2.2 一个简单的词法分析器示例
- 格式:ppt
- 大小:156.50 KB
- 文档页数:20



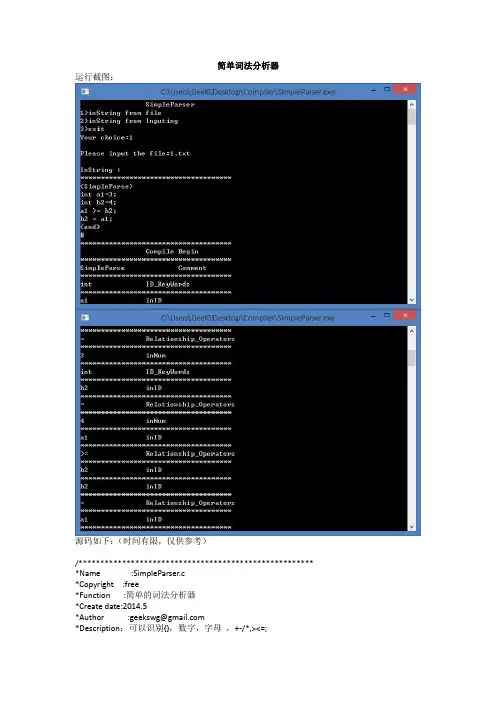
简单词法分析器运行截图:源码如下:(时间有限,仅供参考)/****************************************************** *Name :SimpleParser.c*Copyright :free*Function :简单的词法分析器*Create date:2014.5*Author :geekswg@*Description:可以识别{},数字,字母,+-/*,><=;******************************************************/ #include<stdio.h>//#include<stdbool.h>//C99包含bool头文件,VC6.0报错#include<memory.h>#include<string.h>//包含strcmp()函数//宏定义bool类型兼容VC6.0#define bool char#define true 1#define false 0#define MAXSIZE 500#define SOC '{' //start of comment#define EOC '}' //end of comment/*#define ADD +#define MIN -#define MUL *#define DIV /*/char inStr[MAXSIZE];//bool型,是否是关键字,是返回truebool isKeyword(char s1[],char s2[]){if(!strcmp(s1,s2))return true;elsereturn false;}//bool型,是否是数字,是返回truebool isDigit(char c){if(c > 47 && c<58){//ASCII(0-9)return true;}elsereturn false;}//bool型,是否是字符,是返回truebool isLetter(char c){if((c > 64 && c < 91) || (c >96 && c <123)){//A-Z,a-z)return true;}elsereturn false;}//读入待分析的字符串;void inFile(char inStr[]){FILE *fp;//文件指针int i = 0;char filename[50]; //文件名memset(filename,0,sizeof(filename)); //清空数组;printf("\nPlease input the file:");scanf("%s",&filename);// printf("\n%s",filename);while((fp = fopen(filename,"r"))==NULL){//以只读方式打开文件printf("\nCan't Find file!Input again:");scanf("%s",&filename);}while(!feof(fp)){//直到文件结束符停止fscanf(fp,"%c",&inStr[i]);//将文件中的数据写到inStr中i++;}inStr[i]='\0';fclose(fp);}//录入待分析的字符串;void inString(char inStr[]){//录入函数int i=0;char inchar;printf("SimpleParser For Test \n");printf("Please Inpuet Strings:(End of '#')\n:");while( inchar !='#'){//以#为结束符标志;scanf("%c",&inchar);inStr[i++] = inchar;}}/**********************************//打印数组//参数待分析字符串,备注信息字符串//***********************************/void display(char inStr[],char info[]){//打印数组int i = 0;printf("\n*************************************\n");while( inStr[i] != '\0' ){//直到数组结束标志printf("%c",inStr[i++]);//打印元素}printf("\t\t%s",info);// printf("\n*************************************\n");// printf("#\n");}/**********************************//parser for comment//参数待分析字符串,位置下标int i// 返回值位置下标int i***********************************/int parser_com(char inStr[],int i){//parser for comment"{}"char temp[MAXSIZE] ;//存放{}内的字符串memset(temp,0,sizeof(temp)); //清空数组,以防止第二次调用时有上次的字符串;int t=0;while(inStr[++i] != EOC){temp[t]=inStr[i];t++;}// printf("Comment \t:");display(temp,"Comment");return i;}/**********************************//parser for letter//参数待分析字符串,位置下标int i// 返回值位置下标int i***********************************/int parser_letter(char inStr[],int i){int t = 0;char temp[MAXSIZE];memset(temp,0,sizeof(temp)); //清空数组;while(isDigit(inStr[i]) || isLetter(inStr[i])){//如果是数字或字母temp[t++] = inStr[i];i++;}//判断是否是关键字,如需添加关键字添加else