药物基因组学相关数据库
- 格式:pdf
- 大小:1.40 MB
- 文档页数:8

生物信息学数据库分类整理汇总生物信息学数据库是存储和管理生物学领域的大量数据的重要工具和资源,对于生物信息学研究、基因组学、蛋白质组学、转录组学等领域的研究具有重要的意义。
本文将对生物信息学数据库进行分类整理和汇总,方便生物信息学研究者更好地使用和了解这些数据库。
1.基因组数据库:- GenBank:美国国家生物技术信息中心(NCBI)维护的基因序列数据库,包含已知基因的核酸序列。
- Ensembl:英国恩格斯尔基因组项目维护的一个综合性基因组数据库,包含多种物种的基因组数据。
- UCSC Genome Browser:加利福尼亚大学圣克鲁兹分校开发的一个基因组浏览器,提供多种物种的基因组序列和注释信息。
2.蛋白质数据库:- UniProt:一个综合性的蛋白质数据库,集成了多个蛋白质序列和注释信息资源。
- Protein Data Bank (PDB):存储大量已解析的蛋白质结构数据的数据库,提供原子级别的结构信息。
- Protein Information Resource (PIR):收集和整理蛋白质序列、结构和功能信息的数据库。
3.转录组数据库:- NCBI Gene Expression Omnibus (GEO):存储和共享大量的高通量基因表达数据的数据库。
- ArrayExpress:欧洲生物信息学研究所(EBI)开发的一个基因表达数据库,包含多种生物组织和疾病的表达数据。
4.疾病数据库:- Online Mendelian Inheritance in Man (OMIM):记录人类遗传疾病和相关基因的数据库。
- Orphanet:收集和整理罕见疾病和相关基因的数据库。
5.代谢组数据库:- Human Metabolome Database (HMDB):一个综合性的人类代谢物数据库,包括代谢产物的结构和功能信息。
- Kyoto Encyclopedia of Genes and Genomes (KEGG):包含多种生物体代谢途径的数据库。

KEGG数据库的使用方法与介绍KEGG(Kyoto Encyclopedia of Genes and Genomes)数据库是一个综合性的基因组学数据库,其中包含了丰富的生物信息学数据和工具,帮助研究人员进行基因、蛋白质、代谢物和药物的研究。
KEGG数据库的使用涉及到以下几个方面的内容:数据源、数据库结构、主要功能和应用、数据访问和使用方法,以及最新的更新和发展趋势。
一、数据源二、数据库结构三、主要功能和应用1.基因注释和功能预测2.代谢通路分析KEGG Pathway数据库是KEGG最重要的部分之一,收集了大量的代谢通路信息。
用户可以通过KEGG Pathway数据库了解代谢通路中的基因、蛋白质和化学反应等。
同时,KEGG Pathway还提供了绘制和分析代谢通路的工具,方便用户进行研究。
3.药物研究KEGG数据库中的KEGG Drug库提供了大量的关于药物的信息,包括化学结构、作用机制和药理学特性等。
研究人员可以通过KEGG Drug库了解药物的相关信息,如副作用、靶点和药物相互作用等,有助于药物研发和预测。
四、数据访问和使用方法1.网页界面:KEGG数据库提供了用户友好的网页界面,用户可以通过关键词、浏览分类目录或输入基因、化学物质等标识符来查询相关数据。
通过网页界面,用户可以直观地查看和分析数据,也可以进行一些简单的数据处理和交互。
2. 软件工具:KEGG数据库还提供了一些软件工具,如KAAS(KEGG Automatic Annotation Server)、KegArray、KegDraw等。
用户可以使用这些工具进行基因组注释、代谢通路分析、基因表达数据分析等。
五、最新的更新和发展趋势1. 数据整合:KEGG数据库正在与其他生物信息学数据库进行整合,如与UniProt、Ensembl等进行数据链接和互操作。
这将进一步丰富和提高KEGG数据库中的数据质量和相关性。
2.数据挖掘:KEGG数据库将更加注重数据挖掘和机器学习技术的应用,开发新的算法和工具来挖掘隐藏在数据中的模式和关联,为研究提供更深入的洞察。
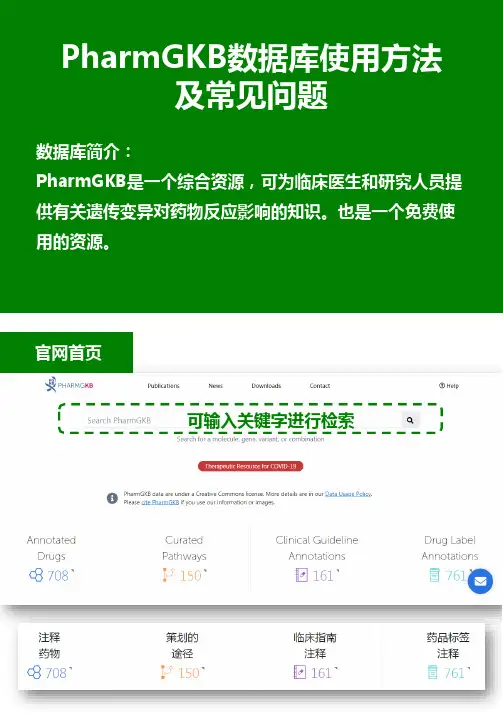
PharmGKB数据库使用方法及常见问题数据库简介:PharmGKB是一个综合资源,可为临床医生和研究人员提供有关遗传变异对药物反应影响的知识。
也是一个免费使用的资源。
官网首页可输入关键字进行检索第一种:以“药物通用名”为关键字进行检索——最常用(往往对药物更熟悉)第二种:以“基因名”或“基因变体”或“rs号”为关键词进行检索——在已知基因名、基因变体或rs 号的前提下输入关键字后点击搜索点击临床注释按照证据等级由高到低,依次分析即可常用的2种检索方法查询步骤以查询阿司匹林药物相关基因为例演示第一种检索方法1、进入pharmgkb官网,输入“aspirin”,然后点击右侧搜索图标。
