EViews6.0在面板数据模型估计中的操作
- 格式:doc
- 大小:3.59 MB
- 文档页数:26
Eviews6.0面板数据操作一、数据输入1、创建工作文档。
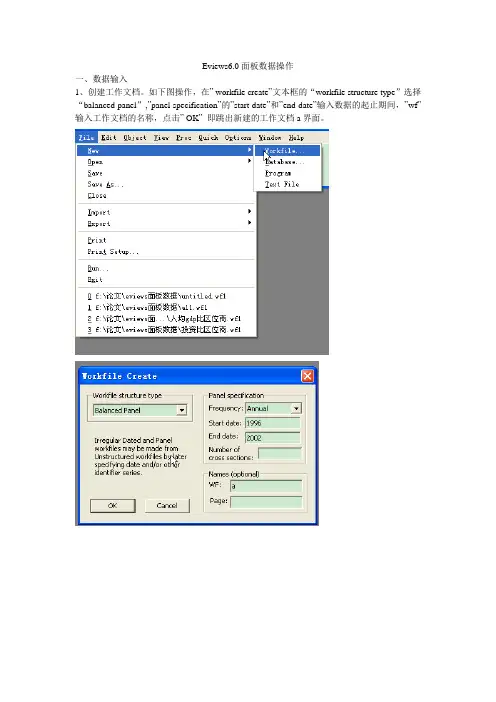
如下图操作,在” workfile create”文本框的“workfile structure type”选择“balanced panel”,”panel specification”的”start date”和”end date”输入数据的起止期间,”wf”输入工作文档的名称,点击” OK”即跳出新建的工作文档a界面。
2、创建新对象。
操作如下图。
在”new object”文本框的”type of object”选择”pool”,”name for object ”输入新对象的名称。
创建成功后的界面如下面第3张图所示。
-3、输入数据。
双击”workfile”界面的,跳出”pool”界面,输入个体。
一般输入方式为如下:若上海输入_sh,北京输入_bj,…。
个体输入完成后,点击该界面的键,在跳出的”series list”输入变量名称,注意变量后要加问号。
格式如下:y? x?。
点击”OK”后,跳出数据输入界面,如下面第4张图所示。
在这个界面上点击键,即可以输入或者从EXCEL处复制数据。
在输入数据后,记得保存数据。
保存操作如下:在跳出的“workfile save”文本框选择“ok”即可,则自动保存到我的文档。
然后在“workfile”界面如下会显示保存路径:d:\my documents\a.wf1。
若要保存到自己选择的路径下面,则在保存时选择“save as”,在跳出的文本框里选择自己要保存的路径以及命名文件名称。
4、单位根检验。
一般回归前要检验面板数据是否存在单位根,以检验数据的平稳性,避免伪回归,或虚假回归,确保估计的有效性。
单位根检验时要分变量检验。
(补充:网上对面板数据的单位根检验和协整检验存在不同意见,一般认为时间区间较小的面板数据无需进行这两个检验。
)(1)生成数据组。
如下图操作。
点击”make group”后在跳出的”series list”里输入要单位根检验的变量,完成后就会跳出如下图3所示的组数据。

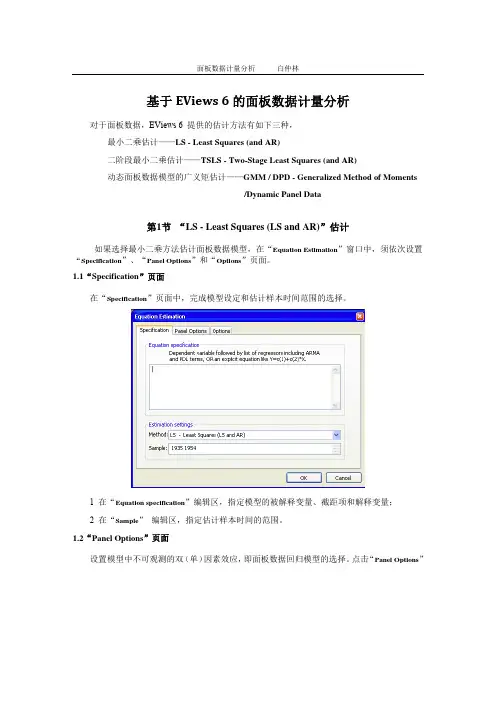
基于EViews 6的面板数据计量分析对于面板数据,EViews 6 提供的估计方法有如下三种,最小二乘估计——LS - Least Squares (and AR)二阶段最小二乘估计——TSLS - Two-Stage Least Squares (and AR)动态面板数据模型的广义矩估计——GMM / DPD - Generalized Method of Moments/Dynamic Panel Data第1节“LS - Least Squares (LS and AR)”估计如果选择最小二乘方法估计面板数据模型,在“Equation Estimation”窗口中,须依次设置“Specification”、“Panel Options”和“Options”页面。
1.1“Specification”页面在“Specification”页面中,完成模型设定和估计样本时间范围的选择。
1 在“Equation specification”编辑区,指定模型的被解释变量、截距项和解释变量;2 在“Sample”编辑区,指定估计样本时间的范围。
1.2“Panel Options”页面设置模型中不可观测的双(单)因素效应,即面板数据回归模型的选择。
