S语言词法分析器设计
- 格式:doc
- 大小:147.00 KB
- 文档页数:7

编译原理词法分析实验报告实验名称:词法分析器的设计与实现一、实验目的:1.熟悉编译原理中词法分析的基本概念和原理;2.掌握正则表达式的使用方法;3.实现一个简单的词法分析器。
二、实验内容:1.设计一个简单的编程语言,包含如下几种类型的词法单元:关键字、标识符、常量、运算符和界符。
2.使用正则表达式定义每种词法单元的模式。
3.设计一个词法分析器,将源代码中的每个词法单元识别出来并输出。
三、实验步骤:1. 确定编程语言的词法单元类型和正则表达式模式,定义相应的单词类型(如 TokenType)和模式(如 regex)。
2. 实现一个词法分析器的类 Lexer,包含以下方法:(1)一个构造方法,用于初始化词法分析器的输入源代码。
(2) 一个getNextToken方法,用于获取源代码中的下一个词法单元。
3. 在getNextToken方法中,使用正则表达式逐个识别源代码中的词法单元,并返回相应的Token对象。
4. 设计一个Token类,包含以下属性:词法单元类型、词法单元的值和位置信息等。
5.在主程序中使用词法分析器,将源代码中的每个词法单元识别出来并输出。
四、实验结果:1.设计一个简单的编程语言,包含如下词法单元类型(示例):(1) 关键字:if、else、while、for等;(2)标识符:变量名等;(3)常量:整数、浮点数、字符串等;(4)运算符:+、-、*、/、=等;(5)界符:(、)、{、}、;等。
2. 实现一个词法分析器,识别出源代码中的每个词法单元,并输出相应的Token对象。
五、实验总结:通过本次实验,我熟悉了编译原理中词法分析的基本概念和原理,并掌握了正则表达式的使用方法。
我成功完成了一个简单的词法分析器的设计与实现,实现了源代码中每个词法单元的识别与输出。
这次实验对我深化了对编译原理中词法分析的理解,并提高了我的编程能力。

编译原理课程设计(一)——词法分析器1、题目编写程序实现一个简易的词法分析器。
2、实验目的对一段程序代码进行词法分析,将程序段中的关键字、标识符、常数、运算符、界符按照一定的种别编码分析出来。
3、环境及工具操作系统:windows XP ;使用工具:Microsoft Visual C++ 6.0; 编程语言:C 语言;4、分析程序输入:从文件中读入程序段;程序输出:由单词种别和单词符号的属性值组成的二元式;单词种别通常使用整数编码,编码方式可以有多种,在设计词法分析器之前应确定一种程序处理起来较方便的编码方式。
当一个种别中含有多个单词符号时,在分析出其属于哪个种别的时候应同时给出其单词符号属性,本程序为方便起见,采用单词符号本身来作为其属性,以标识同种别种的不同单词符号。
标识符及关键字的识别:字母开头的字母和数字组成的串是多数编程语言的标识符,所以我们的简易词法分析器中,将标识符定义为这种字母数字串。
当第一个字母为字母且紧接着的字符为数字或字母时,应将其串接在一起为一个单词,直到紧跟着的不在是字母数字时。
由于关键字通常为一个单词,则这样得到的串可能是标识符也可能是关键字,又因为一种语言的关键字通常是有限个,则我们可以构造一个存放所有关键字的表,查询关键字表,可以判断得到的串是否为关键字。
界符和运算符的识别:它们多为当个字符,建立两个分别存放界符合运算符的表,读取字符后,进行查表便可以得出它们的类型。
为方便词法分析器的设计,可以使用状态转换图,根据一种特定的编程语言先设计出其状态转换图才能更好将其用代码实现。
典型状态转换图结构如下:(a)有不含回路含分支的状态节点:对应if …else if …else …语句;(b)有含回路的状态节点:对应while …if …语句。
(b )5、状态转换图6、程序框架描述程序中编写了以下函数,各个函数实现的作用如下:1. GetChar():将下一输入的字符读入到全局变量ch中,搜素指示器前移一个字符的位置。

词法分析器实验报告词法分析器实验报告实验目的:设计、编制、调试一个词法分析子程序,识别单词,加深对词法分析原理的理解。
实验要求:该程序要实现的是一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分界符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
(一)实验内容(1)功能描述:对给定的程序通过词法分析器弄够识别一个个单词符号,并以二元式(单词种别码,单词符号的属性值)显示。
而本程序则是通过对给定路径的文件的分析后以单词符号和文字提示显示。
(2)程序结构描述:函数调用格式:函数调用格式函数名(实在参数表 )Switch(m)、 isKey(String string)、isLetter(char c)、实参isDigit(char c)、isOperator(char c)isKey(String string)、isLetter(char c)、调作为表达式isDigit(char c)、isOperator(char c) 用方作为语句 getChar()、judgement()、法函数的递归调用 isOperator(char c) 、isLetter(char c)、isDigit(char c)参数含义:1String string;存放读入的字符串 String str; 存放暂时读入的字符串 char ch; 存放读入的字符 int rs 判断读入的文件是否为空 char []data 存放文件中的数据 int m;通过switch用来判断字符类型,函数之间的调用关系图:mainComplier..judgementisOperate()M=0 getChar( )isDigit()M=4 For(ch )isLetter() M=2Switch(m)isKey() M=3 函数功能:Judgement()判断输入的字符并输出单词符号,返回值为空; getChar() 读取文件的,返回值为空;isLetter(char c) 判断读入的字符是否为字母的,返回值为Boolean类型; switch (m) 判断跳转输出返回值为空;isOperator(char c)判断是否为运算符的,返回值为Boolean类型;isKey(String string)判断是否为关键字的,返回值为Boolean类型;isDigit(char c) 判断读入的字符是否为数字的,返回值为Boolean类型。

计算机网络课程设计报告班级:计1102姓名:杨勇学号: 41155047词法分析器:一、实验目的调试并完成一个词法分析程序,加深对词法分析原理的理解。
二、实验要求1、待分析的简单语言的词法(1)关键字:begin if then while do end所有关键字都是小写。
(2)运算符和界符::= + –* / <<= <>>>= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(NUM),通过以下正规式定义:ID=letter(letter| digit)*NUM=digit digit *(4)空格由空白、制表符和换行符组成。
