4章-核酸序列分析报告
- 格式:ppt
- 大小:14.99 MB
- 文档页数:131







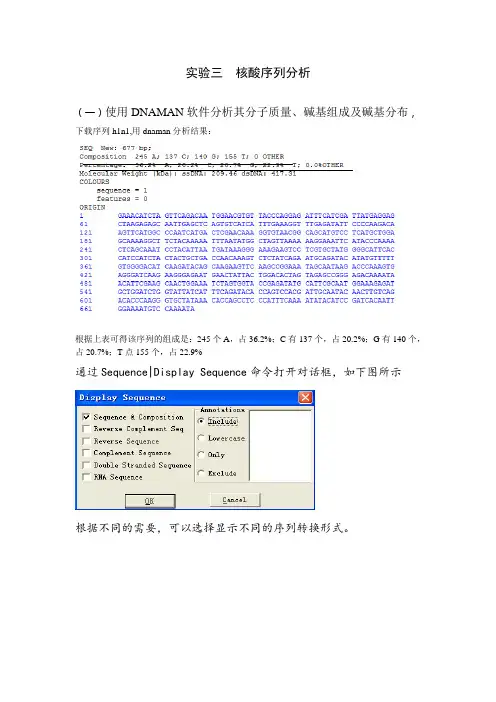
实验三核酸序列分析(一)使用DNAMAN软件分析其分子质量、碱基组成及碱基分布,下载序列h1n1,用dnaman分析结果:根据上表可得该序列的组成是:245个A,占36.2%;C有137个,占20.2%;G有140个,占20.7%;T点155个,占22.9%通过Sequence|Display Sequence命令打开对话框,如下图所示根据不同的需要,可以选择显示不同的序列转换形式。
点击Restriction/Restriction Analysis,选择其中一些参数,可分析当前Channel序列酶切位点。
参数说明如下:Results 分析结果显示其中包括:Show summary(显示概要)Show sites on sequence(在结果中显示酶切位点)Draw restriction map(显示限制性酶切图)Draw restriction pattern(显示限制性酶切模式图)Ignore enzymes with more than(忽略切点多于设定的切点个数的酶)Ignore enzymes with less than(忽略切点少于设定的切点个数的酶)Target DNA (目标DNA特性)circular(环型DNA),dam/dcm methylation(dam/dcm甲基化)all DNA in Sequence Channel(选择此项,在Sequence Channel 中的所有序列将被分析,如果选择了Draw restriction pattern,那么当所有的channel中共有两条DNA时,则只能选择两个酶分析,如果共有三个以上DNA时,则只能用一个酶分析。
限制性酶切分析进行PCR引物设计:构建系统发育树点击左上角按钮,可以从弹出的对话框中选择不同的结果显示特性选项。
点击按钮下的按钮,出现下列选择项:可以通过这些选项,绘制同源关系图(例如Tree|homology tree命令)。


核酸序列分析【实验目的】1、掌握已知或未知序列接受号的核酸序列检索的基本步骤;2、掌握使用BioEdit软件进行核酸序列的基本分析;3、熟悉基于核酸序列比对分析的真核基因结构分析(内含子/外显子分析);4、了解基因的电子表达谱分析。
【实验原理】针对核酸序列的分析就是在核酸序列中寻找基因,找出基因的位置和功能位点的位置,以及标记已知的序列模式等过程。
在此过程中,确认一段DNA序列是一个基因需要有多个证据的支持。
一般而言,在重复片段频繁出现的区域里,基因编码区和调控区不太可能出现;如果某段DNA片段的假想产物与某个已知的蛋白质或其它基因的产物具有较高序列相似性的话,那么这个DNA片段就非常可能属于外显子片段;在一段DNA序列上出现统计上的规律性,即所谓的"密码子偏好性",也是说明这段DNA是蛋白质编码区的有力证据;其它的证据包括与"模板"序列的模式相匹配、简单序列模式如TATA Box等相匹配等。
一般而言,确定基因的位置和结构需要多个方法综合运用,而且需要遵循一定的规则:对于真核生物序列,在进行预测之前先要进行重复序列分析,把重复序列标记出来并除去;选用预测程序时要注意程序的物种特异性;要弄清程序适用的是基因组序列还是cDNA序列;很多程序对序列长度也有要求,有的程序只适用于长序列,而对EST这类残缺的序列则不适用。
1. 重复序列分析对于真核生物的核酸序列而言,在进行基因辨识之前都应该把简单的大量的重复序列标记出来并除去,因为很多情况下重复序列会对预测程序产生很大的扰乱,尤其是涉及数据库搜索的程序。
2. 数据库搜索把未知核酸序列作为查询序列,在数据库里搜索与之相似的已有序列是序列分析预测的有效手段。
在理论课中已经专门介绍了序列比对和搜索的原理和技术。
但值得注意的是,由相似性分析作出的结论可能导致错误的流传;有一定比例的序列很难在数据库里找到合适的同源伙伴。
对于EST序列而言,序列搜索将是非常有效的预测手段。
核酸序列特征分析核酸序列特征分析是一个针对基因及其控制结构的重要研究课题,它可以帮助我们更好地理解遗传物质的结构和功能。
