计量经济学eviews应用习题
- 格式:doc
- 大小:148.50 KB
- 文档页数:3

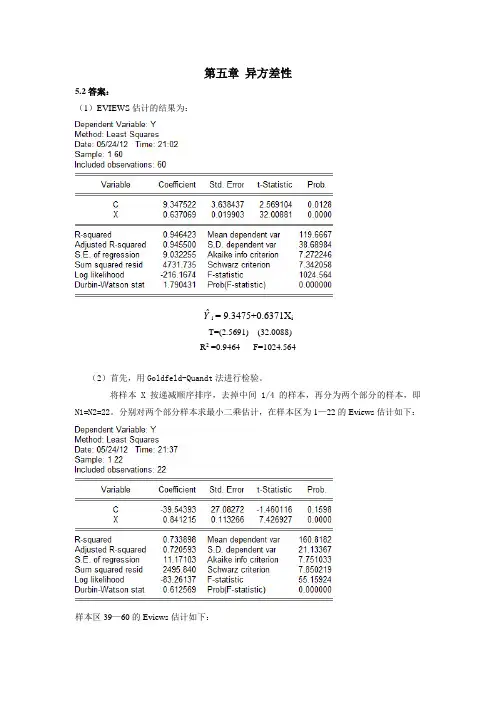
第五章异方差性5.2答案:(1)EVIEWS估计的结果为:Yˆi= 9.3475+0.6371X iT=(2.5691) (32.0088)R2 =0.9464 F=1024.564(2)首先,用Goldfeld-Quandt法进行检验。
将样本X按递减顺序排序,去掉中间1/4的样本,再分为两个部分的样本,即N1=N2=22。
分别对两个部分样本求最小二乘估计,在样本区为1—22的Eviews估计如下:样本区39—60的Eviews估计如下:得到两个部分各自的残差平方和,即∑e 12 =2495.840∑e 22 =603.0148求F 统计量为: F=∑∑e e 2221=2495.840/603.0148=4.1390给定α=0.05,查F 分布表,得临界值为F 0.05=(20,20)=2.12.比较临界值与F 统计量值,有F =4.1390>F 0.05=(20,20)=2.12,说明该模型的随机误差项存在异方差。
其次,用White 法进行检验结果如下:给定α=0.05,在自由度为2下查卡方分布表,得χ2=5.9915。
比较临界值与卡方统计量值,即nR2=10.8640>χ2=5.9915,同样说明模型中的随机误差项存在异方差。
(2)用权数W1=1/X,作加权最小二乘估计,得如下结果用White法进行检验得如下结果:F-statistic 3.138491 Probability 0.050925Obs*R-squared 5.951910 Probability 0.050999。
比较临界值与卡方统计量值,即nR2=5.9519<χ2=5.9915,说明加权后的模型中的随机误差项不存在异方差。
其估计的结果为:Yˆi= 10.3705+0.6309X iT=(3.9436) (34.0467)R2 =0.21144 F=1159.176 DW=0.95855.3答案:(1)EVIEWS估计结果:Yˆi= 179.1916+0.7195X iT=(0.808709) (15.74411)R2 =0.895260 F=247.8769 DW=1.461684 (2)利用White方法检验异方差,则White检验结果见下表:由上述结果可知,该模型存在异方差。
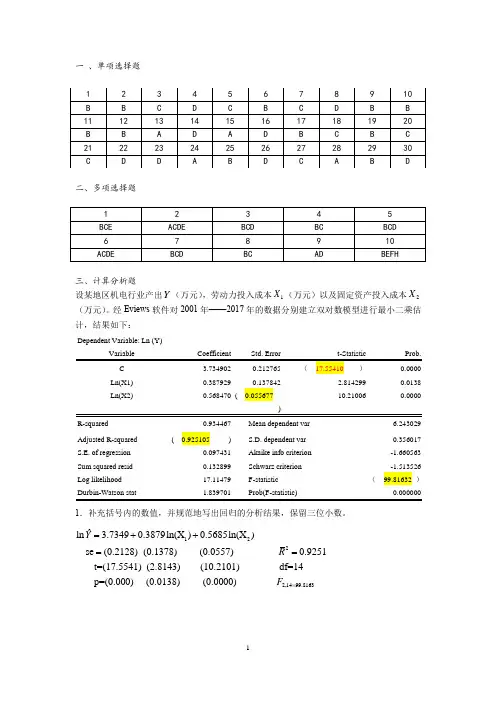
一 、单项选择题二、多项选择题三、计算分析题设某地区机电行业产出Y (万元),劳动力投入成本1X (万元)以及固定资产投入成本2X (万元)。
经Eviews 软件对2001年——2017年的数据分别建立双对数模型进行最小二乘估计,结果如下:Dependent Variable: Ln (Y)Ln(X1) 0.3879290.1378422.814299 0.0138 Ln(X2)0.568470 ( 0.05567710.210060.0000R-squared 0.934467 Mean dependent var6.243029 Adjusted R-squared ( 0.925105 ) S.D. dependent var0.356017 S.E. of regression 0.097431 Akaike info criterion -1.660563 Sum squared resid 0.132899 Schwarz criterion -1.513526 Log likelihood 17.11479 F-statistic ( 99.81632 )1.补充括号内的数值,并规范地写出回归的分析结果,保留三位小数。
122ˆln 3.73490.3879ln(X )0.5685ln(X ) se (0.2128) (0.1378) (0.0557) 0.9251t=(17.5541) (2.8143) (10.2101) df=14 p=(0.000) (0.0138)Y R =++==2,1499.8163(0.0000) F =2. 对模型的估计结果进行偏回归系数和整体显著性检验。
(t0.025(14)=2.145;t0.025(15)=2.131;F0.05(2,14)=3.74;F0.05(3,14)=3.34)。
(注意运用临界值法!!)样本量为17,临界值选取t0.025(14)=2.145F临界值选取F0.05(2,14)=3.743. 如果有两种可供选择的措施以提高机电行业产出,措施一是加大劳动力的投入,措施二是增大固定资产的投入,你认为哪个措施效果更明显,为什么?选择措施二,因为劳动力成本增长1个百分点,机电行业产增长0.39个百分点,而固定资产投入成本增长1个百分点,机电行业销售额仅增长0.57个百分点四、分析题根据我国31个细分制造业的数据,得到生产函数的如下估计结果:ln(Ŷi)=1.168+0.37ln(K i)+0.61ln(L i)se= (0.331) ( a) (0.1293)t= (3.53) ( 4.23) ( b )R2=0.94其中,Y为总产出,K为资本投入,L为劳动投入。

计量经济学复习习题第二章回归模型习题一、填空题:1.在Eviews 软件中,估计线性模型的命令是__LS_____。
2.在Eviews 软件中,估计非线性模型的命令是_____NLS_____。
3.被解释变量的观测值i Y 与其回归理论值)(Y E 之间的偏差,称为__随机扰动项__;被解释变量的观测值i Y 与其回归估计值i Y ?之间的偏差,称为____残差____。
4.对线性回归模型μββ++=X Y 10进行最小二乘估计,最小二乘准则是残差平方和最小。
5.高斯—马尔可夫定理证明在总体参数的各种无偏估计中,普通最小二乘估计量具有方差最小的特性,并由此才使最小二乘法在数理统计学和计量经济学中获得了最广泛的应用。
6.普通最小二乘法得到的参数估计量具有无偏性、有效性、一致性统计性质。
9.对计量经济学模型作统计检验包括 R 平方检验、F 检验、 T 检验。
10.判定系数R 2可以判定回归直线拟合的优劣,又称为可决系数。
11.可以利用线性回归模型的系数直接进行边际分析,利用双对数模型的回归系数进行弹性分析。
12.动态模型是在方程中引入滞后变量。
二、单选题:1.回归分析中定义的( B )A.解释变量和被解释变量都是随机变量B.解释变量为非随机变量,被解释变量为随机变量C.解释变量和被解释变量都为非随机变量D.解释变量为随机变量,被解释变量为非随机变量2.最小二乘准则是指使(D )达到最小值的原则确定样本回归方程。
A.()∑=-n t tt Y Y 1? B.∑=-n t t t Y Y 1? C.t t Y Y ?max - D.()21?∑=-n t t t Y Y3.双对数模型μββ++=X Y ln ln 10中,参数1β的含义是( D )。
A.X 的相对变化,引起Y 的期望值绝对量变化B.Y 关于X 的边际变化C.X 的绝对量发生一定变动时,引起因变量Y 的相对变化率D.Y 关于X 的弹性4.在多元回归中,调整后的判定系数与判定系数的关系有 ( B)A .< B . > C . = D .与的关系不确定 5.根据样本资料已估计得出人均消费支出Y 对人均收入X 的回归方程为X Y ln 75.000.2ln +=),这表明人均收入每增加1%,人均消费支出将增加(C )。
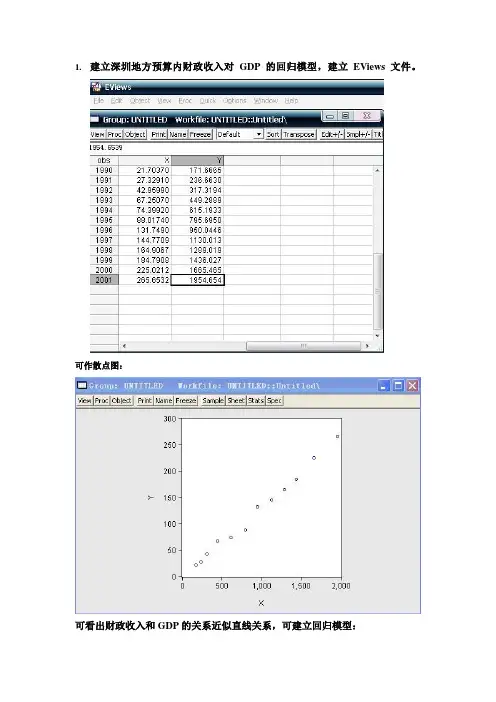
1.建立深圳地方预算内财政收入对GDP的回归模型,建立EViews文件。
