基于二级Hash的快速最长匹配分词算法
- 格式:pdf
- 大小:317.03 KB
- 文档页数:5



哈希匹配算法哈希匹配算法是一种常用的字符串匹配算法,它通过将字符串映射为一个固定长度的哈希值来进行匹配。
在实际应用中,哈希匹配算法被广泛用于字符串匹配、模式匹配、数据索引等领域。
一、哈希匹配算法的基本原理哈希匹配算法的基本原理是将字符串通过一个哈希函数转换为一个唯一的哈希值,然后将这个哈希值与其他字符串进行比较,从而实现字符串匹配的功能。
哈希函数的设计非常重要,它应该具备以下特点:1. 输入相同的字符串,哈希函数应该返回相同的哈希值;2. 输入不同的字符串,哈希函数应该返回不同的哈希值。
1. 字符串匹配:在文本处理、搜索引擎等领域,哈希匹配算法常被用于字符串匹配。
通过将待匹配的字符串和已有的字符串进行哈希映射,可以快速地找到匹配的结果。
2. 模式匹配:在字符串处理、编译原理等领域,哈希匹配算法被用于模式匹配。
通过将模式串和待匹配的字符串进行哈希映射,可以高效地找到模式串在待匹配字符串中的位置。
3. 数据索引:在数据库、搜索引擎等领域,哈希匹配算法被用于数据索引。
通过将数据的关键字进行哈希映射,可以快速地找到对应的数据项。
三、哈希匹配算法的优缺点1. 优点:(1)高效性:哈希匹配算法通过哈希映射的方式进行匹配,能够快速定位到待匹配字符串的位置,从而提高匹配效率。
(2)灵活性:哈希匹配算法可以根据实际需求设计不同的哈希函数,适应不同的应用场景。
(3)可扩展性:哈希匹配算法可以通过调整哈希函数的参数来适应不同规模的数据集。
2. 缺点:(1)冲突问题:由于哈希函数的映射是将一个无限的输入域映射到一个有限的输出域,所以在实际应用中,哈希函数可能会出现冲突,导致多个不同的字符串映射到同一个哈希值上。
(2)哈希函数设计困难:设计一个好的哈希函数是非常困难的,需要考虑多个因素,并且需要保证输入相同的字符串一定能够得到相同的哈希值,输入不同的字符串一定能够得到不同的哈希值。
四、哈希匹配算法的改进方法1. 拉链法:当哈希函数出现冲突时,可以使用拉链法来解决。
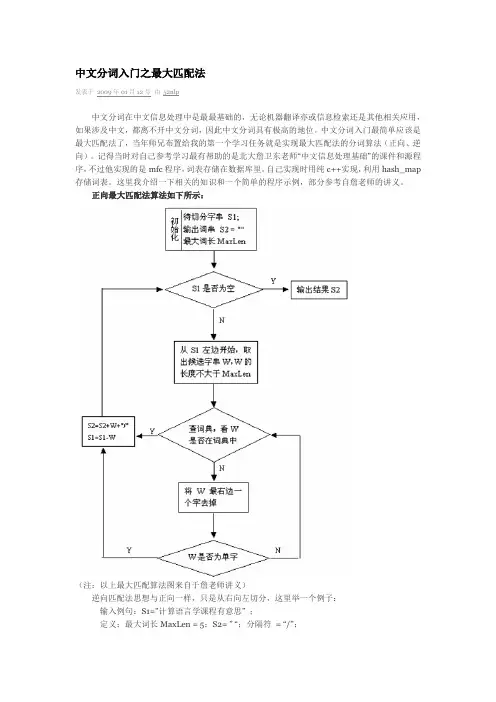
中文分词入门之最大匹配法发表于2009年01月12号由52nlp中文分词在中文信息处理中是最最基础的,无论机器翻译亦或信息检索还是其他相关应用,如果涉及中文,都离不开中文分词,因此中文分词具有极高的地位。
中文分词入门最简单应该是最大匹配法了,当年师兄布置给我的第一个学习任务就是实现最大匹配法的分词算法(正向、逆向)。
记得当时对自己参考学习最有帮助的是北大詹卫东老师“中文信息处理基础”的课件和源程序,不过他实现的是mfc程序,词表存储在数据库里。
自己实现时用纯c++实现,利用hash_map 存储词表。
这里我介绍一下相关的知识和一个简单的程序示例,部分参考自詹老师的讲义。
正向最大匹配法算法如下所示:(注:以上最大匹配算法图来自于詹老师讲义)逆向匹配法思想与正向一样,只是从右向左切分,这里举一个例子:输入例句:S1=”计算语言学课程有意思” ;定义:最大词长MaxLen = 5;S2= ” “;分隔符= “/”;假设存在词表:…,计算语言学,课程,意思,…;最大逆向匹配分词算法过程如下:(1)S2=”";S1不为空,从S1右边取出候选子串W=”课程有意思”;(2)查词表,W不在词表中,将W最左边一个字去掉,得到W=”程有意思”;(3)查词表,W不在词表中,将W最左边一个字去掉,得到W=”有意思”;(4)查词表,W不在词表中,将W最左边一个字去掉,得到W=”意思”(5)查词表,“意思”在词表中,将W加入到S2中,S2=” 