2、找到药物“aspirin”,然后点击下面的“临床注释”以查询阿司匹林药物相关基因为例3、该列表显示了PharmGKB收录的与阿司匹林药物效应相关的所有基因及基因变体,并按照“证据等级”由高到低顺序。
接下来点击“现在阅读”进入详情页,对每个基因变体进行具体分析。
证据等级变体基因分子(大多是药物)4、在详情页可见,该基因的G变体影响阿司匹林的疗效。
演示以“三原则”分析PTGS1(rs10306114)变体详情页下拉即可看到PharmGKB引用的证据文献,对此可进行更详细全面的解读,以进一步确定“临床意义的一致性”第二种检索方法演示以rs号为关键字检索时,会在列表页显示与该变体相关的所有药物的信息,见红框。
你可能关心的问题1、PharmGKB是否具有PubMed的所有药物基因组学文章?•不会。
PharmGKB管理者会定期从主要药物基因组学期刊以及在整理VIP和途径的文献综述过程中发现的个别文章中手动整理文章。
证据文献列表中的文章集并不代表PubMed中的全部药物基因组学文献。
2、手动整理哪些数据?•临床注释,基于基因型的临床指南,药物标签注释,变体注释,单倍型,VIP摘要,药物途径,文献注释和药物遗传学摘要等。
3、如果我看到数据错误该怎么办?•请使用页面上的“反馈(信封图像)”按钮与我们联系,说明显示错误的信息,并描述问题。

Disgenet是一个基于网络的药物基因组学数据库,旨在提供一个集中的、综合性的工具,以研究基因在疾病发展中的作用。
在Disgenet中,疾病靶点筛选需要依据一系列标准,这些标准主要包括以下几个方面:
1.基因功能研究:通过基因敲除、转基因、基因编辑等实验方法研究基因在生
物体内的功能以及在疾病发展中的可能角色。
2.基因变异与疾病关联:研究基因变异与疾病的关联,包括变异类型、频率、
分布等,以确定与特定疾病相关的基因变异。
3.药物靶点研究:通过研究药物与基因的相互作用,确定药物的作用机制和靶
点,为药物研发提供参考。
4.基因组学和表观遗传学研究:综合利用基因组学和表观遗传学的研究方法,
全面了解基因在疾病发展中的调控机制。
总之,Disgenet的疾病靶点筛选标准综合考虑了基因功能、变异、药物靶点以及基因组学和表观遗传学等多方面的研究结果,为药物研发提供了重要的参考依据。

药物基因组学数据库1、Drugbank.drugbank.ca/2、dgidb/3、pharmGKBhttps:///4、cancercommoncancercommon./5、ChEMBLhttps:///chembldb/6、mycancergenome/7、TTD.sg/group/cjttd/8、guidetopharmcology/9、clearityfoundation/10、CIViChttps:///#/home11、DoCM/1 Drugbank药物和药物靶标资源库。
DrugBank是一个独特的生物信息学/化学信息学资源,它结合了详细的药物(例如化学制品)数据和综合的药物靶点(即:蛋白质)信息。
该数据库包含了超过4100个药物条目,包括超过800个FDA认可的小分子和生物技术药物,以及超过3200个试验性药物。
此外,超过1.4万条蛋白质或药物靶序列被到这些药物条目。
每个DrugCard条目包含超过80个数据域,其中一半信息致力于药物/化学制品数据,另一半致力于药物靶点和蛋白质数据。
许多数据域超到其他数据库(KEGG、PubChem、ChEBI、Swiss-Prot和GenBank)和各种结构查看小应用程序。
该数据库是完全可搜索的,支持大量的文本、序列、化学结构和关系查询搜索。
DrugBank的潜在应用包括模拟药物靶点发现、药物设计、药物对接或筛选、药物代谢预测、药物相互作用预测和普通药学教育。
DrugBank可以在www.drugbank.ca使用。
广泛应用于计算机辅助的药物靶标的发现、药物设计、药物分子对接或筛选、药物活性和作用预测等。
在查询中,每一种药物对应1个DrugCard,即我们所得到的检索结果。
每一个DrugCard都包含的数据信息分为药物、靶标和酶三部分。
药物信息包括了该药物的CAS号、商品名、分子式、分子量、SMILES、2D和3D结构、logP、logS、pKa、熔点、吸收性、Caco-2细胞穿透性、药物类别和临床使用、性质描述、剂型与给药途径、半衰期、体的生物转化、毒性、作用于哪些生物体、食物对服用的影响、与其它药物的相互作用、作用机理、代谢途径、药理学特征、与蛋白质的结合情况、溶解度、物质形态、同义词、关于合成的相关文献等,还与ChEBI、GenBank、PubChem等外部数据库有。

常用的生物数据库(一)引言概述:本文将介绍一些常用的生物数据库,这些数据库在生命科学研究中起到了重要的作用。
