verilog语言编写8位全加器
- 格式:docx
- 大小:15.06 KB
- 文档页数:3

<实验报告一>学生姓名:班级学号:指导老师:<基于封装设计思想实现8位全加器>一、实验名称:基于封装设计思想实现8位全加器二、实验学时:3学时三、实验目的:1) 在掌握QuartusII软件环境和全加器原理的基础上,重点学习Verilog封装的设计方法。
2)进一步巩固文本和图形法结合的设计方法。
四、实验内容分别用原理图输入法和文本输入法来设计八位全加器。
1)原理图输入法:给出一位全加器的原理图,在quartusⅡ中封装一位全加器,再用它顺序链接形成八位全加器。
2)文本输入法:用Verilog语言编写源程序来实现八位全加器。
五、实验仪器1.PC机2. 数字系统设计实验开发板六、实验步骤1)熟悉quartusII的使用a)打开开发环境,如图表1图表 12)原理图输入法a) 我们在这里给出一位加法器的原理图图表2。
图表 2b) 给出一位加法器的真值表图表3。
图表 33) 文本输入方法i.创建Verilog程序文件,如图表。
图表 5ii.把同学们自己写的源程序输入进去,然后编译,如果不明白,可以参考以前的实验。
iii.代码可以参考《V erilog数字系统设计教程》,P199,进行设计。
4)通过文本输入法或原理图输入法实现一位加法运算器,并将其封装,然后通过8个一位加法器的链接实现8位加法器。
封装方法:一位加法器程序编写并编译通过后,点击File->Creat/Update->Creat Symbol Files for Current File可以产生与module同名的元器件,然后可以通过对器件的连接产生一个8位加法器。
请同学们根据一位加法器设计出8位加法器的电路图。
然后进行仿真。
我们在这里提供一个4位加法器的参考设计图6.图表 4七、实验结果1.文本输入法1.1一位全加器:程序代码:module one_bit(s,co,x,y,ci);input x,y,ci;output s,co;wire a,b,c;xor (s,ci,x,y);andand1(a,x,y),and2(b,x,ci),and3(c,y,ci);or (co,a,b,c);endmodule波形图:1.2 八位全加器程序代码:module eight_bit(s,co,x,y); input [7:0] x,y;output [7:0] s;output co;assign {co,s}=x+y;endmodule波形图:2.原理图输入法:2.1 一位全加器原理图:波形图:2.2 八位全加器:原理图:波形图:八、问题讨论:为什么我们有时候用always,而有时候又用assign,同学们能否正确区分它们的区别?assign语句即持续赋值语句,主要用于对wire型变量的赋值,因为wire即线型的值不能存住,需要一直给值,所以需要用持续赋值。

8位全加器一、实验目的用verilog语言编写一个8位全加器,并在modelsim软件上进行仿真。
二、代码1、源代码:module add8(sum,cout,in1,in2,cin);input [7:0] in1,in2;input cin;output [7:0] sum;output cout;assign {cout,sum}=in1+in2+cin;endmodule2、激励:`timescale 1ns/100psmodule add8_tb;reg[7:0] A,B;reg CIN;wire [7:0] SUM;wire COUT;add8 ul(1.sum(SUM),.cout(COUT),.in1(A),.in2(B),.cin(CIN));initialbeginA=8'd0;B=8'd0;CIN=1'b0;#10 A=8'd20;B=8'd129;CIN=1'b1; #10 A=8'd27;B=8'd19;CIN=1'b0; #10 A=8'd157;B=8'd29;CIN=1'b0; #10 A=8'd37;B=8'd68;CIN=1'b0; #10 A=8'd11;B=8'd69;CIN=1'b0; #10 A=8'd54;B=8'd67;CIN=1'b1; #10 A=8'd211;B=8'd0;CIN=1'b0; #10 A=8'd87;B=8'd43;CIN=1'b1; #10 A=8'd23;B=8'd171;CIN=1'b0; #10 A=8'd12;B=8'd12;CIN=1'b1; #10 A=8'd112;B=8'd115;CIN=1'b0; endendmodule23三、实验过程1、上机过程2、仿真波形3、波形说明波形图中,从上至下依次为:输入加数A、输入加数B、输入进位CIN、输出进位COUT、输出和SUM。


Verilog实现的8位超前进位加法器。
经过modelsim验证正确可用,在DC下综合成功//文件名:add_8.v//模块名:add_8//`timescale 1ns/1nsmodule add_8 ( input [7:0]a, input [7:0]b, input cin, output [7:0] s, output co );wire [7:0]c_tmp;wire [7:0]g;wire [7:0]p;assign co = c_tmp[7];assign g[0] = a[0] & b[0],g[1] = a[1] & b[1],g[2] = a[2] & b[2],g[3] = a[3] & b[3],g[4] = a[4] & b[4],g[5] = a[5] & b[5],g[6] = a[6] & b[6],g[7] = a[7] & b[7];assign p[0] = a[0] | b[0],p[1] = a[1] | b[1],p[2] = a[2] | b[2],p[3] = a[3] | b[3],p[4] = a[4] | b[4],p[5] = a[5] | b[5],p[6] = a[6] | b[6],p[7] = a[7] | b[7];assign c_tmp[0] = g[0] | ( p[0] & cin ),c_tmp[1] = g[1] | ( p[1] & g[0]) | ( p[1] & p[0] & cin),c_tmp[2] = g[2] | ( p[2] & g[1]) | ( p[2] & p[1] & g[0]) | ( p[2] & p[1] & p[0] & cin),c_tmp[3] = g[3] | ( p[3] & g[2]) | ( p[3] & p[2] & g[1]) | ( p[3] & p[2] & p[1] & g[0])| ( p[3] & p[2] & p[1] & p[0] & cin),c_tmp[4] = g[4] | ( p[4] & g[3]) | ( p[4] & p[3] & g[2]) | ( p[4] & p[3] & p[2] & g[1])| ( p[4] & p[3] & p[2] & p[1] & g[0]) | ( p[4] & p[3] & p[2] & p[1] & p[0] &cin),c_tmp[5] = g[5] | ( p[5] & g[4]) | ( p[5] & p[4] & g[3]) | ( p[5] & p[4] & p[3] & g[2])| ( p[5] & p[4] & p[3] & p