意思/”,并将W从S1中去掉,此时S1=”计算语言学课程有”;(6)S1不为空,于是从S1左边取出候选子串W=”言学课程有”;(7)查词表,W不在词表中,将W最左边一个字去掉,得到W=”学课程有”;(8)查词表,W不在词表中,将W最左边一个字去掉,得到W=”课程有”;(9)查词表,W不在词表中,将W最左边一个字去掉,得到W=”程有”;(10)查词表,W不在词表中,将W最左边一个字去掉,得到W=”有”,这W是单字,将W 加入到S2中,S2=“ /有/意思”,并将W从S1中去掉,此时S1=”计算语言学课程”;(11)S1不为空,于是从S1左边取出候选子串W=”语言学课程”;(12)查词表,W不在词表中,将W最左边一个字去掉,得到W=”言学课程”;(13)查词表,W不在词表中,将W最左边一个字去掉,得到W=”学课程”;(14)查词表,W不在词表中,将W最左边一个字去掉,得到W=”课程”;(15)查词表,“意思”在词表中,将W加入到S2中,S2=“课程/ 有/ 意思/”,并将W从S1中去掉,此时S1=”计算语言学”;(16)S1不为空,于是从S1左边取出候选子串W=”计算语言学”;(17)查词表,“计算语言学”在词表中,将W加入到S2中,S2=“计算语言学/ 课程/ 有/ 意思/”,并将W从S1中去掉,此时S1=”";(18)S1为空,输出S2作为分词结果,分词过程结束。


分词和数据库匹配算法分词和数据库匹配算法是自然语言处理领域中常用的技术手段,对于文本处理以及信息检索等任务具有重要的作用。
本文将从分词和数据库匹配算法的定义、常用方法以及实际应用等方面进行讨论。
一、分词算法分词是将连续的文本划分为一个个有意义的词语的过程,也是自然语言处理的基本任务之一。
常见的分词算法主要有基于规则的算法、基于统计的算法和基于深度学习的算法。
1.基于规则的算法:基于规则的分词算法主要依赖于一些预先设定好的规则来进行划分,比如根据词典进行最长匹配。
这类算法相对简单直观,但是需要大量的人工规则和对语料的分析处理。
2.基于统计的算法:基于统计的分词算法主要基于大规模语料库的统计信息来进行分词,比如根据词频和互信息等。
常见的统计模型有隐马尔可夫模型(HMM)和条件随机场(CRF)。
这类算法相对准确,但需要大规模的训练数据。
3.基于深度学习的算法:近年来,随着深度学习的发展,基于深度学习的分词算法也日渐兴起。
例如,可以使用循环神经网络(RNN)或者长短时记忆网络(LSTM)进行分词。
这类算法在大规模数据集上训练的情况下,可以达到较好的效果。
二、数据库匹配算法数据库匹配算法是用于在数据库中找到与给定查询条件最匹配的记录的算法。
常见的数据库匹配算法包括模糊匹配算法、全文检索算法和最邻近匹配算法等。
1.模糊匹配算法:模糊匹配算法用于在给定的查询条件下,对数据库中的记录进行模糊匹配。
最常见的模糊匹配算法是编辑距离算法,它可以计算两个字符串之间的相似程度。
通过计算编辑距离,可以找到与给定查询条件相似度最高的记录。
2.全文检索算法:全文检索算法用于对数据库中的文本进行全面的检索。
常见的算法有倒排索引算法,它通过构建索引数据结构,将每个词与包含该词的记录关联起来。
通过对查询条件进行分词,并在索引中进行检索,可以快速找到与查询条件相匹配的记录。
3.最邻近匹配算法:最邻近匹配算法主要用于在数据库中找到与给定查询条件最相似的记录。

二级Hash全局和局部索引筛选的长序列比对并行算法
潘登;钟诚
【期刊名称】《小型微型计算机系统》
【年(卷),期】2022(43)9
