IKAnalyzer中文分词器V3.2.3使用手册
- 格式:pdf
- 大小:489.31 KB
- 文档页数:16

ElasticSearch使用手册一、ElasticSearch简介1.1.什么是ElasticSearchElasticSearch(以下均检查ES)是Compass(基于Lucene开源项目)作者Shay Banon在2010年发布的高性能、实时、分布式的开源搜索引擎。
后来成立了ElasticSearch公司,负责ES相关产品的开发及商用服务支持,ES依旧采用免费开源模式,但部分插件采用商用授权模式,例如Marvel插件(负责ES的监控管理)、Shield插件(提供ES的授权控制)。
1.2.ElasticSearch的基础概念⏹Collection在SolrCloud集群中逻辑意义上的完整的索引。
它常常被划分为一个或多个Shard,它们使用相同的Config Set。
如果Shard数超过一个,它就是分布式索引,SolrCloud让你通过Collection名称引用它,而不需要关心分布式检索时需要使用的和Shard相关参数。
⏹Config SetSolr Core提供服务必须的一组配置文件。
每个config set有一个名字。
最小需要包括solrconfig.xml (SolrConfigXml)和schema.xml (SchemaXml),除此之外,依据这两个文件的配置内容,可能还需要包含其它文件。
它存储在Zookeeper中。
Config sets可以重新上传或者使用upconfig命令更新,使用Solr的启动参数bootstrap_confdir指定可以初始化或更新它。
⏹CoreCore也就是Solr Core,一个Solr中包含一个或者多个Solr Core,每个Solr Core可以独立提供索引和查询功能,每个Solr Core对应一个索引或者Collection的Shard,Solr Core的提出是为了增加管理灵活性和共用资源。
在SolrCloud中有个不同点是它使用的配置是在Zookeeper中的,传统的Solr core的配置文件是在磁盘上的配置目录中。

Lucene使⽤IKAnalyzer分词实例及IKAnalyzer扩展词库⽅案⼀: 基于配置的词典扩充项⽬结构图如下:IK分词器还⽀持通过配置IKAnalyzer.cfg.xml⽂件来扩充您的专有词典。
⾕歌拼⾳词库下载:在web项⽬的src⽬录下创建IKAnalyzer.cfg.xml⽂件,内容如下<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE properties SYSTEM "/dtd/properties.dtd"><properties><comment>IK Analyzer 扩展配置</comment><!-- ⽤户可以在这⾥配置⾃⼰的扩展字典 --><entry key="ext_dict">/dicdata/use.dic.dic;/dicdata/googlepy.dic</entry><!-- ⽤户可以在这⾥配置⾃⼰的扩展停⽌词字典 --><entry key="ext_stopwords">/dicdata/ext_stopword.dic</entry></properties>词典⽂件的编辑与部署分词器的词典⽂件格式是⽆BOM 的UTF-8 编码的中⽂⽂本⽂件,⽂件扩展名不限。
词典中,每个中⽂词汇独⽴占⼀⾏,使⽤\r\n 的DOS ⽅式换⾏。
(注,如果您不了解什么是⽆BOM 的UTF-8 格式,请保证您的词典使⽤UTF-8 存储,并在⽂件的头部添加⼀空⾏)。
您可以参考分词器源码org.wltea.analyzer.dic 包下的.dic ⽂件。
词典⽂件应部署在Java 的资源路径下,即ClassLoader 能够加载的路径中。
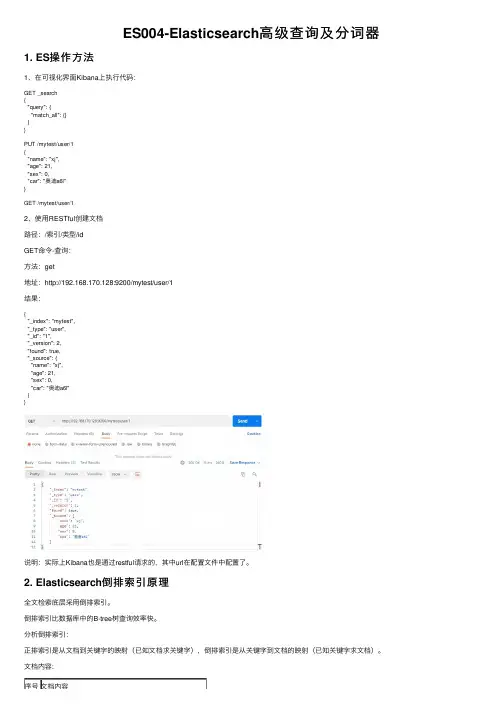
ES004-Elasticsearch⾼级查询及分词器1. ES操作⽅法1、在可视化界⾯Kibana上执⾏代码:GET _search{"query": {"match_all": {}}}PUT /mytest/user/1{"name": "xj","age": 21,"sex": 0,"car": "奥迪a6l"}GET /mytest/user/12、使⽤RESTful创建⽂档路径:/索引/类型/idGET命令-查询:⽅法:get地址:http://192.168.170.128:9200/mytest/user/1结果:{"_index": "mytest","_type": "user","_id": "1","_version": 2,"found": true,"_source": {"name": "xj","age": 21,"sex": 0,"car": "奥迪a6l"}}说明:实际上Kibana也是通过restful请求的,其中url在配置⽂件中配置了。
2. Elasticsearch倒排索引原理全⽂检索底层采⽤倒排索引。
倒排索引⽐数据库中的B-tree树查询效率快。
分析倒排索引:正排索引是从⽂档到关键字的映射(已知⽂档求关键字),倒排索引是从关键字到⽂档的映射(已知关键字求⽂档)。
⽂档内容:序号⽂档内容1⼩俊是⼀家科技公司创始⼈,开的汽车是奥迪a8l,加速爽。

IKAnalyzer是一个开源的中文分词工具,它采用了基于汉字的切分方式,并提供了多种分词算法和模式匹配算法。
下面是一些IKAnalyzer的基本用法:1. 引入依赖:在使用IKAnalyzer之前,需要先将其添加到您的项目中。
如果您使用Maven进行项目管理,可以通过在pom.xml文件中添加以下依赖来引入IKAnalyzer:```xml<dependency><groupId>org.wltea.analyzer</groupId><artifactId>IKAnalyzer</artifactId><version>版本号</version></dependency>```请注意,您需要将“版本号”替换为您要使用的实际版本号。
2. 创建IKAnalyzer实例:在使用IKAnalyzer进行分词之前,需要创建一个IKAnalyzer实例。
您可以通过以下代码创建一个默认的IKAnalyzer实例:```javaAnalyzer analyzer = new IKAnalyzer();```3. 进行分词:一旦创建了IKAnalyzer实例,您可以使用它来对文本进行分词。
以下是一个简单的示例:```javaString text = "我爱中国";TokenStream tokenStream = analyzer.tokenStream("", text);while (tokenStream.incrementToken()) {System.out.println(tokenStream.getAttribute(CharTermAttribute.class ));}```此代码将打印出分词后的结果。
