对深度学习自适应网络学习可迁移特征的理解
- 格式:pdf
- 大小:1.17 MB
- 文档页数:13

迁移学习中的领域自适应研究迁移学习是机器学习领域中的一个非常重要的研究方向。
它的目的是将已有的知识迁移到新的环境中,以提高学习效果。
传统的机器学习算法在解决某个特定问题时,通常需要具有大量的标记数据才能进行训练。
但是,在现实生活中,我们面临的问题往往是数据缺乏的,这就给机器学习算法的应用带来了极大的困难。
迁移学习可以通过将在某个领域学习到的知识迁移到新环境中,实现新问题的解决。
迁移学习的核心思想是通过利用不同领域之间的相似性,将已有的知识迁移到新的领域中,从而提高学习的效果。
在实际中,迁移学习可以被应用到很多领域。
其中,领域自适应是一个很重要的研究方向。
领域自适应是指将源领域和目标领域之间的差异降到最小,从而实现迁移学习的过程。
在实际中,不同领域之间的差异是不可避免的,如数据分布、特征表示和标记信息等方面的差异。
所以,如何准确地计算领域之间的相似性,以及如何充分利用源领域的知识,提高在目标领域的学习效果,是领域自适应研究中需要解决的核心问题。
针对领域自适应问题,很多研究者都提出了自己的解决方案。
其中,一些比较典型的方法包括基于实例的方法、基于模型的方法和基于深度学习的方法等。
基于实例的方法是通过对源领域和目标领域中的实例进行比较,计算两个领域之间的相似度,并通过在源领域和目标领域中选择一些相似的实例进行学习。
这种方法的好处在于简单易用,并且不需要太多的领域知识。
但是,由于采用的是实例级别的比较,它对领域之间的差异的适应性并不高。
基于模型的方法是将源领域和目标领域之间的关系建模,并在新的领域中进行迁移。
这种方法需要先训练一个源模型,然后根据源模型和目标领域之间的关系,去调整模型参数,从而实现迁移学习的过程。
与基于实例的方法相比,基于模型的方法可以更充分地利用源领域中的知识,而且对领域之间的差异也有更好的适应性。
基于深度学习的方法是近年来非常流行的领域自适应方案。
它可以通过深度神经网络来表示特征,以提高领域之间的可迁移性。

深度学习技术的迁移学习策略与实践一、深度学习技术的迁移学习策略1.1 什么是迁移学习在机器学习领域中,迁移学习是指利用已经训练好的神经网络(或其他模型)的知识和参数,来解决不同但相关领域的问题。
也就是说,通过将一个已经在某个特定任务上训练得到的深度学习模型应用到另一个任务上,以提高新任务的准确性和效果。
1.2 迁移学习的意义与优势传统的机器学习方法需要大量标注数据进行训练才能达到较好的效果。
然而,在真实世界中,很多任务往往缺少足够数量和质量的标注样本。
迁移学习则可以通过利用已有知识、参数等方面的信息来减少对大规模标注数据依赖。
此外,迁移学习还可以帮助解决"数据倾斜"问题。
在现实场景中,常常会出现类别不平衡的情况,即某些类别拥有更多样本而其他类别样本较少。
这样会导致传统机器学习方法出现预测偏差。
而通过从旧任务中迁移学习,可以平衡类别之间的样本分布,从而提高模型的性能。
1.3 迁移学习中的策略与方法在实践中,有多种迁移学习策略和方法可供选择。
下面介绍几种常见的迁移学习方法:(1)基于特征表示的迁移学习:该方法将已训练好的模型作为特征提取器,将输入数据映射到新任务所需的特征空间。
这样做的好处是可以重复使用旧模型已经学到的知识,并且由于只需要调整少部分参数,训练时间相对较短。
(2)网络微调(Fine-tuning):该方法是在已经训练好的模型基础上再进行微调。
首先,将原始网络结构冻结住,只对最后几层进行重新训练。
然后逐渐解冻其他层,并在更少数量的步骤内微调整个网络。
(3)预训练与微调:预训练指在大规模无标注数据上进行初步训练得到一个辅助任务上表现良好的深度学习模型,并利用其参数初始化新任务所需网络。
随后,在目标任务上进一步优化模型。
这种方法通常应用于深度神经网络模型中。
(4)领域自适应:当源领域和目标领域的数据存在差异时,可以通过领域自适应方法来减小这种差异。
主要有实例权重调整、特征选择与映射等方法。

深度学习技术中的模型迁移性问题深度学习技术的快速发展使得计算机视觉、自然语言处理等领域取得了显著的进展。
然而,深度学习模型在面对新的领域或任务时往往需要重新训练。
这种情况下,模型迁移性问题变得至关重要。
模型迁移性指的是在一个任务上训练的模型能否有效地迁移到另一个任务上。
本文将探讨深度学习技术中的模型迁移性问题,并介绍一些解决方案。
首先,我们需要了解模型迁移性问题的根本原因。
深度学习模型的迁移性问题主要由两个方面导致:任务域间的差异和数据集的不匹配。
任务域间的差异指的是不同任务之间的特征分布和潜在关系的差异。
数据集的不匹配则指的是训练集和测试集之间的分布差异。
这些差异使得在一个任务上训练的模型无法直接应用到另一个任务上,从而导致性能下降或失效。
为解决模型迁移性问题,研究人员提出了多种方法和技术。
其中一种方法是领域自适应。
领域自适应技术旨在通过学习一个通用的表示,使得模型能够在不同的任务和领域中共享知识。
这种方法的关键在于对抗性训练,通过最小化源领域和目标领域之间的差异来实现模型的迁移。
例如,生成对抗网络(GANs)可以用来生成与目标领域相似的样本,以缓解领域间的差异问题。
另一种解决模型迁移性问题的方法是迁移学习。
迁移学习通过在源任务上学习到的知识来帮助解决目标任务。
迁移学习分为三个主要策略:特征提取、模型调整和参数初始化。
特征提取策略将源任务上学习到的特征应用到目标任务中,以提高模型性能。
模型调整策略则通过微调模型的某些层或添加新的层来适应目标任务。
参数初始化策略则通过使用源任务上的参数作为初始化值来加快目标任务的训练过程。
除了以上提到的方法,还有一些其他技术也可用于解决模型迁移性问题。
例如,多任务学习是一种同时学习多个相关任务的方法,可以提高模型在新任务上的泛化能力。
领域对抗神经网络(DANN)是一种使用领域分类器来推动模型表示在源领域和目标领域之间的混淆,从而缓解模型迁移性问题。
尽管已经有了一些有效的方法用于解决深度学习技术中的模型迁移性问题,但这个问题仍然具有挑战性。
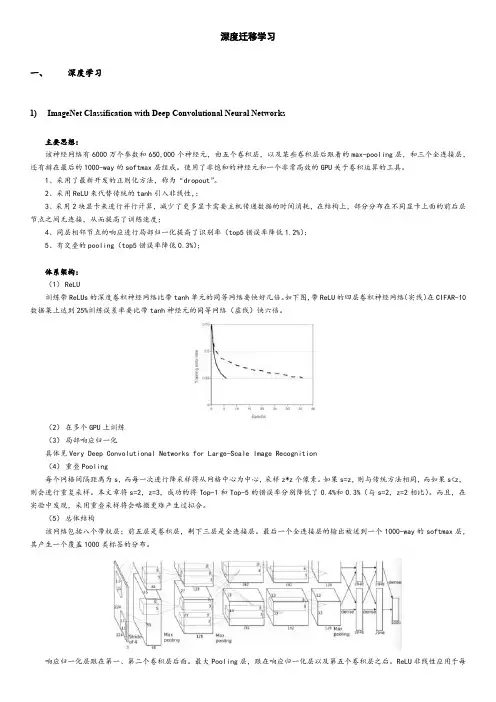
深度迁移学习一、深度学习1)ImageNet Classification with Deep Convolutional Neural Networks主要思想:该神经网络有6000万个参数和650,000个神经元,由五个卷积层,以及某些卷积层后跟着的max-pooling层,和三个全连接层,还有排在最后的1000-way的softmax层组成。
使用了非饱和的神经元和一个非常高效的GPU关于卷积运算的工具。
1、采用了最新开发的正则化方法,称为“dropout”。
2、采用ReLU来代替传统的tanh引入非线性,;3、采用2块显卡来进行并行计算,减少了更多显卡需要主机传递数据的时间消耗,在结构上,部分分布在不同显卡上面的前后层节点之间无连接,从而提高了训练速度;4、同层相邻节点的响应进行局部归一化提高了识别率(top5错误率降低1.2%);5、有交叠的pooling(top5错误率降低0.3%);体系架构:(1)ReLU训练带ReLUs的深度卷积神经网络比带tanh单元的同等网络要快好几倍。