可作散点图:可看出财政收入和GDP的关系近似直线关系,可建立回归模型:=i Y i i 21μββ++GDP利用EViews 估计其参数结果为即 =i γ-3.611151+0.134582GDP i(4.16179) (0.003867)t=(-0.867692) (34.80013)R=0.99181 F=1211.049经检验说明,GDP 对地方财政收入确有显著影响。
R=0.99181,说明GDP 解释了地方财政收入变动的99%,模型拟合程度较好。
模型说明当GDP 每增长1亿元,平均说来地方财政收入将增长0.134582亿元。
当2005年GDP 为3600亿元时,地方财政收入的点预测值为=2005Y -3.611151+0.134582*3600=480.884(亿元)区间预测: 平均值为:∑x x i σ=(n-1)=587.2686*587.2686*(12-1)=3793728.494 (3600-917.5874)*(3600-917.5874)=7195337.357取∂=0.05,Y 平均值置信度95%预测区间为2005GDP =3600时 480.884±2.228*7.5325*494.3293728357.7195337121+=44±25.2735(亿元) Y 个别值置信度95%的预测区间为:即 480.884±2.228*7.5325*494.3293728357.71953371211++=480.884±30.3381(亿元)2. 呈现负相关关系,计算线性相关系数为-0.882607.作散点图:建立描述投诉率(Y )依赖航班按时到达正点率(X )的回归方程:i t 21t μββ++=X Y利用EViews 估计其参数结果为即t Y=6.017832-0.070414t X(1.017832)(-0.014176)t=(5.718961)(-4.967254)R=0.778996 F=24.67361这说明当航班正点到达比率每提高1个百分点,平均说来每10万名乘客投诉次数将下降0.07次。

《计量经济学》实验报告实验一:EViews5.0软件安装及基本操作女人看完这些文章还没过隐吗?请速度看下面的↓↓女人推荐精彩文章↓↓注:下载原文后点及连接进入,不下载无法观看养胸美胸比养脸更重要,女性朋友一定要知道男人厌倦女人身体的全过程,惊呆了!卖爆了!采用iphone6外观设计理念~顶极高配神机~万众期待,顶级配置卖爆了!TVS沿用劳力士经典款设计打造,顶级镶钻机械腕表官方活动价698元】限量1折抢大牌! 仅此一天全国货到付款!送自己送朋友送父母(孝敬父母首选)解压安装包,双击“Setup.exe”,选择安装路径进行安装;安装完毕后,复制“eviews5.0破解文件夹”下的“eviews5.reg文件”和“eviews5.exe文件”到安装目录下;双击“Eviews5.reg”进行注册,安装完毕。
2.基本操作(数据来源于李子奈版课后习题P61.12)运行Eviews,依次单击file→new→work file→unstructed→observation 31。
命令栏中输入“data y gdp”,打开“y gdp”表,接下来将数据输入其中。
做出“y gdp”的散点图,依次单击quick→graph→scatter→gdp y。
结果如下:开始进行LS回归:回归方程为:Y = -10.39340931 + 0.0710********GDP对回归方程做检验:斜率项t值9.59大于t在5%显著水平下的检验值2.045,拒绝零假设;截距项t 值0.121小于2.045,接受零假设。
可决系数0.76,拟合较好,方程F检验值91.99通过F检验。
下面进行预测:拓展工作空间:打开work file窗口,单击 Proc→Structure,将End date 的数据31→32;确定预测值的起止日期:打开work file窗口,点击Quick→Sample,填入“1 32”。
打开GDP数据表,在GDP的最下方填,按回车键。

计量经济学论文e v i e w s 分析计量经济作业The document was prepared on January 2, 2021我国旅游收入的计量分析一、经济理论陈述在研读了大量统计和计量资料的基础上,选择了三个大方面进行研究,既包括旅游人数,人均旅游花费和基本交通建设.其中,在旅游人数这个解释变量的划分上,我们考虑到随着全球经济一体化的发展,越来越多的外国游客来中国旅游消费.中国旅游的国际市场是个有发展潜力的新兴市场,尽管外国游客前来旅游的方式包罗万象而且消费能力也不尽相同,但从国际服务贸易的角度出发,我们在做变量选择时,运用国际营销的知识进行市场细分,划分了国际和国内两个市场.这样,在旅游人数这个解释变量的最终确定上,我们选择了2X国内旅游人数,3X入境旅游人数.这点选择除了理论支持外,在现实旅游业发展中我们也看到很多景区包括成都的近郊也有不少外国游客的身影.所以,我们选取这两个解释变量等待下一步进行模型设计和检验.另外,对于人均旅游花费,我们在进行市场细分时,没有延续前两个变量的选择模式,有几个原因.首先,外国游客前来旅游的形式和消费方式各异且很难统计.我们在花大力气收集数据后,仍然没有比较权威的统计数据资料.其次,随着国家对农业的不断重视和扶持,我国农业有了长足发展.农村居民纯收入增加,用于旅游的花费也有所上升.而且鉴于农村人口较多,前面的市场细分也不够细化,在这个解释变量的确定上,我们选择农村人均旅游花费,既是从我国基本国情出发,也是对第一步研究分析的补充.所以我们确定了4X城镇居民人均旅游花费和5X农村居民人均旅游花费.旅游发展除了对消费者市场的划分研究,还应考虑到该产业的基础硬件设施.在众多可选择对象中我们经分析研究结合大量文献资料决定从交通建设着手.在我国,交通一般分布为公路,铁路,航班,航船等.由于考虑到我国一般大众的旅游交通方式集中在公路和铁路上,为了避免解释变量的过多过繁以及可能带来的多重共线形等问题,我们只选取了前二者.即确定了6X公路长度和7X铁路长度这两个解释变量.其中,考虑到我国旅游业不断发展过程中,高速公路的修建也不断增多,在6X的确定过程中,我们已经将其拟合,尽量保证解释变量的完整和真实.二、相关数据三、计量经济模型的建立Y=c1+c2X2+c3X3+c4X4+c5X5+c6X6+U我们建立了下述的一般模型:其中Y——1994-2003年各年全国旅游收入C1——待定参数X——国内旅游人数万人2X——入境旅游人数万人3X——城镇居民人均旅游花费元4X——农村居民人均旅游花费元5X——公路长度含高速万公里6X——铁路长度万公里7U——随即扰动项四、模型的求解和检验利用Eviews软件,采用以上数据对该模型进行OLS回归,结果如下:Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 01:56Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.CX2X3X4X5X6X7R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic由此可见,该模型可决系数很高,F检验显着,但是2X、6X、7X的系数t检验不显着,且7X的系数符号不符合经济意义,说明存在严重的多重共线性.所以进行以下修正:〈一〉.