eviews面板大数据实例分析报告(包会)
- 格式:doc
- 大小:782.50 KB
- 文档页数:33

Eviews实验报告
本次实验使用Eviews对数据进行了分析和建模,主要分为以下几个部分:
一、数据预处理
1. 数据清洗:对数据进行了初步的检查和清洗,处理了数据中的缺失值和异常值;
2. 数据变换:对原始数据进行了对数化处理,使其符合正态分布。
二、数据分析
1. 描述性统计:通过统计均值、标准差、相关系数等指标,对数据进行了分析和描述;
2. 单因素分析:使用单因素方差分析对不同自变量与因变量之间的关系进行了检验。
三、建模分析
1. 模型选择:根据变量相关性和变量显著性等因素,最终选择了一组自变量,建立了多元线性回归模型;
2. 模型检验:对建立的模型进行了残差分析,验证了模型的可靠性和稳定性;
3. 预测分析:利用建立的模型对新数据进行了预测,并进行了模型预测精度的评估。
四、实验结论
通过Eviews的分析和建模,得出了以下结论:
1. 数据清洗和变换可以提高数据分析的准确性和可靠性;
2. 描述性统计和单因素分析可以为建模提供有用的参考和决策依据;
3. 多元线性回归模型可以较好地解释自变量与因变量之间的关系,并可进行预测和决策分析。
综上所述,本次实验通过Eviews软件对数据进行了分析和建模,得出了有关数据的一些重要结论,为后续数据分析和决策提供了基础和支持。


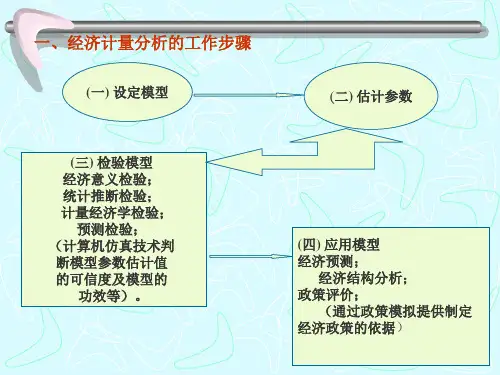

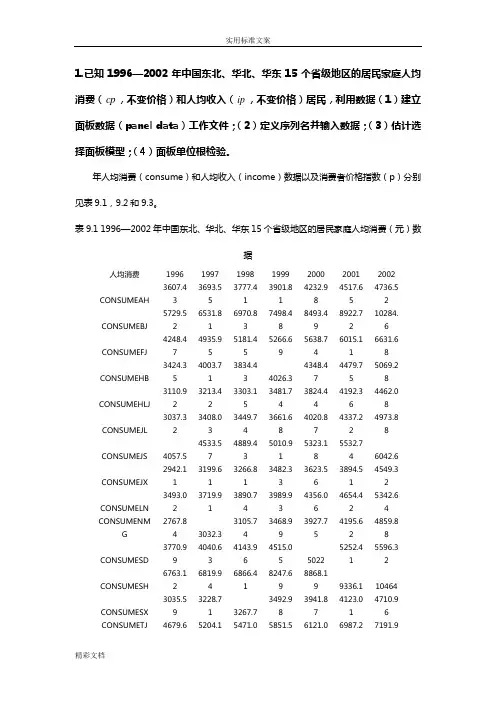
1.已知1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp,不变价格)和人均收入(ip,不变价格)居民,利用数据(1)建立面板数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。
年人均消费(consume)和人均收入(income)数据以及消费者价格指数(p)分别见表9.1,9.2和9.3。
表9.1 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数据人均消费1996 1997 1998 1999 2000 2001 2002CONSUMEAH 3607.433693.553777.413901.814232.984517.654736.52CONSUMEBJ 5729.526531.816970.837498.488493.498922.7210284.6CONSUMEFJ 4248.474935.955181.455266.695638.746015.116631.68CONSUMEHB 3424.354003.713834.43 4026.34348.474479.755069.28CONSUMEHLJ 3110.923213.423303.153481.743824.444192.364462.08CONSUMEJL 3037.323408.033449.743661.684020.874337.224973.88CONSUMEJS 4057.5 4533.574889.435010.915323.185532.74 6042.6CONSUMEJX 2942.113199.613266.813482.333623.563894.514549.32CONSUMELN 3493.023719.913890.743989.934356.064654.425342.64CONSUMENMG 2767.84 3032.33105.743468.993927.754195.624859.88CONSUMESD 3770.994040.634143.964515.05 50225252.415596.32CONSUMESH 6763.126819.946866.418247.698868.19 9336.1 10464CONSUMESX 3035.593228.71 3267.73492.983941.874123.014710.96CONSUMETJ 4679.65204.15471.05851.56121.06987.27191.91 5 1 3 42 6CONSUMEZJ 5764.276170.146217.936521.547020.227952.398713.08表9.2 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均收入(元)数据人均收入1996 1997 1998 1999 2000 2001 2002INCOMEAH 4512.774599.274770.47 5064.6 5293.55 5668.8 6032.4INCOMEBJ 7332.017813.168471.98 9182.7610349.6911577.7812463.92INCOMEFJ 5172.936143.646485.63 6859.81 7432.26 8313.08 9189.36INCOMEHB 4442.814958.675084.64 5365.03 5661.16 5984.82 6679.68INCOME HLJ 3768.314090.72 4268.5 4595.14 4912.88 5425.87 6100.56INCOMEJL 3805.534190.584206.64 4480.01 4810 5340.46 