SQL语句经典实现
- 格式:doc
- 大小:76.50 KB
- 文档页数:5
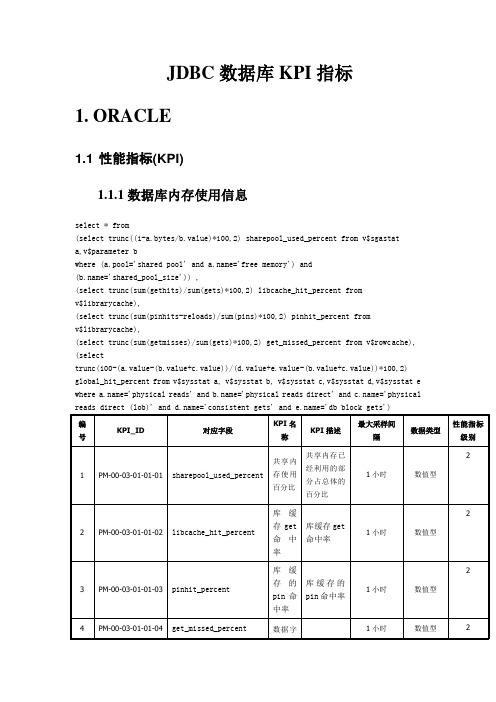
JDBC数据库KPI指标1.ORACLE1.1 性能指标(KPI)1.1.1数据库内存使用信息select * from(select trunc((1-a.bytes/b.value)*100,2) sharepool_used_percent from v$sgastata,v$parameter bwhere (a.pool='shared pool' and ='free memory') and(='shared_pool_size')) ,(select trunc(sum(gethits)/sum(gets)*100,2) libcache_hit_percent fromv$librarycache),(select trunc(sum(pinhits-reloads)/sum(pins)*100,2) pinhit_percent fromv$librarycache),(select trunc(sum(getmisses)/sum(gets)*100,2) get_missed_percent from v$rowcache), (selecttrunc(100-(a.value-(b.value+c.value))/(d.value+e.value-(b.value+c.value))*100,2) global_hit_percent from v$sysstat a, v$sysstat b, v$sysstat c,v$sysstat d,v$sysstat e where ='physical reads' and ='physical reads direct' and ='physical reads direct (lob)' and ='consistent gets' and ='db block gets')1.1.2数据库内表空间的读写次数select as tablespace_name,sum(fs.phyrds) as phyrds,sum(fs.phywrts) as phywrts from v$filestat fs,v$datafile df,v$tablespace tswhere fs.file#=df.file#and df.ts#=ts.ts#group by 1.1.3数据库表空间的利用情况select c.tablespace_name,trunc(a.bytes/1048576,2) Megs_Alloc,trunc(b.bytes/1048576,2) Megs_Free,trunc((a.bytes-b.bytes)/1048576,2) Megs_Used,trunc(b.bytes/a.bytes * 100,2) Pct_Free,trunc((a.bytes-b.bytes)/a.bytes * 100,2) Pct_Used,trunc(c.initial_extent/1048576,2) Init_Ext,trunc(c.next_extent/1048576,2) Next_Ext,trunc(a.minbytes/1048576,2) Min_Ext,trunc(a.maxbytes/1048576,2) Max_Ext,nvl(d.num_segs,0) Num_segs,nvl(d.num_exts,0) Num_Extsfrom (select tablespace_name,sum(a.bytes) bytes,min(a.bytes) minbytes,max(a.bytes) maxbytesfrom sys.dba_data_files agroup by tablespace_name) a,(select a.tablespace_name,nvl(sum(b.bytes),0) bytesfrom sys.dba_data_files a,sys.dba_free_space bwhere a.tablespace_name = b.tablespace_name (+)and a.file_id = b.file_id (+)group by a.tablespace_name) b,sys.dba_tablespaces c,(select tablespace_name,count(distinct segment_name) num_segs,count(extent_id) num_extsfrom sys.dba_extentsgroup by tablespace_name) dwhere a.tablespace_name = b.tablespace_name(+)and a.tablespace_name = c.tablespace_nameand a.tablespace_name = d.tablespace_name(+)order by c.tablespace_name1.1.4数据文件或数据设备的读写次数select as datafile_name,ds.BYTES/1024/1024 FILE_SIZE ,db.CHECKPOINT_CHANGE# SCN ,f.phyrds,f.phywrts ,trunc((f.READTIM+f.WRITETIM)/(f.PHYRDS+f.PHYWRTS),2) AVGIO ,f.LSTIOTIM LASTIOfrom v$datafile ds,v$filestat f ,V$database dbwhere f.file#=ds.file#1.1.5数据库碎片的情况select tablespace_name,trunc(100-sqrt(max(blocks)/sum(blocks))*(100/sqrt(sqrt(count(blocks)))),2) FSFIfrom dba_free_spacegroup by tablespace_name order by 11.1.6数据库日志空间或回滚段使用情况select as roll_name,s.extents,s.rssize,s.hwmsize,s.xacts,s.status,s.waits from v$rollname n,v$rollstat s where n=n1.1.7数据库锁使用情况select * from(select count(*) as total_locks from v$lock),(select count(*) as user_locks from v$lock where type in ('TM','TX','UL')),(select trunc(dnum/lnum*100,2) as deadlock_percent from (select count(*) as dnum from v$lock l,v$session s,v$lock x wherex.sid in (select sid from v$session) and l.type in ('TM', 'TX', 'UL') and l.ctime > 120 and s.lockwait=l.kaddrand l.id1 = x.id1 and l.id2 = x.id2 and x.sid != l.sid and x.lmode >0),(select count(*) as lnum from v$lock) ),(select nvl(avg(sysdate-logon_time)*86400,0) as avg_lock_wait_time from v$session where lockwait is not null),(select dmllocks-locks as avail_locks from (select value as dmllocks from v$parameter where name='dml_locks'),(select count(*) as locks from v$lock where type in ('TM','TX','UL')))1.1.8会话信息select * from(select count(*) as total_sessions from v$session),(select count(*) as wait_sessions from v$session where lockwait is not null), (select count(*) as active_sessions from v$session where status='ACTIVE')1.1.9事物提交情况select user_commits,user_rollbacks,user_commits+user_rollbacks as total_trans, trunc(user_commits/(user_commits+user_rollbacks)*100,2) as user_commit_percent, trunc(user_rollbacks/(user_commits+user_rollbacks)*100,2) as user_rollback_percent from (select value as user_commits from v$sysstat where name='user commits'), (select value as user_rollbacks from v$sysstat where name='user rollbacks')1.1.10配置占用情况select trannums,max_trans,trannums/max_trans*100 astran_used_percent,procnums,max_procs, trunc(procnums/max_procs*100,2) as proc_used_percentfrom (select count(*) as trannums from v$transaction),(select value as max_trans from v$parameter where name='transactions'), (select count(*) as procnums from v$process),(select value as max_procs from v$parameter where name='processes')1.2 配置数据1.2.1表空间配置信息1.2.2数据文件配置信息1.2.3回滚段配置信息2.SQLSERVER2.1 性能指标(KPI)2.1.1数据库全局性能select@@connections as connections,@@cpu_busy as cpu_busy,@@io_busy as io_busy,@@idle as idle,@@pack_sent as pack_sent,@@pack_received as pack_received,@@packet_errors as packet_errors,@@total_errors as total_disk_errors, @@total_read as total_read,@@total_write as total_write2.1.2数据库采集间隔性能sp_monitor2.1.3数据库实例性能select rtrim(instance_name) as database_name,sum(case counter_name when 'Data File(s) Size (KB)'then cntr_value else 0 end) as data_file_size,sum(case counter_name when 'Log File(s) Size (KB)'then cntr_value else 0 end) as log_file_size,sum(case counter_name when 'Log File(s) Used Size (KB)'then cntr_value else 0 end) as log_file_used,sum(case counter_name when 'Percent Log Used'then cntr_value else 0 end) aslog_used_percent,sum(case counter_name when 'Active Transactions'then cntr_value else 0 end) as active_trans,sum(case counter_name when 'Transactions/sec'then cntr_value else 0 end) as trans_rate, sum(case counter_name when 'Repl. Pending Xacts'then cntr_value else 0 end) asrepl_pending_xacts,sum(case counter_name when 'Repl. Trans. Rate'then cntr_value else 0 end) asrepl_trans_rate,sum(case counter_name when 'Log Cache Reads/sec'then cntr_value else 0 end) aslog_cache_read_rate,cast(round(100.0*sum(case counter_name when 'Log Cache Hit Ratio'then cntr_value else 0 end) /sum(case counter_name when 'Log Cache Hit Ratio Base'then cntr_value+0.01 else 0.01 end),2) as numeric(20,2)) as log_cache_hit_percent,sum(case counter_name when 'Bulk Copy Rows/sec'then cntr_value else 0 end) asbulk_copy_rate,sum(case counter_name when 'Bulk Copy Throughput/sec'then cntr_value else 0 end) as bulk_copy_throughput,sum(case counter_name when 'Backup/Restore Throughput/sec'then cntr_value else 0 end) as backup_restore_throughput,sum(case counter_name when 'DBCC Logical Scan Bytes/sec'then cntr_value else 0 end) as dbcc_scan_rate,sum(case counter_name when 'Shrink Data Movement Bytes/sec'then cntr_value else 0 end) as shrink_data_move_rate,sum(case counter_name when 'Log Flushes/sec'then cntr_value else 0 end) aslog_flush_rate,sum(case counter_name when 'Log Bytes Flushed/sec'then cntr_value else 0 end) as log_bytes_flush_rate,sum(case counter_name when 'Log Flush Waits/sec'then cntr_value