如下图,带ReLU的四层卷积神经网络(实线)在CIFAR-10数据集上达到25%训练误差率要比带tanh神经元的同等网络(虚线)快六倍。
(2)在多个GPU上训练(3)局部响应归一化具体见Very Deep Convolutional Networks for Large-Scale Image Recognition(4)重叠Pooling每个网格间隔距离为s,而每一次进行降采样将从网格中心为中心,采样z*z个像素。
如果s=z,则与传统方法相同,而如果s<z,则会进行重复采样。
本文章将s=2,z=3,成功的将Top-1和Top-5的错误率分别降低了0.4%和0.3%(与s=2,z=2相比)。
而且,在实验中发现,采用重叠采样将会略微更难产生过拟合。
(5)总体结构该网络包括八个带权层;前五层是卷积层,剩下三层是全连接层。

深度学习技术中的半监督学习与迁移学习深度学习作为人工智能领域的一个重要分支,在多个领域展现出了强大的能力。
然而,在实际应用中,我们往往面临着数据标注不充足的问题,这时半监督学习和迁移学习这两种技术可以为我们提供有效的解决方案。
本文将重点介绍深度学习技术中的半监督学习和迁移学习的概念、方法和应用。
首先,让我们来了解一下半监督学习。
在半监督学习中,我们既有带有标签的数据,也有大量未被标注的数据。
相比于传统的监督学习,半监督学习充分利用未标注数据的信息,通过在模型训练过程中引入这些未标注数据来提高模型性能。
深度学习中的半监督学习方法包括自编码器、生成对抗网络和图卷积网络等。
自编码器通过学习将输入数据压缩到低维的隐空间表示,并尝试重构原始输入,从而学习到数据的特征表示。
生成对抗网络则通过生成器和判别器的对抗训练,实现从未标注数据中学习到生成分布。
图卷积网络则针对图数据结构,通过利用图邻居节点的信息进行学习。
半监督学习在许多领域如图像分类、文本分类和语义分割等任务中都取得了很好的效果。
接下来,我们来介绍迁移学习。
迁移学习旨在将在一个领域中学到的知识迁移到另一个相关领域中。
在深度学习中,迁移学习可以通过多种方式实现,如特征提取、模型微调和领域自适应等。
特征提取是指将预训练模型的顶层去掉,然后在新任务上添加新的输出层进行微调。
这样做的好处是可以利用在大规模数据上预训练的模型学习到的全局特征,从而更好地适应新的任务。
模型微调则是在预训练模型的基础上继续训练部分或所有的层,以适应新的任务。
领域自适应则通过设计特定的损失函数或网络结构,实现在源领域学到的知识在目标领域的迁移。
迁移学习在计算机视觉、自然语言处理和语音识别等领域都有广泛的应用,有效解决了数据不足的问题。
在实际应用中,半监督学习和迁移学习可以相互结合,进一步提高深度学习模型的性能。
当我们面临数据标注不足的情况时,可以先利用半监督学习的方式使用未标注数据进行训练,然后再利用迁移学习的方法将模型迁移到新任务上。

深度学习的特征及其意义教师个人的专业素养的提升,离不开集体的研讨、分享。
内容提要:深度学习的提出,既是对教学规律的尊重,也是对时代挑战的主动回应。
深度学习的五个特征,为理解教学活动提供了新的视角,为消解种种二元对立观念提供了理论支持。
深度学习的研究与实践,确立了学生个体经验与人类历史文化的相关性,落实了学生在教学活动中的主体地位,使学生能够在教学活动中模拟性地“参与”人类社会历史实践,形成有助于未来发展的核心素养,而教师的作用与价值也在深度学习中得以充分实现。
关键词:深度学习教学规律社会历史实践核心素养近十年来国际上最先进的教学理论其实根本不是国内疯传的“翻转课堂”等技术性的策略,而是源于人工智能和脑科学的深度学习理论。
深度学习注重学生沉浸于知识的情境和学习的情境,强调批判性思维,注重实现知识的内在价值。
理解深度学习理论对深化我国的教学改革具有重要的意义。
认真是一种态度一、深度学习概念的提出深度学习的概念,源于 30 年多来计算机科学、人工神经网络和人工智能的研究。
上世纪八九十年代,人们提出了一系列机器学习模型,应用最为广泛的包括支持向量机(Support Vector Machine,SVM)和逻辑回归(Logistic Regression,LR),这两种模型分别可以看作包含 1 个隐藏层和没有隐藏层的浅层模型。
计算机面对较为复杂的问题解决训练时,可以利用反向传播算法计算梯度,再用梯度下降方法在参数空间中寻找最优解。
浅层模型往往具有凸代价函数,理论分析相对简单,训练方法也容易掌握,取得了很多成功的应用。
随着人工智能的发展,计算机和智能网络如何通过基于算法革新,模拟人脑抽象认知和思维,准确且高清晰度的处理声音、图像传播甚至更为复杂的数据处理和问题解决等问题,在 21 世纪来临的时候成为摆在人工智能领域的关键问题。
30 年多来,加拿大多伦多大学计算机系辛顿教授(Hinton,G.)一直从事机器学习模型、神经网络与人工智能等问题的相关研究,并在机器学习模型特别是突破浅层学习模型,实现计算机抽象认知方面取得了突破性的进展。

深度学习是近年来人工智能领域的热门话题,它通过模仿人类大脑的神经网络结构,实现了诸多令人惊叹的成果。
然而,在实际应用中,我们发现深度学习算法在处理新领域的数据时,往往需要大量的标注样本才能取得较好的效果。
而由于获取标注样本通常非常耗时耗力,迁移学习和领域自适应就成为了解决这一问题的重要方法。
迁移学习是指在一个任务中学到的知识如何应用在另一个任务上的过程。
深度学习中的迁移学习则更加关注如何将已经训练好的模型应用到新的任务上。
这种方法通过利用已有模型中学到的知识,减少新任务的训练时间和标注样本数量,提高模型的泛化性能。
迁移学习的思想源于认知科学和生物学领域的研究,人类在掌握一项新技能时,往往能够利用之前学到的知识和经验。
深度学习中的迁移学习一般可以分为两种类型:基于特征的迁移和基于模型的迁移。
基于特征的迁移是指利用已训练模型的底层特征提取能力,将其作为新任务的输入特征进行训练。
比如,在图像分类任务中,可以使用在大规模图像数据集上预训练的卷积神经网络(CNN)提取图像的低级特征,然后用这些特征来训练一个简单的分类器。
由于底层特征对于不同的任务有一定的共性,因此通过这种方式可以在新任务上取得不错的效果。
基于模型的迁移则更加直接,即将已训练模型的参数直接应用到新任务中,而不仅仅是特征。
这种方法在新任务和原任务之间存在一定的相似性时效果较好。
例如,在自然语言处理任务中,可以利用已经训练好的语言模型来初始化新任务的模型参数,然后通过微调的方式进一步优化模型。
除了迁移学习,另一个解决深度学习中数据稀缺问题的方法是领域自适应。
领域自适应是指将已有领域的知识迁移到新领域上,使得模型对新领域的数据具有更好的泛化能力。
在深度学习中,领域自适应可以通过调整网络结构、标注样本权重等方式来实现。
领域自适应的一个重要思想是最大化源领域和目标领域之间的相似性,同时最小化它们的差异。
这可以通过对抗性训练来实现,例如生成对抗网络(GAN)。

监督学习中的迁移学习方法介绍迁移学习是机器学习领域中的一个重要分支,它旨在解决在一个领域中训练好的模型在另一个领域中表现较差的问题。
在监督学习中,迁移学习方法被广泛应用于各种任务,包括图像识别、自然语言处理、文本分类等。