6260.16INCOMEJS 5185.79 5765.26017.85 6538.2 6800.23 7375.1 8177.64INCOMEJX 3780.2 4071.324251.42 4720.58 5103.58 5506.02 6335.64INCOMELN 4207.23 4518.14617.24 4898.61 5357.79 5797.01 6524.52INCOME NMG 3431.813944.674353.02 4770.53 5129.05 5535.89 6051INCOMESD 4890.285190.795380.08 5808.96 6489.97 7101.08 7614.36INCOMESH 8178.488438.89 8773.110931.6411718.0112883.46 13249.8INCOMESX 3702.693989.924098.73 4342.61 4724.11 5391.05 6234.36INCOMETJ 5967.716608.397110.54 7649.83 8140.5 8958.7 9337.56INCOMEZJ 6955.797358.727836.76 8427.95 9279.1610464.67 11715.6表9.3 1996—2002年中国东北、华北、华东15个省级地区的消费者物价指数(1)建立面板数据工作文件首先建立工作文件。

eviews案例分析作业Eviews案例分析作业。
本次作业将使用Eviews软件进行一个实际案例的分析,以展示Eviews在实际经济数据分析中的应用。
我们选取了美国GDP(国内生产总值)和失业率的数据,来进行相关性分析和趋势预测。
首先,我们导入美国GDP和失业率的时间序列数据,并进行数据的初步观察和描述性统计分析。
通过Eviews的数据视图功能,我们可以直观地看到这两个变量的变化趋势和波动情况,从而为后续的分析提供基础。
接下来,我们将利用Eviews进行相关性分析,探讨美国GDP与失业率之间的关系。
通过Eviews的相关性分析功能,我们可以得到它们之间的相关系数,并利用散点图和回归分析来观察它们之间的线性关系。
通过这些分析,我们可以初步了解到美国GDP和失业率之间的关联程度,为后续的预测分析提供参考。
在完成相关性分析后,我们将利用Eviews进行趋势预测。
通过Eviews的时间序列分析功能,我们可以选择合适的模型对美国GDP和失业率的未来趋势进行预测。
在选择模型的过程中,我们将充分考虑数据的平稳性、季节性等特点,以确保模型的准确性和可靠性。
最终,我们将得到美国GDP和失业率未来的预测值,并进行可视化展示,以便更直观地观察它们的趋势变化。
通过本次Eviews案例分析作业,我们不仅对Eviews软件的使用有了更深入的了解,同时也对实际经济数据的分析方法有了更加清晰的认识。
Eviews作为一款专业的计量经济学软件,具有强大的数据分析和建模功能,可以帮助我们更好地理解和预测经济现象,为经济决策提供科学依据。
总之,Eviews案例分析作业不仅是对所学知识的巩固和实践,更是对实际问题的解决和预测。
通过本次作业,我们不仅提升了对Eviews软件的熟练度,更深入了解了经济数据分析的方法和技巧,为今后的学习和工作打下了坚实的基础。
希望通过这次作业的学习,能够更好地应用Eviews软件进行实际经济数据的分析和预测,为经济决策提供更加科学的支持。

e v i e w s面板数据实例分析包会修订版IBMT standardization office【IBMT5AB-IBMT08-IBMT2C-ZZT18】1.已知1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp,不变价格)和人均收入(ip,不变价格)居民,利用数据(1)建立面板数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。
年人均消费(consume)和人均收入(income)数据以及消费者价格指数(p)分别见表9.1,9.2和9.3。
表9.1 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数据199719981999200020012002人均消费1996CONSUMEAH3607.433693.553777.413901.814232.984517.654736.52 CONSUMEBJ5729.526531.816970.837498.488493.498922.7210284.6 CONSUMEFJ4248.474935.955181.455266.695638.746015.116631.68 CONSUMEHB3424.354003.713834.434026.34348.474479.755069.28 CONSUMEHLJ3110.923213.423303.153481.743824.444192.364462.08 CONSUMEJL3037.323408.033449.743661.684020.874337.224973.88CONSUMEJS4057.54533.574889.435010.915323.185532.746042.6 CONSUMEJX2942.113199.613266.813482.333623.563894.514549.32 CONSUMELN3493.023719.913890.743989.934356.064654.425342.64 