遗传算法优化BP神经网络权值和阈值(完整版)
- 格式:doc
- 大小:48.00 KB
- 文档页数:2

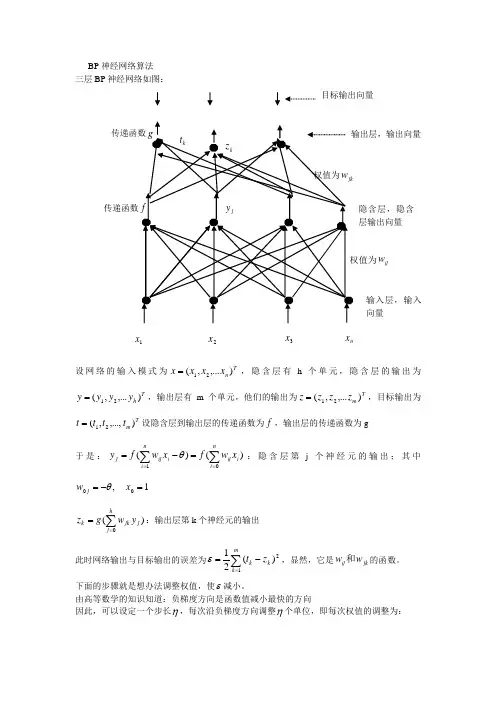
BP 神经网络算法 三层BP 神经网络如图:设网络的输入模式为Tn x x x x ),...,(21=,隐含层有h 个单元,隐含层的输出为T h y y y y ),...,(21=,输出层有m 个单元,他们的输出为T m z z z z ),...,(21=,目标输出为T m t t t t ),...,,(21=设隐含层到输出层的传递函数为f ,输出层的传递函数为g于是:)()(1∑∑===-=ni i ij ni iij j x w f xw f y θ:隐含层第j 个神经元的输出;其中1,00=-=x w j θ)(0∑==hj j jk k y w g z :输出层第k 个神经元的输出此时网络输出与目标输出的误差为∑=-=m k k k z t 12)(21ε,显然,它是jk ij w w 和的函数。
下面的步骤就是想办法调整权值,使ε减小。
由高等数学的知识知道:负梯度方向是函数值减小最快的方向因此,可以设定一个步长η,每次沿负梯度方向调整η个单位,即每次权值的调整为:1x 3x 2x n x隐含层,隐含层输出向量ij w传递函数输入层,输入向量目标输出向量pqpq w w ∂∂-=∆εη,η在神经网络中称为学习速率 可以证明:按这个方法调整,误差会逐渐减小。
BP 神经网络(反向传播)的调整顺序为: 1)先调整隐含层到输出层的权值 设k v 为输出层第k 个神经元的输入∑==hj j jkk y wv 0j k k k jkk k k k m k k k jk m k k k jk y v g z t w v v z z z t w z t w )(')()(21)(211212--=∂∂∂∂∂-=∂-=∂∂∑∑==ε -------复合函数偏导公式若取x e x f x g -+==11)()(,则)1()111(11)1()('2k k v v v v k z z ee e e u g kk k k -=+-+=+=---- 于是隐含层到输出层的权值调整迭代公式为:j k k jk jk y z z t w t w )1()()1(-+=+η2)从输入层到隐含层的权值调整迭代公式为:其中j u 为隐含层第j 个神经元的输入:∑==ni iij j xw u 0注意:隐含层第j 个神经元与输出层的各个神经元都有连接,即jy ∂∂ε涉及所有的权值ij w ,因此∑∑==--=∂∂∂∂∂-∂=∂∂m k jk k k k j k k k m k k k k j w u f z t y u u z z z t y 002)(')()(ε于是:因此从输入层到隐含层的权值调整迭代为公式为:i j ij ij x t w t w ηδ+=+)()1(ijj j j j m k k k ij m k k k ij w u u y y z t w z t w ∂∂∂∂∂-=∂-=∂∂∑∑==1212)(21)(21εi j i j m k jk k k k ij mk k k ij x x u f w u f z t w z t w δε-=--=∂-=∂∂∆==∑∑)('})('){()(21012例:下表给出了某地区公路运力的历史统计数据,请建立相应的预测模型,并对给出的2010和73.3900 3.9635 0.98802011 75.5500 4.0975 1.0268function main()clc % 清屏clear all; %清除内存以便加快运算速度close all; %关闭当前所有figure图像SamNum=20; %输入样本数量为20TestSamNum=20; %测试样本数量也是20ForcastSamNum=2; %预测样本数量为2HiddenUnitNum=8; %中间层隐节点数量取8,比工具箱程序多了1个InDim=3; %网络输入维度为3OutDim=2; %网络输出维度为2%原始数据%人数(单位:万人)sqrs=[20.55 22.44 25.37 27.13 29.45 30.10 30.96 34.06 36.42 38.09 39.13 39.99 ...41.93 44.59 47.30 52.89 55.73 56.76 59.17 60.63];%机动车数(单位:万辆)sqjdcs=[0.6 0.75 0.85 0.9 1.05 1.35 1.45 1.6 1.7 1.85 2.15 2.2 2.25 2.35 2.5 2.6...2.7 2.85 2.953.1];%公路面积(单位:万平方公里)sqglmj=[0.09 0.11 0.11 0.14 0.20 0.23 0.23 0.32 0.32 0.34 0.36 0.36 0.38 0.49 ...0.56 0.59 0.59 0.67 0.69 0.79];%公路客运量(单位:万人)glkyl=[5126 6217 7730 9145 10460 11387 12353 15750 18304 19836 21024 19490 20433 ...22598 25107 33442 36836 40548 42927 43462];%公路货运量(单位:万吨)glhyl=[1237 1379 1385 1399 1663 1714 1834 4322 8132 8936 11099 11203 10524 11115 ...13320 16762 18673 20724 20803 21804];p=[sqrs;sqjdcs;sqglmj]; %输入数据矩阵t=[glkyl;glhyl]; %目标数据矩阵[SamIn,minp,maxp,tn,mint,maxt]=premnmx(p,t); %原始样本对(输入和输出)初始化rand('state',sum(100*clock)) %依据系统时钟种子产生随机数rand是产生0到1的均匀分布,randn是产生均值为0,方差为1的正态分布rand(n)或randn(n)产生n*n阶矩阵,rand(m,n)或randn(n)产生m*n的随机数矩阵NoiseVar=0.01; %噪声强度为0.01(添加噪声的目的是为了防止网络过度拟合)Noise=NoiseVar*randn(2,SamNum); %生成噪声SamOut=tn + Noise; %将噪声添加到输出样本上TestSamIn=SamIn; %这里取输入样本与测试样本相同因为样本容量偏少TestSamOut=SamOut; %也取输出样本与测试样本相同MaxEpochs=50000; %最多训练次数为50000lr=0.035; %学习速率为0.035E0=0.65*10^(-3); %目标误差为0.65*10^(-3)W1=0.5*rand(HiddenUnitNum,InDim)-0.1; %初始化输入层与隐含层之间的权值B1=0.5*rand(HiddenUnitNum,1)-0.1; %初始化输入层与隐含层之间的阈值W2=0.5*rand(OutDim,HiddenUnitNum)-0.1; %初始化输出层与隐含层之间的权值B2=0.5*rand(OutDim,1)-0.1; %初始化输出层与隐含层之间的阈值ErrHistory=[]; %给中间变量预先占据内存for