空格一般用来分隔ID、NUM,运算符、界符和关键字,词法分析阶段通常被忽略。
2、各种单词符号对应的种别码3、词法分析程序的功能输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
三、C语言程序源代码:#include <stdio.h>#include <string.h>char prog[80],token[8],ch;int syn,p,m,n,sum;char *rwtab[6]={"begin","if","then","while","do","end"}; scaner();main(){p=0;printf("\n please input a string(end with '#'):/n");do{scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;do{scaner();switch(syn){case 11:printf("( %-10d%5d )\n",sum,syn);break;case -1:printf("you have input a wrong string\n");getch();exit(0);default: printf("( %-10s%5d )\n",token,syn);break;}}while(syn!=0);getch();}scaner(){ sum=0;for(m=0;m<8;m++)token[m++]=NULL;ch=prog[p++];m=0;while((ch==' ')||(ch=='\n'))ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0) { syn=n+1;break;}}else if((ch>='0')&&(ch<='9')) { while((ch>='0')&&(ch<='9')) { sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':token[m++]=ch;ch=prog[p++];if(ch=='=')token[m++]=ch;}else{ syn=20;p--;}break;case '>':token[m++]=ch; ch=prog[p++];if(ch=='='){ syn=24;token[m++]=ch;}else{ syn=23;p--;}break;case '+': token[m++]=ch; ch=prog[p++];if(ch=='+')token[m++]=ch;}else{ syn=13;p--;} break;case '-':token[m++]=ch; ch=prog[p++];if(ch=='-'){ syn=29;token[m++]=ch;}else{ syn=14;p--;} break;case '!':ch=prog[p++];{ syn=21;token[m++]=ch;}else{ syn=31;p--;}break;case '=':token[m++]=ch; ch=prog[p++];if(ch=='='){ syn=25;token[m++]=ch;}else{ syn=18;p--;}break;case '*': syn=15;token[m++]=ch; break;case '/': syn=16; token[m++]=ch; break;case '(': syn=27; token[m++]=ch; break;case ')': syn=28; token[m++]=ch; break;case '{': syn=5; token[m++]=ch; break;case '}': syn=6; token[m++]=ch; break;case ';': syn=26; token[m++]=ch; break;case '\"': syn=30; token[m++]=ch;break;case '#': syn=0;token[m++]=ch;break;case ':':syn=17;token[m++]=ch;break;default: syn=-1;break;}token[m++]='\0';}三、实验结果:1、给定源程序begin x:=9; if x>0 then x:=2*x+1/3; end#输出结果2、源程序(包括上式未有的while、do以及判断错误语句):beginx<=$;whilea<0dob<>9-x;end#输出结果四、总结分析:通过此次实验,让我了解到如何设计、编制并调试词法分析程序,加深对词法分析原理的理解;熟悉了构造词法分析程序的手工方式的相关原理,根据识别语言单词的状态转换图,使用某种高级语言(例如C++语言)直接编写此法分析程序。

词法分析器实验报告词法分析器实验报告一、引言词法分析器是编译器中的重要组成部分,它负责将源代码分解成一个个的词法单元,为之后的语法分析提供基础。
本实验旨在设计和实现一个简单的词法分析器,以深入理解其工作原理和实现过程。
二、实验目标本实验的目标是设计和实现一个能够对C语言代码进行词法分析的程序。
该程序能够将源代码分解成关键字、标识符、常量、运算符等各种词法单元,并输出其对应的词法类别。
三、实验方法1. 设计词法规则:根据C语言的词法规则,设计相应的正则表达式来描述各种词法单元的模式。
2. 实现词法分析器:利用编程语言(如Python)实现词法分析器,将源代码作为输入,根据词法规则将其分解成各种词法单元,并输出其类别。
3. 测试和调试:编写测试用例,对词法分析器进行测试和调试,确保其能够正确地识别和输出各种词法单元。
四、实验过程1. 设计词法规则:根据C语言的词法规则,我们需要设计正则表达式来描述各种词法单元的模式。
例如,关键字可以使用'|'操作符将所有关键字列举出来,标识符可以使用[a-zA-Z_][a-zA-Z0-9_]*的模式来匹配,常量可以使用[0-9]+的模式来匹配等等。
2. 实现词法分析器:我们选择使用Python来实现词法分析器。
首先,我们需要读取源代码文件,并将其按行分解。
然后,针对每一行的代码,我们使用正则表达式进行匹配,以识别各种词法单元。
最后,我们将识别出的词法单元输出到一个结果文件中。
3. 测试和调试:我们编写了一系列的测试用例,包括各种不同的C语言代码片段,以测试词法分析器的正确性和鲁棒性。
通过逐个测试用例的运行结果,我们可以发现和解决词法分析器中的问题,并进行相应的调试。
五、实验结果经过多次测试和调试,我们的词法分析器能够正确地将C语言代码分解成各种词法单元,并输出其对应的类别。
例如,对于输入的代码片段:```cint main() {int a = 10;printf("Hello, world!\n");return 0;}```我们的词法分析器将输出以下结果:```关键字:int标识符:main运算符:(运算符:)运算符:{关键字:int标识符:a运算符:=常量:10运算符:;标识符:printf运算符:(常量:"Hello, world!\n"运算符:)运算符:;关键字:return常量:0运算符:;```可以看到,词法分析器能够正确地将代码分解成各种词法单元,并输出其对应的类别。

