正则表达式全部符号解释
- 格式:doc
- 大小:65.50 KB
- 文档页数:4

php中正则表达式中的特殊符号字符/意义:对于字符,通常表⽰按字⾯意义,指出接着的字符为特殊字符,不作解释。
例如:/b/匹配字符'b',通过在b 前⾯加⼀个反斜杠,也就是/b/,则该字符变成特殊字符,表⽰匹配⼀个单词的分界线。
或者:对于⼏个字符,通常说明是特殊的,指出紧接着的字符不是特殊的,⽽应该按字⾯解释。
例如:*是⼀个特殊字符,匹配任意个字符(包括0个字符);例如:/a*/意味匹配0个或多个a。
为了匹配字⾯上的*,在a前⾯加⼀个反斜杠;例如:/a*/匹配'a*'。
字符^意义:表⽰匹配的字符必须在最前边。
例如:/^A/不匹配"an A,"中的'A',但匹配"An A."中最前⾯的'A'。
字符$意义:与^类似,匹配最末的字符。
例如:/t$/不匹配"eater"中的't',但匹配"eat"中的't'。
字符*意义:匹配*前⾯的字符0次或n次。
例如:/bo*/匹配"A ghost booooed"中的'boooo'或"A bird warbled"中的'b',但不匹配"Agoat grunted"中的任何字符。
字符+意义:匹配+号前⾯的字符1次或n次。
等价于{1,}。
例如:/a+/匹配"candy"中的'a'和"caaaaaaandy."中的所有'a'。
字符?意义:匹配?前⾯的字符0次或1次。
例如:/e?le?/匹配"angel"中的'el'和"angle."中的'le'。
字符.意义:(⼩数点)匹配除换⾏符外的所有单个的字符。
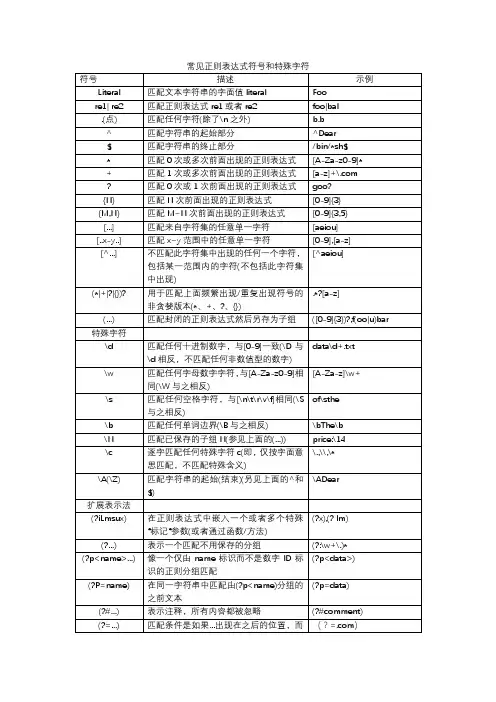

正则表达式中常见的基本符号一、元字符。
1. 点号(.)- 含义:匹配除换行符之外的任何单个字符。
- 原因:在正则表达式中,点号是一个非常通用的匹配单个字符的符号。
例如,在模式“a.c”中,它可以匹配“abc”“a c”“a!c”等,只要中间是一个除换行符以外的字符就可以匹配成功。
这在处理一些格式不太固定但有部分固定内容的文本时非常有用。
2. 星号(*)- 含义:匹配前面的元素零次或多次。
- 原因:它主要用于表示某个字符或字符组可以出现任意次数(包括零次)。
例如,“ab*”可以匹配“a”(因为b出现零次)、“ab”、“abb”、“abbb”等。
在处理像电话号码中可选的区号部分或者某个单词的复数形式(其中字母可能重复多次)等情况时会用到。
3. 加号(+)- 含义:匹配前面的元素一次或多次。
- 原因:与星号类似,但至少要求前面的元素出现一次。
例如,“ab+”可以匹配“ab”、“abb”、“abbb”等,但不能匹配“a”,因为这里的b必须至少出现一次。
在验证密码强度时,如果要求密码中必须包含至少一个数字,可以使用类似“[0 - 9]+”的模式。
4. 问号(?)- 含义:匹配前面的元素零次或一次。
- 原因:用于表示某个字符或字符组是可选的。
例如,“colou?r”可以匹配“color”和“colour”,因为u是可选的。
在处理不同的拼写变体或者可选的语法结构时很有用。
二、字符类相关符号。
1. 方括号([])- 含义:定义一个字符类,匹配方括号内的任意一个字符。
- 原因:这是一种指定多个可能字符的简洁方式。
例如,“[aeiou]”可以匹配任何一个元音字母。
可以在方括号内使用范围表示法,如“[a - z]”匹配任何小写字母,“[0 - 9]”匹配任何数字。
这种方式在验证输入是否为特定类型的字符(如字母、数字、特定符号等)时非常常见。
2. 脱字符(^)在字符类中的用法。
- 含义:当脱字符在字符类的开头时,表示否定该字符类,即匹配除了字符类中字符以外的任何字符。