i=1:MaxEpochsHiddenOut=logsig(W1*SamIn+repmat(B1,1,SamNum)); % 隐含层网络输出NetworkOut=W2*HiddenOut+repmat(B2,1,SamNum); % 输出层网络输出Error=SamOut-NetworkOut; % 实际输出与网络输出之差SSE=sumsqr(Error) %能量函数(误差平方和)ErrHistory=[ErrHistory SSE];if SSE<E0,break, end %如果达到误差要求则跳出学习循环% 以下六行是BP网络最核心的程序% 他们是权值(阈值)依据能量函数负梯度下降原理所作的每一步动态调整量Delta2=Error;Delta1=W2'*Delta2.*HiddenOut.*(1-HiddenOut);dW2=Delta2*HiddenOut';dB2=Delta2*ones(SamNum,1);dW1=Delta1*SamIn';dB1=Delta1*ones(SamNum,1);%对输出层与隐含层之间的权值和阈值进行修正W2=W2+lr*dW2;B2=B2+lr*dB2;%对输入层与隐含层之间的权值和阈值进行修正W1=W1+lr*dW1;B1=B1+lr*dB1;endHiddenOut=logsig(W1*SamIn+repmat(B1,1,TestSamNum)); % 隐含层输出最终结果NetworkOut=W2*HiddenOut+repmat(B2,1,TestSamNum); % 输出层输出最终结果a=postmnmx(NetworkOut,mint,maxt); % 还原网络输出层的结果x=1990:2009; % 时间轴刻度newk=a(1,:); % 网络输出客运量newh=a(2,:); % 网络输出货运量figure ;subplot(2,1,1);plot(x,newk,'r-o',x,glkyl,'b--+') %绘值公路客运量对比图;legend('网络输出客运量','实际客运量');xlabel('年份');ylabel('客运量/万人');subplot(2,1,2);plot(x,newh,'r-o',x,glhyl,'b--+') %绘制公路货运量对比图;legend('网络输出货运量','实际货运量');xlabel('年份');ylabel('货运量/万吨');% 利用训练好的网络进行预测% 当用训练好的网络对新数据pnew进行预测时,也应作相应的处理pnew=[73.39 75.553.96354.09750.9880 1.0268]; %2010年和2011年的相关数据;pnewn=tramnmx(pnew,minp,maxp); %利用原始输入数据的归一化参数对新数据进行归一化;HiddenOut=logsig(W1*pnewn+repmat(B1,1,ForcastSamNum)); % 隐含层输出预测结果anewn=W2*HiddenOut+repmat(B2,1,ForcastSamNum); % 输出层输出预测结果%把网络预测得到的数据还原为原始的数量级;anew=postmnmx(anewn,mint,maxt)。


基于遗传算法的BP神经网络算法人工神经网络(Artificial Neural Network,ANN)是一种模拟人脑中神经元运作原理的数学模型。
反向传播神经网络(Back Propagation Neural Network,BPNN)是一种常用的人工神经网络模型,其训练方法是通过计算输出与期望输出之间的误差,并将误差反向传播进行网络参数的调整。
遗传算法(Genetic Algorithm,GA)是一种基于生物进化理论的优化方法,通过模拟基因遗传和进化的过程来最优解。
BP神经网络算法结合遗传算法能够提高网络的训练效果,并进一步提升算法的性能。
1.随机初始化BP神经网络的权重和阈值。
BP神经网络的训练需要初始化网络的权重和阈值,遗传算法可以随机生成初始值作为种群的个体。
2.选择适应度函数。
适应度函数用于评估每个个体的适应度程度,即个体在解决问题中的优劣程度。
对于BP神经网络,适应度函数可以选择网络的误差函数,如均方误差。
3.选择遗传算子。
遗传算子包括选择、交叉和变异操作。
选择操作根据个体的适应度确定被选中参与下一代个体的概率。
交叉操作模拟基因交换,通过交叉操作可以产生新的个体。
变异操作则模拟基因突变,通过变异操作可以增加种群的多样性。
4.根据选择的适应度函数计算种群的适应度值。
对于BP神经网络,可以使用遗传算法对初始种群进行迭代并通过BP算法进行训练,根据训练结果计算个体的适应度值。
5.根据选择的适应度值进行选择操作。
根据适应度值选择种群中的个体,并根据选择的概率生成新的种群。
6.进行交叉操作。
通过交叉操作将选定的个体进行基因交换,并生成新的个体。
7.进行变异操作。
对选定的个体进行基因突变,增加种群的多样性。
8.根据选择的适应度函数计算新种群的适应度值。
对新生成的个体进行适应度评估。
9.判断终止条件。
终止条件可以根据算法的需求进行设置,如达到指定的迭代次数或达到指定的适应度阈值。
10.重复进行步骤5至步骤9,直到满足终止条件。

利用云模型和遗传算法优化BP神经网络权值摘要:标准BP算法主要根据训练样本确定神经网络的权值,由于BP算法采用沿梯度下降的搜索算法,因而其结果对初始权值非常敏感,收敛速度慢,易陷入局部极小。
结合正态云模型云滴的随机性和稳定倾向性,以及遗传算法的全局搜索能力,收敛速度快等特性优化神经网络的权值和阈值。
分类实验结果表明,该算法比标准BP算法收敛速度快,分类正确率高。
关键词:云模型;遗传算法;标准BP算法;神经网络0 引言BP算法(Back Propogation Algorithm)是目前应用最为广泛的神经网络学习算法,但由于BP算法采用沿梯度下降的搜索算法,因而其结果对初始权值非常敏感,不同的初始权值可能导致不同的结果以及易陷入局部极小等问题。
本文结合遗传算法的高度并行、随机、自适应的全局性概率搜索以及正态云模型云滴的随机性和稳定倾向性特点优化神经网络的权值和阈值。
该算法中的交叉概率、变异概率由X条件云发生器产生。
1 优化原理先利用神经网络试探出最好的网络隐层结点数,再利用本文提出的算法调整网络的权值以及阈值,然后再用调整好的权值和阈值进行分类。
编码:对于包含一层隐藏层模式为m-n-l多层神经网络共有q=m*n+n*l+n+l个权值和阈值需要优化,其中m为输入层结点数,n 为隐藏层结点数,l为输出层结点数。
将这q个权值和阈值记为W=(W 1,W2,…,W q),采用实数编码,将行向量W看作是一条染色体,而其中每个实数W i(i=1,2,…,q)是染色体的一个基因位。
