潘省初计量经济学——第七章
- 格式:ppt
- 大小:861.00 KB
- 文档页数:61

练习题7.1参考解答(1)先用第一个模型回归,结果如下:22216.4269 1.008106 t=(-6.619723) (67.0592)R 0.996455 R 0.996233 DW=1.366654 F=4496.936PCE PDI =-+==利用第二个模型进行回归,结果如下:122233.27360.9823820.037158 t=(-5.120436) (6.970817) (0.257997)R 0.996542 R 0.996048 DW=1.570195 F=2017.064t t t PCE PDI PCE -=-++==(2)从模型一得到MPC=1.;从模型二得到,短期MPC=0.,长期MPC= 0.+(0.)=1.01954练习题7.2参考答案(1)在局部调整假定下,先估计如下形式的一阶自回归模型:*1*1*0*tt ttu Y X Y +++=-ββα估计结果如下:122ˆ15.104030.6292730.271676 se=(4.72945) (0.097819) (0.114858)t= (-3.193613) (6.433031) (2.365315)R =0.987125 R =0.985695 F=690.0561 DW=1.518595t t t Y X Y -=-++根据局部调整模型的参数关系,有****11 ttu u αδαβδββδδ===-=将上述估计结果代入得到: *1110.2716760.728324δβ=-=-=*20.738064ααδ==-*0.864001ββδ==故局部调整模型估计结果为: *ˆ20.7380640.864001ttYX =-+ 经济意义解释:该地区销售额每增加1亿元,未来预期最佳新增固定资产投资为0.亿元。
运用德宾h 检验一阶自相关:(121(1 1.34022d h =-=-⨯=在显著性水平05.0=α上,查标准正态分布表得临界值21.96h α=,由于21.3402 1.96h h α=<=,则接收原假设0=ρ,说明自回归模型不存在一阶自相关。
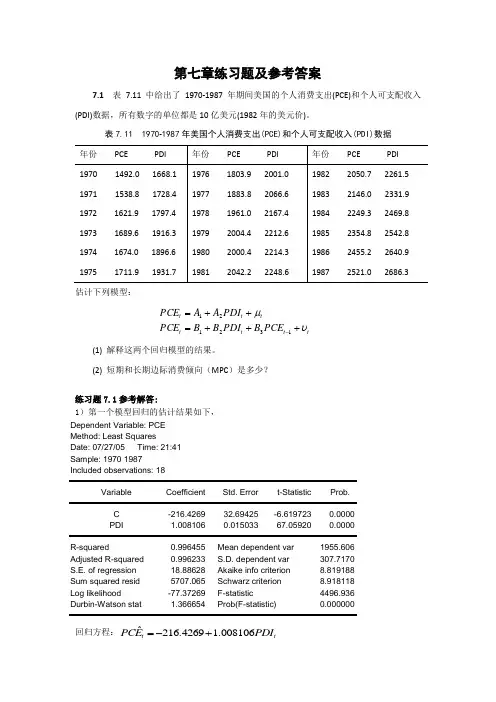
第七章练习题及参考答案7.1 表7.11中给出了1970-1987年期间美国的个人消费支出(PCE)和个人可支配收入(PDI)数据,所有数字的单位都是10亿美元(1982年的美元价)。
表7.11 1970-1987年美国个人消费支出(PCE)和个人可支配收入(PDI)数据估计下列模型:tt t t tt t PCE B PDI B B PCE PDI A A PCE υμ+++=++=-132121(1) 解释这两个回归模型的结果。
(2) 短期和长期边际消费倾向(MPC )是多少?练习题7.1参考解答:1)第一个模型回归的估计结果如下,Dependent Variable: PCEMethod: Least Squares Date: 07/27/05 Time: 21:41 Sample: 1970 1987 Included observations: 18Variable Coefficient Std. Error t-StatisticProb. C -216.4269 32.69425 -6.619723 0.0000 PDI 1.008106 0.015033 67.05920 0.0000 R-squared 0.996455 Mean dependent var1955.606 Adjusted R-squared 0.996233 S.D. dependent var 307.7170 S.E. of regression 18.88628 Akaike info criterion 8.819188 Sum squared resid 5707.065 Schwarz criterion 8.918118 Log likelihood -77.37269 F-statistic 4496.936 Durbin-Watson stat 1.366654 Prob(F-statistic)0.000000回归方程:ˆ216.4269 1.008106t tPCE PDI =-+(32.69425) (0.015033) t =(-6.619723) (67.05920) 2R =0.996455 F=4496.936 第二个模型回归的估计结果如下,Dependent Variable: PCEMethod: Least Squares Date: 07/27/05 Time: 21:51 Sample (adjusted): 1971 1987 Included observations: 17 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.C -233.2736 45.55736 -5.120436 0.0002 PDI 0.982382 0.140928 6.970817 0.0000 PCE(-1) 0.037158 0.144026 0.2579970.8002R-squared 0.996542 Mean dependent var 1982.876 Adjusted R-squared 0.996048 S.D. dependent var 293.9125 S.E. of regression 18.47783 Akaike info criterion 8.829805 Sum squared resid 4780.022 Schwarz criterion 8.976843 Log likelihood -72.05335 F-statistic 2017.064 Durbin-Watson stat 1.570195 Prob(F-statistic)0.000000回归方程:1ˆ233.27360.98240.0372t t t PCE PDI PCE -=-+- (45.557) (0.1409) (0.1440)t = (-5.120) (6.9708) (0.258) 2R =0.9965 F=2017.0642)从模型一得到MPC=1.008;从模型二得到,短期MPC=0.9824,由于模型二为自回归模型,要先转换为分布滞后模型才能得到长期边际消费倾向,我们可以从库伊克变换倒推得到长期MPC=0.9824/(1+0.0372)=0.9472。