本文将介绍几种常见的迁移学习方法,以及它们在监督学习中的应用。
领域自适应领域自适应是一种常见的迁移学习方法,它旨在解决源领域和目标领域分布不同的问题。
在监督学习中,领域自适应可以通过在源领域上训练好的模型来提高目标领域上的性能。
这种方法通常涉及到对源领域和目标领域的数据进行特征提取和变换,以使它们更加接近。
在图像识别任务中,领域自适应方法可以通过对图像进行特征提取和变换来提高模型的性能。
迁移学习的应用迁移学习方法在监督学习中有着广泛的应用。
在图像识别任务中,迁移学习方法可以通过在一个数据集上训练好的模型来提高在另一个数据集上的性能。
例如,可以使用在ImageNet数据集上预训练好的模型来提高在特定领域上的图像识别性能。
在自然语言处理任务中,迁移学习方法可以通过在一个任务上训练好的模型来提高在另一个任务上的性能。
例如,可以使用在大规模语料库上训练好的词向量来提高在文本分类任务上的性能。
深度迁移学习深度迁移学习是一种基于深度学习的迁移学习方法,它旨在解决在深度神经网络中的迁移学习问题。
在监督学习中,深度迁移学习方法可以通过在一个领域上训练好的深度神经网络来提高在另一个领域上的性能。
这种方法通常涉及到对神经网络的参数进行微调,以使它更适应目标领域的数据分布。
在图像识别任务中,深度迁移学习方法可以通过在一个大规模图像数据集上训练好的深度神经网络来提高在特定领域上的图像识别性能。
小结迁移学习是监督学习中的一个重要分支,它旨在解决在一个领域训练好的模型在另一个领域表现较差的问题。
在监督学习中,迁移学习方法被广泛应用于各种任务,包括图像识别、自然语言处理、文本分类等。
本文介绍了几种常见的迁移学习方法,以及它们在监督学习中的应用。

深度学习模型的迁移学习在迁移学习中的应用深度学习技术近年来在各个领域取得了巨大的突破和成功。
然而,训练一个高质量的深度学习模型需要大量的数据和计算资源,而这对于一些具有资源限制的任务来说是一项挑战。
为了解决这个问题,迁移学习逐渐受到了研究者们的关注。
迁移学习是指将一个已经在某个任务上学习过的深度学习模型应用于一个新的任务上的过程。
通过重用已经训练好的模型参数或共享模型的一部分参数,迁移学习可以有效提高在新任务上的性能。
下面我们将详细介绍深度学习模型的迁移学习在迁移学习中的应用。
一、迁移学习的定义与意义迁移学习是指在一个任务(源任务)上学到的知识能够迁移到另一个任务(目标任务)上,并且能够带来性能的提升。
传统的机器学习方法在不同任务之间通常需要重新进行数据收集、特征提取和模型训练,而迁移学习则可以通过利用源任务上已有的知识和模型参数,避免从头开始训练新模型,从而节省了时间和资源。
迁移学习的意义在于解决数据稀缺和计算资源有限的问题。
在许多实际应用中,由于某些任务的数据集难以获得或者成本过高,而且深度学习模型通常需要大量的计算资源来训练和优化。
通过迁移学习,我们可以利用已经训练好的模型在新任务上取得较好的表现,无需重新训练整个模型,减少了计算和数据开销。
二、迁移学习中的模型选择在迁移学习中,合适的模型选择是至关重要的。
一个好的模型应该具有通用性和泛化能力。
具体来说,我们可以选择预训练的深度神经网络模型,如在大规模图像分类任务上训练好的AlexNet、VGG或ResNet等模型。
这些模型通过在大规模数据集上进行训练,可以学到丰富的特征表示,并且具备较好的泛化能力。
当然,模型的选择也要考虑到目标任务的具体需求。
如果源任务和目标任务的输入领域差别较大,我们可以选择一些具有较强迁移能力的模型,如Domain Adversarial Neural Networks(DANN)等。
这类模型通过在特征层面上进行域适应,使得源领域和目标领域的特征分布更加相似,从而提高迁移学习的性能。

极视角学术分享王晋东中国科学院计算技术研究所2017年12月14日1迁移学习简介23451 迁移学习的背景⏹智能大数据时代⏹数据量,以及数据类型不断增加⏹对机器学习模型的要求:快速构建和强泛化能力⏹虽然数据量多,但是大部分数据往往没有标注⏹收集标注数据,或者从头开始构建每一个模型,代价高昂且费时⏹对已有标签的数据和模型进行重用成为了可能⏹传统机器学习方法通常假定这些数据服从相同分布,不再适用文本图片及视频音频行为1 迁移学习简介⏹迁移学习⏹通过减小源域(辅助领域)到目标域的分布差异,进行知识迁移,从而实现数据标定。
⏹核心思想⏹找到不同任务之间的相关性⏹“举一反三”、“照猫画虎”,但不要“东施效颦”(负迁移)减小差异知识迁移135源域数据标记数据难获取1 迁移学习应用场景⏹应用前景广阔⏹模式识别、计算机视觉、语音识别、自然语言处理、数据挖掘…不同视角、不同背景、不同光照的图像识别语料匮乏条件下不同语言的相互翻译学习不同用户、不同设备、不同位置的行为识别不同领域、不同背景下的文本翻译、舆情分析不同用户、不同接口、不同情境的人机交互不同场景、不同设备、不同时间的室内定位⏹数据为王,计算是核心⏹数据爆炸的时代!⏹计算机更强大了!⏹但是⏹大数据、大计算能力只是有钱人的游戏⏹云+端的模型被普遍应用⏹通常需要对设备、环境、用户作具体优化⏹个性化适配通常很复杂、很耗时⏹对于不同用户,需要不同的隐私处理方式⏹特定的机器学习应用⏹推荐系统中的冷启动问题:没有数据,如何作推荐?⏹为什么需要迁移学习⏹数据的角度⏹收集数据很困难⏹为数据打标签很耗时⏹训练一对一的模型很繁琐⏹模型的角度⏹个性化模型很复杂⏹云+端的模型需要作具体化适配⏹应用的角度⏹冷启动问题:没有足够用户数据,推荐系统无法工作因此,迁移学习是必要的1 迁移学习简介:迁移学习方法常见的迁移学习方法分类基于实例的迁移(instance based TL)•通过权重重用源域和目标域的样例进行迁移基于特征的迁移(feature based TL)•将源域和目标域的特征变换到相同空间基于模型的迁移(parameter based TL)•利用源域和目标域的参数共享模型基于关系的迁移(relation based TL)•利用源域中的逻辑网络关系进行迁移1 迁移学习简介:迁移学习方法研究领域常见的迁移学习研究领域与方法分类12领域自适应问题345⏹领域自适应问题⏹按照目标域有无标签⏹目标域全部有标签:supervised DA⏹目标域有一些标签:semi-supervised DA⏹目标域全没有标签:unsupervised DA⏹Unsupervised DA最有挑战性,是我们的关注点123领域自适应方法453 领域自适应:方法概览⏹基本假设⏹数据分布角度:源域和目标域的概率分布相似⏹最小化概率分布距离⏹特征选择角度:源域和目标域共享着某些特征⏹选择出这部分公共特征⏹特征变换角度:源域和目标域共享某些子空间⏹把两个域变换到相同的子空间⏹解决思路概率分布适配法(Distribution Adaptation)特征选择法(Feature Selection)子空间学习法(Subspace Learning)数据分布特征选择特征变换假设:条件分布适配(Conditional distribution假设:联合分布适配(Joint distribution adaptation)假设:源域数据目标域数据(1)目标域数据(2)⏹边缘分布适配(1)⏹迁移成分分析(Transfer