词法分析器实验报告一、实验目的及要求本次实验通过用C语言设计、编制、调试一个词法分析子程序,识别单词,实现一个C语言词法分析器,经过此过程可以加深对编译器解析单词流的过程的了解。
运行环境:硬件:windows xp软件:visual c++6.0二、实验步骤1.查询资料,了解词法分析器的工作过程与原理。
2.分析题目,整理出基本设计思路。
3.实践编码,将设计思想转换用c语言编码实现,编译运行。
4.测试功能,多次设置包含不同字符,关键字的待解析文件,仔细察看运行结果,检测该分析器的分析结果是否正确。
通过最终的测试发现问题,逐渐完善代码中设置的分析对象与关键字表,拓宽分析范围提高分析能力。
三、实验内容本实验中将c语言单词符号分成了四类:关键字key(特别的将main说明为主函数)、普通标示符、常数和界符。
将关键字初始化在一个字符型指针数组*key[]中,将界符分别由程序中的case列出。
在词法分析过程中,关键字表和case列出的界符的内容是固定不变的(由程序中的初始化确定),因此,从源文件字符串中识别出现的关键字,界符只能从其中选取。
标识符、常数是在分析过程中不断形成的。
对于一个具体源程序而言,在扫描字符串时识别出一个单词,若这个单词的类型是关键字、普通标示符、常数或界符中之一,那么就将此单词以文字说明的形式输出.每次调用词法分析程序,它均能自动继续扫描下去,形成下一个单词,直到整个源程序全部扫描完毕,从而形成相应的单词串。
输出形式例如:void $关键字流程图、程序流程图:程序:#include<string.h>#include<stdio.h>#include<stdlib.h>#include<ctype.h>//定义关键字char*Key[10]={"main","void","int","char","printf","scanf","else","if","return"}; char Word[20],ch; // 存储识别出的单词流int IsAlpha(char c) { //判断是否为字母if(((c<='z')&&(c>='a'))||((c<='Z')&&(c>='A'))) return 1;else return 0;}int IsNum(char c){ //判断是否为数字if(c>='0'&&c<='9') return 1;else return 0;}int IsKey(char *Word){ //识别关键字函数int m,i;for(i=0;i<9;i++){if((m=strcmp(Word,Key[i]))==0){if(i==0)return 2;return 1;}}return 0;}void scanner(FILE *fp){ //扫描函数char Word[20]={'\0'};char ch;int i,c;ch=fgetc(fp); //获取字符,指针fp并自动指向下一个字符if(IsAlpha(ch)){ //判断该字符是否是字母Word[0]=ch;ch=fgetc(fp);i=1;while(IsNum(ch)||IsAlpha(ch)){ //判断该字符是否是字母或数字Word[i]=ch;i++;ch=fgetc(fp);}Word[i]='\0'; //'\0' 代表字符结束(空格)fseek(fp,-1,1); //回退一个字符c=IsKey(Word); //判断是否是关键字if(c==0) printf("%s\t$普通标识符\n\n",Word);//不是关键字else if(c==2) printf("%s\t$主函数\n\n",Word);else printf("%s\t$关键字\n\n",Word); //输出关键字 }else //开始判断的字符不是字母if(IsNum(ch)){ //判断是否是数字Word[0]=ch;ch=fgetc(fp);i=1;while(IsNum(ch)){Word[i]=ch;i++;ch=fgetc(fp);}Word[i]='\0';fseek(fp,-1,1); //回退printf("%s\t$无符号实数\n\n",Word);}else //开始判断的字符不是字母也不是数字{Word[0]=ch;switch(ch){case'[':case']':case'(':case')':case'{':case'}':case',':case'"':case';':printf("%s\t$界符\n\n",Word); break;case'+':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word);//运算符“+=”}else if(ch=='+'){printf("%s\t$运算符\n\n",Word); //判断结果为“++”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“+”}break;case'-':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word); }else if(ch=='-'){printf("%s\t$运算符\n\n",Word); //判断结果为“--”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“-”}break;case'*':case'/':case'!':case'=':ch=fgetc(fp);if(ch=='='){printf("%s\t$运算符\n\n",Word);}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word);}break;case'<':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word); //判断结果为运算符“<=”}else if(ch=='<'){printf("%s\t$运算符\n\n",Word); //判断结果为“<<”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“<”}break;case'>':ch=fgetc(fp);Word[1]=ch;if(ch=='=') printf("%s\t$运算符\n\n",Word);else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word);}break;case'%':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word);}if(IsAlpha(ch)) printf("%s\t$类型标识符\n\n",Word);else {fseek(fp,-1,1);printf("%s\t$取余运算符\n\n",Word);}break;default:printf("无法识别字符!