点击“Panel Options”该页面包含三方面内容。
1 效应设置在“Effects specification”选择区,设定面板数据模型的个体效应和时间效应,可选择的选项有“None”、“Fixed”和“Random”,分别表示“无效应”、“固定效应”和“随机效应”。
如果选择了“Fixed”或“Random”,EViews在输出结果中自动添加一个共同常数,即截距项,以保证效应之和为零。
否则,截距项必要时,须在“Specification”页面的“Equation specification”编辑区设定模型截距项。
2 GLS加权设置“GLS Weights”可以在下拉框中选择如下选项之一。
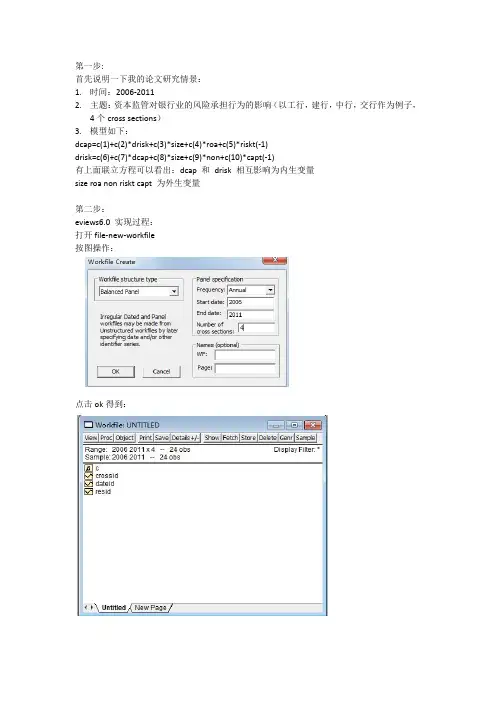
第一步:首先说明一下我的论文研究情景:1.时间:2006-20112.主题:资本监管对银行业的风险承担行为的影响(以工行,建行,中行,交行作为例子,4个cross sections)3.模型如下:dcap=c(1)+c(2)*drisk+c(3)*size+c(4)*roa+c(5)*riskt(-1)drisk=c(6)+c(7)*dcap+c(8)*size+c(9)*non+c(10)*capt(-1)有上面联立方程可以看出:dcap 和drisk 相互影响为内生变量size roa non riskt capt 为外生变量第二步:eviews6.0 实现过程:打开file-new-workfile按图操作:点击ok得到:点击object-new objectType选pool,ok:跳出的横框:Cross Section Identifiers 填入数据变量名称:(这是纵轴的)GSYHJSYHZGYHJTYH(前面提及的四大银行)然后点view-spreadsheet(stacked data)series list小框输入(这是横轴的变量名称)dcap drisk size roa non riskt capt点击edit+/- 手动输入数据或用import导入数据或粘贴复制进去也行:此时点object-new object,这次type选择system 用以联立方程分析:在system框内输入联立方程和工具变量:dcap=c(1)+c(2)*drisk+c(3)*size+c(4)*roa+c(5)*riskt(-1)drisk=c(6)+c(7)*dcap+c(8)*size+c(9)*non+c(10)*capt(-1)inst dcap drisk size roa non riskt(-1) capt(-1)点右上方的estimate,method选择TSLS(两阶段最小二乘估计):整个过程就是先建立workfile再建立panel data最后建立联立方程systemTSLS估计即可。


详细的EVIEWS面板数据分析操作引言EVIEWS是一款专业的经济统计软件,广泛应用于经济学和金融领域的数据分析和建模。
EVIEWS提供了丰富的面板数据分析功能,可以帮助用户进行面板数据的处理、描述统计、回归分析等操作。
本文将详细介绍EVIEWS中面板数据分析的操作流程和常用功能。
EVIEWS面板数据的导入首先,我们需要将面板数据导入到EVIEWS中进行分析。
EVIEWS支持多种数据格式的导入,包括Excel、CSV、数据库等。
在导入面板数据时,需要保证数据具有正确的格式,例如面板数据应包含个体(cross-sectional)和时间(time-series)的维度,且面板数据的变量应按照一定的顺序排列。
在导入面板数据后,我们可以利用EVIEWS提供的数据操作命令对数据进行处理和调整。
