Eviews数据统计与分析教程12章 面板数据(Panel Data)模型
- 格式:ppt
- 大小:289.50 KB
- 文档页数:20

面板数据模型的分析及Eviews实现一、面板数据和模型概述在经济学研究和实际应用中,我们经常需要同时分析和比较横截面观察值和时间序列观察值结合起来的数据,即:数据集中的变量同时含有横截面和时间序列的信息。
这种数据被称为面板数据(panel data),它与我们以前分析过的纯粹的横截面数据和时间序列数据有着不同的特点。
简单地讲,面板数据因同时含有时间序列数据和截面数据,所以其统计质既带有时间序列的性质,又包含一定的横截面特点。
因而,以往采用的计量模型和估计方法就需要有所调整。
例1 表1中展示的数据就是一个面板数据的例子。
其他类似的例子还有:历次人口普查中有关不同年龄段的受教育状况;同行业不同公司在不同时间节点上的产值等。
这里,不同的年龄段和公司代表不同的截面,而不同时间节点数据反映了数据的时间序列性。
研究和分析面板数据的模型被称为面板数据模型(panel data model)。
它的变量取值都带有时间序列和横截面的两重性。
一般的线性模型只单独处理横截面数据或时间序列数据,而不能同时分析和对比它们。
面板数据模型,相对于一般的线性回归模型,其长处在于它既考虑到了横截面数据存在的共性,又能分析模型中横截面因素的个体特殊效应。
当然,我们也可以将横截面数据简单地堆积起来用回归模型来处理,但这样做就丧失了分析个体特殊效应的机会。
二、一般面板数据模型介绍 符号介绍:ity ——因变量在横截面i 和时间t 上的数值;j it x ——第j 个解释变量在横截面i 和时间t 上的数值;假设:有K 个解释变量,即K j ,,2,1 =;有N 个横截面,即N i ,,2,1 =; 时间指标T t ,,2,1 =。
记第i 个横截面的数据为⎪⎪⎪⎪⎪⎭⎫⎝⎛=iT i i i y y y y21; ⎪⎪⎪⎪⎪⎭⎫⎝⎛=K iT iT iT Ki i i K i i i i x x x x x x x x x X 212221212111;⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=iT i i i μμμμ 21 其中对应的i μ是横截面i 和时间t 时随机误差项。


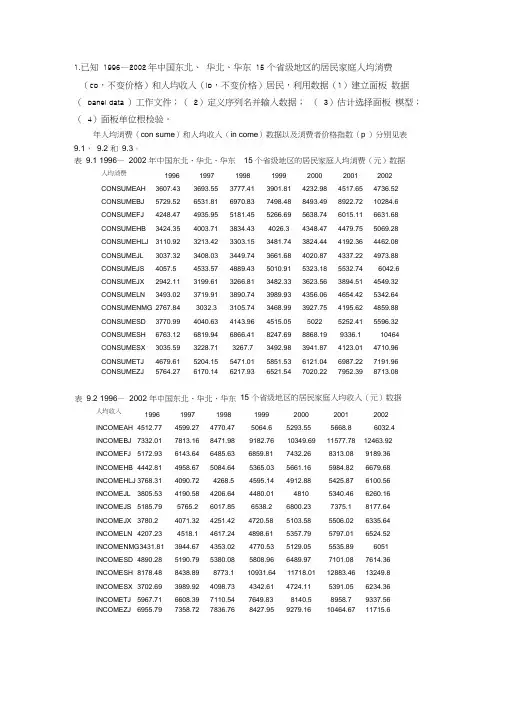
1.已知 1996—2002年中国东北、 华北、华东 15 个省级地区的居民家庭人均消费(cp ,不变价格)和人均收入(ip ,不变价格)居民,利用数据(1)建立面板 数据( panel data )工作文件;( 2)定义序列名并输入数据; ( 3)估计选择面板 模型;( 4)面板单位根检验。
年人均消费(con sume )和人均收入(in come )数据以及消费者价格指数(p )分别见表 9.1, 9.2 和 9.3。
表 9.1 1996— 2002 年中国东北、华北、华东 15 个省级地区的居民家庭人均消费(元)数据人均消费1996 1997 1998 1999 2000 2001 2002 CONSUMEAH 3607.43 3693.55 3777.41 3901.81 4232.98 4517.65 4736.52 CONSUMEBJ 5729.52 6531.81 6970.83 7498.48 8493.49 8922.72 10284.6 CONSUMEFJ 4248.47 4935.95 5181.45 5266.69 5638.74 6015.11 6631.68 CONSUMEHB3424.354003.71 3834.43 4026.3 4348.47 4479.75 5069.28 CONSUMEHLJ 3110.92 3213.42 3303.15 3481.74 3824.44 4192.36 4462.08 CONSUMEJL 3037.32 3408.03 3449.74 3661.68 4020.87 4337.22 4973.88 CONSUMEJS 4057.5 4533.57 4889.43 5010.91 5323.18 5532.74 6042.6 CONSUMEJX 2942.11 3199.61 3266.81 3482.33 3623.56 3894.51 4549.32 CONSUMELN3493.023719.91 3890.74 3989.93 4356.06 4654.42 5342.64 CONSUMENMG 2767.84 3032.3 3105.74 3468.99 3927.75 4195.62 4859.88 CONSUMESD 3770.99 4040.63 4143.96 4515.05 5022 5252.41 5596.32 CONSUMESH 6763.12 6819.94 6866.41 8247.69 8868.19 9336.1 10464 CONSUMESX 3035.59 3228.71 3267.7 3492.98 3941.87 4123.01 4710.96 CONSUMETJ 4679.61 5204.15 5471.01 5851.53 6121.04 6987.22 7191.96 CONSUMEZJ5764.276170.146217.936521.547020.227952.398713.08人均收入1996 1997 1998 1999 2000 2001 