中文符号正则表达式一、校验数字的表达式数字:^[0-9]*$n位的数字:^\d{n}$至少n位的数字:^\d{n,}$m-n位的数字:^\d{m,n}$零和非零开头的数字:^(0|[1-9][0-9]*)$非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})?$正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$有两位小数的正实数:^[0-9]+(.[0-9]{2})?$有1~3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$非零的正整数:^[1-9]\d*$ 或^([1-9][0-9]*){1,3}$ 或^\+?[1-9][0-9]*$非零的负整数:^\-[1-9][]0-9"*$ 或^-[1-9]\d*$非负整数:^\d+$ 或^[1-9]\d*|0$非正整数:^-[1-9]\d*|0$ 或^((-\d+)|(0+))$非负浮点数:^\d+(\.\d+)?$ 或^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[ 1-9][0-9]*))$负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9] *[1-9][0-9]*)))$浮点数:^(-?\d+)(\.\d+)?$ 或^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$二、校验字符的表达式汉字:^[\u4e00-\u9fa5]{0,}$英文和数字:^[A-Za-z0-9]+$ 或^[A-Za-z0-9]{4,40}$长度为3-20的所有字符:^.{3,20}$由26个英文字母组成的字符串:^[A-Za-z]+$由26个大写英文字母组成的字符串:^[A-Z]+$由26个小写英文字母组成的字符串:^[a-z]+$由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或^\w{3,20}中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+禁止输入含有~的字符[^~\x22]+其它:.*匹配除 \n 以外的任何字符。


正则表达式所有标点符号
在正则表达式中,标点符号不仅是用来分隔不同的字符和子表达式的,它们还有特定的含义和用法。
以下是正则表达式中所有标点符号的含义及用法:
1. ^:表示匹配字符串的开始位置,例如 ^a 表示以字母 a 开
始的字符串。
2. $:表示匹配字符串的结束位置,例如 a$ 表示以字母 a 结
尾的字符串。
3. .:匹配任意一个字符,例如 a.b 可以匹配 aab、acb、a1b 等。
4. *:匹配前面的字符出现任意多次,例如 ab*c 可以匹配 ac、abc、abbc、abbbc 等。
5. +:匹配前面的字符出现至少一次,例如 ab+c 可以匹配 abc、abbc、abbbc 等。
6. ?:匹配前面的字符出现零次或一次,例如 ab?c 可以匹配 ac、abc 等。
7. []:表示字符集合,可以匹配其中任意一个字符,例如 [abc] 可以匹配 a、b、c 中任何一个字符。
8. [^]:表示取反字符集合,可以匹配除了其中任何一个字符以外的字符,例如 [^abc] 可以匹配除了 a、b、c 以外的任意一个字符。
9. ():表示分组,可以对其中的字符进行分组提取,例如 (ab)+c 表示匹配一个或多个 ab 后面跟着字母 c。
10. {}:表示重复次数,可以匹配前面的字符重复出现的次数,例如 a{2,5}c 表示匹配两个到五个 a 后面跟着字母 c。
11. |:表示或者,可以匹配其中任意一个子表达式,例如 a|b|c 表示匹配 a、b、c 中任意一个字符。
以上是正则表达式中所有标点符号的含义及用法,熟练掌握它们可以帮助你更高效地编写正则表达式。


js正则表达式符号含义\ 做为转意,即通常在"\"后⾯的字符不按原来意义解释,如/b/匹配字符"b",当b前⾯加了反斜杆后/\b/,转意为匹配⼀个单词的边界。