例如,可以通过group命令将数据按照个体或时间进行分组,通过sort命令对数据进行排序,以便后续的面板数据分析。
面板数据的描述统计分析在面板数据导入并处理完毕后,我们可以进行面板数据的描述统计分析。
EVIEWS提供了丰富的统计功能,可以计算面板数据的平均值、标准差、相关系数等指标。
下面介绍几个常用的描述统计功能:1.summary命令:该命令可以计算面板数据每个变量的平均值、标准差、最大值、最小值等统计指标,并输出到EVIEWS的结果窗口中。
2.correlation命令:该命令可以计算面板数据各变量之间的相关系数矩阵,并输出到结果窗口中。
3.tabulate命令:该命令可以对面板数据进行交叉分组统计,例如计算变量A在变量B的每个取值下的频数和比例。
通过对面板数据进行描述统计分析,可以初步了解数据的分布特征和变量间的关系,为后续的面板数据分析提供基础。
面板数据的回归分析除了描述统计分析,EVIEWS还提供了面板数据的回归分析功能。
通过面板数据回归分析,可以探究变量间的因果关系和影响程度。
下面介绍两个常用的回归分析命令:1.panel least squares(PLS)命令:该命令可以进行面板数据的最小二乘回归分析。

计量经济学软件EVIEWS6.0基本操作一、什么是EVIEWSEVIEWS (ECONOMETRIC VIEWS)软件是QMS(QUANTITATIVE MICRO SOFTWARE)公司开发的、基于Windows平台下的应用软件,其前身是DOS操作系统下的TSP软件。
EVIEWS软件主要应用在经济学领域,可用于回归分析与预测(REGRESSION AND FORECASTING)、时间序列(TIME SERIES)以及横截面数据(CROSS-SECTIONAL DATA )分析。
与其他统计软件(如EXCEL、SAS、SPSS、stata、R)相比,EVIEWS功能优势是菜单操作简单明了,使用方法,非常适用计量经济学初级学员。
本手册对EVIEWS软件6.0版本进行简单介绍,目的是让初级学员通过本章介绍,能够对学过的计量经济理论和方法进行简单应用,以便完成本书所述的相关实验项目。
二、EVIEWS安装EVIEWS6.0文件安装包大小约190MB,可在网上下载①。
下载完毕后,按照包中安装文件所述安装方法安装该软件。
安装完毕后,将快捷键发送的桌面,电脑桌面显示有EVIEWS6.0图标,整个安装过程就结束了。
双击EVIEWS按钮即可启动该软件(图1),图1所示界面称为EVIEWS软件主窗口,主窗口中的菜单,如File菜单称为EVIEWS主菜单。
图1三、Eviews工作特点初次使EVIEWS6.0计量经济学软件,必须了解其工作过程。
如,想要完成一个校准一元线性回归模型的参数估计,必须要完成两大步工作。
第一大步工作就是在建立一个工作文档(即EVIEWS6.0中的Workfile文档)、建立变量、导入数据;第二大步工作是在第一大步工作的基础上,根据模型特征,选用适当的参数估计方法,完成参数估计及相关检验。
四、具体示例在这里,我们通过一个简单的标准一元线性回归模型的估计过程来说明Eviews软件完成回归分析的基本过程。
EViews 6.0在面板数据模型估计中的实验操作1、进入工作目录cd d:\nklx3,在指定的路径下工作是一个良好的习惯2、建立面板数据工作文件workfile(1)最好不要选择EViews默认的blanaced panel 类型Moren_panel(2)按照要求建立简单的满足时期周期和长度要求的时期型工作文件3、建立pool对象(1)新建对象(2)选择新建对象类型并命名(3)为新建pool对象设置截面单元的表示名称,在此提示下(Cross Section Identifiers: (Enter identifiers below this line )输入截面单元名称。