2002 INCOMEAH 4512.77 4599.27 4770.47 5064.6 5293.55 5668.86032.4INCOMEBJ 7332.01 7813.16 8471.98 9182.76 10349.69 11577.78 12463.92 INCOMEFJ 5172.93 6143.64 6485.63 6859.81 7432.26 8313.08 9189.36 INCOMEHB 4442.81 4958.67 5084.64 5365.03 5661.16 5984.82 6679.68 INCOMEHLJ 3768.31 4090.72 4268.5 4595.14 4912.88 5425.87 6100.56 INCOMEJL 3805.53 4190.58 4206.64 4480.01 4810 5340.46 6260.16 INCOMEJS 5185.79 5765.2 6017.85 6538.2 6800.23 7375.1 8177.64 INCOMEJX 3780.2 4071.32 4251.42 4720.58 5103.58 5506.02 6335.64 INCOMELN 4207.23 4518.1 4617.24 4898.61 5357.79 5797.01 6524.52 INCOMENMG3431.81 3944.67 4353.02 4770.53 5129.05 5535.89 6051 INCOMESD 4890.28 5190.79 5380.08 5808.96 6489.97 7101.08 7614.36 INCOMESH 8178.48 8438.89 8773.1 10931.64 11718.01 12883.46 13249.8 INCOMESX 3702.69 3989.92 4098.73 4342.61 4724.11 5391.05 6234.36 INCOMETJ 5967.71 6608.39 7110.54 7649.83 8140.5 8958.7 9337.56 INCOMEZJ 6955.797358.727836.768427.959279.1610464.6711715.615 个省级地区的居民家庭人均收入(元)数据表 9.2 1996— 2002 年中国东北、华北、华东< >\ Uinni«d X NewPage -/ 程如下:表9.3 1996 — 2002年中国东北、华北、华东物价指数1996 1997 1998 1999 2000 2001 2002 PAH 109.9 101.3 100 97.8 100.7 100.5 99 PBJ 111.6 105.3 102.4 100.6 103.5 103.1 98.2 PFJ 105.9 101.7 99.7 99.1 102.1 98.7 99.5 PHB 107.1 103.598.4 98.1 99.7 100.5 99 PHLJ 107.1 104.4 100.4 96.8 98.3 100.8 99.3 PJL 107.2 103.7 99.2 98 98.6 101.3 99.5 PJS 109.3 101.7 99.4 98.7 100.1 100.8 99.2 PJX 108.4 102 101 98.6 100.3 99.5 100.1 PLN 107.9 103.1 99.3 98.6 99.9 100 98.9PNMG 107.6 104.5 99.3 99.8 101.3 100.6100.2PSD 109.6 102.8 99.4 99.3 100.2 101.8 99.3 PSH 109.2 102.8 100 101.5 102.5 100 100.5 PSX 107.9 103.1 98.6 99.6 103.9 99.8 98.4 PTJ109 103.1 99.5 98.9 99.6 101.2 99.6 PZJ107.9102.899.798.810199.899.1(1)建立面板数据工作文件首先建立工作文件Tetcli from DB .Update sslectei from DB... Stor* selected to DB... Copy.s^lectedL . selectelFrijit Selected15个省级地区的消费者物价指数Ssntple: E c 回 r@sidGenerate Series. BDisplay Filter *New Obj set...建立面板数据库在窗口中输入15个不同省级地区的标识AH BJ FJHB HLJJL JS JX LNNMG SD SH sx TJ ZJI(2)定义序列名并输入数据产生3*15个尚未输入数据的变量名。



Panel data 简介及其在eviews 中的应用武汉大学经济学系数量经济学教研室《实践教改项目组》编制面板数据(panel data )回归模型与规则的时间序列或截面数据回归模型的区别在于其变量有两个下标,它同时使用截面数据和时间序列数据。
一、panel data 的优点面板数据相对于时间序列数据或截面数据的优点:1.能提供给研究者大量的数据点,这样可以增加自由度并减少解释变量间的共线性,从而改进计量经济估计的有效性。
为了估计模型参数,样本点越多越好。
样本点越多,估计的结果有效性越好,当样本点足够多时,估计结果可以视为具有一致性; 2. 面板数据模型可以从多层面分析经济问题。