4. 自定义分词规则:如果您需要更精细的控制分词结果,可以使用自定义词典和规则。

1、学会使用11大Java开源中文分词器
2、对比分析11大Java开源中文分词器的分词效果
本文给出了11大Java开源中文分词的使用方法以及分词结果对比代码,至于效果哪个好,那要用的人结合自己的应用场景自己来判断。
11大Java开源中文分词器,不同的分词器有不同的用法,定义的接口也不一样,我们先定义一个统一的接口:
从上面的定义我们知道,在Java中,同样的方法名称和参数,但是返回值不同,这种情况不可以使用重载。
这两个方法的区别在于返回值,每一个分词器都可能有多种分词模式,每种模式的分词结果都可能不相同,第一个方法忽略分词器模式,返回所有模式的所有不重复分词结果,第二个方法返回每一种分词器模式及其对应的分词结果。
在这里,需要注意的是我们使用了Java8中的新特性默认方法,并使用stream把一个map 的value转换为不重复的集合。
下面我们利用这11大分词器来实现这个接口:
1、word分词器
2、Ansj分词器
3、Stanford分词器
4、FudanNLP分词器
5、Jieba分词器
6、Jcseg分词器
7、MMSeg4j分词器
8、IKAnalyzer分词器
9、Paoding分词器
10、smartcn分词器
11、HanLP分词器
现在我们已经实现了本文的第一个目的:学会使用11大Java开源中文分词器。
最后我们来实现本文的第二个目的:对比分析11大Java开源中文分词器的分词效果,程序如下:。

IKAnalyzer中文分词器V3.2使用手册目录1.IK Analyzer 3.X介绍 (2)2.使用指南 (5)3.词表扩展 (14)4.针对solr的分词器应用扩展 (16)5.关于作者 (18)1.IK Analyzer 3.X介绍IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。
从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。
最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。
新版本的IK Analyzer 3.X则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
1.1 IK Analyzer 3.X结构设计1.2 IK Analyzer 3.X特性●采用了特有的“正向迭代最细粒度切分算法“,具有80万字/秒的高速处理能力。
●采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
●优化的词典存储,更小的内存占用。
支持用户词典扩展定义●针对Lucene全文检索优化的查询分析器IKQueryParser(作者吐血推荐);采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。
1.3 分词效果示例IK Analyzer 3.2.8版本支持细粒度切分和最大词长切分,以下是两种切分方式的演示样例。
文本原文1:IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。
从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。
●最大词长分词结果:ikanalyzer | 是| 一个| 开源| 的| 基于| java | 语言| 开发| 的| 轻量级| 的| 中文| 分词| 工具包| 从| 2006 | 年| 12 | 月| 推出| 1.0 | 版| 开始| ikanalyzer | 已经| 推出| 出了| 3 | 个| 大| 版本●最细粒度分词结果:ikanalyzer | 是| 一个| 一| 个| 开源| 的| 基于| java | 语言| 开发| 的| 轻量级| 量级| 的| 中文| 分词| 工具包| 工具| 从| 2006 | 年| 12 | 月| 推出|1.0 | 版| 开始| ikanalyzer | 已经| 推出| 出了| 3 | 个| 大| 版本文本原文2:作者博客: 电子邮件:linliangyi2005@●最大词长分词结果:作者| 博客| | 电子邮件| linliangyi2005@●最细粒度分词结果:作者| 博客| | linliangyi | 2007 | javaeye | com | 电子邮件| linliangyi2005@ | linliangyi | 2005 | gmail | com文本原文3古田县城关六一四路四百零五号●最大词长分词结果:古田县| 县城| 城关| 六一四| 路| 四百零五| 号●最细粒度分词结果:古田县| 古田| 县城| 城关| 六一四| 六一| 四| 路| 四百零五| 四| 百| 零| 五| 号文本原文4曙光天阔I620r-G /A950r-F 夏普SH9020C●最大词长分词结果:曙光| 天| 阔| i620r-g | a950r-f | 夏普| sh9020c●最细粒度分词结果:曙光| 天| 阔| i620r-g | i | 620 | r | g | a950r-f | a | 950 | r | f | 夏普| sh9020c | sh |9020 | c2.使用指南2.1下载地址GoogleCode开源项目:/p/ik-analyzer/ GoogleCode SVN下载:/svn/trunk/2.2与相关项目的版本兼容IK分词器版本Lucene 版本Solr版本3.1.3GA及先前版兼容2.9.1及先前版本没有solr接口3.1.5GA 兼容2.9.1及先前版本对solr1.3提供接口实现(详细请参考对应版本使用手册)3.1.6GA 兼容2.9.1及先前版本对solr1.3、solr1.4提供接口实现(详细请参考对应版本使用手册)3.2.0G及后续版本兼容Lucene2.9及3.0版本不支持Lucene2.4及先前版本仅对solr1.4提供接口实现(请参考本手册solr部分说明)2.3安装部署IK Analyzer安装包包含:1.《IKAnalyzer中文分词器V3.X使用手册》(即本文档)2.IKAnalyzer3.X.jar(主jar包)3.IKAnalyzer.cfg.xml(分词器扩展配置文件)4.ext_stopword.dic(扩展的stopword词典,3.2以上版本提供)它的安装部署十分简单,将IKAnalyzer3.X.jar部署于项目的lib目录中;IKAnalyzer.cfg.xml 与ext_stopword.dic文件放置在代码根目录(对于web项目,通常是WEB-INF/classes 目录,同hibernate、log4j等配置文件相同)下即可。

