CentOS6.6安装hadoop2.7.3教程
- 格式:docx
- 大小:3.08 MB
- 文档页数:42

Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS本教程讲述如何配置Hadoop 集群,默认读者已经掌握了Hadoop 的单机伪分布式配置,否则请先查看Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置。
本教程由厦门大学数据库实验室出品,转载请注明。
本教程适合于原生Hadoop 2,包括Hadoop 2.6.0, Hadoop 2.7.1 等版本,主要参考了官方安装教程,步骤详细,辅以适当说明,保证按照步骤来,都能顺利安装并运行Hadoop。
另外有Hadoop安装配置简略版方便有基础的读者快速完成安装。
为了方便新手入门,我们准备了两篇不同系统的Hadoop 伪分布式配置教程。
但其他Hadoop 教程我们将不再区分,可同时适用于Ubuntu 和CentOS/RedHat 系统。
例如本教程以Ubuntu 系统为主要演示环境,但对Ubuntu/CentOS 的不同配置之处、CentOS 6.x 与CentOS 7 的操作区别等都会尽量给出注明。
环境本教程使用Ubuntu 14.04 64位作为系统环境,基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1,Hadoop 2.4.1 等。
本教程简单的使用两个节点作为集群环境: 一个作为Master 节点,局域网IP 为192.168.1.121;另一个作为Slave 节点,局域网IP 为192.168.1.122。
准备工作Hadoop 集群的安装配置大致为如下流程:1.选定一台机器作为Master2.在Master 节点上配置hadoop 用户、安装SSH server、安装Java 环境3.在Master 节点上安装Hadoop,并完成配置4.在其他Slave 节点上配置hadoop 用户、安装SSH server、安装Java 环境5.将Master 节点上的/usr/local/hadoop 目录复制到其他Slave 节点上6.在Master 节点上开启Hadoop配置hadoop 用户、安装SSH server、安装Java 环境、安装Hadoop 等过程已经在Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置中有详细介绍,请前往查看,不再重复叙述。

1.1软件环境1)CentOS6.5x642)Jdk1.7x643)Hadoop2.6.2x644)Hbase-0.98.95)Zookeeper-3.4.61.2集群环境集群中包括 3个节点:1个Master, 2个Slave2安装前的准备2.1下载JDK2.2下载Hadoop2.3下载Zookeeper2.4下载Hbase3开始安装3.1 CentOS安装配置1)安装3台CentOS6.5x64 (使用BasicServer模式,其他使用默认配置,安装过程略)2)Master.Hadoop 配置a)配置网络修改为:保存,退出(esc+:wq+enter ),使配置生效b) 配置主机名修改为:c)配置 hosts修改为:修改为:在最后增加如下内容以上调整,需要重启系统才能生效g) 配置用户新建hadoop用户和组,设置 hadoop用户密码id_rsa.pub ,默认存储在"/home/hadoop/.ssh" 目录下。
a) 把id_rsa.pub 追加到授权的 key 里面去b) 修改.ssh 目录的权限以及 authorized_keys 的权限c) 用root 用户登录服务器修改SSH 配置文件"/etc/ssh/sshd_config"的下列内容3) Slavel.Hadoop 、Slavel.Hadoop 配置及用户密码等等操作3.2无密码登陆配置1)配置Master 无密码登录所有 Slave a)使用 hadoop 用户登陆 Master.Hadoopb)把公钥复制所有的 Slave 机器上。
使用下面的命令格式进行复制公钥2) 配置Slave 无密码登录Mastera) 使用hadoop 用户登陆Slaveb)把公钥复制Master 机器上。
使用下面的命令格式进行复制公钥id_rsa 和相同的方式配置 Slavel 和Slave2的IP 地址,主机名和 hosts 文件,新建hadoop 用户和组c) 在Master机器上将公钥追加到authorized_keys 中3.3安装JDK所有的机器上都要安装 JDK ,先在Master服务器安装,然后其他服务器按照步骤重复进行即可。
centos 7+hadoop2.7.3详细安装教程前言:Hadoop 运行在jar环境下,因此安装hadoop的前提是得在系统上安装好jdk。
本次实验环境使用centos7进行安装。
需要安装的工具:1.虚拟机2.Centos 7镜像文件3.Filezilla(用于上传本地下载的hadoop镜像到centos系统,以及可以远程操作linux 文件系统)4.secureCrt(远程连接linux,敲指令方便。
本次安装的linux是没有图形界面的,命令窗口不能复制粘贴,因此使用secureCRT操作linux系统,方便后续修改hadoop 文件时可以复制粘贴)5.JDK镜像6.Hadoop2.7.3镜像文件一、虚拟机安装a)安装最新版本,具体安装方法比较简单,请上网自行搜索。
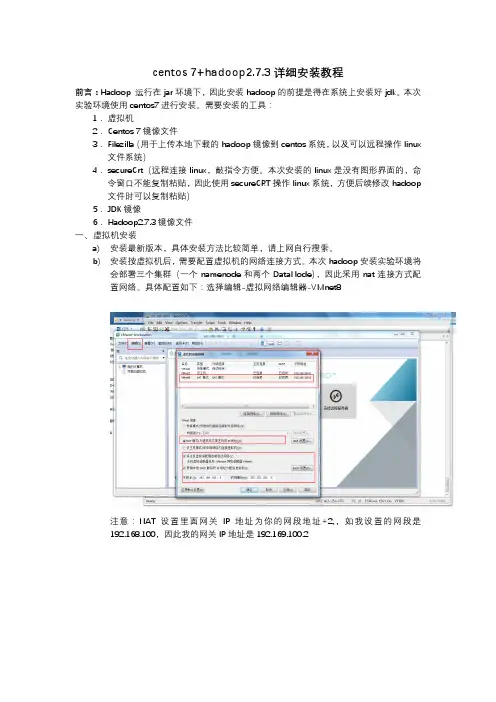
b)安装按虚拟机后,需要配置虚拟机的网络连接方式。
本次hadoop安装实验环境将会部署三个集群(一个namenode和两个DataNode),因此采用nat连接方式配置网络。
具体配置如下:选择编辑-虚拟网络编辑器-VMnet8注意:NAT设置里面网关IP地址为你的网段地址+2,,如我设置的网段是192.168.100,因此我的网关IP地址是192.169.100.2二、安装三台centos7(三台安装方式一样,仅是里面IP地址配置不一样。
具体安装多少台视各位看官需要配置多少集群而定)a)文件菜单选择新建虚拟机b)选择经典类型安装,下一步。
c)选择稍后安装操作系统,下一步。
d)选择Linux系统,版本选择CentOS7 64位。
e)命名虚拟机,给虚拟机起个名字,将来显示在Vmware左侧。
