Eviews9章条件异方差模型
- 格式:ppt
- 大小:303.50 KB
- 文档页数:24
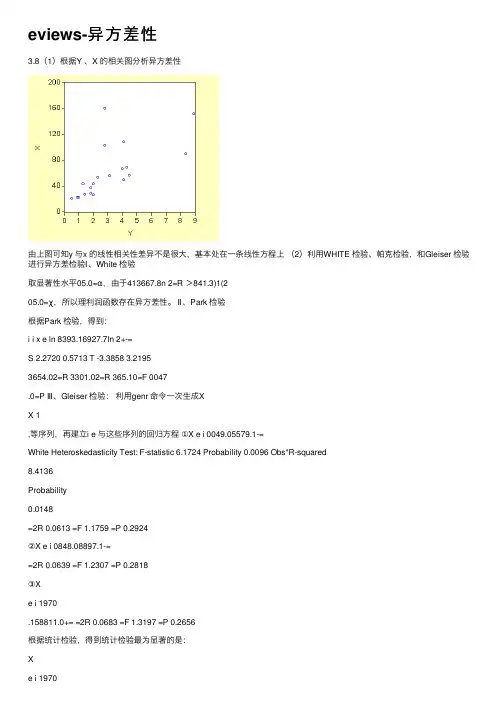
eviews-异⽅差性3.8(1)根据Y 、X 的相关图分析异⽅差性由上图可知y 与x 的线性相关性差异不是很⼤,基本处在⼀条线性⽅程上(2)利⽤WHITE 检验、帕克检验,和Gleiser 检验进⾏异⽅差检验Ⅰ、White 检验取显著性⽔平05.0=α,由于413667.8n 2=R >841.3)1(205.0=χ,所以理利润函数存在异⽅差性。
Ⅱ、Park 检验根据Park 检验,得到:i i x e ln 8393.16927.7ln 2+-=S 2.2720 0.5713 T -3.3858 3.21953654.02=R 3301.02=R 365.10=F 0047.0=P Ⅲ、Gleiser 检验:利⽤genr 命令⼀次⽣成XX 1,等序列,再建⽴i e 与这些序列的回归⽅程①X e i 0049.05579.1-=White Heteroskedasticity Test: F-statistic 6.1724 Probability 0.0096 Obs*R-squared8.4136Probability0.0148=2R 0.0613 =F 1.1759 =P 0.2924②X e i 0848.08897.1-==2R 0.0639 =F 1.2307 =P 0.2818③Xe i 1970.158811.0+= =2R 0.0683 =F 1.3197 =P 0.2656根据统计检验,得到统计检验最为显著的是:Xe i 1970.158811.0+= =2R 0.0683 =F 1.3197 =P 0.2656;上述四个⽅程表明,利润函数存在着异⽅差(只要取显著性⽔平012.0>α)(3)取权数 e 1w 3= 24e1w =利⽤加权最⼩⼆乘法估计模型:依次键⼊命令:4,3,2,1i )(i ==X C Y W W LS或在⽅程窗⼝中点击Estimate\Options 按钮,并在权数变量栏依次输⼊4321W W W W 、、、,可以得到⼀下估计结果:③ X Y 0387.07076.0?+= e 1w 3=S 0.2082 0.0053 T 3.3978 7.2001=2R 0.7422 =2n R 5.0534 =P 0.000001 ④ X Y0429.05918.0?+= 24e 1w = S 0.1283 0.004 T 4.61144 10.49056=2R 0.8594 =2n R 18.0642 =P 0模型④最优,所以利⽤WLS ⽅法估计的利润函数为 X Y 0429.05918.0?+= 2e 1w = S 0.1283 0.004 T 4.6114 10.49=2R 0.8594 =2n R 18.064 =P 03.9设根据某年全国各地区的统计资料建⽴城乡居民储蓄函数i i i bX a S ε++=时(其中,S 为城乡居民储蓄存款余额、X 为⼈均收⼊),如果经检验得知:228.1i i X e =:(1)说明该检验结果的经济含义;(2)写出利⽤加权最⼩⼆乘法估计储蓄函数的具体步骤;(3)写出使⽤Ewiews 软件估计模型时的有关命令。
姓名 学号实验题目 异方差的诊断与修正一、实验目的与要求:要求目的:1、用图示法初步判断是否存在异方差,再用White 检验异方差;2、用加权最小二乘法修正异方差。
二、实验内容根据1998年我国重要制造业的销售利润与销售收入数据,运用EV 软件,做回归分析,用图示法,White 检验模型是否存在异方差,如果存在异方差,运用加权最小二乘法修正异方差。
三、实验过程:(实践过程、实践所有参数与指标、理论依据说明等)(一) 模型设定为了研究我国重要制造业的销售利润与销售收入是否有关,假定销售利润与销售收入之间满足线性约束,则理论模型设定为:i Y =1β+2βi X +i μ其中,i Y 表示销售利润,i X 表示销售收入。
由1998年我国重要制造业的销售收入与销售利润的数据,如图1:1988年我国重要制造业销售收入与销售利润的数据 (单位:亿元)(二) 参数估计Dependent Variable: Y Method: Least Squares Date: 10/19/05 Time: 15:27 Sample: 1 28Included observations: 28Variable Coefficient Std. Error t-Statistic Prob. C 12.03564 19.51779 0.616650 0.5428 X0.1043930.008441 12.366700.0000R-squared 0.854696 Mean dependent var 213.4650 Adjusted R-squared 0.849107 S.D. dependent var 146.4895 S.E. of regression 56.90368 Akaike info criterion 10.98935 Sum squared resid 84188.74 Schwarz criterion 11.08450 Log likelihood -151.8508 F-statistic 152.9353 Durbin-Watson stat1.212795 Prob(F-statistic)0.000000估计结果为: iY ˆ = 12.03564 + 0.104393i X (19.51779) (0.008441) t=(0.616650) (12.36670)2R =0.854696 2R =0.849107 S.E.=56.89947 DW=1.212859 F=152.9353这说明在其他因素不变的情况下,销售收入每增长1元,销售利润平均增长0.104393元。