Component Analysis,TCA)[Pan, TNN-11]⏹优化目标:⏹最大均值差异(Maximum Mean Discrepancy,MMD)⏹边缘分布适配(2)⏹迁移成分分析(TCA)方法的一些扩展⏹Adapting Component Analysis (ACA) [Dorri, ICDM-12]⏹最小化MMD,同时维持迁移过程中目标域的结构⏹Domain Transfer Multiple Kernel Learning (DTMKL) [Duan, PAMI-12]⏹多核MMD⏹Deep Domain Confusion (DDC) [Tzeng, arXiv-14]⏹把MMD加入到神经网络中⏹Deep Adaptation Networks (DAN) [Long, ICML-15]⏹把MKK-MMD加入到神经网络中⏹Distribution-Matching Embedding (DME) [Baktashmotlagh, JMLR-16]⏹先计算变换矩阵,再进行映射⏹Central Moment Discrepancy (CMD) [Zellinger, ICLR-17]⏹不只是一阶的MMD,推广到了k阶⏹条件分布适配⏹Domain Adaptation of Conditional Probability Models viaFeature Subsetting[Satpal, PKDD-07]⏹条件随机场+分布适配⏹优化目标:⏹Conditional Transferrable Components (CTC) [Gong,ICML-15]⏹定义条件转移成分,对其进行建模⏹联合分布适配(1)⏹联合分布适配(Joint Distribution Adaptation,JDA)[Long, ICCV-13]⏹直接继承于TCA,但是加入了条件分布适配⏹优化目标:⏹问题:如何获得估计条件分布?⏹充分统计量:用类条件概率近似条件概率⏹用一个弱分类器生成目标域的初始软标签⏹最终优化形式⏹联合分布适配的结果普遍优于比单独适配边缘或条件分布⏹联合分布适配(2)⏹联合分布适配(JDA)方法的一些扩展⏹Adaptation Regularization (ARTL) [Long, TKDE-14]⏹分类器学习+联合分布适配⏹Visual Domain Adaptation (VDA)[Tahmoresnezhad, KIS-17]⏹加入类内距、类间距⏹Joint Geometrical and Statistical Alignment (JGSA)[Zhang, CVPR-17]⏹加入类内距、类间距、标签适配⏹[Hsu,TIP-16]:加入结构不变性控制⏹[Hsu, AVSS-15]:目标域选择⏹Joint Adaptation Networks (JAN)[Long, ICML-17]⏹提出JMMD度量,在深度网络中进行联合分布适配平衡因子当,表示边缘分布更占优,应该优先适配⏹联合分布适配(4)⏹平衡分布适配(BDA):平衡因子的重要性⏹平衡分布适配(BDA):平衡因子的求解与估计⏹目前尚无精确的估计方法;我们采用A-distance来进行估计⏹求解源域和目标域整体的A-distance⏹对目标域聚类,计算源域和目标域每个类的A-distance ⏹计算上述两个距离的比值,则为平衡因子⏹对于不同的任务,边缘分布和条件分布并不是同等重要,因此,BDA 方法可以有效衡量这两个分布的权重,从而达到最好的结果⏹概率分布适配:总结⏹方法⏹基础:大多数方法基于MMD距离进行优化求解⏹分别进行边缘/条件/联合概率适配⏹效果:平衡(BDA)>联合(JDA)>边缘(TCA)>条件⏹使用⏹数据整体差异性大(相似度较低),边缘分布更重要⏹数据整体差异性小(协方差漂移),条件分布更重要⏹最新成果⏹深度学习+分布适配往往有更好的效果(DDC、DAN、JAN)BDA、JDA、TCA精度比较DDC、DAN、JAN与其他方法结果比较⏹特征选择法(Feature Selection)⏹从源域和目标域中选择提取共享的特征,建立统一模型⏹Structural Correspondence Learning (SCL) [Blitzer, ECML-06]⏹寻找Pivot feature,将源域和目标域进行对齐⏹特征选择法其他扩展⏹Joint feature selection and subspace learning [Gu, IJCAI-11]⏹特征选择/变换+子空间学习⏹优化目标:⏹Transfer Joint Matching (TJM) [Long, CVPR-14]⏹MMD分布适配+源域样本选择⏹优化目标:⏹Feature Selection and Structure Preservation (FSSL) [Li, IJCAI-16]⏹特征选择+信息不变性⏹优化目标:⏹特征选择法:总结⏹从源域和目标域中选择提取共享的特征,建立统一模型⏹通常与分布适配进行结合⏹选择特征通常利用稀疏矩阵⏹子空间学习法(Subspace Learning)⏹将源域和目标域变换到相同的子空间,然后建立统一的模型⏹统计特征变换(Statistical Feature Transformation)⏹将源域和目标域的一些统计特征进行变换对齐⏹流形学习(Manifold Learning)⏹在流形空间中进行子空间变换统计特征变换流形学习⏹统计特征变换(1)⏹子空间对齐法(Subspace Alignment,SA)[Fernando, ICCV-13]⏹直接寻求一个线性变换,把source变换到target空间中⏹优化目标:⏹直接获得线性变换的闭式解:⏹子空间分布对齐法(Subspace Distribution Alignment,SDA)[Sun, BMVC-15]⏹子空间对齐+概率分布适配⏹空间对齐法:方法简洁,计算高效⏹统计特征变换(2)⏹关联对齐法(CORrelation Alignment,CORAL)[Sun, AAAI-15]⏹最小化源域和目标域的二阶统计特征⏹优化目标:⏹形式简单,求解高效⏹深度关联对齐(Deep-CORAL) [Sun, ECCV-16]⏹在深度网络中加入CORAL⏹CORAL loss:⏹流形学习(1)⏹采样测地线流方法(Sample Geodesic Flow, SGF) [Gopalan, ICCV-11]⏹把领域自适应的问题看成一个增量式“行走”问题⏹从源域走到目标域就完成了一个自适应过程⏹在流形空间中采样有限个点,构建一个测地线流⏹测地线流式核方法(Geodesic Flow Kernel,GFK)[Gong, CVPR-12]⏹继承了SGF方法,采样无穷个点⏹转化成Grassmann流形中的核学习,构建了GFK⏹优化目标:SGF方法GFK方法⏹流形学习(2)⏹域不变映射(Domain-Invariant Projection,DIP)[Baktashmotlagh,CVPR-13]⏹直接度量分布距离是不好的:原始空间特征扭曲⏹仅作流形子空间学习:无法刻画分布距离⏹解决方案:流形映射+分布度量⏹统计流形法(Statistical Manifold) [Baktashmotlagh, CVPR-14]⏹在统计流形(黎曼流形)上进行分布度量⏹用Fisher-Rao