3. 与时间序列数据或截面数据相比,面板数据能够更好的进行识别并控制和检验更复杂的行为模型。
二、模型的基本结构和分类面板数据回归模型的主要结构如下:T t N i u a X y it it it ,,2,1,,,2,1,/==++=β (1)其中,i 表示截面维度,可以表示家庭,个人,公司,国家等等;t 表示时间序列维度,是面板数据所研究的时间区间;it X 为解释变量,β为1⨯K 维向量,K 为解释变量的个数,β是斜率,a 是截距。
模型的矩阵形式为:11221111111121111111221111111111⨯⨯⨯⨯⨯⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎭⎫ ⎝⎛+⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎭⎫ ⎝⎛''''''+⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎭⎫ ⎝⎛NT NT N T T k NT NT N T T NT NT NT N T T u u u u u u X X X X X X y y y y y y βα 其中()k t t itX X X ,11,1,''=' 众所周知,随机误差项it u 包含了模型解释变量所不能解释的所有其它因素,并且it u 满足一些经典假设,这些假设是我们估计模型参数的基础。




面板数据模型1.面板数据定义。
时间序列数据或截面数据都是一维数据。
例如时间序列数据是变量按时间得到的数据;截面数据是变量在截面空间上的数据。
面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。
面板数据是同时在时间和截面空间上取得的二维数据。
面板数据示意图见图1。
面板数据从横截面(cross section)上看,是由若干个体(entity, unit, individual)在某一时刻构成的截面观测值,从纵剖面(longitudinal section)上看是一个时间序列。
面板数据用双下标变量表示。
例如y i t, i = 1, 2, …, N; t = 1, 2, …, TN表示面板数据中含有N个个体。
T表示时间序列的最大长度。
若固定t不变,y i ., ( i = 1, 2, …, N)是横截面上的N个随机变量;若固定i不变,y. t, (t = 1, 2, …, T)是纵剖面上的一个时间序列(个体)。
图1 N=7,T=50的面板数据示意图例如1990-2000年30个省份的农业总产值数据。
固定在某一年份上,它是由30个农业总产总值数字组成的截面数据;固定在某一省份上,它是由11年农业总产值数据组成的一个时间序列。
面板数据由30个个体组成。
共有330个观测值。
对于面板数据y i t, i = 1, 2, …, N; t = 1, 2, …, T来说,如果从横截面上看,每个变量都有观测值,从纵剖面上看,每一期都有观测值,则称此面板数据为平衡面板数据(balanced panel data)。
若在面板数据中丢失若干个观测值,则称此面板数据为非平衡面板数据(unbalanced panel data)。
注意:EViwes 3.1、4.1、5.0既允许用平衡面板数据也允许用非平衡面板数据估计模型。
Panel Data模型的EViews操作过程两种模式:Ⅰ. 关于Panel工作文件;Ⅱ. 关于Pool对象。
数据的预处理1.在EXCEL文件中,将每个变量各年的原始数据按照年份顺序排成一列,称之为堆积数据(见表“数据-年份”)。
2.输入截面单元的标识(表示地区的符号,前面加_;如:_HB、_NMG等)。
3.将数据按照地区分类(即按地区排序,见表“数据-地区”)。
Ⅰ. 关于Panel工作文件的操作过程案例1:我国农村居民消费函数(2000-2010年,27个省市数据,工作文件:NXF)一、输入数据1、创建Panel工作文件选择File / New / Workfile,在出现的创建工作文件对话框中:(1)在文件结构类型中,选择“平衡面板(Balanced Panel)”;(2)输入起始、终止期,截面单元个数。
2.更改截面标识(如果取默认的截面标示,此步可以省略)序列crossid 中是以数字1、2、…标记截面标识,为了便于区分,可以重新定义一个字符串序列。
(1)点击object / New object ,选择series Alpha 并输入序列名(设为dq ); (2)双击dq 序列,在打开的序列窗口中粘贴截面标识的字符串序列;(3)双击工作文件窗口中的Range ,在弹出的对话框中,将截面标识的的ID 序列改成新的标识序列:dq3.输入数据键入命令:DATA Y X ,然后用复制+粘贴方式从Excel 文件中将各个变量的堆积数据(注意:数据事先要按照截面单元堆积,本例中是按照“地区”)复制到工作文件之中;此时工作文件中各个变量都是堆积数据。
工作文件中将生成分别表示截面标识和时期标识的两个序列:Crossid — 截面标识 dateid — 时期标识二、模型估计过程1.估计混合模型直接在命令窗口键入命令:LS Y C X2.估计变截距模型在方程窗口中点击Estimate按钮,在弹出的方程描述框中选择Panel Options选项卡,此时可以在截面和时期列表中选择None、Fixed、Random,用来选择单因素(或双因素)固定效应、随机效应变截距模型;同时可以选择GMM、GLS、SUR等估计方法。