![[经管营销]计量经济学第七章](https://uimg.taocdn.com/950e4ff243323968001c92b9.webp)

计量经济学中级教程习题参考答案第一章 绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据(4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3 时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YYn==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 经典线性回归模型2.1 判断题(说明对错;如果错误,则予以更正) (1)对 (2)对 (3)错只要线性回归模型满足假设条件(1)~(4),OLS 估计量就是BLUE 。
(4)错R 2 =ESS/TSS 。
(5)错。
我们可以说的是,手头的数据不允许我们拒绝原假设。
(6)错。
因为∑=22)ˆ(tx Var σβ,只有当∑2t x 保持恒定时,上述说法才正确。
2.2 应采用(1),因为由(2)和(3)的回归结果可知,除X 1外,其余解释变量的系数均不显著。

计量经济学中级教程习题参考答案第一章 绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据(4)估计参数 (5)假设检验 (6)预测和政策分析1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3 时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1n ii Y Y n ==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.1074130********=+++。
第二章 经典线性回归模型2.1 判断题(说明对错;如果错误,则予以更正)(1)对(2)对(3)错只要线性回归模型满足假设条件(1)~(4),OLS 估计量就是BLUE 。
(4)错。


潘省初计量经济学中级教程习题参考答案计量经济学中级教程习题参考答案第一章绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说)(2)建立计量经济模型(3)收集数据(4)估计参数(5)假设检验(6)预测和政策分析1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3 时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1n ii Y Y n ==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 经典线性回归模型2.1 判断题(说明对错;如果错误,则予以更正)(1)对(2)对(3)错只要线性回归模型满足假设条件(1)~(4),OLS 估计量就是BLUE 。
(4)错R 2 =ESS/TSS 。
(5)错。
我们可以说的是,手头的数据不允许我们拒绝原假设。
(6)错。
因为∑=22)ˆ(t x Var σβ,只有当∑2t x 保持恒定时,上述说法才正确。
2.2 应采用(1),因为由(2)和(3)的回归结果可知,除X 1外,其余解释变量的系数均不显著。