[2] & g[1]) | ( p[5] & p[4] & p[3] & p[2] & p[1] & g[0])| ( p[5] & p[4] & p[3] & p[2] & p[1] & p[0] & cin),c_tmp[6] = g[6] | ( p[6] & g[5]) | ( p[6] & p[5] & g[4]) | ( p[6] & p[5] & p[4] & g[3])| ( p[6] & p[5] & p[4] & p[3] & g[2]) | ( p[6] & p[5] & p[4] & p[3] & p[2] & g[1])| ( p[6] & p[5] & p[4] & p[3] & p[2] & p[1] & g[0])| ( p[6] & p[5] & p[4] & p[3] & p[2] & p[1] & p[0] & cin),c_tmp[7] = g[7] | ( p[7] & g[6]) | ( p[7] & p[6] & g[5]) | ( p[7] & p[6] & p[5] & g[4])| ( p[7] & p[6] & p[5] & p[4] & g[3]) | ( p[7] & p[6] & p[5] & p[4] & p[3] & g[2])| ( p[7] & p[6] & p[5] & p[4] & p[3] & p[2] & g[1])| ( p[7] & p[6] & p[5] & p[4] & p[3] & p[2] & p[1] & g[0])| ( p[7] & p[6]& p[5] & p[4] & p[3] & p[2] & p[1] & p[0] & cin);assign s[7:0] = a[7:0] ^ b[7:0] ^{c_tmp[6:0],cin};endmodule。
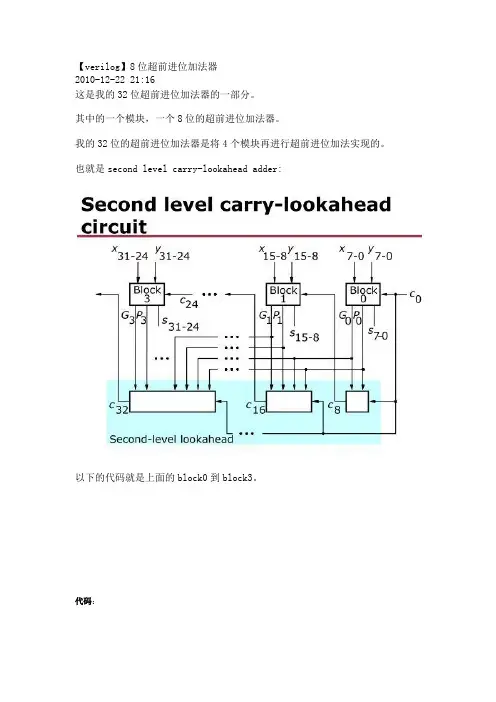
【verilog】8位超前进位加法器2010-12-22 21:16这是我的32位超前进位加法器的一部分。
其中的一个模块,一个8位的超前进位加法器。
我的32位的超前进位加法器是将4个模块再进行超前进位加法实现的。
也就是second level carry-lookahead adder:以下的代码就是上面的block0到block3。
代码://Written by alexyangfox#module eight_bit_unit(A,B,c0,G_level,PG_level,carry,sum);input [7:0] A; //加数Ainput [7:0] B; //加数Binput c0; //输入的进位c0 (Carry 0)output [7:0] sum; //输出和output G_level,PG_level,carry; //产生的极间PG(propagate)和G(generate)//因为我这里想要的是做2级超前进位加法器//一个32位的超前进位加法器由4个八位的超前进位加法器组成//然后四个加法器又被当作独立的模块,四个加法器再超前进位一次形成第二级wirepg0,pg1,pg2,pg3,pg4,pg5,pg6,pg7,g0,g1,g2,g3,g4,g5,g6,g7,c0,c1,c2,c3,c4,c5,c6,c7,c8;wire G_level,PG_level,carry;//全部 PG的计算(propagate)//有的人将PG定义为: PG=A + B//而我在此处使用通常定义: PG = A xor B//由于有这样的关系 A + B = (A xor B) + AB//但是AB已经在Gernerate中:C_n=Generator_(n-1) + Propagate_(n-1)*C_(n-1)//PG 和 G只是用来计算进位数的,所以使用哪种PG的定义并没有影响//在实际电路中,若使用PG=A+B的方案,还可以减少晶体管的使用//well,sth interesting :XOR is not "exclusive or" (nor),it's //"exclusive disjunction or"assign pg0=A[0]^B[0];assign pg1=A[1]^B[1];assign pg2=A[2]^B[2];assign pg3=A[3]^B[3];assign pg4=A[4]^B[4];assign pg5=A[5]^B[5];assign pg6=A[6]^B[6];assign pg7=A[7]^B[7];//计算所有的 Generate (G)assign g0=A[0] & B[0];assign g1=A[1] & B[1];assign g2=A[2] & B[2];assign g3=A[3] & B[3];assign g4=A[4] & B[4];assign g5=A[5] & B[5];assign g6=A[6] & B[6];assign g7=A[7] & B[7];//进位产生器//公式:C_n=Generator_(n-1) + Propagate_(n-1)*C_(n-1)//c1=g0 + pg0*c0assign c1=g0|( pg0 & c0);//c2=g1+ pg1*g0 + pg1*pg0*c0assign c2=g1|( pg1 & g0)|( pg1 & pg0 & c0);//c3=g2+ pg2*g1+ pg2*pg1*g0 + pg2*pg1*pg0*c0assign c3=g2|( pg2 & g1)|( pg2 & pg1 & g0)|( pg2 & pg1 & pg0 & c0);//c4= g3 + pg3*g2+ pg3*pg2*g1+ pg3*pg2*pg1*g0// + pg3*pg2*pg1*pg0*c0assign c4=g3|(pg3 & g2)|(pg3 & pg2 & g1)|( pg3 & pg2 & pg1 & g0)|(pg3 & pg2 & pg1 & pg0 & c0);//c5= g4 + pg4*g3 + pg4*pg3*g2+ pg4*pg3*pg2*g1// + pg4*pg3*pg2*pg1*g0 + pg4*pg3*pg2*pg1*pg0*c0assign c5=g4|( pg4 & g3)|( pg4 & pg3 & g2)|( pg4 & pg3 & pg2 & g1)|( pg4& pg3 & pg2 & pg1 & g0)|( pg4 & pg3 & pg2 & pg1 & pg0 & c0);//c6=g5 + pg5*g4 + pg5*pg4*g3 + pg5*pg4*pg3*g2// + pg5*pg4*pg3*pg2*g1 + pg5*pg4*pg3*pg2*pg1*g0// + pg5*pg4*pg3*pg2*pg1*pg0*c0assign c6=g5|( pg5 & g4)|( pg5 & pg4 & g3)|( pg5 & pg4 & pg3 & g2)|( pg5 & pg4 & pg3 & pg2 & g1)|( pg5 & pg4 & pg3 & pg2 & pg1 & g0)|( pg5 & pg4 & pg3 & pg2 & pg1 & pg0 & c0);//c7=g6 + pg6*g5 + pg6*pg5*g4 + pg6*pg5*pg4*g3 + pg6*pg5*pg4*pg3*g2// + pg6*pg5*pg4*pg3*pg2*g1 + pg6*pg5*pg4*pg3*pg2*pg1*g0// + pg6*pg5*pg4*pg3*pg2*pg1*pg0*c0assign c7=g6|( pg6 & g5)|( pg6 & pg5 & g4)|( pg6 & pg5 & pg4 & g3)|( pg6 & pg5 & pg4 & pg3 & g2)|( pg6 & pg5 & pg4 & pg3 & pg2 & g1)|( pg6 & pg5 & pg4 & pg3 & pg2 & pg1 & g0)|( pg6 & pg5 & pg4 & pg3 & pg2 & pg1 & pg0 & c0);//c8=g7 + pg7*g6 + pg7*pg6*g5 + pg7*pg6*pg5*g4 + pg7*pg6*pg5*pg4*g3 +pg7*pg6*pg5*pg4*pg3*g2// + pg7*pg6*pg5*pg4*pg3*pg2*g1 + pg7*pg6*pg5*pg4*pg3*pg2*pg1*g0//+ pg7*pg6*pg5*pg4*pg3*pg2*pg1*pg0*c0assign c8=g7|(pg7 & g6)|(pg7 & pg6 & g5)|(pg7 & pg6 & pg5 & g4)|(pg7 & pg6 & pg5 & pg4 & g3)|(pg7 & pg6 & pg5 & pg4 & pg3 & g2)|(pg7 & pg6 & pg5 & pg4 & pg3 & pg2 & g1)|(pg7 & pg6 & pg5 & pg4 & pg3 & pg2 & pg1 & g0)|(pg7 & pg6 & pg5 & pg4 & pg3 & pg2 & pg1 & pg0 & c0);//这句写成:c8=G_level|(pg7 & pg6 & pg5 & pg4 & pg3 & pg2 & pg1 & pg0 & c0);会减少器件使用,但是会增加延迟?//极间超前进位信号G_level和PG_level的产生//Actually I am building a two_level carry look ahead adder.//回顾上面C8的计算公式,将它拆解成两部分://C8=G_level + C0*PG_level//于是,我们很容易得到这个://G_level=item0+item1+...+item7//PG_level=pg7*pg6*pg5*pg4*pg3*pg2*pg1*pg0assign PG_level=pg7 & pg6 & pg5 & pg4 & pg3 & pg2 & pg1 & pg0;assign G_level=g7|(pg7 & g6)|(pg7 & pg6 & g5)|(pg7 & pg6 & pg5 & g4)|(pg7 & pg6 & pg5 & pg4 & g3)|(pg7 & pg6 & pg5 & pg4 & pg3 & g2)|(pg7 & pg6 & pg5 & pg4 & pg3 & pg2 & g1)|(pg7 & pg6 & pg5 & pg4 & pg3 & pg2 & pg1 & g0);//the parts above explains the term "Carry look_ahead"//计算输出结果//两个异或门(Xor GAtes)assign sum[0]=A[0] ^ B[0] ^ c0;assign sum[1]=A[1] ^ B[1] ^ c1;assign sum[2]=A[2] ^ B[2] ^ c2;assign sum[3]=A[3] ^ B[3] ^ c3;assign sum[4]=A[4] ^ B[4] ^ c4;assign sum[5]=A[5] ^ B[5] ^ c5;assign sum[6]=A[6] ^ B[6] ^ c6;assign sum[7]=A[7] ^ B[7] ^ c7;assign carry=c8;endmodule。

8位加法器设计程序过程八位加法器是一种组合逻辑电路,用于计算两个八位二进制数的和。
在设计过程中,需要确定输入和输出的位数、电路逻辑、输入输出关系等。
下面是一个八位加法器设计程序的详细过程。
1.确定输入和输出的位数:首先,我们需要明确八位加法器的输入和输出的位数。
在这个例子中,我们使用八位二进制数作为输入,并需要输出一个八位的和。
因此,输入和输出的位数均为8位。
2.确定输入和输出的表示形式:在计算机中,二进制数通常以补码形式进行表示。
因此,在这个例子中,我们将使用补码表示输入和输出。
3.分析电路逻辑:一个八位加法器由八位的全加器以及一个进位逻辑组成。
全加器用于计算两个相应位数相加的结果,而进位逻辑负责处理进位位。
因此,我们需要设计八个全加器和一个进位逻辑。
4.设计全加器电路:全加器是八位加法器的核心部分,用于计算两个位的和以及进位。
全加器的输入包括两个加数位和一个来自前一位的进位位。
输出包括和位以及进位位。
以下是一个典型的全加器电路:- 输入:A、B和C_in- 输出:Sum和C_out-逻辑表达式:Sum = A 异或 B 异或 C_inC_out = (A and B) 或 (C_in and (A 异或 B))设计八个这样的全加器电路,分别用于计算八个相应位数的和以及进位。
5.设计进位逻辑电路:进位逻辑电路负责处理来自各个位的进位。
具体来说,进位逻辑电路需要计算进位位以及进位到下一位的值。
以下是一个典型的进位逻辑电路:- 输入:C_in、C_0、C_1、C_2、C_3、C_4、C_5、C_6 和 C_7- 输出:C_out 和 C_next-逻辑表达式:C_out = C_7C_next = (C_6 and C_7) 或 (C_5 and (C_6 or C_7)) 或 (C_4 and (C_5 or (C_6 or C_7))) 或 ......(C_1 and (C_2 or (C_3 or (C_4 or (C_5 or (C_6 or C_7))))))其中,C_out代表从最高位传出的进位,C_next代表传递给下一位的进位。

v e r i l o g八位十进制计数器实验报告附源代码修订版IBMT standardization office【IBMT5AB-IBMT08-IBMT2C-ZZT18】8位10进制计数器实验报告一、实验目的学习时序逻辑电路学会用verilog语言设计时序逻辑电路掌握计数器的电路结构掌握数码管动态扫描显示原理二、实验内容实现一个8bit十进制(BCD码)计数器端口设置:用拨动开关实现复位和使能LED灯来表示8位数据用数码管显示16进制的八位数据1.复位时计数值为8‘h02.复位后,计数器实现累加操作,步长为1,逢9进1,,计数值达到8‘h99后,从0开始继续计数3.使能信号为1时正常计数,为0时暂停计数,为1时可继续计数。
4.每0.5s计数值加15.8位的结果显示在LED灯上,其中LED灯亮表示对应的位为1,LED灯灭表示对应的灯为06.用isim进行仿真,用forever语句模拟时钟信号输入,并给变量赋值仿真initial语句。
7.用7段数码管的后两位显示16进制下8位结果。
三、实验结果烧写结果:拨动reset开关到1时,LED灯显示10010000,7段数码管显示“90”。
之后拨动WE开关呢,开始计数,LED开始变化并且7段数码管开始计数。