并选择Linux系统保存在宿主机的哪个目录下,应该一个虚拟机保存在一个目录下,不能多个虚拟机使用一个目录。
f)指定磁盘容量,是指定分给Linux虚拟机多大的硬盘,默认20G就可以,下一步。
g)点击自定义硬件,可以查看、修改虚拟机的硬件配置,这里我们不做修改。

Hadoop的安装与配置建立一个三台电脑的群组,操作系统均为Ubuntu,三个主机名分别为wjs1、wjs2、wjs3。
1、环境准备:所需要的软件及我使用的版本分别为:Hadoop版本为0.19.2,JDK版本为jdk-6u13-linux-i586.bin。
由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
所以在三台主机上都设置一个用户名为“wjs”的账户,主目录为/home/wjs。
a、配置三台机器的网络文件分别在三台机器上执行:sudo gedit /etc/network/interfaceswjs1机器上执行:在文件尾添加:auto eth0iface eth0 inet staticaddress 192.168.137.2gateway 192.168.137.1netmask 255.255.255.0wjs2和wjs3机器上分别执行:在文件尾添加:auto eth1iface eth1 inet staticaddress 192.168.137.3(wjs3上是address 192.168.137.4)gateway 192.168.137.1netmask 255.255.255.0b、重启网络:sudo /etc/init.d/networking restart查看ip是否配置成功:ifconfig{注:为了便于“wjs”用户能够修改系统设置访问系统文件,最好把“wjs”用户设为sudoers(有root权限的用户),具体做法:用已有的sudoer登录系统,执行sudo visudo -f /etc/sudoers,并在此文件中添加以下一行:wjsALL=(ALL)ALL,保存并退出。
}c、修改三台机器的/etc/hosts,让彼此的主机名称和ip都能顺利解析,在/etc/hosts中添加:192.168.137.2 wjs1192.168.137.3 wjs2192.168.137.4 wjs3d、由于Hadoop需要通过ssh服务在各个节点之间登陆并运行服务,因此必须确保安装Hadoop的各个节点之间网络的畅通,网络畅通的标准是每台机器的主机名和IP地址能够被所有机器正确解析(包括它自己)。

hadoop安装实验总结Hadoop安装实验总结Hadoop是一个开源的分布式计算框架,用于处理大规模数据集。
在本次实验中,我成功安装了Hadoop,并进行了相关的配置和测试。
以下是我对整个过程的总结和经验分享。
1. 环境准备在开始安装Hadoop之前,我们需要确保已经具备了以下几个环境条件:- 一台Linux操作系统的机器,推荐使用Ubuntu或CentOS。
- Java开发环境,Hadoop是基于Java开发的,因此需要安装JDK。
- SSH服务,Hadoop通过SSH协议进行节点之间的通信,因此需要确保SSH服务已启动。
2. 下载和安装Hadoop可以从Hadoop官方网站上下载最新的稳定版本。
下载完成后,解压缩到指定目录,并设置环境变量。
同时,还需要进行一些配置,包括修改配置文件和创建必要的目录。
3. 配置Hadoop集群Hadoop是一个分布式系统,通常会配置一个包含多个节点的集群。
在配置文件中,我们需要指定集群的各个节点的IP地址和端口号,并设置一些重要的参数,如数据存储路径、副本数量等。
此外,还可以根据实际需求调整其他配置参数,以优化集群性能。
4. 启动Hadoop集群在完成集群配置后,我们需要启动Hadoop集群。
这一过程需要先启动Hadoop的各个组件,包括NameNode、DataNode、ResourceManager和NodeManager等。
启动成功后,可以通过Web 界面查看集群的状态和运行情况。
5. 测试Hadoop集群为了验证Hadoop集群的正常运行,我们可以进行一些简单的测试。
例如,可以使用Hadoop提供的命令行工具上传和下载文件,查看文件的副本情况,或者运行一些MapReduce任务进行数据处理。
这些测试可以帮助我们了解集群的性能和可靠性。
6. 故障排除与优化在实际使用Hadoop时,可能会遇到一些故障和性能问题。
为了解决这些问题,我们可以通过查看日志文件或者使用Hadoop提供的工具进行故障排查。

Hadoop详细安装过程一、本文思路1、安装虚拟化PC工具VMware,用于支撑Linux系统。
2、在VMware上安装Ubuntu系统。
3、安装Hadoop前的准备工作:安装JDK和SSH服务。
4、配置Hadoop。
5、为了方便开发过程,需安装eclipse。
6、运行一个简单的Hadoop程序:WordCount.java注:在win7系统上,利用虚拟工具VMware建立若干个Linux系统,每个系统为一个节点,构建Hadoop集群。
先在一个虚拟机上将所有需要配置的东西全部完成,然后再利用VMware 的克隆功能,直接生成其他虚拟机,这样做的目的是简单。
二、所需软件1、VMware:VMware Workstation,直接百度下载(在百度软件中心下载即可)。
2、Ubuntu系统:ubuntu-15.04-desktop-amd64.iso,百度网盘:/s/1qWxfxso注:使用15.04版本的Ubuntu(其他版本也可以),是64位系统。
3、jdk:jdk-8u60-linux-x64.tar.gz,网址:/technetwork/java/javase/downloads/jdk8-downloads-2133151.html注:下载64位的Linux版本的jdk。
4、Hadoop:hadoop-1.2.1-bin.tar.gz,网址:/apache/hadoop/common/hadoop-1.2.1/注:选择1.2.1版本的Hadoop。
5、eclipse:eclipse-java-mars-1-linux-gtk-x86_64.tar.gz,网址:/downloads/?osType=linux注:要选择Linux版本的,64位,如下:6、hadoop-eclipse-plugin-1.2.1.jar,这是eclipse的一个插件,用于Hadoop的开发,直接百度下载即可。
