对应分析
- 格式:doc
- 大小:79.00 KB
- 文档页数:11

对应分析数据一、背景介绍在当今信息爆炸的时代,大量的数据被生成和收集,为了更好地理解和利用这些数据,对数据进行对应分析是非常重要的。
对应分析是一种统计方法,用于研究两组数据之间的关系和相互作用。
通过对数据进行对应分析,我们可以发现数据中的模式、趋势和相关性,从而为决策提供有价值的信息。
二、对应分析的定义和原理对应分析(Correspondence Analysis,简称CA)是一种多变量数据分析方法,它通过将高维数据映射到低维空间中,从而揭示数据之间的关系。
对应分析的原理基于数学上的奇异值分解(Singular Value Decomposition,简称SVD)和特征值分解(Eigenvalue Decomposition),通过计算数据矩阵的特征值和特征向量,将数据在低维空间中进行降维和可视化。
三、对应分析的步骤和方法1. 数据预处理:对数据进行清洗和标准化,去除异常值和缺失值,并将数据转换为适合对应分析的格式。
2. 计算数据矩阵:根据数据的特点,构建数据矩阵,其中行表示样本或观测对象,列表示变量或属性。
3. 计算对应分析的结果:通过对数据矩阵进行奇异值分解或特征值分解,得到对应分析的结果,包括特征值、特征向量和对应坐标。
4. 解释和解读结果:根据对应分析的结果,进行可视化和解释,发现数据中的模式、趋势和相关性,并提取有用的信息。
5. 结果验证和应用:对对应分析的结果进行验证和应用,评估模型的准确性和可靠性,并将结果应用于实际问题的决策和优化。
四、对应分析的应用领域对应分析广泛应用于各个领域,包括市场调研、消费者行为、社会科学、生物学、医学等。
以下是对应分析在几个典型领域的应用示例:1. 市场调研:通过对应分析,可以分析不同产品或品牌在市场中的位置和竞争关系,帮助企业制定市场策略和推广计划。
2. 消费者行为:对应分析可以帮助分析消费者对不同产品或服务的偏好和关联性,为企业提供精准的市场定位和产品定价策略。




对应分析数据一、概述对应分析数据是一种数据分析方法,用于研究两个或者多个变量之间的关系。
通过对数据进行对应分析,可以揭示变量之间的相关性,并匡助我们理解数据暗地里的模式和趋势。
本文将介绍对应分析数据的基本概念、步骤和应用场景。
二、基本概念1. 对应分析对应分析是一种多元数据分析方法,它通过将多个变量映射到一个低维空间中,从而揭示变量之间的关系。
对应分析可以匡助我们发现数据中的结构和模式,进而进行更深入的分析。
2. 对应图对应图是对应分析结果的可视化表示。
对应图通常是一个二维平面图,其中每一个数据点表示一个观测值,不同的颜色或者符号表示不同的组别或者类别。
通过观察对应图,我们可以看到数据点之间的关系和趋势。
三、步骤对应分析数据的步骤如下:1. 数据准备首先,需要准备要进行对应分析的数据。
数据可以是任何类型的,可以是定量数据(如数值)或者定性数据(如类别)。
确保数据的质量和完整性非常重要。
2. 数据标准化对应分析需要对数据进行标准化,以消除不同变量之间的量纲差异。
常用的标准化方法包括Z-score标准化和归一化等。
3. 计算对应分析利用对应分析的算法,对标准化后的数据进行计算,得到对应分析的结果。
对应分析的算法有多种,常用的包括主成份分析(PCA)和多维尺度分析(MDS)等。
4. 绘制对应图将对应分析的结果绘制成对应图,以便更直观地观察数据之间的关系和趋势。
对应图可以通过各种数据可视化工具来实现,如散点图、气泡图等。
5. 解读对应图通过观察对应图,我们可以解读数据之间的关系和趋势。
可以观察数据点的分布情况、类别之间的距离和相对位置等。
根据对应图的结果,可以进一步进行数据分析和决策。