《计量经济学》课程实验指导书目录实验一计量经济学古典线性回归模型实验 (1)实验二计量经济学异方差模型实验 (12)实验三计量经济学自相关模型实验 (19)实验四计量经济学多重共线性模型实验 (24)实验五计量经济学虚拟变量模型和滞后变量模型实验 (30)实验六计量经济学单方程模型综合性实验 (38)实验七计量经济学联立方程模型综合性实验 (59)主要参考书1.潘省初著《计量经济学》:中国人民大学出版社,2002年,第1版。
2.袁建文编著《计量经济学实验》:科学出版社,2002年,第1版。
实验一、计量经济学古典线性回归模型实验一、实验目的与要求:使学生掌握古典线性回归模型的设定、估计、检验、预测方法以及至少掌握一种计量经济学软件的使用,提高学生应用计量经济学古典线性回归模型方法解决实际问题的实践动手能力。
要求学生能对简单的实际经济问题正确地选择古典线性回归模型的理论形式,能使用计量经济学软件包Eviews估计模型参数,能进行经济意义、拟合优度、参数显著性和方程显著性等检验,能进行模型经济意义分析以及预测因变量值。
二、实验内容与步骤:1.选择简单的实际经济问题学生从本实验指导书提供的参考选题中或从其它途径选择合适的实际经济问题。
2.古典线性回归模型的理论形式设定学生针对所选的实际经济问题,依据有关的经济理论设定恰当的古典线性回归模型的理论形式。
3.经济意义和统计检验学生应用计量经济学软件包Eviews对已设定的古典线性回归模型进行初步估计并进行经济意义和统计检验。
4.模型经济意义分析及预测因变量值三、实验例题:美国1980-1995年未偿付抵押贷款债务下表提供了以下数据,非农业未偿付抵押贷款(Y,亿美元),个人收入(X2,亿美元),新住宅抵押试建立美国非农业未偿付抵押贷款古典线性回归模型,若1997年个人收入为6543亿美元,新住宅抵押贷款费用为8%,试预测1997年未偿付抵押贷款额(亿美元)。
实验步骤及内容如下:1.古典线性回归模型的理论形式设定以非农业未偿付抵押贷款(Y)作为被解释变量,个人收入(X 2)及未偿付抵押贷款(X 3)作为解释变量。

第7章 双变量模型:假设检验7.1 古典线性回归模型基本假定:A7.1 解释变量(X )与扰动项不相关 如果X 是确定性变量,该假定自然成立。
A7.2 扰动项的期望或均值为零。
即E(u i )=0 (7-1) A7.3 同方差假定,即Var(u i )为常数 (7-2) A7.4 无自相关假定,即随机扰动项之间是互不相关的。
即COV(u i ,u j )=0 当i ≠j 时 (7-3)7.2 普通最小二乘估计量的方差和标准差7.2.1 widget 一例中的方差和标准差及需求函数小结 Widget 的需求函数如下:())1203.0(7464.0ˆ=-=se 2.1576X 49.6670Y i i具体计算可用软件演示。
7.3 普通最小二乘估计量的性质OLS 估计量是最优线性无偏估计量。
b 1和b 2满足: (1)线性:即b 1和b 2是随机变量Y 的线性函数。
(2)无偏性,即()()()σσ22211ˆ===E B b E B b E 2 (3)最小方差性,即b 1的方差小与其他任何一个B 1的无偏估计量的方差 b 2的方差小与其他任何一个B 2的无偏估计量的方差蒙特卡洛试验,假定已知如下信息:i i i i i u 2.0X 1.5u X B B Y ++=++=21u i 服从N(0,4)分布。
假定X 有10个观察值:1,2,3,4,5,7,7,8,9,10。
试验及试验结果见 表7-2 蒙特卡洛试验 (书104页)7.4 OLS 估计量的抽样分布或概率分布为了求得OLS 估计量b 1和b 2的抽样分布,我们需要在增加一条假定,即:A7.5 在总体回归函数 i i i u X B B Y ++=21中,误差项u i 服从均值为零,方差为σ2的正态分布,即2(0,)iu N σ (7-17) 正态变量b 1和b 2的均值和方差为:;)var(;)var(),(~);,(~2222222122222112121∑∑∑==⋅==i b iib b b x b xn X b B N b B N b σσσσσσ (7-19)图 7-4 估计量分布的几何图形见书P107。
计量经济学中级教程习题参考答案第一章 绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据(4)估计参数 (5)假设检验 (6)预测和政策分析1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3 时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1n ii Y Y n ==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.1074130********=+++。
第二章 经典线性回归模型2.1 判断题(说明对错;如果错误,则予以更正)(1)对(2)对(3)错只要线性回归模型满足假设条件(1)~(4),OLS 估计量就是BLUE 。
(4)错R 2 =ESS/TSS 。
(5)错。
我们可以说的是,手头的数据不允许我们拒绝原假设。
(6)错。
因为∑=22)ˆ(t x Var σβ,只有当∑2t x 保持恒定时,上述说法才正确。
2.2 应采用(1),因为由(2)和(3)的回归结果可知,除X 1外,其余解释变量的系数均不显著。