条件异方差模型
条件异方差模型(ConditionalHeteroskedasticityModels,CHM)是一种用来检验和处理数据中异方差(heteroskedasticity)问题的模型,旨在估计和检验观测数据中异方差的存在,以及其影响程度,来获得更准确的分析结果。
条件异方差模型可分为简单异方差模型和动态异方差模型。
简单异方差模型假设观测值有固定的异方差,而动态异方差模型则假设异方差可以动态变化。
异方差模型通常包括四个步骤:
(1)数据准备:首先,将数据转换为异方差模型可识别的数据格式,其中可能包括数据集的统计量,如平均值,方差,偏度,峰度等;
(2)模型拟合:使用统计模型拟合数据,用于预测观测值的异方差;
(3)异方差识别:利用拟合的模型,采用检验的方法来识别异方差的存在;
(4)异方差处理:对于经识别的异方差,采用最优化的处理办法,以获得更准确和实用的异方差分析结果。
由于条件异方差模型提供了一种有效的方法来理解和处理异方差,因此,它在许多学科中,如财务分析,统计分析,市场营销,投资管理,经济分析等领域中被广泛应用。
- 1 -。

条件异方差模型分析解析第三节自回归条件异方差(ARCH)模型金融时间序列数据通常表现出一种所谓的集群波动现象。
模型随机误差项中同时含有自相关和异方差。
一、ARCH 模型(Auto-regressive Conditional Heteroskedastic —自回归条件异方差模型)对于回归模型t kt k t t x b x b b y ε++++= 110 (3.3.1)若2t ε服从AR (q )过程t q t q t t νεαεααε++++=--221102 (3.3.2)其中tν独立同分布,并满足0)(=t E ν , 2)(σν=tD 则称(3.3.2)式为ARCH 模型,序列t ε服从q 阶ARCH 过程,记为t ε~ARCH (q )。
(3.3.1)和(3.3.2)称为回归—ARCH 模型。
注:不同时点t ε的方差2)(tt D σε=是不同的。
对于AR (p )模型t p t p t t y y y εφφ+++=-- 11 (3.3.3)如果tε~ARCH (q ),则(3.3.3)与(3.3.2)结合称为AR (p )-ARCH (q )模型。
ARCH (q )模型还可以表示为 *t t h = εt ν (3.3.4) 21022110j t q j q t q t t h -=--∑+=+++=εααεαεααα (3.3.5)其中,tν独立同分布,且0)(=t E ν,1)(=t D ν,00>α 0≥j α)2,1(q j = 且11<∑=q j j α(保证ARCH 平稳)。
有时,(3.3.5)式等号右边还可以包括外生变量,但要注意应保证th 值是非负的。
如:p t p t q t q t t h h h ----++++++=θθεαεαα 1122110 1011<+<∑∑==p j j q i iθα对于任意时刻t ,条件期望E (tε| ,1-t ε)=0)(*=t t E h ν (3.3.6)条件方差t t t t t h E h E ==-)(*),|(2212νεσ (3.3.7)(3.3.7)式反映了序列条件方差随时间而变化。