distance (Hellinger distance)进行度量⏹子空间学习法:总结⏹主要包括统计特征对齐和流形学习方法两大类⏹和分布适配结合效果更好⏹趋势:与神经网络结合1234最新研究成果5⏹领域自适应的最新研究成果(1)⏹与深度学习进行结合⏹Deep Adaptation Networks (DAN)[Long, ICML-15]⏹深度网络+MMD距离最小化⏹Joint Adaptation Networks (JAN)[Long, ICML-17]⏹深度网络+联合分布距离最小化⏹Simultaneous feature and task transfer[Tzeng, ICCV-15]⏹特征和任务同时进行迁移⏹Deep Hashing Network (DHN) [CVPR-17]⏹在深度网络中同时学习域适应和深度Hash特征⏹Label Efficient Learning of Transferable Representations acrossDomains and Tasks [Luo, NIPS-17]⏹在深度网络中进行任务迁移⏹领域自适应的最新研究成果(2)⏹与对抗学习进行结合⏹Domain-adversarial neural network[Ganin, JMLR-16]⏹深度网络中加入对抗[Tzeng, arXiv-17]⏹Adversarial Discriminative Domain Adaptation (ADDA)⏹对抗+判别⏹开放世界领域自适应⏹Open set domain adaptation[Busto, ICCV-17]⏹当源域和目标域只共享一部分类别时如何迁移?⏹与张量(Tensor)表示相结合⏹When DA Meets tensor representation[Lu, ICCV-17]⏹用tensor的思想来做领域自适应⏹与增量学习结合⏹Learning to Transfer (L2T) [Wei, arXiv-17]⏹提取已有的迁移学习经验,应用于新任务12345参考资料图:Office+Caltech、USPS+MNIST、ImageNet+VOC、COIL20数据集•[Pan, TNN‐11] Pan S J, Tsang I W, Kwok J T, et al. Domain adaptation via transfer component analysis[J]. IEEE Transactions on Neural Networks, 2011, 22(2): 199‐210.•[Dorri, ICDM‐12] Dorri F, Ghodsi A. Adapting component analysis[C]//Data Mining (ICDM), 2012 IEEE 12th International Conference on. IEEE, 2012: 846‐851.•[Duan, PAMI‐12] Duan L, Tsang I W, Xu D. Domain transfer multiple kernel learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(3): 465‐479.•[Long, ICML‐15] Long M, Cao Y, Wang J, et al. Learning transferable features with deep adaptation networks[C]//International Conference on Machine Learning.2015: 97‐105.•[Baktashmotlagh, JMLR‐16] Baktashmotlagh M, Harandi M, Salzmann M. Distribution‐matching embedding for visual domain adaptation[J]. The Journal of Machine Learning Research, 2016, 17(1): 3760‐3789.•[Zellinger, ICLR‐17] Zellinger W, Grubinger T, Lughofer E, et al. Central moment discrepancy (CMD) for domain‐invariant representation learning[J]. arXiv preprint arXiv:1702.08811, 2017.•[Satpal, PKDD‐07] Satpal S, Sarawagi S. Domain adaptation of conditional probability models via feature subsetting[C]//PKDD. 2007, 4702: 224‐235.•[Gong, ICML‐15] Gong M, Zhang K, Liu T, et al. Domain adaptation with conditional transferable components[C]//International Conference on Machine Learning.2016: 2839‐2848.•[Long, ICCV‐13] M. Long, J. Wang, G. Ding, J. Sun, and P. S. Yu, “Transfer feature learning with joint distribution adaptation,”in ICCV, 2013, pp. 2200–2207.•[Long, TKDE‐14] Long M, Wang J, Ding G, et al. Adaptation regularization: A general framework for transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(5): 1076‐1089.•[Tahmoresnezhad, KIS‐17] J. Tahmoresnezhad and S. Hashemi, “Visual domain adaptation via transfer feature learning,” Knowl. Inf. Syst., 2016.•[Zhang, CVPR‐17] Zhang J, Li W, Ogunbona P. Joint Geometrical and Statistical Alignment for Visual Domain Adaptation, CVPR 2017.•[Hsu, AVSS‐15] T. Ming Harry Hsu, W. Yu Chen, C.‐A. Hou, and H. T. et al., “Unsupervised domain adaptation with imbalanced cross‐domain data,” in ICCV, 2015, pp. 4121–4129.•[Hsu, TIP‐16] P.