if即可//若使用关键字表应该效果更好if(isKeyword(temp,"int")){display(temp,"ID_KeyWords");}else if(isKeyword(temp,"char")){display(temp,"ID_KeyWords");}// printf("Letter \t:");else{display(temp,"inID");}return --i;}int parser_digit(char inStr[],int i){int t = 0;char temp[MAXSIZE];memset(temp,0,sizeof(temp)); //清空数组;while(inStr[i] != ' ' && inStr[i] != '\n' && isDigit(inStr[i])){ temp[t++] = inStr[i];i++;}// printf("Digit \t:");display(temp,"inNum");return --i;}/*// prasers for operators like "+,-,* /"//之后放入了parser()中了int parser_ops(char inStr[],int i){int t = 0;char temp[MAXSIZE];memset(temp,0,sizeof(temp)); 清空数组;return i;}*/// prasers for relationship operators like ">,<,="int parser_rel(char inStr[],int i){int t = 0;char temp[MAXSIZE];memset(temp,0,sizeof(temp)); //清空数组;while(inStr[i]=='>' || inStr[i]=='<' || inStr[i]=='='){temp[t] = inStr[i];t++;i++;}// printf("\nRelationship_Operator\t:");display(temp,"Relationship_Operators");return --i;}/**********************************//词法分析主程序,//参数待分析字符串//***********************************/void parser(char inStr[]){int i = 0;while(inStr[i] != '#'){/*switch(inStr[i]){case '{': i = pareser_com(inStr,i);break;//如果是{,使用case ' ': ;break; //如果是空格跳过case '+':;break;default:;break; //}*///之前使用switch,后来觉得if ,else更方便if(inStr[i] == SOC){//SOC'{'-start of commenti = parser_com(inStr,i);//如果是{,使用pareser_com;}else if(inStr[i] == '+'){display("+","Operator");}else if(inStr[i] == '-'){display("-","Operator");}else if(inStr[i] == '*'){display("*","Operator");}else if(inStr[i] == '/'){display("/","Operator");}else if(inStr[i]=='>' || inStr[i]=='=' || inStr[i]=='<'){i = parser_rel(inStr,i);//parser for relationship;}/*else if(inStr[i] > 47 && inStr[i] <58){//0-9;i = parser_digit(inStr,i);}*/else if(isDigit(inStr[i])){i = parser_digit(inStr,i);}/*else if((inStr[i] >64 && inStr[i]<91)|| (inStr[i]>96 && inStr[i] <123)){//A-Z,a-zi = parser_letter(inStr,i);}*/else if(isLetter(inStr[i])){i = parser_letter(inStr,i);}i++;}memset(inStr,0,sizeof(inStr));//清空数组;}//主菜单;void menu(){char choice;printf("\t\tSimpleParser\n");printf("1)inString from file\n2)inString from Inputing\n3)exit\n");printf("Your choice:");scanf("%c",&choice);while(choice!='1'&& choice!='2' && choice!='0' ){printf("\nerror,Your choice:");scanf("%c",&choice);}switch(choice){case '0':{system("PAUSE");exit(0);};break;case '1':inFile(inStr); break;case '2':inString(inStr); break;default:;break;}}int main(){/*inString(inStr);inFile(inStr);*/menu();printf("\nInString :");display(inStr,"\n*************************************");printf("\n\t\tCompile Begin");parser(inStr);system("PAUSE"); //调用系统暂停return 0;}。