else 0 end) aslog_wait_rate,sum(case counter_name when 'Log Flush Wait Time'then cntr_value else 0 end) aslog_flush_wait_time,sum(case counter_name when 'Log Truncations'then cntr_value else 0 end) aslog_truncations,sum(case counter_name when 'Log Growths'then cntr_value else 0 end) as log_growths, sum(case counter_name when 'Log Shrinks'then cntr_value else 0 end) as log_shrinks from sysperfinfo where object_name ='SQLServer:Databases'group by instance_name2.1.4数据库常规活动性能selectsum(case counter_name when 'Logins/sec'then cntr_value else 0 end) as logins_rate, sum(case counter_name when 'Logouts/sec'then cntr_value else 0 end) as logouts_rate, sum(case counter_name when 'User Connections'then cntr_value else 0 end) asuser_connectionsfrom sysperfinfo where object_name ='SQLServer:General Statistics'2.1.5数据库SQL请求和编译性能selectsum(case counter_name when 'Batch Requests/sec'then cntr_value else 0 end) as batch_request_rate,sum(case counter_name when 'Auto-Param Attempts/sec'then cntr_value else 0 end) as auto_param_attempt_rate,sum(case counter_name when 'Failed Auto-Params/sec'then cntr_value else 0 end) as failed_auto_param_rate,sum(case counter_name when 'Safe Auto-Params/sec'then cntr_value else 0 end) as safe_auto_param_rate,sum(case counter_name when 'Unsafe Auto-Params/sec'then cntr_value else 0 end) as unsafe_auto_param_rate,sum(case counter_name when 'SQL Compilations/sec'then cntr_value else 0 end) as sql_compliation_rate,sum(case counter_name when 'SQL Re-Compilations/sec'then cntr_value else 0 end) as sql_recompliation_ratefrom sysperfinfo where object_name ='SQLServer:SQL Statistics'2.1.6数据库缓冲区管理性能selectcast(round(100.0*sum(case counter_name when 'Buffer cache hit ratio'then cntr_value else 0 end) /sum(case counter_name when 'Buffer cache hit ratio base'then cntr_value+0.01 else 0.01 end),2) as numeric(20,2)) as buffer_cache_hit_percent,sum(case counter_name when 'Page lookups/sec'then cntr_value else 0 end) aspage_lookup_rate,sum(case counter_name when 'Free list stalls/sec'then cntr_value else 0 end) asfree_list_stall_rate,sum(case counter_name when 'Free pages'then cntr_value else 0 end) as free_pages, sum(case counter_name when 'Total pages'then cntr_value else 0 end) as total_pages, sum(case counter_name when 'Target pages'then cntr_value else 0 end) as target_pages, sum(case counter_name when 'Database pages'then cntr_value else 0 end) asdatabase_pages,sum(case counter_name when 'Reserved pages'then cntr_value else 0 end) asreserved_pages,sum(case counter_name when 'Stolen pages'then cntr_value else 0 end) as stolen_pages, sum(case counter_name when 'Lazy writes/sec'then cntr_value else 0 end) aslazy_write_rate,sum(case counter_name when 'Readahead pages/sec'then cntr_value else 0 end) as readahead_page_rate,sum(case counter_name when 'Procedure cache pages'then cntr_value else 0 end) as procedure_cache_pages,sum(case counter_name when 'Page reads/sec'then cntr_value else 0 end) aspage_read_rate,sum(case counter_name when 'Page writes/sec'then cntr_value else 0 end) aspage_write_rate,sum(case counter_name when 'Checkpoint pages/sec'then cntr_value else 0 end) as checkpoint_page_rate,sum(case counter_name when 'AWE lookup maps/sec'then cntr_value else 0 end) as awe_lookup_map_rate,sum(case counter_name when 'AWE stolen maps/sec'then cntr_value else 0 end) as awe_stolen_map_rate,sum(case counter_name when 'AWE write maps/sec'then cntr_value else 0 end) as awe_write_map_rate,sum(case counter_name when 'AWE unmap calls/sec'then cntr_value else 0 end) as awe_unmap_call_rate,sum(case counter_name when 'AWE unmap pages/sec'then cntr_value else 0 end) as awe_unmap_page_rate,sum(case counter_name when 'Page life expectancy'then cntr_value else 0 end) as page_life_expectancyfrom sysperfinfo where object_name ='SQLServer:Buffer Manager'2.1.7数据库内存使用信息selectsum(case counter_name when 'Connection Memory (KB)'then cntr_value else 0 end) as connection_memory,sum(case counter_name when 'Granted Workspace Memory (KB)'then cntr_value else 0 end) as granted_workspace_memory,sum(case counter_name when 'Lock Memory (KB)'then cntr_value else 0 end) as lock_memory, sum(case counter_name when 'Lock Blocks Allocated'then cntr_value else 0 end) as lock_blocks_allocated,sum(case counter_name when 'Lock Owner Blocks Allocated'then cntr_value else 0 end) as lock_owner_blocks_allocated,sum(case counter_name when 'Lock Blocks'then cntr_value else 0 end) as lock_blocks, sum(case counter_name when 'Lock Owner Blocks'then cntr_value else 0 end) aslock_owner_blocks,sum(case counter_name when 'Maximum Workspace Memory (KB)'then cntr_value else 0 end) as maximum_workspace_memory,sum(case counter_name when 'Memory Grants Outstanding'then cntr_value else 0 end) as memory_grants_outstanding,sum(case counter_name when 'Memory Grants Pending'then cntr_value else 0 end) as memory_grants_pending,sum(case counter_name when 'Optimizer Memory (KB)'then cntr_value else 0 end) as optimizer_memory,sum(case counter_name when 'SQL Cache Memory (KB)'then cntr_value else 0 end) assql_cache_memory,sum(case counter_name when 'Total Server Memory (KB)'then cntr_value else 0 end) as total_server_memory,sum(case counter_name when 'Target Server Memory(KB)'then cntr_value else 0 end) as target_server_memory,100.0* sum(case counter_name when 'Total Server Memory (KB)'then cntr_value else 0 end) /sum(case counter_name when 'Target Server Memory(KB)'then cntr_value else 0 end) as memory_used_percentfrom sysperfinfo where object_name ='SQLServer:Memory Manager'2.1.8可用页使用统计selectsum(case counter_name when 'Free pages'then cntr_value else 0 end) as free_pages, sum(case counter_name when 'Free list requests/sec'then cntr_value else 0 end) as free_list_request_rate,sum(case counter_name when 'Free list empty/sec'then cntr_value else 0 end) asfree_list_empty_ratefrom sysperfinfo where object_name ='SQLServer:Buffer Partition'2.1.9数据库逻辑页访问统计selectsum(case counter_name when 'Extent Deallocations/sec'then cntr_value else 0 end) as extent_deallocate_rate,sum(case counter_name when 'Extents Allocated/sec'then cntr_value else 0 end) as extent_allocate_rate,sum(case counter_name when 'Forwarded Records/sec'then cntr_value else 0 end) as forward_record_rate,sum(case counter_name when 'FreeSpace Page Fetches/sec'then cntr_value else 0 end) as freespace_page_fetch_rate,sum(case counter_name when 'FreeSpace Scans/sec'then cntr_value else 0 end) as freespace_scan_rate,sum(case counter_name when 'Full Scans/sec'then cntr_value else 0 end) asfull_scan_rate,sum(case counter_name when 'Index Searches/sec'then cntr_value else 0 end) asindex_search_rate,sum(case counter_name when 'Mixed page allocations/sec'then cntr_value else 0 end) as mixpage_allocate_rate,sum(case counter_name when 'Pages Allocated/sec'then cntr_value else 0 end) aspage_allocate_rate,sum(case counter_name when 'Page