选择算子:采用轮盘赌和精英保留选择策略。
每个染色体产生后代的数目正比于它的适应度值的大小,并且每一代中染色体的总数保持不变,这种方法也称为轮盘赌选择。
假设群体的大小为n,个体A i的适应度值为f(A i),则个体A i被选择的概率P(A i)为:P(A i)=f(A i)∑ni=1f(A i)交叉算子:随机产生二串长度为q的二进制串,设有两个父代,P=(P1,P2,…,P q)以及M=(M1,M2,…,M q),采用下面的方式得到两个子代:C=(C1,C2,…,C q) 和D=(D1,D 2,…,D q),用其中的一个二进制串产生子代C,用另一个二进制串产生子代D。



基于遗传算法改进的BP神经网络加热炉控制系统参数优化摘要以加热炉控制系统为研究对象,提出了一种基于遗传算法改进的BP网络优化PID控制参数方法,并与经典的临界比例度―Ziegler-Nichols方法进行比较。
仿真结果表明该算法具有较好的控制效果。
关键词 PID控制;BP神经网络;遗传算法;参数优化1 引言由于常规PID控制具有鲁棒性好,结构简单等优点,在工业控制中得到了广泛的应用。
PID控制的基本思想是将P(偏差的比例),I(偏差的积分)和 D (偏差的微分)进线性组合构成控制器,对被控对象进行控制。
所以系统控制的优劣取决于这三个参数。
但是常规PID控制参数往往不能进行在线调整,难以适应对象的变化,另外对高阶或者多变量的强耦合过程,由于整定条件的限制,以及对象的动态特性随着环境等的变化而变化,PID参数也很难达到最优的状态。
神经网络具有自组织、自学习等优点,提出了利用BP神经网络的学习方法,对控制器参数进行在线调整,以满足控制要求。
由于BP神经网络学习过程较慢,可能导致局部极小点[2]。
本文提出了改进的BP算法,将遗传算法和BP算法结合对网络阈值和权值进行优化,避免权值和阈值陷入局部极小点。
2 加热炉的PID控制加热炉控制系统如图1所示,控制规律常采用PID控制规律。
图1 加热炉控制系统简图若加热炉具有的数学模型为:则PID控制过程箭图可以用图2表示。
其中,采用经典参数整定方法――临界比例度对上述闭环系统进行参数整定,确定PID控制器中 K p=2.259, K i=0.869, K d=0.276。
参考输入为单位阶跃信号,仿真曲线如图3所示。
图2 PID控制系统图3 Z―N整定的控制曲线仿真曲线表明,通过Z―N方法整定的参数控制效果不佳,加上PID参数不易实现在线调整,所以该方法不宜用于加热炉的在线控制。
3 基于遗传算法改进的BP神经网络PID控制器参数优化整定对于加热炉控制系统设计的神经网络自整定PID控制,它不依赖对象的模型知识,在网络结构确定之后,其控制功能能否达到要求完全取决于学习算法。


遗传算法优化神经网络-更好拟合函数1.案例背景BP神经网络是一种反向传递并且能够修正误差的多层映射函数,它通过对未知系统的输入输出参数进行学习之后,便可以联想记忆表达该系统。
但是由于BP网络是在梯度法基础上推导出来的,要求目标函数连续可导,在进化学习的过程中熟练速度慢,容易陷入局部最优,找不到全局最优值。
并且由于BP网络的权值和阀值在选择上是随机值,每次的初始值都不一样,造成每次训练学习预测的结果都有所差别。
遗传算法是一种全局搜索算法,把BP神经网络和遗传算法有机融合,充分发挥遗传算法的全局搜索能力和BP神经网络的局部搜索能力,利用遗传算法来弥补权值和阀值选择上的随机性缺陷,得到更好的预测结果。
本案例用遗传算法来优化神经网络用于标准函数预测,通过仿真实验表明该算法的有效性。
2.模型建立2.1预测函数2.2 模型建立遗传算法优化BP网络的基本原理就是用遗传算法来优化BP网络的初始权值和阀值,使优化后的BP网络能够更好的预测系统输出。
遗传算法优化BP网络主要包括种群初始化,适应度函数,交叉算子,选择算子和变异算子等。
2.3 算法模型3.编程实现3.1代码分析用matlabr2009编程实现神经网络遗传算法寻找系统极值,采用cell工具把遗传算法主函数分为以下几个部分:Contents•清空环境变量•网络结构确定•遗传算法参数初始化•迭代求解最佳初始阀值和权值•遗传算法结果分析•把最优初始阀值权值赋予网络预测•BP网络训练•BP网络预测主要的代码段分析如下:3.2结果分析采用遗传算法优化神经网络,并且用优化好的神经网络进行系统极值预测,根据测试函数是2输入1输出,所以构建的BP网络结构是2-5-1,一共去2000组函数的输入输出,用其中的1900组做训练,100组做预测。
遗传算法的基本参数为个体采用浮点数编码法,个体长度为21,交叉概率为0.4,变异概率为0.2,种群规模是20,总进化次数是50次,最后得到的遗传算法优化过程中最优个体适应度值变化如下所示:4 案例扩展4.1 网络优化方法的选择4.2 算法的局限性清空环境变量clcclear网络结构建立%读取数据load data input output%节点个数inputnum=2;hiddennum=5;outputnum=1;%训练数据和预测数据input_train=input(1:1900,:)';input_test=input(1901:2000,:)';output_train=output(1:1900)';output_test=output(1901:2000)';%选连样本输入输出数据归一化[inputn,inputps]=mapminmax(input_train);[outputn,outputps]=mapminmax(output_train);%构建网络net=newff(inputn,outputn,hiddennum);遗传算法参数初始化maxgen=50; %进化代数,即迭代次数sizepop=20; %种群规模pcross=[0.4]; %交叉概率选择,0和1之间pmutation=[0.2]; %变异概率选择,0和1之间%节点总数numsum=inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum;lenchrom=ones(1,numsum);bound=[-3*ones(numsum,1) 3*ones(numsum,1)]; %数据围%------------------------------------------------------种群初始化--------------------------------------------------------individuals=struct('fitness',zeros(1,sizepop), 'chrom',[]); %将种群信息定义为一个结构体avgfitness=[]; %每一代种群的平均适应度bestfitness=[]; %每一代种群的最佳适应度bestchrom=[]; %适应度最好的染色体%初始化种群for