生物数据库是存储和管理生物学数据的平台,为科学家们提供了丰富的数据资源,便于他们进行进一步的研究和分析。
在本文中,我们将介绍五个常用的生物数据库,分别是A数据库、B数据库、C数据库、D数据库和E数据库。
正文:一、A数据库1. A数据库是一个广泛应用于基因组学研究的生物数据库。
2. A数据库提供了大量的基因序列和蛋白质序列,以及与这些序列相关的注释信息。
3. A数据库还提供了丰富的基因组数据和表达数据,可以帮助研究人员了解基因的功能和调控机制。
4. A数据库还提供了工具和资源,用于基因组比较和功能注释分析。
5. A数据库不仅仅适用于基础研究,也为生物技术和药物开发提供了重要的数据支持。
二、B数据库1. B数据库是一个专门用于蛋白质相关研究的生物数据库。
2. B数据库提供了大量的蛋白质序列和结构信息,以及与这些蛋白质相关的功能和互作信息。
3. B数据库还提供了工具和资源,用于预测蛋白质结构和功能,并对蛋白质相互作用网络进行分析。
4. B数据库不仅仅适用于基础研究,也为药物设计和生物工程提供了重要的数据支持。
5. B数据库的数据来源于多个实验室的研究成果,经过严格的质量控制和标准化处理。
三、C数据库1. C数据库是一个应用于植物研究的生物数据库。
2. C数据库提供了大量的植物基因组数据和表达数据,以及与这些数据相关的注释信息和功能注释分析结果。
3. C数据库还提供了工具和资源,用于植物基因功能分析和代谢途径研究。
4. C数据库不仅仅适用于基础研究,还为农业和生物能源领域的研究提供了重要的数据支持。
5. C数据库的数据来源于多个研究机构和实验室的合作项目,经过严格的数据收集和整理。
四、D数据库1. D数据库是一个广泛应用于微生物研究的生物数据库。
2. D数据库提供了大量的微生物基因组数据和表达数据,以及与这些数据相关的功能注释信息和分类信息。

kegg 解读Kegg(Kyoto Encyclopedia of Genes and Genomes)是一个广泛被应用于生物信息学领域的数据库。
它的主要目标是将基因组、化学物质和其他生物大分子有机地整合在一起,为生物学家、生物信息学家和医学研究人员提供有关代谢途径、生物网络和相关信息的详细数据。
本文将对Kegg数据库进行解读,介绍其功能和应用。
一、Kegg数据库简介Kegg数据库是由日本京都大学生物信息中心创建和维护的一个综合性数据库。
它通过整合基因组、代谢物和附加信息,提供了生物学大分子的全面知识库。
Kegg数据库的内容包括基因功能、生物化学途径、代谢物结构和化学反应等。
目前,Kegg数据库涵盖了大量的物种,包括人类、动物、植物、微生物等。
二、Kegg数据库的功能1. 基因功能注释Kegg数据库提供了基因功能注释的工具和资源,帮助研究人员从大量的基因序列中识别和注释功能。
可以通过Kegg的基因分类方式,将基因按照功能进行分类,并提供详细的注释信息和功能预测。
2. 代谢途径分析Kegg数据库中包含了大量的代谢途径信息,可以帮助研究人员理解生物体代谢的整体框架。
通过Kegg的图谱展示和路径分析工具,可以可视化地展示代谢途径,并分析其中的关键代谢步骤和相互作用。
3. 疾病相关信息Kegg数据库还提供了与疾病相关的信息,包括疾病的发病机制、相关基因和蛋白质等。
对于研究人员来说,这意味着可以通过Kegg数据库寻找潜在的药物靶点和疾病相关的代谢通路,以及潜在的治疗策略。
4. 生物网络分析Kegg数据库中的生物网络信息可用于研究基因、蛋白质和代谢物之间的相互作用。
通过分析这些生物网络,可以揭示基因调控网络、蛋白质相互作用和信号转导途径等重要生物学过程。
三、Kegg数据库的应用1. 基因组学研究Kegg数据库为基因组学研究提供了宝贵的资源和工具。
研究人员可以利用Kegg的代谢途径信息,推断基因在代谢网络中的功能和相互作用,帮助揭示生物的生理和代谢特征。

NCBI功能详介NCBI(National Center for Biotechnology Information)是美国国家生物技术信息中心,是全球最大的生物信息学数据库之一,也是生物医学研究领域最重要的资源之一、NCBI提供了广泛的生物学和医学数据库和工具,以帮助科学家们进行基因组学、蛋白质学、遗传学、药物研发等方面的研究。
NCBI的主要功能包括:1. PubMed:NCBI的PubMed是最大的生物医学文献数据库。
它收录了全球范围内的生物医学文献,并提供了非常强大的功能,以帮助科学家们找到自己感兴趣的论文。
3. BLAST:BLAST(Basic Local Alignment Search Tool)是NCBI 提供的一种重要的生物信息学工具。
它可以用来比对生物序列(如DNA、RNA或蛋白质序列),以找到相似的序列或已知的序列。