计量方法检验及修正多重共线性的检验:首先对Y进行各个解释变量的逐步回归, 由最小二乘法,结合经济意义和统计检验得出拟合效果最好的两个解释变量如下:Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 02:00Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.CX4X5R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic继续采用逐步回归法将其余解释变量代入,得出拟合效果最好的三个解释变量,结果如下:Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 02:01Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.CX2X4X5R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic以上模型估计效果最好,继续逐步回归得到以下结果:Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 02:40Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.CX2X3X4X5R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic各项拟合效果都较好.虽然2X的t检验不是很显着,但考虑到其经济意义在模型中的重要地位,暂时保留.继续引入6X.Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 02:41Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.CX2X3X4X5X6R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic根据以上回归结果可得,6X的引入使得模型中2X、6X的t检验均不显着,再考察二者的相关系数为,说明2X、6X高度相关,模型产生了多重共线性,因此将6X去掉.再将7X代入检验.Dependent Variable: YMethod: Least SquaresDate: 12/23/10 Time: 02:42Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.CX2X3X4X5X7R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statisticX的系数为负,与经济意义相悖,因此也去掉.由此确定带入模型的解7释变量为2X、3X、4X、5X.异方差性的检验:再对模型的异方差性进行检验:鉴于我们的样本资料是时间序列数据,选用ARCH检验.ARCH Test:F-statistic ProbabilityObsR-squared ProbabilityTest Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 12/23/10 Time: 02:43Sample adjusted: 1995 2003Included observations: 9 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.CRESID^2-1R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid +08 Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic这里ObsR-squared为,P=>所以接受0H,表明模型中随机误差项不存在异方差.再考虑P=3的情况:ARCH Test:F-statistic ProbabilityObsR-squared ProbabilityTest Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 12/23/10 Time: 02:46Sample adjusted: 1997 2003Included observations: 7 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.CRESID^2-1RESID^2-2RESID^2-3R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid +08 Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic这里ObsR-squared为,P=>.所以仍然接受0H,表明模型中随机误差项不存在异方差.自相关性的检验:随机扰动项可能存在一阶负自相关.借助残差项和其一阶滞后项的二维坐标图进一步分析:由图示可看出,残差项和其一阶滞后项显然存在负自相关,然后利用对数线形回归修正自相关性,得到相应结果如下:Dependent Variable: LOGYMethod: Least SquaresDate: 12/23/10 Time: 02:52Sample: 1994 2003Included observations: 10Variable Coefficient Std. Error t-Statistic Prob.CLOGX2LOGX3LOGX4LOGX5R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watson stat ProbF-statistic从估计的结果看,DW=,说明修正后有了明显好转,随机扰动项几乎不存在一阶自相关.我们进行了一系列检验和修正后的最终结果如下:2R= 2R= F=五、经济意义解释C3和C3分别衡量我国旅游收入国内和入境旅游人数的弹性,也就是表示当旅游人数每变动百分之一时,平均来说,旅游收入变动的百分比.这里要特别注意,例如1998年国内旅游人数为69450万人,入境旅游人数为万人,则国内旅游人数每增加1%,即增加万人,国内旅游收入增加%,而入境旅游人数每增加1%,即增加万人,国内旅游收入增加%.C4和C5分别衡量我国旅游收入我国城镇居民和农村居民人均旅游花费的弹性,也就表示当人均花费每变动百分之一时,平均来说,旅游收入变动的百分比.城镇居民人均旅游花费每增加1%,国内旅游收入增加%;农村居民人均旅游花费每增加1%,国内旅游收入增加 %.六、政策建议为了促进我国旅游事业的快速发展,我们提出了以下几点建议:1、实施政府主导型旅游发展战略政府主导型旅游发展战略是按照旅游业自身的特点,在以市场为主,合理配置资源的基础上,充分发挥政府的主导作用,促进旅游业更快发展.1建设和完善旅游法制体系,力争旅游法的尽早出台.2提高旅游管理部门的地位,或组织高层次的协调机制,以适应旅游产业大规模和大发展的前景.3中央政府的主导需要相应的资金基础.从1992年起,财政部建立了旅游发展基金,其来源是在出境机场费中加收20元人民币,对旅游业的发展起到了积极的作用.考虑到旅游大发展的需要,多渠道,多形式开辟政府基金来源是必要的.4加大促销投入.长期以来我国促销经费严重缺乏.中央一年所能提供的促销经费不足500万美元,这大大限制了我国对国际旅游市场大面积,深层次的开发,难以产生影响客源流向的招徕效果.从国际上看,为了使自己处在有利的市场竞争地位,每个国家每年都投入相当数量的旅游经费,用于开展旅游对外促销活动.按照世界一般规律,吸引一个国际旅游者平均需要3—5美元的促销经费,而我国尚不足美元,这种状态,显然无法适应国际旅游市场竞争的需要. 因此,在政府主导型战略的实施中加大促销投入是一项重要的工作.2、旅游市场创新旅游经济是特色经济,而特色就需要充分地发扬创新意识,做到人无我有,人有我精,人精我专. 对于旅游市场的开拓,各地旅游开发和建设模式大同小异,无论是山水风景区,历史文化名城,滨海沙滩度假地,还是温泉休养区,大都只是大众旅游市场的共同特征,因此,重复建设的模式正成为旅游开拓市场的通病.随着现代旅游者需求日益成熟,伴随着主题公园等人造景区大规模发展之势,生态旅游由于世界各国重视人和自然共生共存共荣环保概念的强化,以可持续发展为方向的生态旅游正在世界各地呈方兴未艾之势.区域旅游的发展开始以若干不同旅游项目满足相应不同分众市场的开发模式以获得综合整体效益,形成规模经济的发展趋势.3、不同产业匹配发展产业之间相互联系,旅游业的存在不是独立的,在促进旅游业的同时也要加大工业和农业的发展.如我国农业人口占据很大比例,而国内旅游收入的主要来源集中在为数不多的城镇居民上,农村市场还存在很大的空白.可以说,我国的国内旅游市场还没有开发完全,农村市场非常广阔,具有很大潜力,所以发展农业,必然会极大促进我国的旅游事业.。