三、安装过程1、安装VMware。

hadoop安装以及配置启动命令本次安装使⽤的Hadoop⽂件是badou学院的Hadoop1.2.1.tar.gz,以下步骤都是在此版本上进⾏。
1、安装,通过下载tar.gz⽂件安装到指定⽬录2、安装好后需要配置Hadoop集群配置信息: 在hadoop的conf路径中的masters中添加master(集群机器主的hostname)在slaves中添加集群的slave的hostname名称名称对应的是各⾃机器的hostname这样通过hosts⽂件中配置的域名地址映射可以直接找到对应的机器 a、core-site.xml 在xml⽂件中添加<property><name>hadoop.tmp.dir</name><value>/usr/local/src/hadoop.1.2.1/tmp</value></property> <property><name></name><value>hdfs://192.168.79.10:9000</value></property> c、hdfs-site.xml 在⽂件中添加<property><name>dfs.replication</name><value>3</value></property><!-- 复制节点数 --> d、hadoop-env.xml 在⽂件中添加export JAVA_HOME=/usr/local/src/jdk1.6.0_45 步骤2配置好后将当前hadoop⽂件夹复制到集群中其他机器上,只需要在对应机器上修改其对应的ip、port、jdk路径等信息即可搭建集群3、配置好Hadoop环境后需要测试环境是否可⽤: a、⾸先进⼊Hadoop的安装⽬录,进⼊bin⽬录下,先将Hadoop环境初始化,命令:./hadoop namenode -format b、初始化之后启动Hadoop,命令:./start_all.sh c、查看Hadoop根⽬录下的⽂件,命令:./hadoop fs -ls/ d、上传⽂件,命令:./hadoop fs -put ⽂件路径 e、查看⽂件内容,命令:./hadoopo fs -cat hadoop⽂件地址注意:在安装Hadoop环境时先安装好机器集群,使得⾄少3台以上(含3台)机器之间可以免密互相登录(可以查看上⼀篇的linux的ssh免密登录)执⾏Python⽂件时的部分配置/usr/local/src/hadoop-1.2.1/bin/hadoop/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar。

Hadoop集群的搭建方法与步骤随着大数据时代的到来,Hadoop作为一种分布式计算框架,被广泛应用于数据处理和分析领域。
搭建一个高效稳定的Hadoop集群对于数据科学家和工程师来说至关重要。
本文将介绍Hadoop集群的搭建方法与步骤。
一、硬件准备在搭建Hadoop集群之前,首先要准备好适合的硬件设备。
Hadoop集群通常需要至少三台服务器,一台用于NameNode,两台用于DataNode。
每台服务器的配置应该具备足够的内存和存储空间,以及稳定的网络连接。
二、操作系统安装在选择操作系统时,通常推荐使用Linux发行版,如Ubuntu、CentOS等。
这些操作系统具有良好的稳定性和兼容性,并且有大量的Hadoop安装和配置文档可供参考。
安装操作系统后,确保所有服务器上的软件包都是最新的。
三、Java环境配置Hadoop是基于Java开发的,因此在搭建Hadoop集群之前,需要在所有服务器上配置Java环境。
下载最新版本的Java Development Kit(JDK),并按照官方文档的指引进行安装和配置。
确保JAVA_HOME环境变量已正确设置,并且可以在所有服务器上运行Java命令。
四、Hadoop安装与配置1. 下载Hadoop从Hadoop官方网站上下载最新的稳定版本,并将其解压到一个合适的目录下,例如/opt/hadoop。
2. 编辑配置文件进入Hadoop的安装目录,编辑conf目录下的hadoop-env.sh文件,设置JAVA_HOME环境变量为Java的安装路径。
然后,编辑core-site.xml文件,配置Hadoop的核心参数,如文件系统的默认URI和临时目录。
接下来,编辑hdfs-site.xml文件,配置Hadoop分布式文件系统(HDFS)的相关参数,如副本数量和数据块大小。
最后,编辑mapred-site.xml文件,配置MapReduce框架的相关参数,如任务调度器和本地任务运行模式。

linuxxshelljdkhadoop(环境搭建)虚拟机安装(⼤数据搭建环境)【hadoop是2.6.5版本xshell是6版本jdk是1.8.0.131 虚拟机是CentOS-6.9-x86_64-bin-DVD1.iso vmware10】1.创建虚拟机第⼀步:在VMware中创建⼀台新的虚拟机。
如图2.2所⽰。
图2.2第⼆步:选择“⾃定义安装”,然后单击“下⼀步”按钮,如图2.3所⽰。
图2.3第三步:单击“下⼀步” 按钮,如图2.4所⽰。
图2.4第四步:选择“稍后安装操作系统”,然后单击“下⼀步” 按钮,如图2.5所⽰。
图2.5第五步:客户机操作系统选择Linux,版本选择“CentOS 64位”,然后单击“下⼀步” 按钮,如图2.6所⽰。
图2.6第六步:在这⾥可以选择“修改虚拟机名称”和“虚拟机存储的物理地址”,如图2.7所⽰。
图2.7第七步:根据本机电脑情况给Linux虚拟机分配“处理器个数”和每个处理器的“核⼼数量”。
注意不能超过⾃⼰电脑的核数,推荐处理数量为1,每个处理器的核⼼数量为1,如图2.8所⽰。
图2.8第⼋步:给Linux虚拟机分配内存。
分配的内存⼤⼩不能超过⾃⼰本机的内存⼤⼩,多台运⾏的虚拟机的内存总合不能超过⾃⼰本机的内存⼤⼩,如图2.9所⽰。
图2.9第九步:使⽤NAT⽅式为客户机操作系统提供主机IP地址访问主机拨号或外部以太⽹⽹络连接,如图2.10所⽰。
图2.10第⼗步:选择“SCSI控制器为LSI Logic(L)”,然后单击“下⼀步” 按钮,如图2.11所⽰。
图2.11第⼗⼀步:选择“虚拟磁盘类型为SCSI(S)”,然后单击“下⼀步” 按钮,如图2.12所⽰。
图2.12第⼗⼆步:选择“创建新虚拟磁盘”,然后单击“下⼀步” 按钮,如图2.13所⽰。
图2.13第⼗三步:根据本机的磁盘⼤⼩给Linux虚拟机分配磁盘,并选择“将虚拟机磁盘拆分为多个⽂件”,然后单击“下⼀步”按钮,如图2.14所⽰。