CONSUMENMG2767.843032.33105.743468.993927.754195.624859.88 CONSUMESD3770.994040.634143.964515.0550225252.415596.32 CONSUMESH6763.126819.946866.418247.698868.199336.110464 CONSUMESX3035.593228.713267.73492.983941.874123.014710.96 CONSUMETJ4679.615204.155471.015851.536121.046987.227191.96 CONSUMEZJ5764.276170.146217.936521.547020.227952.398713.08表9.2 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均收入(元)数据人均收入1996199719981999200020012002INCOMEAH4512.774599.274770.475064.65293.555668.86032.4 INCOMEBJ7332.017813.168471.989182.7610349.6911577.7812463.92 INCOMEFJ5172.936143.646485.636859.817432.268313.089189.36 INCOMEHB4442.814958.675084.645365.035661.165984.826679.68 INCOMEHLJ3768.314090.724268.54595.144912.885425.876100.56 INCOMEJL3805.534190.584206.644480.0148105340.466260.16 INCOMEJS5185.795765.26017.856538.26800.237375.18177.64 INCOMEJX3780.24071.324251.424720.585103.585506.026335.64 INCOMELN4207.234518.14617.244898.615357.795797.016524.52 INCOMENMG3431.813944.674353.024770.535129.055535.896051 INCOMESD4890.285190.795380.085808.966489.977101.087614.36 INCOMESH8178.488438.898773.110931.6411718.0112883.4613249.8INCOMESX3702.693989.924098.734342.614724.115391.056234.36 INCOMETJ5967.716608.397110.547649.838140.58958.79337.56 INCOMEZJ6955.797358.727836.768427.959279.1610464.6711715.6表9.3 1996—2002年中国东北、华北、华东15个省级地区的消费者物价指数物价指数1996199719981999200020012002PAH109.9101.310097.8100.7100.599PBJ111.6105.3102.4100.6103.5103.198.2PFJ105.9101.799.799.1102.198.799.5PHB107.1103.598.498.199.7100.599PHLJ107.1104.4100.496.898.3100.899.3PJL107.2103.799.29898.6101.399.5(1)建立面板数据工作文件首先建立工作文件。
Eviews实验-面板数据模型可以建立两种Eviews工作文件:(1)混合(pool)数据型工作文件;(2)面板数据型工作文件。
根据教材第10章案例:关于酒后驾车,研究酒精税和关于酒后驾车的法律规定对交通死亡事故的效应。
美国每年有4万高速公路交通事故,约1/3涉及酒后驾车。
这个比率在饮酒高峰期会上升。
早晨1-3点25%的司机饮酒。
饮酒司机出交通事故数是不饮酒司机的13倍。
现有1982-1988年48个州共336组美国公路交通事故死亡人数与啤酒税的数据。
原始数据的excel文件为:fatality.xls或fatality.xlsx一、建立混合数据型工作文件,估计模型首先建立时间序列(年度)工作文件:Fatality_pool.wfl.建立新的对象:Eviews菜单,Object-New object-pool在窗口中输入48个州的标识(注:也可输入_1, _2……类似格式)在新建的混合数据库(Pool)窗口的工具栏中点击Sheet键(第2种路径是,点击View键,选Spreadsheet (stacked data)功能),从而打开Series List(列写序列名)窗口,定义时间序列变量“mrall? Beertax?”,其中“?”表示与marll和beertax相关的48个州标识。
点击OK键,从而打开混合数据库(Pool)窗口(图5)。
点击Edit+-键,使EViwes处于可编辑状态,用复制和粘贴的方法输入数据。
(提示:注意excel 数据中的排序)图所示为以时间为序的阵列式排列(stacked data)。
点击Order+-键,还可以变换为以截面为序的阵列式排列。
输入完成后的情形见图。