异方差的eviews操作图3-1 我国制造工业销售利润与销售收入相关图从图中可以看出,随着销售收入的增加,销售利润的平均水平不断提高,但离散程度也逐步扩大。
这说明变量之间可能存在递增的异方差性。
⑵残差分析首先将数据排序(命令格式为:SORT 解释变量),然后建立回归方程。
在方程窗口中点击Resids按钮就可以得到模型的残差分布图(或建立方程后在Eviews工作文件窗口中点击resid对象来观察)。
图3-2 我国制造业销售利润回归模型残差分布图3-2显示回归方程的残差分布有明显的扩大趋势,即表明存在异方差性。
2、Goldfeld-Quant检验⑴将样本安解释变量排序(SORT X)并分成两部分(分别有1到10共11个样本合19到28共10个样本)⑵利用样本1建立回归模型1(回归结果如图3-3),其残差平方和为2579.587。
SMPL 1 10LS Y C X图3-3 样本1回归结果⑶利用样本2建立回归模型2(回归结果如图3-4),其残差平方和为63769.67。
SMPL 19 28 LS Y C X图3-4 样本2回归结果⑷计算F 统计量:12/RSS RSS F ==63769.67/2579.59=24.72,21RSS RSS 和分别是模型1和模型2的残差平方和。
取05.0=α时,查F 分布表得44.3)1110,1110(05.0=----F ,而44.372.2405.0=>=F F ,所以存在异方差性3、White 检验⑴建立回归模型:LS Y C X ,回归结果如图3-5。
图3-5 我国制造业销售利润回归模型⑵在方程窗口上点击View\Residual\Test\White Heteroskedastcity,检验结果如图3-6。
图3-6 White 检验结果其中F 值为辅助回归模型的F 统计量值。
取显著水平05.0=α,由于2704.699.5)2(2205.0=<=nR χ,所以存在异方差性。

第四章异方差性例4.1.4一、参数估计进入Eviews软件包,确定时间范围,编辑输入数据;选择估计方程菜单:(1)在Workfile对话框中,由路径:Quick/Estimate Equation,进入Equation Specification对话框,键入“log(y) c log(x1) log(x2)”,确认ok,得到样本回归估计结果;(2)直接在命令栏里输入“ls log(y) c log(x1) log(x2)”,按Enter,得到样本回归估计结果;(3)在Group的当前窗口,由路径:Procs/Make Equation,进入Equation Specification窗口,键入“log(y) c log(x1) log(x2)”,确认ok,得到样本回归估计结果。
如表4.1:表4.1图4.1估计结果为:(3.14) (1.38) (9.25)R2=0.7798 D.W.=1.78 F=49.60 RSS=0.8357括号内为t统计量值。
二、检验模型的异方差(一)图形法(1)生成残差平方序列。
①在Workfile的对话框中,由路径:Procs/Generate Series,进入Generate Series by Equation对话框,键入“e2=resid^2”,生成残差平方项序列e2;②直接在命令栏里输入“genr e2=resid^2”,按Enter,得到残差平方项序列e2。
(2)绘制散点图。
①直接在命令框里输入“scat log(x2) e2”,按Enter,可得散点图4.2。
②选择变量名log(x2)与e2(注意选择变量的顺序,先选的变量将在图形中表示横轴,后选的变量表示纵轴),再按路径view/graph/scatter/simple scatter ,可得散点图4.2。
③由路径quick/graph进入series list窗口,输入“log(x2) e2”,确认并ok,再在弹出的graph窗口把line graph换成scatter diagram,再点ok,可得散点图4.2。


田青帆1006010131 国贸1001班建立模型Y t=β1+β2X t+uX:1994-2011年中国国内生产总值Y:1994-2011年中国进口总额数据来源:国泰安数据服务中心/p/sq/一、异方差的检验1、图示法由上图可以看出,残差平方项e2随X的变动而变动,一次,模型很可能存在异方差,但是否确实存在异方差还应通过更进一步的检验。
2、等级相关系数检验t值为29.48788,自由度为18-2=16在95%的显著水平下,查表可得t0.025(16)=2.1199t>t0.025(16),说明X i和|e i|之间存在系统关系,则说明模型中存在异方差3、戈德菲尔德-夸特检验(样本分段比检验)在本例中,样本容量为18,删去中间4个观测值,余下部分平分的两个样本区间:1-7和12-18,他们的样本数都是7个,用OLS方法对这两个子样本进行回归估计,结果如下图所示计算检验统计量FF=[RSS2/(n2-k)] ÷[RSS1/(n1-k)]n2-k=n1-k=7-2=5F=RSS2/RSS1=4588102/229037.4=20.03在95%的显著水平下,查表可得F0.05(5,5)=5.05 F>F0.05(5,5)所以,模型存在异方差4、戈里瑟(Glejser)检验用残差绝对值建立的回归模型为|e i|=α1+α2 (1/X i)由上表可知,回归模型为|e i|=1416.049+10.37101(1/X i)≠0,则存在异方差α25、怀特检验由上图可知:P值=0.017140﹤0.05,所以存在异方差二、异方差的修正(加权最小二乘法)1、选择1/x为权数,即对模型两边同时乘以1/x,使用最小二乘法进行回归估计,所得结果如下:由上图可知,P值=0.0001﹤0.05,模型依然存在异方差2、选择1/|e|为权数,即对模型两边同时乘以1/|e|,使用最小二乘法进行回归估计,所得结果如下:此时,P值=0.2139>0.05,将异方差模型变成了同方差。