从99后到达00,LED重新开始从00000000开始亮,且数码管重新从00开始计数。
之后拨动WE开关,暂停计数,LED暂停亮灭,七段数码管暂停变化,WE拨回1,继续计数。
拨动复位信号时,无视WE信号,直接复位。
仿真结果:当输入reset信号时波形变化如下当达到一个扫描信号的周期时的波形如下当达到一个以上计数信号的周期时的波形实验分析:实验总体结构和模块间关系如图所示:(其中还需要补上使能信号)实验原理:由于要求实现数码管和LED灯的显示,先考虑LED灯,可以直接由8位输出信号控制,而数码管需要同时显示两个不同的数字,需要时分复用,即快速的交替显示十位和个位,利用人眼的视觉暂留来达到同时显示。

实验一:8位全加器实验步骤1、熟悉QUARTUSⅡ集成开发环境;2、熟悉GW48-PK2型FPGA实验箱;3、编写8位全加器的Verilog HDL源代码;4、完成计算机模拟功能仿真;5、下载到Altera ACEXEP1K30中,使用实验箱完成硬件验证;6、完成实验报告实验要求8位全加器输入:Clk,Rst_,In1,In2,Cin输出:Count,Sum1.实验代码如下:module adder_8(Cout,Sum,In1,In2,Cin,Rst_,Clk);input[7:0]In1,In2;input Clk,Rst_,Cin;output[7:0]Sum;output Cout;reg[7:0]Sum;reg Cout;always@(posedge Clk)beginif(!Rst_)beginSum<=8'b0000_0000;Cout<=1'b0;endelse{Cout,Sum}=In1+In2+Cin;endendmodule2.实验仿真截图如下:(1)无输出进位的仿真截图:说明1:此图中,由于加数和被加数都比较小,导致高位没有进位。
此图中,输入低位进位设为总为1,所以和总是比两个加数直接相加所得结果大1。
只有时钟脉冲上升沿到达时,此之前的加数相加在复位端为高电平时所加和才不为零,其他所加结果都为零。
而且在图中,采集频率要比时钟频率高,也即加数和被加数及所加的和的数字采集时间要比时钟慢。
如图中,时钟的周期是10ns,数字采集周期是20ns,所以图中和的结果总是比加数有延迟。
(2)有输出进位得仿真截图:说明2:此图中,由于加数和被加数都比较大,所以有输出进位。
图中低位进位与(1)图相比,有0又有1,所以结果也和(1)中略有不同。
只有时钟脉冲上升沿到达时,此之前的加数相加在复位端为高电平时所加和才不为零,其他所加结果都为零。
且和(1)中一样,图中,采集频率要比时钟频率高,也即加数和被加数及所加的和的数字采集时间要比时钟慢。
![verilog八位十进制计数器实验报告[附源代码]](https://uimg.taocdn.com/00632cfe195f312b3169a5ad.webp)
8位10进制计数器实验报告一、实验目的●学习时序逻辑电路●学会用verilog语言设计时序逻辑电路●掌握计数器的电路结构●掌握数码管动态扫描显示原理二、实验内容实现一个8bit十进制(BCD码)计数器端口设置:用拨动开关实现复位和使能LED灯来表示8位数据用数码管显示16进制的八位数据1.复位时计数值为8‘h02.复位后,计数器实现累加操作,步长为1,逢9进1,,计数值达到8‘h99后,从0开始继续计数3.使能信号为1时正常计数,为0时暂停计数,为1时可继续计数。
4.每0.5s计数值加15.8位的结果显示在LED灯上,其中LED灯亮表示对应的位为1,LED灯灭表示对应的灯为06.用isim进行仿真,用forever语句模拟时钟信号输入,并给变量赋值仿真initial语句。
7.用7段数码管的后两位显示16进制下8位结果。
三、实验结果烧写结果:拨动reset开关到1时,LED灯显示10010000,7段数码管显示“90”。
之后拨动WE开关呢,开始计数,LED开始变化并且7段数码管开始计数。
从99后到达00,LED重新开始从00000000开始亮,且数码管重新从00开始计数。
之后拨动WE开关,暂停计数,LED暂停亮灭,七段数码管暂停变化,WE拨回1,继续计数。
拨动复位信号时,无视WE信号,直接复位。
仿真结果:当输入reset信号时波形变化如下当达到一个扫描信号的周期时的波形如下当达到一个以上计数信号的周期时的波形实验分析:实验总体结构和模块间关系如图所示:(其中还需要补上使能信号)实验原理:由于要求实现数码管和LED灯的显示,先考虑LED灯,可以直接由8位输出信号控制,而数码管需要同时显示两个不同的数字,需要时分复用,即快速的交替显示十位和个位,利用人眼的视觉暂留来达到同时显示。
这样就需要两种不同的频率信号。
一种是每0.5s一次,作为计数信号,用脉冲生成器生成,另一种是1ms一次的扫描信号,用降频器生成,将计数信号输入计数器来计数,并将计数的值和扫描信号同时输入扫描显示模块。

8位全加器一、实验目得用verilog语言编写一个8位全加器,并在modelsim软件上进行仿真。
二、代码1、源代码:module add8(sum,cout,in1,in2,cin);input [7:0] in1,in2;inputcin;output [7:0] sum;output cout;assign {cout,sum}=in1+in2+cin;endmodule2、激励:`timescale 1ns/100psmodule add8_tb;reg[7:0] A,B;reg CIN;wire [7:0] SUM;wireCOUT;add8 ul(、sum(SUM),、cout(COUT),、in1(A),、in2(B),、cin(CIN));initialbeginA=8'd0;B=8'd0;CIN=1'b0;#10 A=8'd20;B=8'd129;CIN=1'b1;#10 A=8'd27;B=8'd19;CIN=1'b0;#10 A=8'd157;B=8'd29;CIN=1'b0;#10 A=8'd37;B=8'd68;CIN=1'b0;#10 A=8'd11;B=8'd69;CIN=1'b0;#10 A=8'd54;B=8'd67;CIN=1'b1;#10 A=8'd211;B=8'd0;CIN=1'b0;#10 A=8'd87;B=8'd43;CIN=1'b1;#10 A=8'd23;B=8'd171;CIN=1'b0;#10 A=8'd12;B=8'd12;CIN=1'b1;#10 A=8'd112;B=8'd115;CIN=1'b0;endendmodule三、实验过程1、上机过程2、仿真波形3、波形说明波形图中,从上至下依次为:输入加数A、输入加数B、输入进位CIN、输出进位COUT、输出与SUM。

Verilog实验报告基于封装设计思想实现8位全加器小组成员:实验时间:2010年5月 16日实验报告---基于封装设计思想实现8位全加器实验时间:2010年5月16日小组成员:一、实验目的1)在掌握QuartusII软件环境和全加器原理的基础上,重点学习Verilog封装的设计方法。
2)进一步巩固文本和图形法结合的设计方法。
二.实验仪器1.PC机2. 数字系统设计实验开发板三.实验学时:3学时四.实验原理:全加器的原理设计.五.实验步骤1)熟悉quartusII的使用a)打开开发环境,如错误!未找到引用源。