中级计量经济学-第四章-习题以及解答思路(EViews)第4章习题一表1给出了1965~1970年美国制造业利润和销售额的季度数据。
假定利润不仅与销售额有关,而且和季度因素有关。
要求对下列二种情况分别估计利润模型:(1)如果认为季度影响使利润平均值发生变异,应如何引入虚拟变量?(2)如果认为季度影响使利润对销售额的变化率发生变异,如何引入虚拟变量?表1Quarterly 65-70Quick- Equation EstimationY c x @seas(1) @seas(2) @seas(3)Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 18:38Sample: 1965Q1 1970Q4Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C6868.0151892.766 3.6285590.0018 X0.0382650.011483 3.3322520.0035 @SEAS(1)-182.1690654.3568-0.2783940.7837 @SEAS(2)1140.294630.6806 1.8080380.0865 @SEAS(3)-400.3371636.1128-0.6293490.5366R-squared0.525596Mean dependentvar12838.54Adjusted R-squared0.425721S.D. dependentvar1433.284S.E. of regression1086.160Akaike infocriterion17.00174Sum squared resid22415107Schwarz criterion17.24716 Log likelihood-199.0208F-statistic 5.262563Durbin-Watson stat0.388380Prob(F-statistic)0.005024T和P在5%情况下都不通过,第二季度相对还好一点假设第二季度显著,结果的经济含义是什么?Y c x @seas(2) @seas(3) @seas(4)Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 18:47Sample: 1965Q1 1970Q4Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C6685.8461711.618 3.9061550.0009 X0.0382650.0114833.3322520.0035 @SEAS(2)1322.463638.4258 2.0714440.0522 @SEAS(3)-218.1681632.1991-0.3450940.7338@SEAS(4)182.1690654.35680.2783940.7837R-squared0.525596Mean dependentvar12838.54Adjusted R-squared0.425721S.D. dependentvar1433.284S.E. of regression1086.160Akaike infocriterion17.00174Sum squared resid22415107Schwarz criterion17.24716 Log likelihood-199.0208F-statistic 5.262563Durbin-Watson stat0.388380Prob(F-statistic)0.005024第二季度依旧显著影响四种都试一下(去掉一个季节),选一个最显著的124Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 18:51Sample: 1965Q1 1970Q4Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C6467.6781789.178 3.6148880.0018 X0.0382650.011483 3.3322520.0035 @SEAS(1)218.1681632.19910.3450940.7338 @SEAS(2)1540.632628.3419 2.4519000.0241 @SEAS(4)400.3371636.11280.6293490.5366R-squared0.525596Mean dependentvar12838.54Adjusted R-squared0.425721S.D. dependentvar1433.284S.E. of regression1086.160Akaike infocriterion17.00174Sum squared resid22415107Schwarz criterion17.24716 Log likelihood-199.0208F-statistic 5.262563Durbin-Watson stat0.388380Prob(F-statistic)0.005024134Dependent Variable: Y Method: Least SquaresDate: 11/26/14 Time: 18:52 Sample: 1965Q1 1970Q4 Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C8008.3091827.543 4.3820090.0003 X0.0382650.011483 3.3322520.0035 @SEAS(1)-1322.463638.4258-2.0714440.0522 @SEAS(3)-1540.632628.3419-2.4519000.0241 @SEAS(4)-1140.294630.6806-1.8080380.0865R-squared0.525596Mean dependentvar12838.54Adjusted R-squared0.425721S.D. dependentvar1433.284S.E. of regression1086.160Akaike infocriterion17.00174Sum squared resid22415107Schwarz criterion17.24716 Log likelihood-199.0208F-statistic 5.262563Durbin-Watson stat0.388380Prob(F-statistic)0.005024(2)Y=c+βx+α1D1X+α2D2X+α3D3XD1=1(第一季度)0(其他)Y