i=1:sizepop%随机产生一个种群individuals.chrom(i,:)=Code(lenchrom,bound); %编码(binary和grey的编码结果为一个实数,float的编码结果为一个实数向量)x=individuals.chrom(i,:);%计算适应度individuals.fitness(i)=fun(x,inputnum,hiddennum,outputnum,net,inputn, outputn); %染色体的适应度end%找最好的染色体[bestfitness bestindex]=min(individuals.fitness);bestchrom=individuals.chrom(bestindex,:); %最好的染色体avgfitness=sum(individuals.fitness)/sizepop; %染色体的平均适应度% 记录每一代进化中最好的适应度和平均适应度trace=[avgfitness bestfitness];迭代求解最佳初始阀值和权值进化开始for i=1:maxgeni% 选择individuals=Select(individuals,sizepop);avgfitness=sum(individuals.fitness)/sizepop;%交叉individuals.chrom=Cross(pcross,lenchrom,individuals.chrom,sizepop,bou nd);% 变异individuals.chrom=Mutation(pmutation,lenchrom,individuals.chrom,sizep op,i,maxgen,bound);% 计算适应度for j=1:sizepopx=individuals.chrom(j,:); %解码individuals.fitness(j)=fun(x,inputnum,hiddennum,outputnum,net,inputn, outputn);end%找到最小和最大适应度的染色体及它们在种群中的位置[newbestfitness,newbestindex]=min(individuals.fitness);[worestfitness,worestindex]=max(individuals.fitness);% 代替上一次进化中最好的染色体if bestfitness>newbestfitnessbestfitness=newbestfitness;bestchrom=individuals.chrom(newbestindex,:);endindividuals.chrom(worestindex,:)=bestchrom;individuals.fitness(worestindex)=bestfitness;avgfitness=sum(individuals.fitness)/sizepop;trace=[trace;avgfitness bestfitness]; %记录每一代进化中最好的适应度和平均适应度endi =1i =2i =3i =4i =5i =6i =7i =8i =9i =10i =11i =12i =13i =14i =15i =16i =17i =18i =19i =20i =21i =22i =23i =24i =25i =26i =27i =28i =29i =30i =31i =32i =33i =34i =35i =36i =37i =38i =39i =40i =41i =42i =43i =44i =45i =46i =47i =48i =49i =50遗传算法结果分析figure(1)[r c]=size(trace);plot([1:r]',trace(:,2),'b--');title(['适应度曲线 ''终止代数=' num2str(maxgen)]); xlabel('进化代数');ylabel('适应度');legend('平均适应度','最佳适应度');disp('适应度变量');x=bestchrom;Warning: Ignoring extra legend entries.适应度变量把最优初始阀值权值赋予网络预测%用遗传算法优化的BP网络进行值预测w1=x(1:inputnum*hiddennum);B1=x(inputnum*hiddennum+1:inputnum*hiddennum+hiddennum);w2=x(inputnum*hiddennum+hiddennum+1:inputnum*hiddennum+hiddennum+hidd ennum*outputnum);B2=x(inputnum*hiddennum+hiddennum+hiddennum*outputnum+1:inputnum*hidd ennum+hiddennum+hiddennum*outputnum+outputnum);net.iw{1,1}=reshape(w1,hiddennum,inputnum);net.lw{2,1}=reshape(w2,outputnum,hiddennum);net.b{1}=reshape(B1,hiddennum,1);net.b{2}=B2;BP网络训练%网络进化参数net.trainParam.epochs=100;net.trainParam.lr=0.1;%net.trainParam.goal=0.00001;%网络训练net=train(net,inputn,outputn);BP网络预测%数据归一化inputn_test=mapminmax('apply',input_test,inputps);an=sim(net,inputn_test);test_simu=mapminmax('reverse',an,outputps);error=test_simu-output_test;figure(2)plot(error)k=error./output_testk =Columns 1 through 9-0.0003 0.0010 0.0003 0.0001 0.0002 -0.0005 0.0003 0.0003 0.0109Columns 10 through 18-0.0007 -0.0003 0.0002 -0.0008 -0.0015 -0.0002 0.0011 0.0002 0.0004Columns 19 through 270.0002 0.0003 -0.0000 0.0000 -0.0004 -0.0004 0.0005 0.0001 0.0023Columns 28 through 36-0.0000 -0.0003 0.0000 -0.0005 -0.0002 0.0003 -0.0002 -0.0002 0.0001Columns 37 through 450.0001 0.0002 0.0002 0.0011 -0.0004 -0.0006 0.0002 0.0000 0.0000Columns 46 through 540.0001 0.0001 