‐H. Hsiao, F.‐J. Chang, and Y.‐Y. Lin, “Learning discriminatively reconstructed source data for object recognition with few examples,” TIP, vol. 25, no.8, pp. 3518–3532, 2016.•[Long, ICML‐17] Long M, Wang J, Jordan M I. Deep transfer learning with joint adaptation networks. ICML 2017.•[Wang, ICDM‐17] Wang J, Chen Y, Hao S, Feng W, Shen Z. Balanced Distribution Adaptation for Transfer Learning. ICDM 2017. pp.1129‐1134.•[Blitzer, ECML‐06] Blitzer J, McDonald R, Pereira F. Domain adaptation with structural correspondence learning[C]//Proceedings of the 2006 conference on empirical methods in natural language processing. Association for Computational Linguistics, 2006: 120‐128.•[Gu, IJCAI‐11] Gu Q, Li Z, Han J. Joint feature selection and subspace learning[C]//IJCAI Proceedings‐International Joint Conference on Artificial Intelligence. 2011, 22(1): 1294.•[Long, CVPR‐14] Long M, Wang J, Ding G, et al. Transfer joint matching for unsupervised domain adaptation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 1410‐1417.•[Li, IJCAI‐16] Li J, Zhao J, Lu K. Joint Feature Selection and Structure Preservation for Domain Adaptation[C]//IJCAI. 2016: 1697‐1703.•[Fernando, ICCV‐13] Fernando B, Habrard A, Sebban M, et al. Unsupervised visual domain adaptation using subspace alignment[C]//Proceedings of the IEEE international conference on computer vision. 2013: 2960‐2967.•[Sun, BMVC‐15] Sun B, Saenko K. Subspace Distribution Alignment for Unsupervised Domain Adaptation[C]//BMVC. 2015: 24.1‐24.10.•[Sun, AAAI‐16] Sun B, Feng J, Saenko K. Return of Frustratingly Easy Domain Adaptation[C]//AAAI. 2016, 6(7): 8.•[Sun, ECCV‐16] Sun B, Saenko K. Deep coral: Correlation alignment for deep domain adaptation[C]//Computer Vision–ECCV 2016 Workshops. Springer International Publishing, 2016: 443‐450.•[Gopalan, ICCV‐11] Gopalan R, Li R, Chellappa R. Domain adaptation for object recognition: An unsupervised approach[C]//Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011: 999‐1006.•[Gong, CVPR‐12] Gong B, Shi Y, Sha F, et al. Geodesic flow kernel for unsupervised domain adaptation[C]//Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012: 2066‐2073.•[Baktashmotlagh, CVPR‐13] Baktashmotlagh M, Harandi M T, Lovell B C, et al. Unsupervised domain adaptation by domain invariant projection[C]//Proceedings of the IEEE International Conference on Computer Vision. 2013: 769‐776.•[Baktashmotlagh, CVPR‐14] Baktashmotlagh M, Harandi M T, Lovell B C, et al. Domain adaptation on the statistical manifold[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014: 2481‐2488.•[Ganin, JMLR‐16] Ganin Y, Ustinova E, Ajakan H, et al. Domain‐adversarial training of neural networks[J]. Journal of Machine Learning Research, 2016, 17(59): 1‐35.•[Busto, ICCV‐17] Panareda Busto P, Gall J. Open Set Domain Adaptation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2017: 754‐763.•[Lu, ICCV‐17] Lu H, Zhang L, Cao Z, et al. When unsupervised domain adaptation meets tensor representations. ICCV 2017.•[Tzeng, arXiv‐17] Tzeng E, Hoffman J, Saenko K, et al. Adversarial discriminative domain adaptation[J]. arXiv preprint arXiv:1702.05464, 2017.•[Wei, arXiv‐17] Wei Y, Zhang Y, Yang Q. Learning to Transfer. arXiv1708.05629, 2017.。