c x @seas(1)*x @seas(2)*x @seas(3)*xDependent Variable: Y Method: Least SquaresDate: 11/26/14 Time: 19:00 Sample: 1965Q1 1970Q4 Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C6965.8521753.642 3.9722200.0008 X0.0373630.011139 3.3542150.0033 @SEAS(1)*X-0.0008930.004259-0.2095880.8362 @SEAS(2)*X0.0077120.003962 1.9465020.0665 @SEAS(3)*X-0.0022910.004041-0.5669850.5774R-squared0.528942Mean dependentvar12838.54Adjusted R-squared0.429771S.D. dependentvar1433.284S.E. of regression1082.323Akaike infocriterion16.99466Sum squared resid22257030Schwarz criterion17.24009 Log likelihood-198.9359F-statistic 5.333675Durbin-Watson stat0.418713Prob(F-statistic)0.004722Dependent Variable: Y Method: Least SquaresDate: 11/26/14 Time: 19:10 Sample: 1965Q1 1970Q4 Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C8008.3091827.543 4.3820090.0003 X0.0382650.011483 3.3322520.0035 @SEAS(1)-1322.463638.4258-2.0714440.0522 @SEAS(3)-1540.632628.3419-2.4519000.0241 @SEAS(4)-1140.294630.6806-1.8080380.0865R-squared0.525596Mean dependentvar12838.54Adjusted R-squared0.425721S.D. dependent 1433.284varS.E. of regression1086.160Akaike infocriterion17.00174Sum squared resid22415107Schwarz criterion17.24716 Log likelihood-199.0208F-statistic 5.262563Durbin-Watson stat0.388380Prob(F-statistic)0.005024Dependent Variable: Y Method: Least SquaresDate: 11/26/14 Time: 19:11 Sample: 1965Q1 1970Q4 Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C6965.8521753.642 3.9722200.0008 X0.0350720.011790 2.9746750.0078 @SEAS(1)*X0.0013980.0042410.3297360.7452 @SEAS(2)*X0.0100030.004068 2.4588230.0237 @SEAS(4)*X0.0022910.0040410.5669850.5774R-squared0.528942Mean dependentvar12838.54Adjusted R-squared0.429771S.D. dependentvar1433.284S.E. of regression1082.323Akaike infocriterion16.99466Sum squared resid22257030Schwarz criterion17.24009 Log likelihood-198.9359F-statistic 5.333675Durbin-Watson stat0.418713Prob(F-statistic)0.004722Dependent Variable: Y Method: Least SquaresDate: 11/26/14 Time: 19:11 Sample: 1965Q1 1970Q4 Included observations: 24Variable Coefficient Std. Error t-Statistic Prob.C6965.8521753.642 3.9722200.0008 X0.0364710.012353 2.9524150.0082 @SEAS(2)*X0.0086040.004237 2.0305390.0565 @SEAS(3)*X-0.0013980.004241-0.3297360.7452@SEAS(4)*X0.0008930.0042590.2095880.8362R-squared0.528942Mean dependentvar12838.54Adjusted R-squared0.429771S.D. dependent 1433.284varS.E. of regression1082.323Akaike infocriterion16.99466Sum squared resid22257030Schwarz criterion17.24009 Log likelihood-198.9359F-statistic 5.333675Durbin-Watson stat0.418713Prob(F-statistic)0.004722。

实验练习题1、根据美国各航空公司航班正点到达的比率X (%)和每10万名乘客投诉的次数Y 进Dependent Variable: Y Method: Least Squares Sample: 1 9(1)对以上结果进行简要分析(包括方程显著性检验、参数显著性检验、DW 值的评价、对斜率的解释等,显著性水平均取0.05)。
(2)按标准书写格式写出回归结果。
2、已知变量Y 和X 的数据如下表所示,试采用OLS 法(列出表格)估计模型i Y =0β3、以下是某次线性回归的EViews 输出结果,部分数值已略去(用大写字母标示),但它们和表中其它特定数值有必然联系,分别据此求出这些数值,并写出过程。
(保留3位小数)Dependent Variable: YMethod: Least Squares Sample: 1 134、用1970-1994年间日本工薪家庭实际消费支出Y 与实际可支配收入X (单位:103日元)数据估计线性模型Y =01X u ββ++,然后用得到的残差序列t e 绘制以下图形。
(1)试根据图形分析随机误差项之间是否存在自相关?若存在,是正自相关还是负自相关?(2)此模型的估计结果为 ˆ50.870.64ttYX =+ t : (6.14) (30.01)2R =0.975,F =900.51,DW =0.35试用DW 检验法检验随机误差项之间是否存在自相关。
5、用一组截面数据估计消费(Y )—收入(X )方程Y =01X u ββ++的结果为i Y =9.3480.637i X +t :(2.57)(32.01)2R =0.95,F =1024.56,DW =1.79(1)根据回归的残差序列e(t)图分析本模型是否存在异方差?注:abs[e(t)]表示e(t)的绝对值。