IKanalyzer、ansj_seg、jcseg三种中⽂分词器的实战较量选⼿:IKanalyzer、ansj_seg、jcseg硬件:i5-3470 3.2GHz 8GB win7 x64⽐赛项⽬:1、搜索;2、⾃然语⾔分析选⼿介绍: 1,IKanalyzer IKanalyzer采⽤的是“正向迭代最细粒度切分算法”,是⽐较常见⽽且很容易上⼿的分词器了。
⼀般新⼿上路学习lucene或者solr都会⽤这个。
优点是开源(其实java分词器多是开源的,毕竟算法都是业内熟知的)、轻量、⽬前来看没有太⼤的bug,源码简单易懂,做⼆次开发也很简单,即使遇到solr/Lucene版本更新,只需要⾃⼰稍微修改下实现类就可以通⽤。
缺点是过于简单⽩痴,只是简单的根据配置好的词库进⾏分词,没有任何智能可⾔,连“和服”、“和服务器”这种⽼梗都破不了。
我⼿头的IKanalyzer是被我进⾏⼆次开发后的版本,修改了⼀些问题,词库读取⽅式改成树形。
IKanalyzer可以作为⾮智能分词器的代表出场。
2,ansj_segansj_seg分词器⽤的⼈可能不太多吧,不过个⼈觉得是开源分词器⾥最强悍功能最丰富的。
作者孙建,我曾在微博上与他有过简单的交流,讨论过ansj_seg分词器的⼀些⼩的bug和不⾜。
ansj_seg基于中科院的 ictclas 中⽂分词算法,智能、⾼效。
虽然现在已经有ictclas 的for java版本,但是 ansj_seg从实现到使⽤来说要强⼤的多,⽽且作者⾃产⾃销⾃⽤,很多细节和⼩功能都有考虑,在索引和⾃然语⾔分析⽅⾯都有很优秀的表现。
我⼿头的ansj_seg是⾃⼰修复了⼀些bug后的版本。
ansj_seg可以作为ictclas 算法实现的分词器的代表出场。
3,jcsegjcseg分词器使⽤的是mmseg算法和fmm算法,这个分词器类似ansj_seg的很多地⽅,智能、⼈性化,个⼈感觉体验要超过同门师兄弟mmseg4j,所以可以作为mmseg算法实现的分词器的代表出场。

Elasticsearch之中⽂分词器插件es-ik的⾃定义热更新词库
接上⽂:上⽂中我们了解到,词表对特定query的效果影响⽐较⼤,也是解决badcase的⼿段之⼀。
然后系统提供的通⽤词表和扩展词表的每次改动都需要对ES进⾏重启,在web系统中,这是不允许的,因此我们需要搭建⼀个可以不需要重启ES的动态词表,每次只需要更新远程词表的位置就可以了。
在IKAnalyzer.cfg.xml中,我们看到系统是⽀持远程词典的:
然后,我们就按照这个策略配置⼀个试试:
在服务器下,创建了⼀个php⽂件
通过这个⽂件可以直接加载出词典内容来;
然后配置到“ext_stopwords”中:
的内容为:
查看 es-ik 插件的源码可以发现:
在 class中:
1min词表会同步⼀次
所以必须保证下⾯两个值中⾄少⼀个发⽣了变化,最简单的就跟我上⾯⼀样整个时间戳就可以了。
有了这个,以后就可以⼈为控制切词结果了,没必要切的太细的也可以指定组合之后的结果就不再切分了。
完美。

Ikanalyzer分词器动态自定义词库的方法IKanalyzer可通过配置Ikanalyzer.cfg.xml进行自定义词库,但有时需要在程序中根据不同的文章动态调用不同的词库进行分词,这就需要自定义Configuration类来实现。
方法如下:首先,拷贝Ikanalyzer源码中的DefaultConfig.java,改为MyConfiguration.java,然后做如下改写:public class MyConfiguration implements Configuration{//懒汉单例private static final Configuration CFG = new MyConfiguration();/** 分词器默认字典路径*/private String PATH_DIC_MAIN = "org/wltea/analyzer/dic/main2012.dic";//需要把static final去掉private String static final PATH_DIC_QUANTIFIER ="org/wltea/analyzer/dic/quantifier.dic";/** 分词器配置文件路径*/private static final String FILE_NAME = "IKAnalyzer.cfg.xml";//保留静态自定义词库的功能//配置属性——扩展字典private static final String EXT_DICT = "ext_dict";//配置属性——扩展停止词典private static final String EXT_STOP = "ext_stopwords";private Properties props;/** 是否使用smart方式分词*/private boolean useSmart;/*** 返回单例* @return Configuration单例*/public static Configuration getInstance(){return CFG;}/** 初始化配置文件*/MyConfiguration(){props = new Properties();InputStream input =this.getClass().getClassLoader().getResourceAsStream(FILE_NAME);if(input != null){try {props.loadFromXML(input);} catch (InvalidPropertiesFormatException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}}/*** 返回useSmart标志位* useSmart =true ,分词器使用智能切分策略,=false则使用细粒度切分* @return useSmart*/public boolean useSmart() {return useSmart;}/*** 设置useSmart标志位* useSmart =true ,分词器使用智能切分策略,=false则使用细粒度切分* @param useSmart*/public void setUseSmart(boolean useSmart) { eSmart = useSmart;}/*** 新加函数:设置主词典路径** @return String 主词典路径*/public void setMainDictionary(String