大数据技术实验报告大数据技术实验一Hadoop大数据平台安装实验1实验目的在大数据时代,存在很多开源的分布式数据采集、计算、存储技术,本实验将在熟练掌握几种常见Linux命令的基础上搭建Hadoop(HDFS、MapReduce、HBase、Hive)、Spark、Scala、Storm、Kafka、JDK、MySQL、ZooKeeper等的大数据采集、处理分析技术环境。
2实验环境个人笔记本电脑Win10、Oracle VM VirtualBox 5.2.44、CentOS-7-x86_64-Minimal-1511.iso3实验步骤首先安装虚拟机管理程序,然后创建三台虚拟服务器,最后在虚拟服务器上搭建以Hadoop 集群为核心的大数据平台。
3.1快速热身,熟悉并操作下列Linux命令·创建一个初始文件夹,以自己的姓名(英文)命名;进入该文件夹,在这个文件夹下创建一个文件,命名为Hadoop.txt。
·查看这个文件夹下的文件列表。
·在Hadoop.txt中写入“Hello Hadoop!”,并保存·在该文件夹中创建子文件夹”Sub”,随后将Hadoop.txt文件移动到子文件夹中。
·递归的删除整个初始文件夹。
3.2安装虚拟机并做一些准备工作3.2.1安装虚拟机下载系统镜像,CentOS-7-x86_64-Minimal-1511.iso。
虚拟机软件使用Oracle VM VirtualBox 5.2.44。
3.2.2准备工作关闭防火墙和Selinux,其次要安装perl 、libaio、ntpdate 和screen。
然后检查网卡是否开机自启,之后修改hosts,检查网络是否正常如图:然后要创建hadoop用户,之后多次用,并且生成ssh 密钥并分发。
最后安装NTP 服务。
3.3安装MYSQL 3.3.1安装3.3.2测试3.4安装ZooKeeper。

hadoop2.7.1安装手册1、准备阶段述·hadoop-2.7.1.tar.gz安装包·jdk1.6以上版本,这里统一使用jdk1.8版本jdk-8u45-linux-x64.rpm·CentOS-6.4安装包2、安装步骤概述2.1、安装Centos-6.4系统2.2、安装jdk1.82.4、如若使用64位机器,请编译hadoop-2.7.1文件2.4、zookeeper安装,单机安装以及集群安装2.5、关闭linux防火墙,安装已编译好的hadooop安装包以及配置QJM,或者配置High Availability With NFS,验证hadoop是否安装成功2.6、sqoop的编译与安装2.7、Mysql安装2.8、HBASE安装2.9、HIVE安装3、集群规划集群规划:4、安装具体步骤4.1、安装Centos-6.4系统(1)、下载64位的CentOS-6.4镜像文件CentOS-6.4-x86_64-bin-DVD1.isoCentOS-6.4-x86_64-bin-DVD2.iso系统安装只用到CentOS-6.4-x86_64-bin-DVD1.iso这个镜像,第二个镜像是系统自带的软件安装包下载完成之后,使用光盘刻录软件将ISO镜像文件刻录在CD或者DVD光盘里得到一张安装光盘(2)、安装CentOS·使用安装介质启动电脑出现如下界面·选择Install or upgrade an existing system,并跳过media test ·出现引导界面,点击next·语言选择,选“English”,以防止出现乱码·键盘布局选择:U.S.English·选择“Basic Storage Devies”,点击next·询问是否忽略所有数据,新电脑安装系统选择"Yes,discard any data" ·Hostname填写·网络设置安装图示顺序点击就可以了·时区可以在地图上点击,选择“shanghai”并取消System clock uses UTC前面的对勾·设置root的密码·硬盘分区,一定要按照图示点选·调整分区,必须要有/home这个分区,如果没有这个分区,安装部分软件会出现不能安装的问题·询问是否格式化分区·将更改写入到硬盘·引导程序安装位置·选择安装模式选择Minimal Desktop安装模式,并且选择现在进行客户化定制在进行“客户化定制时”可直接next,不过在language support时,选择“Chinese Support”,如下图:·(3)、修改虚拟机主机名并建立IP地址与主机名之间的映射关系,最后重启虚拟机以root权限登录·修改主机名:vi /etc/sysconfig/network ;分别修改HOSTNAME的值,为对应的主机名hadoop01、hadoop02、hadoop03·建立IP地址与主机名之间的映射关系:vi /etc/hosts;在hadoop01虚拟机的hosts文件中添加如下字段:172.16.112.113 hadoop01在hadoop02虚拟机的hosts文件中添加如下字段:172.16.112.114 hadoop02在hadoop03虚拟机的hosts文件中添加如下字段:172.16.112.115 hadoop03在hadoop02虚拟机的hosts文件中添加如下字段:172.16.112.116 hadoop04在hadoop02虚拟机的hosts文件中添加如下字段:172.16.112.117 hadoop05在hadoop02虚拟机的hosts文件中添加如下字段:172.16.112.118 hadoop06在hadoop02虚拟机的hosts文件中添加如下字段:172.16.112.119 hadoop074.2、安装jdk1.8(1)、在hadoop家目录下创建software文件夹,并使用Secure CRT工具,点击Secure FX将所需要的jdk安装包上传到linux系统上的software文件中·切换回当前用户:su – hadoop01·创建目录:mkdir /home/hadoop01/software·上传文件:(以二进制文件形式传输)(2)、安装jdk1.8·进入jdk1.8存放目录:cd /home/hadoop01/software/·切换为root用户:su,输入密码·安装jdk1.8: rpm -ivh jdk-8u45-linux-x64.rpm(3)、配置jdk环境变量·设置环境变量:vi /etc/profile·在profile文件中设置JAVA_HOME、CLASS_PATH、PATH三个环境变量:# JAVA_HOMEexport