神经网络中的迁移学习策略在神经网络领域,迁移学习策略已经成为一个备受瞩目的研究方向。
迁移学习的核心理念是将在一个任务上学到的知识应用到另一个相关任务中,以提高模型的性能和泛化能力。
本文将探讨神经网络中的迁移学习策略,包括其定义、应用领域、方法和挑战,以及未来的发展趋势。
## 1. 迁移学习的定义迁移学习,又称为知识迁移,是一种机器学习方法,旨在通过从一个任务中学到的知识来改善在另一个任务上的性能。
这种方法与传统的机器学习方法不同,后者通常假设训练数据和测试数据的分布是相同的。
在迁移学习中,我们面对的是不完全相同的分布或任务,这使得问题更具挑战性。
## 2. 迁移学习的应用领域迁移学习在多个领域中都有广泛的应用,其中一些重要的领域包括:### 自然语言处理(NLP)在NLP领域,迁移学习被用于情感分析、命名实体识别、机器翻译等任务。
通过在一个任务上训练的模型,可以更快速地在其他相关任务上取得良好的效果。
### 计算机视觉在计算机视觉中,迁移学习被用于图像分类、物体检测、人脸识别等任务。
通过从一个数据集中学到的特征,可以减少在新任务上的训练时间和数据需求。
### 强化学习迁移学习在强化学习中也有应用,帮助智能体在一个任务上学到的策略迁移到另一个任务中,从而提高学习效率。
### 医学影像分析在医学领域,迁移学习用于医学图像的分析和疾病诊断,减少了对大规模标记数据的需求,从而更快速地为患者提供帮助。
## 3. 迁移学习的方法迁移学习有多种方法,其中一些常见的包括:### 领域自适应领域自适应是一种常见的迁移学习方法,旨在解决源领域和目标领域之间的分布差异。
通过调整模型的参数或特征,使其适应目标领域的数据分布,可以提高性能。
### 迁移学习中的神经网络架构一些神经网络架构,如迁移学习中的卷积神经网络(CNNs)和循环神经网络(RNNs),已经被广泛用于迁移学习任务。
这些网络在不同任务之间共享层次特征,以促进知识的迁移。
什么是迁移学习?它都用在深度学习的哪些场景上?迁移学习是机器学习方法之一,它可以把为一个任务开发的模型重新用在另一个不同的任务中,并作为另一个任务模型的起点。
这在深度学习中是一种常见的方法。
由于在计算机视觉和自然语言处理上,开发神经网络模型需要大量的计算和时间资源,技术跨度也比较大。
所以,预训练的模型通常会被重新用作计算机视觉和自然语言处理任务的起点。
AInspir是一套完全由飔拓自主研发,基于Hadoop和Spark技术实现的企业级专业大数据分析挖掘平台,在它的帮助下,数据模型的设计如同编写伪代码一样容易,用户只需关注模型的高层结构,而无需担心任何琐碎的底层问题,可以快速建立数据模型来解决医疗、金融等实际问题,让人工智能发挥出最大作用。
这篇文章会发现告诉你,如何使用迁移学习来加速训练过程和提高深度学习模型的性能,以及解答以下三个问题:什么是迁移学习,以及如何使用它深度学习中迁移学习的常见例子在自己的预测模型问题上什么时候使用迁移学习什么是迁移学习?迁移学习是机器学习技术的一种,其中在一个任务上训练的模型被重新利用在另一个相关的任务上。
书本解释:“迁移学习和领域自适应指的是将一个任务环境中学到的东西用来提升在另一个任务环境中模型的泛化能力”——2016年“Deep Learning”,526页迁移学习也是一种优化方法,可以在对另一个任务建模时提高进展速度或者是模型性能。
“迁移学习就是通过从已学习的相关任务中迁移其知识来对需要学习的新任务进行提高。
”——第11章:转移学习,机器学习应用研究手册,2009年。
迁移学习还与多任务学习和概念漂移等问题有关,它并不完全是深度学习的一个研究领域。
尽管如此,由于训练深度学习模型所需耗费巨大资源,包括大量的数据集,迁移学习便成了深度学习是一种很受欢迎的方法。
但是,只有当从第一个任务中学到的模型特征是容易泛化的时候,迁移学习才能在深度学习中起到作用。
“在迁移学习中,我们首先在基础数据集和任务上训练一个基础网络,然后将学习到的特征重新调整或者迁移到另一个目标网络上,用来训练目标任务的数据集。
深度迁移学习中的域适应方法深度学习在计算机视觉、自然语言处理等领域取得了令人瞩目的成果,但在实际应用中,往往需要在不同的领域之间迁移学习。
然而,不同领域之间的数据分布往往存在差异,这导致传统的迁移学习方法无法有效地将知识从一个领域迁移到另一个领域。
为了解决这个问题,研究人员提出了一系列的域适应方法,帮助实现在深度迁移学习中的知识迁移。
本文将介绍几种常见的域适应方法,并分析其优缺点。
一、领域自适应(Domain Adaptation)领域自适应是一种常见的域适应方法,其目标是通过对源领域数据进行调整,使其在目标领域上表现更好。
最常见的领域自适应方法是通过最小化源领域和目标领域之间的分布差异来实现。
具体方法包括最大均值差异(Maximum Mean Discrepancy)和领域对抗神经网络(Domain Adversarial Neural Network)等。
1. 最大均值差异(Maximum Mean Discrepancy)最大均值差异是一种基于核方法的领域自适应方法。
该方法通过最小化源领域和目标领域的均值差异,来实现领域适应。
具体方法是通过将源领域数据和目标领域数据映射到一个特征空间,在特征空间中计算源领域和目标领域之间的均值差异,并最小化这个差异。
2. 领域对抗神经网络(Domain Adversarial Neural Network)领域对抗神经网络是一种深度学习方法,通过引入一个领域分类器来学习源领域和目标领域之间的差异。
具体方法是将源领域数据和目标领域数据输入到一个共享的特征提取器中,然后将提取到的特征输入到领域分类器和任务分类器中。
领域分类器的目标是将源领域和目标领域进行区分,而任务分类器的目标是进行分类任务。
通过对抗训练的方式,领域对抗神经网络能够降低源领域和目标领域之间的分布差异,实现领域适应。
二、特征选择(Feature Selection)特征选择是另一种常见的域适应方法,其目标是寻找对源领域和目标领域都有用的特征,去除对迁移学习无用的特征。
跨领域知识迁移的深度学习方法深度学习(Deep Learning)是一种基于人工神经网络的机器学习方法,近年来在各个领域中都取得了显著的成果。
随着大数据时代的到来,知识的积累愈加庞大,跨领域知识迁移成为了重要的研究方向。
在这篇文章中,我们将探讨跨领域知识迁移的深度学习方法。
一、介绍跨领域知识迁移是指将已经学习过的知识应用于新的领域中。
传统的机器学习算法在处理跨领域问题时往往面临着数据不匹配、特征差异等困难,而深度学习方法则可以通过学习抽象的特征表示来解决这些问题。
在跨领域知识迁移的研究中,深度学习方法发挥着重要的作用。
二、深度神经网络深度神经网络是深度学习的核心工具,具有多层的神经网络结构。
这些网络通常包括输入层、隐藏层和输出层,每一层都由多个神经元组成。