0.0000 -0.0001 0.0016 0.0002 -0.0003 -0.0000 -0.0000Columns 55 through 630.0000 0.0003 -0.0004 0.0001 0.0002 0.0002 0.0002 0.0000 0.0002Columns 64 through 720.0002 -0.0001 0.0003 0.0005 0.0002 -0.0003 -0.0001 -0.0000 0.0002Columns 73 through 810.0000 -0.0002 -0.0002 0.0002 -0.0000 -0.0003 0.0001 -0.0001 0.0006Columns 82 through 90-0.0006 0.0003 0.0068 -0.0005 0.0001 -0.0001 -0.0001 -0.0010 -0.0002Columns 91 through 990.0001 0.0002 -0.0000 0.0003 0.0000 0.0000 -0.0003 -0.0001 0.0003Column 100-0.0004。

遗传算法优化的BP神经⽹络建模【精品毕业设计】(完整版)遗传算法优化的BP神经⽹络建模⼗⼀⽉匆匆过去,每天依然在忙碌着与⽂档相关的东西,在寒假前⼀个多⽉⾥,努⼒做好⼿头上的事的前提下多学习专业知识,依然是坚持学习与素质提⾼并重,依然是坚持锻炼⾝体,为明年找⼯作打下基础。
遗传算法优化的BP神经⽹络建模借鉴别⼈的程序做出的仿真,最近才有时间整理。
⽬标:对y=x1^2+x2^2⾮线性系统进⾏建模,⽤1500组数据对⽹络进⾏构建⽹络,500组数据测试⽹络。
由于BP神经⽹络初始神经元之间的权值和阈值⼀般随机选择,因此容易陷⼊局部最⼩值。
本⽅法使⽤遗传算法优化初始神经元之间的权值和阈值,并对⽐使⽤遗传算法前后的效果。
步骤:未经遗传算法优化的BP神经⽹络建模1、随机⽣成2000组两维随机数(x1,x2),并计算对应的输出y=x1^2+x2^2,前1500组数据作为训练数据input_train,后500组数据作为测试数据input_test。
并将数据存储在data中待遗传算法中使⽤相同的数据。
2、数据预处理:归⼀化处理。
3、构建BP神经⽹络的隐层数,次数,步长,⽬标。
4、使⽤训练数据input_train训练BP神经⽹络net。
5、⽤测试数据input_test测试神经⽹络,并将预测的数据反归⼀化处理。
6、分析预测数据与期望数据之间的误差。
遗传算法优化的BP神经⽹络建模1、读取前⾯步骤中保存的数据data;2、对数据进⾏归⼀化处理;3、设置隐层数⽬;4、初始化进化次数,种群规模,交叉概率,变异概率5、对种群进⾏实数编码,并将预测数据与期望数据之间的误差作为适应度函数;6、循环进⾏选择、交叉、变异、计算适应度操作,直到达到进化次数,得到最优的初始权值和阈值;7、将得到最佳初始权值和阈值来构建BP神经⽹络;8、使⽤训练数据input_train训练BP神经⽹络net;9、⽤测试数据input_test测试神经⽹络,并将预测的数据反归⼀化处理;10、分析预测数据与期望数据之间的误差。
function Val=de_code(x)% 全局变量声明global S P_train T_train P_test T_test mint maxtglobal p t r s s1 s2% 数据提取x=x(:,1:S);[m,n]=find(x==1);p_train=zeros(size(n,2),size(T_train,2));p_test=zeros(size(n,2),size(T_test,2));for i=1:length(n)p_train(i,:)=P_train(n(i),:);p_test(i,:)=P_test(n(i),:);endt_train=T_train;p=p_train;t=t_train;% 遗传算法优化BP网络权值和阈值r=size(p,1);s2=size(t,1);s=r*s1+s1*s2+s1+s2;aa=ones(s,1)*[-1,1];popu=20; % 种群规模initPpp=initializega(popu,aa,'gabpEval'); % 初始化种群gen=100; % 遗传代数% 调用GAOT工具箱,其中目标函数定义为gabpEvalx=ga(aa,'gabpEval',[],initPpp,[1e-6 1 0],'maxGenTerm',gen,...'normGeomSelect',0.09,'arithXover',2,'nonUnifMutation',[2 gen 3]); % 创建BP网络net=newff(minmax(p_train),[s1,1],{'tansig','purelin'},'trainlm'); % 将优化得到的权值和阈值赋值给BP网络[W1,B1,W2,B2]=gadecod(x);net.IW{1,1}=W1;net.LW{2,1}=W2;net.b{1}=B1;net.b{2}=B2;% 设置训练参数net.trainParam.epochs=1000;net.trainParam.show=10;net.trainParam.goal=0.1;net.trainParam.lr=0.1;net.trainParam.showwindow=0;% 训练网络net=train(net,p_train,t_train);% 仿真测试tn_sim=sim(net,p_test);% 反归一化t_sim=postmnmx(tn_sim,mint,maxt);% 计算均方误差SE=sse(t_sim-T_test);% 计算适应度函数值Val=1/SE;endfunction [sol,Val]=fitness(sol,options)global Sfor i=1:Sx(i)=sol(i);endVal=de_code(x);end%% 遗传算法的优化计算——输入自变量降维%%% 清空环境变量clear allclcwarning off%% 声明全局变量global P_train T_train P_test T_test mint maxt S s1 S=30;s1=50;%% 导入数据load data.mata=randperm(569);Train=data(a(1:500),:);Test=data(a(501:end),:);% 训练数据P_train=Train(:,3:end)';T_train=Train(:,2)';% 测试数据P_test=Test(:,3:end)';T_test=Test(:,2)';% 显示实验条件total_B=length(find(data(:,2)==1));total_M=length(find(data(:,2)==2));count_B=length(find(T_train==1));count_M=length(find(T_train==2));number_B=length(find(T_test==1));number_M=length(find(T_test==2));disp('实验条件为:');disp(['病例总数:' num2str(569)...' 