(2)其次,用White法进行检验。
EViews输出结果见下表:Dependent Variable: RESID^2Method: Least SquaresSample: 1 60Included observations: 60若给定显著水平,以上结果能否说明该模型存在异方差?查卡方分布临界值的自由度是多少?6. 下表是中国某地人均可支配收入(INCOME)与储蓄(SAVE)之间的回归分析结果(单位:元):Dependent Variable: SAVEMethod: Least SquaresSample: 1 31Included observations: 31Variable Coefficient Std. Error t-Statistic Prob.C -695.1433 118.0444 -5.888827 0.0000INCOME 0.087774 0.004893 ――――R-squared 0.917336 Mean dependent var 1266.452Adjusted R-squared 0.914485 S.D. dependent var 846.7570S.E. of regression 247.6160 Akaike info criterion 13.92398Sum squared resid 1778097. Schwarz criterion 14.01649Log likelihood -213.8216 F-statistic 321.8177Durbin-Watson stat 1.892420 Prob(F-statistic) 0.0000001)请写出样本回归方程表达式,然后分析自变量回归系数的经济含义2)解释样本可决系数的含义3)写出t检验的含义和步骤,并在5%的显著性水平下对自变量的回归系数进行t检验(临界值: t0.025(29)=2.05)。

计量经济学实验练习题及答案TTA standardization office【TTA 5AB- TTAK 08- TTA 2C】实验练习题1、根据美国各航空公司航班正点到达的比率X (%)和每10万名乘客投诉的次数Y 进行回归,EViews Method: Least SquaresSample: 1 9(1)对以上结果进行简要分析(包括方程显着性检验、参数显着性检验、DW 值的评价、对斜率的解释等,显着性水平均取)。
(2)按标准书写格式写出回归结果。
2、已知变量Y 和X 的数据如下表所示,试采用OLS 法(列出表格)估计模型i Y =0β+3、以下是某次线性回归的EViews 输出结果,部分数值已略去(用大写字母标示),但它们位小数)Method: Least SquaresSample: 1 134、用1970-1994年间日本工薪家庭实际消费支出Y 与实际可支配收入X (单位:103日元)数据估计线性模型Y =01X u ββ++,然后用得到的残差序列t e 绘制以下图形。
(1)试根据图形分析随机误差项之间是否存在自相关若存在,是正自相关还是负自相关(2)此模型的估计结果为t :2R =,F =,DW =试用DW 检验法检验随机误差项之间是否存在自相关。
5、用一组截面数据估计消费(Y )—收入(X )方程Y =01X u ββ++的结果为i Y =9.3480.637i X +t :()()2R =,F =,DW =(1)根据回归的残差序列e(t)图分析本模型是否存在异方差?注:abs[e(t)]表示e(t)的绝对值。
(2)其次,用White 法进行检验。
EViews 输出结果见下表:Method: Least Squares Sample: 1 60若给定显着水平α=是多少6. 下表是中国某地人均可支配收入(INCOME )与储蓄(SAVE )之间的回归分析结果(单位:元):Dependent Variable: SAVEMethod: Least Squares Sample: 1 31Included observations: 31VariableCoefficient Std. Errort-StatisticProb.CINCOME――――R-squaredMean dependent varAdjusted R-squared . dependent var . of regressionAkaike info criterionSum squared resid 1778097. Schwarz criterionLog likelihoodF-statisticDurbin-Watson statProb(F-statistic)1)请写出样本回归方程表达式,然后分析自变量回归系数的经济含义 2)解释样本可决系数的含义3)写出t 检验的含义和步骤,并在5%的显着性水平下对自变量的回归系数进行t 检验(临界值: (29)=)。
计量经济学习题一、名词解释1、普通最小二乘法:为使被解释变量的估计值与观测值在总体上最为接近使Q= 最小,从而求出参数估计量的方法,即之。
2、总平方和、回归平方和、残差平方和的定义:TSS度量Y自身的差异程度,称为总平方和。
TSS除以自由度n-1=因变量的方差,度量因变量自身的变化;RSS度量因变量Y的拟合值自身的差异程度,称为回归平方和,RSS除以自由度(自变量个数-1)=回归方差,度量由自变量的变化引起的因变量变化部分;ESS度量实际值与拟合值之间的差异程度,称为残差平方和。
RSS除以自由度(n-自变量个数-1)=残差(误差)方差,度量由非自变量的变化引起的因变量变化部分。
3、计量经济学:计量经济学是以经济理论为指导,以事实为依据,以数学和统计学为方法,以电脑技术为工具,从事经济关系与经济活动数量规律的研究,并以建立和应用经济计量模型为核心的一门经济学科。
而且必须指出,这些经济计量模型是具有随机性特征的。
4、最小样本容量:即从最小二乘原理和最大似然原理出发,欲得到参数估计量,不管其质量如何,所要求的样本容量的下限;即样本容量必须不少于模型中解释变量的数目(包扩常数项),即之。
5、序列相关性:模型的随机误差项违背了相互独立的基本假设的情况。
6、多重共线性:在线性回归模型中,如果某两个或多个解释变量之间出现了相关性,则称为多重共线性。
7、工具变量法:在模型估计过程中被作为工具使用,以替代模型中与随机误差项相关的随机解释变量。
这种估计方法称为工具变量法。
8、时间序列数据:按照时间先后排列的统计数据。
9、截面数据:发生在同一时间截面上的调查数据。
10、相关系数:指两个以上的变量的样本观测值序列之间表现出来的随机数学关系。
11、异方差:对于线性回归模型提出了若干基本假设,其中包括随机误差项具有同方差;如果对于不同样本点,随机误差项的方差不再是常数,而互不相同,则认为出现了异方差性。
12、外生变量:外生变量是模型以外决定的变量,作为自变量影响内生变量,外生变量决定内生变量,其参数不是模型系统的元素。