JAVA_HOME=/usr/java/jdk1.8.0_45# CLASSPATHexportCLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar#PATHexport PATH=$PATH:$JAVA_HOME/bin·启动配置项:source /etc/profile·验证jdk是否安装成功:java –version如图:安装成功4.3编译hadoop2.7.1(1)、实现ssh登录,公钥自联·登录root用户:su ,输入密码·打开公钥验证服务:#RSAAuthentication yes#PubkeyAuthentication yes#AuthorizedKeysFile .ssh/authorized_keys去掉这也项的#·重启ssh服务:service sshd restart·以hadoop01账户登录linux系统:su – hadoop01·启动ssh协议:rpm -qa|grep opensshrpm -qa|grep rsync·生成密钥对:ssh-keygen -t rsa -P '' 直接回车·将公钥写入授权文件:cat ~/.ssh/id_dsa.pub >> authorized-keys·修改授权文件权限:授权文件:chmod 600 ~/.ssh/authorized-keys·验证ssh登录:ssh localhost多次ssh登录到localhost用户观察是否还需要输入密码如图时,成功(2)、将hadoop01作为Master节点,配置ssh免密码登陆,使得hadoop01无密码登录所有的slave节点:·将其他两台hadoop02,hadoop03,hadoop04,hadoop05,hadoop06,hadoop07实现一次自联过程·分别修改hadoop02,hadoop03,hadoop04,hadoop05,hadoop06,hadoop07节点上.ssh文件的权限和authorized-keys文件的权限:chmod 700 ~/.sshchmod 600 authorized-keys·将hadoop01节点的公钥传给hadoop02,hadoop03,hadoop04,hadoop05,hadoop06,hadoop07:scp ~/.ssh/id_rsa.pub hadoop@hadoop02:~/scp ~/.ssh/id_rsa.pub hadoop@hadoop03:~/scp ~/.ssh/id_rsa.pub hadoop@hadoop04:~/scp ~/.ssh/id_rsa.pub hadoop@hadoop05:~/scp ~/.ssh/id_rsa.pub hadoop@hadoop06:~/scp ~/.ssh/id_rsa.pub hadoop@hadoop07:~/·将hadoop01的公钥追加到hadoop02,hadoop03,hadoop04,hadoop05,hadoop06,hadoop07的authorized-keys中:cat ~/id_rsa.pub >> ~/.ssh/authorized-keys·验证是否实现ssh登录ssh hadoop02ssh hadoop03ssh hadoop04ssh hadoop05ssh hadoop06ssh hadoop07(3)、编译hadoop-2.7.1环境·所需软件:maven、protobuf、openssl库、CMake、ant·安装maven:1、解压缩压缩包:tar -zxvf apache-maven-3.3.3-bin.tar.gz2、设置Maven环境变量:#MAVENexport MAVEN_HOME=/home/hadoop/software/apache-maven-3.3.3#environment pathexport PATH= /home/hadoop/software/apache-maven-3.3.3/bin3、生效source /etc/profile4、验证mavenmvn –v·安装protobuf-2.5.01、安装依赖包以root身份登录yum install gcc-c++2、解压protobuf-2.5.0安装包tar -zxvf protobuf-2.5.0.tar.gz3、进入protobuf-2.5.0文件夹,进行如下操作:./configuremakemake checkmake installldconfig4、修改环境变量:vi /etc/profile#protobufexport LD_LIBRARY_PATH=/home/hadoop/software/protobuf-2.5.05、生效source /etc/profile注意:配置/etc/profile,在虚拟机重启后,可能配置会失效,所以重启后,需要再次执行source操作。
Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0都能顺利在CentOS 中安装并运行Hadoop。
环境本教程使用CentOS 6.4 32位作为系统环境,请自行安装系统(可参考使用VirtualBox安装CentOS)。
如果用的是Ubuntu 系统,请查看相应的Ubuntu安装Hadoop教程。
本教程基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1, Hadoop 2.4.1等。
Hadoop版本Hadoop 有两个主要版本,Hadoop 1.x.y 和Hadoop 2.x.y 系列,比较老的教材上用的可能是0.20 这样的版本。
Hadoop 2.x 版本在不断更新,本教程均可适用。
如果需安装0.20,1.2.1这样的版本,本教程也可以作为参考,主要差别在于配置项,配置请参考官网教程或其他教程。
新版是兼容旧版的,书上旧版本的代码应该能够正常运行(我自己没验证,欢迎验证反馈)。
装好了CentOS 系统之后,在安装Hadoop 前还需要做一些必备工作。
创建hadoop用户如果你安装CentOS 的时候不是用的“hadoop” 用户,那么需要增加一个名为hadoop 的用户。
首先点击左上角的“应用程序” -> “系统工具” -> “终端”,首先在终端中输入su,按回车,输入root 密码以root 用户登录,接着执行命令创建新用户hadoop:如下图所示,这条命令创建了可以登陆的hadoop 用户,并使用/bin/bash 作为shell。