良性:' num2str(total_B)...' 恶性:' num2str(total_M)]);disp(['训练集病例总数:' num2str(500)...' 良性:' num2str(count_B)...' 恶性:' num2str(count_M)]);disp(['测试集病例总数:' num2str(69)...' 良性:' num2str(number_B)...' 恶性:' num2str(number_M)]);%% 数据归一化[P_train,minp,maxp,T_train,mint,maxt]=premnmx(P_train,T_train);P_test=tramnmx(P_test,minp,maxp);%% 创建单BP网络t=cputime;net_bp=newff(minmax(P_train),[s1,1],{'tansig','purelin'},'trainlm'); % 设置训练参数net_bp.trainParam.epochs=1000;net_bp.trainParam.show=10;net_bp.trainParam.goal=0.1;net_bp.trainParam.lr=0.1;net_bp.trainParam.showwindow=0;%% 训练单BP网络net_bp=train(net_bp,P_train,T_train);%% 仿真测试单BP网络tn_bp_sim=sim(net_bp,P_test);% 反归一化T_bp_sim=postmnmx(tn_bp_sim,mint,maxt);e=cputime-t;T_bp_sim(T_bp_sim>1.5)=2;T_bp_sim(T_bp_sim<1.5)=1;result_bp=[T_bp_sim' T_test'];%% 结果显示(单BP网络)number_B_sim=length(find(T_bp_sim==1 & T_test==1));number_M_sim=length(find(T_bp_sim==2 &T_test==2));disp('(1)BP网络的测试结果为:');disp(['良性乳腺肿瘤确诊:' num2str(number_B_sim)...' 误诊:' num2str(number_B-number_B_sim)...' 确诊率p1=' num2str(number_B_sim/number_B*100) '%']);disp(['恶性乳腺肿瘤确诊:' num2str(number_M_sim)...' 误诊:' num2str(number_M-number_M_sim)...' 确诊率p2=' num2str(number_M_sim/number_M*100) '%']);disp(['建模时间为:' num2str(e) 's'] );%% 遗传算法优化popu=20;bounds=ones(S,1)*[0,1];% 产生初始种群% initPop=crtbp(popu,S);initPop=randint(popu,S,[0 1]);% 计算初始种群适应度initFit=zeros(popu,1);for i=1:size(initPop,1)initFit(i)=de_code(initPop(i,:));endinitPop=[initPop initFit];gen=100;% 优化计算[X,EndPop,BPop,Trace]=ga(bounds,'fitness',[],initPop,[1e-6 10],'maxGenTerm',...gen,'normGeomSelect',0.09,'simpleXover',2,'boundaryMutation',[2 gen 3]);[m,n]=find(X==1);disp(['优化筛选后的输入自变量编号为:' num2str(n)]);% 绘制适应度函数进化曲线figureplot(Trace(:,1),Trace(:,3),'r:')hold onplot(Trace(:,1),Trace(:,2),'b')xlabel('进化代数')ylabel('适应度函数')title('适应度函数进化曲线')legend('平均适应度函数','最佳适应度函数')xlim([1 gen])%% 新训练集/测试集数据提取p_train=zeros(size(n,2),size(T_train,2));p_test=zeros(size(n,2),size(T_test,2));for i=1:length(n)p_train(i,:)=P_train(n(i),:);p_test(i,:)=P_test(n(i),:);endt_train=T_train;%% 创建优化BP网络t=cputime;net_ga=newff(minmax(p_train),[s1,1],{'tansig','purelin'},'trainlm'); % 训练参数设置net_ga.trainParam.epochs=1000;net_ga.trainParam.show=10;net_ga.trainParam.goal=0.1;net_ga.trainParam.lr=0.1;net_ga.trainParam.showwindow=0;%% 训练优化BP网络net_ga=train(net_ga,p_train,t_train);%% 仿真测试优化BP网络tn_ga_sim=sim(net_ga,p_test);% 反归一化T_ga_sim=postmnmx(tn_ga_sim,mint,maxt);e=cputime-t;T_ga_sim(T_ga_sim>1.5)=2;T_ga_sim(T_ga_sim<1.5)=1;result_ga=[T_ga_sim' T_test'];%% 结果显示(优化BP网络)number_b_sim=length(find(T_ga_sim==1 & T_test==1));number_m_sim=length(find(T_ga_sim==2 &T_test==2));disp('(2)优化BP网络的测试结果为:');disp(['良性乳腺肿瘤确诊:' num2str(number_b_sim)...' 误诊:' num2str(number_B-number_b_sim)...' 确诊率p1=' num2str(number_b_sim/number_B*100) '%']);disp(['恶性乳腺肿瘤确诊:' num2str(number_m_sim)...' 误诊:' num2str(number_M-number_m_sim)...' 确诊率p2=' num2str(number_m_sim/number_M*100) '%']);disp(['建模时间为:' num2str(e) 's'] );%%%% <html>% <table align="center" > <tr> <td align="center"><font size="2">版权所有:</font><a% href="/">Matlab中文论坛</a> <script % src="/stat.php?id=971931&web_id=971931&show=pic" language="JavaScript" ></script> </td> </tr></table>% </html>%。