词法分析c实现一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的C语言程序源代码:#include <stdio.h>#include <string.h>char prog[80],token[8],ch;int syn,p,m,n,sum;char *rwtab[6]={"begin","if","then","while","do","end"};scaner();main(){p=0;printf("\n please input a string(end with '#'):/n");do{scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;do{scaner();switch(syn){case 11:printf("( %-10d%5d )\n",sum,syn);break;case -1:printf("you have input a wrong string\n");getch();exit(0);default: printf("( %-10s%5d )\n",token,syn);break;}}while(syn!=0);getch();}scaner(){ sum=0;for(m=0;m<8;m++)token[m++]=NULL;ch=prog[p++];m=0;while((ch==' ')||(ch=='\n'))ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){ syn=n+1;break;}}else if((ch>='0')&&(ch<='9')) { while((ch>='0')&&(ch<='9')) { sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=22;token[m++]=ch;}else{ syn=20;p--;}break;case '>':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=24;token[m++]=ch;}else{ syn=23;p--;}break;case '+': token[m++]=ch;ch=prog[p++];if(ch=='+'){ syn=17;token[m++]=ch;}else{ syn=13;p--;}break;ch=prog[p++];if(ch=='-'){ syn=29;token[m++]=ch;}else{ syn=14;p--;}break;case '!':ch=prog[p++];if(ch=='='){ syn=21;token[m++]=ch;}else{ syn=31;p--;}break;case '=':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=25;token[m++]=ch;}else{ syn=18;p--;}break;case '*': syn=15;token[m++]=ch;break;case '/': syn=16;token[m++]=ch;break;case '(': syn=27;token[m++]=ch;break;case ')': syn=28;break;case '{': syn=5;token[m++]=ch;break;case '}': syn=6;token[m++]=ch;break;case ';': syn=26;token[m++]=ch;break;case '\"': syn=30;token[m++]=ch;break;case '#': syn=0;token[m++]=ch;break;case ':':syn=17;token[m++]=ch;break;default: syn=-1;break;}token[m++]='\0';}四、结果分析:输入begin x:=9: if x>9 then x:=2*x+1/3; end # 后经词法分析输出如下序列:(begin 1)(x 10)(:17)(= 18)(9 11)(;26)(if 2)……如图5-1所示:。


词法分析器实验报告一、实验目的及要求本次实验通过用C语言设计、编制、调试一个词法分析子程序,识别单词,实现一个C语言词法分析器,经过此过程可以加深对编译器解析单词流的过程的了解。
运行环境:硬件:windows xp软件:visual c++6.0二、实验步骤1.查询资料,了解词法分析器的工作过程与原理。
2.分析题目,整理出基本设计思路。
3.实践编码,将设计思想转换用c语言编码实现,编译运行。
4.测试功能,多次设置包含不同字符,关键字的待解析文件,仔细察看运行结果,检测该分析器的分析结果是否正确。
通过最终的测试发现问题,逐渐完善代码中设置的分析对象与关键字表,拓宽分析范围提高分析能力。
三、实验内容本实验中将c语言单词符号分成了四类:关键字key(特别的将main说明为主函数)、普通标示符、常数和界符。
将关键字初始化在一个字符型指针数组*key[]中,将界符分别由程序中的case列出。
在词法分析过程中,关键字表和case列出的界符的内容是固定不变的(由程序中的初始化确定),因此,从源文件字符串中识别出现的关键字,界符只能从其中选取。
标识符、常数是在分析过程中不断形成的。
对于一个具体源程序而言,在扫描字符串时识别出一个单词,若这个单词的类型是关键字、普通标示符、常数或界符中之一,那么就将此单词以文字说明的形式输出.每次调用词法分析程序,它均能自动继续扫描下去,形成下一个单词,直到整个源程序全部扫描完毕,从而形成相应的单词串。