path) { this.PATH_DIC_MAIN = path;}/*** 获取主词典路径** @return String 主词典路径*/public String getMainDictionary(){return PATH_DIC_MAIN;}/*** 获取量词词典路径* @return String 量词词典路径*/public String getQuantifierDicionary(){return PATH_DIC_QUANTIFIER;}/*** 获取扩展字典配置路径* @return List<String> 相对类加载器的路径*/public List<String> getExtDictionarys(){List<String> extDictFiles = new ArrayList<String>(2);String extDictCfg = props.getProperty(EXT_DICT);if(extDictCfg != null){//使用;分割多个扩展字典配置String[] filePaths = extDictCfg.split(";");if(filePaths != null){for(String filePath : filePaths){if(filePath != null && !"".equals(filePath.trim())){ extDictFiles.add(filePath.trim());}}}}return extDictFiles;}/*** 获取扩展停止词典配置路径* @return List<String> 相对类加载器的路径*/public List<String> getExtStopWordDictionarys(){List<String> extStopWordDictFiles = new ArrayList<String>(2); String extStopWordDictCfg = props.getProperty(EXT_STOP); if(extStopWordDictCfg != null){//使用;分割多个扩展字典配置String[] filePaths = extStopWordDictCfg.split(";");if(filePaths != null){for(String filePath : filePaths){if(filePath != null && !"".equals(filePath.trim())){extStopWordDictFiles.add(filePath.trim());}}}}return extStopWordDictFiles;}}调用方法在分词程序中调用方法如下:String text = "";//需要分词的字符串MyConfiguration mycfg = new MyConfiguration();mycfg.setUseSmart(true); //设置为智能分词mycfg.setMainDictionary("msay.dic"); //动态设置自定义的词库IKSegmenter seg = new IKSegmenter(new StringReader(text) ,mycfg);.......本源码经测试可正常运行。

ik分词器分词原理IK分词器(IKAnalyzer)是一款针对中文文本的智能分词器,其为搜索引擎、虚拟客服交互、搜索导航系统等提供智能分词服务,是目前中文处理领域应用最广泛、使用最多的中文分词器。
分词器使用算法能够自动对中文文本进行分词处理,其原理主要分为以下四部分:1.库算法:IK分词器使用词库算法来处理中文文本。
使用词库算法时,先分析出每个文本中的词语,然后从词库中找出其中的名词、动词等词,最终将文本中的每个词按规则匹配出来。
2.向分词:使用双向分词算法时,会将文本从左到右、从右到左依次拆分,以最大概率的分词结果来分析文本。
这样就能将一个文本拆分成尽可能多的最短的词语,使搜索更加准确简单。
3. N-最短路径:使用N-最短路径算法时,会构建一个有向图,将其中每个点都看作是文本中的一个词,而每个边都会携带一个权值,表示两个词之间的词性分析结果。
然后在有向图中搜索出来一条最优的路径,从而得到一个最优的分词结果。
4. HMM算法:HMM算法是一种基于隐马尔科夫模型的算法,是计算机语言处理领域常用的算法之一。
使用HMM算法时,先搭建一个隐马尔科夫模型,然后根据文本中的每个词语来计算概率,最终得到一个最优的分词结果。
以上就是IK分词器分词原理的总结,基于这四种分词算法,IK 分词器能够对中文文本进行准确的分词处理,为文本信息搜索提供了可靠的技术基础。
IK分词器的分词原理是以中文文本的分词为基础的,它是通过新颖的语言处理技术,将文本中的内容进行语义解析,最后得出准确有效的分词结果。
IK分词器可以针对文本内容,根据文本中出现的词语,使用词库算法来处理文本,通过双向分词算法从中提取出尽可能多的最短的词语,从而保证搜索的准确性。
此外,IK分词器还使用N-最短路径算法和HMM算法,可以从中构建出一个有向图,搜索出最优的路径,从而完成文本的分词处理。
综上所述,IK分词器具有易用性高、计算效率高、速度快等优点,为新型搜索引擎等提供可靠的技术基础,是当前中文分词领域应用最广泛、使用最多的分词器。

ES-⾃然语⾔处理之中⽂分词器前⾔中⽂分词是中⽂⽂本处理的⼀个基础步骤,也是中⽂⼈机⾃然语⾔交互的基础模块。
不同于英⽂的是,中⽂句⼦中没有词的界限,因此在进⾏中⽂⾃然语⾔处理时,通常需要先进⾏分词,分词效果将直接影响词性、句法树等模块的效果。
当然分词只是⼀个⼯具,场景不同,要求也不同。
在⼈机⾃然语⾔交互中,成熟的中⽂分词算法能够达到更好的⾃然语⾔处理效果,帮助计算机理解复杂的中⽂语⾔。
根据中⽂分词实现的原理和特点,可以分为:基于词典分词算法基于理解的分词⽅法基于统计的机器学习算法基于词典分词算法基于词典分词算法,也称为字符串匹配分词算法。
该算法是按照⼀定的策略将待匹配的字符串和⼀个已经建⽴好的"充分⼤的"词典中的词进⾏匹配,若找到某个词条,则说明匹配成功,识别了该词。
常见的基于词典的分词算法为⼀下⼏种:正向最⼤匹配算法。
逆向最⼤匹配法。
最少切分法。
双向匹配分词法。
基于词典的分词算法是应⽤最⼴泛,分词速度最快的,很长⼀段时间内研究者在对对基于字符串匹配⽅法进⾏优化,⽐如最⼤长度设定,字符串存储和查找⽅法以及对于词表的组织结构,⽐如采⽤TRIE索引树,哈希索引等。
这类算法的优点:速度快,都是O(n)的时间复杂度,实现简单,效果尚可。
算法的缺点:对歧义和未登录的词处理不好。
