归方程,从而正确回答校正混杂因素后吸烟行为与性别的联系及其强度。
4. 配对病例-对照研究资料若采用非条件logistic回归进行分析,对结果有何影响?
答:采用配对(匹配)方法的目的是对可能的混杂因素加以控制,有助于提高研究效率和可靠性。
配对设计的特点是对子内部控制的混杂变量一致,有较好的可比性。
配对(匹配)资料若采用非条件logistic回归进行分析,则忽视了这种可比性,降低了分析方法的检验效能。
三、计算题
探讨肾细胞癌转移有关的因素研究中,收集了26例行根治性肾切除术患者的肾癌标本资料(教材表18-19),有关变量说明如下,试进行logistic回归分析。
X:确诊时患者的年龄(岁)。
1
X:肾细胞癌血管内皮生长因子,其阳性表达由低到高共3个等级,分别赋值1、2、3。
2
X:肾细胞癌组织内微血管数。
3
X:肾细胞癌细胞核组织学分级,由低到高共4级,分别赋值1、2、3、4。
4
5X :肾细胞癌分期,由低到高共4期,分别赋值1、2、3、4。
Y :肾细胞癌转移情况,有转移=1,无转移=0。
教材表18-19 26例行根治性肾切除术患者的肾癌标本资料
数据摘自 倪宗瓒. 卫生统计学 4版,人民卫生出版社,2004。
解:
Logistic 回归分析结果显示:肾细胞癌转移与肾细胞癌血管内皮生长因子和肾细胞癌细胞核组织学分级有关。
肾细胞癌血管内皮生长因子2X 和肾细胞癌细胞核组织学分级4X 的回归系数均为正值,说明两个变量取值越大,则肾细胞癌转移的危险性越大。
在肾细胞癌细胞核组织学分级不变条件下,肾细胞癌血管内皮生长因子每增加一级,肾细胞癌转移的优势增至11.172倍,增加10.172倍;在肾细胞癌血管内皮生长因子不变条件下,肾细胞癌细胞核组织学分级每增加一级,肾细胞癌转移的优势增至8.136倍,增加7.136倍。
(毛宗福 余红梅)。