四、应用场景对应分析数据在各个领域都有广泛的应用,以下列举几个常见的应用场景:1. 市场调研对应分析数据可以匡助市场调研人员了解不同产品或者品牌之间的关系和竞争状况。
通过对应分析,可以发现市场中的潜在细分市场和目标客户群体。

对应分析原理
对应分析原理是一种用来确定两个或多个事物之间的对应关系的方法。
它主要包括以下几个步骤:
1. 收集相关数据:首先,需要收集与待分析事物相关的数据。
这些数据可以是各种类型的,比如数字、文字、图像等。
2. 建立对应关系:在收集到足够的数据之后,需要根据数据的特征建立对应关系。
对应关系可以是一对一的,也可以是一对多的。
3. 分析数据特征:根据建立的对应关系,可以对数据的特征进行分析。
可以使用统计学方法、机器学习算法等来识别数据的模式和规律。
4. 验证对应关系:在分析数据特征之后,需要对建立的对应关系进行验证。
可以使用交叉验证、模型评估等方法来验证对应关系的准确性和可靠性。
5. 应用对应关系:最后,根据对应分析的结果,可以应用对应关系来解决实际问题。
比如,可以根据对应关系预测未知数据的属性或进行分类。
通过对应分析原理,我们可以更好地理解不同事物之间的对应关系,从而为实际问题提供科学的解决方案。
无论是在科学研究、工程设计还是商业决策中,对应分析都具有重要的应用价值。

对应分析法一、简介对应分析(Correspondence analysis)也称关联分析、R-Q型因子分析,是近年新发展起来的一种多元相依变量统计分析技术,是一种多元统计分析技术,主要分析定性数据的方法,也是强有力的数据图示化技术。
对应分析是一种数据分析技术,它能够帮助我们研究由定性变量构成的交互汇总表来揭示变量间的联系。
交互表的信息以图形的方式展示。
主要适用于有多个类别的定类变量,可以揭示同一个变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系,适用于两个或多个定类变量。
对应分析是由法国人Benzenci于1970年提出的,起初在法国和日本最为流行,然后引入到美国。
对应分析法是在R型和Q型因子分析的基础上发展起来的一种多元统计分析方法,因此对应分析又称为R-Q型因子分析。
在因子分析中,如果研究的对象是样品,则需采用Q型因子分析;如果研究的对象是变量,则需采用R型因子分析。
但是,这两种分析方法往往是相互对立的,必须分别对样品和变量进行处理。
因此,因子分析对于分析样品的属性和样品之间的内在联系,就比较困难,因为样品的属性是变值,而样品却是固定的。
于是就产生了对应分析法。
对应分析就克服了上述缺点,它综合了R型和Q型因子分析的优点,并将它们统一起来使得由R型的分析结果很容易得到Q型的分析结果,这就克服了Q 型分析计算量大的困难;更重要的是可以把变量和样品的载荷反映在相同的公因子轴上,这样就把变量和样品联系起来便于解释和推断。
对应分析数据的典型格式是列联表或交叉频数表。
常表示不同背景的消费者对若干产品或产品的属性的选择频率。
背景变量或属性变量可以并列使用或单独使用。
两个变量间——简单对应分析;多个变量间——多元对应分析。
对应分析的基本思想是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。
它最大特点是能把众多的样品和众多的变量同时作到同一张图解上,将样品的大类及其属性在图上直观而又明了地表示出来,具有直观性。
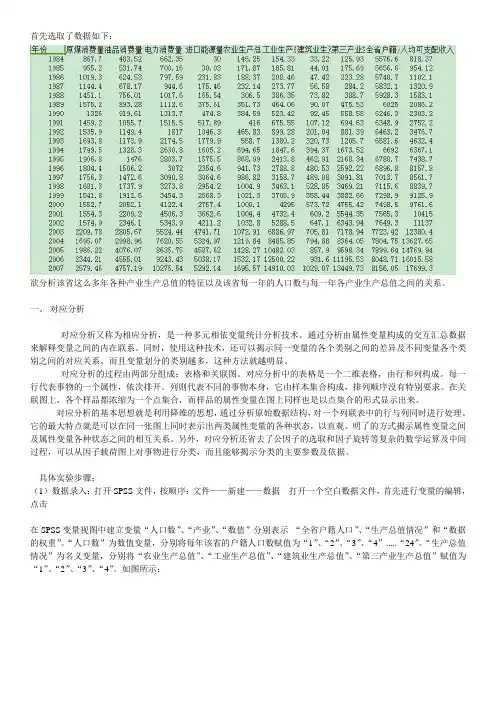
首先选取了数据如下:欲分析该省这么多年各种产业生产总值的特征以及该省每一年的人口数与每一年各产业生产总值之间的关系。
一、对应分析对应分析又称为相应分析,是一种多元相依变量统计分析技术。