CentOS创建hadoop用户接着使用如下命令修改密码,按提示输入两次密码,可简单的设为“hadoop”(密码随意指定,若提示“无效的密码,过于简单”则再次输入确认就行):可为hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题,执行:如下图,找到root ALL=(ALL) ALL这行(应该在第98行,可以先按一下键盘上的ESC键,然后输入:98 (按一下冒号,接着输入98,再按回车键),可以直接跳到第98行),然后在这行下面增加一行内容:hadoop ALL=(ALL) ALL(当中的间隔为tab),如下图所示:为hadoop增加sudo权限添加上一行内容后,先按一下键盘上的ESC键,然后输入:wq (输入冒号还有wq,这是vi/vim编辑器的保存方法),再按回车键保存退出就可以了。
➢3.10.2.进程➢JpsMaster节点:namenode/tasktracker(如果Master不兼做Slave, 不会出现datanode/TasktrackerSlave节点:datanode/Tasktracker说明:JobTracker 对应于NameNodeTaskTracker 对应于DataNodeDataNode 和NameNode 是针对数据存放来而言的JobTracker和TaskTracker是对于MapReduce执行而言的mapreduce中几个主要概念,mapreduce整体上可以分为这么几条执行线索:jobclient,JobTracker与TaskTracker。
1、JobClient会在用户端通过JobClient类将应用已经配置参数打包成jar文件存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker创建每个Task(即MapTask和ReduceTask)并将它们分发到各个TaskTracker服务中去执行2、JobTracker是一个master服务,软件启动之后JobTracker接收Job,负责调度Job的每一个子任务task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。
一般情况应该把JobTracker部署在单独的机器上。
3、TaskTracker是运行在多个节点上的slaver服务。
TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。
TaskTracker都需要运行在HDFS的DataNode上3.10.3.文件系统HDFS⏹查看文件系统根目录:Hadoop fs–ls /。
CentOS 6.0 安装过程图解(一)开始安装与系统设置原始出处:天天Linux网CentOS6.0发布已经有几天,狼第一时间下载并安装构建测试环境,安装过程全程截图,供初学的童鞋们参考。
CentOS6的安装过程其实和RHEL6基本相同,但和RHEL5(CentOS5)还是有一定的区别,我会在下面注释说明。
CentOS6的介绍与下载,请看CentOS 6.0 正式发布与Scientific Linux。
图片较多,请耐心等待,点击查看大图。
OK,Let’s go !从光盘引导安装图一:光盘引导界面,选择“安装或升级已存在的系统”。
图二:检测光盘媒体介质,没什么问题就跳过吧。
图三:准备开始了。
各种设置图四:安装过程语言,一般英文OK了。
图五:设置键盘,这个一般就美式键盘。
图六:安装到何种类型的设备,可选基本基本存储设备或专门的存储(SANs)。
图七:设置主机名。
图八:在此处可以设置网络连接。
图九:设置IPV4地址。
图十:设置时区,中国的娃就选亚洲上海。
图十一:设置管理员用户root 密码。
(二)系统分区开始分区图一:使用什么样的分区方式。
分区方式有以下几种选择:1.使用所有的磁盘空间创建默认分区;2.删除Linux 分区创建默认分区;3.缩小存在的系统利用剩余空间创建默认分区;4.使用空闲的空间创建默认分区;5.手动自定义分区。
图三:建立/boot分区,大小200M够了,CentOS6默认已经使用ext4的文件系统了。
图四:交换分区,内存较小时(<2G)设置为内存的两倍。
生产环境几十上百G物理内存,交换分区的设定参照《服务器究竟设置多大的交换分区合适》图五:根分区,实验环境,把剩余所有的可用空间都给它就行了。
图六:分区完成。
图七:格式化。
图八:将所有磁盘改变写入磁盘。
图九:系统引导器的安装位置,默认选择/dev/sda。
class="entry-title"(三)选择要安装的软件包选择要安装的软件包图一:选择要搭建的服务器的主要用途,可选中“Customize now”立即进行软件包的调整。
Hadoop2.7.3+Hbase-1.2.6完全分布式安装部署Hadoop安装部署基本步骤:1、安装jdk,配置环境变量。
jdk可以去⽹上⾃⾏下载,环境变量如下:编辑 vim /etc/profile ⽂件,添加如下内容:export JAVA_HOME=/opt/java_environment/jdk1.7.0_80(填写⾃⼰的jdk安装路径)export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport PATH=$PATH:$JAVA_HOME/bin输⼊命令,source /etc/profile 使配置⽣效分别输⼊命令,java 、 javac 、 java -version,查看jdk环境变量是否配置成功2、linux环境下,⾄少需要3台机⼦,⼀台作为master,2台(以上)作为slave。
这⾥我以3台机器为例,linux⽤的是CentOS 6.5 x64为机器。
master 192.168.172.71slave1 192.168.172.72slave2 192.168.172.733、配置所有机器的hostname和hosts。
(1)更改hostname,可以编辑 vim /etc/sysconfig/network 更改master的HOSTNAME,这⾥改为HOSTNAME=master 其它slave为HOSTNAME=slave1、HOSTNAME=slave2 ,重启后⽣效。