-或-对正则表达式功能字符的还原,如"*"匹配它前⾯元字符0次或多次,/a*/将匹配a,aa,aaa,加了"\"后,/a\*/将只匹配"a*"。
^ 匹配⼀个输⼊或⼀⾏的开头,/^a/匹配"an A",⽽不匹配"An a"$ 匹配⼀个输⼊或⼀⾏的结尾,/a$/匹配"An a",⽽不匹配"an A"* 匹配前⾯元字符0次或多次,/ba*/将匹配b,ba,baa,baaa+ 匹配前⾯元字符1次或多次,/ba*/将匹配ba,baa,baaa? 匹配前⾯元字符0次或1次,/ba*/将匹配b,ba(x) 匹配x保存x在名为$1...$9的变量中x|y 匹配x或y{n} 精确匹配n次{n,} 匹配n次以上{n,m} 匹配n-m次[xyz] 字符集(character set),匹配这个集合中的任⼀⼀个字符(或元字符)[^xyz] 不匹配这个集合中的任何⼀个字符[\b] 匹配⼀个退格符\b 匹配⼀个单词的边界\B 匹配⼀个单词的⾮边界\cX 这⼉,X是⼀个控制符,/\cM/匹配Ctrl-M\d 匹配⼀个字数字符,/\d/ = /[0-9]/\D 匹配⼀个⾮字数字符,/\D/ = /[^0-9]/\n 匹配⼀个换⾏符\r 匹配⼀个回车符\s 匹配⼀个空⽩字符,包括\n,\r,\f,\t,\v等\S 匹配⼀个⾮空⽩字符,等于/[^\n\f\r\t\v]/\t 匹配⼀个制表符\v 匹配⼀个重直制表符\w 匹配⼀个可以组成单词的字符(alphanumeric,这是我的意译,含数字),包括下划线,如[\w]匹配"$5.98"中的5,等于[a-zA-Z0-9] \W 匹配⼀个不可以组成单词的字符,如[\W]匹配"$5.98"中的$,等于[^a-zA-Z0-9]。

正则表达式-语法⼤全1. 正则表达式规则1.1 普通字符字母、数字、汉字、下划线、以及后边章节中没有特殊定义的标点符号,都是"普通字符"。
表达式中的普通字符,在匹配⼀个字符串的时候,匹配与之相同的⼀个字符。
,匹配结果是:成功;匹配到的内容是:"c";匹配到的位置是:开始于2,结束于3。
(注:下标从0开始还是从1开始,因当前编程语⾔的不同⽽可能不同),匹配结果是:成功;匹配到的内容是:"bcd";匹配到的位置是:开始于1,结束于4。
1.2 简单的转义字符⼀些不便书写的字符,采⽤在前⾯加 "/" 的⽅法。
这些字符其实我们都已经熟知了。
表达式可匹配/r, /n代表回车和换⾏符/t制表符//代表 "/" 本⾝还有其他⼀些在后边章节中有特殊⽤处的标点符号,在前⾯加 "/" 后,就代表该符号本⾝。
⽐如:^, $ 都有特殊意义,如果要想匹配字符串中 "^" 和 "$" 字符,则表达式就需要写成 "/^" 和 "/$"。
表达式可匹配/^匹配 ^ 符号本⾝/$匹配 $ 符号本⾝/.匹配⼩数点(.)本⾝这些转义字符的匹配⽅法与 "普通字符" 是类似的。
也是匹配与之相同的⼀个字符。
,匹配结果是:成功;匹配到的内容是:"$d";匹配到的位置是:开始于3,结束于5。
1.3 能够与 '多种字符' 匹配的表达式正则表达式中的⼀些表⽰⽅法,可以匹配 '多种字符' 其中的任意⼀个字符。
⽐如,表达式 "/d" 可以匹配任意⼀个数字。
虽然可以匹配其中任意字符,但是只能是⼀个,不是多个。
这就好⽐玩扑克牌时候,⼤⼩王可以代替任意⼀张牌,但是只能代替⼀张牌。