基于理解的分词⽅法这种分词⽅法是通过让计算机模拟⼈对句⼦的理解,达到识别词的效果,其基本思想就是在分词的同时进⾏句法、语义分析,利⽤句法信息和语义信息来处理歧义现象,它通常包含三个部分:分词系统,句法语义⼦系统,总控部分,在总控部分的协调下,分词系统可以获得有关词,句⼦等的句法和语义信息来对分词歧义进⾏判断,它模拟来⼈对句⼦的理解过程,这种分词⽅法需要⼤量的语⾔知识和信息,由于汉语⾔知识的笼统、复杂性,难以将各种语⾔信息组成及其可以直接读取的形式,因此⽬前基于理解的分词系统还在试验阶段。
基于统计的机器学习算法这类⽬前常⽤的算法是HMM,CRF,SVM,深度学习等算法,⽐如stanford,Hanlp分词⼯具是基于CRF算法。
ik-analyzer 用法-回复ikanalyzer是一个中文分词工具,可以将中文文本切分成一个个独立的词语,是实现中文自然语言处理任务的重要工具之一。
它具有易于使用、高性能和准确的特点,被广泛应用于搜索引擎、信息检索、文本分析等领域。
1. ikanalyzer的安装要使用ikanalyzer,首先需要将其安装到你的项目中。
ikanalyzer是基于Java开发的,可以通过Maven或手动下载jar包的方式进行安装。
以下是Maven安装的步骤:首先,在项目的pom.xml文件中添加如下依赖:xml<dependency><groupId>org.wltea</groupId><artifactId>IKAnalyzer</artifactId><version>2012_u6</version></dependency>然后运行Maven命令进行安装:bashmvn install2. ikanalyzer的基本用法安装完成后,我们可以开始使用ikanalyzer进行中文分词。
下面是一个简单的示例代码:javaimport org.wltea.analyzer.core.IKSegmenter;import org.wltea.analyzer.core.Lexeme;import java.io.StringReader;public class IkanalyzerExample {public static void main(String[] args) throws Exception { String text = "这是一个ikanalyzer的示例。
";StringReader reader = new StringReader(text);IKSegmenter segmenter = new IKSegmenter(reader, true);Lexeme lexeme;while ((lexeme = segmenter.next()) != null) {System.out.print(lexeme.getLexemeText() + " ");}}}以上代码中,首先将待分词的文本传入一个StringReader对象中,然后创建IKSegmenter对象,将StringReader对象和一个布尔值(用于控制是否使用智能分词)传给IKSegmenter的构造函数。
Elasticsearch7.x-IK 分词器插件(ik_smart ,ik_max_word )⼀、安装IK 分词器Elasticsearch 也需要安装IK 分析器以实现对中⽂更好的分词⽀持。
去Github 下载最新版elasticsearch-ikhttps:///medcl/elasticsearch-analysis-ik/releases将ik ⽂件夹放在elasticsearch/plugins ⽬录下,重启elasticsearch 。
Console 控制台输出:[2019-09-04T08:50:23,395][INFO ][o.e.p.PluginsService ] [THINKPAD-T460P] loaded plugin [analysis-ik]⼆、测试分词效果IK 分词器有两种分词模式:ik_max_word 和ik_smart 模式。
1、ik_max_word会将⽂本做最细粒度的拆分,⽐如会将“中华⼈民共和国⼈民⼤会堂”拆分为“中华⼈民共和国、中华⼈民、中华、华⼈、⼈民共和国、⼈民、共和国、⼤会堂、⼤会、会堂等词语。
2、ik_smart会做最粗粒度的拆分,⽐如会将“中华⼈民共和国⼈民⼤会堂”拆分为中华⼈民共和国、⼈民⼤会堂。
测试两种分词模式的效果。
分词查询要⽤GET 、POST 请求,需要把请求参数写在body 中,且需要JSON 格式。
发送:post localhost:9200/_analyze(1)测试ik_max_word(2)测试ik_smartPOST _analyze{"analyzer": "ik_max_word","text":"中华⼈民共和国⼈民⼤会堂"}POST _analyze⽹上关于两种分词器使⽤的最佳实践是:索引时⽤ik_max_word ,在搜索时⽤ik_smart 。
IK分词器⽤法⼀)新建maven⼯程1.1)项⽬结构如下:1.2)IKAnalyzer.cfg.xml内容如下:<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE properties SYSTEM "/dtd/properties.dtd"><properties><comment>IK Analyzer 扩展配置</comment><entry key="ext_dict">extend.dic;</entry><entry key="ext_stopwords">stopword.dic;</entry></properties>1.3)在pom⽂件中添加如下jar<dependency><groupId>com.janeluo</groupId><artifactId>ikanalyzer</artifactId><version>2012_u6</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>4.7.2</version></dependency>⼆)新建类IKAnalyzerSupplyProductpublic class IKAnalyzerSupplyProduct {public static String startIKAnalyzer(String line) throws IOException{IKAnalyzer analyzer = new IKAnalyzer();// 使⽤智能分词analyzer.setUseSmart(true);// 打印分词结果try {return printAnalysisResult(analyzer, line);} catch (Exception e) {e.printStackTrace();}finally{if(analyzer!