2)原理图输入法:八个一位加法器连接成的一个八位加法器原理图图表:3)仿真波形:4)封装后的八位加法器:5)程序代码:module yy1(x,y,sum,c1,c2);input x;input y;input c1;output sum;output c2;assign{c2,sum}=x+y+c1;endmodule六.问题回答:assign 用于描述组合逻辑,always(敏感事件列表) 用于描述时序逻辑。
所有的assign 和 always 块都是并行发生的。
并行块、顺序块,将要并行执行的语句写在fork//语句并行执行join将要顺序执行的语句写在begin//语句顺序执行end并行块和顺序块都可以写在initial 或 always@ 之后,也就是说写在块中的语句是时序逻辑的对assign之后不能加块,实现组合逻辑只能用逐句的使用assign 组合逻辑如果不考虑门的延时的话当然可以理解为瞬时执行的,因此没有并行和顺序之分,并行和顺序是针对时序逻辑来说的。
值得注意的是所有的时序块都是并行执行的。
initial块只在信号进入模块后执行1次而always块是由敏感事件作为中断来触发执行的。
七.实验总结:经过这次实验,我们复习了一些Verilog的基本知识,并且熟习了一些封装等的操作,为以后的实验打下基础。
所谓流水线处理,如同生产装配线一样,将操作执行工作量分成若干个时间上均衡的操作段,从流水线的起点连续地输入,流水线的各操作段以重叠方式执行。
这使得操作执行速度只与流水线输入的速度有关,而与处理所需的时间无关。
这样,在理想的流水操作状态下,其运行效率很高。
如果某个设计的处理流程分为若干步骤,而且整个数据处理是单流向的,即没有反馈或者迭代运算,前一个步骤的输出是下一个步骤的输入,则可以采用流水线设计方法来提高系统的工作频率。
下面用8位全加器作为实例,分别列举了非流水线方法、2级流水线方法和4级流水线方法。
(1)非流水线实现方式module adder_8bits(din_1, clk, cin, dout, din_2, cout);input [7:0] din_1;input clk;input cin;output [7:0] dout;input [7:0] din_2;output cout;reg [7:0] dout;reg cout;always @(posedge clk) begin{cout,dout} <= din_1 + din_2 + cin;endendmodule(2)2级流水线实现方式:module adder_4bits_2steps(cin_a, cin_b, cin, clk, cout, sum);input [7:0] cin_a;input [7:0] cin_b;input cin;input clk;output cout;output [7:0] sum;reg cout;reg cout_temp;reg [7:0] sum;reg [3:0] sum_temp;always @(posedge clk) begin{cout_temp,sum_temp} = cin_a[3:0] + cin_b[3:0] + cin;endalways @(posedge clk) begin{cout,sum} = {{1'b0,cin_a[7:4]} + {1'b0,cin_b[7:4]} + cout_temp, sum_temp};endendmodule注意:这里在always块内只能用阻塞赋值方式,否则会出现逻辑上的错误!(3)4级流水线实现方式:module adder_8bits_4steps(cin_a, cin_b, c_in, clk, c_out, sum_out); input [7:0] cin_a;input [7:0] cin_b;input c_in;input clk;output c_out;output [7:0] sum_out;reg c_out;reg c_out_t1, c_out_t2, c_out_t3;reg [7:0] sum_out;reg [1:0] sum_out_t1;reg [3:0] sum_out_t2;reg [5:0] sum_out_t3;always @(posedge clk) begin{c_out_t1, sum_out_t1} = {1'b0, cin_a[1:0]} + {1'b0, cin_b[1:0]} + c_in;endalways @(posedge clk) begin{c_out_t2, sum_out_t2} = {{1'b0, cin_a[3:2]} + {1'b0, cin_b[3:2]} + c_out_t1, sum_out_t1};endalways @(posedge clk) begin{c_out_t3, sum_out_t3} = {{1'b0, cin_a[5:4]} + {1'b0, cin_b[5:4]} + c_out_t2, sum_out_t2};endalways @(posedge clk) begin{c_out, sum_out} = {{1'b0, cin_a[7:6]} + {1'b0, cin_b[7:6]} + c_out_t3, sum_out_t3};endendmodule总结:利用流水线的设计方法,可大大提高系统的工作速度。
由一位全加器构成8位全加器电科6012202023 裴佳文一、实验目的用verilog语言编写由1位全加器构成8位全加器,自行编写testbench代码并在modelsim软件上进行仿真。
二、代码1、源代码:1位全加器:module P1(A,B,Cin,sum,Cout);input A,B,Cin;output sum,Cout;wire s1,t1,t2,t3;xor x1(s1,A,B),x2(sum,s1,Cin);and A1(t3,A,B),A2(t2,B,Cin),A3(t1,A,Cin);or o1(Cout,t1,t2,t3);endmodule由1位全加器构成8位全加器module P(J,W,Psum,PCout,PCin);input [7:0] J,W;input Pcin;output [7:0] Psum;output Pcout;wire [7:1]Ptemp;P1:PA1(.A(J[0]),.B(W[0]),.Cin(PCin),.sum(Psum[0]),.Cout(Ptemp[1])),PA2(.A(J[1]),.B(W[1]),.Cin(Ptemp[1]),.sum(Psum[1]),.Cout(Ptemp[2])),PA3(.A(J[2]),.B(W[2]),.Cin(Ptemp[2]),.sum(Psum[2]),.Cout(Ptemp[3])), PA4(.A(J[3]),.B(W[3]),.Cin(Ptemp[3]),.sum(Psum[3]),.Cout(Ptemp[4])),PA5(.A(J[4]),.B(W[4]),.Cin(Ptemp[4]),.sum(Psum[4]),.Cout(Ptemp[5]))PA6(.A(J[5]),.B(W[5]),.Cin(Ptemp[5]),.sum(Psum[5]),.Cout(Ptemp[6])) PA7(.A(J[6]),.B(W[6]),.Cin(Ptemp[6]),.sum(Psum[6]),.Cout(Ptemp[7])) PA8(.A(J[7]),.B(W[7]),.Cin(Ptemp[7]),.sum(Psum[7]),.Cout(PCout). endmodule2、激励:`timescale 