第二章简单线性回归模型2.1(1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: YMethod: Least SquaresDate: 12/23/15 Time: 14:37Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 56.64794 1.960820 28.88992 0.0000 X1 0.128360 0.027242 4.711834 0.0001R-squared 0.526082 Mean dependentvar 62.50000Adjusted R-squared 0.502386 S.D. dependentvar 10.08889S.E. of regression 7.116881 Akaike infocriterion 6.849324Sum squared resid 1013.000 Schwarzcriterion 6.948510Log likelihood -73.34257 Hannan-Quinncriter. 6.872689F-statistic 22.20138 Durbin-Watsonstat 0.629074 Prob(F-statistic) 0.000134有上可知,关系式为y=56.64794+0.128360x1②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 12/23/15 Time: 15:01Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 38.79424 3.532079 10.98340 0.0000 X2 0.331971 0.046656 7.115308 0.0000R-squared 0.716825 Mean dependentvar 62.50000Adjusted R-squared 0.702666 S.D. dependentvar 10.08889S.E. of regression 5.501306 Akaike infocriterion 6.334356Sum squared resid 605.2873 Schwarzcriterion 6.433542Log likelihood -67.67792 Hannan-Quinncriter. 6.357721F-statistic 50.62761 Durbin-Watsonstat 1.846406 Prob(F-statistic) 0.000001由上可知,关系式为y=38.79424+0.331971x2③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 12/23/14 Time: 15:20Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 31.79956 6.536434 4.864971 0.0001 X3 0.387276 0.080260 4.825285 0.0001R-squared 0.537929 Mean dependentvar 62.50000Adjusted R-squared 0.514825 S.D. dependentvar 10.08889S.E. of regression 7.027364 Akaike infocriterion 6.824009Sum squared resid 987.6770 Schwarzcriterion 6.923194Log likelihood -73.06409 Hannan-Quinncriter. 6.847374F-statistic 23.28338 Durbin-Watsonstat 0.952555Prob(F-statistic) 0.000103由上可知,关系式为y=31.79956+0.387276x3(2)①关于人均寿命与人均GDP模型,由上可知,可决系数为0.526082,说明所建模型整体上对样本数据拟合较好。
一、问题背景高新区自开始设立至今短短十多年的时间,以其惊人的经济发展速度为世人所关注。
随着我国经济发展模式的逐步转变,高新区已经成为我国依靠科技进步和技术创新推动经济社会发展、走中国特色自主创新道路的一面旗帜。
“十二五”时期,面对新的机遇和挑战,国家高新区应注重提升五种能力,努力成为加快转变经济发展方式的排头兵。
为了探索高新经济发展的内在规律性,本文采用截面数据对高新区的投入产出进行分析,力求能够增进对高新区经济发展的了解,对高新区的进一步发展有所帮助。
二、模型设定本文研究的是高新区投入对产出的影响,所以本模型的被解释变量Y 即为高新区的产出。
就目前对高新区数据的统计来看,反映高新区产出的主要有“工业总产值”、“工业增加值”、“技工贸总收入”、“利润”和“上缴税额”几个总量指标。
按照生产函数理论,产出利用增加值,所以模型中我们将使用“工业增加值”指标数据来估计各高新区的总产出。
从高新区的投入来看,对产出有重要影响的因素主要包括以下几个方面:资本K ,劳动力L ,技术投入T ,此外,体制改革,管理模式创新也可以看作是投入的要素,但因其不可量化,因此归入模型的扰动项中。
这样,按照科布道格拉斯形式的生产函数,我们设定函数形式为:u T L AK Y γβα= 两边取自然对数得:u T L K A Y ln ln ln ln ln ln ++++=γβα其中,资本数据K 我们利用的是当年的年末净资产来进行估计,即当年年末资产减去当年年末负债后得到的数据;用当年年末从业人员来估计劳动力L ;用当年技术研发投入来估计技术投入T 。
数据选用的是截面数据。
从《国家高新技术产业开发区十年发展报告(1991-2000年)》得到1999年全国53个高新区各项指标统计数据:三、模型估计用Eviews 软件进行回归分析,得到如下结果:Dependent Variable: Y Method: Least SquaresDate: 13/12/11 Time: 19:31 Sample: 1 53C 0.664556 0.644854 1.030553 0.3078 LNK 0.478131 0.171585 2.786560 0.0076 LNL 0.367855 0.174496 2.108104 0.0402 R-squared0.740558 Mean dependent var6.280427Adjusted R-squared 0.724674 S.D. dependent var 0.440805 S.E. of regression 0.231297 Akaike info criterion -0.017755Sum squared resid 2.621421 Schwarz criterion 0.130946 Log likelihood4.470508 F-statistic 46.62236从表可以看出,回归方程为:TL K Y ln 140542.0ln 367855.0ln 478131.0664556.0ln +++=T= (1.030553) (2.786560) (2.109104) (1.520604)740558.02=R 724674.02=R(1) 经济意义检验从回归结果可以看出,模型估计的γβα,,的参数值都为正、且小于1,与生产函数理论中γβα,,各数值的意义相符。