通过分析由属性变量构成的交互汇总数据来解释变量之间的内在联系。
同时,使用这种技术,还可以揭示同一变量的各个类别之间的差异及不同变量各个类别之间的对应关系。
而且变量划分的类别越多,这种方法就越明显。
对应分析的过程由两部分组成:表格和关联图。
对应分析中的表格是一个二维表格,由行和列构成。
每一行代表事物的一个属性,依次排开。
列则代表不同的事物本身,它由样本集合构成,排列顺序没有特别要求。
在关联图上,各个样品都浓缩为一个点集合,而样品的属性变量在图上同样也是以点集合的形式显示出来。
对应分析的基本思想就是利用降维的思想,通过分析原始数据结构,对一个列联表中的行与列同时进行处理。
它的最大特点就是可以在同一张图上同时表示出两类属性变量的各种状态,以直观、明了的方式揭示属性变量之间及属性变量各种状态之间的相互关系。
另外,对应分析还省去了公因子的选取和因子旋转等复杂的数学运算及中间过程,可以从因子载荷图上对事物进行分类,而且能够揭示分类的主要参数及依据。
具体实验步骤:(1)数据录入:打开SPSS文件,按顺序:文件——新建——数据打开一个空白数据文件,首先进行变量的编辑,点击在SPSS变量视图中建立变量“人口数”、“产业”、“数值”分别表示“全省户籍人口”、“生产总值情况”和“数据的权重”。
“人口数”为数值变量,分别将每年该省的户籍人口数赋值为“1”、“2”、“3”、“4”.....“24”。
“生产总值情况”为名义变量,分别将“农业生产总值”、“工业生产总值”、“建筑业生产总值”、“第三产业生产总值”赋值为“1”、“2”、“3”、“4”。
如图所示:在SPSS活动数据文件的数据视图中,把相关数据输入到各个变量中。
(2)打开数据文件,进入SPSS Statistics 数据编辑器窗口,在菜单栏中选择“数据——加权个案”命令,将变量“数值”选入加权个案,单击“确定”按钮。



对应分析对应分析的基本思想对应分析(Correspondence Analysis)又称为相应分析,是由法国统计学家于1970提出的,是在R型和Q型因子分析基础上,发展起来的一种多元相依的变量统计分析技术。
它通过分析由定性变量构成的交互汇总表来揭示变量间的关系。
当以变量的一系列类别以及这些类别的分布图来描述变量之间的联系时,使用这一分析技术可以揭示同一变量的各个类别之间的差异以及不同变量各个类别之间的对应关系。
汇总表中分值,1(点))2.主成分(principal components):通过主成分分析,可以在以两个主成分为坐标的空间中,标出行轮廓或列轮廓,或同时标出行、列轮廓,从而探索它们之间的关系。
这种近似的表示行轮廓和列轮廓的图形叫对应图。
3.惯量(inertials)和特征值(eigenvalues):惯量是度量行轮廓和列轮廓的变差的统计量。
总惯量表示轮廓点的全部变差,作图用的前两个维度分别对应于两个主惯量(principal inertias),表示在坐标方向上的变差;主惯量就是对行轮廓和列轮廓作主成分分析时得到的特征值,特征值的平方根叫奇异值(singular values)。
4.卡方(Chi-square)、似然比卡方(likelihood ratio Chi-square)、曼图—汉斯泽鲁卡方(Mantel-Haenszel Chi-square)、法系数(phi-coefficient)、列联系数(contingency coefficient),这些均是检验对应分析显着性或近似效果的统计量。
实例分析[例11-1]某公司进行一次市场调查,得到轿车特征与一些用户特征的数据。
如有:轿车大小(大、中、小)、轿车类型(家用型、跑车、商用车)、收入(一份收入、双份收入)、状态(已婚、已婚有孩子、未婚、未婚有孩子)、房子(租房、买房)等数据。