BLAST对生物学研究非常重要,可以用于序列比对、功能注释、物种分类等各种应用。
4. Entrez数据库:Entrez是NCBI提供的一种综合性数据库工具,可以用来访问和多个数据库,如PubMed、GenBank、Protein、Nucleotide等。
用户可以使用Entrez来查找和获取各种类型的生物学数据,如文献、序列、蛋白质结构等。
5. PubChem:PubChem是一个提供生物化学信息的数据库,包含大量的有关化合物的实验数据、化学结构、药物作用等信息。
它可以帮助研究人员进行药物发现、化合物筛选和毒性评估等方面的研究。
6. dbSNP:DBSNP(Single Nucleotide Polymorphism Database)是一个用于存储和查询单核苷酸多态性数据的数据库。
它收集了全球范围内各种不同物种的单核苷酸变异信息,包括单核苷酸变异的位点、变异类型、频率等。
7. GEO:GEO(Gene Expression Omnibus)是一个用于存储和共享基因表达数据的数据库。

medline数据库1. 概述Medline数据库是一个医学文献数据库,由美国国家医学图书馆(National Library of Medicine)创建和维护。
它收录了自1946年以来的生物医学和生命科学领域的文献,包括医学研究、临床实验、医学教育及相关领域的文献。
2. 数据内容Medline数据库涵盖了各种医学和生命科学的领域,包括但不限于:•临床医学:医学研究、临床试验、疾病诊断和治疗等方面的文献。
•生物医学研究:生物医学实验室研究、动物模型、细胞研究等方面的文献。
•基因组学和生物信息学:基因组学研究和生物信息学分析等方面的文献。
•药物研发:药物研发、药理学、药效学等方面的文献。
Medline数据库中的文献主要来源于定期索引的期刊文章,也包括各种学术会议论文、学位论文和专著。
目前,Medline数据库每年都有新的更新和添加内容,以保持数据库的及时性和准确性。
3. 检索和访问用户可以通过以下方法来检索和访问Medline数据库中的文献:3.1 在线检索可以通过访问美国国家医学图书馆的网站,使用Medline数据库的在线检索功能。
用户可以在检索框中输入关键词、作者、标题等信息,以找到与所查询主题相关的文献。
3.2 数据下载Medline数据库提供了数据下载的功能,用户可以按照自己的需求将数据库中的文献下载到本地进行深入研究和分析。
下载的文献可以以多种格式提供,包括文本格式、XML格式等。
4. 应用场景Medline数据库在医学和生命科学领域具有广泛的应用价值,主要包括以下几个方面:•临床医学研究:医生和临床医学研究人员可以利用Medline数据库来查找最新的疾病诊断和治疗方法的相关文献,以提高临床实践的准确性和效果。
•生物医学研究:科研人员可以通过Medline数据库来了解最新的生物医学研究进展,帮助他们更好地设计实验和解读实验结果。
•教育和培训:教育机构和培训机构可以使用Medline数据库来提供学生和研究人员面对面的教学和培训,以培养他们在医学和生命科学领域的科研能力。

ncbi使用指导NCBI是美国国家生物技术信息中心(National Center for Biotechnology Information)的缩写,是一个提供生物医学和遗传学相关数据和信息的数据库。
NCBI提供了许多工具和资源,以帮助研究人员在基因组学、蛋白质学、遗传学和生物信息学等领域进行研究。
以下是使用NCBI的一些基本指南:1. 访问NCBI网站:使用任何现代网络浏览器,打开NCBI的主页(https://)即可开始使用。
2. 搜索文献:在NCBI主页上的搜索框中,输入你要搜索的关键词,如基因名、疾病名或其他相关的信息。
点击“搜索”按钮,即可看到与你的搜索关键词相关的论文和研究。
3. 搜索序列:如果你希望搜索某个特定基因或蛋白质的序列,可以使用“基因”或“蛋白质”选项卡下的搜索工具。
在搜索框中输入你要搜索的序列信息,点击“搜索”按钮,即可找到与该序列相关的信息和研究。
4. 访问数据库:NCBI提供了许多数据库,如GenBank(基因组数据库)、PubMed(文献数据库)和BLAST(序列比对工具)。
你可以使用NCBI的导航菜单,选择你感兴趣的数据库进行浏览和搜索。
5. 下载数据:在NCBI的数据库中,你可以找到大量的基因组序列、蛋白质序列和其他相关数据。
你可以通过点击数据记录的链接,进入详情页,然后选择下载你需要的数据文件或信息。
6. 利用NCBI工具:NCBI还提供了一些生物信息学工具,如BLAST(序列比对工具)、Primer-BLAST(引物设计工具)和Gene Expression Omnibus(基因表达数据库)。
你可以使用这些工具进行基因序列比对、引物设计和基因表达分析等。