输出形式例如:void $关键字流程图、程序流程图:程序:#include<string.h>#include<stdio.h>#include<stdlib.h>#include<ctype.h>//定义关键字char*Key[10]={"main","void","int","char","printf","scanf","else","if","return"}; char Word[20],ch; // 存储识别出的单词流int IsAlpha(char c) { //判断是否为字母if(((c<='z')&&(c>='a'))||((c<='Z')&&(c>='A'))) return 1;else return 0;}int IsNum(char c){ //判断是否为数字if(c>='0'&&c<='9') return 1;else return 0;}int IsKey(char *Word){ //识别关键字函数int m,i;for(i=0;i<9;i++){if((m=strcmp(Word,Key[i]))==0){if(i==0)return 2;return 1;}}return 0;}void scanner(FILE *fp){ //扫描函数char Word[20]={'\0'};char ch;int i,c;ch=fgetc(fp); //获取字符,指针fp并自动指向下一个字符if(IsAlpha(ch)){ //判断该字符是否是字母Word[0]=ch;ch=fgetc(fp);i=1;while(IsNum(ch)||IsAlpha(ch)){ //判断该字符是否是字母或数字Word[i]=ch;i++;ch=fgetc(fp);}Word[i]='\0'; //'\0' 代表字符结束(空格)fseek(fp,-1,1); //回退一个字符c=IsKey(Word); //判断是否是关键字if(c==0) printf("%s\t$普通标识符\n\n",Word);//不是关键字else if(c==2) printf("%s\t$主函数\n\n",Word);else printf("%s\t$关键字\n\n",Word); //输出关键字 }else //开始判断的字符不是字母if(IsNum(ch)){ //判断是否是数字Word[0]=ch;ch=fgetc(fp);i=1;while(IsNum(ch)){Word[i]=ch;i++;ch=fgetc(fp);}Word[i]='\0';fseek(fp,-1,1); //回退printf("%s\t$无符号实数\n\n",Word);}else //开始判断的字符不是字母也不是数字{Word[0]=ch;switch(ch){case'[':case']':case'(':case')':case'{':case'}':case',':case'"':case';':printf("%s\t$界符\n\n",Word); break;case'+':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word);//运算符“+=”}else if(ch=='+'){printf("%s\t$运算符\n\n",Word); //判断结果为“++”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“+”}break;case'-':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word); }else if(ch=='-'){printf("%s\t$运算符\n\n",Word); //判断结果为“--”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“-”}break;case'*':case'/':case'!':case'=':ch=fgetc(fp);if(ch=='='){printf("%s\t$运算符\n\n",Word);}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word);}break;case'<':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word); //判断结果为运算符“<=”}else if(ch=='<'){printf("%s\t$运算符\n\n",Word); //判断结果为“<<”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“<”}break;case'>':ch=fgetc(fp);Word[1]=ch;if(ch=='=') printf("%s\t$运算符\n\n",Word);else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word);}break;case'%':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word);}if(IsAlpha(ch)) printf("%s\t$类型标识符\n\n",Word);else {fseek(fp,-1,1);printf("%s\t$取余运算符\n\n",Word);}break;default:printf("无法识别字符!\n\n"); break;}}}main(){char in_fn[30]; //文件路径FILE *fp;printf("\n请输入源文件名(包括路径和后缀名):");while(1){gets(in_fn);//scanf("%s",in_fn);if((fp=fopen(in_fn,"r"))!=NULL) break; //读取文件内容,并返回文件指针,该指针指向文件的第一个字符else printf("文件路径错误!请重新输入:");}printf("\n******************* 词法分析结果如下 *******************\n");do{ch=fgetc(fp);if(ch=='#') break; //文件以#结尾,作为扫描结束条件else if(ch==' '||ch=='\t'||ch=='\n'){} //忽略空格,空白,和换行else{fseek(fp,-1,1); //回退一个字节开始识别单词流scanner(fp);}}while(ch!='#');return(0);}4.实验结果解析源文件:void main(){int a=3;a+=b;printf("%d",a);return;}#解析结果:5.实验总结分析通过本次实验,让再次浏览了有关c语言的一些基本知识,特别是对文件,字符串进行基本操作的方法。