现请分析它们之间的联系。
以下是spss11.0作出的对应图:从对应图可以推断出下面一些结论:1.已婚有孩子、家用车和中型车相关性较大。
对应分析
对应分析适用于:两个大类(可以看做一个行和一个列)中每个大类的细分指标的相关关系研究。
例如有A和B两大类,A中有A1-A5五个类型,B中有B1-B5五个类型。
研究这些细分类型的相关关系。
首先做卡方检验(行列相关性分析,当P<0.05时,说明行和列中的指标有相关性),然后进行对应分析。
一、进行卡方检验,检验分组之间的相关性。
通过卡方检验,P<0.05。
说明这两组数据间有相关性。
二、对应分析
有两组变量,分别设为行和列;再定义范围,每组有几个小变量就是它的范围。
三、对应分析的卡方检验
通过卡方检验,P<0.05。
说明这两组数据间有相关性
四、分析图
五、结论
1、靠近原点的没有意义。
2、在同一个象限的,趋势相同的,说明有相关性。
3、第四象限:眼深色比其他眼睛颜色而言,头发出现深色和黑色的比例高。
4、第三象限:头发金色比其他颜色而言,眼睛出现浅色和蓝色的比例高。
最优尺度分析
最优尺度分析是对应分析的升级版,适用于:多个大类(大于等与3个大类)中每个大类的细分指标的相关关系研究。
例如有A、B 和C三大类,A中有A1-A5五个类型,B中有B1-B5五个类型,C中有C1-C5五个类型,类型间的相互关系。
对应分析(Correspondence Analysis)在进行数据分析时,经常要研究两个定性变量(品质变量)之间的相关关系。
我们曾经介绍过使用列联表和卡方检验来检验两个品质变量之间相关性的方法,但是该方法存在一定的局限性。
卡方检验只能对两个变量之间是否存在相关性进行检验,而无法衡量两个品质型变量各水平之间的内在联系。
例如,汽车按产品类型可以分豪华型、商务型、节能型、耐用型,按销售区域可分为华北区、华南区、华中区、华东区、西南区、西北区、东北区。
利用卡方检验,只能检验销售地区与对型的偏好之间是否相关,但无法知道不同地区的消费者到底比较偏好哪种车型。
对应分析方法(Correspondence Analysis)又称相应分析、关联分析,是一种多元相依变量统计分析技术,是对两个定性变量(因素)的多种水平之间的对应性进行研究,通过分析由定性变量构成的交互汇总数据来解释变量之间的内在联系。
同时,使用这种分析技术还可以揭示同一变量的各个类别之间的差异以及不同变量各个类别之间的对应关系。
特别是当分类变量的层级数比较大时,对应分析可以将列联表中众多的行和列的关系在低维的空间中表示出来。
而且,变量划分的类别越多,这种方法的优势就越明显。
对应分析以两变量的交叉列联表为研究对象,利用“降维”的方法,通过图形的方式,直观揭示变量不同类别之间的联系,特别适合于多分类定性变量的研究。
对应分析的基本思想是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。
它最大特点是能把众多的样品和众多的变量同时作到同一张图上,将样品的大类及其属性在图上直观而又明了地表示出来,具有直观性。
另外,它还省去了因子选择和因子轴旋转等复杂的数学运算及中间过程,可以从因子载荷图上对样品进行直观的分类,而且能够指示分类的主要参数(主因子)以及分类的依据,是一种直观、简单、方便的多元统计方法。
该统计研究技术在市场细分、产品定位、品牌形象以及满意度研究等领域得到了广泛的运用。
对应分析对应分析是指在进行某种事物或情况时,通过对应关系的分析来进行推理、研究或解决问题的方法。
在不涉及AI和人工智能的情况下,对应分析可以应用于各种领域和问题,例如产品定位、市场调研、销售策略等等。
下面将简要介绍对应分析的相关概念和应用。