7. 阅读文献:NCBI的PubMed数据库是一个广泛的生物医学文献数据库,你可以使用关键词搜索文献,并阅读或下载全文。
你还可以使用PubMed Central(PMC)访问免费的全文文章。
总之,NCBI是一个丰富的生物医学信息资源,提供了许多工具和数据库,以帮助研究人员进行基因组学和生物信息学研究。

gdb数据库使用记录
GDB(Global Database)是一个全球性的数据库,用于存储和检索与基因组学、生物信息学和系统生物学相关的数据。
以下是使用GDB数据库的一些常见记录:
基因组序列:GDB数据库中存储了大量基因组序列数据,包括DNA序列、蛋白质序列等。
这些数据可用于基因组学研究、基因功能分析、进化生物学等领域。
基因注释:GDB数据库中的基因注释信息包括基因名称、基因功能、基因产物等,这些信息有助于理解基因的结构和功能。
变异数据:GDB数据库中还包含大量与人类和其他物种的遗传变异相关的数据,这些数据可用于遗传疾病研究、药物发现等领域。
蛋白质结构:GDB数据库中存储了大量蛋白质的三维结构数据,这些数据有助于理解蛋白质的功能和相互作用。
系统生物学数据:GDB数据库中还包含大量与系统生物学相关的数据,包括代谢途径、信号转导通路等,这些数据有助于理解生物系统的整体行为。
使用GDB数据库通常需要进行数据库查询、数据分析、可视化等操作。
具体的使用方法取决于所使用的工具和数据类型,一般需要通过编程或使用特定的查询语言(如SQL)来完成。
对于初学者来说,可以参考GDB数据库的官方文档、教程或在线课程来学习如何使用该数据库。
KEGG使用教程KEGG(Kyoto Encyclopedia of Genes and Genomes,京都基因组和基因组百科全书)是一个涉及基因组、基因和生物化合物的综合数据库,为研究生物学、生物信息学和系统生物学提供重要的资源和工具。
本教程将介绍KEGG数据库的基本用法,帮助用户更好地利用该数据库进行研究。
一、KEGG数据库概述KEGG数据库包含了大量的关于基因组、代谢途径、疾病和药物等方面的信息。
其主要包含了以下三个数据库:1.KEGGPATHWAY:代谢途径数据库,包含了多种生物途径的详细信息,如糖代谢途径、氨基酸代谢途径等。
2.KEGGGENES:基因数据库,提供了大量的基因序列、功能注释和基因组定位等信息。
3.KEGGDRUG:药物数据库,包含了多种药物的结构信息、药物靶点和作用机制等。
二、KEGG数据库的使用方法2.基因:在栏中输入基因名或ID,然后点击按钮。
系统将返回与输入相关的基因信息,包括基因描述、序列、功能注释等。
3.代谢途径:在栏中输入感兴趣的代谢途径名或ID,然后点击按钮。
系统将返回与输入相关的代谢途径信息,包括途径图、相关基因和代谢产物等。
4.药物:在栏中输入感兴趣的药物名或ID,然后点击按钮。
系统将返回与输入相关的药物信息,包括药物结构、作用靶点和相关的疾病等。
5. 序列比对:在KEGG网站的工具栏中,选择“Sequencesimilarity search”选项,可以进入基因序列比对的页面。
用户可以将自己的序列与KEGG数据库中的序列进行比对,以查找相关基因或代谢途径。
7. 可视化分析:KEGG数据库还提供了一些用于代谢途径之间相互作用和基因表达等数据分析的工具和资源。
用户可以在KEGG网站的工具栏中选择“Analysis”选项,进入相应的页面进行数据可视化和分析。
三、使用案例以糖代谢途径为例,介绍KEGG数据库的使用方法。
1. 在KEGG网站的栏中输入“Glycolysis”(糖酵解),点击按钮。
DataBase肿瘤药物敏感性基因组学数据库GDSChttps:///Genomics of Drug Sensitivity in Cancer (GDSC),提供免费公开的肿瘤治疗基因组数据,致⼒于发现潜在的肿瘤治疗靶点以改善肿瘤治疗,是全球最⼤的同类型公共数据库。
⾸页可见,GDSC数据库⽀持化合物(药物)、细胞系和癌基因三种检索⽅式。
化合物的相关信息由⾏业、学术合作伙伴或供应商处获取;癌基因组突变信息来⾃COSMIC数据库。
GDSC数据库基本上每年会有⼀个⼤版本的更新,年中会有不定期的⼩版本更新。
截⾄本稿,最新版本是Release 8.1 (Oct 2019) ,数据统计可见,共收录453种药物,988个细胞系,以及38万+组检测IC50值:注:数据量并⾮持续增加的,与TCGA⼀样,对于新的质控标准下,不满⾜QC阈值的数据将被移除。
GDSC⽬前提供两个数据集:GDSC1是该⽹站上可⽤的原始数据集(2009-2015年间收集)的扩展。
⽽GDSC2则基于改进的技术、设备和程序等所得的最新的数据(2015-⾄今)。
例如:GDSC1使⽤DNA染料(Syto60),⽽GDSC2使⽤代谢测定法(Resazurin / CellTiter-Glo)来确定细胞活⼒。