本文将介绍核酸序列特征分析的基本原理、步骤及分析方法,最后介绍可视化工具。
一、核酸序列特征分析的基本原理核酸序列特征分析是一种统计分析方法,用于全面分析核酸序列的某种特征,以发现和探索结构以及功能关系。
这种方法依赖于统计模型,以及不同特征度量标准,例如单碱基特征、二碱基特征、多碱基特征和序列分类等等。
可以选择不同特征的集合,用来发现序列的一些特殊结构,包括基因、调控序列、蛋白质结构和功能。
二、核酸序列特征分析的步骤核酸序列特征分析的步骤一般分为五个步骤:(1)获取输入数据,根据特征选择相应的特征计算库。
(2)利用统计模型以及参数,计算得出相应特征度量值,并将它们存储到计算机中。
(3)根据特征选择合适的建模方法,比如对数据进行聚类。
(4)根据模型参数,绘制特征分析图。
(5)根据图形结果做出结论,并给出相应的解释。
三、核酸特征分析中的分析方法1、基于核酸序列的单碱基特征分析:该方法的主要目的是分析单个碱基的分布,例如A/G,C/T,或者任意一对对立的碱基,通过比较单碱基出现次数的差异,来确定特定序列应该具有什么样的特征。
2、基于核酸序列的二碱基特征分析:该方法是针对两个或多个二碱基的比较,可以用来确定二碱基的组合的特征,以探究其中的影响因素。
3、基于核酸序列的多碱基特征分析:该方法是以一组碱基为单位进行分析,识别给定序列的多碱基特征,并评估它们之间的相关性。
4、基于核酸序列的序列分类:这是一种机器学习方法,通过特征选择,建立一个分类模型,然后将训练集中的序列分类为种类,利用这一模型,可以对未知序列进行预测。
四、可视化工具随着科技的发展,可视化工具也得到了极大的改进,它们可以帮助我们更好地理解核酸序列特征分析的结果。
例如Cytoscape,这是一个开源的网络可视化软件,可以帮助我们更直观地了解核酸序列中的二碱基关系;SeqView,这是一个基于web的序列可视化工具,提供了多种的可视化效果,例如3D结构、双向序列特征分析等;Circos,这是一个用于可视化大规模连接数据和关系的高效工具,可以帮助我们将序列特征分析结果可视化为动态图形。
核酸序列分析1、核酸序列检索可通过NCBI使用Entrez系统进行检索,也可用EBI的SRS服务器进行检索。
在同时检索多条序列时,可通过罗逻辑关系式按照GenBank接受号进行批量检索。
如用“AF113671 [ac] OR AF113672 [ac]”可同时检索这两条序列。
其中“[ac]”是序列接受号的描述字段。
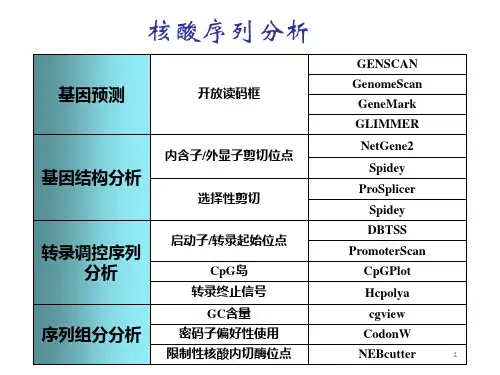
2、核酸序列的基本分析(1)分子质量、碱基组成、碱基分布分子质量、碱基组成、碱基分布可通过一些常用软件等直接获得。
如:BioEdit(/BioEdit/bioedit.html),DNAMAN()。
(2)序列变换进行序列分析时,经常需要对DNA序列进行各种变换,例如反向序列、互补序列、互补反向序列、显示DNA双链、转换为RNA序列等。
这些用DNAMAN软件可很容易实现,这些功能集中在Sequence→Display,从中可选择不同的序列变换方式对当前通道的序列进行转换。
(3)限制性酶切分析该方面最好的资源是限制酶数据库(Restriction Enzyme Database,REBASE)。
REBASE数据库(,/rebase)中含有限制酶的所有信息,包括甲基化酶、相应的微生物来源、识别序列位点、裂解位点、甲基化特异性、酶的商业来源及公开发表的和未发表的参考文献。
其它资源还有:WebGene:/~tjyin/WebGene/RE.html,/personal/tyin.htmlWebCutter2:http://www//firstmarkert/firstmarket/cutter/cut2.html同时,很多软件也能够识别REBASE限制酶数据库。
强烈推荐使用集成化的软件如BioEdit和DNAMAN等。
所得出的结果给出指定DNA序列的酶切位点信息,为克隆鉴定和亚克隆提供了重要信息。
在实际进行分子生物学实验中,有时需要对多条相关序列(如发生突变的一批序列)同时进行酶切分析,以便为后续的克隆鉴定提供参考。