1ns/100psmodule P_tb;reg[7:0] A,B;reg CIN;wire [7:0] SUM;wire COUT;P ul(.Psum(SUM),.PCout(COUT),.J(A),.W(B),.PCin(CIN));initialbeginA=8'd0;B=8'd0;CIN=1'b0;#10 A=8'd20;B=8'd129;CIN=1'b1;#10 A=8'd27;B=8'd19;CIN=1'b0;#10 A=8'd157;B=8'd29;CIN=1'b0;#10 A=8'd37;B=8'd68;CIN=1'b0;#10 A=8'd11;B=8'd69;CIN=1'b0;#10 A=8'd54;B=8'd67;CIN=1'b1;#10 A=8'd211;B=8'd0;CIN=1'b0;#10 A=8'd87;B=8'd43;CIN=1'b1;#10 A=8'd23;B=8'd171;CIN=1'b0;#10 A=8'd12;B=8'd12;CIN=1'b1;#10 A=8'd112;B=8'd115;CIN=1'b0;endendmodule三、实验过程1、仿真过程2、仿真波形3、波形说明波形图中,从上至下依次为:输入加数A、输入加数B、输入进位CIN、输出进位COUT、输出和SUM。
基于verilog HDL的八位超前进位加法器Verilog 综合作业陈孙文2011-10-25指导老师:邓婉玲老师目录:1. 超前进位加法器原理2. 算法代码3. modelsim SE软件实现功能仿真4. synplify pro软件实现综合正文:一、原理(1)、全加器列出真值表如表所示,若Ai、Bi两个一位二进制数相加,以Ci表示来自低位的的进位,Si表示和,Ci表示向高位的进位,可以看出该电路考虑来低位的进位,是一个一位数的全加器电路,其逻辑符号如图所示。
串并行超前进位加法器的特点是:各级进位信号同时产生,减小或消除因进位信号逐级传递所用的时间。
每一位的进位信号不依赖于从低位逐级传递,而是—开始就能确定。
全加器真值可以得到逻辑表达式:为表达简单,定义两个中间变量Gi和Pi得出得到各位进位信号的逻辑表达式为:当实际位数较多时,往往将全部数位按4位一组分成若干组,组内采用超前进位,组间采用串行进价,组成所谓的串并行进位加法器。
二、算法代码:有4bits.v、8bits.v、testbench.v三个文件;4bits.v实现输入为4位数的加法器;8bits.v中调用4bits.v中的函数来实现8位数相加;testbench.v 为测试代码;实现四位加法4bits.v部分:module fast_adder4b(ina,inb,carry_in,sum_out,clk,rst_n);parameter ADDER_WIDTH=4;parameter SUM_WIDTH=5;input [ADDER_WIDTH-1:0]ina; //输入数ina,8位input [ADDER_WIDTH-1:0]inb; //输入数inb,8位input carry_in;input rst_n;input clk;output [SUM_WIDTH-1:0] sum_out;reg [SUM_WIDTH-1:0] sum_out;wire [ADDER_WIDTH-1:0]sg;wire [ADDER_WIDTH-1:0]sp;wire [ADDER_WIDTH-1:0]sc;assign sg[0]=ina[0]&inb[0]; //中间变量G0=ina0&inb0;assign sg[1]=ina[1]&inb[1];assign sg[2]=ina[2]&inb[2];assign sg[3]=ina[3]&inb[3];assign sp[0]=ina[0]^inb[0]; //中间变量P0=ina0^inb0;assign sp[1]=ina[1]^inb[1];assign sp[2]=ina[2]^inb[2];assign sp[3]=ina[3]^inb[3];assign sc[0]=sg[0]|(sp[0]&carry_in); //进位位C0assign sc[1]=sg[1]|(sp[1]&(sg[0]|(sp[0]&carry_in)));assign sc[2]=sg[2]|(sp[2]&(sg[1]|(sp[1]&(sg[0]|(sp[0]&carry_in)))));assign sc[3]=sg[3]|(sp[3]&(sg[2]|(sp[2]&(sg[1]|(sp[1]&(sg[0]|(sp[0]&carry_in)))))));always@(posedge clk or negedge rst_n)beginif(!rst_n)sum_out<=5'b00000;elsebeginsum_out[0]<=sp[0]^carry_in; //输出结果位sum_out[1]<=sp[1]^sc[0];sum_out[2]<=sp[2]^sc[1];sum_out[3]<=sp[3]^sc[2];sum_out[4]<=sc[3];endendendmodule实现八位加法8bits.v部分:module pipe_adder8b(ina,inb,sum_out,clk,rst_n);parameter ADDER_WIDTH=8;parameter SUM_WIDTH=9;parameter HALF_ADDER_WIDTH=4;input [ADDER_WIDTH-1:0]ina;input [ADDER_WIDTH-1:0]inb;input rst_n;input clk;output[SUM_WIDTH-1:0] sum_out;reg [SUM_WIDTH-1:0] sum_out;reg [HALF_ADDER_WIDTH-1:0] ina_lsb;reg [HALF_ADDER_WIDTH-1:0] ina_msb;reg [HALF_ADDER_WIDTH-1:0] inb_lsb;reg [HALF_ADDER_WIDTH-1:0] inb_msb;reg [HALF_ADDER_WIDTH-1:0] ina_msb1;reg [HALF_ADDER_WIDTH-1:0] inb_msb1;reg [HALF_ADDER_WIDTH:0] sum11;wire[HALF_ADDER_WIDTH:0] sum1;wire[HALF_ADDER_WIDTH:0] sum2;always @(posedge clk or negedge rst_n)beginif(!rst_n)beginina_lsb<=4'b0000;ina_msb<=4'b0000;inb_lsb<=4'b0000;inb_msb<=4'b0000;endelsebeginina_lsb<=ina[3:0];ina_msb<=ina[7:4];inb_lsb<=inb[3:0];inb_msb<=inb[7:4];endendfast_adder4b u1(ina_lsb,inb_lsb,1'b0,sum1,clk,rst_n); //低四位调用4位加法器模块always @(posedge clk or negedge