建议采用汉语拼音,例如29个省市区的汉语拼音,建议在拼音名前加一个下划线“_”,如图关闭建立的pool对象,它就出现在当前工作文件中。
4、在pool对象中建立面板数据序列双击pool对象,打开pool对象窗口,在菜单view的下拉项中选择spreedsheet (展开表)在打开的序列列表窗口中输入你要建立的序列名称,如果是面板数据序列必须在序列名后添加“?”。
例如,输入GDP?,在GDP后的?的作用是各个截面单元的占位符,生成了29个省市区的GDP的序列名,即GDP后接截面单元名,再在接时期,就表示出面板数据的3维数据结构(1变量2截面单元3时期)了。
请看工作文件窗口中的序列名。
展开表(类似excel)中等待你输入、贴入数据。
(1)打开编辑(edit)窗口(2)贴入数据(3)关闭pool窗口,赶快存盘见好就收6、在pool窗口对各个序列进行单位根检验选择单位根检验设置单位根检验单位根检验结果注意检验方法和两种检验的零假设:Null: Unit root (assumes common unit root process)各截面有相同的单位根Null: Unit root (assumes individual unit root process)允许各截面有不同单位根其中,Levin, Lin & Chu t*检验拒绝含有单位根的零假设,即拒绝非平稳7、在pool窗口对面板数据组合进行协整检验选择进行协整检验协整检验设置对话框,注意有3种检验方法(test type)协整检验结果,同样要注意两种假定(含有AR,即含有单位根,非协整),两种零假设都是非协整,小概率事件发生拒绝非协整。

EViews 6.0在面板数据模型估计中的实验操作
1、进入工作目录cd d:\nklx3,在指定的路径下工作是一个良好的习惯
2、建立面板数据工作文件workfile
(1)最好不要选择EViews默认的blanaced panel 类型
Moren_panel
(2)按照要求建立简单的满足时期周期和长度要求的时期型工作文件
3、建立pool对象
(1)新建对象
(2)选择新建对象类型并命名
(3)为新建pool对象设置截面单元的表示名称,在此提示下(Cross Section Identifiers: (Enter identifiers below this line )输入截面单元名称。
建议采用汉语拼音,例如29个省市区的汉语拼音,建议在拼音名前加一个下划线“_”,如图
关闭建立的pool对象,它就出现在当前工作文件中。
4、在pool对象中建立面板数据序列
双击pool对象,打开pool对象窗口,在菜单view的下拉项中选择spreedsheet (展开表)
在打开的序列列表窗口中输入你要建立的序列名称,如果是面板数据序列必须在序列名后添加“?”。
例如,输入GDP?,在GDP后的?的作用是各个截面单元的占位符,生成了29个省市区的GDP的序列名,即GDP后接截面单元名,再在接时期,就表示出面板数据的3维数据结构(1变量2截面单元3时期)了。
请看工作文件窗口中的序列名。
展开表(类似excel)中等待你输入、贴入数据。
(1)打开编辑(edit)窗口
(2)贴入数据
(3)关闭pool窗口,赶快存盘见好就收6、在pool窗口对各个序列进行单位根检验
选择单位根检验
设置单位根检验
单位根检验结果
注意检验方法和两种检验的零假设:
Null: Unit root (assumes common unit root process)各截面有相同的单位根Null: Unit root (assumes individual unit root process)允许各截面有不同单位根
其中,Levin, Lin & Chu t*检验拒绝含有单位根的零假设,即拒绝非平稳
7、在pool窗口对面板数据组合进行协整检验
选择进行协整检验
协整检验设置对话框,注意有3种检验方法(test type)
协整检验结果,同样要注意两种假定(含有AR,即含有单位根,非协整),两种零假设都是非协整,小概率事件发生拒绝非协整。
本例题检验的4个序列时协整的,特别提示还要看各个序列的单位根检验是否是同阶单整的,否则单凭协整检验的结果根据不足。
在pool对象窗口的proc(过程)的下拉式菜单中选择估计打开模型设置窗口。
混合模型的设置
混合模型的结果
9、建立变系数模型
这里只建立一次变一个变量且在截面维的变系数模型。
当然也可是在时间维的变系数。
而且可以一次不止变一个变量的系数。
变系数模型的设置
变系数模型的估计结果
10、建立截距维的固定效应模型,并检验模型的冗余性(是否比混合模型优?)截面维固定效应模型的设置
截面维固定效应模型的估计结果
截面维固定效应模型的冗余性检验,首先在pool模型的view中选择似然比的检验菜单选项
似然比检验的结果,零假设固定效应模型是冗余的,小概率事件发生,拒绝冗余,于是摒弃混合模型:
11、建立截距维的随机效应模型,并进行Hausman检验,确定是选择随机效应亦或是固定效应模型,零假设:随机效应模型成立。
截面维随机效应模型的设置
截面维随机效应模型的估计结果
截面维随机效应模型的Hausman检验菜单项的选择
截面维随机效应模型Hausman检验的结果:
Hausman检验的零假设是应当选择随机效应模型,小概率事件发生拒绝零假设,选择固定效应模型
12、13在时间维重复10、和11、的工作,确定数据适合采用何种模型?
14、建立截面变截距模型,分析没有观察的截面单元因素的影响
截面变截距模型的设置
截面变截距模型的估计结果
15、建立时期变截距模型,分析没有观察的时期因素的影响时期变截距模型的设置
时期变截距模型的估计结果
16、在整个估计、检验构成中养成使用冻结和命名保存的习惯,以便撰写报告时调用。
17、工作中注意使用工作文件窗口顶部的显示过滤器,简化你的窗口,以免眼花缭乱。
过虑前
选择过虑
过虑后
对同一组数据处理两个模型,例如生产函数和增长模型,可以导出page,在导入page,使它们既有联系又有区别。
18、祝大家好运,也祝贺在下从北京地质学院毕业50周年,十分荣幸我的校友5月15日在北京举行了纪念会;十分荣幸杨遵义院士(古生物)、王鸿祯院士(地史)、涂光织院士(矿床,同班小王成了涂夫人,可惜,自古红颜多薄命)和张本仁院士(南京大学研究生毕业,教完构造课就成了右派?,教课时还不是院士)是在下的院士老师,还有许多老师都将永远的铭记,教数学的女老师(苏教授的夫人),教俄语的王语今教授。
也特向我在武汉大学的老师张尧庭教授、冯文权教授致敬。
特发此贴祝福我的老师们和同学们健康。
谢谢。
19、面板数据优点很多,但是请注意面板数据模型方法的协方差分析的方法学特性,它是将其他序列的影响保持固定,并从总变异中扣除它们的影响以后,再判别目标序列的差异显著性。
_gongshang
_zhongguo
_jianshe
_jiaotong
_beijing
_ningbo
_huaxia
_minsheng
_nanjing
_pufa
_shenfazhan
_xingye
_zhaoshang _zhongxin _nongye
_guangda。