GDSC2中已经重复了许多来⾃GDSC1的实验,官⽅建议使⽤GDSC2!【但实际选哪个⽤,由你⾃⼰决定,实际上有些基因的数据在GDSC1中有,在GDSC2中则不存在...】注:类似于现⾏TCGA的GDC Legacy 和 GDC Portal!GDSC数据库提供在线的数据分析和可视化。
其中,⽕⼭图(Volcano Plot)⽤于展⽰基因特征和药物敏感性之间的联系(ANOVA分析):Gene specific volcano plots represent the effect of a mutated gene (e.g. BRAF) on the responses to all drugs analysed. A drug-specificvolcano plot represents how genomic changes influence response to a specific drug (e.g. BRAF inhibitor PLX4720).IC50,半抑制浓度,即凋亡细胞与全部细胞数之⽐等于50%时所对应的药物浓度。
⽣物数据库介绍——NCBINCBI(National Center for Biotechnology Information,美国国家⽣物技术信息中⼼)除了维护GenBank核酸序列数据库外,还提供数据分析和检索资源。
NCBI资源包括Entrez、Entrez编程组件、MyNCBI、PubMed、PudMed Central、PubReader、Gene、the NCBI Taxonomy Browser、BLAST、Pimer-Blast、COBALT、RefSeq、UniGene、HomoloGene、ProtEST、dbMHC、dbSNP、dbVar、Epigenomics、the Genetic Testing Registry、Genome和相关⼯具、⽐对查看器、跟踪存档、Sequence Read Archive、BioProject、BioSample、ClinVar、MedGen、HIV-1/⼈类蛋⽩质相互作⽤数据库、Gene Expression Omnibus、Probe、Online Mendelian Inheritance in Animals、the Molecular Modeling Database、the Conserved Domain Database、the Conserved Domain Architecture Retrieval Tool、Biosystem、Protein Clusters and thePubChem suite of small molecule databases,所有这些资源可以在NCBI主页找到。
Databases⼀个提供有关基因组组装结构,装配名称和其他元数据,统计报告以及基因组序列数据链接等信息的数据库。
⼀个有关培养物、动植物样本和其他⾃然样本的精选元数据集。
记录显⽰样本状态,有关馆藏的机构的信息,以及NCBI中相关数据链接。
用GDSC数据库的结肠癌细胞系数据来计算基因与IC50的相关性结肠癌是一种常见的恶性肿瘤,其中细胞系是研究癌症发病机制和药物治疗的重要工具。
GDSC数据库(Genomics of Drug Sensitivity in Cancer)提供了包含基因组学和药物敏感性信息的大量癌症细胞系数据。
在这个数据库中,我们可以利用这些数据来计算基因与药物IC50(对50%细胞生长抑制的药物浓度)之间的相关性。
接下来,我们可以使用线性回归模型来计算基因与IC50之间的相关性。
线性回归模型可以帮助我们了解基因对药物敏感性的影响程度。
我们可以选择一个基因作为预测变量,将其与IC50作为响应变量,然后通过拟合线性回归模型来计算二者之间的相关性。
除了线性回归模型,我们还可以利用其他计算相关性的方法,例如皮尔逊相关系数、斯皮尔曼相关系数和Kendall相关系数等。
这些方法可以帮助我们确定基因与IC50之间的线性或非线性关系。
在计算相关性之后,我们可以进行统计显著性检验,以确定计算结果的可靠性。
常用的显著性检验方法包括t检验和F检验,可以帮助我们判断基因与IC50之间的相关性是否显著。
此外,为了获得更准确的结果,我们可以考虑使用多个细胞系的数据进行分析,并进行交叉验证来评估模型的性能。
这样可以减少单个细胞系的特异性,从而提高结果的稳定性和可靠性。
最后,我们还可以使用机器学习算法来进一步挖掘基因与IC50之间的复杂关系。
例如,我们可以使用支持向量回归、随机森林或神经网络等模型来构建基于基因组学数据和IC50的预测模型。
这样可以更好地理解基因对药物敏感性的贡献,并预测新的治疗策略。
在总结中,利用GDSC数据库的结肠癌细胞系数据可以帮助我们计算基因与IC50之间的相关性。
通过选择合适的数据处理和统计分析方法,我们可以获得基因与药物敏感性之间的相关程度,并进一步研究基因对药物敏感性的作用机制。