编号:审定成绩:重庆邮电大学毕业设计(论文)设计(论文)题目:基于遗传算法的BP神经网络的优化问题研究学院名称:学生姓名:专业:班级:学号:指导教师:答辩组负责人:填表时间:2010年06月重庆邮电大学教务处制摘要本文的主要研究工作如下:1、介绍了遗传算法的起源、发展和应用,阐述了遗传算法的基本操作,基本原理和遗传算法的特点。
2、介绍了人工神经网络的发展,基本原理,BP神经网络的结构以及BP算法。
3、利用遗传算法全局搜索能力强的特点与人工神经网络模型学习能力强的特点,把遗传算法用于神经网络初始权重的优化,设计出混合GA-BP算法,可以在一定程度上克服神经网络模型训练中普遍存在的局部极小点问题。
4、对某型导弹测试设备故障诊断建立神经网络,用GA直接训练BP神经网络权值,然后与纯BP算法相比较。
再用改进的GA-BP算法进行神经网络训练和检验,运用Matlab软件进行仿真,结果表明,用改进的GA-BP算法优化神经网络无论从收敛速度、误差及精度都明显高于未进行优化的BP神经网络,将两者结合从而得到比现有学习算法更好的学习效果。
【关键词】神经网络BP算法遗传算法ABSTRACTThe main research work is as follows:1. Describing the origin of the genetic algorithm, development and application, explain the basic operations of genetic algorithm, the basic principles and characteristics of genetic algorithms.2. Describing the development of artificial neural network, the basic principle, BP neural network structure and BP.3. Using the genetic algorithm global search capability of the characteristics and learning ability of artificial neural network model with strong features, the genetic algorithm for neural network initial weights of the optimization, design hybrid GA-BP algorithm, to a certain extent, overcome nerves ubiquitous network model training local minimum problem.4. A missile test on the fault diagnosis of neural network, trained with the GA directly to BP neural network weights, and then compared with the pure BP algorithm. Then the improved GA-BP algorithm neural network training and testing, use of Matlab software simulation results show that the improved GA-BP algorithm to optimize neural network in terms of convergence rate, error and accuracy were significantly higher than optimized BP neural network, a combination of both to be better than existing learning algorithm learning.Key words:neural network back-propagation algorithms genetic algorithms目录第一章绪论 (1)1.1 遗传算法的起源 (1)1.2 遗传算法的发展和应用 (1)1.2.1 遗传算法的发展过程 (1)1.2.2 遗传算法的应用领域 (2)1.3 基于遗传算法的BP神经网络 (3)1.4 本章小结 (4)第二章遗传算法 (5)2.1 遗传算法基本操作 (5)2.1.1 选择(Selection) (5)2.1.2 交叉(Crossover) (6)2.1.3 变异(Mutation) (7)2.2 遗传算法基本思想 (8)2.3 遗传算法的特点 (9)2.3.1 常规的寻优算法 (9)2.3.2 遗传算法与常规寻优算法的比较 (10)2.4 本章小结 (11)第三章神经网络 (12)3.1 人工神经网络发展 (12)3.2 神经网络基本原理 (12)3.2.1 神经元模型 (12)3.2.2 神经网络结构及工作方式 (14)3.2.3 神经网络原理概要 (15)3.3 BP神经网络 (15)3.4 本章小结 (21)第四章遗传算法优化BP神经网络 (22)4.1 遗传算法优化神经网络概述 (22)4.1.1 用遗传算法优化神经网络结构 (22)4.1.2 用遗传算法优化神经网络连接权值 (22)4.2 GA-BP优化方案及算法实现 (23)4.3 GA-BP仿真实现 (24)4.3.1 用GA直接训练BP网络的权值算法 (25)4.3.2 纯BP算法 (26)4.3.3 GA训练BP网络的权值与纯BP算法的比较 (28)4.3.4 混合GA-BP算法 (28)4.4 本章小结 (31)结论 (32)致谢 (33)参考文献 (34)附录 (35)1 英文原文 (35)2 英文翻译 (42)3 源程序 (47)第一章绪论1.1 遗传算法的起源从生物学上看,生物个体是由细胞组成的,而细胞则主要由细胞膜、细胞质、和细胞核构成。
BP 神经网络原理2。
