第六讲判别分析
- 格式:pptx
- 大小:1.90 MB
- 文档页数:89










______________________________________________________________________________________________________________判别分析的基本原理和模型一、判别分析概述(一)什么是判别分析判别分析是多元统计中用于判别样品所属类型的一种统计分析方法,是一种在已知研究对象用某种方法已经分成若干类的情况下,确定新的样品属于哪一类的多元统计分析方法。
判别分析方法处理问题时,通常要给出用来衡量新样品与各已知组别的接近程度的指标,即判别函数,同时也指定一种判别准则,借以判定新样品的归属。
所谓判别准则是用于衡量新样品与各已知组别接近程度的理论依据和方法准则。
常用的有,距离准则、Fisher准则、贝叶斯准则等。
判别准则可以是统计性的,如决定新样品所属类别时用到数理统计的显著性检验,也可以是确定性的,如决定样品归属时,只考虑判别函数值的大小。
判别函数是指基于一定的判别准则计算出的用于衡量新样品与各已知组别接近程度的函数式或描述指标。
(二)判别分析的种类按照判别组数划分有两组判别分析和多组判别分析;按照区分不同总体的所用数学模型来分有线性判别分析和非线性判别分析;按照处理变量的方法不同有逐步判别、序贯判别等;按照判别准则来分有距离准则、费舍准则与贝叶斯判别准则。
二、判别分析方法(一)距离判别法1.基本思想:首先根据已知分类的数据,分别计算各类的重心,即分组(类)均值,距离判别准则是对于任给一新样品的观测值,若它与第i类的重心距离最近,就认为它来自精品资料第i 类。
因此,距离判别法又称为最邻近方法(nearest neighbor method )。
距离判别法对各类总体的分布没有特定的要求,适用于任意分布的资料。
2.两组距离判别两组距离判别的基本原理。
设有两组总体B A G G 和,相应抽出样品个数为21,n n ,n n n =+)(21,每个样品观测p 个指标得观测数据如下,总体A G 的样本数据为:()()()()()()()()()A x A x A x A x A x A x A x A x A x p n n n p p 111212222111211该总体的样本指标平均值为:()()()A x A x A x p 21,总体B G 的样本数据为:()()()()()()()()()B x B x B x B x B x B x B x B x B x p n n n p p 222212222111211该总体的样本指标平均值为:()()()B x B x B x p 21,现任取一个新样品X ,实测指标数值为X =(p x x x ,,,21 ),要求判断X 属于哪一类?首先计算样品X 与A G 、B G 两类的距离,分别记为()A G X D ,、()B G X D ,,然后按照距离最近准则判别归类,即样品距离哪一类最近就判为哪一类;如果样品距离两类的距离相同,则暂不归类。
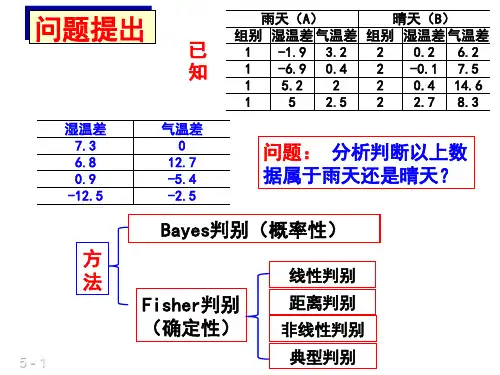
第六章判别分析第六章判别分析近年来,判别分析在植物分类、天⽓预报、经济决策与管理、社会调查、农业科研、科研数据整理分析中都得到了⼴泛的应⽤。
判别分析是⼀种很有实⽤价值⽽且应⽤极其⼴泛的⼀种统计⽅法。
本章介绍两种常⽤的判别⽅法:距离判别及Fisher 判别。
§1 距离判别距离判别是先给出⼀个样品到某个总体的距离的定义,然后根据样品到各个总体的距离的远近,来判断该样品应归属于哪⼀个总体。
本节先介绍多元分析中⼴泛应⽤的马⽒距离的概念,然后,再介绍距离判别的⽅法。
⼀、马⽒距离 1.概念距离是⼀个最直观的概念,多元分析中许多⽅法都可⽤距离的观点来推导,其中最著名的⼀个距离是印度统计学家Mahalanobis 于1936年引进的,所以习惯上称之为马⽒距离。
下⾯我们很快会看到,马⽒距离是我们熟知的欧⽒距离的⼀种推⼴。
定义:设P 维总体G 的均值向量为u ,协差阵为V>0(有V -1>0存在)X,Y 是总体G 的两个样品,则:(1)X 与Y 两点的马⽒距离d(X,Y)为:211)]()[(),(Y X V Y X Y X d -'-=-(2) X 与总体G 的马⽒距离为:211)]()[(),(u X V u X G X d -'-=-2.性质很容易证明,马⽒距离符合作为距离的三条基本公理:设X ,Y ,Z 是总体G 的三个样品,则有: (1)⾮负性:Y X Y X d Y Xd =?=≥0),(,0),( (2)对称性:),(),(X Y d Y X d =(3)满⾜三⾓不等式:),(),(),(Z Y d Y X d Z X d +≤证:(2)),()]()[()]()[(),(211211X Y d X Y V X Y Y X V Y X Y X d =-'-=-'-=-- 其它性质不证。
由马⽒距离的定义知,当V=E 时,X 与Y 的马⽒距离就变成为欧⽒距离:221121)()()]()[(),(p p y x y x Y X Y X Y X d -++-=-'-=所以,马⽒距离是欧⽒距离的推⼴,欧⽒距离是马⽒距离的特例。
判别分析的原理及其操作1 判别分析的原理1.1 判别分析的涵义判别分析(Discriminant Analysis,简称DA)技术是由费舍(R.A.Fisher)于1936年提出的。
它是根据观察或测量到的若干变量值判断研究对象如何分类的方法。
具体地讲,就是已知一定数量案例的一个分组变量(grouping variable)和这些案例的一些特征变量,确定分组变量和特征变量之间的数量关系,建立判别函数(discriminant function),然后便可以利用这一数量关系对其他已知特征变量信息、但未知分组类型所属的案例进行判别分组。
沿用多元回归模型的称谓,在判别分析中称分组变量为因变量,而用以分组的其他特征变量称为判别变量(discriminant variable)或自变量。
判别分析技术曾经在许多领域得到成功的应用,例如医学实践中根据各种化验结果、疾病症状、体征判断患者患的是什么疾病;体育选材中根据运动员的体形、运动成绩、生理指标、心理素质指标、遗传因素判断是否选入运动队继续培养;还有动物、植物分类,儿童心理测验,地理区划的经济差异,决策行为预测等。
1.2 判别分析的假设条件判别分析的基本条件是:分组变量的水平必须大于或等于2,每组案例的规模必须至少在一个以上;各判别变量的测度水平必须在间距测度等级以上,即各判别变量的数据必须为等距或等比数据;各分组的案例在各判别变量的数值上能够体现差别。
判别分析对判别变量有三个基本假设。
其一是每一个判别变量不能是其他判别变量的线性组合。
否则将无法估计判别函数,或者虽然能够求解但参数估计的标准误很大,以致于参数估计统计性不显著。
其二是各组案例的协方差矩阵相等。
在此条件下,可以使用很简单的公式来计算判别函数和进行显著性检验。
其三是各判别变量之间具有多元正态分布,即每个变量对于所有其他变量的固定值有正态分布。
1.3 判别分析的过程1.3.1 对已知分组属性案例的处理此过程为判别分析的第一阶段,也是建立判别分析基本模型的阶段,即分析和解释各组指标特征之间的差异,并建立判别函数。