这些研究结果对于个体化药物治疗和癌症治疗策略的制定具有重要意义。
KEGG使用经验分享KEGG(Kyoto Encyclopedia of Genes and Genomes)是一个用于分析生物信息学和基因组学的数据库,它提供了广泛的基因组,路径,药物和疾病信息。
KEGG可用于研究和识别基因和蛋白质之间的关系,帮助理解疾病的发展机制以及开发新的药物靶点。
我使用KEGG已经有一段时间了,我想分享一些我在使用过程中学到的经验和技巧。
首先,KEGG提供了一个简单直观的界面,可以通过浏览器轻松访问。
在KEGG主页上,你可以通过条目或者浏览分类来找到你感兴趣的基因、代谢途径或者疾病。
你可以特定的基因名、蛋白质名或者疾病名来获取相关信息。
浏览途径时,KEGG提供了一个非常直观且易于理解的图形界面,展示了途径中的分子和它们之间的相互作用。
你可以点击每个分子,获取更多关于它的详细信息,包括基因的注释、结构和相关文献。
KEGG还提供了一些实用的工具和资源。
比如,它提供了一个代谢物数据库,可以用来查询和特定的化合物。
你可以查找一个化合物的结构、性质和它们在生物学系统中的作用。
此外,KEGG还有一些有用的分析工具。
比如,它提供了一个基因集富集分析工具,可以根据基因表达数据和KEGG数据库,帮助你找到与一些生物过程或疾病相关的基因集。
这个工具可以帮助你理解基因与疾病之间的关系,找到可能的生物标志物或者潜在的治疗靶点。
当你使用KEGG进行研究时,有几点是需要注意的。
首先,KEGG数据库中的信息可能不是最新的。
在使用KEGG中的结果时,最好通过查阅最新的文献和数据库来确认结果的准确性。
其次,KEGG虽然提供了一个非常丰富的基因和代谢途径数据库,但并不是所有的基因和途径都被完全注释。
在进行研究时,我们需要对结果进行进一步的验证和分析。
另外,KEGG提供的工具和资源可能需要一些基础的生物信息学知识来使用。
如果你对生物信息学和基因组学没有很好的了解,你可能需要事先学习一些基础知识,以便更好地使用KEGG。
药物基因组学数据库
1、Drugbank
2、dgidb
3、pharmGKB
4、cancercommon
5、ChEMBL
6、mycancergenome
7、TTD
8、guidetopharmcology
9、clearityfoundation
10、CIViC
https:///#/home
11、DoCM
/
1 Drugbank
药物和药物靶标资源库。
DrugBank是一个独特的生物信息学/化学信息学资源,它结合了详细的药物(例如化学制品)数据和综合的药物靶点(即:蛋白质)信息。
该数据库包含了超过4100个药物条目,包括超过800个FDA认可的小分子和生物技术药物,以及超过3200个试验性药物。
此外,超过1.4万条蛋白质或药物靶序列被链接到这些药物条目。
每个DrugCard条目包含超过80个数据域,其中一半信息致力于药物/化学制品数据,另一半致力于药物靶点和蛋白质数据。
许多数据域超链接到其他数据库(KEGG、PubChem、ChEBI、Swiss-Prot和GenBank)和各种结构查看小应用程序。
该数据库是完全可搜索的,支持大量的文本、序列、化学结构和关系查询搜索。
DrugBank的潜在应用包括模拟药物靶点发现、药物设计、药物对接或筛选、药物代谢预测、药物
相互作用预测和普通药学教育。
DrugBank可以在http://www.drugbank.ca 使用。
广泛应用于计算机辅助的药物靶标的发现、药物设计、药物分子对接或筛选、药物活性和作用预测等。
在查询中,每一种药物对应1个DrugCard,即我们所得到的检索结果。
每一个DrugCard都包含的数据信息分为药物、靶标和酶三部分。
药物信息包括了该药物的CAS号、商品名、分子式、分子量、SMILES、2D 和3D结构、logP、logS、pKa、熔点、吸收性、Caco-2细胞穿透性、药物类别和临床使用、性质描述、剂型与给药途径、半衰期、体内的生物转化、毒性、作用于哪些生物体、食物对服用的影响、与其它药物的相互作用、作用机理、代谢途径、药理学特征、与蛋白质的结合情况、溶解度、物质形态、同义词、关于合成的相关文献等,还与ChEBI、GenBank、PubChem等外部数据库有链接。
靶标的信息包括ID、名称、靶标基因的名称、蛋白质序列、残基数目、分子量、等电点、功能和活性、参与的代谢途径和反应、体内分布、靶标信号、跨膜区域、靶标基因序列及其在GenBank、HGNC等外部数据库中的ID和链接、参考文献,以及在GenBank和Swiss-Prot中的链接。
酶的信息包括名称、蛋白质序列、基因名称、在Swiss-Prot 等数据库中的链接。