编译原理第三章练习题答案一、选择题1. 在编译原理中,词法分析器的作用是什么?A. 将源代码转换为汇编代码B. 将源代码转换为中间代码C. 识别源代码中的词法单元D. 检查源代码的语法正确性答案:C2. 词法单元中,标识符和关键字的区别是什么?A. 标识符可以重定义,关键字不可以B. 标识符和关键字都是常量C. 标识符是用户自定义的,关键字是语言预定义的D. 标识符和关键字都是变量名答案:C3. 下列哪个不是词法分析器生成的属性?A. 行号B. 列号C. 词法单元的类型D. 词法单元的值答案:A4. 词法分析器通常使用哪种数据结构来存储词法单元?A. 栈B. 队列C. 链表D. 数组答案:C5. 词法分析器的实现方法有哪些?A. 手工编写正则表达式B. 使用词法分析器生成器C. 编写扫描程序D. 所有上述方法答案:D二、简答题1. 简述词法分析器的基本工作流程。
答案:词法分析器的基本工作流程包括:读取源代码字符,根据正则表达式匹配词法单元,生成词法单元的类型和值,并将它们作为输出。
2. 什么是正规文法?它在词法分析中有什么作用?答案:正规文法是一种形式文法,它使用正则表达式来定义语言的词法结构。
在词法分析中,正规文法用于描述程序设计语言的词法规则,帮助词法分析器识别和生成词法单元。
三、应用题1. 给定一个简单的词法分析器,它需要识别以下词法单元:标识符、关键字(如if、while)、整数、运算符(如+、-、*、/)、分隔符(如逗号、分号)。
请描述该词法分析器的实现步骤。
答案:实现步骤如下:- 定义词法单元的类别和对应的正则表达式。
- 读取源代码字符,逐个字符进行匹配。
- 使用状态机或有限自动机来识别词法单元。
- 根据匹配结果生成相应的词法单元类型和值。
- 输出识别的词法单元。
2. 设计一个简单的词法分析器,它可以识别以下C语言关键字:int, float, if, else, while, return。


编译原理课程设计教案一、课程简介1.1 课程背景编译原理是计算机科学与技术领域的基础课程,旨在培养学生对编译器设计和实现的理解。
通过本课程的学习,学生将掌握编译器的基本原理、构造方法和实现技巧。
1.2 课程目标(1)理解编译器的基本概念、工作原理和分类;(2)熟悉源程序的词法分析、语法分析、语义分析、中间代码、目标代码和优化等基本过程;(3)掌握常用的编译器构造方法和技术;(4)能够设计和实现简单的编译器。
二、教学内容2.1 词法分析(1)词法规则的定义和描述;(2)词法分析器的实现方法;(3)词法分析在编译器中的作用和重要性。
2.2 语法分析(1)语法规则的定义和描述;(2)语法分析树的构建方法;(3)常用的语法分析算法及其特点。
2.3 语义分析(1)语义规则的定义和描述;(2)语义分析的方法和技巧;(3)语义分析在编译器中的作用和重要性。
2.4 中间代码(1)中间代码的定义和表示;(2)中间代码的方法和策略;(3)中间代码在编译器中的作用和重要性。
2.5 目标代码和优化(1)目标代码的方法和技巧;(2)代码优化的方法和策略;(3)目标代码和优化在编译器中的作用和重要性。
三、教学方法3.1 讲授法通过讲解编译原理的基本概念、理论和方法,使学生掌握编译器的设计和实现技巧。
3.2 案例分析法分析实际编译器的设计和实现案例,使学生更好地理解编译原理的应用。
3.3 实验法安排实验课程,让学生动手设计和实现简单的编译器组件,提高学生的实际操作能力。
3.4 小组讨论法组织学生进行小组讨论,培养学生的团队合作精神和沟通能力。
四、教学评价4.1 平时成绩包括课堂表现、作业完成情况和小测验成绩,占总评的30%。
4.2 实验成绩包括实验报告和实验演示,占总评的30%。
4.3 期末考试包括理论知识考核和实际操作考核,占总评的40%。
五、教学资源5.1 教材推荐使用《编译原理》教材,为学生提供系统、全面的学习资料。
5.2 课件制作精美、清晰的课件,辅助课堂教学。
词法分析实验报告一、实验目的与要求:1、了解字符串编码组成的词的内涵,感觉一下字符串编码的方法和解读2、了解和掌握自动机理论和正规式理论在词法分析程序和控制理论中的应用二、实验内容:构造一个自己设计的小语言的词法分析器:1、这个小语言能说明一些简单的变量识别诸如begin,end,if,while等保留字;识别非保留字的一般标识符(有下划线、字符、数字,且第一个字符不能是数字)。
识别数字序列(整数和小数);识别:=,<=,>=之类的特殊符号以及;,(,)等界符。
2、相关过程(函数):Scanner()词法扫描程序,提取标识符并填入display表中3、这个小语言有顺序结构的语句4、这个小语言能表达分支结构的语句5、这个小语言能够输出结果总之这个小语言词法分析器能提供以上所说明到的语法描述的功能……三、实验步骤:1、测试评价(1)、测试1:能说明一些简单的变量,如关键字、一般标识符、界符等;(2)、测试2:能输出结果:单词符号(内码形式)、各种信息表(如符号表、常量表等);(3)、测试程序:var x,y,z;beginx:=2;y:=3;if (x+5>=y*y) thenbeginz:=y*y-x;z:=z+x*x;endelsez:=x+y;prn z;end.(4)、结果:①、从键盘读入;部分结果如下:(类型:该标识符所属的类型,如关键字,变量等;下标:该标识符所对应表(如变量标识符表,常量标识符表等)中其相应的位置,下同)②、从文件读入,输出到文件;部分结果如下:其他测试及结果如下:③、出错处理;注:若有错误,则只指出错误,不输出各个表;(5)、评价:这个小语言程序基本上能完成词法分析阶段的工作,识别诸如begin,if等保留字;识别非保留字的一般标识符(有下划线、字符、数字,且第一个字符不能是数字)。
识别数字序列(整数和小数);识别:=,<=,>=之类的特殊符号以及;,(,)等界符。
简单的C语⾔编译器--词法分析器1. 定义词法单元Tag ⾸先要将可能出现的词进⾏分类,可以有不同的分类⽅式。
如多符⼀类:将所有逗号、分号、括号等都归为⼀类,或者⼀符⼀类,将⼀个符号归为⼀类。
我这⾥采⽤的是⼀符⼀类的⽅式。