\n\n"); break;}}}main(){char in_fn[30]; //文件路径FILE *fp;printf("\n请输入源文件名(包括路径和后缀名):");while(1){gets(in_fn);//scanf("%s",in_fn);if((fp=fopen(in_fn,"r"))!=NULL) break; //读取文件内容,并返回文件指针,该指针指向文件的第一个字符else printf("文件路径错误!请重新输入:");}printf("\n******************* 词法分析结果如下 *******************\n");do{ch=fgetc(fp);if(ch=='#') break; //文件以#结尾,作为扫描结束条件else if(ch==' '||ch=='\t'||ch=='\n'){} //忽略空格,空白,和换行else{fseek(fp,-1,1); //回退一个字节开始识别单词流scanner(fp);}}while(ch!='#');return(0);}4.实验结果解析源文件:void main(){int a=3;a+=b;printf("%d",a);return;}#解析结果:5.实验总结分析通过本次实验,让再次浏览了有关c语言的一些基本知识,特别是对文件,字符串进行基本操作的方法。

一、目的编译技术是理论与实践并重的课程,而其实验课要综合运用一、二年级所学的多门课程的内容,用来完成一个小型编译程序。
从而巩固和加强对词法分析、语法分析、语义分析、代码生成和报错处理等理论的认识和理解;培养学生对完整系统的独立分析和设计的能力,进一步培养学生的独立编程能力。
二、任务及要求基本要求:1.词法分析器产生下述小语言的单词序列这个小语言的所有的单词符号,以及它们的种别编码和内部值如下表:单词符号种别编码助记符内码值DIMIFDO STOP END标识符常数(整)=+***,()1234567891011121314$DIM$IF$DO$STOP$END$ID$INT$ASSIGN$PLUS$STAR$POWER$COMMA$LPAR$RPAR------内部字符串标准二进形式------对于这个小语言,有几点重要的限制:首先,所有的关键字(如IF﹑WHILE等)都是“保留字”。
所谓的保留字的意思是,用户不得使用它们作为自己定义的标示符。
例如,下面的写法是绝对禁止的:IF(5)=x其次,由于把关键字作为保留字,故可以把关键字作为一类特殊标示符来处理。
也就是说,对于关键字不专设对应的转换图。
但把它们(及其种别编码)预先安排在一张表格中(此表叫作保留字表)。
当转换图识别出一个标识符时,就去查对这张表,确定它是否为一个关键字。
再次,如果关键字、标识符和常数之间没有确定的运算符或界符作间隔,则必须至少用一个空白符作间隔(此时,空白符不再是完全没有意义的了)。
例如,一个条件语句应写为IF i>0 i= 1;而绝对不要写成IFi>0 i=1;因为对于后者,我们的分析器将无条件地将IFI看成一个标识符。
这个小语言的单词符号的状态转换图,如下图:2.语法分析器能识别由加+ 减- 乘* 除/ 乘方^ 括号()操作数所组成的算术表达式,其文法如下:E→E+T|E-T|TT→T*F|T/F|FF→P^F|Pp→(E)|i使用的算法可以是:预测分析法;递归下降分析法;算符优先分析法;LR分析法等。

一、实验目的设计一个简单的词法分析器,从而进一步加深对词法分析器工作原理的明白得。
二、实验要求一、该个词法分析器要求至少能够识别以下几类单词:(1)关键字:else if int return void while共6个,所有的关键字都是保留字,而且必需是小写;(2)标识符:识别与C语言词法规定相一致的标识符,通过以下正那么表达式概念:ID = letter (letter | digit)*;(3)常数:NUM = digit digit*(.digit digit* |ε)(e(+ | - |ε) digit digit* |ε),letter = a|..|z|A|..|Z|,digit = 0|..|9,包括整数,如123等;小数,如123.45等;科学计数法表示的常数,如1.23e3,2.3e-9等;(4)专用符号:+ - * / < <= > >= == != = ; , ( ) [ ] { } /* */;二、分析器的输入为由上述几类单词组成的程序,输出为该段程序的机内表示形式,即关键字、运算符、界限符变成其对应的机内符,常数利用二进制形式,标识符利用相应的标识符表指针表示。
3、词法分析器应当能够指出源程序中的词法错误,如不可识别的符号、错误的词法等。
三、实验环境实验环境为win7系统、vs2005。
四、实验内容1、词法分析程序的功能:输入:所给文法的源程序字符串。
输出:二元组(syn,token)或(sum或fsum,对应二进制)组成的序列。
其中:syn为单词类别码;token为寄存的单词自身字符串;sum为整型常数;fsum为浮点型常数。
二、各类单词符号类别码如下表:五、要紧函数说明一、程序全局变量char inputstr[300],token[8];//别离寄存程序段、组成单词符号的字符串char ch;//输入字符int syn;//单词字符的类别码int p;//缓冲区inputstr的指针int sum;//整型常量float fsum;//浮点型常量char *rwtab[6]={"else","if","int","return","void","while"};//关键字数组二、语法分析函数void scaner()该函数完成所有的语法分析,关于输入的程序片段,第一去掉空格和换行,然后逐字符分析,找出各个单词(存入token[8]),判别它们的类型(确信syn 值,若是是整数那么是sum值,若是是浮点数那么是fsum)。

词法分析器的设计与实现
1.定义词法规则:根据编程语言的语法规范,定义不同的词法规则,
如关键字、标识符、操作符、常量等。
每个词法规则由一个正则表达式或
有限自动机来描述。
2.构建有限自动机:根据词法规则,构建一个有限自动机(DFA)来
识别词法单元。
有限自动机是一种形式化模型,用于在输入字符序列上进
行状态转换。
3.实现状态转换函数:根据有限自动机的定义,实现状态转换函数。
状态转换函数接受一个输入字符,并返回当前状态和输出的词法单元。
4.实现输入缓冲区:为了方便词法分析器的实现,通常需要实现一个
输入缓冲区,用于存储源代码,并提供一些读取字符的函数。
5. 实现词法分析器:将前面实现的状态转换函数和输入缓冲区结合
起来,实现一个完整的词法分析器。
词法分析器可以使用迭代器模式,每
次调用next(函数来获取下一个词法单元。
6.处理错误情况:在词法分析过程中,可能会遇到一些错误情况,如
未定义的词法单元、不符合语法规范的词法单元等。
词法分析器需要能够
检测并处理这些错误情况。
7.构建测试用例:为了验证词法分析器的正确性,需要构建测试用例,包括各种不同的源代码片段,并验证分析结果是否符合预期。
8.进行性能优化:词法分析是编译器中的一个耗时操作,因此可以进
行一些性能优化,如使用缓存机制、减少状态转换次数等。