=null){analyzer.close();}}return null;}private static String printAnalysisResult(Analyzer analyzer, String keyWord)throws Exception {String resultdata="";String infoData="";if(keyWord!=""&&keyWord!=null){TokenStream tokenStream = analyzer.tokenStream("content",new StringReader(keyWord));tokenStream.addAttribute(CharTermAttribute.class);tokenStream.reset();while (tokenStream.incrementToken()) {CharTermAttribute charTermAttribute = tokenStream.getAttribute(CharTermAttribute.class);String dest= NumberUtil.checkNumber(charTermAttribute.toString().replace("-",""));boolean mailres= RegExpUtil.isEmail(charTermAttribute.toString());boolean hpres=RegExpUtil.isHomepage(charTermAttribute.toString());boolean num=RegExpUtil.isNum(charTermAttribute.toString().replace("-", "").replace("qq", "").replace("QQ", "").replace("+", ""));if(dest!="CELLPHONE"&&dest!="FIXEDPHONE"&&mailres==false&&hpres==false&&num==false){infoData=infoData+" "+charTermAttribute.toString();}}if(infoData!=""&&infoData!=null){resultdata=resultdata+infoData.trim()+"\r\n";}else{resultdata="";}}return resultdata;}public static void main(String[] args) {String word ="8⽉17⽇,“雄鹰突击-2018”中国和⽩俄罗斯特种部队联合训练,在北部战区陆军某综合训练基地完成综合演练并举⾏结训仪式。
Solr安装(单机版) 本⽂记录的是solr在win下安装配置使⽤的过程,最后将solr部署到Linux上通过远程访问。
下⼀篇⽂章会介绍的安装! Solr是基于Lucene的全⽂检索服务器,性能进⾏了优化。
运⾏在jetty、tomcat这些web容器中。
⽽Lucene只是⼀个jar包,不能对外提供服务。
在安装之前我们要先搞清楚下⾯两个问题。
⼀:Solr是如何实现全⽂检索的 索引流程 Solr客户端(浏览器、java程序)可以向solr服务器发送post请求,请求内容是包含Field等信息的⼀个xml⽂档, 通过该⽂档可以对索引进⾏维护。
搜索流程 Solr客户端(浏览器、java程序)可以向solr服务器发送get请求,solr服务器返回⼀个xml⽂档。
⼆:Solrhome和SoleCore SolreHome是solr服务运⾏的主⽬录,⼀个solrhome⽬录⾥⾯包含多个SoleCore。
⼀个SolrCore包含⼀个Solr实例运⾏时所需的配置⽂件和数据⽂件。
Solrcore可以单独对外搜索和索引提供服务,彼此间没有半⽑钱的关系。
Home和core的关系好⽐,数据库连接和数据库的关系,⾃⼰体会。
对solr有个⼤致的认识后我们就要开始安装了~~ 准备⼯具: 1. solr 2. IK Analyzer中⽂分词器 3. ⼀个⼲净的tomcat 安装步骤: 1. 安装solr 2.配置中⽂分词安装步骤: 1.1 解压安装⽂件 1.2 复制solr.war到tomcat的webapps下;然后解压为solr⽂件夹,并删除该solr.war⽂件。
1.3 把solr的lib⽂件夹中的5个扩展包复制到tomcat的lib⽂件夹⾥⾯ 1.4 在tomcat⽂件夹下⾯创建mysolrhome⽂件夹,并且将solr-4.10-3中的solrhome⽂件全部复制过来。
1.5 指定solrhome的路径。
1.6 启动tomcat 输⼊ localhost:8080/solr 能看到solr⾸页就说明已经配置成功了。
ES分词器详解⼀、分词器1、作⽤:①切词 ②normalizaton(提升recall召回率:能搜索到的结果的⽐率)2、分析器①character filter:分词之前预处理(过滤⽆⽤字符、标签等,转换⼀些&=>and 《Elasticsearch》=> Elasticsearch A、HTML Strip Character Filter:html_strip escaped_tags 需要保留的html标签PUT my_index{"settings": {"analysis": {"char_filter": {"my_char_filter":{"type":"html_strip", "escaped_tags":["a"]}},"analyzer": {"my_analyzer":{"tokenizer":"keyword","char_filter":"my_char_filter"}}}}}测试分词 GET my_index/_analyze { "analyzer": "my_analyzer", "text": "liuyucheng <a><b>edu</b></a>" } B、Mapping Character Filter:type mappingPUT my_index{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "keyword","char_filter": ["my_char_filter"]}},"char_filter": {"my_char_filter": {"type": "mapping","mappings": ["٠ => 0","١ => 1","٢ => 2","٣ => 3","٤ => 4","٥ => 5","٦ => 6","٧ => 7","٨ => 8","٩ => 9"]}}}}测试分词POST my_index/_analyze{"analyzer": "my_analyzer","text": "My license plate is ٢٥٠١٥"} C、Pattern Replace Character Filter:正则替换type pattern_replace PUT my_index{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "standard","char_filter": ["my_char_filter"]}},"char_filter": {"my_char_filter": {"type": "pattern_replace","pattern": "(\\d+)-(?