或者直接输: hostname 名字,更改成功,这种⽅式⽆需重启即可⽣效, 但是重启系统后更改的名字会失效,仍是原来的名字 (2)更改host,可以编辑 vim /etc/hosts,增加如下内容: 192.168.172.71 master 192.168.172.72 slave1 192.168.172.73 slave2 hosts可以和hostname不⼀致,这⾥为了好记就写⼀致了。
centos环境下hadoop的安装与配置实验总结实验总结:CentOS环境下Hadoop的安装与配置一、实验目标本次实验的主要目标是学习在CentOS环境下安装和配置Hadoop,了解其基本原理和工作机制,并能够运行简单的MapReduce程序。
二、实验步骤1. 准备CentOS环境:首先,我们需要在CentOS上安装和配置好必要的基础环境,包括Java、SSH等。
2. 下载Hadoop:从Hadoop官方网站下载Hadoop的稳定版本,或者使用CentOS的软件仓库进行安装。
3. 配置Hadoop:解压Hadoop安装包后,需要进行一系列的配置。
这包括设置环境变量、配置文件修改等步骤。
4. 格式化HDFS:使用Hadoop的命令行工具,对HDFS进行格式化,创建其存储空间。
5. 启动Hadoop:启动Hadoop集群,包括NameNode、DataNode等。
6. 测试Hadoop:运行一些简单的MapReduce程序,检查Hadoop是否正常工作。
三、遇到的问题和解决方案1. 环境变量配置问题:在配置Hadoop的环境变量时,有时会出现一些问题。
我们需要检查JAVA_HOME是否设置正确,并确保HADOOP_HOME 在PATH中。
2. SSH连接问题:在启动Hadoop集群时,需要确保各个节点之间可以通过SSH进行通信。
如果出现问题,需要检查防火墙设置和SSH配置。
3. MapReduce程序运行问题:在运行MapReduce程序时,可能会遇到一些错误。
这通常是由于程序本身的问题,或者是由于HDFS的权限问题。
我们需要仔细检查程序代码,并确保运行程序的用户有足够的权限访问HDFS。
四、实验总结通过本次实验,我们深入了解了Hadoop的安装和配置过程,以及如何解决在安装和运行过程中遇到的问题。
这对于我们今后在实际应用中部署和使用Hadoop非常重要。
同时,也提高了我们的实践能力和解决问题的能力。
CentOS6.6安装Hadoop2.7.3教程大胡子工作室目录1前言 (1)2安装准备 (1)2.1所需软件 (1)2.1.1CentOS6.6minimal (1)2.1.2Hadoop 2.7.3 (1)2.2安装规划 (1)3安装步骤 (2)3.1安装操作系统 (2)3.2操作系统基本配置 (13)3.2.1配置IP地址 (13)3.2.2配置hostname及网关 (14)3.2.3关闭selinux (15)3.2.4设置limit最大连接数 (15)3.2.5配置DNS (16)3.2.6配置本地hosts (17)3.2.7添加hadoop用户 (17)3.2.8关闭防火墙 (18)3.3安装jdk (19)3.4配置ssh免密码登录 (19)3.4.1切换hadoop用户 (20)3.4.2生成免登陆ssh证书 (20)3.4.3追加授权 (20)3.5配置master计算机的hadoop (22)3.5.1解压缩hadoop文件 (23)3.5.2创建存储hadoop数据文件的目录 (23)3.5.3设置hadoop的环境变量 (23)3.5.4配置core-site.xml文件 (26)3.5.5配置hdfs-site.xml文件 (28)3.5.6配置mapred-site.xml文件 (30)3.5.7配置yarn-site.xml文件 (32)3.5.8配置slaves文件 (34)3.5.9格式化HDFS文件系统 (34)3.6配置slave计算机的hadoop (34)3.6.1创建hadoop文件夹 (35)3.6.2将文件分发给slave计算机 (35)3.6.3设置hadoop的环境变量 (35)4hadoop的控制 (36)4.1hadoop的启动 (36)4.2hadoop的关闭 (36)4.3hadoop的状态查看 (37)4.3.1使用命令查看 (37)4.3.2使用web端查看 (39)1前言本篇介绍如何在CentOS-6.6.x86_64下安装hadoop 2.7.3集群服务,主要提供给有一定电脑使用基础的并初学hadoop的程序猿同志们,尽量做到详细介绍安装步骤。
2安装准备2.1所需软件下载所需的软件,如下给出下载地址及提取码:2.1.1CentOS6.6minimal下载地址:/s/1i4XjyOP 提取密码: i3ac2.1.2Hadoop 2.7.3下载地址:/s/1i4U145R 提取密码: 5xkf2.2安装规划本教程计划安装1个master , 3个slave 详细信息如下表2-1:表2-1 部署计划表Hostname Ip OS节点用途master.hadoop192.168.2.32CentOS 6.6.x86_64Namenode slave1.hadoop192.168.2.28CentOS 6.6.x86_64Datanode slave2.hadoop192.168.2.30CentOS 6.6.x86_64Datanode slave3.hadoop192.168.2.16CentOS 6.6.x86_64Datanode3安装步骤安装规划完成后,本集群需要大概4台计算机,如不具备实际的硬件条件,可以采用安装虚拟机的方式,虚拟出4台计算机(虚拟软件可以选择virtual box或者VMware,具体虚拟化软件的安装过程不进行描述,请自行问熊)。
3.1安装操作系统操作系统尽量选择占用磁盘空间及内存空间小的系统,本文以CentOS6.6minimal.x86_64为例。
安装步骤如下:设置光驱启动,进入操作系统安装界面,选择Install or upgrade an existing system选项,按回车进入。
如下图3-1图3-1 操作系统安装选项检测硬盘界面点击skip按钮。
如下图3-2图3-2 跳过存储介质检测在欢迎页面直接点击next按钮继续。
如下图3-3图3-3 安装欢迎界面安装语言界面,选择简体中文并点击next。
如下图3-4图3-4 安装语言选择键盘选择使用默认的美国英语式,点击next。
如下图3-5图3-5 键盘选择存储设备选择默认的【基本存储设备】,点击next。