以上是词法分析器的设计与实现的一般步骤,具体实现过程可能因编程语言和编译器的不同而有所差异。
实验1-3 《编译原理》S语言词法分析程序设计方案一、实验目的了解词法分析程序的两种设计方法之一:根据状态转换图直接编程的方式;二、实验内容1.根据状态转换图直接编程编写一个词法分析程序,它从左到右逐个字符的对源程序进行扫描,产生一个个的单词的二元式,形成二元式(记号)流文件输出。
在此,词法分析程序作为单独的一遍,如下图所示。
词法分析程序二元式文件源程序具体任务有:(1)组织源程序的输入(2)拼出单词并查找其类别编号,形成二元式输出,得到单词流文件(3)删除注释、空格和无用符号(4)发现并定位词法错误,需要输出错误的位置在源程序中的第几行。
将错误信息输出到屏幕上。
(5)对于普通标识符和常量,分别建立标识符表和常量表(使用线性表存储),当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则返回0并且填写符号表或常量表。
标识符表结构:变量名,类型(整型、实型、字符型),分配的数据区地址注:词法分析阶段只填写变量名,其它部分在语法分析、语义分析、代码生成等阶段逐步填入。
常量表结构:常量名,常量值三、实验要求1.能对任何S语言源程序进行分析在运行词法分析程序时,应该用问答形式输入要被分析的S源语言程序的文件名,然后对该程序完成词法分析任务。
2.能检查并处理某些词法分析错误词法分析程序能给出的错误信息包括:总的出错个数,每个错误所在的行号,错误的编号及错误信息。
本实验要求处理以下两种错误(编号分别为1,2):1:非法字符:单词表中不存在的字符处理为非法字符,处理方式是删除该字符,给出错误信息,“某某字符非法”。
2:源程序文件结束而注释未结束。
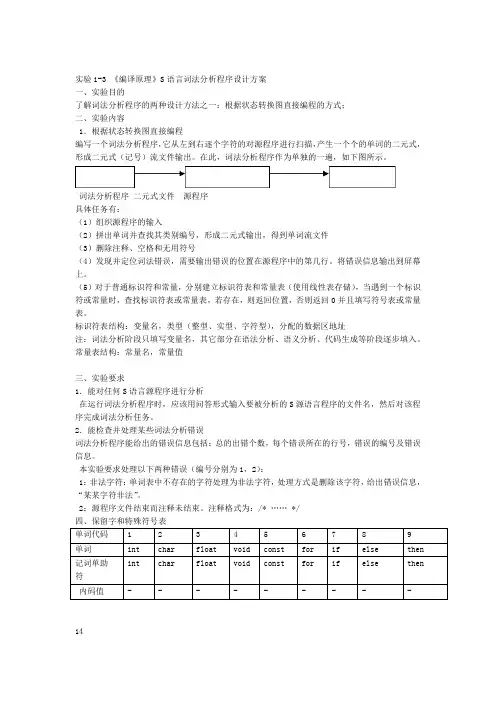
注释格式为:/* …… */四、保留字和特殊符号表141318171615121110单词代码.单词的构词规则:字母=[A-Za-z]数字=[0-9]标识符=(字母|_)(字母|数字)*=数字(数字)*(.数字|?)+数字四、S语言表达式和语句说明1.算术表达式:+、-、*、/、%2.关系运算符:>、>=、<、<=、==、!=3.赋值运算符:=,+=、-=、*=、/=、%=4.变量说明:类型标识符变量名表;5.类型标识符:int char float6.If语句:if 表达式then 语句 [else 语句]7.For语句:for(表达式1;表达式2;表达式3)语句 8.While语句:while 表达式 do 语句9.S语言程序:由函数构成,函数不能嵌套定义。

《编译原理》课程实验报告课程实验题目:词法分析器学院:计算机科学与技术班级:软件1503学号:04153094姓名:刘欣指导教师姓名:陈燕完成时间:词法分析定义:词法分析器的功能输入源程序,按照构词规则分解成一系列单词符号。
单词是语言中具有独立意义的最小单位,包括关键字、标识符、运算符、界符和常量等(1) 关键字是由程序语言定义的具有固定意义的标识符。
例如,Pascal 中的begin,end,if,while都是保留字。
这些字通常不用作一般标识符。
(2) 标识符用来表示各种名字,如变量名,数组名,过程名等等。
(3) 常数常数的类型一般有整型、实型、布尔型、文字型等。
(4) 运算符如+、-、*、/等等。
(5) 界符如逗号、分号、括号、等等。
输出:词法分析器所输出单词符号常常表示成如下的二元式:(单词种别,单词符号的属性值)单词种别通常用整数编码。
标识符一般统归为一种。
常数则宜按类型(整、实、布尔等)分种。
关键字可将其全体视为一种。
运算符可采用一符一种的方法。
界符一般用一符一种的方法。
对于每个单词符号,除了给出了种别编码之外,还应给出有关单词符号的属性信息。
单词符号的属性是指单词符号的特性或特征。
示例:比如如下的代码段:while(i>=j) i--经词法分析器处理后,它将被转为如下的单词符号序列:<while, _><(, _><id, 指向i的符号表项的指针><>=, _><id, 指向j的符号表项的指针><), _><id, 指向i的符号表项的指针><--, _><;, _>词法分析分析器作为一个独立子程序词法分析是编译过程中的一个阶段,在语法分析前进行。
词法分析作为一遍,可以简化设计,改进编译效率,增加编译系统的可移植性。
也可以和语法分析结合在一起作为一遍,由语法分析程序调用词法分析程序来获得当前单词供语法分析使用。
《编译原理》实验指导书实验一词法分析器的设计一、实验目的和要求加深对状态转换图的实现及词法分析器的理解。
熟悉词法分析器的主要算法及实现过程。
要求学生掌握词法分析器的设计过程,并实现词法分析。
二、实验基本内容给出一个简单语言的词法规则,画出状态转换图,并依据状态转换图编制出词法分析程序,能从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。
并依次输出各个单Error”,然后跳过错误部分继续显示)词法规则如下:三、实验时间:上机三次。
第一次按照自己的思路设计一个程序。
第二、三次在理论课学习后修改程序,使得程序结构更加合理。
四、实验过程和指导:(一)准备:1.阅读课本有关章节(c/c++,数据结构),花一周时间明确语言的语法,写出基本算法以及采用的数据结构和要测试的程序例。
2.初步编制好程序。
3.准备好多组测试数据。
(二)上课上机:将源代码拷贝到机上调试,发现错误,再修改完善。
(三)程序要求:程序输入/输出示例:输入如下一段:main(){/*一个简单的c++程序*/int a,b; //定义变量a = 10;b = a + 20;}要求输出如右图。
要求:(1) 剔除注解符(2) 常数为无符号整数(可增加实型数,字符型数等)(四)练习该实验的目的和思路:程序开始变得复杂起来,可能是大家以前编过的程序中最复杂的,但相对于以后的程序来说还是简单的。
因此要认真把握这个过渡期的练习。
程序规模大概为200行及以上。
通过练习,掌握对字符进行灵活处理的方法。
(五)为了能设计好程序,注意以下事情:1.模块设计:将程序分成合理的多个模块(函数/类),每个模块(类)做具体的同一事情。
2.写出(画出)设计方案:模块关系简图、流程图、全局变量、函数接口等。
3.编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。
4.程序设计语言不限,建议使用面向对象技术及可视化编程语言,如C++,VC,JA V A,VJ++等。
实验1识别器的实现1.实验目的:掌握简单识别程序的分析、设计与实现的基本技术与一般方法。
2.实验题目:(1)假设一个语言允许使用十六进制数,其规定是:必须以数字打头,必须以H结尾,数中允许使用的字母为A,B,C,D,E, F(分别表示10~15)。
该语言的标识符为字母开头的字母数字串。
试设计一个DFA,使它能识别标识符、无符号的十进制和十六进制整数(假定各单词之间用界限符或空格分开),并编制相应的识别程序。
输入:学生自行确定符号串的输入形式,如键盘输入、文本文件、字符数组等。