Deallocations/sec'then cntr_value else 0 end) as page_deallocate_rate,sum(case counter_name when 'Page Splits/sec'then cntr_value else 0 end) aspage_split_rate,sum(case counter_name when 'Probe Scans/sec'then cntr_value else 0 end) asprobe_scan_rate,sum(case counter_name when 'Range Scans/sec'then cntr_value else 0 end) asrange_scan_rate,sum(case counter_name when 'Scan Point Revalidations/sec'then cntr_value else 0 end) as scan_point_revalid_rate,sum(case counter_name when 'Skipped Ghosted Records/sec'then cntr_value else 0 end) as skip_ghost_record_rate,sum(case counter_name when 'Table Lock Escalations/sec'then cntr_value else 0 end) as table_lock_escalate_rate,sum(case counter_name when 'Workfiles Created/sec'then cntr_value else 0 end) as workfile_create_rate,sum(case counter_name when 'Worktables Created/sec'then cntr_value else 0 end) as worktable_create_rate,cast(round(100.0*sum(case counter_name when 'Worktables From Cache Ratio'thencntr_value else 0 end) /sum(case counter_name when 'Worktables From Cache Base'then cntr_value+0.01 else 0.01 end),2) as numeric(20,2)) as worktable_cache_hit_percentfrom sysperfinfo where object_name ='SQLServer:Access Methods'2.2 配置数据2.2.1数据库实例配置信息select(select attribute_value from spt_server_info where attribute_name='DBMS_VER') asdb_version,(select alias from sysconfigures,syslanguages where comment='default language' and value=langid) as default_language,(select attribute_value from spt_server_info where attribute_name='COLLATION_SEQ') as charset,(select value from sysconfigures where comment = 'Minimum size of server memory (MB)') as min_server_memory,(select value from sysconfigures where comment = 'Maximum size of server memory (MB)') as max_server_memory,(select value from sysconfigures where comment = 'Maximum worker threads') asmax_worker_threads,(select value from sysconfigures where comment = 'minimum memory per query (kBytes)')as min_query_memory,(select value from sysconfigures where comment = 'remote login timeout')asremote_login_timeout,(select value from sysconfigures where comment = 'remote query timeout')asremote_query_timeout,(select value from sysconfigures where comment = 'Network packet size')asnet_packet_size,(select value from sysconfigures where comment = 'Allow updates to system tables')as allow_update_system_tables,(select value from sysconfigures where comment = 'Allow triggers to be invoked within triggers')as allow_inner_trigger,(select value from sysconfigures where comment = 'Allow remote access')asallow_remote_access,(select attribute_value from spt_server_info where attribute_name='TABLE_LENGTH') as max_table_lenth,(select attribute_value from spt_server_info where attribute_name='COLUMN_LENGTH') as max_column_length,(select attribute_value from spt_server_info where attribute_name='USERID_LENGTH') as max_user_length,(select attribute_value from spt_server_info where attribute_name='MAX_INDEX_COLS') as max_index_column2.2.2数据库的信息select name as database_name,dbid,mode,crdate,cmptlevel,filename from sysdatabases3.SYBASE3.1 性能指标(KPI)3.1.1数据库全局性能select@@connections as connections,@@cpu_busy as cpu_busy,@@io_busy as io_busy,@@idle as idle,@@pack_sent as pack_sent,@@pack_received as pack_received,@@packet_errors as packet_errors,@@total_errors as total_disk_errors, @@total_read as total_read,@@total_write as total_write3.1.2数据库采集间隔性能sp_monitor3.1.3容量信息select (a.value - (select count(*) from master.dbo.sysprocesses where hostprocess not like ' ')) as connectionsremaining,(((select count(*) from master.dbo.sysprocesses where hostprocess not like '')*100)/a.value) as ConnectionsUsedPCT,(select count(*) from master.dbo.sysprocesses) as NumProcesses,(select count(*) from master.dbo.sysprocesses where blocked != 0) as NumBlockedProcs, (select count(distinct ) from syslogins l, sysprocesses p where l.suid = p.suid) as UniqueLoginsConnected,(b.value - (select count(distinct dbid) from master.dbo.sysprocesses)) as OpenDbRemaining,b.value as TotalOpenDBsValue,(select count(*) from master..sysdatabases) as databasenumber,(c.value - (select count(*) from master.dbo.syslocks)) as LocksRemaining, c.value as TotalLocksValuefrom master.dbo.syscurconfigs a,master.dbo.syscurconfigs b,master.dbo.syscurconfigs c where a.config = 103 and b.config = 105 and c.config = 1063.1.4SQL及进程性能declare @date_start datetimedeclare @temp intselect @date_start = getdate()select @temp = sum(error * severity) from master..sysmessages where error between 1000 and 2000or error between 3000 and 4000group by severityselect (select datediff(ms, @date_start, getdate())) as ResponseSqlTime,(select count(*) from master.dbo.sysengines) as eng, round(1000000 / @@timeticks, 3) as ms, (select sum(memusage) from master.dbo.sysprocesses)*(select convert(float, low) / 1024.0 from master..spt_values where number = 1 and type = 'E') as MemoryUsedByProcs3.1.5数据库信息select distinct db_name(dbid) as DbName,(sum(curunreservedpgs(u.dbid, u.lstart,u.unreservedpgs))) *(d.low / 1024) as DatabaseSpaceFreeMB,(sum(size) - sum(curunreservedpgs(u.dbid, u.lstart, u.unreservedpgs))) *(d.low / 1024) as DatabaseSpaceUsedMB,((sum(size) - sum(curunreservedpgs(u.dbid, u.lstart, u.unreservedpgs))) *(d.low / 1024))*100/(sum(size) / (1048576 / d.low)*1024) as DatabaseSpaceUsedPct from master..sysusages u, master..spt_values dwhere u.segmap <> 4and d.number = 1and d.type = 'E'group by u.dbidhaving u.segmap <> 4and d.number = 1and d.type = 'E'order by u.dbid3.1.6段信息select distinct db_name(dbid) as dbname, name as SegName ,status as SegStatus,'UsedMegaBytes' = sum(size - curunreservedpgs(dbid, lstart, unreservedpgs))*(select convert(float, low) / 1024.0 from master..spt_values where number = 1 and type = 'E'),'UnusedMegaBytes' = sum(curunreservedpgs(dbid, lstart, unreservedpgs))*(select convert(float, low) / 1024.0 from master..spt_values where number = 1 and type = 'E'), 'UsedPercent' = sum(size-curunreservedpgs(dbid, lstart, unreservedpgs))*100/sum(size) from sysusages, syssegments where segmap & power(2,segment) = power(2,segment) group by db_name(dbid),name order by dbid3.2 配置数据3.2.1数据库配置信息select @@version as db_version,(select value from master.dbo.sysconfigures where comment='number of remote connections') as MaxConnection,(select value from master.dbo.sysconfigures where comment='number of devices') as NumberOfDevices,(select value from master.dbo.sysconfigures where comment='number of locks') as NumberOfLocks,(select value from master.dbo.sysconfigures where comment='number of pre-allocated extents') as NumberOfExtents,(select value/1024 from master.dbo.sysconfigures where comment='user log cache size') as UserLogCacheSize,(select value from master.dbo.sysconfigures where comment='number of open indexes') as NumberOfOpenIndexes,(select value/512 from master.dbo.sysconfigures where comment='max memory') as MaxMemory,@@tranchained as