深度神经网络通过反向传播算法来不断调整网络参数,从而实现对输入数据的有效表示和学习。
三、迁移学习迁移学习是跨领域知识迁移的基础理论。
在迁移学习中,我们将从源领域中学习到的知识应用于目标领域中。
深度学习方法可以通过共享网络层次结构和参数来实现迁移学习。
通过共享网络参数,源领域和目标领域之间的相关知识可以得到有效的传递和利用。
四、深度迁移学习方法在深度迁移学习中,我们常用的方法包括:1. 基于预训练模型的迁移学习:预训练模型是在大规模数据上训练得到的模型,可以捕捉到一定领域的语义信息。
我们可以使用预训练模型作为初始模型,在目标领域上进行微调,以提高模型在目标领域上的性能。
2. 多任务学习:多任务学习是指在一个模型中同时学习多个相关任务。
通过共享网络层次结构和参数,模型可以将不同任务中的知识相互迁移和补充。
这种方法可以提高模型的泛化能力和学习效率。
3. 领域自适应:领域自适应是指通过学习领域间的映射关系,将源领域中的知识应用于目标领域中。
这种方法可以最小化源领域和目标领域之间的差异,从而提高模型在目标领域上的性能。
五、应用案例深度学习的跨领域知识迁移方法在许多领域中都得到了广泛应用。
深度学习是人工智能领域中备受瞩目的研究方向。
随着深度学习模型的发展和应用场景的不断扩大,人们开始关注如何将已有的知识和经验迁移到新的任务或领域中。
这就是迁移学习的研究内容。
同时,为了进一步提高深度学习模型的泛化能力和适应不同的数据分布,领域自适应成为了一个热门话题。
本文将探讨深度学习中的迁移学习与领域自适应的概念、方法以及应用。
一、迁移学习的概念迁移学习是一种利用已有知识和经验来改善模型在新任务或新领域上性能的方法。
传统的机器学习中,每个任务通常都需要从零开始训练一个独立的模型,而迁移学习则可以通过重用已有模型的一部分或全部参数,来加快新任务的学习速度,并提升模型的表现。
迁移学习可以分为以下几种类型:同领域迁移、异领域迁移、单任务迁移、多任务迁移等。
不同类型的迁移学习方法适用于不同的场景和问题。
二、领域自适应的概念领域自适应是迁移学习的一种重要形式,主要用于解决源域和目标域分布不同的问题。
在实际应用中,由于数据来源的限制,所得到的源域数据与目标域数据之间存在一定的差异,这会导致在目标域上应用源域训练的模型时出现性能下降的情况。
领域自适应的目标就是通过训练一个能够适应目标域数据分布的模型,使源域的知识能够在目标域上有效地推广。
三、迁移学习与领域自适应的方法在深度学习中,迁移学习与领域自适应的方法有很多种。
其中,基于特征的方法是一类常用的方法。
这种方法通过提取源域数据和目标域数据的共享特征,来保持数据的一致性。
例如,在图像领域,可以通过使用卷积神经网络提取图像的特征,然后使用特定的迁移层将源域和目标域的特征进行对齐,从而达到迁移学习的目的。
另外,基于实例的方法也是一种常见的迁移学习和领域自适应的方法。
这种方法通过选择一些与目标域数据相似的源域实例,将其作为目标域的样本,并与目标域的数据一起进行训练。
这样可以增加目标域数据的多样性,提高模型的泛化能力。
例如,在自然语言处理领域,可以通过将一些与目标领域相似的领域的文本数据与目标域数据一起训练,来提高模型在目标领域上的表现。
深度学习中的迁移学习与领域自适应方法简介引言:在计算机视觉领域,迁移学习和领域自适应是两个重要的技术概念。
它们被广泛应用于解决深度学习网络在数据量不足或数据分布不匹配的情况下的挑战。
本文将介绍深度学习中的迁移学习和领域自适应方法,以及它们在实际应用中的意义和效果。
一、迁移学习的概念与原理迁移学习是指通过将已学习知识从一个任务或领域迁移到另一个任务或领域,以提升目标任务的性能。
其理论基础是源领域和目标领域之间的相似性。
在传统的机器学习方法中,迁移学习常通过调整特征表示或使用预训练的模型进行实现。
而在深度学习中,更常见的迁移学习方式是基于深度神经网络的迁移。
深度神经网络的迁移学习通常分为两种方式:特征提取器的迁移和模型微调。
特征提取器的迁移是指通过冻结预训练的模型的前几层,并将这些层作为特征提取器来提取源领域和目标领域的共享特征。
然后,可以使用这些共享特征作为输入来训练目标任务的特定分类器。
模型微调是指在预训练的模型基础上,对部分或全部网络参数进行微调,以适应目标任务的特征表示。
迁移学习的优势在于可以加速模型的训练过程,减少对大量标注数据的需求,同时提高目标任务的性能和泛化能力。
通过从一个任务中学到的知识,迁移到另一个任务上,可以充分利用已有知识的信息,提高模型对于新任务的理解和推理能力。
二、领域自适应的概念与方法领域自适应是迁移学习的一种特殊形式,主要解决源领域和目标领域分布上的差异问题。
在深度学习中,由于源领域和目标领域的数据分布不匹配,直接将源领域模型应用于目标领域往往会出现性能下降的情况。
因此,领域自适应方法被提出来解决这一问题。
领域自适应方法主要包括实例重加权、特征选择和特征映射等技术。
实例重加权是通过引入权重来调整源领域和目标领域的样本分布,从而减小源领域和目标领域之间的差异。
特征选择是在特征空间中选择具有较强判别能力的特征,以减小特征空间的差异。
特征映射是通过学习一个映射函数,将源领域和目标领域的特征映射到一个共享的空间中,使其在该空间中的分布保持一致。
了解AI中的迁移学习和迁移学习策略迁移学习(Transfer Learning)是指将已经学习到的知识和经验应用于新的问题上,从而加快学习速度和提升学习性能的一种机器学习方法。
在人工智能(Artificial Intelligence, AI)领域中,迁移学习被广泛应用于各种任务中,如图像识别、语音识别、自然语言处理等。
本文将介绍迁移学习的概念、原理以及常用的迁移学习策略。
一、迁移学习的概念和原理迁移学习的概念最早由心理学家Donald M. Miller提出,他将其定义为先前学习的经验和知识对新学习任务的影响。
在机器学习领域中,迁移学习是指将从一个或多个源域(Source Domain)学习到的知识迁移到一个目标域(Target Domain)上的学习方式。
在传统的机器学习任务中,我们通常假设源域和目标域的数据分布和任务是相同的。
然而,在现实中,这个假设往往难以满足。
迁移学习的一个核心目标就是通过利用源域和目标域之间的相关性,将在源域上学习到的知识迁移到目标域上,以提升目标域上任务的性能。
迁移学习的原理可以用一个简单的例子来解释。
假设我们已经在一个大规模的图像数据集上训练了一个深度卷积神经网络(Convolutional Neural Network, CNN),并且取得了很好的图像识别结果。
现在我们需要在一个新的小规模图像数据集上进行图像分类任务。
由于新的数据集规模较小,单独训练一个新的深度学习模型可能会导致过拟合。
这时,我们可以利用之前在大规模数据集上训练的模型参数作为初始参数,在新的数据集上进行微调(fine-tuning),从而提升新任务的性能。
二、迁移学习的策略迁移学习的策略可以分为几个方面,下面我们将介绍几种常用的迁移学习策略。
1. 基于模型的迁移学习基于模型的迁移学习是将源域数据的模型应用于目标域的学习过程。
这种策略通常需要借助源域和目标域之间的数据映射关系,将源域数据中的特征映射到目标域。