正则表达式基本符号:^ 表示匹配字符串的开始位置 (例外用在中括号中[ ] 时,可以理解为取反,表示不匹配括号中字符串)$ 表示匹配字符串的结束位置* 表示匹配零次到多次+ 表示匹配一次到多次 (至少有一次)表示匹配零次或一次. 表示匹配单个字符| 表示为或者,两项中取一项( ) 小括号表示匹配括号中全部字符[ ] 中括号表示匹配括号中一个字符范围描述如[0-9 a-z A-Z]{ } 大括号用于限定匹配次数如 {n}表示匹配n个字符 {n,}表示至少匹配n个字符{n,m}表示至少n,最多m\ 转义字符如上基本符号匹配都需要转义字符如 \* 表示匹配*号\w 表示英文字母和数字 \W 非字母和数字\d 表示数字 \D 非数字常用的正则表达式匹配中文字符的正则表达式: [\u4e00-\u9fa5]匹配双字节字符(包括汉字在内):[^\x00-\xff]匹配空行的正则表达式:\n[\s| ]*\r匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/匹配首尾空格的正则表达式:(^\s*)|(\s*$)匹配IP地址的正则表达式:/(\d+)\.(\d+)\.(\d+)\.(\d+)/g //匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*匹配网址URL的正则表达式:http://(/[\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?sql语句:^(select|drop|delete|create|update|insert).*$1、非负整数:^\d+$2、正整数:^[0-9]*[1-9][0-9]*$3、非正整数:^((-\d+)|(0+))$4、负整数:^-[0-9]*[1-9][0-9]*$5、整数:^-?\d+$6、非负浮点数:^\d+(\.\d+)?$7、正浮点数:^((0-9)+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$8、非正浮点数:^((-\d+\.\d+)?)|(0+(\.0+)?))$9、负浮点数:^(-((正浮点数正则式)))$10、英文字符串:^[A-Za-z]+$11、英文大写串:^[A-Z]+$12、英文小写串:^[a-z]+$13、英文字符数字串:^[A-Za-z0-9]+$14、英数字加下划线串:^\w+$15、E-mail地址:^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$16、URL:^[a-zA-Z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\s*)?$ 或:^http:\/\/[A-Za-z0-9]+\.[A-Za-z0-9]+[\/=\?%\-&_~`@[\]\':+!]*([^<>\"\"])*$17、邮政编码:^[1-9]\d{5}$18、中文:^[\u0391-\uFFE5]+$19、电话号码:^((\d2,3)|(\d{3}\-))?(0\d2,3|0\d{2,3}-)?[1-9]\d{6,7}(\-\d{1,4})?$20、手机号码:^((\d2,3)|(\d{3}\-))?13\d{9}$21、双字节字符(包括汉字在内):^\x00-\xff22、匹配首尾空格:(^\s*)|(\s*$)(像vbscript那样的trim函数)23、匹配HTML标记:<(.*)>.*<\/\1>|<(.*) \/>24、匹配空行:\n[\s| ]*\r25、提取信息中的网络链接:(h|H)(r|R)(e|E)(f|F) *=*('|")?(\w|\\|\/|\.)+('|"| *|>)?26、提取信息中的邮件地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*27、提取信息中的图片链接:(s|S)(r|R)(c|C) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?28、提取信息中的IP地址:(\d+)\.(\d+)\.(\d+)\.(\d+)29、提取信息中的中国手机号码:(86)*0*13\d{9}30、提取信息中的中国固定电话号码:(\d3,4|\d{3,4}-|\s)?\d{8}31、提取信息中的中国电话号码(包括移动和固定电话):(\d3,4|\d{3,4}-|\s)?