=\\d)","replacement": "$1_"}}}}}测试分词POST my_index/_analyze{"analyzer": "my_analyzer","text": "My credit card is 123-456-789"}②tokenizer:分词器③token filter:时态转换、⼤⼩写转换、同义词转换、语⽓词处理等 ⽐如:has=>have him=>he apples=>apple the/oh/a=>⼲掉 A、⼤⼩写 lowercase token filterGET _analyze{"tokenizer" : "standard","filter" : ["lowercase"],"text" : "THE Quick FoX JUMPs"}GET /_analyze{"tokenizer": "standard","filter": [{"type": "condition","filter": [ "lowercase" ],"script": {"source": "token.getTerm().length() < 5"}}],"text": "THE QUICK BROWN FOX"} B、停⽤词 stopwords token filterPUT /my_index{"settings": {"analysis": {"analyzer": {"my_analyzer":{"type":"standard","stopwords":"_english_"}}}}}GET my_index/_analyze"analyzer": "my_analyzer","text": "Teacher Ma is in the restroom"} C、分词器 tokenizer :standardGET /my_index/_analyze{"text": "江⼭如此多娇,⼩姐姐哪⾥可以撩","analyzer": "standard"} D、⾃定义 analysis,设置type为custom告诉Elasticsearch我们正在定义⼀个定制分析器。
IKAnalyzer中文分词器V3.2使用手册目录1.IK Analyzer3.X介绍 (2)2.使用指南 (5)3.词表扩展 (12)4.针对solr的分词器应用扩展 (14)5.关于作者 (16)1.IK Analyzer3.X介绍IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。
从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。
最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。
新版本的IK Analyzer3.X则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
1.1IK Analyzer3.X结构设计1.2IK Analyzer3.X特性�采用了特有的“正向迭代最细粒度切分算法“,具有80万字/秒的高速处理能力。
�采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
�优化的词典存储,更小的内存占用。
支持用户词典扩展定义�针对Lucene全文检索优化的查询分析器IKQueryParser(作者吐血推荐);采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。
1.3分词效果示例文本原文1:IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。
从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。
分词结果:ikanalyzer|是|一个|一|个|开源|的|基于|java|语言|开发|的|轻量级|量级|的|中文|分词|工具包|工具|从|2006|年|12|月|推出|1.0 |版|开始|ikanalyzer|已经|推出|出了|3|个大|个|版本文本原文2:永和服装饰品有限公司分词结果:永和|和服|服装|装饰品|装饰|饰品|有限|公司文本原文3:作者博客:电子邮件:linliangyi2005@分词结果:作者|博客||linliangyi|2007|javaeye|com|电子邮件|邮件地址|linliangyi2005@|linliangyi|2005|gmail|com2.使用指南2.1下载地址GoogleCode开源项目:/p/ik-analyzer/GoogleCode SVN下载:/svn/trunk/2.2与相关项目的版本兼容IK分词器版本L ucene版本S olr版本3.1.5GA兼容2.9.1及先前版本对solr1.3提供接口实现(详细请参考对应版本使用手册)3.1.6GA兼容2.9.1及先前版本对solr1.3、solr1.4提供接口实现(详细请参考对应版本使用手册)3.2.0GA兼容Lucene2.9及3.0版本不支持Lucene2.4及先前版本仅对solr1.4提供接口实现(请参考本手册solr部分说明)2.3安装部署IK Analyzer安装包包含:1.《IKAnalyzer中文分词器V3.X使用手册》(即本文档)2.IKAnalyzer3.X.jar(主jar包)3.IKAnalyzer.cfg.xml(分词器扩展配置文件)4.ext_stopword.dic(扩展的stopword词典,3.2以上版本提供)它的安装部署十分简单,将IKAnalyzer3.X.jar部署于项目的lib目录中;IKAnalyzer.cfg.xml 与ext_stopword.dic文件放置在代码根目录(对于web项目,通常是WEB-INF/classes 目录,同hibernate、log4j等配置文件相同)下即可。
2.4Lucene用户快速入门代码样例IKAnalyzerDemo执行结果:命中:12.5关键API 说明类org.wltea.analyzer.lucene org.wltea.analyzer.lucene..IKAnalyzer 说明:IK 分词器的主类,是IK 分词器的Lucene Analyzer 类实现。