rst_n)beginif(!rst_n)beginina_msb1<=4'b0000;inb_msb1<=4'b0000;endelsebeginina_msb1<=ina_msb;inb_msb1<=inb_msb;endendfast_adder4b u2(ina_msb1,inb_msb1,sum1[4],sum2,clk,rst_n); //高四位调用4位加法器模块always @(posedge clk or negedge rst_n)beginif(!rst_n)sum11<=4'b0000;elsesum11<=sum1;endalways @(posedge clk or negedge rst_n)beginif(!rst_n)sum_out<=9'b0000_00000;elsesum_out<={sum2,sum11[3:0]};endendmoduletestbengch.v部分:`timescale 1ns/1nsmodule test_8a;reg clk,rst_n;reg [7:0]ina,inb;wire [8:0]sum_out;always #20 clk=~clk; //时钟信号40ns一个周期initialbeginrst_n=1;clk=0;#30ina=43; //给a赋值43inb=61;#200 rst_n=0;#40 rst_n=1;#2000 $stop;end//fast_adder4b bbb(.ina(ina),.inb(inb),.carry_in(1'b0),.sum_out(sum_out),.clk(clk),.rst_n(rst_n));pipe_adder8b te(.ina(ina),.inb(inb),.sum_out(sum_out),.clk(clk),.rst_n(rst_n));endmodule三、modelsim软件实现功能仿真三个代码文件compile通过之后,执行simulation;添加待观察端口到波形图wave中,执行simulation->run all命令,在wave波形图中得到以下的仿真波形:四、synplify pro软件综合。
西安邮电大学Verilog HDL实验报告(一)——八位全加器学院名称:电子工程学院班级:学生姓名:学号:实验题目八位全加器一、实验目的:设计的一个八位全加器。
二、实验步骤:1、在ModelSim软件中对激励模块和设计模块进行书写和编译;2、对编译好的模块进行仿真。
三、源代码:1、主程序module fulladder8(c_out,sum,a,b,c_in);output[7:0] sum;output c_out;input [7:0] a,b;input c_in;assign {c_out,sum}=a+b+c_in;endmodule2、激励程序module fulladder8_tb;reg [7:0] A,B;reg C_IN;wire[7:0] SUM;wire C_OUT;fulladder8 fulladder_8(C_OUT,SUM,A,B,C_IN);initialbeginA=8'd10;B=8'd20;C_IN=1;#100;A=8'd30;B=8'd60;C_IN=0;#100;A=8'd88;B=8'd70;C_IN=1;#100;A=8'd29;B=8'd12;C_IN=0;endEndmodule四、仿真结果及分析:输出结果:结果分析:当A=00001010,B=00010100,C_IN=1时,SUM=0001111;当A=00011110,B=0011100,C_IN=0时,SUM=01011010;当A=01011000,B=01000110,C_IN=1时,SUM=10011111;当A=00011101,B=00001100,C_IN=0时,SUM=00101001;由波形可知,SUM=A+B+C_IN;进位则C_OUT = 1六、实验总结:通过这次试验,我学会了八位全加器的实验原理,并将其用软件仿真实现。
8位4级流水线加法器verilog程序module adder8pip(cout,sum,cin,ina,inb,clk);input cin,clk;input[7:0] ina,inb;output cout;output[7:0] sum;reg cout,tempcin;reg[7:0] sum,tempa,tempb;reg firstco,secondco,thirdco; //前三级加法的进位输出reg[1:0] firstsum,thirdina,thirdinb;reg[3:0] secondsum,secondina,secondinb;reg[5:0] thirdsum,firstina,firstinb;always@ (posedge clk)begintempcin=cin;tempa=ina;tempb=inb;//输入数据缓存endalways@ (posedge clk)begin{firstco,firstsum}=tempa[1:0]+tempb[1:0]+tempcin;//第一级低2位相加firstina=tempa[7:2];firstinb=tempb[7:2];//未参加计算的数据缓存endalways@ (posedge clk)begin{secondco,secondsum}={firstina[1:0]+firstinb[1:0]+firstco,firstsum};//第二级2位相加,并与前一级结果合并secondina=firstina[5:2];secondinb=firstinb[5:2];//未参加计算的数据缓存endalways@ (posedge clk)begin{thirdco,thirdsum}={secondina[1:0]+secondinb[1:0]+secondco,secondsum};//第三级2位相加,并与前一级结果合并thirdina=secondina[3:2];thirdinb=secondinb[3:2];//未参加计算的数据缓存endalways@ (posedge clk)begin{cout,sum}={thirdina[1:0]+thirdinb[1:0]+thirdco,thirdsum};//第四级最高2位相加,并与前一级结果合并endendmodule综合之后发现如下警告:FF/Latch (without init value) has a constant value of 0 in block . This FF/Latch will be trimmed during the optimization process. 再看RTL电路图:果然cout被接地了。
数电设计课程设计一、设计目标:设计电路实现2个8位符号数(原码表示)的加减运算,另有一个控制信号select选择加法运算或减法运算,若有溢出则产生溢出指示信号。
二、设计过程:1.推导过程:有符号数的二进制数,可以在补码范围内进行加减运算。
首先将原码转换成补码,再根据select选择信号决定是进行哪一种运算。
若执行减法运算,还需要将被减数变负之后,将减法作为加法处理。
2.分析步骤:原码转补码,先判断数的符号位是正还是负,若为0,则补码等于原码;若符号位为一,则对除符号位以外的每一位取反,再在第一位加一。
补码变负,若sele为低电平,则对被减数B逐位取反再加一,若为高电平,则不执行。