\d{7,14}32、提取信息中的中国邮政编码:[1-9]{1}(\d+){5}33、提取信息中的浮点数(即小数):(-?\d*)\.?\d+34、提取信息中的任意数字:(-?\d*)(\.\d+)?35、IP:(\d+)\.(\d+)\.(\d+)\.(\d+)36、电话区号:/^0\d{2,3}$/37、腾讯QQ号:^[1-9]*[1-9][0-9]*$38、帐号(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$39、中文、英文、数字及下划线:^[\u4e00-\u9fa5_a-zA-Z0-9]+$。

正则表达式表示各个字符的用法
1.字母和数字:
-`[a-z]`:匹配任何小写字母
-`[A-Z]`:匹配任何大写字母
-`[0-9]`:匹配任何数字
2.元字符:
-`.`:匹配任何字符
-`\d`:匹配任何数字,等同于`[0-9]`
-`\D`:匹配任何非数字字符,等同于`[^0-9]`
-`\w`:匹配任何字母、数字或下划线字符,等同于`[a-zA-Z0-9_]` -`\W`:匹配任何非字母、数字或下划线字符,等同于`[^a-zA-Z0-9_]`
-`\s`:匹配任何空白字符,包括空格、制表符、换页符等
-`\S`:匹配任何非空白字符
3.重复符号:
-`*`:匹配前面的元素零次或多次
-`+`:匹配前面的元素一次或多次
-`?`:匹配前面的元素零次或一次
-`{n}`:匹配前面的元素恰好出现n次
-`{n,}`:匹配前面的元素至少出现n次
-`{n,m}`:匹配前面的元素出现n到m次
4.定位符:
-`^`:匹配字符串的开头
-`$`:匹配字符串的结尾
-`\b`:匹配单词的边界
-`\B`:匹配非单词的边界
5.字符类:
-`[...]`:匹配括号中的任意一个字符
-`[^...]`:匹配除括号中的任意一个字符以外的字符
除了上述用法外,正则表达式还支持一些特殊字符组合和转义字符的使用,例如`[a-z\d]`可匹配任何小写字母或数字的字符。
具体用法可以参考正则表达式的语法规则和具体编程语言的正则表达式函数的文档。
正则表达式语法或者符号语法正则表达式是一种用于匹配字符串的模式,通常用于文本搜索、替换和验证等操作。
它是由一些特殊字符和元字符组成的语法,用于描述字符串的结构和模式。
正则表达式的基本符号包括:1. 点号(.):匹配任意单个字符,除了换行符。
2. 加号(+):匹配前面的子表达式一次或多次。
3. 星号(*):匹配前面的子表达式零次或多次。
4. 问号(?):匹配前面的子表达式零次或一次。
5. 方括号([]):定义一个字符集合,匹配其中的任意一个字符。
6. 大括号({}):定义一个重复次数的范围,匹配指定次数的前面的子表达式。
7. 圆括号(()):将多个表达式组合成一个整体,用于分组或优先级控制。
8. 竖线(|):表示逻辑“或”,匹配左右两边的任意一个表达式。
9. 反斜杠(\):转义特殊字符,使其失去特殊含义。
10. 插入符号(^):匹配字符串的开头。
11. $符号:匹配字符串的结尾。
12. 百分号(%):匹配任意数量的非换行字符。
13. 数字符号(\d):匹配任意数字字符,等同于[0-9]。
14. 字母符号(\w):匹配任意字母、数字或下划线字符,等同于[A-Za-z0-9_]。
15. 空白符号(\s):匹配任意空白字符,包括空格、制表符、换行符等。
16. 非空白符号(\S):匹配任意非空白字符。
17. 单词边界符号(b):匹配单词的边界,即字母、数字或下划线字符与非字母、非数字、非下划线字符之间的边界。
18. Unicode属性符号(p{Property}):匹配Unicode属性,如汉字、字母等。
以上是正则表达式的一些基本符号,通过这些符号的组合可以构建出复杂的模式来匹配各种字符串。
以下是一些常用的正则表达式语法:1. 字符匹配:直接使用字符进行匹配,例如`a`可以匹配字符"a",`abc`可以匹配字符串"abc"。