【摘要】通过构建参考基因组的二级Hash索引,以快速筛选出测序长序列在参考基因组中可能匹配的候选区域;建立测序序列局部索引,以加速测序序列和参考基因组候选区域之间的映射定位;对每个候选区域里的k-mer与测序序列的索引命中进行左右扩展获得比对种子;采用等距离抽样方式对种子抽取多个位置,利用抽样结果建立判断依据来过滤掉那些不可能匹配的种子;建立处理包含“均聚物”类型错误的序列片段全局比对得分方程,并行填补比对骨架的空隙,并采取GPU显存预分配和后释放独立的并行比对策略,以提升序列片段全局并行比对效率.模拟与真实数据的实验结果表明,相较于已有同类的长序列比对并行算法,本文提出的并行算法获得整体上较高的比对敏感度、碱基层次灵敏度和准确度,且可有效处理第3代测序长序列含有的“均聚物”类型错误,显著加速了大规模长序列与参考基因组比对的完成.
【总页数】6页(P1999-2004)
【作者】潘登;钟诚
【作者单位】广西大学计算机与电子信息学院广西高校并行分布式计算技术重点实验室
【正文语种】中文
【中图分类】TP301
【相关文献】
1.异构机群系统上双序列全局比对并行算法
2.基于块排序索引的生物序列局部比对查询技术
3.基于Hash索引的高通量基因序列比对并行加速技术研究
4.一个新的核酸序列比对算法及其在序列全局比对中的应用
5.异构机群系统中序列比对并行算法进展
因版权原因,仅展示原文概要,查看原文内容请购买。

分词算法java
在Java中,常用的分词算法包括:
1. 最大匹配算法(MM):
最大匹配算法是一种基于词典的分词算法,它将待分词的文本从左到右进行扫描,根据词典中的词语进行匹配,选择最长的匹配词作为分词结果。
该算法简单高效,但对于歧义词和未登录词处理较差。
2. 正向最大匹配算法(FMM):
正向最大匹配算法与最大匹配算法类似,但它从文本的起始位置开始匹配。
首先取待分词文本中的前n个字符作为匹配字符串(通常取词典中最长的词的长度),如果这个字符串在词典中存在,则作为分词结果,否则取待分词文本的前n-1个字符,继续匹配,直到匹配到词典中的词为止。
3. 逆向最大匹配算法(BMM):
逆向最大匹配算法与正向最大匹配算法类似,但它从文本的末尾位置向前匹配。
首先取待分词文本中的后n个字符作为匹配字符串,如果这个字符串在词典中存在,则作为分词结果,否则取待分词文本的后n-1个字符,继续匹配,直到匹配到词典中的词为止。
4. 双向最大匹配算法(BiMM):
双向最大匹配算法结合了正向最大匹配算法和逆向最大匹配算法的优点。
它
从文本的起始位置和末尾位置同时进行匹配,选择两个结果中词数较少的分词结果作为最终的分词结果。
以上是一些常见的分词算法,你可以根据自己的需求选择合适的算法进行分词处理。
同时,还可以使用一些开源的中文分词库,例如HanLP、jieba等,它们已经实现了这些算法,并提供了丰富的功能和接口供你使用。


一种基于全hash的整词二分词典机制
中文分词是中文自然语言处理领域中的一个重要问题。
分词的目的是将一篇中文文本切分成一个个合理的词语,为后续的文本处理提供基础。
目前,中文分词领域中已有很多相关的算法和技术,但是没有一种分词机制能够同时考虑分词效率和分词准确率。
本文介绍一种基于全hash的整词二分词典机制,可以高效地完成中文分词任务。
该机制针对中文语言的一些特点,采用了特殊的分词算法,并且引入了全hash索引技术,大大提高了分词效率。
同时,该机制采用二分法查找词典,保证了分词准确率。
1. 将中文文本作为输入,将其中的汉字字符以及标点符号按照一定规则转换成数字序列。
2. 建立词典数据库,将每个词语及其对应的出现频率存储在数据库中。
对于一个单独的汉字,其也视为一个词语。
3. 将词典按照一定顺序排序,然后利用hash函数将每个词语进行全hash索引,生成一个hash表。
该表的每个元素存储一个词语的索引值和其对应的出现频率。
4. 将输入的数字序列作为二分查找的输入,在hash表中进行查找。