该类使用方法请参考“代码样例”章节�public IKAnalyzer()说明:构造函数,默认实现最细粒度切分算法�public IKAnalyzer(boolean isMaxWordLength)说明:新构造函数,从版本V3.1.1起参数1:boolean isMaxWordLength ,当为true 时,分词器进行最大词长切分;当为false 时,分词器进行最细粒度切分。
类org.wltea.analyzer.lucene org.wltea.analyzer.lucene..IKQueryParser �public static void setMaxWordLength(boolean isMaxWordLength)说明:设置QueryParser 的解释时,分词器的切词方式,从版本V3.2.3起参数1:boolean isMaxWordLength ,是否采用最大词长分词;true 采用最大词长分词;false 不采用。
返回值:无内容:Document<stored/uncompressed,indexed,tokenized<text:IK Analyzer 是一个结合词典分词和文法分词的中文分词开源工具包。
它使用了全新的正向迭代最细粒度切分算法。
>>�public static Query parse(String field,String query)throws IOException 说明:单条件,单Field查询分析参数1:String field,查询的目标域名称参数2:String query,查询的关键字返回值:构造一个单条件,单Field查询器�public static Query parseMultiField(String[]fields,String query)throws IOException说明:多Field,单条件查询分析参数1:String[]fields,多个查询的目标域名称的数组参数2:String query,查询的关键字返回值:构造一个多Field,单条件的查询器�public static Query parseMultiField(String[]fields,String query, BooleanClause.Occur[]flags)throws IOException说明:多Field,单条件,多Occur查询分析参数1:String[]fields,多个查询的目标域名称的数组参数2:String query,查询的关键字参数3:BooleanClause.Occur[]flags,查询条件的组合方式(Or/And)返回值:构造一个多Field,单条件,多Occur的查询器�public static Query parseMultiField(String[]fields,String[]queries)throws IOException说明:多Field,多条件查询分析参数1:String[]fields,多个查询的目标域名称的数组参数2:String[]queries,对应多个查询域的关键字数组返回值:构造一个多Field,多条件的查询器�public static Query parseMultiField(String[]fields,String[]queries, BooleanClause.Occur[]flags)throws IOException说明:多Field,多条件,多Occur查询参数1:String[]fields,多个查询的目标域名称的数组参数2:String[]queries,对应多个查询域的关键字数组参数3:BooleanClause.Occur[]flags,查询条件的组合方式(Or/And)返回值:构造一个多Field,多条件,多Occur的查询器org.wltea.analyzer.lucene..IKSimilarity类org.wltea.analyzer.lucene说明:IKAnalyzer的相似度评估器。
该类重载了DefaultSimilarity的coord方法,提高词元命中个数在相似度比较中的权重影响,即,当有多个词元得到匹配时,文档的相似度将提高。
该类使用方法请参考“代码样例”章节org.wltea.analyzer..IKSegmentation类org.wltea.analyzer说明:这是IK分词器的核心类。
它是真正意义上的分词器实现。
IKAnalyzer的3.0版本有别于之前的版本,它是一个可以独立于Lucene的Java分词器实现。
当您需要在Lucene以外的环境中单独使用IK中文分词组件时,IKSegmentation正是您要找的。
�public IKSegmentation(Reader input)说明:IK主分词器构造函数,默认实现最细粒度切分参数1:Reader input,字符输入读取�public IKSegmentation(Reader input,boolean isMaxWordLength)说明:IK主分词器新构造函数,从版本V3.1.1起参数1:Reader input,字符输入读取参数2:boolean isMaxWordLength,当为true时,分词器进行最大词长切分;当为false时,分词器进行最细粒度切分。
�public Lexeme next()throws IOException说明:读取分词器切分出的下一个语义单元,如果返回null,表示分词器已经结束。
返回值:Lexeme语义单元对象,即相当于Lucene的词元对象Tokenorg.wltea.analyzer..Lexeme类org.wltea.analyzer说明:这是IK分词器的语义单元对象,相当于Lucene中的Token词元对象。
由于3.0版本被设计为独立于Lucene的Java分词器实现,因此它需要Lexeme来代表分词的结果。
�public int getBeginPosition()说明:获取语义单元的起始字符在文本中的位置返回值:int,语义单元相对于文本的绝对起始位置�public int getEndPosition()说明:获取语义单元的结束字符的下一个位置返回值:int,语义单元相对于文本的绝对终止位置的下一个字符位置�public int getLength()说明:获取语义单元包含字符串的长度返回值:int,语义单元长度=getEndPosition–getBeginPosition �public String getLexemeText()说明:获取语义单元包含字符串内容返回值:String,语义单元的实际内容,即分词的结果3.词表扩展目前,IK分词器自带的主词典拥有27万左右的汉语单词量。