如下图3-6图3-6 存储设备选择安装方式选择【全新安装】,点击next。
如下图3-7图3-7 安装方式选择主机名称设置,按照规划在安装时给各个计算机配置不同的hostname(依次为:master.hadoop,slave1.hadoop,slave2.hadoop,slave3.hadoop),设置完成后点击next(本次截图是安装第一台master计算机时截图)。
如下图3-8图3-8 设置hostname设置时区为亚洲/上海,并勾选系统时钟使用UTC时间(s),点击next。
如下图3-9图3-9 时区选择设置根账户即root用户密码,注意两次输入密码要一致,设置完成后点击next。
如下图3-10图3-10 设置root用户密码在安装类型界面选择【创建自定义布局】,点击next。
如下图3-11图3-11 安装类型界面接下来设置CentOS的磁盘分区,一般CentOS必须要设置的分区,及建议打下如下表3-1表3-1 CentOS系统分区表分区/挂载点大小类型备注swap16000M交换分区,该分区建议为计算机物理内存的1~2倍,我安装的计算机为8G内存,因此设置为16G/boot400M ext4引导分区/5G ext4建议不小于5G/home剩余空间ext4放置用户文件的分区首先添加交换分区(swap),在磁盘驱动器界面选择空闲的磁盘空间,并点击【创建】按钮。
如下图3-12图3-12磁盘驱动器选择在弹出的【生成存储】对话框中选择【生成分区-标准分区】,点击【创建】按钮,如下图3-13图3-13 创建标准分区在弹出的【添加分区】对话框中【文件系统类型】位置选择【swap】,大小设置为【16000】,(一般交换分区(swap)是物理内存的1~2倍,我的计算机内存是8G,因此交换分区设置为16G),点击【确定】。
如下图3-14图3-14 添加交换分区添加/boot分区,在磁盘驱动器位置选择空闲磁盘,并点击创建按钮。
如下图3-15图3-15 选择空闲的磁盘空间在弹出的【生成存储】对话框中选择【生成分区-标准分区】,点击【创建】按钮,如下图3-16图3-16 创建标准分区在弹出的【添加分区】对话框中,挂载点选项选择【/boot】,文件系统类型使用默认的【ext4】,大小设置为【400】M,勾选【强制为主分区】选项,设置完成后点击【确定】按钮。
如下图3-17图3-17 设置/boot分区按照创建/boot分区的步骤完成/和/home两个分区的创建,并点击下一步继续,创建完成后的磁盘分区如下图3-18图3-18 磁盘分区情况图在弹出的【将存储配置写入磁盘】对话框中点击【将修改写入磁盘】按钮,如下图3-19图3-19 确认将配置写入磁盘在引导装载程序界面直接点击下一步开始安装系统,如下图3-20图3-20 引导程序选择当进度条走完时,点击【重新引导系统】按钮,完成操作系统的安装。
如下图3-21图3-21 操作系统安装进度界面按照上述步骤完成剩下3台slave计算机操作系统的安装,此处不再重复介绍,其中需要注意在设置hostname时按照规划中的将其他三台计算机的hostname分别设置为slave1.hadoop,slave2.hadoop,slave3.hadoop。
3.2操作系统基本配置在配置操作系统时,可以使用xshell软件进行远程操作,由于该软件为收费版本请自行购买下载安装,安装完成后远程连接master计算机。
基本配置需要在4个计算机上分别进行设置,除IP地址,hostname分别设置外,其他需要统一按照本节中的设置。
3.2.1配置IP地址系统刚安装完成时如果没有在安装界面配置IP,则需要先配置IP地址才可以xshell远程连接,使用root用户登录系统,使用如下命令打开网卡配置文件。
vi /etc/sysconfig/network-scripts/ifcfg-eth0执行命令后显示系统的网卡0的配置信息,如下图3-22图3-22 网卡0配置文件在vi编辑器中按【A】,将配置文件中的【ONBOOT】设置为【yes】,【BOOTPROTO】设置为【static】,并添加IP地址,子网掩码,网关等三行信息如下信息:IPADDR=192.168.2.32NETMASK=255.255.255.0IPADDR=192.168.2.20最终配置文件如下图3-23图3-23 网卡0设置信息修改完成后按两下【esc】,输入【:wq】保存退出。
最后执行网卡启动命令。
ifup eth0网卡0其中后,即可以使用xshell远程登录计算机。
本设置中的IP地址是按照安装规划中的master计算机进行配置,其余3个slave计算机的IP地址同上(IP地址可以按照读者自己的局域网情况进行设置,保证4台计算机可以互相访问ping通即可)。
3.2.2配置hostname及网关如果在按照操作系统过程中已经进行hostname的设置,可以略过本节中的hostname 设置。
使用命令打开network文件进行修改。
命令如下:vi /etc/sysconfig/network执行命令后显示network的信息如下图3-24图3-24 network信息修改【HOSTNAME】为需要设置的hostname。
再最后添加一行GATEWAY=192.168.2.20设置网关。
修改完成后保存退出。
如果想让设置临时生效的话可以使用hostname命令进行临时设置,但是使用命令设置在计算机重启之后就无效了,想要一直有效需使用上面修改network信息的方式进行修改。
临时修改hostname的命令为:hostname master.hadoop4台计算机进行设置时需要注意hostname的名称。
3.2.3关闭selinux使用vi命令编辑selinux信息关闭selinux。
命令如下:vi /etc/sysconfig/selinux打开selinux信息,修改SELINUX=enforcing为SELINUX=disabled如下图3-25图3-25 关闭selinux修改完成后保存退出。
如需此步骤生效可以使用命令:setenforce 0getenforce或者使用reboot重启计算机。
3.2.4设置limit最大连接数使用vi命令编辑limit信息。
命令如下:vi /etc/security/limits.conf在打开的界面中添加如下两行:* soft nofile 65536* hard nofile 65536如下图3-26图3-26 limit最大连接数设置添加完成后保存退出。