tranchained3.2.2数据库配置信息select distinct db_name(dbid) as DbName,(sum(curunreservedpgs(u.dbid, u.lstart, u.unreservedpgs))) *(d.low / 1024) as DatabaseSpaceFreeMB,(sum(size) - sum(curunreservedpgs(u.dbid, u.lstart, u.unreservedpgs))) *(d.low / 1024) as DatabaseSpaceUsedMB,((sum(size) - sum(curunreservedpgs(u.dbid, u.lstart, u.unreservedpgs))) *(d.low / 1024))*100/(sum(size) / (1048576 / d.low)*1024) as DatabaseSpaceUsedPct from master..sysusages u, master..spt_values dwhere u.segmap <> 4and d.number = 1and d.type = 'E'group by u.dbidhaving u.segmap <> 4and d.number = 1and d.type = 'E'order by u.dbid3.2.3段信息select distinct db_name(dbid) as dbname, name as SegName ,status as SegStatus,'UsedMegaBytes' = sum(size - curunreservedpgs(dbid, lstart, unreservedpgs))*(select convert(float, low) / 1024.0 from master..spt_values where number = 1 and type = 'E'),'UnusedMegaBytes' = sum(curunreservedpgs(dbid, lstart, unreservedpgs))*(select convert(float, low) / 1024.0 from master..spt_values where number = 1 and type = 'E'), 'UsedPercent' = sum(size-curunreservedpgs(dbid, lstart, unreservedpgs))*100/sum(size) from sysusages, syssegments where segmap & power(2,segment) = power(2,segment) group by db_name(dbid),name order by dbid4.MySql4.1 性能指标(KPI)4.1.1服务器连接(工作)时间数(秒)show status like 'Uptime'4.1.2当前累计连接数量(成功和失败)show status like 'connections'4.1.3尝试连接失败的数量show status like 'Aborted_connects'4.1.4最大使用过的连接数show status like 'max_used_connections'4.1.5现在打开的表数量show status like 'open_tables'4.1.6已经打开表的数量show status like 'opened_tables'4.1.7当前的会话数/总共打开的线程数show status like 'Threads_created'4.1.8当前的活动会话数/当前活动线程数show status like 'Threads_running'4.1.9当前打开的连接数show status like 'Threads_connected'4.1.10查询缓存的空间内存show status like 'Qcache_free_memory'4.1.11查询缓存命中次数show status like 'Qcache_hits'4.1.12查询缓存插入次数show status like 'Qcache_inserts'4.1.13关键字缓存的快的数量show status like 'Key_blocks_used'4.1.14磁盘物理读入一个键值的次数show status like 'Key_reads4.1.15请求从缓存读入一个键值的次数show status like 'Key_read_requests'4.1.16请求将一个关键字块写入缓存次数show status like 'Key_write_requests'4.1.17将一个键值块物理写入磁盘的次数show status like 'Key_writes'4.1.18要花超过long_query_time时间的查询数量show status like 'Slow_queries'4.2 配置数据4.2.1运行Server的主机名select user() as users4.2.2版本select version() as version4.2.3数据库数show databases4.2.4数据库中的表数show tables4.2.5Database文件的保存路径show variables like 'datadir'4.2.6当前连接的用户select user() as user4.3 指标分类4.3.1Key4.3.2Connection4.3.3Select4.3.4Database数据库4.3.5Dbinfo数据库信息4.3.6Theads线程4.3.7Table_locks表锁4.3.8Request请求4.3.9QCACHE缓存。

使⽤sql语句实现设置主键⾃增长列1.新建⼀数据表,⾥⾯有字段id,将id设为为主键create table tb(id int,constraint pkid primary key (id))create table tb(id int primary key )2.新建⼀数据表,⾥⾯有字段id,将id设为主键且⾃动编号create table tb(id int identity(1,1),constraint pkid primary key (id))create table tb(id int identity(1,1) primary key )3.已经建好⼀数据表,⾥⾯有字段id,将id设为主键alter table tb alter column id int not nullalter table tb add constraint pkid primary key (id)4.删除主键Declare @Pk varChar(100);Select @Pk=Name from sysobjects where Parent_Obj=OBJECT_ID('tb') and xtype='PK';if @Pk is not nullexec('Alter table tb Drop '+ @Pk)另外⽅法:create table ttt(t1 int,t2 varchar(8))現在想把字段t1設為⾃增字段和主鍵.那麼運⾏下⾯的代碼:CREATE TABLE dbo.Tmp_ttt(t1 int NOT NULL IDENTITY (1, 1),t2 varchar(8) NULL)goSET IDENTITY_INSERT dbo.Tmp_ttt ONgoIF EXISTS(SELECT * FROM dbo.ttt)EXEC('INSERT INTO dbo.Tmp_ttt (t1, t2)SELECT t1, t2 FROM dbo.ttt TABLOCKX')goSET IDENTITY_INSERT dbo.Tmp_ttt OFFgoDROP TABLE dbo.tttgoEXECUTE sp_rename N'dbo.Tmp_ttt', N'ttt', 'OBJECT'goALTER TABLE dbo.ttt ADD CONSTRAINTPK_ttt PRIMARY KEY CLUSTERED(t1) ON [PRIMARY]COMMIT為什麼不⽤alter table ttt drop column t1goalter table ttt add t1 identity(1,1) not nullgoalter table ttt add constrain primary key pk_t (t1)的⽅法.是因為先刪掉⼀列.再增加⼀列.那麼列的順序就改變了.有可能帶來意想不到的問題.(⽐⽅說,你的程序中有個insert語句是沒有寫字段名的)。

表操作例1 对于表的教学管理数据库中的表STUDENTS ,可以定义如下:CREATE TABLE STUDENTSSNO NUMERIC 6, 0 NOT NULLSNAME CHAR 8 NOT NULLAGE NUMERIC3,0SEX CHAR2BPLACE CHAR20PRIMARY KEYSNO例2 对于表的教学管理数据库中的表ENROLLS ,可以定义如下: CREATE TABLE ENROLLSSNO NUMERIC6,0 NOT NULLCNO CHAR4 NOT NULLGRADE INTPRIMARY KEYSNO,CNOFOREIGN KEYSNO REFERENCES STUDENTSSNOFOREIGN KEYCNO REFERENCES COURSESCNOCHECK GRADE IS NULL OR GRADE BETWEEN 0 AND 100例3 根据表的STUDENTS 表,建立一个只包含学号、姓名、年龄的女学生表;CREATE TABLE GIRLAS SELECT SNO, SNAME, AGEFROM STUDENTSWHERE SEX=' 女';例4 删除教师表TEACHER ;DROP TABLE TEACHER例5 在教师表中增加住址列;ALTER TABLE TEACHERSADD ADDR CHAR50例6 把STUDENTS 表中的BPLACE 列删除,并且把引用BPLACE 列的所有视图和约束也一起删除;ALTER TABLE STUDENTSDROP BPLACE CASCADE例7 补充定义ENROLLS 表的主关键字;ALTER TABLE ENROLLSADD PRIMARY KEY SNO,CNO ;视图操作虚表例9 建立一个只包括教师号、姓名和年龄的视图FACULTY ; 在视图定义中不能包含ORDER BY 子句CREATE VIEW FACULTYAS SELECT TNO, TNAME, AGEFROM TEACHERS例10 从学生表、课程表和选课表中产生一个视图GRADE_TABLE , 它包括学生姓名、课程名和成绩;CREATE VIEW GRADE_TABLEAS SELECT SNAME,CNAME,GRADEFROM STUDENTS,COURSES,ENROLLSWHERE =AND=例11 删除视图GRADE_TABLEDROP VIEW GRADE_TABLE RESTRICT索引操作例12 在学生表中按学号建立索引;CREATE UNIQUE INDEX STON STUDENTS SNO,ASC例13 删除按学号所建立的索引;DROP INDEX ST数据库模式操作例14 创建一个简易教学数据库的数据库模式TEACHING_DB ,属主为ZHANG ;CREATE SCHEMA TEACHING_DB AUTHRIZATION ZHANG例15 删除简易教学数据库模式TEACHING_DB ; 1 选用CASCADE ,即当删除数据库模式时,则本数据库模式和其下属的基本表、视图、索引等全部被删除; 2 选用RESTRICT ,即本数据库模式下属的基本表、视图、索引等事先已清除,才能删除本数据库模式,否则拒绝删除;DROP SCHEMA TEACHING_DB CASCADE单表操作例16 找出 3 个学分的课程号和课程名;SELECT CNO, CNAMEFROM COURSESWHERE CREDIT =3例17 查询年龄大于22 岁的学生情况;SELECTFROM STUDENTSWHERE AGE >22例18 找出籍贯为河北的男生的姓名和年龄;SELECT SNAME, AGEFROM STUDENTSWHERE BPLACE =' 河北' AND SEX =' 男'例19 找出年龄在20 ~23 岁之间的学生的学号、姓名和年龄,并按年龄升序排序; ASC 升序或DESC 降序声明排序的方式,缺省为升序;SELECT SNO, SNAME, AGEFROM STUDENTSWHERE AGE BETWEEN 20 AND 23ORDER BY AGE例20 找出年龄小于23 岁、籍贯是湖南或湖北的学生的姓名和性别;条件比较运算符=、<和逻辑运算符AND 与,此外还可以使用的运算符有:>大于、>=大于等于、<=小于等于、<>不等于、NOT 非、OR 或等;谓词LIKE 只能与字符串联用,常常是“ <列名>LIKE pattern” 的格式;特殊字符“_” 和“%” 作为通配符;谓词IN 表示指定的属性应与后面的集合括号中的值集或某个查询子句的结果中的某个值相匹配,实际上是一系列的OR 或的缩写;谓词NOT IN 表示指定的属性不与后面的集合中的某个值相匹配;谓词BETWEEN 是“ 包含于… 之中” 的意思;SELECT SNAME, SEXFROM STUDENTSWHERE AGE <23 AND BPLACE LIKE' 湖%'或SELECT SNAME, SEXFROM STUDENTSWHERE AGE <23 AND BPLACE IN ' 湖南' , ' 湖北'例22 找出学生表中籍贯是空值的学生的姓名和性别;在SQL 中不能使用条件:<列名>=NULL ;在SQL 中只有一个特殊的查询条件允许查询NULL 值:SELECT SNAME, SEXFROM STUDENTSWHERE BPLACE IS NULL多表操作例23 找出成绩为95 分的学生的姓名;子查询SELECT SNAMEFROM STUDENTSWHERE SNO =SELECT SNOFROM ENROLLSWHERE GRADE =95例24 找出成绩在90 分以上的学生的姓名;SELECT SNAMEFROM STUDENTSWHERE SNO INSELECT SNOFROM ENROLLSWHERE GRADE >90或SELECT SNAMEFROM STUDENTSWHERE SNO =ANYSELECT SNOFROM ENROLLSWHERE GRADE >90例25 查询全部学生的学生名和所学课程号及成绩;连接查询SELECT SNAME, CNO, GRADEFROM STUDENTS, ENROLLSWHERE =例26 找出籍贯为山西或河北,成绩为90 分以上的学生的姓名、籍贯和成绩;当构造多表连接查询命令时,必须遵循两条规则;第一,连接条件数正好比表数少 1 若有三个表,就有两个连接条件;第二,若一个表中的主关键字是由多个列组成,则对此主关键字中的每一个列都要有一个连接条件也有少数例外情况SELECT SNAME, BPLACE, GRADEFROM STUDENTS, ENROLLSWHERE BPLACE IN ‘ 山西’ , ‘ 河北’AND GRADE >=90 AND =例28 查出课程成绩在80 分以上的女学生的姓名、课程名和成绩; FROM 子句中的子查询SELECT SNAME,CNAME, GRADEFROM SELECT SNAME, CNAME , GRADEFROM STUDENTS, ENROLLS,COURSESWHERE SEX =' 女'AS TEMP SNAME, CNAME,GRADEWHERE