在DrugBank的主界面上,在Browse菜单下可以浏览数据库的内容,其中PharmaBrowse为用户提供了分类浏览的功能。
这为药剂师、医生以及寻找潜在药物的研究人员提供了方便。
在Search下拉菜单下,就是Drug Bank的4类检索方式。
ChemQuery允许用户通过绘制结构图或书写SMILES、分子式进行结构搜索。
在检索过程中还可以对搜索药物类型、分子量范围、搜索结果相似度、结果数量最大值等进行设置。
TextQuery则为文本检索功能。
文本检索支持逻辑运算符连接及在特定领域内搜索。
例如,在“dextromethorphan”中检索混合物,可以键入“mixtures:dextromethorphan”,即用分号在后面输入领域,同时可以加入逻辑运算符,例如,在“dextrome thorphan”和“doxylamine”2个领域进行检索,可以键入“mixtures:dextromethorphan AND mixtures:doxylamine”。
SeqSearch为用户提供了通过序列检索蛋白质的功能。
Data Extractor是1
个组合检索工具。
用户可以对DrugCard所包含的信息进行选择性的组合检索(1) Browse按钮:Drug Browse、Category Browse、Geno Browse、Reaction Browse、Pathway Browse、Class Browse、Target Browse;
(2) Search按钮:ChemQuery Structure Search、Interax Interaction Search、Sequence Search、Advanced Search、MS Search、MS/MS Search、GC/MS Search、1D NMR Search、2D NMR Search;
(3)其他Tool按钮:HMDB、T3DB、SMPDB、FooDB、PPT-DB、CSF、Serum Metabolome、CCDB、YMDB、BMDB、ECMDB、MarkerDB、BacMap、Ref-DB。
Drug Browse:小分子药物、生物技术药物、显示药物在DrugBank中的ID、药物名称、分子量、化学式、化学结构、药物类型、治疗症状。
Drugs:显示ID、药物名称、治疗疾病
Drugs and Targets:显示ID、药物名称、作用位点(靶标)、靶标类型
总结:可以查找药物名称、分子量、化学式、分子结构、药物所属类型、靶标、靶标类型、治疗疾病、代谢途径等,还可链接到相关网站。
(较实用)
Drug Browse:药名、分子量、化学式、化学结构、药物分类、药效
Geno Browse:药物名称,相互作用的基因/酶,SNP位点、等位基因名称、碱基变化、副作用
Pathway Browse:可查看代谢通路
Classification Browse:药物分类
Target Browse:查靶标及靶标分类和详细细节(药物分类、药理学等)
2ChEMBL
生物活性药物类小分子数据库。
总结:输入分子结构或已知靶标描述或靶标蛋白,每条记录都包括分子的分类、名称、ChEMBI ID、功能、毒性、亚细胞定位、结构、序列、参考文献等。
(偏向于化学)
3 clearityfoundation
关于卵巢癌的公益网站。
治疗卵巢癌复发、有关肿瘤分子信息、临床试验、卵巢癌诊断和治疗分析、新型靶向制剂的临床开发、治疗结果。
(基本无用)
4 DoCM
位点突变数据库,
总结:查找染色体、基因、疾病、突变类型、氨基酸、起始位置、参考文献(稍微简单了点)
5 CIViC
Search:查找描述、疾病名称、疾病DOID、药物PubChem ID、药物名称、证据水平、基因名、PubChem ID、突变位点等查找相关信息。
总结:evidence ID、基因、氨基酸变化、描述、病名、药物、evidence level(A:经过验证的;B:临床;C:临床前;D:个体研究;E:推理的)、evidence type (predictive、diagnostic、prognostic)、evidence direction(supports、dose not support)、clinical significance(sensitivice/resistance or non-response/better outcome/poor outcome/positive/negative)、variant origin(somatic/germline)、trust
rating(1/2/3/4/5 stars),可链接到代谢途径及下载。
(比较实用)
Search:可按不同类型搜索
输入要搜索的单词,如“breast cancer”
点击一个基因/疾病
单击“View Full Detials from MyGene info”,查基因介绍、蛋白结构域、通路。