C代码如下:#ifndef TAG_H#define TAG_Hnamespace Tag {//保留字const intINT = 1, BOOL = 2, MAIN = 3, IF = 4,ELSE = 5, FOR = 6, WHILE = 7, FALSE = 8,BREAK = 9, RETURN = 10, TRUE = 11 ;//运算符const intNOT = 20, NE = 21, AUTOMINUS =22, MINUS = 23,AUTOADD = 24, ADD = 25, OR = 26,AND = 27, MUTIPLY = 28, DIVIDE = 29, MOD = 30,EQ = 31, ASSIN = 32, GE = 33, GT = 34,LE = 35, LS = 36;//分界符const intCOMMA = 40, SEMICOLON = 41, LLBRACKET = 42,RLBRACKET = 43, LMBRACKET = 44, RMBRACKET = 45,LGBRACKET = 46, RGBRACKET = 47;//整数常数const int NUM = 50;//标识符const int ID = 60;//错误const int ERROR = 404;//空const int EMPTY = 70;}#endif2. 具体步骤⼀个⼀个字符地扫描测试代码,忽略空⽩字符,遇到回车时,记录⾏数加1要进⾏区分标识符(即普通变量名字)和保留字因为将标识符和常数都guiwe各⾃归为⼀类,所以要有算法能够识别出⼀整个常数和完整的标识符加⼊适当的⾮法词检测3. 设计词法分析类 设计⼀个词法分析器,当然要包括如何存储⼀个词法单元,如何扫描(scan)测试代码等,直接上代码:myLexer.h#ifndef MYLEXER_H#define MYLEXER_H#include <fstream>#include <string>#include <unordered_map>#include "tag.h"/** 主要是定义基本的词法单元类,* 声明了词法分析类*///存储词法单元class Word {public:Word() = default;Word(std::string s, int t) : lexeme(s), tag(t) {};std::string getLexeme() { return lexeme; };int getTag() { return tag; }void setTag(int t) { tag = t; }void setLexeme(std::string s) { lexeme = s; }private:std::string lexeme;int tag;};//词法分析器类class Lexer {public:Lexer();void reserve(Word w);bool readnext(char c, std::ifstream &in);Word scan(std::ifstream &in);int getLine() { return line; }private:char peek;std::unordered_map<std::string, Word> words;int line;};#endifmyLexer.cpp#include <iostream>#include <cctype>#include <sstream>#include "myLexer.h"void Lexer::reserve(Word w) {words.insert({w.getLexeme(), w});}Lexer::Lexer() {//存⼊保留字,为了区分标识符reserve( Word("int", Tag::INT) );reserve( Word("bool", Tag::BOOL) );reserve( Word("main", Tag::MAIN) );reserve( Word("if", Tag::IF) );reserve( Word("else", Tag::ELSE) );reserve( Word("for", Tag::FOR) );reserve( Word("while", Tag::WHILE) );reserve( Word("break", Tag::BREAK) );reserve( Word("return", Tag::RETURN) );reserve( Word("true", Tag::TRUE) );reserve( Word("false", Tag::FALSE) );peek = ' ';line = 1;}//⽅便处理像>=,++等这些两个字符连在⼀起的运算符 bool Lexer::readnext(char c, std::ifstream &in) {in >> peek;if( peek != c)return false;peek = ' ';return true;}Word Lexer::scan(std::ifstream &in) {//跳过空⽩符while(!in.eof()) {if(peek == ' ' || peek == '\t') {in >> peek;continue;}else if(peek == '\n')++line;elsebreak;in >> peek;}//处理分界符、运算符等switch(peek) {case '!':if(readnext('=', in))return Word("!