输出:标识出规范的符号串与不合规范的符号串。
3.实验要求:(1)上机前编写完整的实验报告,报告中要体现分析→设计→实现等几个过程;如无实验报告,则取消本次上机资格,实验成绩以0分记。
(2)严禁相互抄袭,否则实验成绩以0分记;(3)有完整的源代码,源码有规范的注释,无明显的语法错误;(4)实验报告必须是手写稿(包括源代码),要求书写工整,清晰有条理。
(5)不符合以上(3)、(4)要求者,扣除相应的实验分数。
4.实验步骤(1)分析与设计a)根据给定的语言求出其文法因为该语言的十六进制数,其规定是:必须以数字打头,必须以H结尾,数中允许使用的字母为A,B,C,D,E, F(分别表示10~15)。
该语言的标识符为字母开头的字母数字串。
则可得出该语言的文法可表示如下:S →X’|Y’|Z’(标识符) X’ →P’|P’M’P’ →β|γM’→α|β|γ|αM’|βM’|γM’(无符号十进制) Y’ →α|αY’(十六进制) Z’ →αH|αQ’H Q’→α|β|αQ’ |βQ’α= 0|1| 2|3|4|5|6|7|8|9β = a|b|c|d|e|f|A|B|C|D|E|Fγ = g| h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z|G|H|I|G|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Zb)将该文法转换成正规式由a)小题中M’ →α|β|γ|αM’|βM’|γM’表示为M’→(α|β|γ)*(α|β|γ)Y’ →α|αY’表示为Y’ →α*αQ’→α|β|αQ’ |βQ’表示为Q’→(α|β)*(α|β)则转换成正规表达式为:S= (β|γ) |(β|γ) (α|β|γ)*(α|β|γ) |αH | α(α|β)*(α|β)H |α*αc)由正规式构造NFA初始的NFA图下所示:图1 初始NFA图经过替换规则替换后得到的最终NFA图如下所示:图2 最终的NFA图d)将NFA转换成DFA,并将其最小化对应以上的NFA图,我们可用造表法来表示如下:显然,由图可看出,状态2与状态5等价,而状态1与状态3等价,这里省去状态3和状态5,并将所以指向状态3的状态都指向状态1,指向状态5的都指向状态2。
一.课程设计题目:词法分析器的实现二.课程设计成员三.课程设计内容和要求设计一个程序,调试、编译,实现词法分析的功能,识别各单词或字符所属类别,并显示在屏幕上。
词法分析器:逐个读入源程序字符并按照构词规则切分成一系列单词。
单词是语言中具有独立意义的最小单位,包括保留字、标识符、运算符、标点符号和常量等。
词法分析是编译过程中的一个阶段,在语法分析前进行。
也可以和语法分析结合在一起作为一遍,由语法分析程序调用词法分析程序来获得当前单词供语法分析使用。
要求:通过词法分析器能够实现以下五种类型如单词等的识别。
(1)关键字"begin","end","if","then","else","while","write","r ead"等,"do", "call","const","char","until","procedure","repeat"等(2)运算符:"+","-","*","/","="等(3)界符:"{","}","[","]",";",",",".","(",")",":"等(4)标识符(5)常量四.操作要求首先建立一个或多个文档,此处新建了两个文档,例:07196133.txt文本文档和zhaoxiaodong.txt文本文档,以供选择,各文本文档中都输入有不同的内容,运行程序,出现提示,输入文本文档的名称,即可对文本文档中的内容进行分析,并把分析结果输出显示在屏幕上。
编译原理实验报告实验一一、实验名称:词法分析器的设计二、实验目的:1,词法分析器能够识别简单语言的单词符号2,识别出并输出简单语言的基本字。
标示符。
无符号整数.运算符.和界符。
三、实验要求:给出一个简单语言单词符号的种别编码词法分析器四、实验原理:1、词法分析程序的算法思想算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号.2、程序流程图(1)主程序(2)扫描子程序3、各种单词符号对应的种别码五、实验内容:1、实验分析编写程序时,先定义几个全局变量a[]、token[](均为字符串数组),c,s( char型),i,j,k(int型),a[]用来存放输入的字符串,token[]另一个则用来帮助识别单词符号,s用来表示正在分析的字符.字符串输入之后,逐个分析输入字符,判断其是否‘#’,若是表示字符串输入分析完毕,结束分析程序,若否则通过int digit(char c)、int letter(char c)判断其是数字,字符还是算术符,分别为用以判断数字或字符的情况,算术符的判断可以在switch语句中进行,还要通过函数int lookup(char token[])来判断标识符和保留字。
2 实验词法分析器源程序:#include 〈stdio.h〉#include <math.h>#include <string。
h>int i,j,k;char c,s,a[20],token[20]={’0’};int letter(char s){if((s〉=97)&&(s〈=122)) return(1);else return(0);}int digit(char s){if((s〉=48)&&(s<=57)) return(1);else return(0);}void get(){s=a[i];i=i+1;}void retract(){i=i-1;}int lookup(char token[20]){if(strcmp(token,"while")==0) return(1);else if(strcmp(token,"if")==0) return(2);else if(strcmp(token,"else”)==0) return(3);else if(strcmp(token,"switch”)==0) return(4);else if(strcmp(token,"case")==0) return(5);else return(0);}void main(){printf(”please input string :\n");i=0;do{i=i+1;scanf("%c",&a[i]);}while(a[i]!=’#’);i=1;j=0;get();while(s!