对应分析是一种基于对应关系的研究方法。
对应关系是指在两个事物、情况或变量之间存在一种相互联系或相互影响的关系。
通过对这种关系进行分析,可以揭示隐藏在数据背后的规律和趋势,帮助人们做出决策和解决问题。
在实际应用中,对应分析可以用于产品定位。
产品定位是指将一种产品或服务与目标市场中其他产品或服务区分开来,使其在市场中具有独特的竞争优势。
通过对目标市场中其他产品的特点和消费者需求进行对应分析,可以找到产品定位的破局点,从而设计出能够满足消费者需求并有竞争力的产品。
另外,对应分析也可以用于市场调研。
市场调研是指通过各种研究方法和技术,对市场中的消费者需求、竞争对手、市场环境等进行调查和分析,为企业的决策提供可靠的数据支持。
通过对消费者需求与产品特点、价格、品牌等进行对应分析,可以了解到消费者的购买动机和购买偏好,进而制定有针对性的市场策略。
此外,对应分析还可以应用于销售策略。
销售策略是指企业通过制定一系列销售计划和策略,以实现销售目标的过程。
通过对销售数据、市场需求和竞争对手等因素进行对应分析,可以找出市场中的机会和挑战,为销售策略的制定提供指导。
总而言之,对应分析是一种揭示数据背后规律和趋势的方法。
通过对数据和情况之间的对应关系进行分析,可以帮助人们做出决策和解决问题。
在产品定位、市场调研和销售策略等方面,对应分析都有重要的应用价值。
对应分析不仅能够帮助企业了解市场需求和消费者偏好,还可以为企业的决策提供科学依据。
实验五对应分析
姓名:***
学号:*********
班级:11级统计2班
对应分析
一实验目的:
(1)掌握对应分析方法在spss软件中的实现。
(2) 熟悉对应分析的用途及操作方法。
二准备知识:
对应分析(Correspondence analysis)也称关联分析、R-Q型因子分析,是近年新发展起来的一种多元相依变量统计分析技术,通过分析由定性变量构成的交互汇总表来揭示变量间的联系。
可以揭示同一变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。
是能把众多的样品和众多的变量同时作到同一张图解上,将样品的大类及其属性在图上直观而又明了地表示出来,具有直观性。
另外,它还省去了因子选择和因子轴旋转等复杂的数学运算及中间过程,可以从因子载荷图上对样品进行直观的分类,而且能够指示分类的主要参数(主因子)以及分类的依据,是一种直观、简单、方便的多元统计方法。
三实验思想:
是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。
首先编制两变量的交叉列联表,将交叉列联表中的每个数据单元看成两变量在相应类别上的对应点;然后,对应分析将变量及变量之间的联系同时反映在一张二维或三维的散点图;最后,通过观察对应分布图就能直接地把握变量之间的类别联系。
四实验内容:
五实验步骤:
(1)数据录入。
打开SPSS数据编辑器,建立“对应分析.sav”文件。
在变量视窗中录入3个变量,用A表示“地区”,用B表示“死因”,用C表示“频数”,对A 变量和B变量输入对应的标签和值,C变量输入对应的标签。
然后在数据视图中将数
据对应录入。
(2)进行对应分析。
依次点击“Data→Weight Cases →”再将“频数”导入“频率变量”,依次点击“analyze-data reduction→correspondence→将地区导入行→定义全距→最小值为1,最大值为12。
将死因导入列→定义全距→最小值为1,最大值为10,。
点击更新→点击继续”。
六实验结果:
对应表
对应表:是地区与死因的交叉列联表,表中的数据为相应的频数,有效边际是相应的合计数据。