2. 点号通配符:`.`可以匹配任何单个字符(除换行符外),`\.`可以匹配实际的点号字符。
正则表达式的基本符号
正则表达式是一种用于匹配和处理文本字符串的工具,它使用一系列的特殊符号和元字符来描述、定位和操作文本模式。
以下是一些正则表达式中常见的基本符号:
1. 字符组([]):用于匹配指定范围内的任意单个字符。
例如,[abc]匹配a、b 或c中的任意一个字符。
2. 范围(-):在字符组内指定连续范围的字符。
例如,[a-z]匹配从a到z之间的任意一个小写字母。
3. 元字符(.):匹配除换行符以外的任意单个字符。
例如,a.b可以匹配"aab"、"acb"等。
4. 重复符号(*, +, ?):用于指定模式重复出现的次数。
*表示前面的模式可以出现0次或多次,+表示前面的模式可以出现1次或多次,?表示前面的模式可以出现0次或1次。
5. 边界符(^, $):用于指定模式的边界。
^表示匹配行的开头,$表示匹配行的结尾。
6. 转义符(\):用于将特殊字符转义为普通字符。
例如,\.表示匹配实际的点字符。
7. 分组和捕获(())
在正则表达式中使用括号创建一个子表达式,并且可以对该子表达式进行分组、捕获或重复次数限定。
8. 或(|):用于在多个模式之间进行选择。
例如,(apple|banana)可以匹配"apple"或"banana"。
这只是正则表达式的基本符号的一小部分。
正则表达式还有更多的高级符号和操作符,用于完成更复杂的匹配和处理任务。
学习正则表达式需要更深入的了解和实践,有效地应用于具体的文本处理需求。
正则表达式常⽤符号和字符正则表达式正则表达式是由⼀些字符和特殊符号组成的字符串,他们描述了模式的重复或表述多个字符,于是正则表达式能按照某种模式匹配⼀系列有相似特征的字符串。
也即它们能匹配多个字符串。
常⽤特殊字符和符号0.择⼀匹配(|)| 从多个模式中选择其⼀,类似于逻辑或,例如: 正则表达式匹配的字符串 apple|orange apple,orangecpp|java|python cpp,java,python1.任意匹配单个字符(.). 匹配除了换⾏符\n以外的任意字符,例如: 正则表达式匹配的字符串 a.c a(任意字符)c..任意两个字符2.从字符串开始或结尾或单词边界匹配(^) ($) (\b) (\B)^或\A接字符串,表⽰以该字符串开始(区别:^匹配⼀⾏的开始,\A匹配输⼊的开始)$或\Z接字符串,表⽰以该字符串结尾(同上)\b接字符串,表⽰以该字符串开始(区别于^和\A:匹配⼀个单词起始部分,不管该单词前⾯是否有任何字符。
通俗来说:^匹配字符串的开始,\b匹配单词的开始)\B接字符串,表⽰以该字符串为⼦串但不是边界 正则表达式匹配的字符串 ^in 任何以in开头的字符串com$任何以com结尾的字符串the 任何包含the的字符串 \bthe 任何以the开始的字符串 \bthe\b单词zhe \Bthe任何包含但不以the开始的字符串 the\B任何包含但不以the结尾的字符串3.创建字符集,类似于择⼀匹配([])([])⽤于匹配某些特定字符,区别于(.)匹配任意字符,匹配⽅括号中包含的任意字符。
正则表达式匹配的字符串 c[abcd]d cad,cbd,ccd,cdd[cp][jv][py] cjp,pjp,cvp,cvy,pjp,pjy4.限定范围或否定 (-)([^])⽅括号中两个字符以-符号连接表⽰指定⼀个范围,在连接的字符之中。
⽅括号中紧紧连接^符号表⽰不匹配给定字符集任⼀字符 正则表达式匹配的字符串 [a-c][d-f] ad,ae,af,bd,be,bf,cd,ce,cf,[^aeiou]⼀个⾮元⾳字符[^\t\n]不匹配制表符或换⾏符5.零次,⼀次或多次匹配(*) (+) (?) ;频数匹配 {M} {M,N} {M,} *将匹配其左边的正则表达式出现零次或多次的情况。