GRADE >80表达式与函数的使用例29 查询各课程的学时数;算术表达式由算术运算符+、-、、/与列名或数值常量所组成;SELECT CNAME,COURSE_TIME =CREDIT16FROM COURSES例30 找出教师的最小年龄;内部函数:SQL 标准中只使用COUNT 、SUM 、AVG 、MAX 、MIN 函数,称之为聚集函数Set Function ; COUNT 函数的结果是该列统计值的总数目, SUM 函数求该列统计值之和, AVG 函数求该列统计值之平均值, MAX 函数求该列最大值, MIN 函数求该列最小值;SELECT MINAGEFROM TEACHERS例31 统计年龄小于等于22 岁的学生人数;统计SELECT COUNTFROM STUDENTSWHERE AGE < =22例32 找出学生的平均成绩和所学课程门数;SELECT SNO, AVGGRADE, COURSES =COUNTFROM ENROLLSGROUP BY SNO例34 找出年龄超过平均年龄的学生姓名;SELECT SNAMEFROM STUDENTSWHERE AGE >SELECT AVGAGEFROM STUDENTS例35 找出各课程的平均成绩,按课程号分组,且只选择学生超过 3 人的课程的成绩; GROUP BY 与HAVINGGROUP BY 子句把一个表按某一指定列或一些列上的值相等的原则分组,然后再对每组数据进行规定的操作;GROUP BY 子句总是跟在WHERE 子句后面,当WHERE 子句缺省时,它跟在FROM 子句后面;HAVING 子句常用于在计算出聚集之后对行的查询进行控制;SELECT CNO, AVGGRADE, STUDENTS =COUNTFROM ENROLLSGROUP BY CNOHAVING COUNT >= 3相关子查询例37 查询没有选任何课程的学生的学号和姓名;当一个子查询涉及到一个来自外部查询的列时,称为相关子查询Correlated Subquery ;相关子查询要用到存在测试谓词EXISTS 和NOT EXISTS ,以及ALL 、ANY SOME 等;SELECT SNO, SNAMEFROM STUDENTSWHERE NOT EXISTSSELECTFROM ENROLLSWHERE =例38 查询哪些课程只有男生选读;SELECT DISTINCT CNAMEFROM COURSES CWHERE ' 男' =ALLSELECT SEXFROM ENROLLS , STUDENTSWHERE = AND=例39 要求给出一张学生、籍贯列表,该表中的学生的籍贯省份,也是其他一些学生的籍贯省份;SELECT SNAME, BPLACEFROM STUDENTS AWHERE EXISTSSELECTFROM STUDENTS BWHERE = AND< >例40 找出选修了全部课程的学生的姓名;本查询可以改为:查询这样一些学生,没有一门课程是他不选修的;SELECT SNAMEFROM STUDENTSWHERE NOT EXISTSSELECTFROM COURSESWHERE NOT EXISTSSELECTFROM ENROLLSWHERE =AND =关系代数运算例41 设有某商场工作人员的两张表:营业员表SP_SUBORD 和营销经理表SP_MGR ,其关系数据模式如下:SP_SUBORD SALPERS_ID, SALPERS_NAME, MANAGER_ID, OFFICESP_MGR SALPERS_ID, SALPERS_NAME, MANAGER_ID, OFFICE其中,属性SALPERS_ID 为工作人员的编号, SALPERS_NAME 为工作人员的姓名, MANAGER_ID 为所在部门经理的编号, OFFICE 为工作地点;若查询全部商场工作人员,可以用下面的SQL 语句:SELECT FROM SP_SUBORDUNIONSELECT FROM SP_MGR或等价地用下面的SQL 语句:SELECTFROM TABLE SP_SUBORD UNION TABLE SP_MGR2 INTERSECTSELECT FROM SP_SUBORDINTERSECTSELECT FROM SP_MGR或等价地用下面的SQL 语句:SELECTFROM TABLE SP_SUBORD INTERSECT TABLE SP_MGR或用带ALL 的SQL 语句:SELECT FROM SP_SUBORDINTERSECT ALLSELECT FROM SP_MGR或SELECTFROM TABLE SP_SUBORD INTERSECT ALL TABLE SP_MGR3 EXCEPTSELECT FROM SP_MGREXCEPTSELECT FROM SP_SUBORD或等价地用下面的SQL 语句:SELECTFROM TABLE SP_MGR EXCEPT TABLE SP_ SUBORD或用带ALL 的SQL 语句:EXCEPT ALLSELECT FROM SP_SUBORD例42 查询籍贯为四川、课程成绩在80 分以上的学生信息及其成绩;自然连接SELECT FROM STUDENTSWHERE BPLACE=‘ 四川’NATURAL JOINSELECT FROM ENROLLSWHERE GRADE >=80例列出全部教师的姓名及其任课的课程号、班级;外连接与外部并外连接允许在结果表中保留非匹配元组,空缺部分填以NULL ;外连接的作用是在做连接操作时避免丢失信息;外连接有3 类:1 左外连接Left Outer Join ;连接运算谓词为LEFT OUTER JOIN ,其结果表中保留左关系的所有元组;2 右外连接Right Outer Join ;连接运算谓词为RIGHT OUTER JOIN ,其结果表中保留右关系的所有元组;3 全外连接Full Outer Join ;连接运算谓词为FULL OUTER JOIN ,其结果表中保留左右两关系的所有元组;SELECT TNAME, CNO, CLASSFROM TEACHERS LEFT OUTER JOIN TEACHING USING TNOSQL 的数据操纵例44 把教师李映雪的记录加入到教师表TEACHERS 中;插入INSERT INTO TEACHERSVALUES1476 , ' 李映雪' , 44 , ' 副教授'例45 成绩优秀的学生将留下当教师;INSERT INTO TEACHERS TNO , TNAMESELECT DISTINCT SNO , SNAMEFROM STUDENTS , ENROLLSWHERE =AND GRADE >=90例47 把所有学生的年龄增加一岁;修改UPDATE STUDENTSSET AGE =AGE+1例48 学生张春明在数据库课考试中作弊,该课成绩应作零分计;UPDATE ENROLLSSET GRADE =0WHERE CNO ='C1' AND' 张春明' =SELECT SNAMEFROM STUDENTSWHERE =例49 从教师表中删除年龄已到60 岁的退休教师的数据;删除WHERE AGE >=60SQL 的数据控制例50 授予LILI 有对表STUDENTS 的查询权;表/视图特权的授予一个SQL 特权允许一个被授权者在给定的数据库对象上进行特定的操作;授权操作的数据库对象包括:表/ 视图、列、域等;授权的操作包括:INSERT 、UPDATE 、DELETE 、SELECT 、REFERENCES 、TRIGGER 、UNDER 、USAGE 、EXECUTE 等;其中INSERT 、UPDATE 、DELETE 、SELECT 、REFERENCES 、TRIGGER 有对表做相应操作的权限,故称为表特权;GRANT SELECT ON STUDENTSTO LILIWITH GRANT OPTION例51 取消LILI 的存取STUDENTS 表的特权;REVOKE ALLON STUDENTSFROM LILI CASCADE不断补充中:1. 模糊查找:它判断列值是否与指定的字符串格式相匹配;可用于char、varchar、text、ntext、datetime 和smalldatetime等类型查询;可使用以下通配字符:百分号%:可匹配任意类型和长度的字符,如果是中文,请使用两个百分号即%%;下划线_:匹配单个任意字符,它常用来限制表达式的字符长度;方括号:指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个;^:其取值也相同,但它要求所匹配对象为指定字符以外的任一个字符;例如:限制以Publishing结尾,使用LIKE '%Publishing'限制以A开头:LIKE 'A%'限制以A开头外:LIKE '^A%'2.更改表格ALTER TABLE table_nameADD COLUMN column_name DATATYPE说明:增加一个栏位没有删除某个栏位的语法;ALTER TABLE table_nameADD PRIMARY KEY column_name说明:更改表得的定义把某个栏位设为主键;ALTER TABLE table_nameDROP PRIMARY KEY column_name说明:把主键的定义删除;by在select 语句中可以使用group by 子句将行划分成较小的组,然后,使用聚组函数返回每一个组的汇总信息,另外,可以使用having子句限制返回的结果集;group by 子句可以将查询结果分组,并返回行的汇总信息Oracle 按照group by 子句中指定的表达式的值分组查询结果;在带有group by 子句的查询语句中,在select 列表中指定的列要么是group by 子句中指定的列,要么包含聚组函数select maxsal,job emp group by job;注意maxsal,job的job并非一定要出现,但有意义查询语句的select 和group by ,having 子句是聚组函数唯一出现的地方,在where 子句中不能使用聚组函数;select deptno,sumsal from emp where sal>1200 group by deptno having sumsal>8500 order by deptno;当在gropu by 子句中使用having 子句时,查询结果中只返回满足having条件的组;在一个sql语句中可以有where子句和having子句;having 与where 子句类似,均用于设置限定条件where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,条件中不能包含聚组函数,使用where条件显示特定的行;having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件显示特定的组,也可以使用多个分组标准进行分组;查询每个部门的每种职位的雇员数select deptno,job,count from emp group by deptno,job;4.外连接与内连接有时候,即使在连接的表中没有相应的行,用户可能想从一张表中看数据,Oracle提供了外连接实现该功能;内连接是指连接查询只显示完全满足连接条件的记录,即等值连接,外连接的查询结果是内连接查询结果的扩展;外连接不仅返回满足连接条件的所有记录而且也返回了一个表中那些在另一个表中没有匹配行的记录;外连接的操作符是“+”;“+”号放在连接条件中信息不完全的那一边即没有相应行的那一边;运算符“+”影响NULL行的建立;建一行或多行NULL来匹配连接的表中信息完全的行;外连接运算符“+”只能出现在where子句中表达式的一边;假如在多张表之间有多个连接条件,外连接运算符不能使用or,in逻辑运算符与其它条件组合;假如emp表中deptno=10的ename为空值,dept表中deptno=20的loc为空值:1.selectename,,locfromemp,deptwhere+=;如果在中有的数值在中没有值,则在做外连接时,结果中ename会产生一个空值;=102.selectename,,locfromemp,deptwhere=+;如果在中有的数值在中没有值,则在做外连接时,结果中loc会产生一个空值;;=205.自连接自连接是指同一张表的不同行间的连接;该连接不受其他表的影响;用自连接可以比较同一张表中不同行的某一列的值;因为自连接查询仅涉及到某一张表与其自身的连接;所以在from子句中该表名出现两次,分别用两个不同的别名表示,两个别名当作两张不同的表进行处理,与其它的表连接一样,别名之间也使用一个或多个相关的列连接;为了区分同一张表的不同行的列,在名前永别名加以限制;select,managerfromemp worker,emp managerwhere=;6.集合运算基合运算符可以用于从多张表中选择数据;①UNION运算用于求两个结果集合的并集两个结果集合的所有记录,并自动去掉重复行;select ename,sal from account where sal>2000unionselect ename,sal from research where sal>2000unionselect ename,sal from sales where sal>2000;注:ename,sal 是必须一致的;②UNION ALL运算用于求两个结果集合的并集两个结果集中的所有记录,并且不去掉重复行;select ename,sal from account where sal>2000unionselect ename,sal from research where sal>2000unionselect ename,sal from sales where sal>2000;③INTERSECT运算intersect运算返回查询结果中相同的部分;各部门中有哪些相同的职位select Job from accountintersectselect Job from researchintersectselect Job from sales;④MINUS运算minus返回两个结果集的差集;在第一个结果集中存在的,而在第二个结果集中不存在的行; 有那些职位是财务部中有,而在销售部门中没有select Job from accountminusselect Job from sales;。