eviews异方差、自相关检验与解决办法一、异方差检验:1.相关图检验法LS Y C X 对模型进行参数估计GENR E=RESID 求出残差序列GENR E2=E^2 求出残差的平方序列SORT X 对解释变量X排序SCAT X E2 画出残差平方与解释变量X的相关图2.戈德菲尔德——匡特检验已知样本容量n=26,去掉中间6个样本点(即约n/4),形成两个样本容量均为10的子样本。
SORT X 将样本数据关于X排序SMPL 1 10 确定子样本1LS Y C X 求出子样本1的回归平方和RSS1SMPL 17 26 确定子样本2LS Y C X 求出子样本2的回归平方和RSS2计算F统计量并做出判断。
解决办法3.加权最小二乘法LS Y C X 最小二乘法估计,得到残差序列GRNR E1=ABS(RESID) 生成残差绝对值序列LS(W=1/E1) Y C X 以E1为权数进行加权最小二成估计二、自相关1.图示法检验LS Y C X 最小二乘法估计,得到残差序列GENR E=RESID 生成残差序列SCAT E(-1) E et—et-1的散点图PLOT E 还可绘制et的趋势图2.广义差分法LS Y C X AR(1) AR(2)首先,你要对广义差分法熟悉,不是了解,如果你是外行,我奉劝你还是用eviews来做就行了,其实我想老师要你用spss无非是想看你是否掌握广义差分,好了,废话不多说了。
接着,使用spss16来解决自相关。
第一步,输入变量,做线性回归,注意在Liner Regression 中的Statistics中勾上DW,在save中勾Standardized,查看结果,显然肯定是有自相关的(看dw值)。
第二步,做滞后一期的残差,直接COPY数据(别告诉我不会啊),然后将残差和滞后一期的残差做回归,记下它们之间的B指(就是斜率)。
第三步,再做滞后一期的X1和Y1,即自变量和因变量的滞后一期的值,也是直接COPY。

实验一异方差性【实验目的】掌握异方差性问题出现的来源、后果、检验及修正的原理,以及相关的Eviews操作方法。
【实验内容】以《计量经济学学习指南与练习》补充习题4-16为数据,练习检查和克服模型的异方差的操作方法。
【4-16】表4-1给出了美国18个行业1988年研究开发(R&D)费用支出丫与销售收入X 的数据。
请用帕克(Park)检验、戈里瑟(Gleiser)检验、G-Q检验与怀特(White)检验来检验丫关于X的回归模型是否存在异方差性?若存在异方差性,请尝试消除它。
【实验步骤】一■检查模型是否存在异方差性1、图形分析检验(1)散点相关图分析做出销售收入X与研究开发费用丫的散点相关图(SCAT X 丫)。
观察相关图可以看出,随着销售收入的增加,研究开发费用的平均水平不断提高,但离散程度也逐步扩大。
这说明变量之间可能存在递增的异方差性。
0 50,000 100,000 150,000 200.000 250,000(2)残差图分析首先对数据按照解释变量X 由小至大进行排序(SORT X ),然后建立一元线 性回归方程(LS 丫 C X )。
Dependentvariable: Y Method: Least Squares Date: 12/06/11 Time : 23:08 Sample: 1 17Included obseivations: 17VariableCo EfficientStd. Errort-StallStic Prob C 187.5068 1106.681 0.169432 0.8677 X0.031993 0.0111112 8793580.0115 R-squared0.355966 Mean dependent var 2676.188 Adjusted R-squared 0.313031 S.D. dependent var3438.207 S.E. of regression 2849711 Aka ike Info criterion 13.85795 Sum squared resid 1 22E+O0 Schwarz criterion 18.95698 Log likelihood -158.2926 Hannan-Quinn criter. 18.86770 F-statistic8.290703 Durbin-Watson stat2.738533Prob(F-statistic)0.011464因此,模型估计式为:丫 =187.507 0.032* X ------- (*)2 (0.17)(2.88)R 2=0.31s.e.=2850F=0.011建立残差关于X 的散点图,可以发现随着X 增加,残差呈现明显的扩大 趋势,表明存在递增的异方差。