具体地,根据输入的数字序列,通过hash函数得到一个索引值,然后利用二分法查找hash表,找到其对应的词语和出现频率。
5. 对于一个较长的数字序列(如一个句子),将其不断拆分成较短的数字序列,然后对每个数字序列利用步骤4的方法进行分词。
对于数字序列中的每一个子序列,记录其对应的词语和出现频率,最后得到整个句子的分词结果。
总之,基于全hash的整词二分词典机制可以高效地完成中文分词任务,可以为后续的文本处理提供更好的基础。

一是词典分词方法,该方法的主要任务就是构建词典,确定扫描方向,研究匹配原则。
二是理解分词方法,其主要是利用深度学习技术,把自动分词技术看作是基于知识的逻辑推理过程。
三是统计分词方法,其主要是基于上下文中汉字与汉字之间相邻出现的概率来实现自动分词。
本文旨在用Python语言实现词典分词方法中的正反向最大长度匹配。
1 实现过程■1.1 数据集本文采用的数据集是人名日报人工分词后的内容,部分数据状况如下:图1 部分数据集■1.2 构建正向匹配词典树首先,把数据集里的每个不重复的词读到变量word_list下,对应代码如下:def get_word_list():IN=open(“train.txt”, “r”, encoding=”gb18030”,errors=’ignore’)word_list = []for line in IN:single_sen = line.strip()if not single_sen:continueelse:single_sen = single_sen.split(“ “)for word in single_sen:word_list.append(word)return list(set(word_list))树结构如图2所示。
图2 正向匹配例子词典树结构使用嵌套字典的数据结构来保存词典树,效果如图3所示。
图3 例子的词典树数据结构词的第一个字作为最外层字典的Key,例如“中”,“打”和“地”,词的第二个字以Key的方式保存在第一个字字典的Value当中,例如“间”和“国”保存在“中”的词典下面。
以此类推,根据数据集里的所有词构建完整的词典树。
对应代码如下:def create_single_tree(flag,cur_dict,word,cur_word,cur_num,length_of_word):if flag == 0:returnif not cur_dict.get(cur_word):cur_dict[cur_word]={}cur_num+=1if cur_num==length_of_word:flag=0returnreturncreate_single_tree(flag,cur_dict[cur_word],word,word[cur_num],cur_num,length_of_word)def create_whole_dict_tree(dict_tree,word_list):56 | 电子制作 2020年09月www�ele169�com | 57软件开发for word in word_list:try:create_single_tree(1,dict_tree,word,word[0],0, len(word))except IndexError:continue return dict_treecreate_single_tree 函数每次取word_list 里的一个词来填充词典树。
二次Hash+二分最大匹配快速分词算法
杨安生
【期刊名称】《情报探索》
【年(卷),期】2009(000)008
【摘要】通过对已有的分词算法尤其是快速分词算法的分析,提出了一种新的分词词典结构.并据此提出了二次Hash+二分最大匹配快速分词算法.该算法具有较快的分词速度.