点击PoolGener可以通过公式用已有的变量生成新变量(注意:输入变量时,不要忘记带变量后缀“?”)如mrall为每万人死亡率,定义死亡人数:vfrall=10000*mrall。
建立新的页面,对1982年的数据进行分析。

中国税收增长的分析一、研究的目的要求改革开放以来,随着经济体制的改革深化和经济的快速增长,中国的财政收支状况发生了很大的变化,中央和地方的税收收入1978年为519.28亿元到2002年已增长到17636.45亿元25年间增长了33倍。
为了研究中国税收收入增长的主要原因,分析中央和地方税收收入的增长规律,预测中国税收未来的增长趋势,需要建立计量经济学模型。
影响中国税收收入增长的因素很多,但据分析主要的因素可能有:〔1〕从宏观经济看,经济整体增长是税收增长的基根源泉。
〔2〕公共财政的需求,税收收入是财政的主体,社会经济的开展和社会保障的完善等都对公共财政提出要求,因此对预算指出所表现的公共财政的需求对当年的税收收入可能有一定的影响。
〔3〕物价水平。
我国的税制结构以流转税为主,以现行价格计算的DGP等指标和和经营者收入水平都与物价水平有关。
〔4〕税收政策因素。
我国自1978年以来经历了两次大的税制改革,一次是1984—%。
但是第二次税制改革对税收的增长速度的影响不是非常大。
因此可以从以上几个方面,分析各种因素对中国税收增长的具体影响。
二、模型设定为了反映中国税收增长的全貌,选择包括中央和地方税收的‘国家财政收入’中的“各项税收〞〔简称“税收收入〞〕作为被解释变量,以反映国家税收的增长;选择“国内生产总值〔GDP〕〞作为经济整体增长水平的代表;选择中央和地方“财政支出〞作为公共财政需求的代表;选择“商品零售物价指数〞作为物价水平的代表。
由于税制改革难以量化,而且1985年以后财税体制改革对税收增长影响不是很大,可暂不考虑。
所以解释变量设定为可观测“国内生产总值〔GDP〕〞、“财政支出〞、“商品零售物价指数〞从《中国统计年鉴》收集到以下数据年份财政收入〔亿元〕Y国内生产总值(亿元〕X2财政支出〔亿元〕X3商品零售价格指数〔%)X419781979 102 1980 106 1981198219831984 717119851986 106 1987198819891990199119921993199419951996199719981999 97 200020012002设定线性回归模型为:Y i=β0+β2X2+β3X3+β4X4+μ三、参数估计利用eviews软件可以得到Y关于X2的散点图:可以看出Y和X2成线性相关关系Y关于X3的散点图:可以看出Y和X3成线性相关关系Y关于X4的散点图:Dependent Variable: YMethod: Least SquaresDate: 12/01/09 Time: 13:16Sample: 1978 2002Included observations: 25Variable Coefficient Std. Error t-Statistic Prob.CX2X3X4R-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid 1463163. Schwarz criterionLog likelihood F-statisticDurbin-Watson stat Prob(F-statistic)模型估计的结果为:Y i=+0.022067X2+X3+X4(940.6119) (0.0056) (0.0332) (8.7383)t={-2.7458} {3.9567} {21.1247} {2.7449}R2=0.997 R2=0.997 F=2717.254 df=21四、模型检验模型估计结果说明,在假定其他变量不变的情况下,当年GDP每增长1亿元,税收收入就会增长0.02207亿元;在假定其他变量不变的情况下,当年财政支出每增长1亿元,税收收入就会增长0.7021亿元;在假定其他变量不变的情况下,当零售商品物价指数上涨一个百分点,税收收入就会增长23.985亿元。
Eviews6.0面板数据操作1.数据输入1.1创建工作文档如下图操作,在”work”文本框的“work type”选择“balanced panel”,”panel specification”的”start date”和”end date”输入数据的起止期间,”wf”输入工作文档的名称,点击”OK”即跳出新建的工作文档a界面。
1.2创建新对象操作如下图。
在”new object”文本框的”type of object”选择”pool”,”name for object ”输入新对象的名称。
创建成功后的界面如下面第3张图所示。
1.3输入数据双击”workfile”界面的,跳出”pool”界面,输入个体。
一般输入方式为如下:若上海输入_sh,北京输入_bj,…。
个体输入完成后,点击该界面的键,在跳出的”series list”输入变量名称,注意变量后要加问号。
格式如下:y? x?。
点击”OK”后,跳出数据输入界面,如下面第4张图所示。
在这个界面上点击键,即可以输入或者从EXCEL处复制数据。
在输入数据后,记得保存数据。
保存操作如下:在跳出的“work”文本框选择“ok”即可,则自动保存到我的文档。
然后在“workfile”界面如下会显示保存路径:d:\my documents\a.wf1。
若要保存到自己选择的路径下面,则在保存时选择“save as”,在跳出的文本框里选择自己要保存的路径以及命名文件名称。