可以看到,某省12个地区10种恶性肿瘤的死亡率的数据,可以看出八,十一地区的死亡率较高,而在所有地区中肠癌,肺癌的死亡率最高。
尽管通过对应表发现消地区与死因的某些联系,但没有揭示出具体的规律。
摘要表
若将“对应表”中的数据看为一个矩阵A ,则“摘要”中的惯量为AA ’的特征值i λ,奇异值为对应特征值开根所得的结果,“Inertia ”为惯量,是度量行列关系的强度。
惯量比例中的“解释”为各特征值所占特征值总和的百分比,即方差贡献率9
1
/
i i i
λλ=∑。
在“摘要”中,由对应分析的基本原理可知,提取的特征根个数为1},min{-c r ,这里,由于地区有12个水平(r =12),死因有10种(c=10),因此惯量,也即特征值。
其中第一个特征根的值最大,意味着它解释各别差异的能力最强,地位最重要,其他特征根的重要性依次下降,特征根的总和为0.272;第四、第五列是对交叉列联表作卡方检验的卡方观测值(308.376)和相应的小p 值(0.000),由于小p=0.000<0.05α=,因此拒绝原假设,认为行变量和列变量有显著的相关性关系;第六列是各个特征根的方差贡献率,第一个特征根的方差贡献率为0.425,方差贡献率是最高的;第七列是各特征根的累计方差贡献率,由于前两个特征根就已经解释了各类别差异的75.7%,因此最终提取2个因子是可行的,信息丢失少。
概述行点
概述行点:显示了行变量各分类降维的情况,表中的“Mass”表示行变量占各变量总和的百分比,“维中的得分”为各变量在各公共因子上的得分。
第二列是行变量各类别的百分比;第三、第四列是行变量各类别在第1、第2个因子上的因子载荷,它们将成为分布图中的数据点的坐标;第五列为各特征根;第六、第七列是行变量各分类对第1、第2个因子值差异的影响程度;五地区对第1个因子值的差异影响最大(21.5%),一地区对第2个因子值的差异影响最大(35.7%),第八、第九、第十列是第1、第2因子对行变量各分类差异的解释程度。
一地区对第1个因子解释了1.3%的差异,第2个因子解释了93.4%的差异,两因子共解释了94.7%的差异。
七地区的信息丢失较为严重。
概述列点
概述列点:显示了列变量各分类降维的情况,表中的“Mass”表示列变量占各变量总和的百分比,“维中的得分”为各变量在各公共因子上的得分。
第二列是列变量各类别的百分比;第三、第四列是列变量各类别在第1、第2个因子上的因子载荷,它们将成为分布图中的数据点的坐标;第五列为各特征根;第六、第七列是列变量各分类对第1、第2个因子值差异的影响程度;食道癌对第1个因子值的差异影响最大(63.7%),胃癌对第2个因子值的差异影响最大(69.6%),第八、第九、第十列是第1、第2因子对列变量各分类差异的解释程度。
食道癌对第1个因子解释了88.5%的差异,第2个因子解释了9.7%的差异,两因子共
解释了98.2%的差异。
鼻咽癌的信息丢失较为严重。
行和列点
对称的标准化
可以看出,一地区偏向于胃癌;二地区相对偏向于鼻咽癌;三地区偏向于白血病,宫颈癌;四地区地区偏向于鼻咽癌;五地区偏向于食道癌;六地区偏向于癌肠;七地区偏向于肝癌;八地区比较孤立,相对偏向于鼻咽癌;九地区偏向于白血病;十地区比较孤立,相对偏向于食道癌;十一地区偏向于肠癌,肝癌;十二地区偏向于肺癌,白血病。
最终我们可以看出各个地区对应的死因分别为:
一地区<——> 胃癌;
二地区<——> 鼻咽癌;
三地区<——> 白血病,宫颈癌;
四地区<——> 鼻咽癌;
五地区<——> 食道癌;
六地区<——> 癌肠;
七地区<——> 肝癌;
八地区<——> 鼻咽癌;
九地区<——> 白血病;
十地区<——> 食道癌;
十一地区<——> 肠癌,肝癌;
十二地区<——> 肺癌,白血病;
符号<——>表示这种关系是相互的。