=", Tag::NE);elsereturn Word("!", Tag::NOT);case '-':if(readnext('-', in))return Word("--", Tag::AUTOMINUS);elsereturn Word("-", Tag::MINUS);case '+':if(readnext('+', in))return Word("++", Tag::AUTOADD);elsereturn Word("+", Tag::ADD);case '|':if(readnext('|', in))return Word("||", Tag::OR);elsereturn Word("error", Tag::ERROR);case '&':if(readnext('&', in))return Word("&&", Tag::AND);elsereturn Word("error", Tag::ERROR);case '*':in >> peek;return Word("*", Tag::MUTIPLY);case '/':in >> peek;return Word("/", Tag::DIVIDE);case '%':in >> peek;return Word("%", Tag::MOD);case '=':if(readnext('=', in))return Word("==", Tag::EQ);elsereturn Word("=", Tag::ASSIN);case '>':if(readnext('=', in))return Word(">=", Tag::GE);elsereturn Word(">", Tag::GT);case '<':if(readnext('=', in))return Word("<=", Tag::LE);elsereturn Word("<", Tag::LS);case ',':in >> peek;return Word(",", Tag::COMMA);case ';':in >> peek;return Word(";", Tag::SEMICOLON);case '(':in >> peek;return Word("(", Tag::LLBRACKET);case ')':in >> peek;return Word(")", Tag::RLBRACKET);case '[':in >> peek;return Word("[", Tag::LMBRACKET);case ']':in >> peek;return Word("]", Tag::RMBRACKET);case '{':in >> peek;return Word("{", Tag::LGBRACKET);case '}':in >> peek;return Word("}", Tag::RGBRACKET);}//处理常数if(isdigit(peek)) {int v = 0;do {v = 10*v + peek - 48;in >> peek;} while(isdigit(peek));if(peek != '.')return Word(std::to_string(v), Tag::NUM);}//处理标识符if(isalpha(peek)) {std::ostringstream b;do {b << peek;in >> peek;} while(isalnum(peek) || peek == '_');std::string tmp = b.str();//判断是否为保留字if(words.find(tmp) != words.end())return words[tmp];elsereturn Word(tmp, Tag::ID);}if(peek != ' ' && peek != '\t' && peek != '\n')return Word("error", Tag::ERROR);return Word("empty", Tag::EMPTY);} 设计完成后,⾃⼰写⼀个Main函数,在while循环中调⽤scan函数,每次打印出Word内容,就能够得到。
实验一词法分析程序设计与实现一、实验目的:加深对词法分析器的工作过程的理解;加强对词法分析方法的掌握;能够采用一种编程语言实现简单的词法分析程序;能够使用自己编写的分析程序对简单的程序段进行词法分析。
二、实验内容:自定义一种程序设计语言,或者选择已有的一种高级语言(C语言),编制它的词法分析程序。
词法分析程序的实现可以采用任何一种编程工具。
三、实验要求:1. 对单词的构词规则有明确的定义;2. 编写的分析程序能够正确识别源程序中的单词符号;3. 识别出的单词以<种别码,值>的形式保存在符号表中;4. 词法分析中源程序的输入以.c格式,分析后的符号表保存在.txt文件中。
5. *对于源程序中的词法错误,能够做出简单的错误处理,给出简单的错误提示,保证顺利完成整个源程序的词法分析;6. 实验报告要求用自动机或者文法的形式对词法定义做出详细说明,说明词法分析程序的工作过程,说明错误处理的实现*。
四、实验学时:12学时五、实验步骤:1. 定义目标语言的可用符号表和构词规则;2. 依次读入源程序符号,对源程序进行单词切分和识别,直到源程序结束;3. 对正确的单词,按照它的种别以<种别码,值>的形式保存在符号表中;4. *对不正确的单词,做出错误处理*。
词法分析(Lexical Analysis) 是编译的第一阶段。
词法分析器的主要任务是读入源程序的输入字符、将他们组成词素,生成并输出一个词法单元序列,每个词法单元对应一个词素。
这个词法单元序列被输出到语法分析器进行语法分析。
知识储备词法单元:由一个词法单元名和一个可选的属性值组成。
词法单元名是一个表示某种词法单位的抽象符号,比如一个特定的关键字,或者代表一个标识符的输入字符序列。
词法单元名字是由语法分析器处理的输入符号。
模式:描述了一个词法单元的词素可能具有的形式。
词素:源程序中的一个字符序列,它和某个词法单元的模式匹配,并被词法分析器识别为该词法单元的一个实例。
写⼀个简单的C词法分析器写⼀个简单的C词法分析器在写本⽂过程中,我参考了《》中的⼀些内容。
这⾥我们主要讨论写⼀个C语⾔的词法分析器。
⼀、关键字⾸先,C语⾔中关键字有:auto、break、case、char、const、continue、default、do、double、else、enum、extern、float、for、goto、if、int、long、register、return、short、signed、sizeof、static、struct、switch、typedef、unsigned、union、void、volatile、while等共32个关键字。
⼆、运算符C语⾔中的运算符有:(、)、[、]、->、.、!、~、++、--、-、()、*、&、*、/、%、+、-、<<、>>、<、<=、>、>=、==、!=、&、^、|、&&、||、?:、=、+=、-=、*=、/=、%=、&=、^=、|=、<<=、>>=、,、等共45个运算符。