1.4单位根检验一般回归前要检验面板数据是否存在单位根,以检验数据的平稳性,避免伪回归,或虚假回归,确保估计的有效性。
单位根检验时要分变量检验。
(补充:网上对面板数据的单位根检验和协整检验存在不同意见,一般认为时间区间较小的面板数据无需进行这两个检验。
)1.4.1生成数据组如下图操作。
点击”make group”后在跳出的”series list”里输入要单位根检验的变量,完成后就会跳出如下图3所示的组数据。
1.已知1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp,不变价格)和人均收入(ip,不变价格)居民,利用数据(1)建立面板数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。
年人均消费(consume)和人均收入(income)数据以及消费者价格指数(p)分别见表9.1,9.2和9.3。
表9.1 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数据人均消费1996 1997 1998 1999 2000 2001 2002CONSUMEAH 3607.433693.553777.413901.814232.984517.654736.52CONSUMEBJ 5729.526531.816970.837498.488493.498922.7210284.6CONSUMEFJ 4248.474935.955181.455266.695638.746015.116631.68CONSUMEHB 3424.354003.713834.43 4026.34348.474479.755069.28CONSUMEHLJ 3110.923213.423303.153481.743824.444192.364462.08CONSUMEJL 3037.323408.033449.743661.684020.874337.224973.88CONSUMEJS 4057.5 4533.574889.435010.915323.185532.74 6042.6CONSUMEJX 2942.113199.613266.813482.333623.563894.514549.32CONSUMELN 3493.023719.913890.743989.934356.064654.425342.64CONSUMENMG 2767.84 3032.33105.743468.993927.754195.624859.88CONSUMESD 3770.994040.634143.964515.05 50225252.415596.32CONSUMESH 6763.126819.946866.418247.698868.19 9336.1 10464CONSUMESX 3035.593228.71 3267.73492.983941.874123.014710.96CONSUMETJ 4679.65204.15471.05851.56121.06987.27191.91 5 1 3 42 6CONSUMEZJ 5764.276170.146217.936521.547020.227952.398713.08表9.2 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均收入(元)数据人均收入1996 1997 1998 1999 2000 2001 2002INCOMEAH 4512.774599.274770.47 5064.6 5293.55 5668.8 6032.4INCOMEBJ 7332.017813.168471.98 9182.7610349.6911577.7812463.92INCOMEFJ 5172.936143.646485.63 6859.81 7432.26 8313.08 9189.36INCOMEHB 4442.814958.675084.64 5365.03 5661.16 5984.82 6679.68INCOME HLJ 3768.314090.72 4268.5 4595.14 4912.88 5425.87 6100.56INCOMEJL 3805.534190.584206.64 4480.01 4810 5340.46 6260.16INCOMEJS 5185.79 5765.26017.85 6538.2 6800.23 7375.1 8177.64INCOMEJX 3780.2 4071.324251.42 4720.58 5103.58 5506.02 6335.64INCOMELN 4207.23 4518.14617.24 4898.61 5357.79 5797.01 6524.52INCOME NMG 3431.813944.674353.02 4770.53 5129.05 5535.89 6051INCOMESD 4890.285190.795380.08 5808.96 6489.97 7101.08 7614.36INCOMESH 8178.488438.89 8773.110931.6411718.0112883.46 13249.8INCOMESX 3702.693989.924098.73 4342.61 4724.11 5391.05 6234.36INCOMETJ 5967.716608.397110.54 7649.83 8140.5 8958.7 9337.56INCOMEZJ 6955.797358.727836.76 8427.95 9279.1610464.67 11715.6表9.3 1996—2002年中国东北、华北、华东15个省级地区的消费者物价指数(1)建立面板数据工作文件首先建立工作文件。