=’#'){ memset(token,0,20);switch(s){case 'a':case ’b':case ’c':case ’d':case ’e’:case ’f’:case 'g’:case ’h':case 'i':case ’j':case 'k’:case ’l':case 'm’:case 'n':case ’o':case ’p':case ’q’:case 'r’:case 's’:case 't’:case ’u’:case ’v’:case ’w’:case ’x':case ’y':case ’z’:while(letter(s)||digit(s)){token[j]=s;j=j+1;get();}retract();k=lookup(token);if(k==0)printf("(%d,%s)”,6,token);else printf("(%d,—)",k);break;case ’0':case ’1’:case ’2':case ’3':case '4’:case '5’:case ’6':case ’7’:case ’8’:case '9’:while(digit(s)){token[j]=s;j=j+1;get();}retract();printf(”%d,%s",7,token);break;case '+':printf(”(’+',NULL)”);break;case ’-':printf("(’-',null)");break;case ’*':printf(”('*’,null)");break;case '<':get();if(s=='=’) printf(”(relop,LE)”);else{retract();printf("(relop,LT)");}break;case ’=':get();if(s=='=’)printf("(relop,EQ)");else{retract();printf(”('=',null)”);}break;case ’;':printf(”(;,null)");break;case ' ’:break;default:printf("!\n”);}j=0;get();} }六:实验结果:实验二一、实验名称:语法分析器的设计二、实验目的:用C语言编写对一个算术表达式实现语法分析的语法分析程序,并以四元式的形式输出,以加深对语法语义分析原理的理解,掌握语法分析程序的实现方法和技术.三、实验原理:1、算术表达式语法分析程序的算法思想首先通过关系图法构造出终结符间的左右优先函数f(a),g(a)。
实验1-3 S语言词法分析器设计一、实验名称:S语言词法分析器设计二、实验目的:通过手工编写简化C语言词法分析器,熟悉并深入理解编译程序词法分析器的工作原理。
三、实验容:1.根据保留字和特殊符号表能区分出源文件中的保留字、普通标识符和特殊符号,并能进行简单的错误处理。
2.设计词法分析器模块调用结构图和各模块流程图。
3.程序源代码。
4.程序的执行结果:输入文件,输出结果文件及屏幕信息。
四、实验中出现的问题及解决方法。
遇到问题及解决:1、关于注释//和除号/。
需要区分,在isanotation函数中。
2、关于遇到空格时回退,一开始没有懂,后来经过同学讲解,明白了如何回退的。
3、关于词法分析器的思想过程,经过老师再三讲解,已经大致明白,具体步骤,在最后体会部分中。
五、程序结构和代码程序结构:代码:#include<stdio.h>#include<stdlib.h>#include<string>#include<iostream>using namespace std;//关键字表stringkeywords[20]={"include","void","main","int","c har","float","double","if","else","then","break"," continue","for","do","while","printf","scanf","be gin","end","return"};char aa[99999]=" ";//关键字表初始为空string id[10000];int pp=0;//常数表string nu[10000];int qq=0;//初始化函数void initscanner(){int i=0;FILE *fp;if((fp=fopen("源程序.txt","r"))==NULL)//打开源程序文件{printf("没有找到此文件!");exit(0);}char ch=fgetc(fp);while(ch!=EOF){aa[i]=ch;i++;ch=fgetc(fp);}fclose(fp);}int decide1(char a) //判断是否是字母{if((a>='a'&&a<='z')||(a>='A'&&a<='Z')) return 1;else return 0;}int decide2(char a) //判断是否是数字{if(a>='0'&&a<='9')return 1;else return 0;}int isalpha(int st) //识别保留字和标识符{char wordbuf[20]=" ";int n=0;for( ; ; ){wordbuf[n]=aa[st];st++;n++; if((decide2(aa[st])==1)||(decide1(aa[st])==1)||( aa[st]=='_'))wordbuf[n]=aa[st];else break;}int flag=0;for(int k=0;k<20;k++){if(strcmp(keywords[k].c_str(),wordbuf)==0) flag=1;}if(flag==0){int flagg=-1;for(int t=0;t<pp;t++){if(strcmp(id[t].c_str(),wordbuf)==0){flagg=t;}}if(flagg!=-1) printf(" (id,%d) ",flagg);else{id[pp]=wordbuf;printf(" (id,%d) ",pp);pp++;}}else{printf(" (");for(int i=0;i<n;i++){printf("%c",wordbuf[i]);}printf(",-) ");}return st;}int isnumber(int st) //识别数字{char numbuf[20]=" ";int n=0;int k=0;int flag=0;for( ; ; ){numbuf[n]=aa[st];st++;n++;if(decide2(aa[st])==1){numbuf[n]=aa[st];}else if((k==0)&&(aa[st]=='.')){numbuf[n]=aa[st];k++;}else if(decide1(aa[st])==1){numbuf[n]=aa[st];flag=1;continue;}else break;}if(flag==0){int flagg=-1;for(int t=0;t<qq;t++)if(strcmp(nu[t].c_str(),numbuf)==0)flagg=t;if(flagg!=-1) printf(" (nu,%d) ",flagg); else{nu[qq]=numbuf;printf(" (nu,%d) ",qq);qq++;}}else{printf(" (");for(int i=0;i<n;i++) printf("%c",numbuf[i]); printf(",错误) ");} return st;}int isanotation(int st) //处理除号/和注释{char tabuf[9999]=" ";int n=0;st++;if(aa[st]=='/'){printf(" (//,-) ");st++;while(aa[st]!