说明:-减号与-负号在词法阶段⽆法判别,需要在语法或予以阶段判别;同理*乘号与*指针操作符也是这样的。
三、界符另外C语⾔还有以下界符:;、{、}、:四、标⽰符C语⾔中标⽰符的定义为:开头可以是下划线或字母,后⾯可以是下划线、字母或数字。
五、常数整形数和浮点数六、空⽩符C语⾔中的空⽩符有:空格符、制表符、换⾏符,这些空⽩符在词法分析阶段可以被忽略。
七、注释C语⾔中的注释形式为:/*…*/,可以多⾏注释。
下⾯我们给出C程序中token和其对应的种别码:单词符号种别码单词符号种别码单词符号种别码auto1union28[55break2unsigned29]56case3void30^57char4volatile31^=58const5while32{59continue6-33|60default7--34||61do8-=35|=62double9->36}63else10!37~64enum11!=38+65extern12%39++66float13%=40+=67for14&41< 68goto15&&42<< 69if16&=43<<=70int17(44<=71long18)45=72sizeof2350>>=77static2451"78struct2552/*注释*/79switch2653常数80typedef2754标识符81我们的词法分析程序根据所给的源代码程序,输出的是⼆元组:<单词符号, 种别码>。
写⼀个整数四则运算的解析器——词法分析部分写⼀个简单的词法、语法分析器,来最终分析出整数四则运算表达式的结果。
为了简化词语法分析我们只允许出现0~9,+,-,*,/,空格,\r, \n这⼏个字符词法分析:⽅法1. 状态机我们先准备3个判断⽅法:// 是否是数字function isNum(letter) {return letter === '0' || letter === '1' || letter === '2' || letter === '3' || letter === '4' || letter === '5' || letter === '0' || letter === '6' || letter === '7' || letter === '8' || letter === '9' }// 是否是运算符function isOperater(letter) {return letter === '+' || letter === '-' || letter === '*' || letter === '/'}// 是否是间隔符function isEmptyLetter(letter) {return letter === ' ' || letter === '\r' || letter === '\n'}定义⽣成token的函数:const tokenList = []function generateToken(type, token) {console.log("⽣成token: " + token);tokenList.push({type, token});}定义状态转移函数:let token = []function startToken(letter) {if (isNum(letter)) {// 如果是数字,则进⼊inNumber状态token.push(letter)return inNumber} else if (isOperater(letter)) {// 如果是+-*/, 就马上⽣成⼀个tokengenerateToken(letter, letter)return startToken} else if (isEmptyLetter(letter)) {// 如果是空⽩字符,则跳过return startToken} else {// 如果是其他字符则报错throw new Error('出现意外字符')}}function inNumber(letter) {if (isNum(letter)) {token.push(letter)return inNumber} else {// 直到遇到⾮数字, 把前⾯push的数字⽣成⼀个数字token, 然后清空tokengenerateToken('number', token.join(''))token = []// 最后让新的letter马上执⾏⼀次startTokenreturn startToken(letter)}}开始词法分析:// 要词法分析的字符串const str = '123* 656 - 644 + 3131'// 分割成⼀个个字母let strArr = str.split('');// 定义状态机let state = startToken// 遍历字母,不停地更新状态机for(let letter of strArr) {state = state(letter)}// 结束state(Symbol('EOF'))generateToken('EOF', 'EOF')得出结果:⽅法2. 正则分析// 要词法分析的字符串let str = '123* 656 - 644 + 3131'// 过滤间隔符str = str.replace(/[\r\n ]/g, '')const operatorRegExp = /[+\-*/]/g// 获取运算的数字tokenlet numList = str.split(operatorRegExp)// 获取运算符tokenlet operatorList = str.match(operatorRegExp)const tokenList = []numList.forEach((item, idx) => {tokenList.push({type: 'number', token: item})if (idx !== numList.length - 1) {tokenList.push({type: operatorList[idx], token: operatorList[idx]}) }})// 结束tokenList.push({type: 'EOF', token: 'EOF'})console.log(tokenList)得出结果:到这⾥词法分析就已经完成了。