【总页数】3页(P90-92)
【作者】杨安生
【作者单位】广东惠州学院,惠州,516015
【正文语种】中文
【中图分类】TP391.12
【相关文献】
1.全二分快速自动分词算法构建 [J], 张海营
2.全二分最大匹配快速分词算法 [J], 李振星;徐泽平;唐卫清;唐荣锡
3.中文分词算法之最大匹配算法的研究 [J], 张玉茹
4.一种基于改进最大匹配快速中文分词算法 [J], 林浩;韩冰;杨乐华
5.基于逆向最大匹配分词算法的汉盲翻译系统 [J], 杨文珍;徐豪杰;汪文妃;宣建强;赵维;吴新丽;潘海鹏
因版权原因,仅展示原文概要,查看原文内容请购买。
基于哈希表的最长前缀匹配算法改进
刘舱强;邓昌胜;余谅
【期刊名称】《微计算机信息》
【年(卷),期】2009(025)030
【摘要】在实际应用中经常需要查找某IP地址其在数据库中对应的真实的物理地址,而数据库的数据量往往很大,显然直接去查询数据库不能满足大量数据以及高速查找的要求.在最长前缀匹配算法的基础上,提出了一种基于哈希查找表的IP地址查找算法.将数据库中的信息建立为一个哈希表,并将点分十进制IP地址的部分前缀作为键值,映射到哈希表中的一条记录,从而得到所需的信息.最后用C#语言实现了该算法,实验表明该算法具有很高的效率.
【总页数】3页(P143-144,142)
【作者】刘舱强;邓昌胜;余谅
【作者单位】610064,成都,四川大学计算机学院;610064,成都,四川大学计算机学院;610064,成都,四川大学计算机学院
【正文语种】中文
【中图分类】TP393
【相关文献】
1.一种改进的IPV6最长前缀匹配路由查找算法 [J], 刘阳;高仲合
2.一种无回溯的最长前缀匹配搜索算法 [J], 张飞飞;李华伟;韩银和
3.一种基于最长前缀匹配的分段式IP查表方法 [J], 张文柱;王炫
4.一种基于模式最长前缀正文分割的串匹配新算法 [J], 庞善臣;王淑栋
5.可加速最长前缀匹配的布隆过滤查找方案 [J], 王乾;乔庐峰;陈庆华
因版权原因,仅展示原文概要,查看原文内容请购买。
一种基于模式最长前缀正文分割的串匹配新算法
庞善臣;王淑栋
【期刊名称】《小型微型计算机系统》
【年(卷),期】2004(025)003
【摘要】字符串的模式匹配问题是计算机科学的基本问题之一,本文提出了基于模式最长前缀正文分割的匹配新算法(Text Divided Algorithm,以下简称TD算法).首先在模式P中寻找最长的前缀子串subp,使其末字符在subp中只出现一次;然后根据subp末字符的特点,将正文T进行分段,按段对模式P进行匹配.新算法有以下重要的特点:1. 最坏情况下,本算法有效地减少了字符重复比较的次数,从而提高了算法的匹配效率;2. 匹配算法在二维匹配和不精确匹配中较易推广;3. 匹配过程近似于直接算法,便于接受和理解.
【总页数】3页(P404-406)
【作者】庞善臣;王淑栋
【作者单位】山东科技大学,信息科学与工程学院,山东,泰安,271019;山东科技大学,信息科学与工程学院,山东,泰安,271019;华中科技大学,控制科学与工程系,湖北,武汉,430074
【正文语种】中文
【中图分类】TP301
【相关文献】
1.FilterFA:一种基于字符集规约的模式串匹配算法 [J], 张萍;何慧敏;张春燕;曹聪;刘燕兵;谭建龙
2.一种基于循环前缀的OFDM时频同步新算法 [J], 刘平
3.一种基于压缩前缀树的频繁模式挖掘算法 [J], 郭云峰;张集祥
4.一种基于子串识别的多模式串匹配算法 [J], 何慧敏;刘燕兵;谭建龙;郭莉
5.一种基于魂芯DSP的单模式位并行串匹配算法 [J], 陈瑞;顾乃杰;叶鸿
因版权原因,仅展示原文概要,查看原文内容请购买。