=10){tabuf[n]=aa[st];st++;n++;}printf(" (");for(int i=0;i<n;i++)printf("%c",tabuf[i]);printf(",注释容) ");}else if(aa[st]=='*'){printf(" (/*,-) ");st++;int stt=st+1;while(1){if(aa[st]=='*'&&aa[st+1]=='/') break; tabuf[n]=aa[st];st++;n++;if(aa[st+1]==NULL){printf("(/* 错误\n)");return st+1;}} printf(" (");for(int i=0;i<n;i++)printf("%c",tabuf[i]);printf(",注释容) ");printf(" (*/,-) ");st=st+2;}else if(aa[st]=='='){st++;printf(" (/*,-) ");}else printf(" (/,-) ");return st;}int isother(int st) //函数识别其他特殊字符{switch(aa[st]){case '=': st++;if(aa[st]=='='){st++;printf(" (rlop,==) ");}else printf(" (rlop,=) ");break;case '+': st++;if(aa[st]=='='){st++;printf(" (+=,-) ");}else if(aa[st]=='+'){st++;printf(" (++,-) ");}else printf(" (+,-) ");break;case '-': st++;if(aa[st]=='='){st++;printf(" (-=,-) ");}else if(aa[st]=='-'){st++;printf(" (--,-) "); }else printf(" (-,-) "); break;case '*': st++;if(aa[st]=='='){st++;printf(" (*=,-) ");}else printf(" (*,-) "); break;case '>': st++;if(aa[st]=='='){st++;printf(" (rlop,>=) ");}else printf(" (rlop,>) "); break;case '<': st++;if(aa[st]=='='){st++;printf(" (rlop,<=) ");}else printf(" (rlop,<) "); break;case '%': st++;if(aa[st]=='='){st++;printf(" (\%=,-) ");}else printf(" (\%,-) "); break;case '!': st++;if(aa[st]=='='){st++;printf(" (!=,-) ");}else printf(" (!,错误!) "); break;case '&': st++;if(aa[st]=='&'){st++;printf(" (&&,-) ");}else printf(" (&,错误) "); break;case '|': st++;if(aa[st]=='|'){st++;printf(" (||,-) ");}else printf(" (|,错误) "); break;case '{': st++;printf(" ({,-) "); break;case '}': st++;printf(" (},-) "); break;case '(': st++;printf(" ((,-) "); break;case ')': st++;printf(" (),-) "); break;case '[': st++;printf(" ([,-) "); break;case ']': st++;printf(" (],-) "); break;case ':': st++;printf(" (:,-) "); break;case '#': st++;printf(" (#,-) "); break;case ';': st++;printf(" (;,-) "); break;case '.': st++;printf(" (.,-) "); break;case ',': st++;printf(" (,,-) ");break;case ' ': st++;break;case ' ': st++;break;case 10: st++;printf("\n");break;case 34: st++;printf(" (\",-) ");break;case 39: st++;printf(" (',-) ");break;default: printf(" (%c,错误) ",aa[st]);st++;}return st;}int lexscan(int st) //根据读入的单词的第一个字符确定调用不同的单词识别函数{if(decide1(aa[st])==1)//如果是字母st=isalpha(st);else if(decide2(aa[st])==1)//如果是数字st=isnumber(st);else if(aa[st]=='/')//如果是标识符或关键字st=isanotation(st);else st=isother(st);//其他特殊字符return st;}void scanner() //若文件未结束,反复调用lexscan函数识别单词{int i=0;while(aa[i]!=NULL)i=lexscan(i);}void print(){cout<<endl;cout<<endl<<"关键字、标示符表如下:"<<endl;cout<<"======================== ====================="<<endl;for(int i=0;i<pp;i++)cout<<i<<" "<<id[i]<<endl;cout<<"======================== ====================="<<endl; cout<<endl;cout<<"常数表如下:"<<endl;cout<<"======================== ====================="<<endl; for(int j=0;j<qq;j++)cout<<j<<" "<<nu[j]<<endl;cout<<"======================== ====================="<<endl;}void main(){ cout<<"二元式流如下:"<<endl;cout<<"======================== ====================="<<endl; initscanner();scanner();print();}程序执行结果截图:源程序截图:。