打开工作文件后,过程如下:物价指数 19961997 199819992000 2001 2002PAH 109.9 101.3 100 97.8 100.7 100.5 99 PBJ 111.6 105.3 102.4100.6103.5 103.198.2 PFJ 105.9 101.7 99.799.1102.198.7 99.5PHB 107.1 103.5 98.4 98.199.7100.5 99 PHLJ 107.1 104.4 100.496.898.3100.8 99.3 PJL 107.2 103.7 99.29898.6 101.3 99.5 PJS 109.3 101.799.498.7100.1 100.899.2 PJX 108.4 102 10198.6100.399.5100.1 PLN 107.9 103.1 99.398.699.9 100 98.9 PNMG 107.6 104.5 99.399.8101.3 100.6 100.2PSD 109.6 102.8 99.499.3 100.2 101.899.3 PSH 109.2 102.8 100 101.5102.5 100 100.5 PSX 107.9 103.1 98.699.6103.999.8 98.4PTJ 109 103.1 99.598.999.6101.299.6 PZJ107.9102.899.798.810199.899.1建立面板数据库。
在窗口中输入15个不同省级地区的标识。
(2)定义序列名并输入数据产生3*15个尚未输入数据的变量名。
这样可以通过键盘输入或黏贴的方法数据数据。
(3)估计、选择面板模型打开一个pool窗口,先输入变量后缀(所要使用的变量)。
点击Estimate,打开估计窗口。
A.混合模型的估计方法左边的Common表示相同系数,即表示不同个体有相同的斜率。
得到如下输出结果:相应的表达式是:ˆ129.630.76it itCP IP =+ (2.0)(79.7)20.98,4824588r R SSE ==上式表示15个省级地区的城镇人均指出平均占收入的76%。
B.个体固定效应回归模型的估计方法将截距项选择区选Fixed effects (固定效应)得到如下输出结果:相应的表达式为:1215ˆ515.60.7036.3537.6...198.6it it CP IP D D D =+-+++ (6.3) (55) 20.99,2270386r R SSE ==其中虚拟变量1215,,...,D D D 的定义是:1,1,2,...,150,i i i D =⎧=⎨⎩如果属于第个个体,其他15个省级地区的城镇人均指出平均占收入70%。
从上面的结果可以看出北京市居民的自发性消费明显高于其他地区。
接下来用F 统计量检验是应该建立混合回归模型,还是个体固定效应回归模型。
0H :i αα=。
模型中不同个体的截距相同(真实模型为混合回归模型)。
1H :模型中不同个体的截距项i α不同(真实模型为个体固定效应回归模型)。
F 统计量定义为:()/[(1)()]()/(1)/()/()r u r u u u SSE SSE NT k NT N k SSE SSE N F SSE NT N k SSE NT N k --------==----其中r SSE 表示约束模型,即混合估计模型的残差平方和,u SSE 表示非约束模型,即个体固定效应回归模型的残差平方和。
非约束模型比约束模型多了1N -个被估参数。
所以本例中:0.05(4824588227386)/(151)8.1(14,89) 1.82270386/(105151)F F --===--f所以推翻原假设,建立个体固定效应回归模型更合理。
C.时点固定效应回归模型的估计方法 将时间选择为固定效应。
得到如下输出结果:相应的表达式为:127ˆ 2.60.78105.9134.1...93.9it it CP IP D D D =++++- (76.6) 20.987,4028843R SSE ==其中虚拟变量127,,...,D D D 的定义是:1,0,t D ⎧=⎨⎩如果属于第t 个截面,t=1996,...,2002其他D.个体随机效应回归模型估计截距项选择Random effects(个体随机效应)得到如下部分输出结果:相应的表达式是:1215ˆ345.20.72 2.6367.0...106.1it it CP IP D D D =+-+++ (68.5) 20.98,2979246R SSE ==其中虚拟变量1215,,...,D D D 的定义是:1,0,i D ⎧=⎨⎩如果属于第i 个个体,i=1,2,...,15其他接下来利用Hausman 统计量检验应该建立个体随机效应回归模型还是个体固定效应回归模型。
0H :个体效应与回归变量(it IP )无关(个体随机效应回归模型) 1H :个体效应与回归变量(it IP )相关(个体固定效应回归模型)分析过程如下:得到如下检验结果:由检验输出结果的上半部分可以看出,Hausman统计量的值是14.79,相对应的概率是0.0001,即拒接原假设,应该建立个体固定效应模型。