sql经典查询语句查询:select * from table1 where ⼯资>2500 and ⼯资<3000 //查找⼀个⼯资区间select 姓名 from table1 where 性别='0' and ⼯资='4000' //查找性别和⼯资的条件select * from table1 where not ⼯资= 3200 //查找⼯资不等于3200的select * from table1 order by ⼯资desc //将⼯资按照降序排列select * from table1 order by ⼯资 asc //将⼯资按照升序排列select * from table1 where year(出⾝⽇期)=1987 //查询table1 中所有出⾝在1987的⼈select * from table1 where name like '%张' /'%张%' /'张%' //查询1,⾸位字‘张’3,尾位字‘张’2,模糊查询select * from table1 order by money desc //查询表1按照⼯资的降序排列表1 (升序为asc)select * from table1 where brithday is null //查询表1 中出⾝⽇期为空的⼈select * into table2 from table3 //将表3中的所有数据转换成表2 (相当于复制)删库和建库use 数据库(aa) //使⽤数据库aacreate bb(数据库) //创建数据库bbcreate table table3 ( name varchar(10),sex varchar(2),money money, brithday datetime) //创建⼀个表3中有姓名,性别,⼯资,出⾝⽇期(此表说明有四列)insert into table3 values ('张三','男','2500','1989-1-5') //在表中添加⼀⾏张三的记录alter table table3 add tilte varchar(10) //向表3 中添加⼀列“title(职位)”alter table table3 drop column sex //删除table3中‘性别’这⼀列drop database aa //删除数据库aadrop table table3 //删除表3delete * from table3 //删除table3 中所有的数据,但table3这个表还在delete from table1 where 姓名='倪涛' and ⽇期 is nulldelete from table1 where 姓名='倪涛' and ⽇期='1971'更改库表的数据update table3 set money=money*1.2 //为表3所有⼈⼯资都增长20%update table3 set money=money*1.2 where title='经理' //为表3中“职位”是经理的⼈⼯资增长20%update table1 set ⼯资= 5000 where 姓名='孙⼋' //将姓名为孙⼋的⼈的⼯资改为5000update table1 set 姓名='敬光' where 姓名='倪涛' and 性别=1 //将性别为男和姓名为倪涛的⼈改为敬光经典查询语句之⼆1显⽰系部编号为03的系部名称Select departname From department Where departno=’03’2.查询系部名称中含有'⼯程'两个字的系部的名称。

实验二:简单查询和连接查询一、实验目的:熟练掌握用SQL语句实现的简单查询和多个数据表连接查询。
二、实验内容:(一)完成下面的简单查询:①查询所有“天津”的供应商明细;②查询所有“红色”的14公斤以上的零件。
③查询工程名称中含有“厂”字的工程明细。
(二)完成下面的连接查询:①等值连接:求s表和j表的相同城市的等值连接。
②自然连接:查询所有的供应明细,要求显示供应商、零件和工程的名称,并按照供应、工程、零件排序。
③笛卡尔积:求s和p表的笛卡尔积④左连接:求j表和spj表的左连接。
⑤右连接:求spj表和j表的右连接。
三、完成情况:成功完成各项查询任务查询的sql语句如下:SELECT*FROM SWHERE CITY='天津';SELECT*FROM PWHERE COLOR='红'AND WEIGHT>=14;SELECT*FROM JWHERE JNAME like'%厂';SELECT*FROM S,JWHERE S.CITY=J.CITY;select SPJ.SNO,S.SNAME,SPJ.PNO,P.PNAME,SPJ.JNO,J.JNAME,SPJ.QTYfrom S,P,J,SPJwhere S.SNO=SPJ.SNO AND P.PNO=SPJ.PNO AND J.JNO=SPJ.JNOORDER BY QTY;select*from S,PSELECT J.JNO,J.JNAME,J.CITY,SPJ.SNO,SPJ.PNO,QTYFROM J LEFT JOIN SPJ on(J.JNO=SPJ.JNO);SELECT J.JNO,J.JNAME,J.CITY,SPJ.SNO,SPJ.PNO,QTYFROM J right JOIN SPJ on(J.JNO=SPJ.JNO);SELECT J.JNO,J.JNAME,J.CITY,SPJ.SNO,SPJ.PNO,QTYFROM SPJ right JOIN J on(J.JNO=SPJ.JNO);四、实验结果:①查询所有“天津”的供应商明细;SNO SNAME STATUS CITYS1 精益 20 天津S4 丰盛泰 20 天津②查询所有“红色”的14公斤以上的零件。

数据库sql语句大全数据库SQL语句大全。
数据库SQL语句是数据库操作的重要组成部分,掌握各种SQL语句对于数据库的管理和应用具有重要意义。
本文将介绍常用的数据库SQL语句,包括数据查询、数据更新、数据删除、数据插入等操作,希望能够帮助大家更好地理解和应用数据库SQL语句。
1. 数据查询。
数据查询是数据库操作中最常见的操作之一,通过SQL语句可以实现对数据库中数据的查询和检索。
常用的数据查询语句包括:SELECT FROM table_name; // 查询表中所有数据。
SELECT column1, column2 FROM table_name; // 查询表中指定列的数据。
SELECT FROM table_name WHERE condition; // 带条件的数据查询。
2. 数据更新。
数据更新是指对数据库中已有数据进行修改操作,通过SQL语句可以实现对数据的更新操作。
常用的数据更新语句包括:UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition; // 更新表中符合条件的数据。
UPDATE table_name SET column = value; // 更新表中所有数据的指定列。
3. 数据删除。
数据删除是指对数据库中已有数据进行删除操作,通过SQL语句可以实现对数据的删除操作。
常用的数据删除语句包括:DELETE FROM table_name WHERE condition; // 删除表中符合条件的数据。
DELETE FROM table_name; // 删除表中所有数据。
4. 数据插入。
数据插入是指向数据库中插入新的数据,通过SQL语句可以实现对数据的插入操作。
常用的数据插入语句包括:INSERT INTO table_name (column1, column2) VALUES (value1, value2); // 向表中插入指定列的数据。
标题:如何使用SQL查询语句实现两列相减循环求差的算法在数据库管理中,我们经常会碰到需要对两列数据进行循环求差的情况。
这种需求在实际工作中也是非常常见的,比如在进行数据分析和业务逻辑处理时,我们可能需要计算某个时间段内的数据变化情况,这时就需要用到两列相减循环求差的算法。
在本文中,我将介绍如何使用SQL查询语句实现这种算法,并为您提供详细的步骤和案例分析。
1.算法思路在SQL中,我们可以通过使用子查询和Join语句来实现两列相减循环求差的算法。
具体思路如下: - 我们需要分别查询出两列数据,并为它们分别创建一个序号字段,以便于后续的数据关联和计算。
- 我们可以使用Join语句将这两个查询结果关联起来,根据序号字段进行关联。
- 我们可以在Join的结果集中使用算术运算符来计算两列数据的差值。
2.SQL实现步骤接下来,我将为您详细介绍如何使用SQL查询语句实现两列相减循环求差的算法。
以表A和表B为例,表A包含列A1和列A2,表B包含列B1和列B2。
步骤一:查询出表A的数据,并为其创建序号字段SELECT ROW_NUMBER() OVER (ORDER BY A1) AS A1_ID, A1, A2 FROM TableA步骤二:查询出表B的数据,并为其创建序号字段SELECT ROW_NUMBER() OVER (ORDER BY B1) AS B1_ID, B1, B2 FROM TableB步骤三:使用Join语句将两个查询结果关联起来SELECT A1_ID, A1, A2, B1, B2FROM(SELECT ROW_NUMBER() OVER (ORDER BY A1) AS A1_ID, A1, A2 FROM TableA) AS AJOIN(SELECT ROW_NUMBER() OVER (ORDER BY B1) AS B1_ID, B1, B2 FROM TableB) AS BON A1_ID = B1_ID步骤四:在Join的结果集中计算两列数据的差值SELECT A1, B1, A2 - B2 AS DifferenceFROM(SELECT ROW_NUMBER() OVER (ORDER BY A1) AS A1_ID, A1, A2 FROM TableA) AS AJOIN(SELECT ROW_NUMBER() OVER (ORDER BY B1) AS B1_ID, B1, B2FROM TableB) AS BON A1_ID = B1_ID3.案例分析假设我们有如下两个表A和表B: TableA | A1 | A2 | | — | – | | 1 | 10 | | 2 | 20 | | 3 | 30 | TableB | B1 | B2 | | —| – | | 1 | 5 | | 2 | 15 | | 3 | 25 |根据上述算法思路和实现步骤,我们可以得到如下结果: | A1 | B1 | Difference | | — | – | ———- | | 1 | 1 | 5 | | 2 | 2 | 5 | | 3 | 3 | 5 |通过以上案例分析,我们可以看到使用SQL查询语句实现两列相减循环求差的算法非常方便和高效。
Student(S#,Sname,Sage,Ssex) 学生表Course(C#,Cname,T#) 课程表SC(S#,C#,score) 成绩表Teacher(T#,Tname) 教师表create table Student(S# varchar(20),Sname varchar(10),Sage int,Ssex varchar(2))前面加一列序号:ifexists(select table_name from information_schema.tableswhere table_name='Temp_Table')drop table Temp_Tablegoselect 排名=identity(int,1,1),* INTO Temp_Table from Studentgoselect * from Temp_Tablegodrop database [ ] --删除空的没有名字的数据库问题:1、查询“”课程比“”课程成绩高的所有学生的学号;select a.S# from (select s#,score from SC where C#='001') a,(select s#,scorefrom SC where C#='002') bwhere a.score>b.score and a.s#=b.s#;2、查询平均成绩大于分的同学的学号和平均成绩;select S#,avg(score)from scgroup by S# having avg(score) >60;3、查询所有同学的学号、姓名、选课数、总成绩;select Student.S#,Student.Sname,count(SC.C#),sum(score)from Student left Outer join SC on Student.S#=SC.S#group by Student.S#,Sname4、查询姓“李”的老师的个数;select count(distinct(Tname))from Teacherwhere Tname like '李%';5、查询没学过“叶平”老师课的同学的学号、姓名;select Student.S#,Student.Snamefrom Studentwhere S# not in (select distinct( SC.S#) from SC,Course,Teacher where SC.C#=Course.C# and Teacher.T#=Course.T# and Teacher.Tname='叶平');6、查询学过“”并且也学过编号“”课程的同学的学号、姓名;select Student.S#,Student.Sname from Student,SC whereStudent.S#=SC.S# and SC.C#='001'and exists( Select * from SC as SC_2 where SC_2.S#=SC.S# and SC_2.C#='002');7、查询学过“叶平”老师所教的所有课的同学的学号、姓名;select S#,Snamefrom Studentwhere S# in (select S# from SC ,Course ,Teacher where SC.C#=Course.C# and Teacher.T#=Course.T# and Teacher.Tname='叶平' group by S# having count(SC.C#)=(select count(C#) from Course,Teacher whereTeacher.T#=Course.T# and Tname='叶平'));8、查询课程编号“”的成绩比课程编号“”课程低的所有同学的学号、姓名;Select S#,Sname from (select Student.S#,Student.Sname,score ,(select score from SC SC_2 where SC_2.S#=Student.S# and SC_2.C#='002') score2 from Student,SC where Student.S#=SC.S# and C#='001') S_2 where score2 <score;9、查询所有课程成绩小于分的同学的学号、姓名;select S#,Snamefrom Studentwhere S# not in (select Student.S# from Student,SC where S.S#=SC.S# and score>60);10、查询没有学全所有课的同学的学号、姓名;select Student.S#,Student.Snamefrom Student,SCwhere Student.S#=SC.S# group by Student.S#,Student.Sname having count(C#) <(select count(C#) from Course);11、查询至少有一门课与学号为“”的同学所学相同的同学的学号和姓名;select S#,Sname from Student,SC where Student.S#=SC.S# and C# in select C# from SC where S#='1001';12、查询至少学过学号为“”同学所有一门课的其他同学学号和姓名;select distinct SC.S#,Snamefrom Student,SCwhere Student.S#=SC.S# and C# in (select C# from SC where S#='001');13、把“SC”表中“叶平”老师教的课的成绩都更改为此课程的平均成绩;update SC set score=(select avg(SC_2.score)from SC SC_2where SC_2.C#=SC.C# ) from Course,Teacher where Course.C#=SC.C# and Course.T#=Teacher.T# and Teacher.Tname='叶平');14、查询和“”号的同学学习的课程完全相同的其他同学学号和姓名;select S# from SC where C# in (select C# from SC where S#='1002') group by S# having count(*)=(select count(*) from SC whereS#='1002');15、删除学习“叶平”老师课的SC表记录;Delect SCfrom course ,Teacherwhere