1 基本BP 算法公式推导基本BP 算法包括两个方面:信号的前向传播和误差的反向传播.即计算实际输出时按从输入到输出的方向进行,而权值和阈值的修正从输出到输入的方向进行.图2—1 BP 网络结构Fig.2-1 Structure of BP network图中:jx 表示输入层第j 个节点的输入,j =1,…,M ;ijw 表示隐含层第i 个节点到输入层第j 个节点之间的权值;iθ表示隐含层第i 个节点的阈值;()x φ表示隐含层的激励函数;ki w 表示输出层第k 个节点到隐含层第i 个节点之间的权值,i =1,…,q ;ka 表示输出层第k 个节点的阈值,k =1,…,L ; ()x ψ表示输出层的激励函数;ko 表示输出层第k 个节点的输出.(1)信号的前向传播过程 隐含层第i 个节点的输入net i :1Mi ij j ij net w x θ==+∑ (3—1)隐含层第i 个节点的输出y i :1()()Mi i ij j i j y net w x φφθ===+∑ (3-2)输出层第k 个节点的输入net k :111()qqMk ki i k ki ij j i ki i j net w y a w w x a φθ====+=++∑∑∑ (3—3)输出层第k 个节点的输出o k :111()()()qq M k k ki i k ki ij j i k i i j o net w y a w w x a ψψψφθ===⎛⎫==+=++ ⎪⎝⎭∑∑∑ (3—4)(2)误差的反向传播过程误差的反向传播,即首先由输出层开始逐层计算各层神经元的输出误差,然后根据误差梯度下降法来调节各层的权值和阈值,使修改后的网络的最终输出能接近期望值。
对于每一个样本p 的二次型误差准则函数为E p :211()2Lp k k k E T o ==-∑ (3—5)系统对P 个训练样本的总误差准则函数为:2111()2P Lp p k k p k E T o ===-∑∑ (3—6)根据误差梯度下降法依次修正输出层权值的修正量Δw ki ,输出层阈值的修正量Δa k ,隐含层权值的修正量Δw ij ,隐含层阈值的修正量i θ∆。
根据他人的代码,稍微改进后,并附上个人对代码的理解情况。
采用遗传算法(GA)对BP网络的权值进行优化。
其思路如下:(1)根据BP的输入值和目标值,确定好BP网络的输入层单元数、隐层单元数(本例只处理1个隐层的情况;多个隐层的方法类似,主要是在构造GA种群基因时有所差异)、以及输出层的单元个数。
(2)根据BP网络的各层单元数来确定其输入层与隐层之间的权值w12,和隐层输出值b1,以及隐层到输出层的权值w23,和输出层输出b2。
这四个值各个元素的组合就组成了一个基因,即根据他们来确定基因长度。
这一步非常重要!可根据以下代码进行理解。
% 权值矩阵分配% 输入到隐层用w_he表示,3x4,3表示输入层个数,4表示输出层个数% w_he=[chrom(i,1) chrom(i,5) chrom(i,9) chrom(i,13);% chrom(i,2) chrom(i,6) chrom(i,10) chrom(i,14);% chrom(i,3) chrom(i,7) chrom(i,11) chrom(i,15)];%以下for循环的作用是将某个基因,分别转换为bp网络所对应的权值或输出值。
% 其中chrom(i,:)表示第i个基因的所有元素% in_num表述输入层单元个数% n表示基本的元素个数% w_he表示输入层到输出层权值;w_out表示因此到输出层的权值% b_he表示隐层输出向量;b_out表示输出层的输出向量。
for j=1:nw_he(:,j)=chrom(i,(j-1)*(in_num+1)+1:j*(in_num+1)-1);w_out(j)=chrom(i,(in_num+1)*n+j);b_he(j)=chrom(i,(in_num+1)*j);endb_out=chrom(i,len);% 隐层到输出层用w_out表示,4x1% w_out=[chrom(i,17) chrom(i,18) chrom(i,19) chrom(i,20)];% b_he=[chrom(i,4) chrom(i,8) chrom(i,12) chrom(i,16)];% b_out=chrom(i,21);(3)确定好权值与基因的对应关系后。
/viewthread.php?tid= 50653&extra=&highlight=%E9%81%97%E4%BC%A0%E7% AE%97%E6%B3%95&page=1
Matlab遗传算法优化神经网络的例子(已调试成功)最近论坛里问到用遗传算法优化神经网络问题的人很多,而且论坛里有很多这方面的代码。
但可惜的是所有代码都或多或少有些错误!最郁闷的莫过于只有发帖寻求问题答案的探索者,却很少有对问题进行解答的victor。
本人在论坛里看到不少会员对能运行成功的遗传算法优化神经网络例子的需求是多么急切,我也深有感触!现把调试成功的一个例子贴出来,供大家参考!(本例子是基于一篇硕士论文里的代码为蓝本改编的,此处就不再注明作者了。
)遗传算法优化bp.rar (3.34 KB)
注:该代码是由会员“书童”耗费了一整天的时间调试成功的,在此再次对我们的“书童”同学乐于助人的高尚品德致敬,并对其深表感谢!PS:参考会员“ilovexyq”意见,先对其做以补充。
该网络为遗传算法
优化bp的一个典型例子,输入为7,输出为7,隐层为25。
该网络输入输出数据就是为了说明问题而随便加的,没有实际意义。
如用于自己的实际问题,把数据替换并根据需要改一下网络结构就行了。
PS:如有问题,请先阅读此贴:
/thread-52587-1-1.html###
[本帖最后由 yuthreestone 于 2009-10-15 10:52 编辑]
搜索更多相关主题的帖子: 调试例子算法Matlab神经网络
/thread-52587-1-1.html
遗传算法优化BP神经网络权值和阈值(完整版)
会员renjia前一段时间分享的程序,地址如下:
/viewthread.php?tid=50653&extra=&highlight=% E9%81%97%E4%BC%A0%E7%AE%97%E6%B3%95&page=1:
(1)renjia提供的程序存在一些小错误,主要是设计的bp网络是两个隐含层,但编码的时候只有一个隐含层。
修改后的程序将bp改成了单隐层以确保一致;(2)很多会员不知道该如何运行程序,各个m文件之间的关系弄不清楚。
修改后的程序共包含三个m文件:
其中,主程序为ga_bp.m,适应度函数为gabpEval.m,编解码子函数为gadecod.m 注意:使用前需安装gaot工具箱(见附件),上述三个文件需放在同一文件夹中且将该文件夹设置为当前工作路径。
运行程序时只需运行主程序ga_bp.m即可。
(3)此程序仅为示例,针对其他的问题,只需将数据修改即可,但需注意变量名保持一致,尤其是全局变量修改时(在gadecod.m和gabpEval.m中也要修改)(4)gaot工具箱如何安装?
点击file选择set path,在弹出的对话框中选择add folder,将gaot文件夹添加进去,然后点击save保存即可。