加法原理,观察二进制的加法运算可知,若相同位大小相同,Cin为0,则相加为0,例如 0+0=0,1+1=0,若Cin为1,则有0+0=1,1+1=1,若相同位大小不同,结果刚好相反。
整个过程等效于A[i]^B[i]^Cin。
判断溢出,判断溢出只需要看最高位的Cin和Cout是否相等,若不等,运算发生溢出。
由此需要引进每一位的Cin和Cout,而每一位的Cin即为前一位的Cout,Cout 又是下一位的Cin,所以只需要一个C,就可知道每一位进位情况。
进位只出现在,同位相加产生进位,或者该位相加后与Cin相加产生进位,所以每一位的C可以表示成(A[i]& B[i])|(B[i]&Cin)|(A[i]&Cin)。
三、实现代码:module adder(A,B,SELE,SUM,OVFL);input [7:0] A,B;input SELE;output[7:0] SUM;output OVFL;wire [7:0] c;wire[7:0] A_2s,B_2s,SUM_2s;assign A_2s = (A[7]!=1)?A:(~A[6:0] + 8'b1);assign B_2s=(B[7]!=1)?((SELE)?B:(~B+ 8'b1)):((SELE)?(~B[6:0]+8'b1):(~(~B[6:0]+8'b1)+8'b1));assign SUM_2s[0] = A_2s[0]^B_2s[0]^0,//初始进位为0c[0] = (A_2s[0] & B_2s[0])|(B_2s[0] & 0)|(A_2s[0] & 0);assign SUM_2s[1] = A_2s[1]^B_2s[1]^c[0],c[1] = (A_2s[1] & B_2s[1])|(B_2s[1] & c[0])|(A_2s[1] & c[0]);assign SUM_2s[2] = A_2s[2]^B_2s[2]^ c[1],c[2] = (A_2s[2] & B_2s[2])|(B_2s[2] & c[1])|(A_2s[2] & c[1]);assign SUM_2s[3] = A_2s[3]^B_2s[3]^ c[2],c[3] = (A_2s[3] & B_2s[3])|(B_2s[3] & c[2])|(A_2s[3] & c[2]);assign SUM_2s[4] = A_2s[4]^B_2s[4]^c[3],c[4] = (A_2s[4] & B_2s[4])|(B_2s[4] & c[3])|(A_2s[4] & c[3]);assign SUM_2s[5] = A_2s[5]^B_2s[5]^ c[4],c[5] = (A_2s[5] & B_2s[5])|(B_2s[5] & c[4])|(A_2s[5] & c[4]);assign SUM_2s[6] = A_2s[6]^B_2s[6]^ c[5],c[6] = (A_2s[6] & B_2s[6])|(B_2s[6] & c[5])|(A_2s[6] & c[5]);assign SUM_2s[7] = A_2s[7]^B_2s[7]^ c[6],c[7] = (A_2s[7] & B_2s[7])|(B_2s[7] & c[6])|(A_2s[7] & c[6]);assign SUM = (SUM_2s[7]==1)?(~SUM_2s[6:0] + 8'b1) : SUM_2s;assign OVFL = (c[6]!=c[7]);endmodule四、仿真结果:1.加法运算:选择信号 SELE=1数据1:00011100+00110001(28+49)理论值:01001101(77),未溢出测试值:01001101(77),未溢出数据2:11101101+11011001((-109)+(-89))理论值:00111010(58),溢出测试值:00111010(58),溢出2.减法运算:选择信号SELE=0数据1:00010000-00101000(16-40)理论值:10011000(-24),未溢出测试组:10011000(-24),未溢出数据2:01110000-11101000(112-(-104))理论值:10101000(40),溢出测试值:10101000(40),溢出五、结论及心得该代码能够达到设计目的,完成两个8位原码的加减法,并判断是否溢出。
8位全加器
一、实验目的
用verilog语言编写一个8位全加器,并在modelsim软件上进行仿真。
二、代码
1、源代码:
module add8(sum,cout,in1,in2,cin);
input [7:0] in1,in2;
input cin;
output [7:0] sum;
output cout;
assign {cout,sum}=in1+in2+cin;
endmodule
2、激励:
`timescale 1ns/100ps
module add8_tb;
reg[7:0] A,B;
reg CIN;
wire [7:0] SUM;
wire COUT;
add8 ul(
.sum(SUM),
.cout(COUT),
.in1(A),
.in2(B),
.cin(CIN)
);
initial
begin
A=8'd0;B=8'd0;CIN=1'b0;
#10 A=8'd20;B=8'd129;CIN=1'b1;
#10 A=8'd27;B=8'd19;CIN=1'b0;
#10 A=8'd157;B=8'd29;CIN=1'b0;
#10 A=8'd37;B=8'd68;CIN=1'b0;
#10 A=8'd11;B=8'd69;CIN=1'b0;
#10 A=8'd54;B=8'd67;CIN=1'b1;
#10 A=8'd211;B=8'd0;CIN=1'b0;
#10 A=8'd87;B=8'd43;CIN=1'b1;
#10 A=8'd23;B=8'd171;CIN=1'b0;
#10 A=8'd12;B=8'd12;CIN=1'b1;
#10 A=8'd112;B=8'd115;CIN=1'b0;
end
endmodule
三、实验过程
1、上机过程
2、仿真波形
3、波形说明
波形图中,从上至下依次为:输入加数A、输入加数B、输入进位CIN、输出进位COUT、输出和SUM。
该程序实现的是A+B+CIN=SUM+COUT。
0+0+0=0;
20+129+1=150;
27+19+0=46;
157+29+0=186;
37+68+0=105;
11+69+0=80;
54+67+1=122;
211+0+0=211;
87+43+1=131;
23+171+0=194;
12+12+1=25;
112+115+0=227;
四、实验过程中碰到的问题
1、对于modelsim软件太陌生,在开始实验的时候,经常做完了上一步就忘了下一步是什么,而且对老师反复强调的很多问题也在手忙脚乱间给忽略了,比如,实验一定要在计算机某一个盘里建立一个独立的文件夹,每次都是实验进行到这一步的时候才想起来还没有建这个文件夹,造成很多返工的情况。
2、开始的时候,由于C语言的习惯,程序的注解全部是用汉字写的,还有在实验刚开始时,将独立文件夹建在桌面上,使得程序在运行过程中出现了大量的汉字,最终结果就是程序莫名其妙的报错,还完全找不到错在哪里,不注重细节导致浪费大量时间。
四、实验心得
本次试验带我进入了verilog的大门,虽然磕磕绊绊,但是我发现我还是挺喜欢这样一个过程,我希望自己能认真努力,让自己的学习更进一步,让之后的实验能顺利一点。