正则表达式⽤法详解正则表达式之基本概念在我们写页⾯时,往往需要对表单的数据⽐如账号、⾝份证号等进⾏验证,⽽最有效的、⽤的最多的便是使⽤正则表达式来验证。
那什么是正则表达式呢?正则表达式(Regular Expression)是⽤于描述⼀组字符串特征的模式,⽤来匹配特定的字符串。
它的应⽤⾮常⼴泛,特别是在字符串处理⽅⾯。
其常见的应⽤如下:验证字符串,即验证给定的字符串或⼦字符串是否符合指定的特征,例如,验证是否是合法的邮件地址、验证是否是合法的HTTP地址等等。
查找字符串,从给定的⽂本当中查找符合指定特征的字符串,这样⽐查找固定字符串更加灵活。
替换字符串,即查找到符合某特征的字符串之后将之替换。
提取字符串,即从给定的字符串中提取符合指定特征的⼦字符串。
第⼀部分:正则表达式之⼯具正所谓⼯欲善其事必先利其器! 所以我们需要知道下⾯⼏个主要的⼯具:第⼆部分:正则表达式之元字符正则表达式中元字符恐怕是我们听得最多的了。
元字符(Metacharacter)是⼀类⾮常特殊的字符,它能够匹配⼀个位置或者字符集合中的⼀个字符。
如.、\w等都是元字符。
刚刚说到,元字符既可以匹配位置,也可以匹配字符,那么我们就可以通过此来将元字符分为匹配位置的元字符和匹配字符的元字符。
A匹配位置的元字符---^、$、\b即匹配位置的元字符只有^(脱字符号)、$(美元符号)和\b这三个字符。
分别匹配⾏的开始、⾏的结尾以及单词的开始或结尾。
它们匹配的都只是位置。
1.^匹配⾏的开始位置如^zzw匹配的是以"zzw"为⾏开头的"zzw"(注意:我这⾥想要表达的是:尽管加了⼀个^,它匹配的仍是字符串,⽽不是⼀整⾏!),如果zzw不是作为⾏开头的字符串,则它不会被匹配。
2.$匹配⾏的结尾位置如zzw$匹配的是以"zzw"为⾏结尾的"zzw"(同样,这⾥$只是匹配的⼀个位置,那个位置是零宽度,⽽不是⼀整⾏),如果zzw不是作为⾏的结尾,那么它不会被匹配。
正则表达式符号大全正则表达式是一种非常强大的字符串匹配工具,通过使用正则表达式符号,我们可以更加精确和高效地匹配字符串。
在本篇文章中,我们将为大家介绍正则表达式符号的大全。
1. 字母和数字匹配符号这些符号在正则表达式中被用来匹配特定的字母或数字:- \d:匹配任意数字,通常用来检查电话号码或邮编等数字信息。
- \w:匹配任意字母或数字,通常用来检查用户名或密码等文本信息。
- \s:匹配任意空格字符,通常用来检查段落缩进、文本对齐等信息。
- \b:匹配单词边界,通常用来检查单词和数字等信息的边界位置。
- \n:匹配换行符,通常用来检查文本行数或段落结构等信息。
2. 特殊字符匹配符号这些符号在正则表达式中被用来匹配特殊的字符:- .:匹配任意单个字符,通常用来检查任意字符的出现情况。
- ^:匹配行首,通常用来检查文本开头的信息。
- $:匹配行尾,通常用来检查文本结尾的信息。
- []:匹配一组字符中的任意一个,通常用来检查密码复杂度等信息。
- [^]:匹配不在一组字符中的任意字符,通常用来检查用户名包含非法字符等信息。
3. 重复匹配符号这些符号在正则表达式中被用来匹配重复出现的字符或模式:- *:匹配零或多个前面的字符或模式,通常用来检查表格中的单元格合并信息。
- +:匹配一或多个前面的字符或模式,通常用来检查重复出现的数字或字母等信息。
- ?:匹配零或一个前面的字符或模式,通常用来检查信息是否可选或是否存在等。
- {n}:匹配前面的字符或模式出现了 n 次,通常用来检查密码长度等信息。
- {n,}:匹配前面的字符或模式出现了至少 n 次,通常用来检查密码复杂度等信息。
- {n,m}:匹配前面的字符或模式出现了 n~m 次,通常用来检查身份证号码、电话号码等信息长度。
4. 逻辑匹配符号这些符号在正则表达式中被用来逻辑判断匹配结果:- |:匹配两个或多个模式之一,通常用来检查信息的多样性。
- ( ):将字符组合在一起,通常用来判断匹配结果的优先级。