(单位:亿元) 年份国民总收入X最终消费年份国民总收入最终消费YXY1978 3645.217 2239.1 1993 35260.02 21899.9 1979 4062.579 2633.7 1994 48108.46 29242.2 1980 4545.624 3007.9 1995 59810.53 36748.2 1981 4889.461 3361.5 1996 70142.49 43919.5 1982 5330.451 3714.8 1997 78060.83 48140.6 1983 5985.552 4126.4 1998 83024.28 51588.2 1984 7243.752 4846.3 1999 88479.15 55636.9 1985 9040.737 5986.3 2000 98000.45 61516 1986 10274.38 6821.8 2001 108068.2 66878.3 1987 12050.62 7804.6 2002 119095.7 71691.2 1988 15036.82 9839.5 2003 135174 77449.5 1989 17000.92 11164.2 2004 159586.7 87032.9 1990 18718.32 12090.5 2005 184088.6 97822.7 1991 21826.2 14091.9 2006 213131.7 110595.3 199226937.28 17203.3 2007251483.2 128444.6(1)以分析国民总收入对消费的推动作用为目的,建立线性回归方案,并估计其参数。
根据散点图可以建立如下简单线性回归模型:t Y =1β+t X 2β+t u利用EViews 可得回归结果:据表可得tY ˆ=3044.343+0.530112t X +t u t=(3.399965)(54.82076)1ˆβ=3044.343 2ˆβ=0.530112(2)计算回归估计的标准误差σˆ和可决系数2R 。
《计量经济学(第二版)》习题解答第一章1.1 计量经济学的研究任务是什么?计量经济模型研究的经济关系有哪两个基本特征? 答:(1)利用计量经济模型定量分析经济变量之间的随机因果关系。
(2)随机关系、因果关系。
1.2 试述计量经济学与经济学和统计学的关系。
答:(1)计量经济学与经济学:经济学为计量经济研究提供理论依据,计量经济学是对经济理论的具体应用,同时可以实证和发展经济理论。
(2)统计数据是建立和评价计量经济模型的事实依据,计量经济研究是对统计数据资源的深层开发和利用。
1.3 试分别举出三个时间序列数据和横截面数据。
1.4 试解释单方程模型和联立方程模型的概念,并举例说明两者之间的联系与区别。
1.5 试结合一个具体经济问题说明计量经济研究的步骤。
1.6 计量经济模型主要有哪些用途?试举例说明。
1.7 下列设定的计量经济模型是否合理,为什么?(1)ε++=∑=31i iiGDP b a GDPε++=3bGDP a GDP其中,GDP i (i =1,2,3)是第i 产业的国内生产总值。
答:第1个方程是一个统计定义方程,不是随机方程;第2个方程是一个相关关系,而不是因果关系,因为不能用分量来解释总量的变化。
(2)ε++=21bS a S其中,S 1、S 2分别为农村居民和城镇居民年末储蓄存款余额。
答:是一个相关关系,而不是因果关系。
(3)ε+++=t t t L b I b a Y 21其中,Y 、I 、L 分别是建筑业产值、建筑业固定资产投资和职工人数。
答:解释变量I 不合理,根据生产函数要求,资本变量应该是总资本,而固定资产投资只能反映当年的新增资本。
(4)ε++=t t bP a Y其中,Y 、P 分别是居民耐用消费品支出和耐用消费品物价指数。
答:模型设定中缺失了对居民耐用消费品支出有重要影响的其他解释变量。
按照所设定的模型,实际上假定这些其他变量的影响是一个常量,居民耐用消费品支出主要取决于耐用消费品价格的变化;所以,模型的经济意义不合理,估计参数时可能会夸大价格因素的影响。
为研究中国改革开放以来国民总收入与最终消费的关系,搜集到以下数据。
(单位:亿元) 年份
国民总收
入X
最终消费
年份
国民总收入
最终消费
Y
X
Y
1978 3645.217 2239.1 1993 35260.02 21899.9 1979 4062.579 2633.7 1994 48108.46 29242.2 1980 4545.624 3007.9 1995 59810.53 36748.2 1981 4889.461 3361.5 1996 70142.49 43919.5 1982 5330.451 3714.8 1997 78060.83 48140.6 1983 5985.552 4126.4 1998 83024.28 51588.2 1984 7243.752 4846.3 1999 88479.15 55636.9 1985 9040.737 5986.3 2000 98000.45 61516 1986 10274.38 6821.8 2001 108068.2 66878.3 1987 12050.62 7804.6 2002 119095.7 71691.2 1988 15036.82 9839.5 2003 135174 77449.5 1989 17000.92 11164.2 2004 159586.7 87032.9 1990 18718.32 12090.5 2005 184088.6 97822.7 1991 21826.2 14091.9 2006 213131.7 110595.3 1992
26937.28 17203.3 2007
251483.2 128444.6
(1)以分析国民总收入对消费的推动作用为目的,建立线性回归方案,并估计其参数。
根据散点图可以建立如下简单线性回归模型:
t Y =1β+t X 2β+t u
利用EViews 可得回归结果:
据表可得
t
Y ˆ=3044.343+0.530112t X +t u t=(3.399965)(54.82076)
1ˆβ=3044.343 2
ˆβ=0.530112
(2)计算回归估计的标准误差σˆ和可决系数2
R 。
σ
ˆ=3580.903 R 2
=0.990769 DW=0.128755
(3)对回归系数进行显著性水平为5%的显著性检验。
0H :1β=0 0H :2β=0
由表中可以看到:SE(1ˆβ)=895.4040,t(1ˆβ)=3.399965 SE(2ˆβ)=0.009670,t(2
ˆβ)=54.82076 显著性水平为5%,即α=5%,查t 分布表得自由度为n-2=28的临界值025.0t (28)=2.048
因为:t(1ˆβ)=3.399965>025.0t (28)=2.048,所以应拒绝0H :1β=0 t(2ˆβ)=54.82076>025.0t (28)=2.048,所以应拒绝0H :2β=0
这表明,国民总收入X 对最终消费Y 确有显著影响。
(4)如果2008年全年国民总收入为300670亿元,比上年增长9.0%,预测可能达到的最终消费水平,并对最终消费的均值给出置信度为95%的预测空间。
利用所估计的模型,可预测当2008年f
Y ˆ=3044.343+0.530112×300670=162433.118(亿元) 利用EViews ,可得当2008年f X =300670亿元时,最终消费的点预测值为162433.2(亿元) 为了作区间预测,根据题意取置信度为95%,即α=5%
f Y 平均值置信度95%的预测区间为2
22/)(1ˆ
ˆi f f x X X n t Y ∑-+σα 通过EViews 可知:
据表可计算出:2
i x ∑=)1(2
-n x σ=68765.512
×(30-1)=1.3713×1011
2
)(X X f -=(300670-63270.07)2
=5.6359×1010
当f X =300670亿元时,将相关数据代入计算得到
162433.118 2.048×3580.903×11
10
10
713.3110359.65301⨯⨯+=162433.118 4888.4577 即,当2008年f X =300670时,f Y 平均值置信度95%的预测区间为 (157544.6603,167321.5757)亿元。