Course.C#=SC.C# and Course.T#= Teacher.T# and Tname='叶平';16、向SC表中插入一些记录,这些记录要求符合以下条件:没有上过编号“”课程的同学学号、、号课的平均成绩;Insert SC select S#,'002',(Select avg(score)from SC where C#='002') from Student where S# not in (Select S# from SC where C#='002');17、按平均成绩从高到低显示所有学生的“数据库”、“企业管理”、“英语”三门的课程成绩,按如下形式显示:学生ID,,数据库,企业管理,英语,有效课程数,有效平均分SELECT S# as 学生ID,(SELECT score FROM SC WHERE SC.S#=t.S# AND C#='004') AS 数据库,(SELECT score FROM SC WHERE SC.S#=t.S# AND C#='001') AS 企业管理,(SELECT score FROM SC WHERE SC.S#=t.S# AND C#='006') AS 英语,COUNT(*) AS 有效课程数, AVG(t.score) AS 平均成绩FROM SC AS tGROUP BY S#ORDER BY avg(t.score)18、查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分SELECT L.C# As 课程ID,L.score AS 最高分,R.score AS 最低分FROM SC L ,SC AS RWHERE L.C# = R.C# andL.score = (SELECT MAX(IL.score)FROM SC AS IL,Student AS IMWHERE L.C# = IL.C# and IM.S#=IL.S#GROUP BY IL.C#)ANDR.Score = (SELECT MIN(IR.score)FROM SC AS IRWHERE R.C# = IR.C#GROUP BY IR.C#);19、按各科平均成绩从低到高和及格率的百分数从高到低顺序SELECT t.C# AS 课程号,max(ame)AS 课程名,isnull(AVG(score),0) AS 平均成绩,100 * SUM(CASE WHEN isnull(score,0)>=60 THEN 1 ELSE 0 END)/COUNT(*) AS 及格百分数FROM SC T,Coursewhere t.C#=course.C#GROUP BY t.C#ORDER BY 100 * SUM(CASE WHEN isnull(score,0)>=60 THEN 1 ELSE 0 END)/COUNT(*) DESC20、查询如下课程平均成绩和及格率的百分数(用"1行"显示): 企业管理(),马克思(),OO&UML (),数据库()SELECT SUM(CASE WHEN C# ='001' THEN score ELSE 0 END)/SUM(CASE C# WHEN '001' THEN 1 ELSE 0 END) AS 企业管理平均分,100 * SUM(CASE WHEN C# = '001' AND score >= 60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C# = '001' THEN 1 ELSE 0 END) AS 企业管理及格百分数,SUM(CASE WHEN C# = '002' THEN score ELSE 0 END)/SUM(CASE C# WHEN '002' THEN 1 ELSE 0 END) AS 马克思平均分,100 * SUM(CASE WHEN C# = '002' AND score >= 60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C# = '002' THEN 1 ELSE 0 END) AS 马克思及格百分数,SUM(CASE WHEN C# = '003' THEN score ELSE 0 END)/SUM(CASE C# WHEN '003' THEN 1 ELSE 0 END) AS UML平均分,100 * SUM(CASE WHEN C# = '003' AND score >= 60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C# = '003' THEN 1 ELSE 0 END) AS UML及格百分数,SUM(CASE WHEN C# = '004' THEN score ELSE 0 END)/SUM(CASE C# WHEN '004' THEN 1 ELSE 0 END) AS 数据库平均分,100 * SUM(CASE WHEN C# = '004' AND score >= 60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C# = '004' THEN 1 ELSE 0 END) AS 数据库及格百分数FROM SC21、查询不同老师所教不同课程平均分从高到低显示SELECT max(Z.T#) AS 教师ID,MAX(Z.Tname) AS 教师姓名,C.C# AS 课程ID,MAX(ame) AS 课程名称,AVG(Score) AS 平均成绩FROM SC AS T,Course AS C ,Teacher AS Zwhere T.C#=C.C# and C.T#=Z.T#GROUP BY C.C#ORDER BY AVG(Score) DESC22、查询如下课程成绩第名到第名的学生成绩单:企业管理(),马克思(),UML (),数据库()[学生ID],[学生姓名],企业管理,马克思,UML,数据库,平均成绩SELECT DISTINCT top 3SC.S# As 学生学号,Student.Sname AS 学生姓名,T1.score AS 企业管理,T2.score AS 马克思,T3.score AS UML,T4.score AS 数据库,ISNULL(T1.score,0) + ISNULL(T2.score,0) + ISNULL(T3.score,0) + ISNULL(T4.score,0) as 总分FROM Student,SC LEFT JOIN SC AS T1ON SC.S# = T1.S# AND T1.C# = '001'LEFT JOIN SC AS T2ON SC.S# = T2.S# AND T2.C# = '002'LEFT JOIN SC AS T3ON SC.S# = T3.S# AND T3.C# = '003'LEFT JOIN SC AS T4ON SC.S# = T4.S# AND T4.C# = '004'WHERE student.S#=SC.S# andISNULL(T1.score,0) + ISNULL(T2.score,0) + ISNULL(T3.score,0) + ISNULL(T4.score,0)NOT IN(SELECTDISTINCTTOP 15 WITH TIESISNULL(T1.score,0) + ISNULL(T2.score,0) + ISNULL(T3.score,0) + ISNULL(T4.score,0)FROM scLEFT JOIN sc AS T1ON sc.S# = T1.S# AND T1.C# = 'k1'LEFT JOIN sc AS T2ON sc.S# = T2.S# AND T2.C# = 'k2'LEFT JOIN sc AS T3ON sc.S# = T3.S# AND T3.C# = 'k3'LEFT JOIN sc AS T4ON sc.S# = T4.S# AND T4.C# = 'k4'ORDER BY ISNULL(T1.score,0) + ISNULL(T2.score,0) +ISNULL(T3.score,0) + ISNULL(T4.score,0) DESC);23、统计列印各科成绩,各分数段人数:课程ID,课程名称,[100-85],[85-70],[70-60],[ <60]SELECT SC.C# as 课程ID, Cname as 课程名称,SUM(CASE WHEN score BETWEEN 85 AND 100 THEN 1 ELSE 0 END) AS [100 - 85],SUM(CASE WHEN score BETWEEN 70 AND 85 THEN 1 ELSE 0 END) AS [85 - 70],SUM(CASE WHEN score BETWEEN 60 AND 70 THEN 1 ELSE 0 END) AS [70 - 60],SUM(CASE WHEN score < 60 THEN 1 ELSE 0 END) AS [60 -] FROM SC,Coursewhere SC.C#=Course.C#GROUP BY SC.C#,Cname;24、查询学生平均成绩及其名次SELECT 1+(SELECT COUNT( distinct 平均成绩)FROM (SELECT S#,AVG(score) AS 平均成绩FROM SCGROUP BY S#) AS T1WHERE 平均成绩> T2.平均成绩) as 名次,S# as 学生学号,平均成绩FROM (SELECT S#,AVG(score) 平均成绩FROM SCGROUP BY S#) AS T2ORDER BY 平均成绩desc;25、查询各科成绩前三名的记录:(不考虑成绩并列情况)SELECT t1.S# as 学生ID,t1.C# as 课程ID,Score as 分数FROM SC t1WHERE score IN (SELECT TOP 3 scoreFROM SCWHERE t1.C#= C#ORDER BY score DESC)ORDER BY t1.C#;26、查询每门课程被选修的学生数select c#,count(S#) from sc group by C#;27、查询出只选修了一门课程的全部学生的学号和姓名select SC.S#,Student.Sname,count(C#) AS 选课数from SC ,Studentwhere SC.S#=Student.S# group by SC.S# ,Student.Sname havingcount(C#)=1;28、查询男生、女生人数Select count(Ssex) as 男生人数from Student group by Ssex having Ssex='男';Select count(Ssex) as 女生人数from Student group by Ssex having Ssex='女';29、查询姓“张”的学生名单SELECT Sname FROM Student WHERE Sname like '张%';30、查询同名同性学生名单,并统计同名人数select Sname,count(*) from Student group by Sname having count(*)>1;;31、年出生的学生名单(注:Student表中Sage列的类型是datetime)select Sname, CONVERT(char (11),DATEPART(year,Sage)) as agefrom studentwhere CONVERT(char(11),DATEPART(year,Sage))='1981';32、查询每门课程的平均成绩,结果按平均成绩升序排列,平均成绩相同时,按课程号降序排列Select C#,Avg(score) from SC group by C# order by Avg(score),C# DESC ;33、查询平均成绩大于的所有学生的学号、姓名和平均成绩select Sname,SC.S# ,avg(score)from Student,SCwhere Student.S#=SC.S# group by SC.S#,Sname havingavg(score)>85;34、查询课程名称为“数据库”,且分数低于的学生姓名和分数Select Sname,isnull(score,0)from Student,SC,Coursewhere SC.S#=Student.S# and SC.C#=Course.C# and ame='数据库'and score <60;35、查询所有学生的选课情况;SELECT SC.S#,SC.C#,Sname,CnameFROM SC,Student,Coursewhere SC.S#=Student.S# and SC.C#=Course.C# ;36、查询任何一门课程成绩在分以上的姓名、课程名称和分数;SELECT distinct student.S#,student.Sname,SC.C#,SC.scoreFROM student,ScWHERE SC.score>=70 AND SC.S#=student.S#;37、查询不及格的课程,并按课程号从大到小排列select c# from sc where scor e <60 order by C# ;38、查询课程编号为且课程成绩在分以上的学生的学号和姓名;select SC.S#,Student.Sname from SC,Student where SC.S#=Student.S# and Score>80 and C#='003';39、求选了课程的学生人数select count(*) from sc;40、查询选修“叶平”老师所授课程的学生中,成绩最高的学生姓名及其成绩select Student.Sname,scorefrom Student,SC,Course C,Teacherwhere Student.S#=SC.S# and SC.C#=C.C# and C.T#=Teacher.T# and Teacher.Tname='叶平' and SC.score=(select max(score)from SC whereC#=C.C# );41、查询各个课程及相应的选修人数select count(*) from sc group by C#;42、查询不同课程成绩相同的学生的学号、课程号、学生成绩select distinct A.S#,B.score from SC A ,SC B where A.Score=B.Score and A.C# <>B.C# ;43、查询每门功成绩最好的前两名SELECT t1.S# as 学生ID,t1.C# as 课程ID,Score as 分数FROM SC t1WHERE score IN (SELECT TOP 2 scoreFROM SCWHERE t1.C#= C#ORDER BY score DESC)ORDER BY t1.C#;44、统计每门课程的学生选修人数(超过人的课程才统计)。
一、基础1、说明:创建数据库CREATE DATABASE database-name2、说明:删除数据库drop database dbname3、说明:备份sql server--- 创建备份数据的 deviceUSE masterEXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1. dat'--- 开始备份BACKUP DATABASE pubs TO testBack4、说明:创建新表create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..)根据已有的表创建新表:A:create table tab_new like tab_old (使用旧表创建新表)B:create table tab_new as select col1,col2… from tab_old definition only5、说明:删除新表drop table tabname6、说明:增加一个列Alter table tabname add column col type注:列增加后将不能删除。
DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。
7、说明:添加主键:Alter table tabname add primary key(col)说明:删除主键: Alter table tabname drop primary key(col)8、说明:创建索引:create [unique] index idxname on tabname(col….) 删除索引:drop index idxname注:索引是不可更改的,想更改必须删除重新建。
9、说明:创建视图:create view viewname as select statement删除视图:drop view viewname10、说明:几个简单的基本的sql语句选择:select * from table1 where 范围插入:insert into table1(field1,field2) values(value1,value2)删除:delete from table1 where 范围更新:update table1 set field1=value1 where 范围查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料!排序:select * from table1 order by field1,field2 [desc]总数:select count as totalcount from table1求和:select sum(field1) as sumvalue from table1平均:select avg(field1) as avgvalue from table1最大:select max(field1) as maxvalue from table1最小:select min(field1) as minvalue from table111、说明:几个高级查询运算词A:UNION 运算符UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。
使用动态SQL语句实现简单的行列转置(动态产生列)要实现简单的行列转置,并动态产生列,可以使用动态SQL语句来实现。
首先,假设有一个表格`table1`,有`id`、`name`和`value`三个字段,我们要将`name`字段的值转换为列名,并将`value`字段的值填充到相应的位置。
动态SQL语句的实现步骤如下:
1. 使用`GROUP_CONCAT`函数将`name`字段的值连接成一个字符串,作为动态列名。
2.使用`CONCAT`函数拼接SQL语句,动态生成列的部分。
3. 使用`GROUP BY`子句将数据按照`id`字段进行分组。
4.使用动态生成的SQL语句进行查询。
下面是实现的示例代码:
```sql
SELECT GROUP_CONCAT(DISTINCT CONCAT('MAX(IF(name = "', name, '", value, NULL)) AS "', name, '"'))
FROM table1;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
```
以上代码将会将`name`字段的值转换为列名,并将`value`字段的值填充到相应的位置,然后按照`id`字段进行分组,返回转置后的结果。
需要注意的是,动态SQL语句的生成需要使用`PREPARE`和`EXECUTE`语句,并在使用完毕后使用`DEALLOCATEPREPARE`释放资源。
--创建数据库javaBuse master;if exists(select*from sysdatabases where name='javaB')drop database javaB;create database javaB;gouse javaB;--创建学员信息表stuInfoif exists(select*from sysobjects where name='stuInfo') drop table stuInfo;gocreate table stuInfo (stuName varchar(50)not null,stuNo varchar(50)primary key check(stuNo like'S253[0-9][0-9]'),--列级stuSex varchar(10)not null check(stuSex in('男','女'))default('男'),stuAge int not null check(stuAge between15 and50), stuSeat int identity(1,1)not null check(stuSeat between 1 and 30),stuAddress text default('地址不详'))--创建学生成绩表(stuMarks)if exists(select*from sysobjects where name='stuMarks') drop table stuMarks;gocreate table stuMarks (examNo varchar(50)primary key check(examNo like 'E200507[0-9][0-9][0-9][0-9]'),stuNo varchar(50)not null check(stuNo like'S253[0-9][0-9]'),foreign key(stuNo)references stuInfo(stuNo),--表级参照完整性writtenExam int not null check(writtenExam between 0 and 100)default(0),labExam int not null check(labExam between 0 and 100)default(0))--创建学员信息表stuInfoif exists(select*from sysobjects where name='stuInfo')drop table stuInfo;gocreate table stuInfo (stuName varchar(50)not null,stuNo varchar(50)not null,stuSex varchar(10)not null,stuAge int not null,stuSeat int identity(1,1)not null,stuAddress text)--1alter table stuInfo add constraint pk1 primary key(stuNo)--alter table stuInfo drop constraint pk1--2alter table stuInfo add constraint ck1 check(stuNo like'S253[0-9][0-9]') alter table stuInfo add constraint ck2 check(stuSex in('男','女'))alter table stuInfo add constraint ck3 check(stuAge between 15 and 50) alter table stuInfo add constraint ck4 check(stuSeat between 1 and 30) --3 有错--alter table stuInfo add constraint df1 default ('男') for (stuSex)--alter table stuInfo add constraint df2 default('地址不详') (stuAddress)--创建学生成绩表(stuMarks)if exists(select*from sysobjects where name='stuMarks') drop table stuMarks;gocreate table stuMarks (examNo varchar(50)primary key check(examNo like'E200507[0-9][0-9][0-9][0-9]'),stuNo varchar(50)not null check(stuNo like'S253[0-9][0-9]'),writtenExam int check(writtenExam between 0 and 100) default(0),labExam int check(labExam between0 and100)default(0)) --4alter table stuMarks add constraint fk1 foreign key(stuNo)references stuInfo(stuNo)--5alter table stuMarks add constraint uq1 unique(examNO)--向学员信息表stuInfo插入数据----主键:stuNoINSERT INTO stuInfo(stuName,stuNo,stuSex,stuAge,stuAddress)VALUES('张秋丽','s25301','男',18,'北京海淀')INSERT INTO stuInfo(stuName,stuNo,stuSex,stuAge,stuAddress)VALUES('李斯文','s25303','女',22,'河南洛阳')INSERT INTO stuInfo(stuName,stuNo,stuSex,stuAge)VALUES('李文才','s25302','男',31)INSERT INTO stuInfo(stuName,stuNo,stuSex,stuAge,stuAddress)VALUES('欧阳俊雄','s25304','男',28,'新疆威武哈')--向学员成绩表stuMarks插入数据----主键ExamNo--外键stuNoINSERT INTO stuMarks(ExamNo,stuNo,writtenExam,LabExam)VALUES('E2005070001','s25301',80,58)INSERT INTO stuMarks(ExamNo,stuNo,writtenExam)VALUES('E2005070002','s25302',50)INSERT INTO stuMarks(ExamNo,stuNo,writtenExam,LabExam)VALUES('E2005070003','s25303',97,82)--查看数据--select*from stuInfoselect*from stuMarks--=======查询数据练习=========--1.查询两表的数据--select stuInfo.*,stuMarks.*from stuInfo,stuMarkswhere stuInfo.stuNo=stuMarks.stuNo--2.查询男学员名单--select stuName from stuInfo where stuSex='男'--3.查询笔试成绩优秀的学员情况(成绩在~100之间)--select stuName,stuInfo.stuNo,stuAge,stuSeat,stuAddressfrom stuInfo,stuMarkswhere stuInfo.stuNo=stuMarks.stuNo and writtenExam between 75 and 100--4.查询参加本次考试的学员成绩,包括学员姓名,笔试成绩,机试成绩--select stuName,writtenExam,labExamfrom stuInfo,stuMarkswhere stuInfo.stuNo=stuMarks.stuNo--5.统计笔试考试平均分和机试考试平均分--select avg(writtenExam)as'笔试平均分数','机试平均分数'=avg(labExam) from stuMarks--6.统计参加本次考试的学员人数select count(stuMarks.stuNo)as'参加本次考试的学员人数'from stuInfo,stuMarkswhere stuInfo.stuNo=stuMarks.stuNo--7.查询没有通过考试的人数(笔试或机试小于分)--select count(stuInfo.stuNo)as'没有通过考试的人数'from stuInfo,stuMarkswhere stuInfo.stuNo=stuMarks.stuNo and(writtenExam<60 or labExam<60)--8.查询学员成绩,显示学号,笔试成绩,机试成绩,平均分--select stuInfo.stuNo,writtenExam,labExam,'此学员平均分数'=(writtenExam+labExam)/2from stuInfo,stuMarkswhere stuInfo.stuNo=stuMarks.stuNo--9.排名次(按平均分从高到低排序),显示学号、平均分--select stuNo,'此学员平均分数'=(writtenExam+labExam)/2from stuMarksorder by'此学员平均分数'desc--10.排名次(按平均分从高到低排序),显示姓名,笔试成绩,机试成绩,平均分-- select stuName,writtenExam,labExam,'此学员平均分数'=(writtenExam+labExam)/2from stuInfo,stuMarkswhere stuInfo.stuNo=stuMarks.stuNoorder by'此学员平均分数'desc--11.根据平均分,显示前两名信息,包括姓名、笔试成绩、机试成绩、平均分--select top 2 stuName,writtenExam,labExam,'此学员平均分数'=(writtenExam+labExam)/2from stuInfo,stuMarkswhere stuInfo.stuNo=stuMarks.stuNoorder by'此学员平均分数'desc/*=======修改数据练习=========*/--都提分----100分封顶(加分后超过分的,按分计算)--update stuMarks set writtenExam=100 where writtenExam>95update stuMarks set labExam=100 where labExam>95update stuMarks set writtenExam=writtenExam+5 where writtenExam<=95 update stuMarks set labExam=labExam+5 where labExam<=95select*from stuMarksClass.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");conn = DriverManager.getConnection("jdbc:sqlserver://localhost:1433;DatabaseName=javab","sa", "361552");Class.forName("com.mysql.jdbc.Driver");conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/javab", "root", "361552");。